
一文学会matplotlib
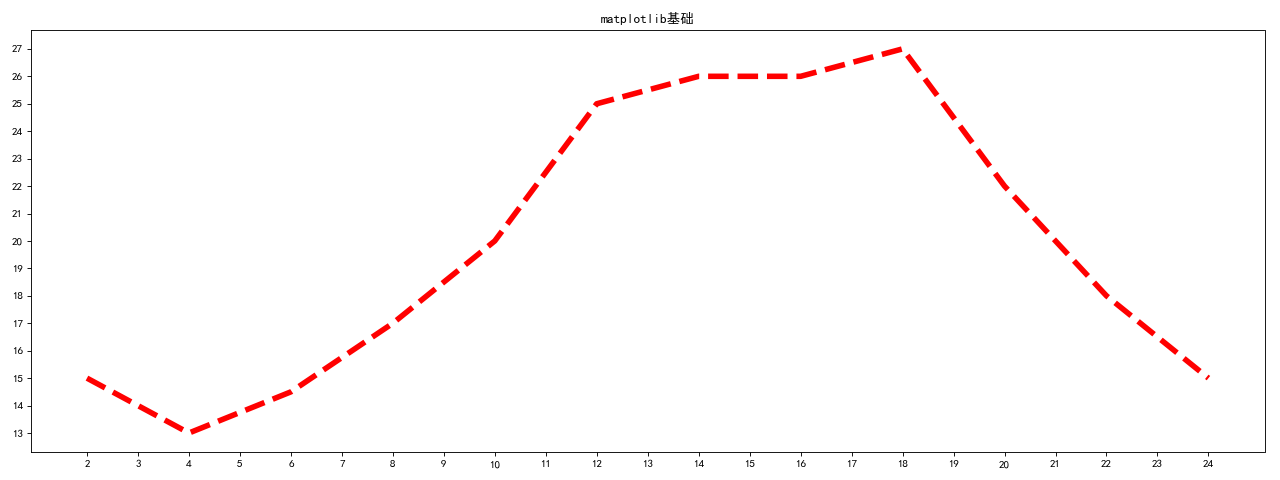
matplotlib基础
“““
假设一天中每隔两个小时(range(2,26,2))的气温(℃)分别是[15,13,14.5,17,20,25,26,26,27,22,18,15]
用matplotlib用图形画出变化的折线图
"""
from matplotlib import pyplot as plt
"""设置中文"""
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
"""设置图片大小"""
plt.figure(figsize=(16, 6), dpi=80)
"""准备数据"""
x = range(2, 26, 2) # x轴,数据是一个可迭代对象
y = [15, 13, 14.5, 17, 20, 25, 26, 26, 27, 22, 18, 15] # y轴数据也是一个可迭代对象
"""绘图"""
plt.plot(x, y, linestyle='--', linewidth=5, color='red')
"""设置x轴的刻度"""
_xtick_labels = [i / 2 for i in range(4, 49)]
plt.xticks(_xtick_labels[::2]) # 当列表太密集可以设置列表步长调整间距
plt.yticks(range(min(y), max(y) + 1))
"""图形保存"""
# plt.savefig('t1.png')
"""图形标题"""
plt.title('matplotlib基础')
"""图形显示"""
plt.show()
一、figure对象
我这里单拿出一个一个的对象,然后后面在进行总结。在matplotlib中,整个图表为一个figure对象。其实对于每一个弹出的小窗口就是一个Figure对象,那么如何在一个代码中创建多个Figure对象,也就是多个小窗口呢?
import matplotlib.pyplot as plt import numpy as np x = np.linspace(-1, 1, 50) y1 = x ** 2 y2 = x * 2 # 这个是第一个figure对象,下面的内容都会在第一个figure中显示 plt.figure() plt.plot(x, y1) # 这里第二个figure对象 plt.figure(num=3, figsize=(10, 5)) plt.plot(x, y2) plt.show()

这里需要注意的是:
- 我们看上面的每个图像的窗口,可以看出figure并没有从1开始然后到2,这是因为我们在创建第二个figure对象的时候,指定了一个num = 3的参数,所以第二个窗口标题上显示的figure3。
- 对于每一个窗口,我们也可以对他们分别去指定窗口的大小。也就是figsize参数。
- 若我们想让他们的线有所区别,我们可以用下面语句进行修改
plt.plot(x,y2,color = 'red',linewidth = 3.0,linestyle = '--')
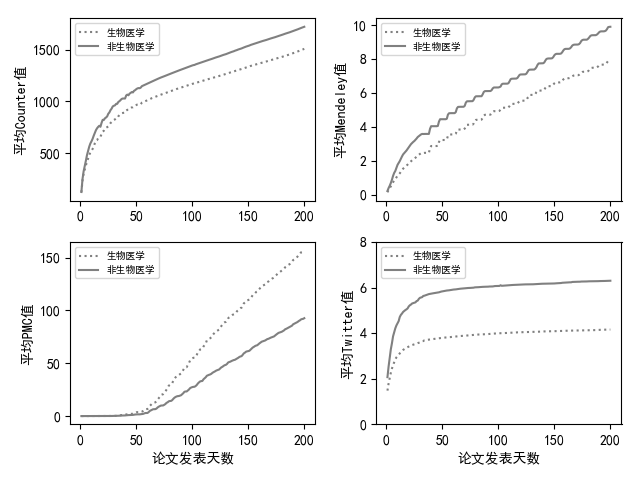
二、figure子图
# -*- coding:utf-8 -*-
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
data = pd.read_csv("data/four platform.csv")
fig, axes = plt.subplots(nrows=2, ncols=2)
ax0, ax1, ax2, ax3 = axes.flatten()
ax0.plot(data["day"], data["Med-counter"], label="生物医学", color='gray', linestyle=':')
ax0.plot(data["day"], data["Nonmed-counter"], label="非生物医学", color='gray', linestyle='-')
ax0.legend(prop={'size': 7}, loc="upper left")
# ax0.set_xlabel('day')
ax0.set_ylabel('平均Counter值')
ax1.plot(data["day"], data["Med-mendeley"], label="生物医学", color='gray', linestyle=':')
ax1.plot(data["day"], data["Nonmed-mendeley"], label="非生物医学", color='gray', linestyle='-')
ax1.legend(prop={'size': 7}, loc="upper left")
# ax1.set_xlabel('day',fontsize=6)
ax1.set_ylabel('平均Mendeley值')
ax2.plot(data["day"], data["Med-pmc"], label="生物医学", color='gray', linestyle=':')
ax2.plot(data["day"], data["Nonmed-pmc"], label="非生物医学", color='gray', linestyle='-')
ax2.legend(prop={'size': 7}, loc="upper left")
ax2.set_xlabel('论文发表天数')
ax2.set_ylabel('平均PMC值')
ax3.plot(data["day"], data["Med-twitter"], label="生物医学", color='gray', linestyle=':')
ax3.plot(data["day"], data["Nonmed-twitter"], label="非生物医学", color='gray', linestyle='-')
ax3.legend(prop={'size': 7}, loc="upper left")
ax3.set_xlabel('论文发表天数')
ax3.set_ylabel('平均Twitter值')
ax3.set_ylim(0, 8)
plt.show()
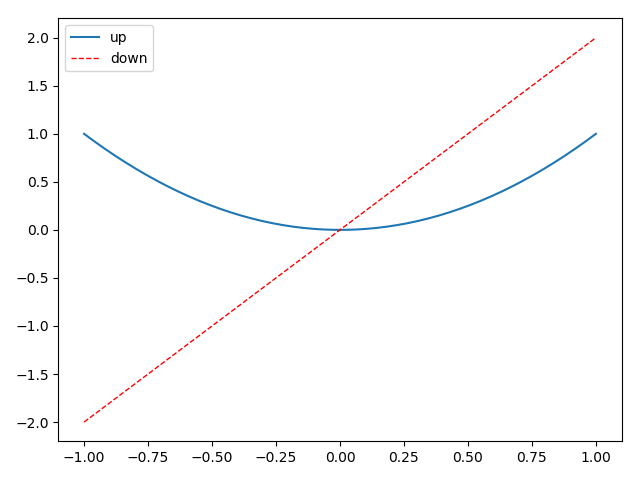
三、legend图例
我们很多时候会再一个figures中去添加多条线,那我们如何去区分多条线呢?这里就用到了legend。
import matplotlib.pyplot as plt import numpy as np x = np.linspace(-1, 1, 50) y1 = x ** 2 y2 = x * 2 plt.figure() # 添加图例 l1, = plt.plot(x, y1, label='linear line') l2, = plt.plot(x, y2, color='red', linewidth=1.0, linestyle='--', label='square line') plt.legend(handles=[l1, l2], labels=['up', 'down'], loc='best') plt.show()
这里需要注意的是:
- 如果我们没有在legend方法的参数中设置labels,那么就会使用画线的时候,也就是plot方法中的指定的label参数所指定的名称,当然如果都没有的话就会抛出异常;
- 其实我们plt.plot的时候返回的是一个线的对象,如果我们想在handle中使用这个对象,就必须在返回的名字的后面加一个","号;
legend = plt.legend(handles=[l1, l2], labels=['hu', 'tang'], loc='upper center', shadow=True)
frame = legend.get_frame()
frame.set_facecolor('r') # 或者0.9...
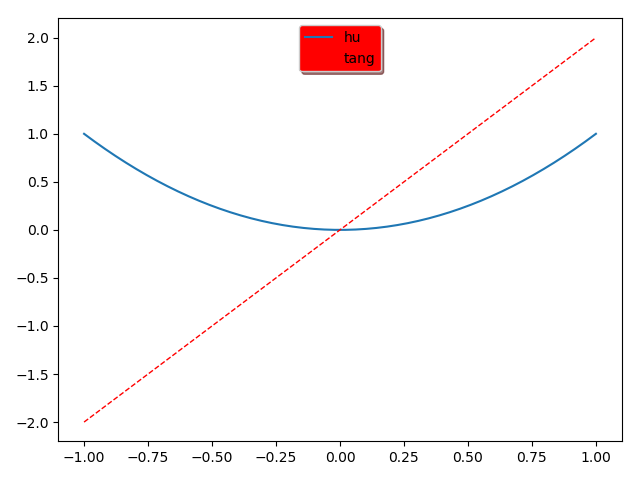
四、在图片上加一些标注annotation
在图片上加注解有两种方式:
# -*- coding: utf-8 -*-
"""
@Datetime: 2019/4/10
@Author: Zhang Yafei
"""
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-3, 3, 50)
y = 2 * x + 1
plt.figure(num=1, figsize=(8, 5))
plt.plot(x, y)
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
# 将底下的作为x轴
ax.xaxis.set_ticks_position('bottom')
# 并且data,以y轴的数据为基本
ax.spines['bottom'].set_position(('data', 0))
# 将左边的作为y轴
ax.yaxis.set_ticks_position('left')
ax.spines['left'].set_position(('data', 0))
print("-----方式一-----")
x0 = 1
y0 = 2 * x0 + 1
plt.plot([x0, x0], [0, y0], 'k--', linewidth=2.5)
plt.scatter([x0], [y0], s=50, color='b')
plt.annotate(r'$2x+1 = %s$' % y0, xy=(x0, y0), xycoords='data',
xytext=(+30, -30), textcoords='offset points', fontsize=16
, arrowprops=dict(arrowstyle='->',
connectionstyle="arc3,rad=.2"))
plt.show()

第一种标注方式
plt.annotate(r'$2x+1 = %s$' % y0, xy=(x0, y0), xycoords='data',
xytext=(+30, -30), textcoords='offset points', fontsize=16
, arrowprops=dict(arrowstyle='->',
connectionstyle="arc3,rad=.2"))
注意:
- xy就是需要进行注释的点的横纵坐标;
- xycoords = 'data'说明的是要注释点的xy的坐标是以横纵坐标轴为基准的;
- xytext=(+30,-30)和textcoords='data'说明了这里的文字是基于标注的点的x坐标的偏移+30以及标注点y坐标-30位置,就是我们要进行注释文字的位置;
- fontsize = 16就说明字体的大小;
- arrowprops = dict()这个是对于这个箭头的描述,arrowstyle='->'这个是箭头的类型,connectionstyle="arc3,rad=.2"这两个是描述我们的箭头的弧度以及角度的。
第二种标注方式
print("-----方式二-----")
plt.text(-3.7, 3, r'$this\ is\ the\ some\ text. \mu\ \sigma_i\ \alpha_t$',
fontdict={'size': 16, 'color': 'r'})

看一下这个图
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-3,3,50)
y1 = 0.1*x
y2 = x**2
plt.figure()
#zorder控制绘图顺序
plt.plot(x,y1,linewidth = 10,zorder = 1,label = r'$y_1\ =\ 0.1*x$')
plt.plot(x,y2,linewidth = 10,zorder = 2,label = r'$y_2\ =\ x^{2}$')
plt.ylim(-2,2)
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.spines['bottom'].set_position(('data',0))
ax.yaxis.set_ticks_position('left')
ax.spines['left'].set_position(('data',0))
plt.show()
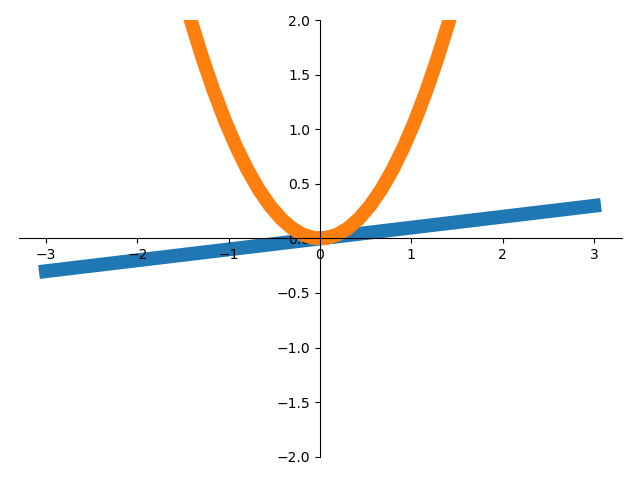
执行效果
从上面看,我们可以看见我们轴上的坐标被掩盖住了,那么我们怎么去修改他呢?
print(ax.get_xticklabels())
print(ax.get_yticklabels())
for label in ax.get_xticklabels() + ax.get_yticklabels():
label.set_fontsize(12)
label.set_bbox(dict(facecolor = 'white',edgecolor='none',alpha = 0.8,zorder = 2))
<a list of 9 Text xticklabel objects>
<a list of 9 Text yticklabel objects>

让坐标轴显示出来
这里需要注意:
- ax.get_xticklabels()获取得到就是坐标轴上的数字;
- set_bbox()这个bbox就是那坐标轴上的数字的那一小块区域,从结果我们可以很明显的看出来;
- facecolor = 'white',edgecolor='none,第一个参数表示的这个box的前面的背景,边上的颜色。
图形种类
一、折线图基础
import random
"""
如果列表a表示10点到12点的每一分钟的气温,如何绘制折线图观察每分钟气温的变化情况?
a= [random.randint(20,35) for i in range(120)]
用matplotlib用图形画出变化的折线图
"""
from matplotlib import pyplot as plt
import matplotlib
from matplotlib import font_manager
#方式一
#windows和linux设置字体
# font = {'family' : 'SimHei'}
# matplotlib.rc('font', **font)
#方式二
my_font = font_manager.FontProperties(fname='font/simsun.ttc')
x = range(120)
y = [random.randint(20,35) for i in range(120)]
plt.figure(figsize=(13,8),dpi=80)
plt.plot(x,y)
#设置x的轴的刻度
_x = list(x) #只有列表才可以取步长,range不可以取步长
_xtick_labels = ['10点{}分'.format(i) for i in range(60)]
_xtick_labels += ['11点{}分'.format(i) for i in range(60)]
#取步长,数字和字符串一一对应,数据的长度一样
plt.xticks(_x[::3],_xtick_labels[::3], rotation=45,fontproperties=my_font) #rotation旋转的度数
#添加描述信息
plt.xlabel('时间',fontproperties=my_font)
plt.ylabel('温度 单位(℃)',fontproperties=my_font)
plt.title('10点到12点每分钟的气温变化情况',fontproperties=my_font)
plt.show()

二、交女朋友数量走势图
# -*- coding: utf-8 -*-
"""
@Datetime: 2018/11/17
@Author: Zhang Yafei
"""
"""
假设大家在30岁的时候,根据自己的实际情况,统计出来了从11岁到30岁每年交的女(男)朋友的数量如列表a,请绘制出该数据的折线图,以便分析自己每年交女(男)朋友的数量走势
a = [1,0,1,1,2,4,3,2,3,4,4,5,6,5,4,3,3,1,1,1]
要求:
y轴表示个数
x轴表示岁数,比如11岁,12岁等
"""
from matplotlib import pyplot as plt
from matplotlib import font_manager
#解决中文字体正常显示
my_font = font_manager.FontProperties(fname='font/simsun.ttc')
#准备数据
x = range(11,31)
y = [1,0,1,1,2,4,3,2,3,4,4,5,6,5,4,3,3,1,1,1]
#设置图形大小
plt.figure(figsize=(11,6),dpi=80)
#设置x,y轴的刻度
_x = list(x)
_xtick_labels = ['{}岁'.format(i) for i in _x]
plt.xticks(_x,_xtick_labels,rotation=45,fontproperties=my_font)
plt.yticks(range(0,9))
#绘制网格
plt.grid(alpha=0.4) #alpha透明度
#设置描述信息
plt.xlabel('年龄',fontproperties=my_font)
plt.ylabel('个数',fontproperties=my_font)
plt.title('11-30岁交女朋友数量走势图',fontproperties=my_font)
plt.plot(x,y)
plt.show()

三、交女朋友数量走势图2
# -*- coding: utf-8 -*-
"""
@Datetime: 2018/11/17
@Author: Zhang Yafei
"""
"""
假设大家在30岁的时候,根据自己的实际情况,统计出来了你和你同桌各自从11岁到30岁每年交的女(男)朋友的数量如列表a和b,请在一个图中绘制出该数据的折线图,以便比较自己和同桌20年间的差异,同时分析每年交女(男)朋友的数量走势
a = [1,0,1,1,2,4,3,2,3,4,4,5,6,5,4,3,3,1,1,1]
b = [1,0,3,1,2,2,3,3,2,1 ,2,1,1,1,1,1,1,1,1,1]
要求:
y轴表示个数
x轴表示岁数,比如11岁,12岁等
"""
from matplotlib import pyplot as plt
from matplotlib import font_manager
#解决中文字体正常显示
my_font = font_manager.FontProperties(fname='font/simsun.ttc')
#准备数据
x = range(11,31)
y_1 = [1,0,1,1,2,4,3,2,3,4,4,5,6,5,4,3,3,1,1,1]
y_2 = [1,0,3,1,2,2,3,3,2,1 ,2,1,1,1,1,1,1,1,1,1]
#设置图形大小
plt.figure(figsize=(11,6),dpi=80)
#设置x,y轴的刻度
_x = list(x)
_xtick_labels = ['{}岁'.format(i) for i in _x]
plt.xticks(_x,_xtick_labels,rotation=45,fontproperties=my_font)
# plt.yticks(range(0,9))
#绘制网格
plt.grid(alpha=0.4) #alpha透明度
#设置描述信息
plt.xlabel('年龄',fontproperties=my_font)
plt.ylabel('个数',fontproperties=my_font)
plt.title('11-30岁交女朋友数量走势图',fontproperties=my_font)
plt.plot(x,y_1,label='自己',color='orange',linestyle=':')
plt.plot(x,y_2,label='同桌',color='cyan',linestyle='--')
plt.legend(prop=my_font,loc='upper left')
plt.show()
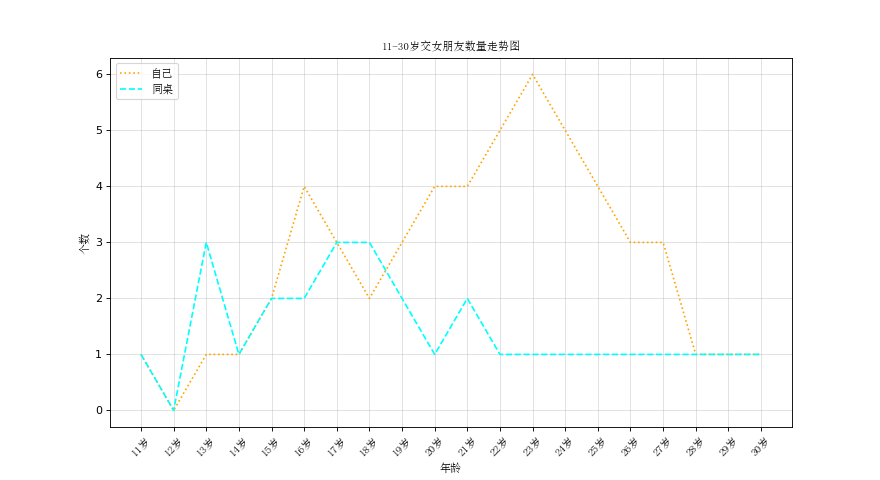
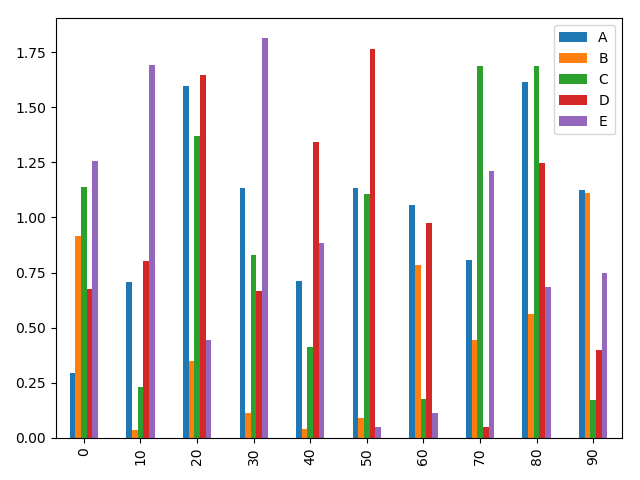
例:dataframe绘制折线图
import matplotlib.pyplot as plt import numpy as np from numpy.random import randn from pandas import DataFrame df = DataFrame(randn(10, 5), columns=['A', 'B', 'C', 'D', 'E'], index=np.arange(0, 100, 10)) df.plot() plt.show()
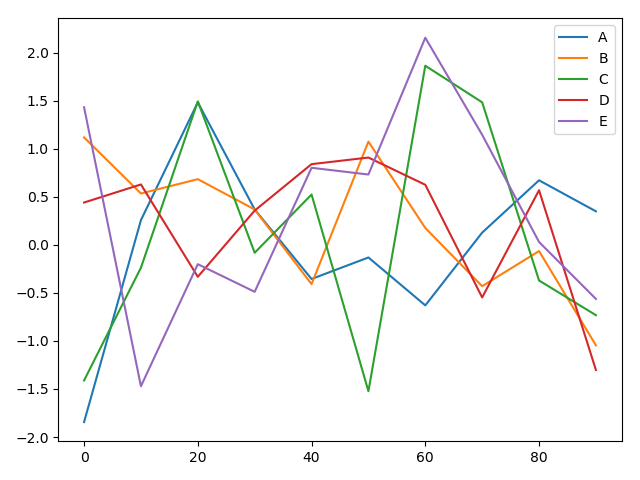
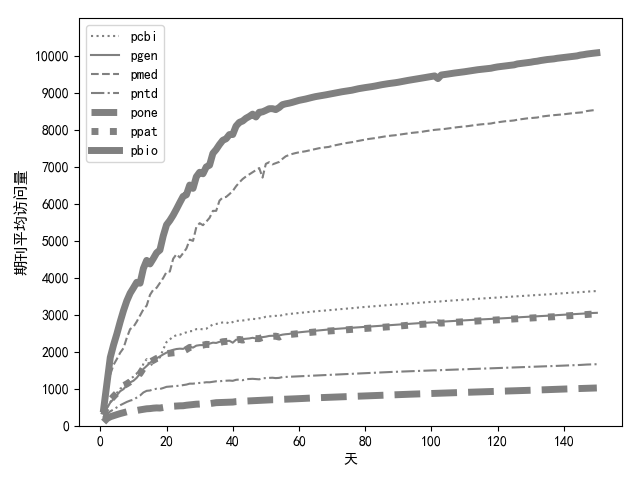
多条折线图
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
f = open(r"期刊整体趋势.csv")
data = pd.read_csv(f)
y = range(0, 11000, 1000)
x = range(0, 180)
plt.plot(data["day"], data["pcbi"], color='gray', linestyle=':')
plt.plot(data["day"], data["pgen"], color='gray', linestyle='-')
plt.plot(data["day"], data["pmed"], color='gray', linestyle='--')
plt.plot(data["day"], data["pntd"], color='gray', linestyle='-.')
plt.plot(data["day"], data["pone"], color='gray', linewidth=5, linestyle='--')
plt.plot(data["day"], data["ppat"], color='gray', linewidth=5, linestyle=':')
plt.plot(data["day"], data["pbio"], color='gray', linewidth=5, linestyle='-')
# plt.plot(data["day"], data["pone"], color='gray', linewidth=5, linestyle='--', marker='2')
# plt.plot(data["day"], data["ppat"], color='gray', linewidth=5, linestyle=':', marker='3')
# plt.plot(data["day"], data["pbio"], color='gray', linewidth=5, linestyle='-', marker='*')
plt.ylim(0, 11000)
plt.legend()
plt.yticks(y)
plt.xlabel("天", fontsize="10")
plt.ylabel("期刊平均访问量", fontsize="11")
plt.show()
四、散点图
# -*- coding: utf-8 -*-
"""
@Datetime: 2018/11/17
@Author: Zhang Yafei
"""
"""
假设通过爬虫你获取到了北京2016年3,10月份每天白天的最高气温(分别位于列表a,b),那么此时如何寻找出气温和随时间(天)变化的某种规律?
a = [11,17,16,11,12,11,12,6,6,7,8,9,12,15,14,17,18,21,16,17,20,14,15,15,15,19,21,22,22,22,23]
b = [26,26,28,19,21,17,16,19,18,20,20,19,22,23,17,20,21,20,22,15,11,15,5,13,17,10,11,13,12,13,6]
"""
from matplotlib import pyplot as plt
from matplotlib import font_manager
#设置中文字体
my_font = font_manager.FontProperties(fname='font/simsun.ttc')
#设置图形大小
plt.figure(figsize=(13,6),dpi=80)
#数据准备
x_3 = range(1,32)
x_10 = range(51,82)
y_3 = [11,17,16,11,12,11,12,6,6,7,8,9,12,15,14,17,18,21,16,17,20,14,15,15,15,19,21,22,22,22,23]
y_10 = [26,26,28,19,21,17,16,19,18,20,20,19,22,23,17,20,21,20,22,15,11,15,5,13,17,10,11,13,12,13,6]
#使用scatter绘制散点图和折线图的唯一区别
plt.scatter(x_3,y_3,label='3月份')
plt.scatter(x_10,y_10,label='10月份')
plt.legend(loc='upper left',prop=my_font)
#调整x的刻度
_x = list(x_3) + list(x_10)
_xtick_labels = ['3月{}日'.format(i) for i in x_3]
_xtick_labels += ['10月{}日'.format(i-50) for i in x_10]
plt.xticks(_x[::3],_xtick_labels[::3],fontproperties=my_font,rotation=45)
#添加描述信息
plt.xlabel('时间',fontproperties=my_font)
plt.ylabel('温度',fontproperties=my_font)
plt.title('3月份和10月份温度对比图',fontproperties=my_font)
#显示
plt.show()

五、条形图
# -*- coding: utf-8 -*-
"""
@Datetime: 2018/11/17
@Author: Zhang Yafei
"""
"""
假设你获取到了2017年内地电影票房前20的电影(列表a)和电影票房数据(列表b),那么如何更加直观的展示该数据?
a = ["战狼2","速度与激情8","功夫瑜伽","西游伏妖篇","变形金刚5:最后的骑士","摔跤吧!爸爸","加勒比海盗5:死无对证","金刚:骷髅岛","极限特工:终极回归","生化危机6:终章","乘风破浪","神偷奶爸3","智取威虎山","大闹天竺","金刚狼3:殊死一战","蜘蛛侠:英雄归来","悟空传","银河护卫队2","情圣","新木乃伊",]
b=[56.01,26.94,17.53,16.49,15.45,12.96,11.8,11.61,11.28,11.12,10.49,10.3,8.75,7.55,7.32,6.99,6.88,6.86,6.58,6.23] 单位:亿
"""
from matplotlib import pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname='font/simsun.ttc')
plt.figure(figsize=(15,8),dpi=80)
a = ["战狼2","速度与激情8","功夫瑜伽","西游伏妖篇","变形金刚5:最后的骑士","摔跤吧!爸爸","加勒比海盗5:死无对证","金刚:骷髅岛","极限特工:终极回归","生化危机6:终章","乘风破浪","神偷奶爸3","智取威虎山","大闹天竺","金刚狼3:殊死一战","蜘蛛侠:英雄归来","悟空传","银河护卫队2","情圣","新木乃伊",]
b = [56.01,26.94,17.53,16.49,15.45,12.96,11.8,11.61,11.28,11.12,10.49,10.3,8.75,7.55,7.32,6.99,6.88,6.86,6.58,6.23]
plt.bar(range(len(a)),b,width=0.3)
plt.xticks(range(len(a)),a,fontproperties=my_font,rotation=90)
plt.savefig('movie.png')
plt.show()

六、横条形图
"""
假设你获取到了2017年内地电影票房前20的电影(列表a)和电影票房数据(列表b),那么如何更加直观的展示该数据?
a = ["战狼2","速度与激情8","功夫瑜伽","西游伏妖篇","变形金刚5:最后的骑士","摔跤吧!爸爸","加勒比海盗5:死无对证","金刚:骷髅岛","极限特工:终极回归","生化危机6:终章","乘风破浪","神偷奶爸3","智取威虎山","大闹天竺","金刚狼3:殊死一战","蜘蛛侠:英雄归来","悟空传","银河护卫队2","情圣","新木乃伊",]
b=[56.01,26.94,17.53,16.49,15.45,12.96,11.8,11.61,11.28,11.12,10.49,10.3,8.75,7.55,7.32,6.99,6.88,6.86,6.58,6.23] 单位:亿
"""
from matplotlib import pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname='font/simsun.ttc')
plt.figure(figsize=(15,8),dpi=80)
a = ["战狼2","速度与激情8","功夫瑜伽","西游伏妖篇","变形金刚5:最后的骑士","摔跤吧!爸爸","加勒比海盗5:死无对证","金刚:骷髅岛","极限特工:终极回归","生化危机6:终章","乘风破浪","神偷奶爸3","智取威虎山","大闹天竺","金刚狼3:殊死一战","蜘蛛侠:英雄归来","悟空传","银河护卫队2","情圣","新木乃伊",]
b = [56.01,26.94,17.53,16.49,15.45,12.96,11.8,11.61,11.28,11.12,10.49,10.3,8.75,7.55,7.32,6.99,6.88,6.86,6.58,6.23]
plt.barh(range(len(a)),b,height=0.3,color='orange')
plt.yticks(range(len(a)),a,fontproperties=my_font)
plt.grid(alpha=0.4)
# plt.savefig('movie.png')
plt.show()

七、绘制多次条形图
# -*- coding: utf-8 -*-
"""
@Datetime: 2018/11/17
@Author: Zhang Yafei
"""
"""
假设你知道了列表a中电影分别在2017-09-14(b_14), 2017-09-15(b_15), 2017-09-16(b_16)三天的票房,为了展示列表中电影本身的票房以及同其他电影的数据对比情况,应该如何更加直观的呈现该数据?
a = ["猩球崛起3:终极之战","敦刻尔克","蜘蛛侠:英雄归来","战狼2"]
b_16 = [15746,312,4497,319]
b_15 = [12357,156,2045,168]
b_14 = [2358,399,2358,362]
"""
from matplotlib import pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname='font/simsun.ttc')
plt.figure(figsize=(15,8),dpi=80)
a = ["猩球崛起3:终极之战","敦刻尔克","蜘蛛侠:英雄归来","战狼2"]
b_16 = [15746,312,4497,319]
b_15 = [12357,156,2045,168]
b_14 = [2358,399,2358,362]
bar_width = 0.2
x_14 = list(range(len(a)))
x_15 = [i+bar_width for i in x_14]
x_16 = [i+bar_width*2 for i in x_14]
plt.bar(range(len(a)),b_14,width=bar_width,label='14日')
plt.bar(x_15,b_15,width=bar_width,label='15日')
plt.bar(x_16,b_16,width=bar_width,label='16日')
plt.legend(prop=my_font)
plt.xticks(x_14,a,fontproperties=my_font)
plt.grid(alpha=0.4)
# plt.savefig('movie.png')
plt.show()

例:dataframe绘制柱状图
import matplotlib.pyplot as plt import numpy as np from numpy.random import randn from pandas import DataFrame df = DataFrame(abs(randn(10, 5)), columns=['A', 'B', 'C', 'D', 'E'], index=np.arange(0, 100, 10)) df.plot(kind='bar') plt.show()
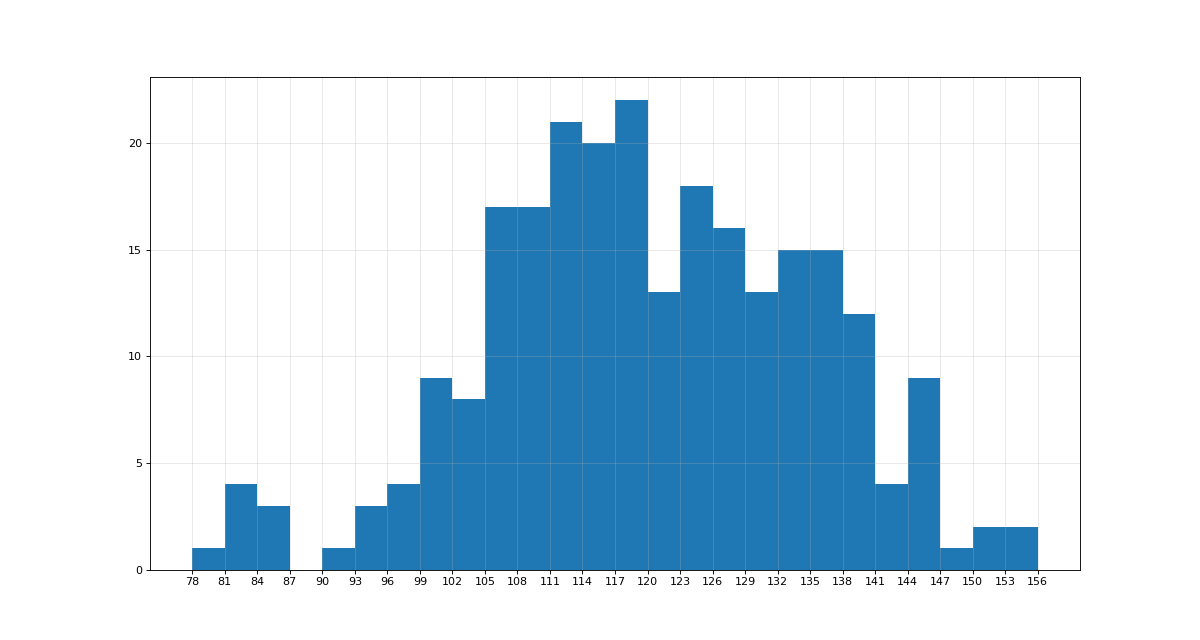
八、直方图
# -*- coding: utf-8 -*- """ @Datetime: 2018/11/17 @Author: Zhang Yafei """ """ 直方图:分布状态 假设你获取了250部电影的时长(列表a中),希望统计出这些电影时长的分布状态(比如时长为100分钟到120分钟电影的数量,出现的频率)等信息,你应该如何呈现这些数据? a=[131, 98, 125, 131, 124, 139, 131, 117, 128, 108, 135, 138, 131, 102, 107, 114, 119, 128, 121, 142, 127, 130, 124, 101, 110, 116, 117, 110, 128, 128, 115, 99, 136, 126, 134, 95, 138, 117, 111,78, 132, 124, 113, 150, 110, 117, 86, 95, 144, 105, 126, 130,126, 130, 126, 116, 123, 106, 112, 138, 123, 86, 101, 99, 136,123, 117, 119, 105, 137, 123, 128, 125, 104, 109, 134, 125, 127,105, 120, 107, 129, 116, 108, 132, 103, 136, 118, 102, 120, 114,105, 115, 132, 145, 119, 121, 112, 139, 125, 138, 109, 132, 134,156, 106, 117, 127, 144, 139, 139, 119, 140, 83, 110, 102,123,107, 143, 115, 136, 118, 139, 123, 112, 118, 125, 109, 119, 133,112, 114, 122, 109, 106, 123, 116, 131, 127, 115, 118, 112, 135,115, 146, 137, 116, 103, 144, 83, 123, 111, 110, 111, 100, 154,136, 100, 118, 119, 133, 134, 106, 129, 126, 110, 111, 109, 141,120, 117, 106, 149, 122, 122, 110, 118, 127, 121, 114, 125, 126,114, 140, 103, 130, 141, 117, 106, 114, 121, 114, 133, 137, 92,121, 112, 146, 97, 137, 105, 98, 117, 112, 81, 97, 139, 113,134, 106, 144, 110, 137, 137, 111, 104, 117, 100, 111, 101, 110,105, 129, 137, 112, 120, 113, 133, 112, 83, 94, 146, 133, 101,131, 116, 111, 84, 137, 115, 122, 106, 144, 109, 123, 116, 111,111, 133, 150] """ from matplotlib import pyplot as plt from matplotlib import font_manager a=[131, 98, 125, 131, 124, 139, 131, 117, 128, 108, 135, 138, 131, 102, 107, 114, 119, 128, 121, 142, 127, 130, 124, 101, 110, 116, 117, 110, 128, 128, 115, 99, 136, 126, 134, 95, 138, 117, 111,78, 132, 124, 113, 150, 110, 117, 86, 95, 144, 105, 126, 130,126, 130, 126, 116, 123, 106, 112, 138, 123, 86, 101, 99, 136,123, 117, 119, 105, 137, 123, 128, 125, 104, 109, 134, 125, 127,105, 120, 107, 129, 116, 108, 132, 103, 136, 118, 102, 120, 114,105, 115, 132, 145, 119, 121, 112, 139, 125, 138, 109, 132, 134,156, 106, 117, 127, 144, 139, 139, 119, 140, 83, 110, 102,123,107, 143, 115, 136, 118, 139, 123, 112, 118, 125, 109, 119, 133,112, 114, 122, 109, 106, 123, 116, 131, 127, 115, 118, 112, 135,115, 146, 137, 116, 103, 144, 83, 123, 111, 110, 111, 100, 154,136, 100, 118, 119, 133, 134, 106, 129, 126, 110, 111, 109, 141,120, 117, 106, 149, 122, 122, 110, 118, 127, 121, 114, 125, 126,114, 140, 103, 130, 141, 117, 106, 114, 121, 114, 133, 137, 92,121, 112, 146, 97, 137, 105, 98, 117, 112, 81, 97, 139, 113,134, 106, 144, 110, 137, 137, 111, 104, 117, 100, 111, 101, 110,105, 129, 137, 112, 120, 113, 133, 112, 83, 94, 146, 133, 101,131, 116, 111, 84, 137, 115, 122, 106, 144, 109, 123, 116, 111,111, 133, 150] #计算组数 d = 3 num_bins = (max(a)-min(a))//d #设置图形大小 plt.figure(figsize=(15,8),dpi=80) plt.hist(a,num_bins) #频数分布直方图 # plt.hist(a,num_bins,density=True) #频率分布直方图 #设置x轴的刻度 plt.xticks(range(min(a),max(a)+d,d)) plt.grid(alpha=0.3) plt.show()
九、案例
# -*- coding: utf-8 -*- """ @Datetime: 2018/11/17 @Author: Zhang Yafei """ """ 在美国2004年人口普查发现有124 million的人在离家相对较远的地方工作。根据他们从家到上班地点所需要的时间,通过抽样统计(最后一列)出了下表的数据,这些数据能够绘制成直方图么? interval = [0,5,10,15,20,25,30,35,40,45,60,90] width = [5,5,5,5,5,5,5,5,5,15,30,60] quantity = [836,2737,3723,3926,3596,1438,3273,642,824,613,215,47] """ from matplotlib import pyplot as plt from matplotlib import font_manager interval = [0,5,10,15,20,25,30,35,40,45,60,90] width = [5,5,5,5,5,5,5,5,5,15,30,60] quantity = [836,2737,3723,3926,3596,1438,3273,642,824,613,215,47] plt.figure(figsize=(13,6),dpi=80) plt.bar(range(len(quantity)),quantity,width=1) #设置x轴的刻度 _x = [i-0.5 for i in range(13)] _xtick_labels = interval + [150] plt.xticks(_x,_xtick_labels) plt.show()

十、饼图
饼图(Pie Graph):又称圆形图,是一个划分为几个扇形的扇形统计图,它能够直观的反映个体与总体的比例关系
例1:芝麻信用失信用户教育水平分布
import matplotlib.pyplot as plt
# font = {
# 'family':'SimHei'
# }
# mpl.rc('font',**font)
# 设置绘图的主题风格(不妨使用R中的ggplot分隔)
plt.style.use('ggplot')
# 构造数据
edu = [0.2515, 0.3724, 0.3336, 0.0368, 0.0057]
labels = ['中专', '大专', '本科', '硕士', '其他']
explode = [0, 0.1, 0, 0, 0] # 用于突出显示大专学历人群
colors = ['#9999ff', '#ff9999', '#7777aa', '#2442aa', '#dd5555'] # 自定义颜色
# 中文乱码和坐标轴负号的处理
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 将横、纵坐标轴标准化处理,保证饼图是一个正圆,否则为椭圆
plt.axes(aspect='equal')
# 控制x轴和y轴的范围
plt.xlim(0, 4)
plt.ylim(0, 4)
# 绘制饼图
plt.pie(x=edu, # 绘图数据
explode=explode, # 突出显示大专人群
labels=labels, # 添加教育水平标签
colors=colors, # 设置饼图的自定义填充色
autopct='%.1f%%', # 设置百分比的格式,这里保留一位小数
pctdistance=0.8, # 设置百分比标签与圆心的距离
labeldistance=1.15, # 设置教育水平标签与圆心的距离
startangle=180, # 设置饼图的初始角度
radius=1.5, # 设置饼图的半径
counterclock=False, # 是否逆时针,这里设置为顺时针方向
wedgeprops={'linewidth': 1.5, 'edgecolor': 'green'}, # 设置饼图内外边界的属性值
textprops={'fontsize': 12, 'color': 'k'}, # 设置文本标签的属性值
center=(1.8, 1.8), # 设置饼图的原点
frame=1) # 是否显示饼图的图框,这里设置显示
# 删除x轴和y轴的刻度
plt.xticks(())
plt.yticks(())
# 添加图标题
plt.title('芝麻信用失信用户教育水平分布')
# 保存图形
plt.savefig('芝麻信用失信用户教育水平分布.png')
# 显示图形
plt.show()

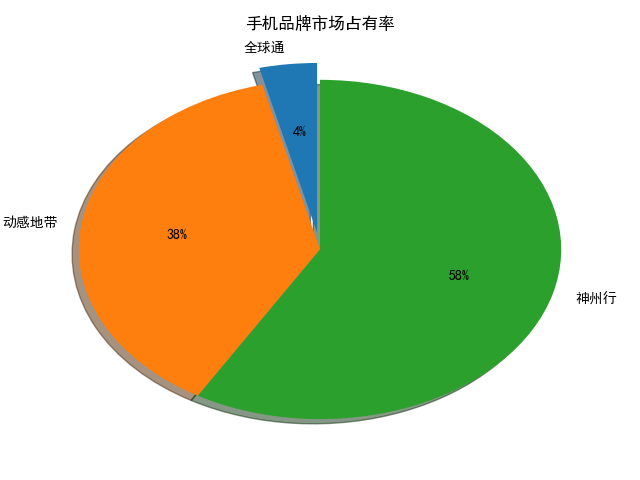
例2:手机品牌市场占有率
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy
from pandas import read_csv
data = read_csv('E:/python/data_analysis/data/pie.csv')
gb = data.groupby(
by=['通信品牌'],
as_index=False
)['号码'].agg({
'用户数': numpy.size
})
font = {
'family': 'SimHei'
}
mpl.rc('font', **font)
explode = [0.1, 0, 0] # 0.1 凸出这部分,
plt.pie(gb['用户数'], labels=gb['通信品牌'], explode=explode, autopct='%.f%%',
shadow=True, labeldistance=1.1, startangle=90, pctdistance=0.6)
plt.title('手机品牌市场占有率')
plt.savefig('手机品牌市场占有率.png')
plt.show()
# labeldistance,文本的位置离远点有多远,1.1指1.1倍半径的位置
# autopct,圆里面的文本格式,%3.1f%%表示小数有三位,整数有一位的浮点数
# shadow,饼是否有阴影
# startangle,起始角度,0,表示从0开始逆时针转,为第一块。一般选择从90度开始比较好看
# pctdistance,百分比的text离圆心的距离
# patches, l_texts, p_texts,为了得到饼图的返回值,p_texts饼图内部文本的,l_texts饼图外label的文本
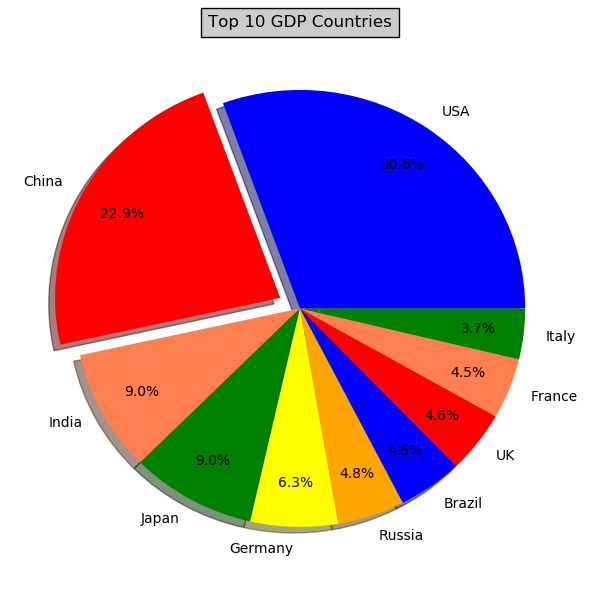
例3:各个国家之间的GDP占比图
import matplotlib.pyplot as plt
def draw_pie(labels, quants):
# make a square figure
plt.figure(1, figsize=(6, 6))
# For China, make the piece explode a bit
expl = [0, 0.1, 0, 0, 0, 0, 0, 0, 0, 0] # 第二块即China离开圆心0.1
# Colors used. Recycle if not enough.
colors = ["blue", "red", "coral", "green", "yellow", "orange"] # 设置颜色(循环显示)
# Pie Plot
# autopct: format of "percent" string;百分数格式
plt.pie(quants, explode=expl, colors=colors, labels=labels, autopct='%1.1f%%', pctdistance=0.8, shadow=True)
plt.title('Top 10 GDP Countries', bbox={'facecolor': '0.8', 'pad': 5})
plt.savefig("pie.jpg")
plt.show()
plt.close()
# quants: GDP
# labels: country name
labels = ['USA', 'China', 'India', 'Japan', 'Germany', 'Russia', 'Brazil', 'UK', 'France', 'Italy']
quants = [15094025.0, 11299967.0, 4457784.0, 4440376.0, 3099080.0, 2383402.0, 2293954.0, 2260803.0, 2217900.0,
1846950.0]
draw_pie(labels, quants)
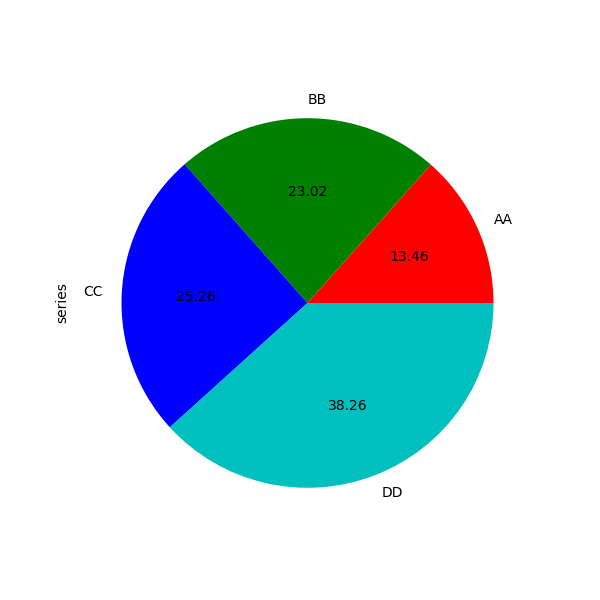
例4:series画饼图
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 简单的饼图
series = pd.Series(3 * np.random.rand(4), index=['a', 'b', 'c', 'd'], name='series')
# series.plot.pie(figsize=(6, 6))
#
#
##多子图饼图
# df = pd.DataFrame(3 * np.random.rand(4, 2), index=['a', 'b', 'c', 'd'], columns=['x', 'y'])
# df.plot.pie(subplots=True, figsize=(8, 4))
# 有比例详情的饼图
series.plot.pie(labels=['AA', 'BB', 'CC', 'DD'], colors=['r', 'g', 'b', 'c'],
autopct='%.2f', fontsize=10, figsize=(6, 6))
plt.show()
十一、等高线图
import matplotlib.pyplot as plt
import numpy as np
# 建立等高线的函数
def f(x, y):
return (1 - x / 2 + x ** 5 + y ** 3) * np.exp(-x ** 2 - y ** 2)
n = 256
x = np.linspace(-3, 3, n)
y = np.linspace(-3, 3, n)
# 等高线图就是网格图,生成网格
X, Y = np.meshgrid(x, y)
# 向等高线图形上面的一些线条增加颜色
C = plt.contour(X, Y, f(X, Y), 5, color='black', linewidth=0.5)
# 向等高线图形不同位置增加颜色
plt.contourf(X, Y, f(X, Y), 5, alpha=0.75, cmap=plt.cm.hot)
# 增加字体
plt.clabel(C, inline=True, fontsize=10)
# 如果修改上面的代码True 改成False 那么线会直接穿过字体
# plt.clabel(C,inline=False,fontsize=10)
# 去掉x,y轴
plt.xticks(())
plt.yticks(())
plt.show()

十二、热图(heatmap)
# 设置一个图片的数据 a = np.random.random(9).reshape(3, 3) print(a) # origin='lower' 换成 origin='upper' # interpolation='nearest' 显示的是类别,什么方式进行显示 # http://matplotlib.org/examples/images_contours_and_fields/interpolation_methods.html plt.imshow(a, interpolation='nearest', cmap='bone', origin='lower') # 在旁边增加一个说明 shrink=0.9 显示的比例是多少 也就是压缩 # plt.colorbar() plt.colorbar(shrink=1.2) # 去掉x,y轴 plt.xticks(()) plt.yticks(()) plt.show()

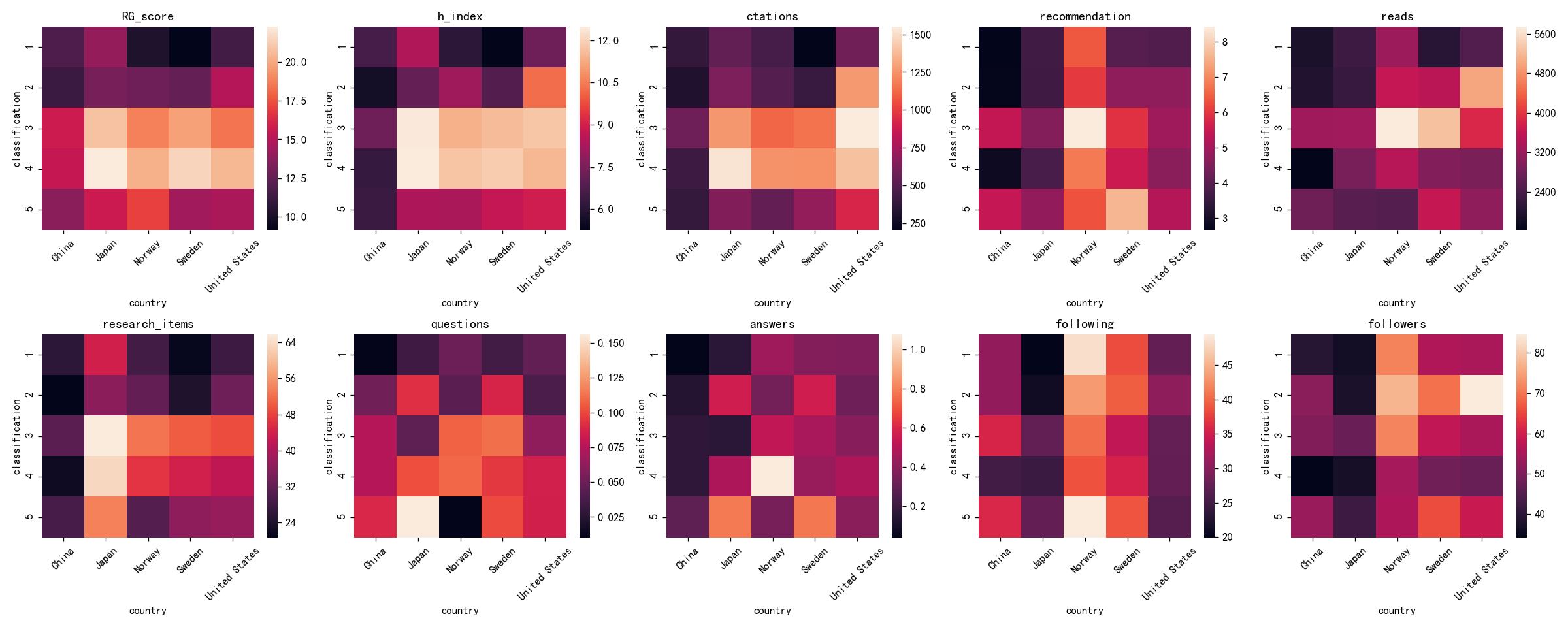
# -*- coding: utf-8 -*-
"""
Datetime: 2019/6/4
Author: Zhang Yafei
Description:
"""
import pandas as pd
import seaborn as sb
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
df = pd.read_excel('result_analysis/groupby_mean.xlsx', encoding='ISO-8859-1')
names = ['RG_score', 'h_index', 'ctations', 'recommendation', 'reads', 'research_items', 'questions', 'answers', 'following', 'followers']
plt.figure(figsize=(20, 8), dpi=120)
def plot_heatmap(args):
name, num = args
plt.subplot(2, 5, num)
pivot_df = pd.pivot_table(df, index=['classification'], columns='country', values=name)
# sb.heatmap(pivot_df, annot=True)
sb.heatmap(pivot_df)
plt.xticks(rotation=45)
plt.tight_layout()
plt.title(name)
list(map(plot_heatmap, zip(names, list(range(1, 11)))))
# 保存图片
plt.savefig('result_analysis/heatmap.png')
# 显示图片
plt.show()
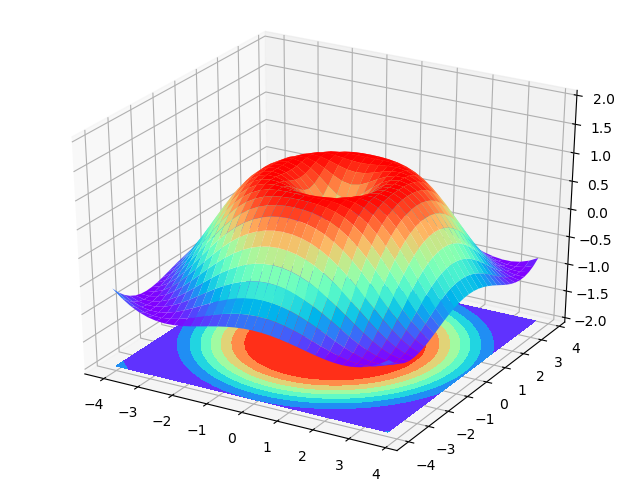
十三、3D图像
# 因为是3D图像我们需要额外的导入一个库
from mpl_toolkits.mplot3d import Axes3D
# 建立窗口
fig = plt.figure()
# 在3D上面加上轴
ax = Axes3D(fig)
# x,y数据
X = np.arange(-4, 4, 0.25)
Y = np.arange(-4, 4, 0.25)
X, Y = np.meshgrid(X, Y)
R = np.sqrt(X ** 2 + Y ** 2)
# 形成高度值
Z = np.sin(R)
# rstride=1 cstride=1 跨度(行列跨)
ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap=plt.get_cmap('rainbow'))
# 等高线图offset=-2 表示比0点的位置低两个点
ax.contourf(X, Y, Z, zdir='z', offset=-2, cmap='rainbow')
ax.set_zlim(-2, 2)
plt.show()
十四、词云图
# -*- coding: utf-8 -*-
"""
Datetime: 2019/6/29
Author: Zhang Yafei
Description:
"""
import os
import random
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from pylab import mpl
from wordcloud import WordCloud
import pandas as pd
plt.figure(figsize=(13, 6), dpi=500)
# 定义一个函数
def grey_color_func(word, font_size, position, orientation, ranndom_state=None, **kwargs):
return "hsl(0,0%%,%d%%)" % random.randint(60, 100)
def plot_wordcloud(cols, rows, num, title, frequence_dict, mask_image='mask1.jpg'):
plt.subplot(rows, cols, num)
# 背景图
root = os.path.dirname(__file__)
mask = np.array(Image.open(os.path.join(root, mask_image)))
# 设置字体
font = os.path.join(root, 'simsun.ttc')
wordcloud = WordCloud(font_path=font, mask=mask, background_color='white').generate_from_frequencies(frequencies=frequence_dict)
# 设置默认字体
mpl.rcParams['font.sans-serif'] = ['SimHei']
# 标题
plt.title(title)
# 显示我们生成图片
plt.imshow(wordcloud)
plt.tight_layout()
# 去掉x,y轴的标签
plt.axis("off")
def plot_wordcloud1(title, frequence_dict, mask_image='mask1.jpg'):
# 背景图
root = os.path.dirname(__file__)
mask = np.array(Image.open(os.path.join(root, mask_image)))
# 设置字体
font = os.path.join(root, 'simsun.ttc')
wordcloud = WordCloud(font_path=font, mask=mask, background_color='white').generate_from_frequencies(frequencies=frequence_dict)
# 设置默认字体
mpl.rcParams['font.sans-serif'] = ['SimHei']
# 标题
plt.title(title)
# 显示我们生成图片
plt.imshow(wordcloud)
# 去掉x,y轴的标签
plt.axis("off")
# plt.savefig(os.path.join('res', f'{title}.png'))
plt.show()
if __name__ == '__main__':
df_0 = pd.read_excel('算法特征分析.xlsx', index_col=0)
df_1 = pd.read_excel('算法特征分析.xlsx', sheet_name=1, index_col=0)
df_2 = pd.read_excel('算法特征分析.xlsx', sheet_name=2, index_col=0)
df_3 = pd.read_excel('算法特征分析.xlsx', sheet_name=3, index_col=0)
df_4 = pd.read_excel('算法特征分析.xlsx', sheet_name=4, index_col=0)
df_5 = pd.read_excel('算法特征分析.xlsx', sheet_name=5, index_col=0)
df_6 = pd.read_excel('算法特征分析.xlsx', sheet_name=6, index_col=0)
df_0_frequences = df_0['论文数'].to_dict()
df_1_frequences = df_1['论文数'].to_dict()
df_2_frequences = df_2['论文数'].to_dict()
df_3_frequences = df_3['论文数'].to_dict()
df_4_frequences = df_4['论文数'].to_dict()
df_5_frequences = df_5['论文数'].to_dict()
df_6_frequences = df_6['论文数'].to_dict()
# plot_wordcloud(rows=1, cols=3, num=1, title='分类算法', frequence_dict=df_0_frequences)
# plot_wordcloud(rows=1, cols=3, num=2, title='统计算法', frequence_dict=df_1_frequences)
# plot_wordcloud(rows=1, cols=3, num=3, title='人工神经网络', frequence_dict=df_2_frequences)
#
# # 图片保存
# plt.savefig('算法影响力4.png')
# 图片可视化
# plt.show()
# plot_wordcloud(rows=1, cols=4, num=1, title='回归算法', frequence_dict=df_3_frequences)
# plot_wordcloud(rows=1, cols=4, num=2, title='聚类算法', frequence_dict=df_4_frequences)
# plot_wordcloud(rows=1, cols=4, num=3, title='降维网络', frequence_dict=df_5_frequences)
# plot_wordcloud(rows=1, cols=4, num=4, title='遗传算法', frequence_dict=df_6_frequences)
# 图片保存
# plt.savefig('res/算法影响力3.png')
# 图片可视化
# plt.show()
plot_wordcloud1(title='分类算法', frequence_dict=df_0_frequences)
# plot_wordcloud1(title='统计算法', frequence_dict=df_1_frequences)
# plot_wordcloud1(title='人工神经网络', frequence_dict=df_2_frequences)
# plot_wordcloud1(title='回归算法', frequence_dict=df_3_frequences)
# plot_wordcloud1(title='聚类算法', frequence_dict=df_4_frequences)
# plot_wordcloud1(title='降维网络', frequence_dict=df_5_frequences)
# plot_wordcloud1(title='遗传算法', frequence_dict=df_6_frequences)



