
准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure
Precision,Recall,F1score,Accuracy四个概念容易混淆,这里做一下解释。
假设一个二分类问题,样本有正负两个类别。那么模型预测的结果和真实标签的组合就有4种:TP,FP,FN,TN,如下图所示。这4个分别表示:实际为正样本你预测为正样本,实际为负样本你预测为正样本,实际为正样本你预测为负样本,实际为负样本你预测为负样本。

那么Precision和Recall表示什么意思?一般Precision和Recall都是针对某个类而言的,比如正类别的Recall,负类别的Recall等。如果你是10分类,那么可以有1这个类别的Precision,2这个类别的Precision,3这个类别的Recall等。而没有类似全部数据集的Recall或Precision这种说法。
Precision表示被分为正例的示例中实际为正例的比例,precision=TP/(TP+FP)。即,一个二分类,类别分别命名为1和2,Precision就表示在类别1中,分对了的数量占了类别1总数量的多少;同理,也表示在类别2中,分对了的数量占类别2总数量的多少。那么这个指标越高,就表示越整齐不混乱。
正样本的Precision表示你预测为正的样本中有多少预测对了,如下公式。
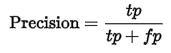
正样本的Recall表示真实标签为正的样本有多少被你预测对了,如下公式。二者的差别仅在于分母的不同。
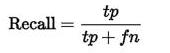
Recall,又称“查全率”——还是查全率好记,也更能体现其实质意义。
还有一个概念:Accuracy,表示你有多少比例的样本预测对了,公式如下,分母永远是全部样本的数量,很好理解。很容易扩展到多类别的情况,比如10分类,那么分子就是第一个类别预测对了多少个+第二个类别预测对了多少个+…+第十个类别预测对了多少个。
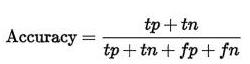
而Accuracy是我们最常见的评价指标,accuracy = (TP+TN)/(P+N),这个很容易理解,就是被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好。我们最常说的就是这个准确率。
“召回率”与“准确率”虽然没有必然的关系(从上面公式中可以看到),在实际应用中,是相互制约的。要根据实际需求,找到一个平衡点。
当 我们问检索系统某一件事的所有细节时(输入检索query查询词),Recall指:检索系统能“回忆”起那些事的多少细节,通俗来讲就是“回忆的能 力”。“能回忆起来的细节数” 除以 “系统知道这件事的所有细节”,就是“记忆率”,也就是recall——召回率。简单的,也可以理解为查全率。
F1score的计算是这样的:1/F1score = 1/2(1/recall + 1/precision)*,简单换算后就成了:F1score=2recallprecision/(recall+precision)。同样F1score也是针对某个样本而言的。一般而言F1score用来综合precision和recall作为一个评价指标。还有F1score的变形,主要是添加一个权重系数可以根据需要对recall和precision赋予不同的权重。


