Python实战案例系列(一)
本节目录
- 烟草扫码数据统计
- 奖学金统计
实战一、烟草扫码数据统计
1. 需求分析
根据扫码信息在数据库文件中匹配相应规格详细信息,并进行个数统计
条码库.xls
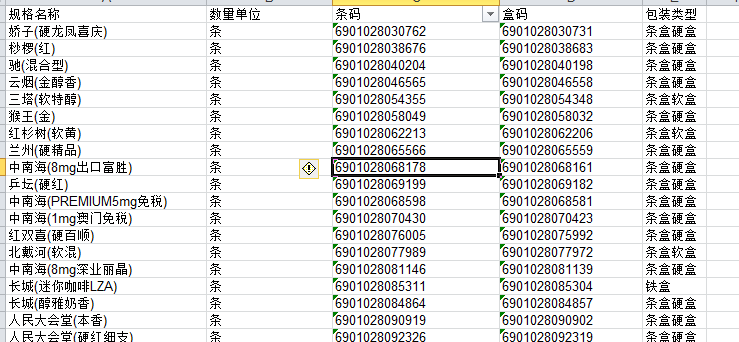
扫码.xlsx
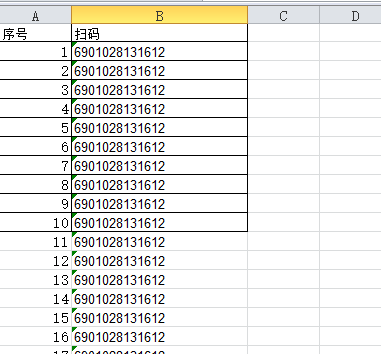
一个条码对应多个规格名称.xlsx

2. 代码实现
# -*- coding: utf-8 -*-
"""
Datetime: 2020/08/05
Author: ZhangYafei
Description: 扫码数据统计
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xlrd xlwt pandas
python scan_code_stat.py -d 条码库文件路径 -f 扫码文件路径 -o 统计结果输出文件路径
或者
python scan_code_stat.py
默认为 -d 条码库 -f 扫码 -o 统计结果.xlsx
"""
from functools import wraps
from collections import defaultdict
import pandas as pd
import os
import time
from optparse import OptionParser
def get_option():
opt_parser = OptionParser()
opt_parser.add_option('-d', '--infile1', action='store', type="string", dest='code_db_file', default='条码库')
opt_parser.add_option('-f', '--infile2', action='store', type="string", dest='code_file', default='扫码')
opt_parser.add_option("-o", "--outfile", action="store", dest="output_file", default='统计结果.xlsx', help='输出文件路径')
option, args = opt_parser.parse_args()
return option.code_db_file, option.code_file, option.output_file
def timeit(func):
"""
装饰器: 判断函数执行时间
:param func:
:return:
"""
@wraps(func)
def inner(*args, **kwargs):
start = time.time()
ret = func(*args, **kwargs)
end = time.time() - start
if end < 60:
print(f'花费时间: {round(end, 2)}秒')
else:
min, sec = divmod(end, 60)
print(f'花费时间 {round(min)}分 {round(sec, 2)}秒')
return ret
return inner
def read_file(file_name: str, converters: dict = None):
if file_name.endswith('xls') or file_name.endswith('xlsx'):
return pd.read_excel(file_name, converters=converters) if converters else pd.read_excel(file_name)
if os.path.exists(f'{file_name}.xls'):
return pd.read_excel(f'{file_name}.xls', converters=converters) if converters else pd.read_excel(f'{file_name}.xls')
elif os.path.exists(f'{file_name}.xlsx'):
return pd.read_excel(f'{file_name}.xlsx', converters=converters) if converters else pd.read_excel(f'{file_name}.xls')
@timeit
def main():
code_db_file, code_file, output_file = get_option()
# 1. 读取条码库并处理为 规格名称 扫码 类型 三列
print('正在读取条码库数据---')
code_db = read_file(code_db_file, converters={'条码': str, '盒码': str})
new_code_db = code_db.dropna(subset=['条码'])[['规格名称', '条码']].copy().rename(columns={'条码': '扫码'})
new_code_db['类型'] = '条码'
new_code_db2 = code_db.dropna(subset=['盒码'])[['规格名称', '盒码']].copy().rename(columns={'盒码': '扫码'})
new_code_db2['类型'] = '盒码'
new_code_db = new_code_db.append(new_code_db2)
new_code_db['扫码'] = new_code_db['扫码'].str.strip()
new_code_db = new_code_db[(new_code_db['扫码'] != '(null)') & (new_code_db['扫码'] != '无')]
code_type_duplicated = set(new_code_db.loc[new_code_db.duplicated(subset=['扫码', '类型']), '扫码'].to_list())
name_dict = defaultdict(set)
code_name_dict = defaultdict(list)
code_name_dict2 = {}
new_code_db2 = new_code_db.set_index(keys=['扫码', '规格名称'])
for code, name in new_code_db2.loc[code_type_duplicated, :].index:
name_dict[code].add(name)
def build_dict(row):
if pd.notna(row['规格名称']):
code_name_dict2[row['扫码']] = row['规格名称']
print('正在读取 一个条码对应多个规格名称.xlsx ---')
total_duplicated_code_df = read_file('一个条码对应多个规格名称.xlsx')
if len(total_duplicated_code_df[total_duplicated_code_df['规格名称'].notna()]) > 0:
total_duplicated_code_df.apply(build_dict, axis=1)
# data = []
for code in name_dict:
if len(name_dict[code]) > 1:
code_name_dict[code] = list(name_dict[code])
# data.append({'扫码': code, '规格名称[多]': ';;'.join(name_dict[code]), '规格名称': ''})
# total_duplicated_code_df = pd.DataFrame(data=data)
# total_duplicated_code_df.to_excel('一个条码对应多个规格名称.xlsx', index=False)
# 2. 将条码和盒码相同的只保留条码
name_duplicated = new_code_db.loc[(new_code_db['扫码'].duplicated()) & (~new_code_db.duplicated(subset=['扫码', '类型'])), '扫码']
new_code_db = new_code_db[~((new_code_db['扫码'].isin(name_duplicated)) & (new_code_db['类型'] == '盒码'))]
duplicated_tiao_he_code_list = new_code_db.loc[new_code_db['扫码'].isin(name_duplicated), '扫码']
# 3. 读取扫码数据并与条码库合并(左连接)
print('正在读取扫码数据---')
scan_code = read_file(file_name=code_file, converters={'扫码': str})
scan_code_count = scan_code['扫码'].value_counts()
scan_code_count = scan_code_count.reset_index().rename(columns={'index': '扫码', '扫码': '数量'})
scan_code_match_data = pd.merge(scan_code_count, new_code_db, on='扫码')
scan_code_match_data.drop_duplicates(inplace=True)
if len(scan_code_match_data.index) == 0:
print('数据匹配结果为空,请重新检查您的数据')
return
duplicated_code_list = scan_code_match_data['扫码'][scan_code_match_data['扫码'].duplicated()]
print(f'{code_file}文件中有 【{len(duplicated_code_list)}】 项扫码匹配到数据库中的规格名称存在重复项 需手动选择匹配')
# 4. 对于重复的扫码 手动匹配重复的规格名称
for index, code in enumerate(duplicated_code_list):
if code in code_name_dict2:
select_name = code_name_dict2[code]
else:
names = code_name_dict[code]
names_str = ''
for n, name in enumerate(names):
names_str += f'【{n}】 {name}\t'
while True:
select_num = int(input(f'扫码{index+1} {code}\t请选择对应规格名称的序号\n{names_str}\n请输入(数字【0-{len(names)-1}】: '))
if select_num >= len(names):
print(f'输入序号超出指定范围(0-{len(names)-1})\t请重新输入')
else:
select_name = names[select_num]
break
print(f'{code} 将匹配的规格名称是: {select_name}')
scan_code_match_data = scan_code_match_data[~((scan_code_match_data['扫码'] == code) & (scan_code_match_data['规格名称'] != select_name))]
scan_code_match_data.set_index(keys=['类型', '规格名称', '扫码'], inplace=True)
code_list = scan_code_match_data.index.get_level_values(2).to_list()
code_types = scan_code_match_data.index.get_level_values(0)
# 5. 计算结果文件所需格式,并导出
res_df = pd.DataFrame(columns=['规格名称', '盒包数量', '条包数量'], index=code_list)
if '条码' in code_types:
for code_type, name, code in scan_code_match_data.loc[code_types == '条码', '数量'].index:
res_df.loc[code, '规格名称'] = name
res_df.loc[code, '条包数量'] = scan_code_match_data.loc[('条码', name, code), '数量']
if '盒码' in code_types:
for code_type, name, code in scan_code_match_data.loc[code_types == '盒码', '数量'].index:
res_df.loc[code, '规格名称'] = name
res_df.loc[code, '盒包数量'] = scan_code_match_data.loc[('盒码', name, code), '数量']
res_df.dropna(subset=['条包数量', '盒包数量'], inplace=True, how='all')
res_df.fillna(0, inplace=True)
# 6. 导出文件 并给重复的规格名称添加颜色
duplicated_name_list = res_df.loc[res_df['规格名称'].duplicated(), '规格名称'].to_list()
writer = pd.ExcelWriter(output_file, engine='xlsxwriter')
res_df.to_excel(excel_writer=writer, index_label='扫码')
workbook = writer.book
worksheet = writer.sheets['Sheet1']
format1 = workbook.add_format({'bold': True,
'bg_color': '#FFD700',
'font_color': '#DC143C'})
format2 = workbook.add_format({'bold': True,
'bg_color': '#90EE90',
'font_color': '#1E90FF'})
format3 = workbook.add_format({'bold': True,
'bg_color': 'red',
'font_color': 'white'})
format4 = workbook.add_format({'align': 'center'})
worksheet.set_column(0, len(res_df.index), cell_format=format4)
for name in duplicated_name_list:
worksheet.conditional_format(1, 1, len(res_df.index), 1,
{'type': 'text',
'criteria': 'containing',
'value': name,
'format': format1})
for code in duplicated_tiao_he_code_list:
worksheet.conditional_format(1, 0, len(res_df.index), 0,
{'type': 'text',
'criteria': 'containing',
'value': code,
'format': format2})
for code in duplicated_code_list:
worksheet.conditional_format(1, 0, len(res_df.index), 0,
{'type': 'text',
'criteria': 'containing',
'value': code,
'format': format3})
writer.save()
print('\n################** 开始打印运行日志 **##################')
print(f'数据已处理完成! 并保存到文件: {output_file}')
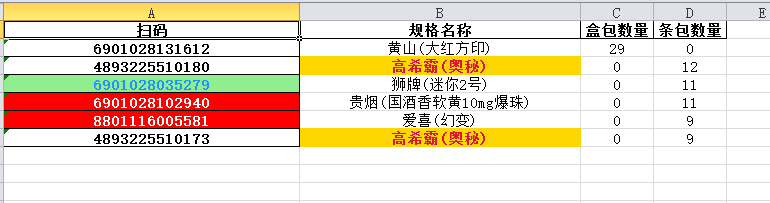
print('【注:1.条码和盒码相同的标注为蓝色背景 2.规格名称相同,扫码不同的标注为黄色背景 3.一个扫码对应多个规格名称标注为红色背景】')
res_check(code_file, output_file)
print('################** 打印运行日志结束 **##################')
def res_check(code_file, output_file):
print('正在检测统计结果数据完整性---')
scan_code_data = read_file(file_name=code_file, converters={'扫码': str})
scan_code_data.drop_duplicates(subset=['扫码'], inplace=True)
scan_code_data.dropna(subset=['扫码'], inplace=True)
res_data = read_file(output_file, converters={'扫码': str})
scan_db = set(scan_code_data['扫码'])
res_db = set(res_data['扫码'])
code_list = scan_db - res_db
if code_list:
print(f'扫码文件中共有条码【{len(scan_db)}】\t结果文件中匹配【{len(res_db)}】\t有【{len(code_list)}】条未匹配')
print('未匹配的条码为:')
for index, code in enumerate(code_list):
print(f'\t条码{index+1}\t{code}')
else:
print(f'扫码文件中共有条码【{len(scan_db)}】\t结果文件中匹配【{len(res_db)}】\t所有扫码已全部匹配')
if __name__ == '__main__':
main()
- 运行
python scan_code_stat.py -d 条码库文件路径 -f 扫码文件路径 -o 统计结果输出文件路径
或者
python scan_code_stat.py
默认为 -d 条码库 -f 扫码 -o 统计结果.xlsx
打印输出
正在读取条码库数据--- 正在读取 一个条码对应多个规格名称.xlsx --- 正在读取扫码数据--- 扫码文件中有 【2】 项扫码匹配到数据库中的规格名称存在重复项 需手动选择匹配 扫码1 6901028102940 请选择对应规格名称的序号 【0】 贵烟(小国酒香) 【1】 贵烟(国酒香软黄10mg爆珠) 请输入(数字【0-1】: 1 6901028102940 将匹配的规格名称是: 贵烟(国酒香软黄10mg爆珠) 扫码2 8801116005581 请选择对应规格名称的序号 【0】 ESSE(CHANGE 4mg) 【1】 爱喜(幻变) 请输入(数字【0-1】: 1 8801116005581 将匹配的规格名称是: 爱喜(幻变) 数据已处理完成! 并保存到文件: 统计结果.xlsx 【注:1.条码和盒码相同的标注为蓝色背景 2.规格名称相同,扫码不同的标注为黄色背景 3.一个扫码对应多个规格名称标注为红色背景】 花费时间: 11.73秒
3. 效果
- 统计结果.xlsx
实战二、奖学金统计
-
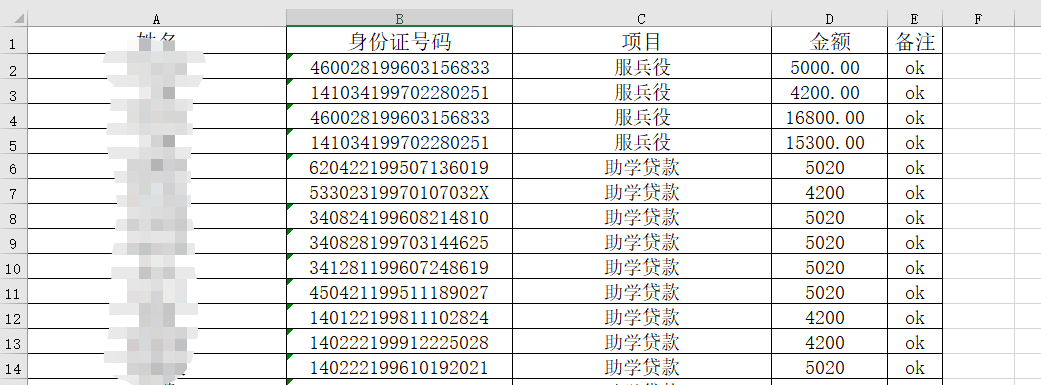
数据介绍
-
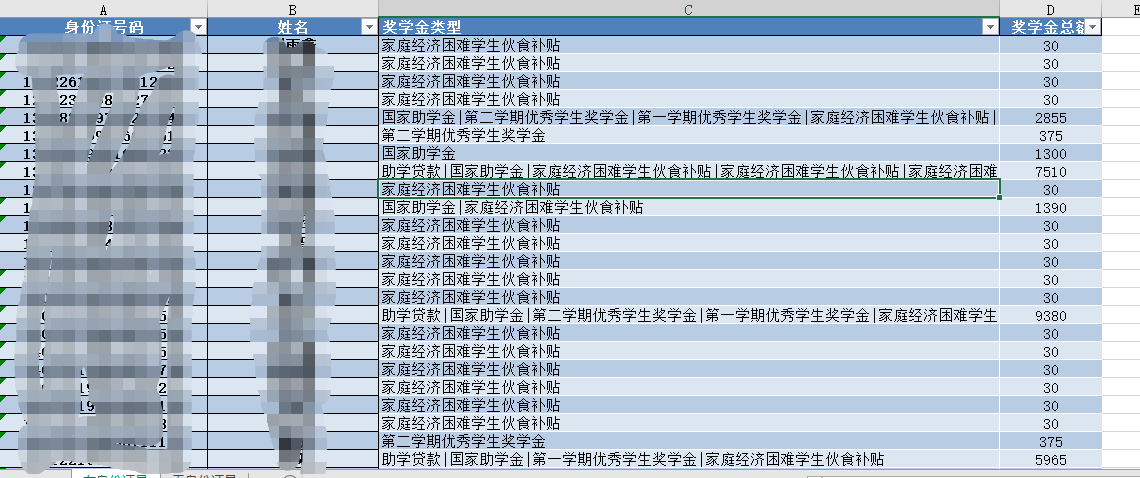
有身份证号.xlsx
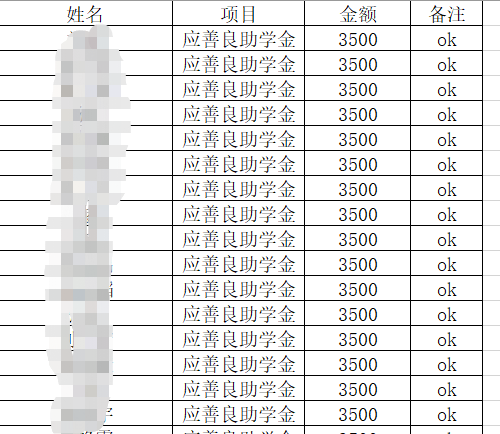
-
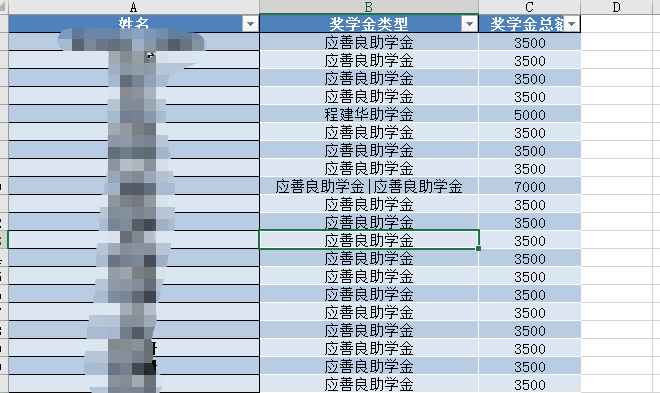
无身份证号.xlsx
-
-
需求
分别统计有身份证号和无身份证号两个文件中每个人获得奖学金的类型和总金额
2. 代码实现
# -*- coding: utf-8 -*-
"""
Datetime: 2020/01/15
Author: Zhang Yafei
Description:
"""
import pandas as pd
class SchorshipStat(object):
def __init__(self, file, idcard_file):
self.df = pd.read_excel(file)
self.df_idcard = pd.read_excel(idcard_file)
@staticmethod
def stat_type(row):
return '|'.join(row['项目'])
@staticmethod
def stat_amount_sum(row):
return row['金额'].sum()
def stat_scholarship_type_total(self, is_save=False, is_print=True):
"""
奖学金统计:身份证号 姓名 奖学金类型 奖学金金额
:param is_save: 是否保存到文件
:param is_print: 是否打印
:return: None
"""
group_df = self.df.groupby(by=['姓名'])
group_df_idcard = self.df_idcard.groupby(by=['身份证号码', '姓名'])
df_result = self.grouped_stat(group_df)
df_idcard_result = self.grouped_stat(group_df_idcard)
if is_print:
print(df_result)
print(df_idcard_result)
if is_save:
with pd.ExcelWriter(path='res/奖学金统计.xlsx') as writer:
df_result.to_excel(excel_writer=writer, sheet_name='无身份证号')
df_idcard_result.to_excel(excel_writer=writer, sheet_name='有身份证号')
def grouped_stat(self, group_dataframe):
"""
分组统计函数
:param group_dataframe:
:return: result_df
"""
scholor_type = group_dataframe.apply(self.stat_type)
scholor_amount_sum = group_dataframe.apply(self.stat_amount_sum)
result_df = pd.concat(objs=[scholor_type, scholor_amount_sum], axis=1)
result_df.rename(columns={0: '奖学金类型', 1: '奖学金总额'}, inplace=True)
return result_df
if __name__ == '__main__':
schorship = SchorshipStat(file='data/无身份证号.xlsx', idcard_file='data/有身份证号.xlsx')
schorship.stat_scholarship_type_total(is_print=True, is_save=True)
3. 运行效果