DRF的序列化器
一、序列化和反序列化
1、序列化:把我们的数据转换成指定的格式提供给别人
例如:我们在django中获取到的数据默认是模型对象,但是模型对象数据无法直接提供给前端或别的平台使用,所以我们需要把数据进行序列化,变成字符串或者json数据,提供给别人。
2、反序列化:把别人提供的数据转换/还原成我们需要的格式
例如:前端js提供过来的json数据,对于python而言json就是字符串,我们需要进行反序列化换成字典,然后接着字典再进行转换成模型对象,这样我们才能把数据保存到数据库中。
二、DRF中的序列化器
1、Serializer 序列化器
序列化并返回给前端,其中bs序列化后的对象,bs.data就是要返回的值,many=True表示返回多条数据,通过Response返回json数据到前端。

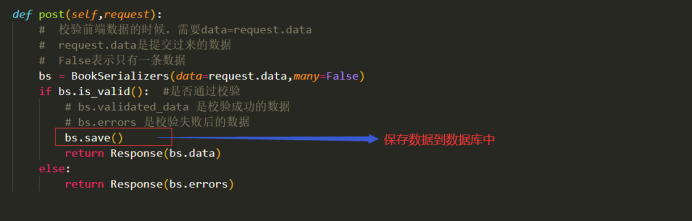
接收前端POST提交的数据和校验:

注意:
此时如果要保存到数据库中,则需要使用常规的模型操作 create()方法。
也可以调用save()方法,但是调用save()方法的时候,会调用序列化器下的create()方法,create方法必须自定义(因为默认的create没有写任何内容)。
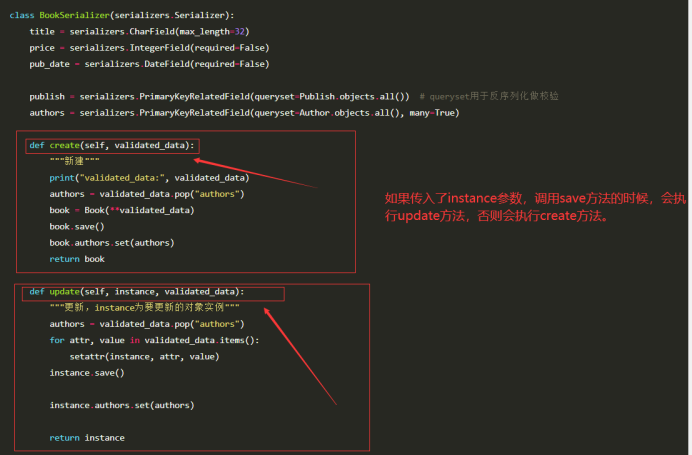
2、ModelSerializer 序列化器
使用ModelSerializer定义序列化器的时候,不需要再像前面一样去自己定义序列化的字段,而是可以直接通过使用模型类。
创建序列化器:(model=Book: 指定对Book表模型进行序列化)

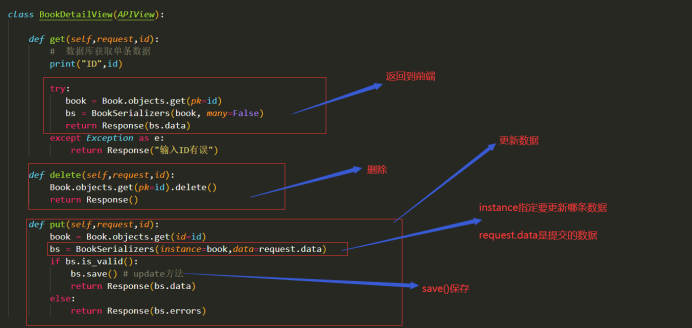
-------- 返回数据到前端 / 接收前端提交的数据 / 保存数据到数据库中 / 更新数据到数据库中:
注意:此时要保存数据只需要调用save()即可, 如果没有传入instance参数则为新增,如果传入了instance则为更新。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现