

几种常用的分布式 ID 解决方案
一、分布式ID概念
说起ID,特性就是唯一,在人的世界里,ID就是身份证,是每个人的唯一的身份标识。在复杂的分布式系统中,往往也需要对大量的数据和消息进行唯一标识。
举个例子,数据库的ID字段在单体的情况下可以使用自增来作为ID,但是对数据分库分表后一定需要一个唯一的ID来标识一条数据,这个ID就是分布式ID。对于分布式ID而言,也需要具备分布式系统的特点:高并发,高可用,高性能等特点。
二、分布式ID实现方案
下表为一些常用方案对比:
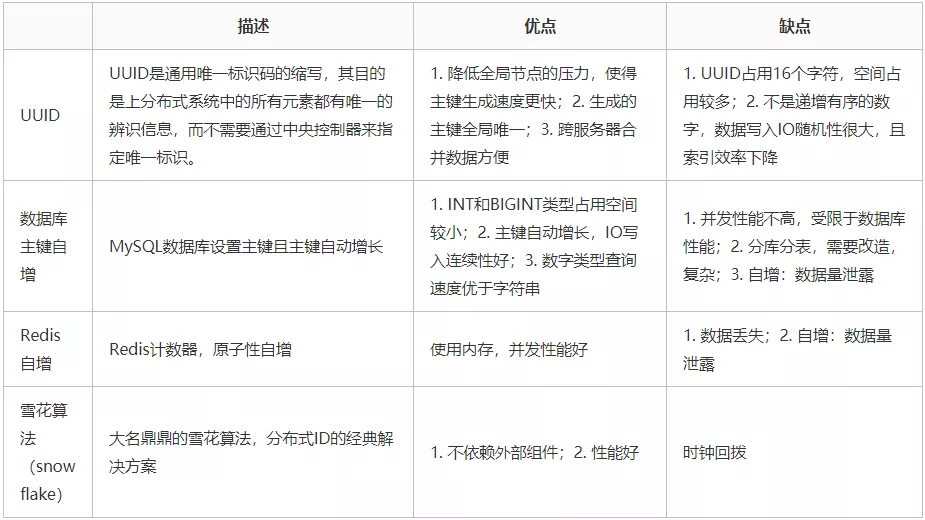
目前流行的分布式ID解决方案有两种:「号段模式」和「雪花算法」。
「号段模式」依赖于数据库,但是区别于数据库主键自增的模式。假设100为一个号段100,200,300,每取一次可以获得100个ID,性能显著提高。
「雪花算法」是由符号位+时间戳+工作机器id+序列号组成的,如图所示:

符号位为0,0表示正数,ID为正数。
时间戳位不用多说,用来存放时间戳,单位是ms。
工作机器id位用来存放机器的id,通常分为5个区域位+5个服务器标识位。
序号位是自增。
雪花算法能存放多少数据?时间范围:2^41 / (3652460601000) = 69年 工作进程范围:2^10 = 1024 序列号范围:2^12 = 4096,表示1ms可以生成4096个ID。
根据这个算法的逻辑,只需要将这个算法用Java语言实现出来,封装为一个工具方法,那么各个业务应用可以直接使用该工具方法来获取分布式ID,只需保证每个业务应用有自己的工作机器id即可,而不需要单独去搭建一个获取分布式ID的应用。下面是推特版的Snowflake算法:
public class SnowFlake {
/**
* 起始的时间戳
*/
private final static long START_STMP = 1480166465631L;
/**
* 每一部分占用的位数
*/
private final static long SEQUENCE_BIT = 12; //序列号占用的位数
private final static long MACHINE_BIT = 5; //机器标识占用的位数
private final static long DATACENTER_BIT = 5;//数据中心占用的位数
/**
* 每一部分的最大值
*/
private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);
private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
/**
* 每一部分向左的位移
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;
private long datacenterId; //数据中心
private long machineId; //机器标识
private long sequence = 0L; //序列号
private long lastStmp = -1L;//上一次时间戳
public SnowFlake(long datacenterId, long machineId) {
if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) {
throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0");
}
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");
}
this.datacenterId = datacenterId;
this.machineId = machineId;
}
/**
* 产生下一个ID
*
* @return
*/
public synchronized long nextId() {
long currStmp = getNewstmp();
if (currStmp < lastStmp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (currStmp == lastStmp) {
//相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列数已经达到最大
if (sequence == 0L) {
currStmp = getNextMill();
}
} else {
//不同毫秒内,序列号置为0
sequence = 0L;
}
lastStmp = currStmp;
return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分
| datacenterId << DATACENTER_LEFT //数据中心部分
| machineId << MACHINE_LEFT //机器标识部分
| sequence; //序列号部分
}
private long getNextMill() {
long mill = getNewstmp();
while (mill <= lastStmp) {
mill = getNewstmp();
}
return mill;
}
private long getNewstmp() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
SnowFlake snowFlake = new SnowFlake(2, 3);
for (int i = 0; i < (1 << 12); i++) {
System.out.println(snowFlake.nextId());
}
}
}
三、分布式ID开源组件
3.1 如何选择开源组件
选择开源组件首先需要看软件特性是否满足需求,主要包括兼容性和扩展性。
其次需要看目前的技术能力,根据目前自己或者团队的技术栈和技术能力,能否可以平滑的使用。
第三,要看开源组件的社区,主要关注更新是否频繁、项目是否有人维护、遇到坑的时候可以取得联系寻求帮助、是否在业内被广泛使用等。
3.2 美团Leaf
Leaf是美团基础研发平台推出的一个分布式ID生成服务,名字取自德国哲学家、数学家莱布尼茨的一句话:“There are no two identical leaves in the world.”Leaf具备高可靠、低延迟、全局唯一等特点。
目前已经广泛应用于美团金融、美团外卖、美团酒旅等多个部门。具体的技术细节,可参考美团技术博客的一篇文章:《Leaf美团分布式ID生成服务》。
目前,Leaf项目已经在Github上开源:
https://github.com/Meituan-Dianping/Leaf。
Leaf在特性如下:
- 全局唯一,绝对不会出现重复的ID,且ID整体趋势递增。
- 高可用,服务完全基于分布式架构,即使MySQL宕机,也能容忍一段时间的数据库不可用。
- 高并发低延时,在CentOS 4C8G的虚拟机上,远程调用QPS可达5W+,TP99在1ms内。
- 接入简单,直接通过公司RPC服务或者HTTP调用即可接入。
3.3 百度UidGenerator
UidGenerator百度开源的一款基于Snowflake算法的分布式高性能唯一ID生成器。采用官网的一段描述:UidGenerator以组件形式工作在应用项目中, 支持自定义workerId位数和初始化策略, 从而适用于docker等虚拟化环境下实例自动重启、漂移等场景。
在实现上, UidGenerator通过借用未来时间来解决sequence天然存在的并发限制; 采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费, 同时对CacheLine补齐,避免了由RingBuffer带来的硬件级「伪共享」问题. 最终单机QPS可达600万。
UidGenerator的GitHub地址:
https://github.com/baidu/uid-generator
3.4 开源组件对比
百度UidGenerator是Java语言的;最近一次提交记录是两年前,基本无人维护;只支持雪花算法。
美团Leaf也是Java语言的;最近维护为2020年;支持号段模式和雪花算法。
综上理论和两款开源组件的对比,还是美团Leaf稍胜一筹。
来源:cnblogs.com/SmallStrange/p/14277333.html

