
GO语言系列- 高级数据类型之数组、切片、map
一、数组和切片
数组
- 1. 数组:是同一种数据类型的固定长度的序列。
- 2. 数组定义:var a [len]int,比如:var a[5]int,一旦定义,长度不能变
- 3. 长度是数组类型的一部分,因此,var a[5] int和var a[10]int是不同的类型
- 4. 数组可以通过下标进行访问,下标是从0开始,最后一个元素下标是:len-1
for i := 0; i < len(a); i++ {
}
for index, v := range a {
}
- 5. 访问越界,如果下标在数组合法范围之外,则触发访问越界,会panic
- 6. 数组是值类型,因此改变副本的值,不会改变本身的值


package main import "fmt" func test1() { var a [10]int a[0] = 10 a[9] = 100 fmt.Println(a) for i := 0; i < len(a); i++ { fmt.Println(a[i]) } for index, val := range a { fmt.Printf("a[%d]=%d\n", index, val) } } func test2() { var a [10]int b := a b[0] = 100 fmt.Println(a) } func test3(arr *[5]int) { (*arr)[0] = 1000 } func main() { test1() test2() var a [5]int test3(&a) fmt.Println(a) } /* [10 0 0 0 0 0 0 0 0 100] 10 0 0 0 0 0 0 0 0 100 a[0]=10 a[1]=0 a[2]=0 a[3]=0 a[4]=0 a[5]=0 a[6]=0 a[7]=0 a[8]=0 a[9]=100 [0 0 0 0 0 0 0 0 0 0] [1000 0 0 0 0] */
数组初始化
a. var age0 [5]int = [5]int{1,2,3}
b. var age1 = [5]int{1,2,3,4,5}
c. var age2 = […]int{1,2,3,4,5,6}
d. var str = [5]string{3:”hello world”, 4:”tom”}
多维数组
a. var age [5][3]int
b. var f [2][3]int = [...][3]int{{1, 2, 3}, {7, 8, 9}}
多维数组遍历
package main
import (
"fmt"
)
func main() {
var f [2][3]int = [...][3]int{{1, 2, 3}, {7, 8, 9}}
for k1, v1 := range f {
for k2, v2 := range v1 {
fmt.Printf("(%d,%d)=%d ", k1, k2, v2)
}
fmt.Println()
}
}
数组示例
package main import ( "fmt" ) func fab(n int) { var a []int a = make([]int, n) a[0] = 1 a[1] = 1 for i := 2; i < n; i++ { a[i] = a[i-1] + a[i-2] } for _, v := range a { fmt.Println(v) } } func testArray() { var a [5]int = [5]int{1, 2, 3, 4, 5} var a1 = [5]int{1, 2, 3, 4, 5} var a2 = [...]int{38, 283, 48, 38, 348, 387, 484} var a3 = [...]int{1: 100, 3: 200} var a4 = [...]string{1: "hello", 3: "world"} fmt.Println(a) fmt.Println(a1) fmt.Println(a2) fmt.Println(a3) fmt.Println(a4) /* [1 2 3 4 5] [1 2 3 4 5] [38 283 48 38 348 387 484] [0 100 0 200] [ hello world] */ } func testArray2() { var a [2][5]int = [...][5]int{{1, 2, 3, 4, 5}, {6, 7, 8, 9, 10}} for row, v := range a { for col, v1 := range v { fmt.Printf("(%d,%d)=%d ", row, col, v1) } fmt.Println() } } func main() { fab(10) testArray() testArray2() }
切片
1. 切片相关概念
- 1. 切片:切片是数组的一个引用,因此切片是引用类型
- 2. 切片的长度可以改变,因此,切片是一个可变的数组
- 3. 切片遍历方式和数组一样,可以用len()求长度
- 4. cap可以求出slice最大的容量,0 <= len(slice) <= (array),其中array是slice引用的数组
- 5. 切片的定义:var 变量名 []类型,比如 var str []string var arr []int
2. 切片的相关语法
- 1. 切片初始化:var slice []int = arr[start:end] 包含start到end之间的元素,但不包含end
- 2. Var slice []int = arr[0:end]可以简写为 var slice []int=arr[:end]
- 3. Var slice []int = arr[start:len(arr)] 可以简写为 var slice[]int = arr[start:]
- 4. Var slice []int = arr[0, len(arr)] 可以简写为 var slice[]int = arr[:]
- 5. 如果要切片最后一个元素去掉,可以这么写: Slice = slice[:len(slice)-1]
3. 切片的内存布局
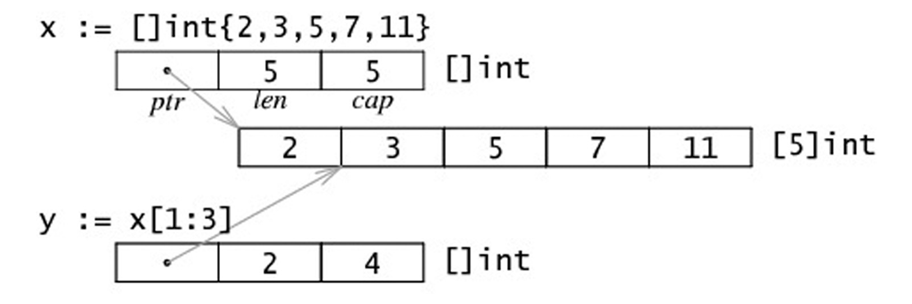
4. 通过make来创建切片
var slice []type = make([]type, len) slice := make([]type, len) slice := make([]type, len, cap)
5. 用append内置函数操作切片
slice = append(slice, 10)
var a = []int{1,2,3}
var b = []int{4,5,6}
a = append(a, b…)
6. For range 遍历切片
for index, val := range slice {
}
7. 切片resize
var a = []int {1,3,4,5}
b := a[1:2]
b = b[0:3]
8. 切片拷贝
s1 := []int{1,2,3,4,5}
s2 := make([]int, 10)
copy(s2, s1)
s3 := []int{1,2,3}
s3 = append(s3, s2…)
s3 = append(s3, 4,5,6)
9. string与slice
string底层就是一个byte的数组,因此,也可以进行切片操作
str := “hello world” s1 := str[0:5] fmt.Println(s1) s2 := str[5:] fmt.Println(s2)
10. string的底层布局
11. 如何改变string中的字符值?
string本身是不可变的,因此要改变string中字符,需要如下操作:
str := “hello world” s := []byte(str) s[0] = ‘o’ str = string(s)
12. 排序和查找操作
排序操作主要都在 sort包中,导入就可以使用了
sort.Ints对整数进行排序, sort.Strings对字符串进行排序, sort.Float64s对 浮点数进行排序. sort.SearchInts(a []int, b int) 从数组a中查找b,前提是a必须有序 sort.SearchFloats(a []float64, b float64) 从数组a中查找b,前提是a必须有序 sort.SearchStrings(a []string, b string) 从数组a中查找b,前提是a必须有序
13. 切片的扩容机制
可以通过查看$GOROOT/src/runtime/slice.go源码,其中扩容相关代码如下:
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
从上面的代码可以看出以下内容:
- 首先判断,如果新申请容量(cap)大于2倍的旧容量(old.cap),最终容量(newcap)就是新申请的容量(cap)。
- 否则判断,如果旧切片的长度小于1024,则最终容量(newcap)就是旧容量(old.cap)的两倍,即(newcap=doublecap),
- 否则判断,如果旧切片长度大于等于1024,则最终容量(newcap)从旧容量(old.cap)开始循环增加原来的1/4,即(newcap=old.cap,for {newcap += newcap/4})直到最终容量(newcap)大于等于新申请的容量(cap),即(newcap >= cap)
- 如果最终容量(cap)计算值溢出,则最终容量(cap)就是新申请容量(cap)。
需要注意的是,切片扩容还会根据切片中元素的类型不同而做不同的处理,比如int和string类型的处理方式就不一样。
示例
package main import "fmt" type slice struct { ptr *[100]int len int cap int } func make1(s slice, cap int) slice { s.ptr = new([100]int) s.cap = cap s.len = 0 return s } func testSlice() { var slice []int var arr [5]int = [...]int{1, 2, 3, 4, 5} slice = arr[:] fmt.Println(slice) fmt.Println(arr[2:4]) // [3,4] fmt.Println(arr[2:]) // [3,4,5] fmt.Println(arr[0:1]) // [1] fmt.Println(arr[:len(arr)-1]) } func modify(s slice) { s.ptr[1] = 1000 } func testSlice2() { var s1 slice s1 = make1(s1, 10) s1.ptr[0] = 100 modify(s1) fmt.Println(s1.ptr) } func modify1(a []int) { a[1] = 1000 } func testSlice3() { var b []int = []int{1, 2, 3, 4} modify1(b) fmt.Println(b) } func testSlcie4() { var a = [10]int{1, 2, 3, 4} b := a[1:5] fmt.Printf("%p\n", b) // 0xc000014238 fmt.Printf("%p\n", &a[1]) // 0xc000014238 } func main() { // testSlice() testSlice2() testSlice3() testSlcie4() }
package main import "fmt" func testSlice() { var a [5]int = [...]int{1, 2, 3, 4, 5} s := a[1:] fmt.Println("a:", a) s[1] = 100 fmt.Printf("s=%p a[1]=%p\n", s, &a[1]) fmt.Println("before a:", a) s = append(s, 10) s = append(s, 10) s = append(s, 10) s = append(s, 10) s = append(s, 10) s[1] = 1000 fmt.Println("after a:", a) fmt.Println(s) fmt.Printf("s=%p a[1]=%p\n", s, &a[1]) } func testCopy() { var a []int = []int{1, 2, 3, 4, 5} b := make([]int, 10) copy(b, a) fmt.Println(b) } func testString() { s := "hello world" s1 := s[0:5] s2 := s[6:] fmt.Println(s1) fmt.Println(s2) } func testModifyString() { s := "我hello world" s1 := []rune(s) s1[0] = 200 s1[1] = 128 s1[2] = 256 str := string(s1) fmt.Println(str) } func main() { // testSlice() testCopy() testString() testModifyString() }
package main import ( "fmt" "sort" ) func testIntSort() { var a = [...]int{1, 8, 43, 2, 456} sort.Ints(a[:]) fmt.Println(a) } func testStrings() { var a = [...]string{"abc", "efg", "b", "A", "eeee"} sort.Strings(a[:]) fmt.Println(a) } func testFloat() { var a = [...]float64{2.3, 0.8, 28.2, 392342.2, 0.6} sort.Float64s(a[:]) fmt.Println(a) } func testIntSearch() { var a = [...]int{1, 8, 43, 2, 456} index := sort.SearchInts(a[:], 2) fmt.Println(index) } func main() { testIntSort() testStrings() testFloat() testIntSearch() }
二、map数据结构
1.map简介
key-value的数据结构,又叫字典或关联数组
a.声明
var map1 map[keytype]valuetype var a map[string]string var a map[string]int var a map[int]string var a map[string]map[string]string
声明是不会分配内存的,初始化需要make
2. map相关操作
var a map[string]string = map[string]string{“hello”: “world”}
a = make(map[string]string, 10)
a[“hello”] = “world” // 插入和更新
Val, ok := a[“hello”] //查找
for k, v := range a { //遍历
fmt.Println(k,v)
}
delete(a, “hello”) // 删除
len(a) // 长度
3. map是引用类型
func modify(a map[string]int) {
a[“one”] = 134
}
4. slice of map
Items := make([]map[int][int], 5)
For I := 0; I < 5; i++ {
items[i] = make(map[int][int])
}
5. map排序
a. 先获取所有key,把key进行排序 b. 按照排序好的key,进行遍历
6. Map反转
- a. 初始化另外一个map,把key、value互换即可
示例
package main import "fmt" func trans(a map[string]map[string]string) { for k, v := range a { fmt.Println(k) for k1, v1 := range v { fmt.Println("\t", k1, v1) } } } func testMap() { var a map[string]string = map[string]string{ "key": "value", } // a := make(map[string]string, 10) a["abc"] = "efg" a["abc1"] = "wew" fmt.Println(a) } func testMap2() { a := make(map[string]map[string]string, 100) a["key1"] = make(map[string]string) a["key1"]["key2"] = "val2" a["key1"]["key3"] = "val3" a["key1"]["key4"] = "val4" a["key1"]["key5"] = "val5" a["key1"]["key6"] = "val6" fmt.Println(a) } func modify(a map[string]map[string]string) { _, ok := a["zhangsan"] if !ok { a["zhangsan"] = make(map[string]string) } a["zhangsan"]["pwd"] = "123456" a["zhangsan"]["nickname"] = "superman" return } func testMap3() { a := make(map[string]map[string]string, 100) modify(a) fmt.Println(a) } func testMap4() { a := make(map[string]map[string]string, 100) a["key1"] = make(map[string]string) a["key1"]["key2"] = "val2" a["key1"]["key3"] = "val3" a["key1"]["key4"] = "val4" a["key1"]["key5"] = "val5" a["key2"] = make(map[string]string) a["key2"]["key22"] = "val22" a["key2"]["key23"] = "val23" trans(a) delete(a, "key1") fmt.Println() trans(a) } func testMap5() { var a []map[int]int a = make([]map[int]int, 5) if a[0] == nil { a[0] = make(map[int]int) } a[0][10] = 10 fmt.Println(a) } func main() { testMap() testMap2() testMap3() testMap4() testMap5() }
package main import ( "fmt" "sort" ) func testMapSort() { var a map[int]int a = make(map[int]int, 5) a[8] = 10 a[3] = 10 a[2] = 10 a[1] = 10 a[18] = 10 var keys []int for k, _ := range a { keys = append(keys, k) // fmt.Println(k, v) } sort.Ints(keys) for _, v := range keys { fmt.Println(v, a[v]) } } func testMapSort2() { var a map[string]int var b map[int]string a = make(map[string]int, 5) b = make(map[int]string, 5) a["8"] = 10 a["3"] = 11 a["2"] = 12 a["1"] = 13 a["18"] = 14 for k, v := range a { b[v] = k } fmt.Println(b) } func main() { testMapSort() testMapSort2() }
补充:golang实现集合(set)
package set import ( "bytes" "fmt" "sync" ) type Set struct { m map[interface{}]bool sync.RWMutex } func New() *Set { return &Set{m: make(map[interface{}]bool)} } func (self *Set) Add(e interface{}) bool { self.Lock() defer self.Unlock() if self.m[e] { return false } self.m[e] = true return true } func (self *Set) Remove(e interface{}) bool { self.Lock() defer self.Unlock() delete(self.m, e) return true } func (self *Set) Clear() bool { self.Lock() defer self.Unlock() self.m = make(map[interface{}]bool) return true } func (self *Set) Contains(e interface{}) bool { self.Lock() defer self.Unlock() //return self.m[e] _, ok := self.m[e] return ok } func (self *Set) IsEmpty() bool { return self.Len() == 0 } func (self *Set) Len() int { self.Lock() defer self.Unlock() return len(self.m) } func (self *Set) Same(other *Set) bool { if other == nil { return false } if self.Len() != other.Len() { return false } for k, _ := range other.m { if !self.Contains(k) { return false } } return true } func (self *Set) Elements() interface{} { self.Lock() defer self.Unlock() // for k := range self.m{ // snapshot = snapshot(snapshot, k) // } initialLen := self.Len() actualLen := 0 snapshot := make([]interface{}, initialLen) for k := range self.m { if actualLen < initialLen { snapshot[actualLen] = k } else { snapshot = append(snapshot, k) } actualLen++ } if actualLen < initialLen { snapshot = snapshot[:actualLen] } return snapshot } func (self *Set) String() string { self.Lock() defer self.Unlock() var buf bytes.Buffer buf.WriteString("Set{") flag := true for k := range self.m { if flag { flag = false } else { buf.WriteString(" ") } buf.WriteString(fmt.Sprintf("%v", k)) } buf.WriteString("}") return buf.String() } func (self *Set) IsSuperSet(other *Set) bool { self.Lock() defer self.Unlock() if other == nil { return false } selfLen := self.Len() otherLen := other.Len() if otherLen == 0 || selfLen == otherLen { return false } if selfLen > 0 && otherLen == 0 { return true } for v := range other.m { if !self.Contains(v) { return false } } return true } //属于A或属于B的元素 func (self *Set) Union(other *Set) *Set { self.Lock() defer self.Unlock() // if other == nil || other.Len() == 0{ // return self // } // // for v := range other.m{ // self.Add(v) // } // return self //不能改变集合A的范围 union := New() for v := range self.m { union.Add(v) } for v := range other.m { union.Add(v) } return union } //属于A且属于B的元素 func (self *Set) Intersect(other *Set) *Set { self.Lock() defer self.Unlock() if other == nil || other.Len() == 0 { return New() } intsSet := New() for v, _ := range other.m { if self.Contains(v) { intsSet.Add(v) } } return intsSet } //属于A且不属于B的元素 func (self *Set) Difference(other *Set) *Set { self.Lock() defer self.Unlock() diffSet := New() if other == nil || other.Len() == 0 { diffSet.Union(self) } else { for v := range self.m { if !other.Contains(v) { diffSet.Add(v) } } } return diffSet } //集合A与集合B中所有不属于A∩B的元素的集合 func (self *Set) SymmetricDifference(other *Set) *Set { self.Lock() defer self.Unlock() //此时A∩B=∅,A中所有元素均不属于空集 // if other == nil || other.Len() == 0{ // return self // } // ints := self.Intersect(other) // //此时A∩B=∅,A为空或B为空,B为空前面已经判断,此时B不能为空,即A为空 // if ints == nil || ints.Len() == 0 { // return other // } // // unionSet := self.Union(other) // result := New() // for v := range unionSet.m{ // if !ints.Contains(v){ // result.Add(v) // } // } ints := self.Difference(other) union := self.Union(other) return union.Difference(ints) }
package main import ( "fmt" "go_dev/go_set/set" ) func main() { setTest() } func setTest() { set1 := set.New() set1.Add(1) set1.Add("e2") set1.Add(3) set1.Add("e4") fmt.Println("set1:", set1) fmt.Printf("set1 Elements:%v\n", set1.Elements()) set2 := set.New() set2.Add(3) set2.Add("e2") set2.Add(5) set2.Add("e6") fmt.Println("set2:", set2) fmt.Printf("set1 union set2:%v\n", set1.Union(set2)) fmt.Printf("set1 intersect set2:%v\n", set1.Intersect(set2)) fmt.Println(set1,set2) fmt.Printf("set1 difference set2:%v\n", set1.Difference(set2)) fmt.Printf("set1 SymmetricDifference set2:%v\n", set1.SymmetricDifference(set2)) set1.Clear() fmt.Println(set1) }
三、包
1. golang中的包
-
a. golang目前有150个标准的包,覆盖了几乎所有的基础库
-
b. golang.org有所有包的文档,没事都翻翻
2. 线程同步
a. import(“sync”) b. 互斥锁, var mu sync.Mutex c. 读写锁, var mu sync.RWMutex
package main import ( "fmt" "math/rand" "sync" "sync/atomic" "time" ) var rwLock *sync.RWMutex func testLock() { var a map[int]int a = make(map[int]int, 5) a[8] = 10 a[3] = 10 a[2] = 10 a[1] = 10 a[18] = 10 for i := 0; i < 2; i++ { go func(b map[int]int) { rwLock.RLock() b[8] = rand.Intn(100) rwLock.Unlock() }(a) } rwLock.RLock() fmt.Println(a) rwLock.Unlock() } func testRWLock() { // var rwLock myLocker = new(sync.RWMutex) // var rwLock sync.RWMutex // var rwLock sync.Mutex var a map[int]int a = make(map[int]int, 5) var count int32 a[8] = 10 a[3] = 10 a[2] = 10 a[1] = 10 a[18] = 10 for i := 0; i < 2; i++ { go func(b map[int]int) { rwLock.Lock() // lock.Lock() b[8] = rand.Intn(100) time.Sleep(time.Millisecond) rwLock.Unlock() // lock.Unlock() }(a) } for i := 0; i < 100; i++ { go func(b map[int]int) { for { rwLock.Lock() time.Sleep(time.Millisecond) // fmt.Println(a) rwLock.Unlock() atomic.AddInt32(&count, 1) } }(a) } time.Sleep(time.Second * 3) fmt.Println(atomic.LoadInt32(&count)) } func main() { rwLock = new(sync.RWMutex) // testLock() testRWLock() }
3. go get安装第三方包
go get github.com/go-sql-driver/mysql
本节作业
-
1. 冒泡排序
-
2. 选择排序
-
3. 插入排序
-
4.快速排序
参考
package main import "fmt" // 冒泡排序:本质上是交换排序的一种 func bsort(a []int) { for i := 0; i < len(a); i++ { for j := 1; j < len(a)-i; j++ { if a[j] < a[j-1] { a[j], a[j-1] = a[j-1], a[j] } } } } func main() { b := [...]int{8, 7, 4, 5, 3, 2, 1} bsort(b[:]) fmt.Println(b) }
package main import "fmt" // 选择排序 func ssort(a []int) { for i := 0; i < len(a); i++ { var min int = i for j := i + 1; j < len(a); j++ { if a[min] > a[j] { min = j } } if min != i { a[i], a[min] = a[min], a[i] } } } func main() { b := [...]int{8, 7, 4, 5, 3, 2, 1} ssort(b[:]) fmt.Println(b) }
package main import "fmt" // 插入排序, 每次将一个数插入到有序序列当中合适的位置 func isort(a []int) { for i := 1; i < len(a); i++ { for j := i; j > 0; j-- { if a[j] > a[j-1] { break } a[j], a[j-1] = a[j-1], a[j] } } } func main() { b := [...]int{8, 7, 4, 5, 3, 2, 1} isort(b[:]) fmt.Println(b) }
package main import "fmt" // 快速排序, 一次排序确定一个元素的位置, 使左边的元素都比它小,右边的元素都比它大 func qsort(a []int, left, right int) { if left >= right { return } val := a[left] // 确定val所在的位置 k := left for i := left + 1; i <= right; i++ { if a[i] < val { a[k] = a[i] a[i] = a[k+1] k++ } } a[k] = val qsort(a, left, k-1) qsort(a, k+1, right) } func main() { b := [...]int{8, 7, 4, 5, 3, 2, 1} qsort(b[:], 0, len(b)-1) fmt.Println(b) }


