Python爬取数据并保存到csv文件中
1、数据源
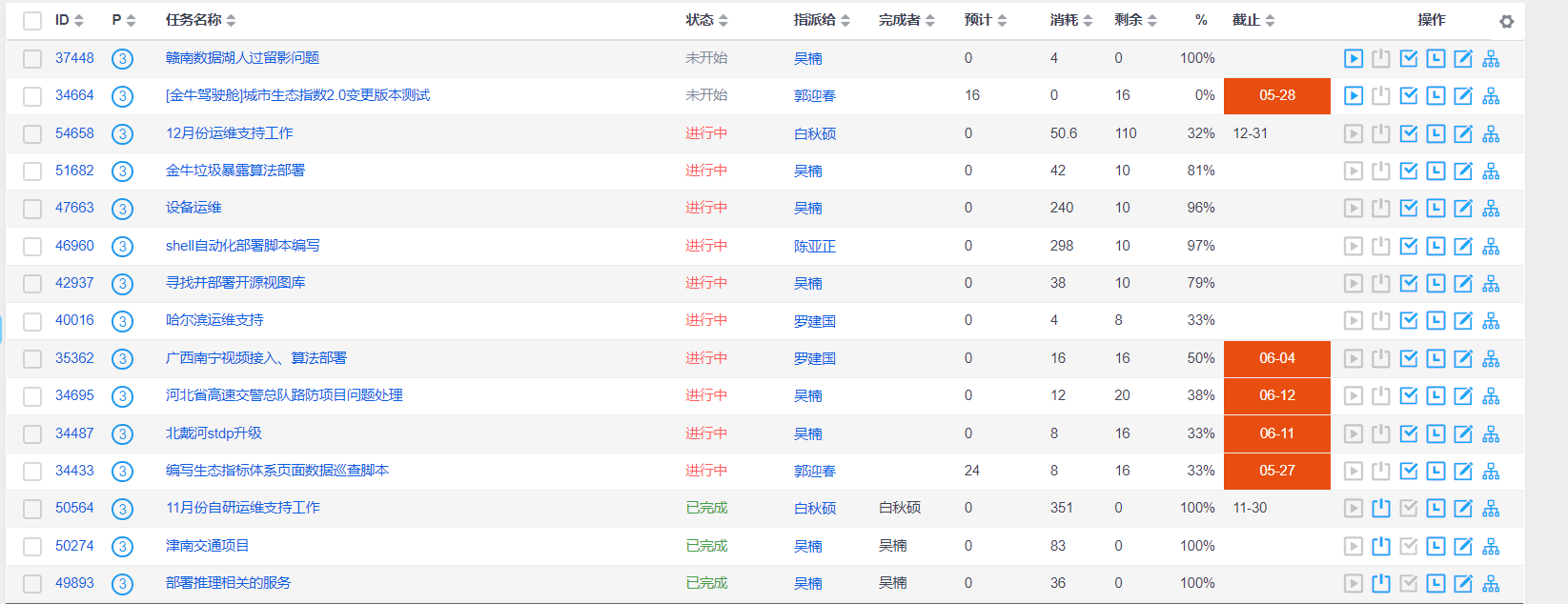
2、Python代码
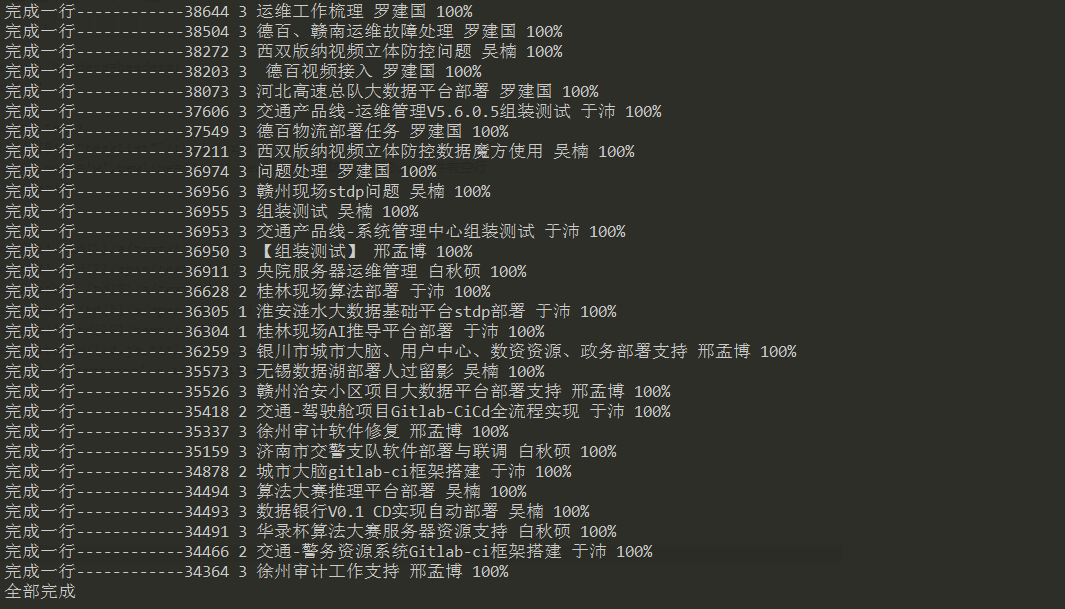
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | import requestsfrom lxml import etreeimport csvurl = 'http://211.103.175.222:5080/zentaopms/www/index.php?m=project&f=task&projectID=830'headers = { 'Cookie': 'lang=zh-cn; device=desktop; theme=default; feedbackView=0; lastProject=830; preProjectID=830; lastTaskModule=0; projectTaskOrder=status%2Cid_desc; pagerProjectTask=2000; keepLogin=on; za=zhangyh01; zp=2a7befd1193619083ca09e00e186dc709a5722c2; windowWidth=1707; windowHeight=679; zentaosid=revjktmd869d6q7ilfhrjp1bpn'}res = requests.get(url,headers=headers)res.encoding = 'utf-8'tree = etree.HTML(res.text)trs = tree.xpath('//*[@id="taskList"]/tbody/tr')f = open('result.csv',mode='w',newline='') # newline='':防止保存的csv文件有空行csv_writer = csv.writer(f)for tr in trs: id = tr.xpath('./td[1]/a/text()')[0] jb = tr.xpath('./td[2]/span/text()')[0] title = tr.xpath('./td[3]/a/text()')[0] name = tr.xpath('./td[5]/a/span/text()')[0] wcl = tr.xpath('./td[10]/text()')[0] csv_writer.writerow([id,jb,title,name,wcl]) print('完成一行------------' + id,jb,title,name,wcl)f.close()print('全部完成') |
3、执行过程
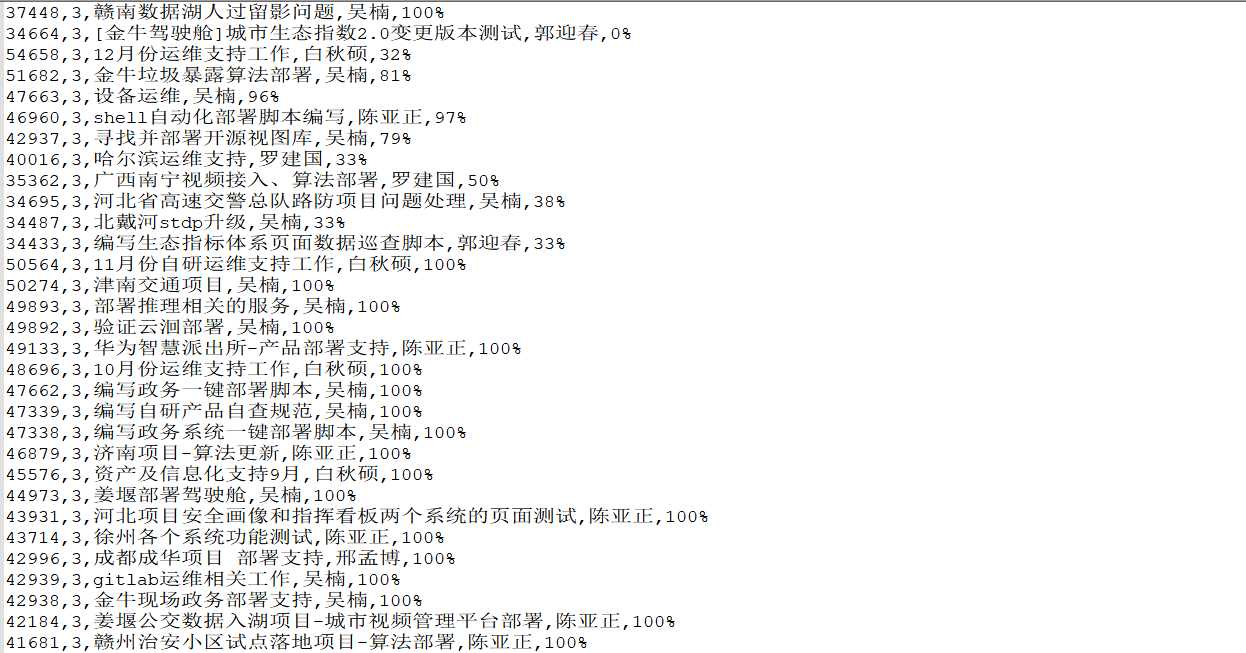
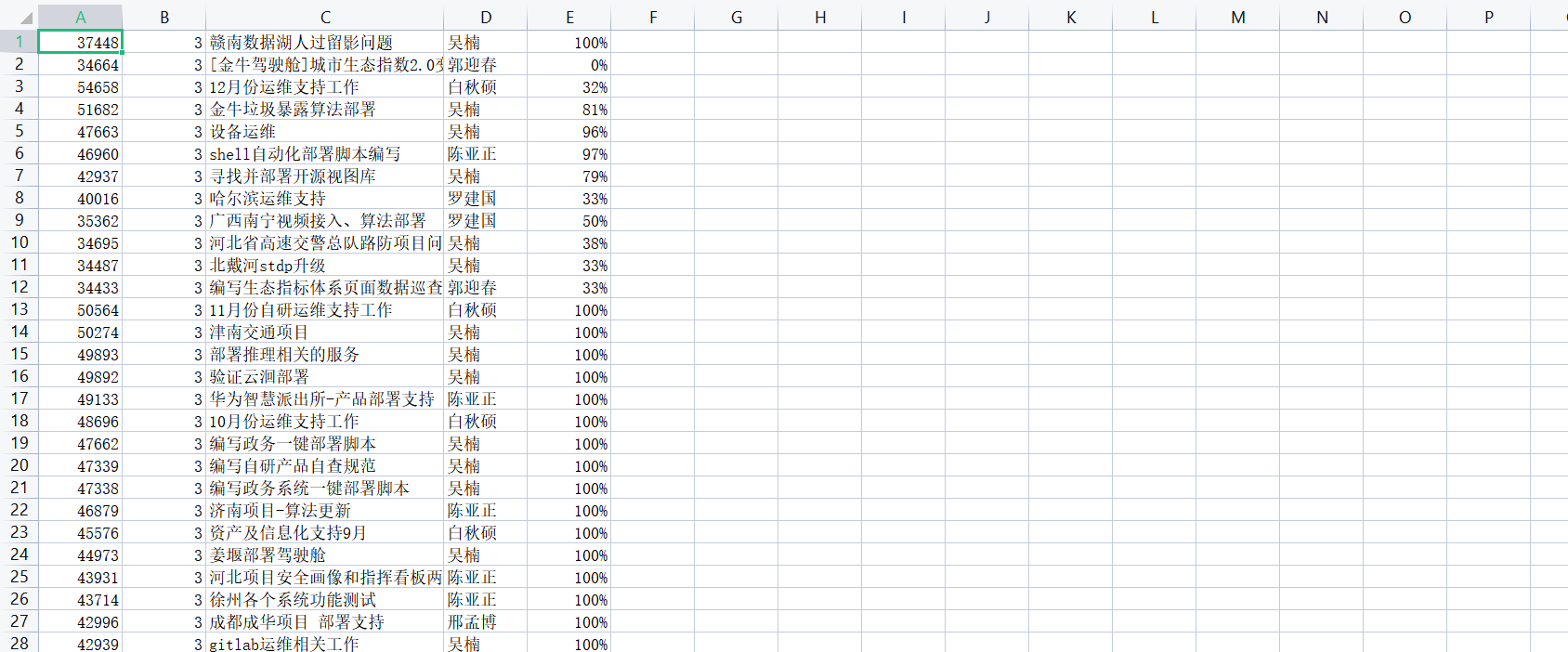
4、保存的结果


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现