Go语言实战爬虫项目
Go语言爬虫框架之Colly和Goquery
Python爬虫框架比较多有requests、urllib, pyquery,scrapy等,解析库有BeautifulSoup、pyquery、Scrapy和lxml等等,基于Go的爬虫框架是比较强健的,尤其Colly和Goquery是比较强大的工具,其灵活性和 表达性都比较优秀。
网络爬虫
网络爬虫是什么?从本质上讲,网络爬虫的工作原理通过检查web页面的HTML内容和执行某种类型的行动基于内容。通常,抓取暴露的链接,爬虫按照队列的去爬取。我们也可以从当前页面保存数据提取。例如,如果我们的维基百科页面上开始,我们可能保存页面的文本和标题。
爬虫的简单算法
initialize Queue
enqueue SeedURL
while Queue is not empty:
URL = Pop element from Queue
Page = Visit(URL)
Links = ExtractLinks(Page)
Enqueue Links on Queue
12345678
Visit和ExtractLinks函数是改变的地方,两个函数的应用都是特定的。我们的爬虫会尽力解释整个WEB的图,就像google一样,或者像Wikipedia一样简单一些。
随着你使用的用例的增加许多事情会变得复杂起来,许多许多的页面会被抓取,你可能需要一个更尖端的爬虫同时运行,对于更为复杂的页面,你需要一个更强大的HTML解释器。
Colly
Colly是一个基于Go语言的灵活的爬虫框架,开箱即用,你会获得一些速率限制,并行爬行等支持。
Colly基本组件之一是Collector,Collector保持跟踪那些需要被爬取的页面,并且保持回调当页面被爬取的时候。
一、开始
创造一个Collector是容易的,但是我们有许多可选项我们可以使用。
c := colly.NewCollector(
// Restrict crawling to specific domains
colly.AllowedDomains("godoc.org"),
// Allow visiting the same page multiple times
colly.AllowURLRevisit(),
// Allow crawling to be done in parallel / async
colly.Async(true),
)
12345678
你可以只有colly.NewCollector(),然后自己添加那些可选项。
我们也可以使用一些特别的限制让我们的爬虫表现的像一个行为良好的网络公民,Colly添加速率限制是简单的。
c.Limit(&colly.LimitRule{
// Filter domains affected by this rule
DomainGlob: "godoc.org/*",
// Set a delay between requests to these domains
Delay: 1 * time.Second
// Add an additional random delay
RandomDelay: 1 * time.Second,
})
12345678
某些网页可能对高流量的访问比较挑剔,他会将你断线。通常设置一个延迟维持几秒中就可让你里淘气榜单远一点。
从这里开始,我们能开始我们的collector通过一个URL种子。
c.Visit("https://godoc.org")
二、OnHTML
我们有一个好的collector他可以从任意网站开始工作,现在我们希望我们的collector做一些什么的话他需要检查页面以便提取链接和其他的数据。
colly.Collector.OnHTML方法允许注册一个回调为当收集器达到页面相匹配的一部分特定的HTML标签说明符。首先,我们可以得到一个回调时当爬虫看到[标记包含一个href链接。]()
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
// Extract the link from the anchor HTML element
link := e.Attr("href")
// Tell the collector to visit the link
c.Visit(e.Request.AbsoluteURL(link))
})
123456
就像和上面看到的一样,在这个回调中你得到一个colly.HTMLElement它包含了匹配到的HTML的数据。
现在,我们有一个实际的网络爬虫的开始:我们发现页面上的链接访问,并告诉我们的collector在后续请求访问这些链接。
OnHTML是一个功能强大的工具。它可以搜索CSS选择器(即div.my_fancy_class或# someElementId),你可以连接多个OnHTML回调你的收集器处理不同类型的页面。
Colly的HTMLElement结构非常有用。除了使用Attr函数获得那些属性之外,还可以提取文本。例如,我们可能想要打印页面的标题:
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println(e.Text)
})
123
三、OnRequest / OnResponse
有些时候你不需要一个特定的HTML元素从一个页面,而是想知道当你的爬虫检索或刚刚检索页面。为此,Colly暴露OnRequest OnResponse回调。
所有这些回调将被调用当访问到每个页面的时候。至于如何在符合OnHTML的使用要求。回调被调用的时候有一些顺序:1。OnRequest 2。OnResponse 3。OnHTML 4。OnScraped(在这边文章中没有提及到,但可能对你有用)
尤其使用的是OnRequest中止回调的能力。这可能是有用的,当你想让你的collector停止。
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println(e.Text)
})
123
在OnResponse,可以访问整个HTML文档,这可能是有用的在某些情况下:
c.OnResponse(func(r *colly.Response) {
fmt.Println(r.Body)
})
123
四、HTMLElement
除了colly.HTMLElement的Attr()方法和text,我们还可以使用它来遍历子元素。ChildText(),ChildAttr()特别是ForEach()方法非常有用。
例如,我们可以使用ChildText()获得所有段落的文本部分:
c.OnHTML("#myCoolSection", func(e *colly.HTMLElement) {
fmt.Println(e.ChildText("p"))
})
123
我们可以使用ForEach()循环遍历一个孩子匹配一个特定的元素选择器:
c.OnHTML("#myCoolSection", func(e *colly.HTMLElement) {
e.ForEach("p", func(_ int, elem *colly.HTMLElement) {
if strings.Contains(elem.Text, "golang") {
fmt.Println(elem.Text)
}
})
})
1234567
五、Bringing in Goquery
Colly的内置HTMLElement对大多数抓取任务都很有用,但是如果我们想对DOM进行特别高级的遍历,我们就必须去别处寻找。 例如,(目前)没有办法将DOM遍历到父元素或通过兄弟元素横向遍历。
输入Goquery,“就像那个j-thing,只在Go中”。 它基本上是jQuery。 在Go。 (这很棒)对于你想从HTML文档中删除的任何内容,可以使用Goquery完成。
虽然Goquery是以jQuery为模型的,但我发现它在很多方面与BeautifulSoup API非常相似。 所以,如果你来自Python抓取世界,那么你可能会对Goquery感到满意。
Goquery允许我们进行比Colly的HTMLElement提供的更复杂的HTML选择和DOM遍历。 例如,我们可能想要找到我们的锚元素的兄弟元素,以获得我们已经抓取的链接的一些上下文:
dom, _ := qoquery.NewDocument(htmlData)
dom.Find("a").Siblings().Each(func(i int, s *goquery.Selection) {
fmt.Printf("%d, Sibling text: %s\n", i, s.Text())
})
1234
此外,我们可以轻松找到所选元素的父级。 如果我们从Colly给出一个锚标记,并且我们想要找到页面
anchor.ParentsUntil("~").Find("title").Text()
1
ParentsUntil遍历DOM,直到找到与传递的选择器匹配的东西。 我们可以使用〜遍历DOM的顶部,然后允许我们轻松获取标题标记。
这实际上只是抓住了Goquery可以做的事情。 到目前为止,我们已经看到了DOM遍历的示例,但Goquery也对DOM操作提供了强大的支持 - 编辑文本,添加/删除类或属性,插入/删除HTML元素等。
将它带回网络抓取,我们如何将Goquery与Colly一起使用? 它很简单:每个Colly HTMLElement都包含一个Goquery选项,您可以通过DOM属性访问它。
c.OnHTML("div", func(e *colly.HTMLElement) {
// Goquery selection of the HTMLElement is in e.DOM
goquerySelection := e.DOM
// Example Goquery usage
fmt.Println(qoquerySelection.Find(" span").Children().Text())
})
1234567
值得注意的是,大多数抓取任务都可以以不需要使用Goquery的方式构建! 只需为html添加一个OnHTML回调,就可以通过这种方式访问整个页面。 但是,我仍然发现Goquery是我的DOM遍历工具带的一个很好的补充。
实战项目
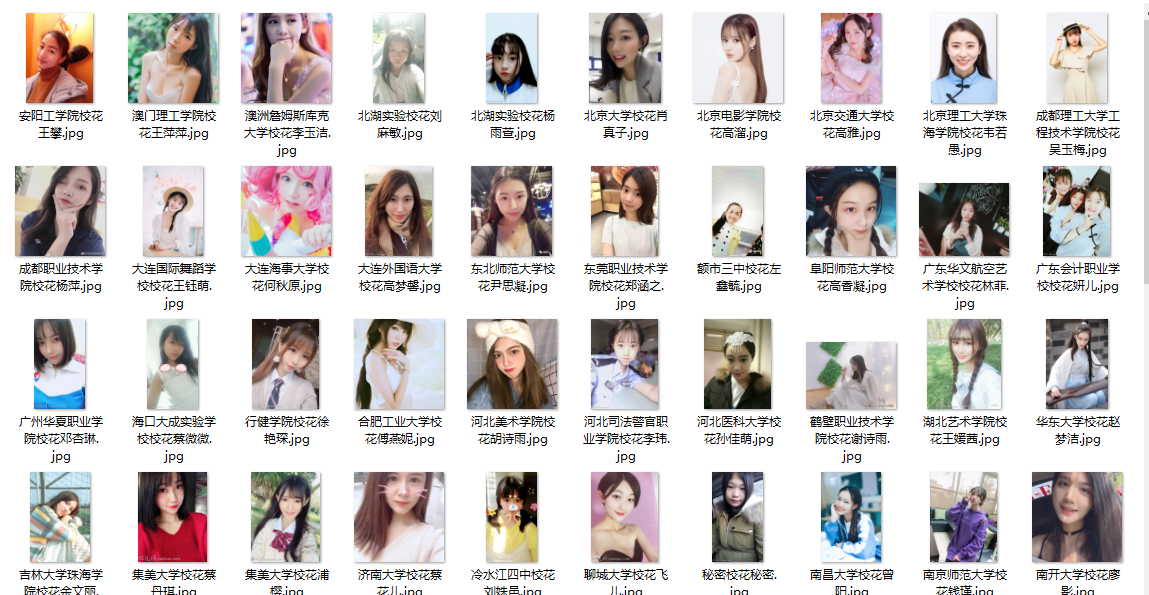
1. metalsucks专辑评论排名信息
-
代码
// go get github.com/PuerkitoBio/goquery
// git clone https://github.com/golang/net
package main
import (
"fmt"
"log"
"net/http"
"github.com/PuerkitoBio/goquery"
)
func main() {
// 请求html页面
res, err := http.Get("http://metalsucks.net")
if err != nil {
// 错误处理
log.Fatal(err)
}
defer res.Body.Close()
if res.StatusCode != 200 {
log.Fatalf("status code error: %d %s", res.StatusCode, res.Status)
}
// 加载 HTML document对象
doc, err := goquery.NewDocumentFromReader(res.Body)
if err != nil {
log.Fatal(err)
}
// Find the review items
doc.Find(".sidebar-reviews article .content-block").Each(func(i int, s *goquery.Selection) {
// For each item found, get the band and title
band := s.Find("a").Text()
title := s.Find("i").Text()
fmt.Printf("Review %d: %s - %s\n", i, band, title)
})
}
-
输出
Review 0: Darkthrone - Old Star
Review 1: Baroness - Gold & Grey
Review 2: Death Angel - Humanicide
Review 3: Devin Townsend - Empath
Review 4: Whitechapel - The Valley
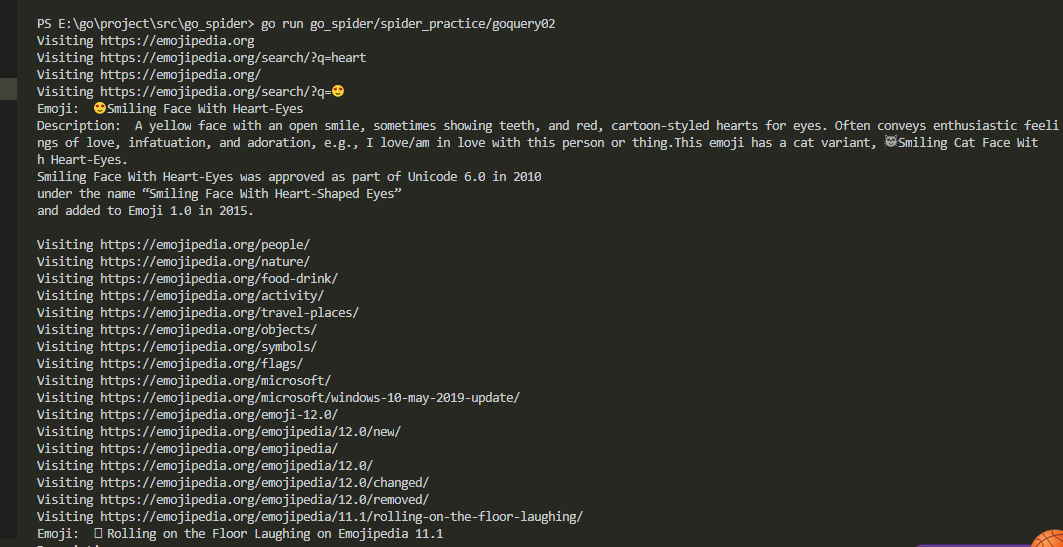
2. emojipedia表情抓取(colly + goquery)
-
代码
package main
import (
"fmt"
"strings"
"time"
"github.com/PuerkitoBio/goquery"
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector(
colly.AllowedDomains("emojipedia.org"),
)
// Callback for when a scraped page contains an article element
c.OnHTML("article", func(e *colly.HTMLElement) {
isEmojiPage := false
// Extract meta tags from the document
metaTags := e.DOM.ParentsUntil("~").Find("meta")
metaTags.Each(func(_ int, s *goquery.Selection) {
// Search for og:type meta tags
property, _ := s.Attr("property")
if strings.EqualFold(property, "og:type") {
content, _ := s.Attr("content")
// Emoji pages have "article" as their og:type
isEmojiPage = strings.EqualFold(content, "article")
}
})
if isEmojiPage {
// Find the emoji page title
fmt.Println("Emoji: ", e.DOM.Find("h1").Text())
// Grab all the text from the emoji's description
fmt.Println(
"Description: ",
e.DOM.Find(".description").Find("p").Text())
}
})
// Callback for links on scraped pages
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
// Extract the linked URL from the anchor tag
link := e.Attr("href")
// Have our crawler visit the linked URL
c.Visit(e.Request.AbsoluteURL(link))
})
c.Limit(&colly.LimitRule{
DomainGlob: "*",
RandomDelay: 1 * time.Second,
})
c.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting", r.URL.String())
})
c.Visit("https://emojipedia.org")
}
-
运行结果
3.校花网图片爬取
- 代码
// 知识点
// 1. http 的用法,返回数据的格式、编码
// 2. 正则表达式
// 3. 文件读写
package main
import (
"bytes"
"fmt"
"io/ioutil"
"net/http"
"os"
"path/filepath"
"regexp"
"strings"
"sync"
"time"
"github.com/axgle/mahonia"
)
var workResultLock sync.WaitGroup
func check(e error) {
if e != nil {
panic(e)
}
}
func ConvertToString(src string, srcCode string, tagCode string) string {
srcCoder := mahonia.NewDecoder(srcCode)
srcResult := srcCoder.ConvertString(src)
tagCoder := mahonia.NewDecoder(tagCode)
_, cdata, _ := tagCoder.Translate([]byte(srcResult), true)
result := string(cdata)
return result
}
func download_img(request_url string, name string, dir_path string) {
image, err := http.Get(request_url)
check(err)
image_byte, err := ioutil.ReadAll(image.Body)
defer image.Body.Close()
file_path := filepath.Join(dir_path, name+".jpg")
err = ioutil.WriteFile(file_path, image_byte, 0644)
check(err)
fmt.Println(request_url + "\t下载成功")
}
func spider(i int, dir_path string) {
defer workResultLock.Done()
url := fmt.Sprintf("http://www.xiaohuar.com/list-1-%d.html", i)
response, err2 := http.Get(url)
check(err2)
content, err3 := ioutil.ReadAll(response.Body)
check(err3)
defer response.Body.Close()
html := string(content)
html = ConvertToString(html, "gbk", "utf-8")
// fmt.Println(html)
match := regexp.MustCompile(`<img width="210".*alt="(.*?)".*src="(.*?)" />`)
matched_str := match.FindAllString(html, -1)
for _, match_str := range matched_str {
var img_url string
name := match.FindStringSubmatch(match_str)[1]
src := match.FindStringSubmatch(match_str)[2]
if strings.HasPrefix(src, "http") != true {
var buffer bytes.Buffer
buffer.WriteString("http://www.xiaohuar.com")
buffer.WriteString(src)
img_url = buffer.String()
} else {
img_url = src
}
download_img(img_url, name, dir_path)
}
}
func main() {
start := time.Now()
dir := filepath.Dir(os.Args[0])
dir_path := filepath.Join(dir, "images")
err1 := os.MkdirAll(dir_path, os.ModePerm)
check(err1)
for i := 0; i < 4; i++ {
workResultLock.Add(1)
go spider(i, dir_path)
}
workResultLock.Wait()
fmt.Println(time.Now().Sub(start))
}
- 运行结果
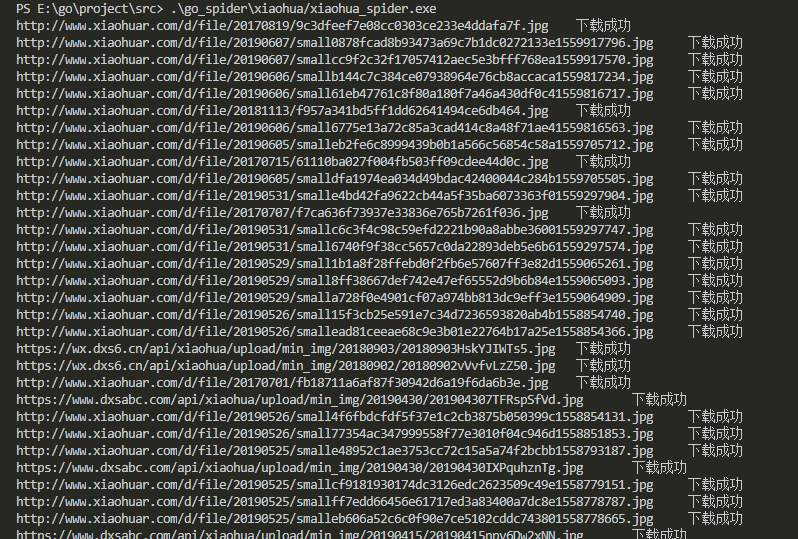
- 下载的图片