9 May 18
一、上课节复习:
python对数据类型的规范是对存入内存中的数据的规范
mysql对数据类型的规范是对存入硬盘中的数据的规范
二、如何判断表与表之间的关系(多对一,多对多,一对一):
a、 左表与右表之间是否有多对一的关系 (多个员工属于一个部门)
b、 右表与左表之间是否有多对一的关系 (多个部门拥有一个员工)
i、a True & b False à 多对一
ii、a False & b True à 多对一
iii、a True & b True à 多对多
iv、a False & b False à 一对一
三、所有数据都存放于一张表中的弊端:
1、表的组织结构复杂不清晰
2、浪费空间
3、扩展性极差
解决方案:分表
a、 分表 + foreign key: 有硬性限制(关联表中的关联字段内容必须来自于被关联表),但后续修改删除麻烦(不能直接修改,删除要先删除关联对象中的相应元素再删除被关联对象中的相应元素)
#foreign key (MUL): 可以理解成外部有一个硬性限制
b、 分表 + foreign key + on update cascade on delete cascade: 有硬性限制,对被关联表进行修改删除,关联表相应元素跟着改变;强耦合
c、 分表: 靠逻辑上的关系维护,解开耦合
四、表与表之间的关系之多对一(两张表之间单向的多对一关系,称为多对一)
i、a True & b False à 多对一
ii、a False & b True à 多对一
实现多对一: 在emp表中新增一个dep_id字段,该字段指向dep表的id字段
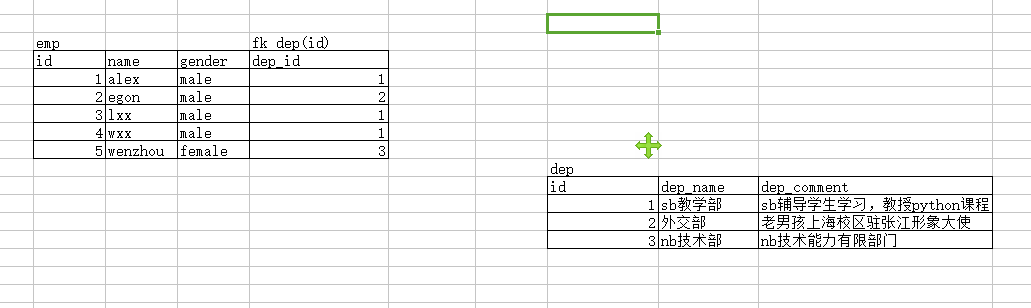
foreign key会带来什么样的效果?
约束1:在创建表时,先建被关联的表dep,才能建关联表emp
create table dep(
id int primary key auto_increment,
dep_name char(10),
dep_comment char(60)
);
create table emp(
id int primary key auto_increment,
name char(16),
gender enum('male','female') not null default 'male',
dep_id int,
foreign key(dep_id) references dep(id)
);
约束2:在插入记录时,必须先插被关联的表dep,才能插关联表emp
insert into dep(dep_name,dep_comment) values
('sb教学部','sb辅导学生学习,教授python课程'),
('外交部','老男孩上海校区驻张江形象大使'),
('nb技术部','nb技术能力有限部门');
insert into emp(name,gender,dep_id) values
('alex','male',1),
('egon','male',2),
('lxx','male',1),
('wxx','male',1),
('wenzhou','female',3);
约束3:更新与删除都需要考虑到关联与被关联的关系
a、单单只加foreign key:有硬性限制,但后续修改删除麻烦(不能直接修改,删除要先删除关联对象中的相应元素再删除被关联对象中的相应元素)
b、foreign key + on update cascade on delete cascade:
1)先删除关联表emp,再删除被关联表dep,准备重建
mysql> drop table emp;
mysql> drop table dep;
2)重建:新增功能,同步更新,同步删除
create table dep(
id int primary key auto_increment,
dep_name char(10),
dep_comment char(60)
);
create table emp(
id int primary key auto_increment,
name char(16),
gender enum('male','female') not null default 'male',
dep_id int,
foreign key(dep_id) references dep(id)
on update cascade
on delete cascade #一条语句
);
insert into dep(dep_name,dep_comment) values
('sb教学部','sb辅导学生学习,教授python课程'),
('外交部','老男孩上海校区驻张江形象大使'),
('nb技术部','nb技术能力有限部门');
insert into emp(name,gender,dep_id) values
('alex','male',1),
('egon','male',2),
('lxx','male',1),
('wxx','male',1),
('wenzhou','female',3);
3)效果演示之同步删除
mysql> select * from dep;
+----+------------------+------------------------------------------------------------------------------------------+
| id | dep_name | dep_comment |
+----+------------------+------------------------------------------------------------------------------------------+
| 1 | sb教学部 | sb辅导学生学习,教授python课程 |
| 2 | 外交部 | 老男孩上海校区驻张江形象大使 |
| 3 | nb技术部 | nb技术能力有限部门 |
+----+------------------+------------------------------------------------------------------------------------------+
3 rows in set (0.00 sec)
mysql> select * from emp;
+----+------------------+--------+--------+
| id | name | gender | dep_id |
+----+------------------+--------+--------+
| 1 | alex | male | 1 |
| 2 | egon | male | 2 |
| 3 | lxx | male | 1 |
| 4 | wxx | male | 1 |
| 5 | wenzhou | female | 3 |
+----+------------------+--------+--------+
5 rows in set (0.00 sec)
mysql> delete from dep where id=1;
Query OK, 1 row affected (0.02 sec)
mysql> select * from dep;
+----+------------------+------------------------------------------------------------------------------------------+
| id | dep_name | dep_comment |
+----+------------------+------------------------------------------------------------------------------------------+
| 2 | 外交部 | 老男孩上海校区驻张江形象大使 |
| 3 | nb技术部 | nb技术能力有限部门 |
+----+------------------+------------------------------------------------------------------------------------------+
2 rows in set (0.00 sec)
mysql> select * from emp;
+----+------------------+--------+--------+
| id | name | gender | dep_id |
+----+------------------+--------+--------+
| 2 | egon | male | 2 |
| 5 | wenzhou | female | 3 |
+----+------------------+--------+--------+
2 rows in set (0.00 sec)
3)效果演示之同步更新
mysql> select * from emp;
+----+------------------+--------+--------+
| id | name | gender | dep_id |
+----+------------------+--------+--------+
| 2 | egon | male | 2 |
| 5 | wenzhou | female | 3 |
+----+------------------+--------+--------+
2 rows in set (0.00 sec)
mysql> update dep set id=200 where id =2;
Query OK, 1 row affected (0.04 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from dep;
+-----+------------------+------------------------------------------------------------------------------------------+
| id | dep_name | dep_comment |
+-----+------------------+------------------------------------------------------------------------------------------+
| 3 | nb技术部 | nb技术能力有限部门 |
| 200 | 外交部 | 老男孩上海校区驻张江形象大使 |
+-----+------------------+------------------------------------------------------------------------------------------+
2 rows in set (0.00 sec)
mysql> select * from emp;
+----+------------------+--------+--------+
| id | name | gender | dep_id |
+----+------------------+--------+--------+
| 2 | egon | male | 200 |
| 5 | wenzhou | female | 3 |
+----+------------------+--------+--------+
2 rows in set (0.00 sec)
五、清空表
1、delete from tb1;
上面的这条命令确实可以将表里的所有记录都删掉,但不会将id重置为0
该条命令不是用来清空表的,delete是用来删除表中某一些符合条件的记录 (delete from tb1 where id > 10;)
2、truncate tb1;
如果要清空表,使用truncate tb1;
作用:将整张表重置
六、多对多(两张表之间是一个双向的多对一关系,称之为多对多)
iii、a True & b True à 多对多
实现多对多:建立第三张表,该表中有一个字段fk左表的id,还有一个字段是fk右表的id
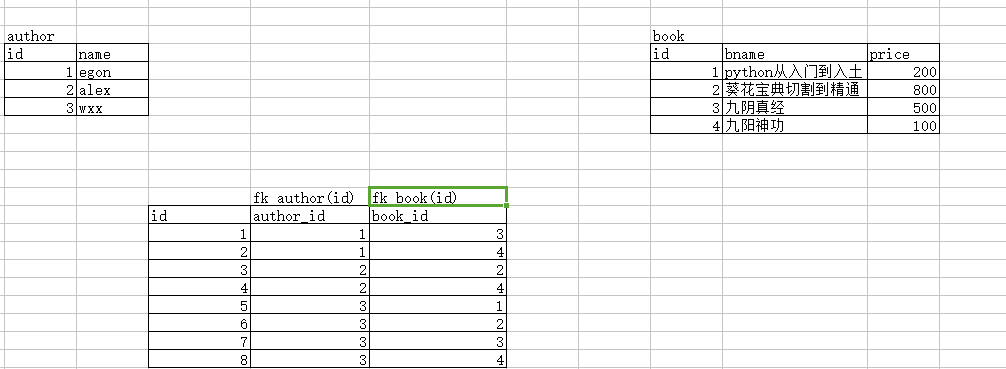
create table author(
id int primary key auto_increment,
name char(16)
);
create table book(
id int primary key auto_increment,
bname char(16),
price int
);
insert into author(name) values
('egon'),
('alex'),
('wxx')
;
insert into book(bname,price) values
('python从入门到入土',200),
('葵花宝典切割到精通',800),
('九阴真经',500),
('九阳神功',100)
;
create table author2book(
id int primary key auto_increment,
author_id int,
book_id int,
foreign key(author_id) references author(id)
on update cascade
on delete cascade,
foreign key(book_id) references book(id)
on update cascade
on delete cascade
);
insert into author2book(author_id,book_id) values
(1,3),
(1,4),
(2,2),
(2,4),
(3,1),
(3,2),
(3,3),
(3,4);
七、多表查询思路:
egon写了什么书?
a、 在author表中找到egon对应的id(author_id)
b、 根据author_id 在关系表中找到对应的book_id
c、 根据book_id 再book表中找到对应的book_name
八、一对一(左表的一条记录唯一对应右表的一条记录,反之也一样)
iv、a False & b False à 一对一
实现一对一:在emp表中新增一个dep_id字段,该字段指向dep表的id字段, foreign key + unique; 在多对一的基础上限制关联表中的相应字段必须唯一
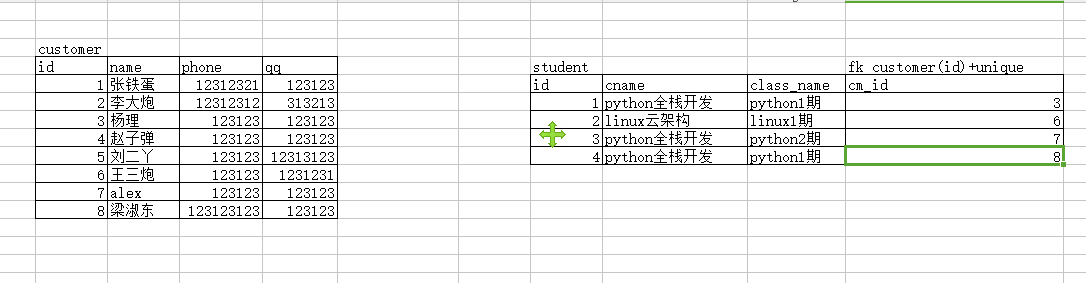
create table customer(
id int primary key auto_increment,
name char(20) not null,
qq char(10) not null,
phone char(16) not null
);
create table student(
id int primary key auto_increment,
class_name char(20) not null,
customer_id int unique, #该字段一定要是唯一的
foreign key(customer_id) references customer(id) #外键的字段一定要保证unique
on delete cascade
on update cascade
);
insert into customer(name,qq,phone) values
('李飞机','31811231',13811341220),
('王大炮','123123123',15213146809),
('守榴弹','283818181',1867141331),
('吴坦克','283818181',1851143312),
('赢火箭','888818181',1861243314),
('战地雷','112312312',18811431230)
;
insert into student(class_name,customer_id) values
('脱产3班',3),
('周末19期',4),
('周末19期',5)
;
九、修改表
1. 修改表名
ALTER TABLE 表名 RENAME 新表名;
#mysql中库名、表名对大小写不敏感
2. 增加字段
ALTER TABLE 表名ADD 字段名 数据类型 [完整性约束条件…], ADD 字段名 数据类型 [完整性约束条件…];
ALTER TABLE 表名ADD 字段名 数据类型 [完整性约束条件…] FIRST; #插第一行
ALTER TABLE 表名ADD 字段名 数据类型 [完整性约束条件…] AFTER 字段名; #插在某一条记录之后
3. 删除字段
ALTER TABLE 表名 DROP 字段名;
4. 修改字段
ALTER TABLE 表名 MODIFY 字段名 数据类型 [完整性约束条件…];
#modify不能改字段名
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 旧数据类型 [完整性约束条件…];
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 新数据类型 [完整性约束条件…];
#change可以改字段名
#修改表通常改的是字段,而不修改数据类型(前后冲突则报错)
十、复制表
a、复制表结构+记录 (key不会复制: 主键、外键和索引)
mysql> create table new_service select * from service;
b、只复制表结构
mysql> select * from service where 1=2; //条件为假,查不到任何记录
Empty set (0.00 sec)
mysql> create table new1_service select * from service where 1=2;
Query OK, 0 rows affected (0.00 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> create table t4 like employees; #表结构一摸一样
十一、删除表
DROP TABLE 表名;
十二、单表查询(预习)
mysql> select * from emp;
+----+------------------+--------+--------+
| id | emp_name | gender | dep_id |
+----+------------------+--------+--------+
| 2 | egon | male | 200 |
| 5 | wenzhou | female | 3 |
+----+------------------+--------+--------+
2 rows in set (0.00 sec)
select id,name from emp
where id > 1 and name like "%on%"
group by dep_id
having 分组后的过滤条件
order by 排序依据
limit n;





