MySQL索引
前言
因为现在使用的mysql默认存储引擎是Innodb,所以本篇文章重点讲述Innodb下的索引, 顺带简单讲述其他引擎。希望小伙伴们能通过这片文章对mysql的索引有更加清晰的认识,废话不多说,我们开始吧。
索引介绍
首先,我们先带着一些问题来看接下来的内容。
- 索引是个什么东西?
- 我们可以创建哪些索引?
- 哪些字段适合建立索引呢?
- 索引是不是越多越好呢?
- 为什么我们不建议使用uuid、身份证号等数据做为主键?
- 为什么不建议使用select * from table?
- 我们使用模糊匹配 ’%三‘ ’张%‘ 在前在后会影响索引的使用吗?
上面的问题我们大家可能都存在或者部分存在疑惑,接下来就是解惑的时间。
什么是索引
在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
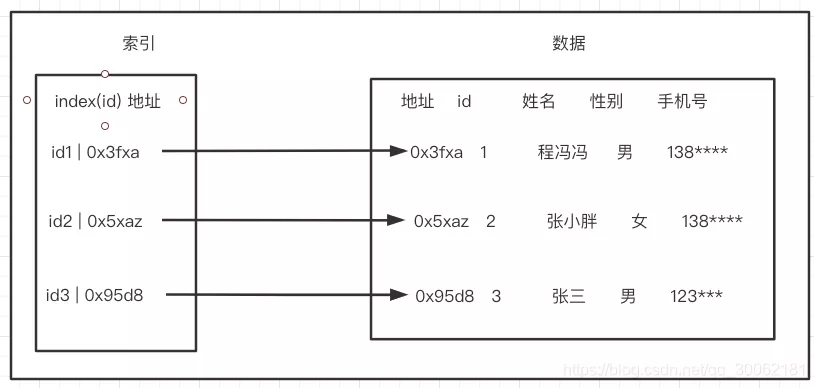
mysql中索引有哪些类型
普通索引
通索引是mysql里最基本的索引,没有什么特殊性,在任何一列上都能进行创建。
-- 创建索引的基本语法
CREATE INDEX indexName ON table(column(length));
-- 例子 length默认我们可以忽略
CREATE INDEX idx_name ON user(name);
主键索引
我们知道每张表一般都会有自己的主键,mysql会在主键上建立一个索引,这就是主键索引。主键是具有唯一性并且不允许为NULL,所以他是一种特殊的唯一索引。一般在建立表的时候选定。
复合索引
复合索引也叫组合索引,指的是我们在建立索引的时候使用多个字段,例如同时使用身份证和手机号建立索引,同样的可以建立为普通索引或者是唯一索引。
复合索引的使用复合最左原则。举个例子 我们使用 phone和name创建索引。
-- 创建索引的基本语法
CREATE INDEX indexName ON table(column1(length),column2(length));
-- 例子
CREATE INDEX idx_phone_name ON user(phone,name);
我们看下面的查询语句,
SELECT * FROM user_innodb where name = '程冯冯';
SELECT * FROM user_innodb where phone = '15100046637';
SELECT * FROM user_innodb where phone = '15100046637' and name = '程冯冯';
SELECT * FROM user_innodb where name = '程冯冯' and phone = '15100046637';
三条sql只有 2 、 3、4能使用的到索引idx_phone_name,因为条件里面必须包含索引前面的字段才能够进行匹配。而3和4相比where条件的顺序不一样,为什么4可以用到索引呢?是因为mysql本身就有一层sql优化,他会根据sql来识别出来该用哪个索引,我们可以理解为3和4在mysql眼中是等价的。
全文索引
全文索引主要用来查找文本中的关键字,而不是直接与索引中的值相比较。fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。fulltext索引配合match against操作使用,而不是一般的where语句加like。
它可以在create table,alter table ,create index使用,不过目前只有char、varchar,text 列上可以创建全文索引。正常情况下我们也不会使用到全文索引,因为这不是mysql的专长。
空间索引
空间索引是对空间数据类型的字段建立的索引,MYSQL中的空间数据类型有4种,分别是GEOMETRY、POINT、LINESTRING、POLYGON。MYSQL使用SPATIAL关键字进行扩展,使得能够用于创建正规索引类型的语法创建空间索引。
创建空间索引的列,必须将其声明为NOT NULL,空间索引只能在存储引擎为MYISAM的表中创建。空间索引一般是用不到了,了解即可。
索引的数据结构
B+Tree
innodb默认索引数据结构是B+Tree,什么是B+Tree呢,它的全名叫做平衡多路查找树PLUS。他是由平衡二叉树查找树(AVL树)演化而来。我们来介绍一下他的演化史(敲黑板,必考题)。
我们上面讲到,索引是一种有序的数据结构,因为有序才能快速的进行查找,所以我们一步步看一下索引的定型演化,首先我们讲一下什么是二叉查找树。
二叉查找树(Binary Search Trees)
二叉树查找树具有以下性质:左子树的键值小于根的键值,右子树的键值大于根的键值。
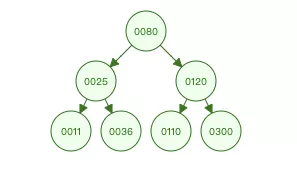
节点的顺序就是11、25、36、80、110、120、300。他的问题是不够稳定,上图我们看到了这是最好的一种情况,插入顺序是80、25、11、36、120、110、300,但是如果我们的插入顺序变成11、25、36、80、110、120、300,那么他的树结构会变成下图这样。
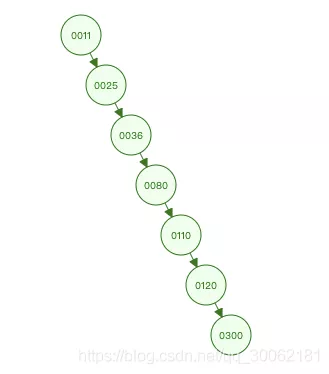
上图好好的一个二叉树变成了一个链表。之前我们查找到300需要3次查询,后者则需要7次效率是直线下降。
这里大家可以去这个网址Data StructureVisualizations自己去操作下这个流程。
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html

那么如何解决掉这种不平衡的问题呢?
AVL Trees (Balanced binary search trees)
这个时候平衡二叉查找树出现了。什么是AVL树,在计算机科学中,AVL树是最先发明的自平衡二叉查找树。在AVL树中任何节点的两个子树的高度最大差别为1,所以它也被称为高度平衡树。增加和删除可能需要通过一次或多次树旋转来重新平衡这个树。
AVL树得名于它的发明者G. M. Adelson-Velsky和E. M. Landis,名字已拼接AVL树的大名就出来了。我们下面看下avl按照11、25、36、80、110、120、300顺序进行插入的效果图。

当子树的高度超过1时他会通过自旋的方式重新平衡树,所以这样我们查询数据的时间复杂度就稳定了。有关avl树是怎样进行旋转平衡的这里就不概述了。
那么,我们使用AVL树作为索引是不是就可以了呢,答案是否定的。我们的索引是存储到磁盘上的,每次进行数据查询会将磁盘里的数据读取到内存中,对磁盘io是非常耗时的,而内存操作非常快。计算机的最小存储单元是块(block)默认4k大小,读取数据是一块一块读取的,而不是随意的读取1/2块数据,对应的我们mysql存储数据也是已页(page)为单位进行存储,默认为16K(16384B),mysql在读取的时候也是一页一页读取的。
--下面的这个命令就是查询page大小
MYSQL> show variables like 'innodb_page_size';
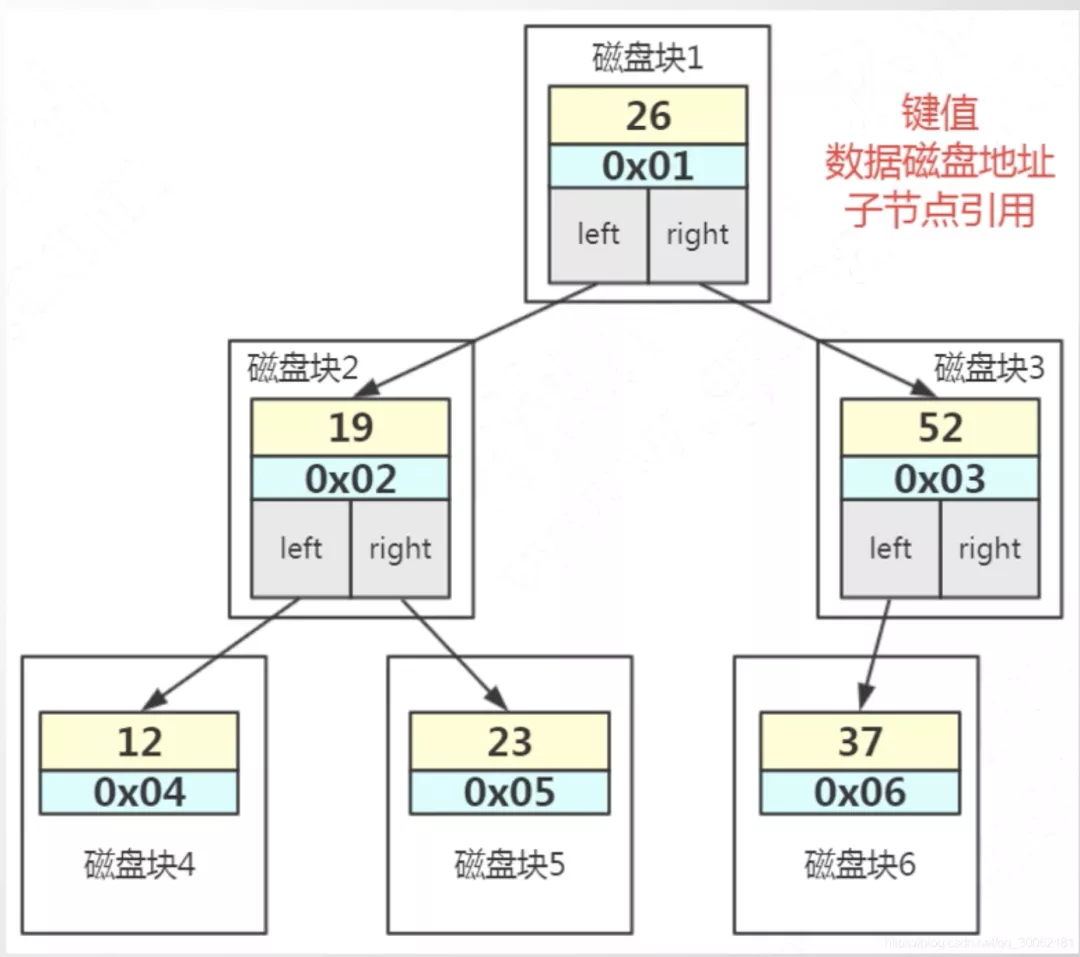
如果使用AVL树,我们的一个节点就是一页,但是一个节点是16k啊兄弟们,一页就放一个节点肯定是太浪费空间了,而且如果有1000w的数据,那么二叉树深度是55,我们要查找一个数据io的次数就有点太多了,显然这样是不合理的,我们可以怎么做呢?
B-Tree(读作 b树 不是b减树)
为了解决AVL浪费磁盘空间以及IO次数过多的问题,我们在一个节点中多存储一些数据,之前我们放一个,现在我们放多个。如果放int值(4B)我们近乎可以放4096个值,当然索引里面还包含其他的数据,不能够放这么多,但是这也是足够的多了。
这样一个节点的值多了那么树的分叉肯定就多了,假如一个节点可以存储1000的值,那么1000 * 1000 * 1000 = 10亿节点,3层的结构就能存储10亿的数据,这样是不是最多IO3次就足够了呢。
所以AVL的进化体B-Tree出现了,B-Tree的全名是多路平衡查找树,B-tree中,每个结点包含:
- 本结点所含关键字的个数;
- 指向父结点的指针;
- 关键字;
- 指向子结点的指针;
对于一棵m阶B-tree,每个结点至多可以拥有m个子结点。各结点的关键字和可以拥有的子结点数都有限制,规定m阶B-tree中,根结点至少有2个子结点,除非根结点为叶子节点,相应的,根结点中关键字的个数为1~m-1 ;非根结点至少有[m/2]([],向上取整)个子结点,相应的,关键字个数为[m/2]-1 ~ m-1。
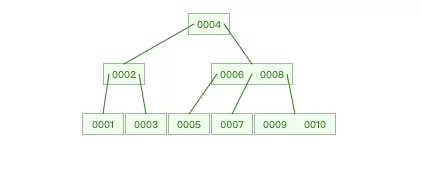
B-Tree的度是可以设置的,上面截图我设置的度为3(达到3即进行分裂),真正索引度就比较大了,一般度的大小会根据索引列的类型进行变更。大家利用好这个网站Data StructureVisualizations,自己多做一些模拟会理解的更加深刻。
说到这里我们越来越接近真相了,我们mysql索引的数据结构到底是不是B-Tree呢?
这就需要说道mysql设计的另外一个概念了——聚集索引和辅助索引。
聚集索引和辅助索引(非聚集索引)
什么是聚集索引(clustered index organize table ),聚集索引中键值的逻辑顺序和表中相应行的物理顺序相同。
聚集索引类似于电话簿,后者按姓氏排列数据。由于聚集索引规定数据在表中的物理存储顺序,因此一个表只能包含一个聚集索引。但该索引可以包含多个列(联合索引),就像电话簿按姓氏和名字进行组织一样,但是在innodb的设计中聚集索引包含整行的数据,所以innodb中索引就是数据本身,这就是大家常说的索引即数据。
官方解释聚集索引:
Every InnoDB table has a special index called the clustered index where the data for the rows is stored. Typically, the clustered index is synonymous with the primary key.
每个InnoDB表都有一个特殊的索引,称为聚簇索引 ,用于存储行数据。通常,聚簇索引与主键同义 。
非聚集索引的话其实就是一个普通索引,但是非聚集索引不存储全部数据,只存储聚集索引的值(一般为主键id)。
所以我们如果使用B-Tree来作为索引结构的话,如果数据行过大,那么一个页存储的数据就会大大减少,这就违背了我们B-Tree的初衷了——在一个页中尽可能的存储多的数据。像前面说的如果我们存储int类型可以存储几千个,那么如果我们存储整行数据呢,可能只能存储三四个,那么树的深度就会大大增加,而且我们的内存空间是有限的,每次mysql预读进来的索引数量有限,这进一步导致搜索效率变差。
所以我们想要的索引就是只包含索引字段,不应该包含全部的数据 ,看下面的对比图。
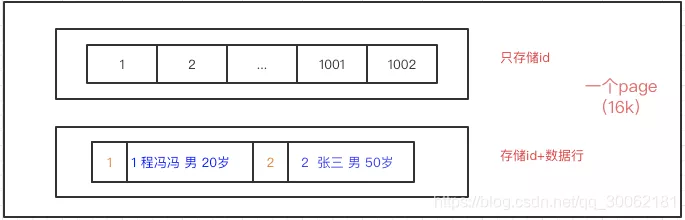
好了,该主角出场了。
B+Tree
为了解决只存储索引的问题,B-Tree的plus版本横空出世,那就是B+树。
B+ 树是一种树数据结构,是一个n叉树,每个节点通常有多个孩子,一颗B+树包含根节点、内部节点和叶子节点,和B-Tree几乎一样,只不过B+Tree不再包含整行的数据了。B+ 树通常用于数据库和操作系统的文件系统中。B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。B+ 树元素自底向上插入。
一个m阶的B树具有如下几个特征:
- 根结点至少有两个子女。
- 每个中间节点都至少包含ceil(m / 2)个孩子,最多有m个孩子。
- 每一个叶子节点都包含k-1个元素,其中 m/2 <= k <= m。
- 所有的叶子结点都位于同一层。
- 每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域分划。
下面是一个简单的展示图,让大家了解B+Tree的数据结构。相对于B-Tree最大的变化有三点:
- 数据下移,所有的非叶子节点不再存储数据而将数据全部存储到叶子节点。
- 所有的叶子节点都有一个双向的指针,做了一个双向链表
- 使用B+Tree查询次数相对固定,因为数据都在叶子节点,每一个层级都会被加载扫描。

还有一点为什么使用B+Tree呢,因为mysql查询路径的选择是根据cost(cost = cpu cost + io cost)计算的,因为索引的查询次数固定,所以io cost计算中他就可以直接舍去了,减轻了myslq的计算量。具体cost的计算不在本篇文章展开。
- cpu cost:server层对返回的记录数的compare时间。
- io cost:引擎层根据扫描记录的记录数计算cost。
另外需要补充的一点,我们已经了解到了innodb引擎中数据和索引是在一起的,而myisam引擎数据和索引是分开的,这个我们可以直接查看本地文件可以看到。
MYSQL> show variables like 'datadir';
上面的命令可以让你看到mysql的库文件存储位置。

以我本机为例,user_innodb表的存储引擎是innodb,他有两个文件.frm(表描述文件)和.ibd(索引和数据文件).
user_myisam表的存储引擎是myisam,他会有三个文件.MYD(数据文件)、.MYI(索引文件)和.frm(表描述文件)。MYD其中D就是data的意思I就是index的意思这样就记住了。ibd猜测下 index + B+Tree + data…。
MYSIAM引擎的索引文件持有的是数据文件的地址引用。
MYSIAM和Innodb的索引区别:
- innodb数据和索引在一起(数据即索引,索引即数据),而mysiam是分开存储的
- innodb索引是有主次的,也就是区分聚集索引和非聚集索引。而mysiam是不区分主次的。
非聚集索引是怎么查找数据的
上面我们已经了解了聚集索引(一般是主键索引)是如何获取的,那非聚集索引呢?下面我们看一张图。
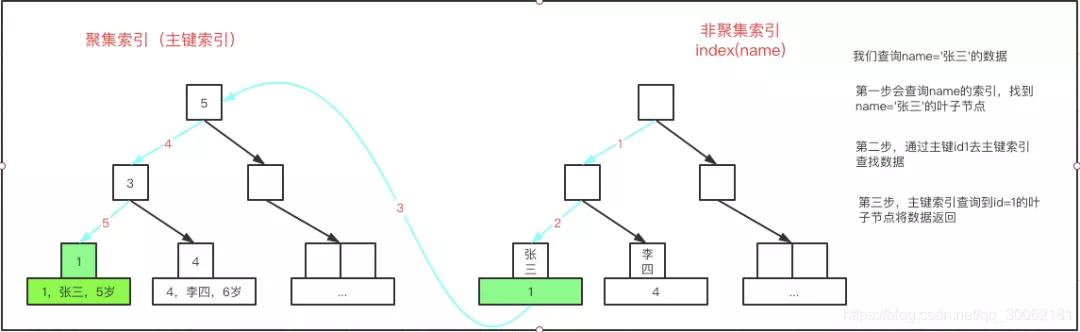
从这个图我们就可以直观的看到,非聚集索引是怎么查询数据的。每次查非聚集索引都会再次通过主键再次去聚集索引里面查询。
这里我们再引申出一个概念那就是回表,我们上图所描述的流程就是回表。回表的原因是我们需要获取的是整行或者是包含非索引字段的数据,因非聚集索引没有该字段所以需要回表查询。
因此我们建议尽量少用SELECT * FROM TABLE,例如我们查询SELECT * FROM USER WHERE name LIKE '张%',但是我们其实想要的只是名字的集合而已,那么我们就可以改造成SELECT name FROM USER WHERE name LIKE '张%',前者会回表查询而后者不会,这应就减少了数据查询的时间同时也减少了数据库的压力。
HASH索引
Hash索引就是将索引字段进行hash存储,整个hash索引的结构是Hash表+链表(因为会存在hash冲突)。
不知道大家有没有碰到过这么一种情况,我们在给数据库创建索引的时候选择了HASH但是创建完成后会默认的给我们改成B+Tree索引!没碰到的小伙伴自己去试一下看看是不是这样。
翻了一下官网找到这么一个图。

InnoDB和MyISAM竟然不支持创建HASH索引。
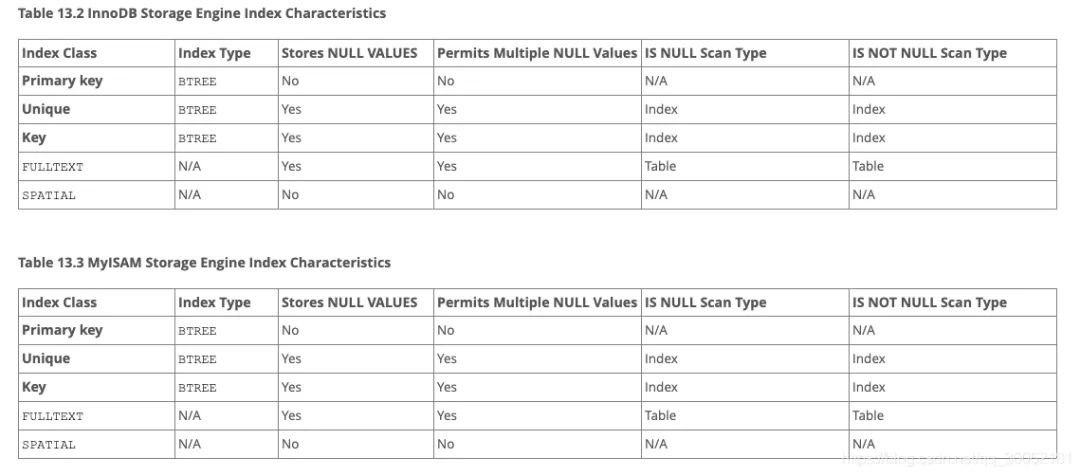
行了,这下次一巴掌打的脑瓜子嗡嗡的,只有MEMORY/NDB才能够创建Hash索引。
那InnoDB里有Hash索引吗?
Hash索引在InnoDB中的使用
在官网的InnoDB架构中有这么一张图。
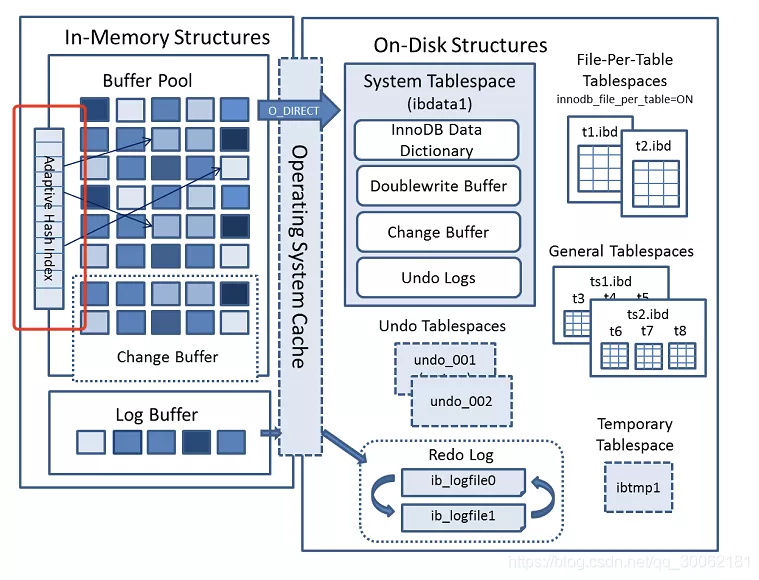
在我们Buffer Pool中有个Adaptive Hash Index(自适应hash索引)。官网是这么介绍的。
The adaptive hash index feature enables InnoDB to perform more like an in-memory database on systems with appropriate combinations of workload and sufficient memory for the buffer pool without sacrificing transactional features or reliability. The adaptive hash index feature is enabled by the innodb_adaptive_hash_index variable, or turned off at server startup by --skip-innodb-adaptive-hash-index. Based on the observed pattern of searches, a hash index is built using a prefix of the index key. The prefix can be any length, and it may be that only some values in the B-tree appear in the hash index. Hash indexes are built on demand for the pages of the index that are accessed often. If a table fits almost entirely in main memory, a hash index can speed up queries by enabling direct lookup of any element, turning the index value into a sort of pointer. InnoDB has a mechanism that monitors index searches. If InnoDB notices that queries could benefit from building a hash index, it does so automatically. With some workloads, the speedup from hash index lookups greatly outweighs the extra work to monitor index lookups and maintain the hash index structure. Access to the adaptive hash index can sometimes become a source of contention under heavy workloads, such as multiple concurrent joins. Queries with LIKE operators and % wildcards also tend not to benefit. For workloads that do not benefit from the adaptive hash index feature, turning it off reduces unnecessary performance overhead. Because it is difficult to predict in advance whether the adaptive hash index feature is appropriate for a particular system and workload, consider running benchmarks with it enabled and disabled. Architectural changes in MySQL 5.6 make it more suitable to disable the adaptive hash index feature than in earlier releases.
他说自适应哈希索引可以在InnoDB不牺牲事务功能或可靠性的情况下创建,但是他的使用范围就是Buffer Pool,那么最终这个hash索引仍然只是一个内存索引。而我们B+Tree索引是存储在磁盘的,一般只有跟节点常驻内存。推荐:250期面试题汇总
是否使用自适应hash索引由参数innodb_adaptive_hash_index控制,具体:
https://dev.mysql.com/doc/refman/5.7/en/innodb-parameters.html#sysvar_innodb_adaptive_hash_index
Hash索引的优缺点
由于Hash是基于内存的索引,那么他的检索效率是非常快的,那既然Hash索引效率这个高,我们是不是都需用Hash索引啊。
我觉得hash索引的优点只有一个,那就是快,不需要磁盘io,直接内存一次性搞定。但是要说他的缺点可真的是太多了。
- Hash索引仅仅能满足"=",“IN"和”<=>"查询,不能使用范围查询。 哈希索引只支持等值比较查询,包括=、 IN 、<=> (注意<>和<=>是不同的操作)。也不支持任何范围查询,例如WHERE price > 100。
- 由于Hash索引比较的是进行Hash运算之后的Hash值 ,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的Hash算法处理之后的Hash值的大小关系,并不能保证和Hash运算前完全一样。
- Hash索引无法被用来避免数据的排序操作。 由于Hash索引中存放的是经过Hash计算之后的Hash值,而且Hash值的大小关系并不一定和Hash运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算;
- Hash索引不能利用部分索引键查询。 对于组合索引,Hash索引在计算Hash值的时候是组合索引键合并后再一起计算Hash值,而不是单独计算Hash值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash索引也无法被利用。
- Hash索引在任何时候都不能避免表扫描。 前面已经知道,Hash索引是将索引键通过Hash运算之后,将 Hash运算结果的Hash值和所对应的行指针信息存放于一个Hash表中,由于不同索引键存在相同Hash值,所以即使取满足某个Hash键值的数据的记录条数,也无法从Hash索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。
- Hash索引遇到大量Hash值相等的情况后性能并不一定就会比BTree索引高。 对于选择性比较低的索引键,如果创建Hash索引,那么将会存在大量记录指针信息存于同一个Hash值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下。
疑问回答环节(主要针对InnoDB)
为什么辅助索引不直接存数据的地址而存主键id呢
因为数据会不断的变动,所以他的地址会跟着一起变。如果直接存储地址,下次找的数据可能就不是原先的数据了。
索引是不是创建的越多越好呢
答:并不是
- 我们已经知道了索引即数据,那么我们过多的创建索引就会导致数据量的增加。
- 我们知道索引是一颗平衡树,我们在更新数据的同时,索引也在频繁的进行页分裂和合并,非常耗时。
有关什么是页分裂和合并推荐一篇知乎文章InnoDB中的页合并与分裂,这里就不单独讲述。
为什么我们推荐使用自增id而不推荐使用uuid或者身份证号等呢
上面我们提到过B+Tree是自底向上插入的,什么意思呢。我们优先会将数据插入到叶子节点中,然后整个树会根据底部的叶子节点进行变动。
当我们使用的是自增主键呢,我们叶子节点链表会根据当前最后一条的位置,将最新的一条数据顺序的插入到后面,看下图。
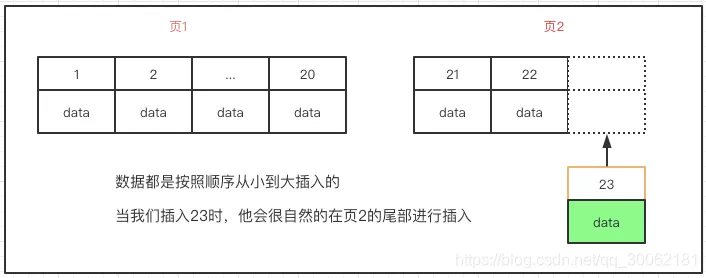
但是当你插入一个uuid时,mysql根本不知道他该插入到哪个位置,需要从头开始寻找插入的位置。但是当我们的插入的页满了时,这就造成了页的分裂和合并,极大的影响了效率。

而且我们使用uuid的话,uuid所占字节也比较长,就导致了每一页存储的数据就会变少,也不利于索引的数据查询。
哪些列适合添加索引呢
- 需要经常where的字段
- 需要join连表的字段
- 需要排序的字段
- 需要group by的字段
我们需不需要在性别上加索引呢?
这个呢我们就做个测试,我有一个300w数据的表。
CREATE TABLE `user_innodb` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`gender` tinyint(1) DEFAULT NULL,
`phone` varchar(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3000001 DEFAULT CHARSET=utf8mb4;
我们首先查询一下性别为男的所有数据。
SELECT *
from user_innodb
where gender = 1;
没加索引之前,我们用explain看下执行效率。
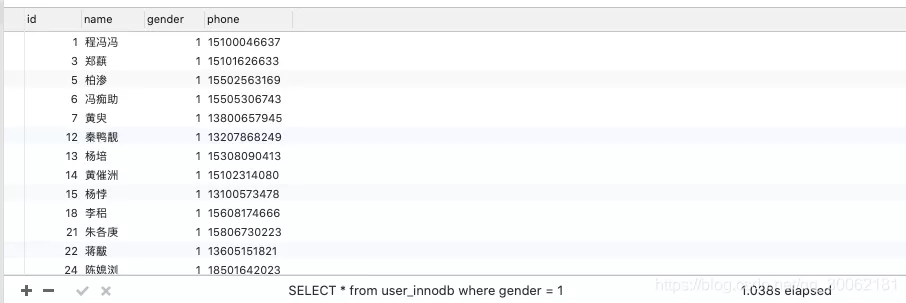
执行结果是1s,还可以接受。
加了索引之后,最终结果出来没让我失望22s。
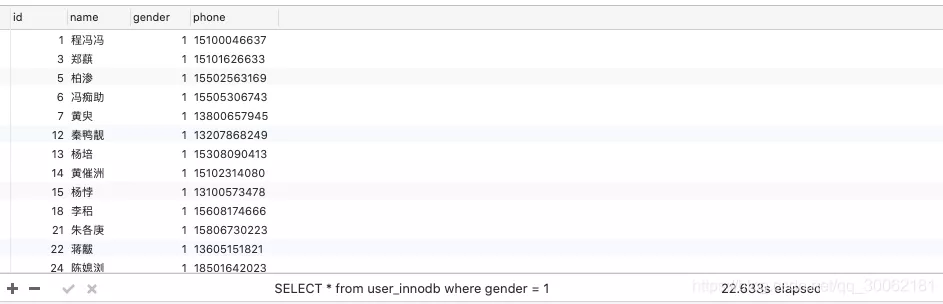
所以实验就证明了不能够在性别上创建索引。为什么会有这么大的差别呢,加了索引反而比不加索引更慢。
因为,在没有索引的情况下,mysql只需遍历底部的链表即可。但是加了索引以后他会查询index(gender)找到合法的索引的主键,然后通过主键再去index(id)里面去找这样一来一回效率自然就直线下降。
那么我们创建索引有什么特别的依据吗,这里就给大家一个公式:count(distinct(column_name)) : count(*),这个可以简单地计算出这个字段的离散值,离散值越高说明建立索引效果更明显。例如我们给手机号加索引,最后计算出来的离散度是1,说明非常有必要加索引。
like '%张’一定不走索引吗
我们再次进行个测试,我们给phone和name两个字段建立一个联合索引idx_phone_name。然后看下下面这条语句的执行计划。
EXPLAIN SELECT *
FROM user_innodb
WHERE name LIKE '%张' and phone = '13204776301';
这种情况下因为phone在索引第一位,所以无论有没有name这个条件都会走索引。

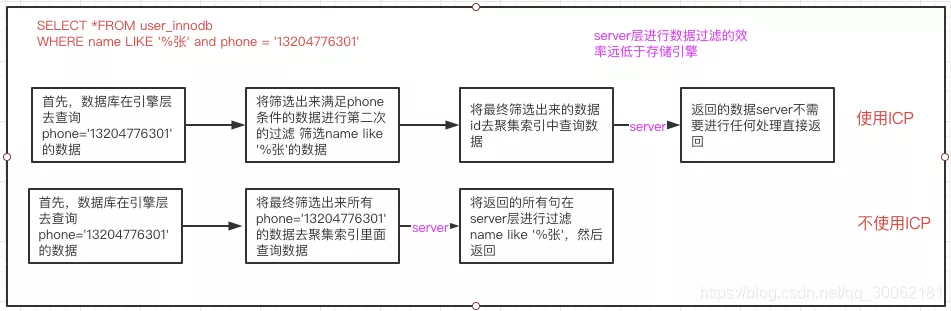
我们可以看到extra里面存在Using index condition(ICP),ICP的全名是index condition pushdown索引条件下推。
ICP 索引条件下推
索引条件下推(ICP)是针对MySQL使用索引从表中检索行的情况的一种优化。如果不使用ICP,则存储引擎将遍历索引以在基表中定位行,并将其返回给MySQL服务器,后者将评估WHERE行的条件。
启用ICP后,如果WHERE可以仅使用索引中的列来评估部分 条件,则MySQL服务器会将这部分条件压入WHERE条件下降到存储引擎。然后,存储引擎通过使用索引条目来评估推送的索引条件,并且只有在满足此条件的情况下,才从表中读取行。ICP可以减少存储引擎必须访问基表的次数以及MySQL服务器必须访问存储引擎的次数。
索引条件下推式优化的适用性取决于以下条件:
- ICP用于 range, ref, eq_ref,和 ref_or_null访问方法时,有一个需要访问的全部表行。
- ICP可用于InnoDB 和MyISAM表,包括分区表InnoDB和 MyISAM表。
- 对于InnoDB表,ICP仅用于二级索引。ICP的目标是减少全行读取次数,从而减少I / O操作。对于 InnoDB聚集索引,完整的记录已被读入InnoDB 缓冲区。在这种情况下使用ICP不会减少I / O。
- 在虚拟生成的列上创建的二级索引不支持ICP。InnoDB 支持虚拟生成的列上的二级索引。
- 引用子查询的条件不能下推。
- 涉及存储功能的条件不能下推。
- 存储引擎无法调用存储的功能。
- 触发条件不能下推。
具体的IPC相关的信息,建议参考官网
我那上面的那条sql进行个举例,说明下什么是ICP,看下图,一切都在图里。
如果表没有主键怎么办,聚集索引怎么建立
- 默认情况下我们在设置表主键的时候,数据库会默认将其设置为聚集索引。
- 如果没有定义主键,那么mysql会找第一个唯一索引来作为局促索引,前提是聚集索引是NOT NULL
- 如果上面的两个条件都没有满足,那么InnoDB会生成一个隐藏的聚集索引GEN_CLUST_INDEX,每一行都生成一个默认自增的主键id。
来源:blog.csdn.net/qq_30062181/article/details/112712362

 浙公网安备 33010602011771号
浙公网安备 33010602011771号