
非关系型数据库之Redis
一、Redis简介
REmote DIctionary Server(Redis) 是一个由Salvatore Sanfilippo写的key-value存储系统。
Redis是一个开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。它通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希(Map), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型。经常被用作数据库,缓存和消息代理。它支持数据结构,如字符串,散列,列表,集合,带有范围查询的排序集,位图,超级日志,带有半径查询和流的地理空间索引。Redis具有内置复制,Lua脚本,LRU驱逐,事务和不同级别的磁盘持久性,并通过Redis Sentinel提供高可用性并使用Redis Cluster自动分区。
为什么选择Redis?
1. 使用Redis有哪些好处?
(1) 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
(2) 支持丰富数据类型,支持string,list,set,sorted set,hash
(3) 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
(4) 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
2. redis相比memcached有哪些优势?
(1) memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型
(2) redis的速度比memcached快很多
(3) redis可以持久化其数据
3. redis常见性能问题和解决方案:
(1) Master最好不要做任何持久化工作,如RDB内存快照和AOF日志文件
(2) 如果数据比较重要,某个Slave开启AOF备份数据,策略设置为每秒同步一次
(3) 为了主从复制的速度和连接的稳定性,Master和Slave最好在同一个局域网内
(4) 尽量避免在压力很大的主库上增加从库
(5) 主从复制不要用图状结构,用单向链表结构更为稳定,即:Master <- Slave1 <- Slave2 <- Slave3...
这样的结构方便解决单点故障问题,实现Slave对Master的替换。如果Master挂了,可以立刻启用Slave1做Master,其他不变。
4. MySQL里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据
相关知识:redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。redis 提供 6种数据淘汰策略:
voltile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据
5. Memcache与Redis的区别都有哪些?
1)、存储方式
Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。
Redis有部份存在硬盘上,这样能保证数据的持久性。
2)、数据支持类型
Memcache对数据类型支持相对简单。
Redis有复杂的数据类型。
3),value大小
redis最大可以达到1GB,而memcache只有1MB
6. Redis 常见的性能问题都有哪些?如何解决?
1).Master写内存快照,save命令调度rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以Master最好不要写内存快照。
2).Master AOF持久化,如果不重写AOF文件,这个持久化方式对性能的影响是最小的,但是AOF文件会不断增大,AOF文件过大会影响Master重启的恢复速度。Master最好不要做任何持久化工作,包括内存快照和AOF日志文件,特别是不要启用内存快照做持久化,如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次。
3).Master调用BGREWRITEAOF重写AOF文件,AOF在重写的时候会占大量的CPU和内存资源,导致服务load过高,出现短暂服务暂停现象。
4). Redis主从复制的性能问题,为了主从复制的速度和连接的稳定性,Slave和Master最好在同一个局域网内
7, redis 最适合的场景
Redis最适合所有数据in-momory的场景,虽然Redis也提供持久化功能,但实际更多的是一个disk-backed的功能,跟传统意义上的持久化有比较大的差别,那么可能大家就会有疑问,似乎Redis更像一个加强版的Memcached,那么何时使用Memcached,何时使用Redis呢?
如果简单地比较Redis与Memcached的区别,大多数都会得到以下观点:
、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
、Redis支持数据的备份,即master-slave模式的数据备份。
、Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
(1)、会话缓存(Session Cache)
最常用的一种使用Redis的情景是会话缓存(session cache)。用Redis缓存会话比其他存储(如Memcached)的优势在于:Redis提供持久化。当维护一个不是严格要求一致性的缓存时,如果用户的购物车信息全部丢失,大部分人都会不高兴的,现在,他们还会这样吗?
幸运的是,随着 Redis 这些年的改进,很容易找到怎么恰当的使用Redis来缓存会话的文档。甚至广为人知的商业平台Magento也提供Redis的插件。
(2)、全页缓存(FPC)
除基本的会话token之外,Redis还提供很简便的FPC平台。回到一致性问题,即使重启了Redis实例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降,这是一个极大改进,类似PHP本地FPC。
再次以Magento为例,Magento提供一个插件来使用Redis作为全页缓存后端。
此外,对WordPress的用户来说,Pantheon有一个非常好的插件 wp-redis,这个插件能帮助你以最快速度加载你曾浏览过的页面。
(3)、队列
Reids在内存存储引擎领域的一大优点是提供 list 和 set 操作,这使得Redis能作为一个很好的消息队列平台来使用。Redis作为队列使用的操作,就类似于本地程序语言(如Python)对 list 的 push/pop 操作。
如果你快速的在Google中搜索“Redis queues”,你马上就能找到大量的开源项目,这些项目的目的就是利用Redis创建非常好的后端工具,以满足各种队列需求。例如,Celery有一个后台就是使用Redis作为broker,你可以从这里去查看。
(4),排行榜/计数器
Redis在内存中对数字进行递增或递减的操作实现的非常好。集合(Set)和有序集合(Sorted Set)也使得我们在执行这些操作的时候变的非常简单,Redis只是正好提供了这两种数据结构。所以,我们要从排序集合中获取到排名最靠前的10个用户–我们称之为“user_scores”,我们只需要像下面一样执行即可:
当然,这是假定你是根据你用户的分数做递增的排序。如果你想返回用户及用户的分数,你需要这样执行:
ZRANGE user_scores 0 10 WITHSCORES
Agora Games就是一个很好的例子,用Ruby实现的,它的排行榜就是使用Redis来存储数据的,你可以在这里看到。
(5)、发布/订阅
最后(但肯定不是最不重要的)是Redis的发布/订阅功能。发布/订阅的使用场景确实非常多。我已看见人们在社交网络连接中使用,还可作为基于发布/订阅的脚本触发器,甚至用Redis的发布/订阅功能来建立聊天系统!(不,这是真的,你可以去核实)。
Redis提供的所有特性中,我感觉这个是喜欢的人最少的一个,虽然它为用户提供如果此多功能。
二、下载和安装
1. windows
在redis官网 http://www.redis.net.cn/download/
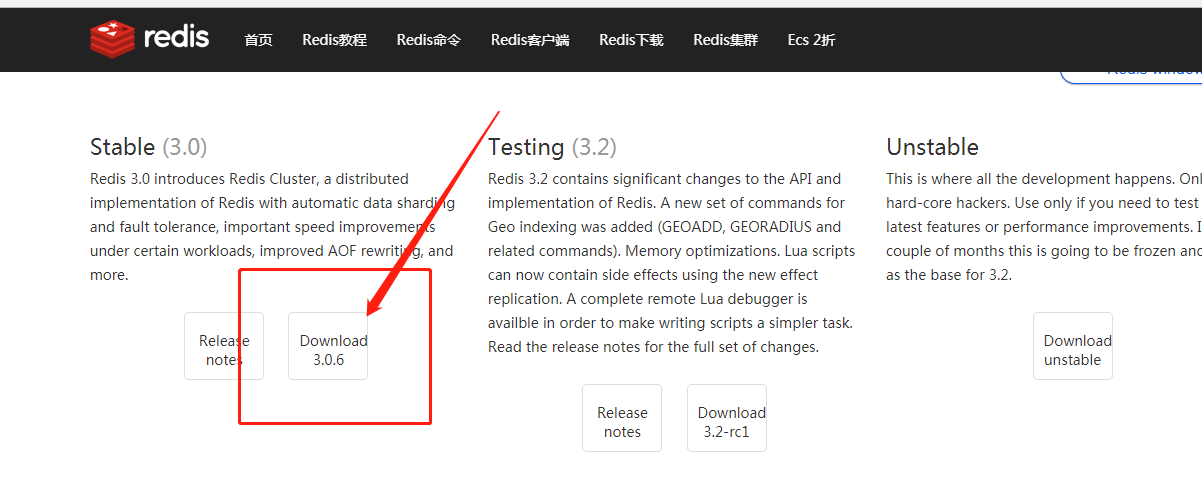
选择对应版本安装即可。
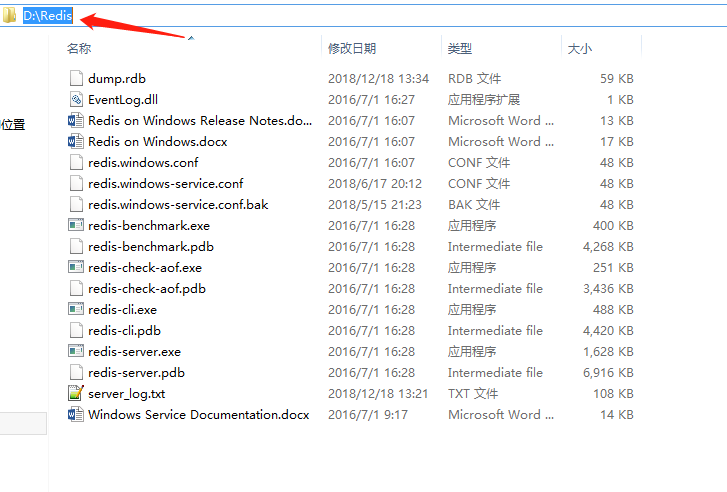
随后把下载文件夹目录添加到环境变量。
修改配置文件
bind 0.0.0.0 port 6379 requirepass 密码
启动服务
启动redis服务
redis-server.exe redis.windows.conf
将redis加入到windows的服务中(service和loglevel前都是两个-)开机自启动
redis-server --service-install redis.windows-service.conf --loglevel verbose
2. linux
下载和安装
yum install redis - redis-server /etc/redis.conf 启动服务器 或者 wget http://download.redis.io/releases/redis-5.0.3.tar.gz tar xzf redis-3.0.6.tar.gz cd redis-3.0.6 make vi redis.conf 修改配置文件 - bind 0.0.0.0 - port 6379 - requirepass 0000
启动服务端
src/redis-server redis.conf
启动客户端
src/redis-cli redis> set foo bar OK redis> get foo "bar"
后台启动服务端
1. 进入 DOS窗口 2. 在进入Redis的安装目录 3. 输入:redis-server --service-install redis.windows.conf --loglevel verbose ( 安装redis服务 ) 4. 输入:redis-server --service-start ( 启动服务 ) 5. 输入:redis-server --service-stop (停止服务)
6. 输入:redis-server --service-uninstall
补充:windows下设置redis允许局域网内部访问
第一步:修改redis.windows.conf
# 大约56行 # bind 127.0.0.1 bind 0.0.0.0 # 大约76行 # protected-mode yes protected-mode no
第二步:重启redis.windows.conf
第三步:关闭防火墙或者设置允许redis通过防火墙
第四步:电脑B访问该计算机redis
redis-cli -h 192.168.0.105 -p 6379
三、启动客户端:redis-cli

redis默认有15个数据库
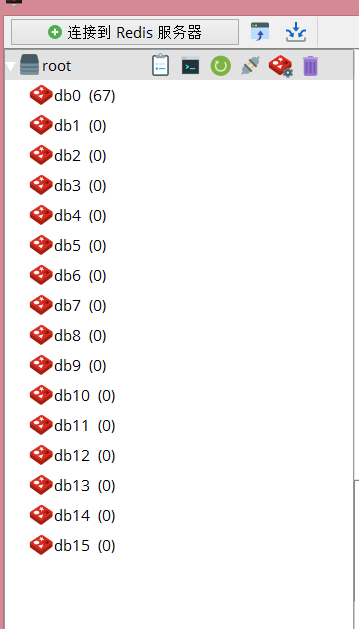
选择1号数据库

四.数据操作
redis是key-value的数据,所以每个数据都是一个键值对。键的类型是字符串。
值的类型分为五种:
- 字符串string
- 哈希hash
- 列表list
- 集合set
- 有序集合zset
1.string
- string是redis最基本的类型
- 最大能存储512MB数据
- string类型是二进制安全的,即可以为任何数据,比如数字、图片、序列化对象等
命令:
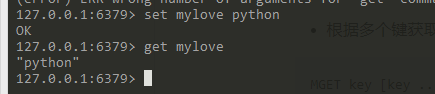
- 设置键值:set key value(单个值),setex key seconds value(设置时间), mset key1 value1 key2 value2 ..(为多个值赋值).
- 获取键值:get key(获取单个值), mget key1 key2(获取多个值)
- 运算:incr,incrby,decr,decrby,append key value, strlen key 要求 value是数字


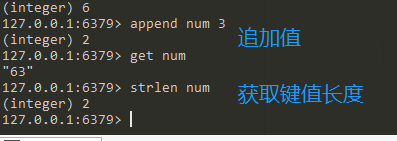
键命令
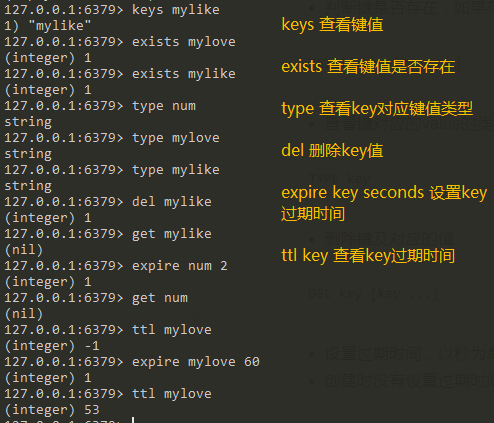
- keys pattern:查看键值 keys * 查看所有键值 keys article*
- exists key:查看键值是否存在
- type key:查看key对应的类型
- del key:删除key
- expire key seconds:设置key过期时间
- ttl key:查看key过期时间
2.hash: 用于存储对象,对象的格式为键值对。
hset key field value: 设置hash key对象指定数据类型的一个值
hmset key field1 value1 filed2 value2 ...:设置hash key对象多个数据类型的值
hget key field:获取指定key的指定数据类型的值
hmget key field1 field2 : 获取key的field1和field中的value
hkeys key : 返回key的field
hlen key:返回key的键值的个数
hvals key:返回key的value
hexists key field: 判断key的field的值是否存在
hdel key filed: 删除key 的field的值
strlen key field: 判断key中field的值的长度
3. list
- 列表的元素类型为string
- 按照插入顺序排序
- 在列表的头部或者尾部添加元素
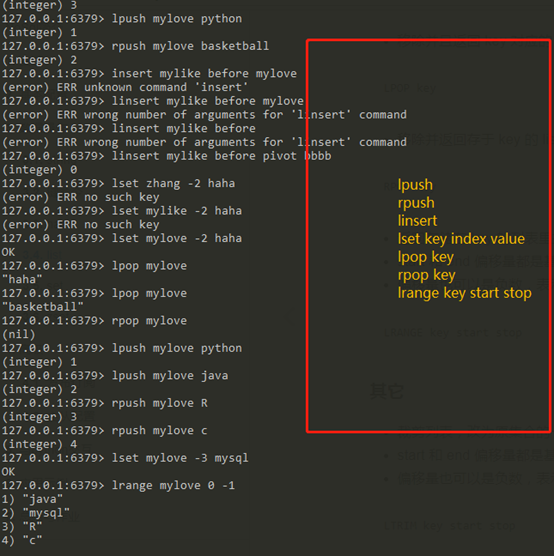
命令:lpush key value: 往列表key的左边插入一个value
rpush key value:往列表key的右边插入一个value
linsert key before|after value new_value:往列表key中value前|后插入new_value
lset key index new_value: 将列表key的第index个value设置为new_value
lpop key:左弹出key列表中的值
rpop key:右弹出key列表中的值
lrange key start end:查看key列表中start-end中的值

4.set
-
- 无序集合
- 元素为string类型
- 元素具有唯一性,不重复
命令:sadd key value : 往无序集合key中插入value值,位置随机
spop key:在无序集合key中随机弹出集合一个值
smembers key:查看无序集合key中的所有元素
scard key:查看无序集合key的值的个数
5.zset
-
- sorted set,有序集合
- 元素为string类型
- 元素具有唯一性,不重复
- 每个元素都会关联一个double类型的score,表示权重,通过权重将元素从小到大排序
- 元素的score可以相同
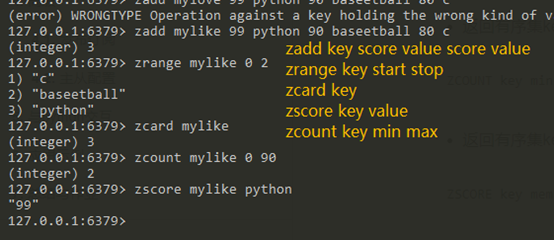
命令:zadd key score1 value1 score2 value2 : 向有序集合key中添加value1,value2并制定相应权重
zrem key value:删除有序集合中的value
zrange key start end:查看有序集合中start-end中的值
zcard key:查看有序集合中元素的个数
zsocre key value:查看有序集合key中value的score
zcount key min max:查看有序集合key中score在min-max之间的元素
五、pipeline
-
1 单操作命令分析
单操作命令操作时间 = 1次网络往返 + 1次命令执行,假如一次get key,那么是单次操作
-
2 批量操作命令分析
如果我们要得到n个key, 如果循环调用get,那么循环操作单次命令时间= n次网络往返+ n次命令执行.
为此,redis中提供了批量操作的命令,如mget, mset,有效的减少RTT网络时间批量操作命令时间 = 1次网络往返 + n 次命令执行
但是,这只支持单类命令的批量操作,如果我要同时发送不同命令,同时操作,怎么办?
这也就出现了pipeline.
-
3 pipeline简介
pipeline 支持同时发送多条不同类型的命令,并一次性得到结果!!!
pipeline操作时间 = 1次网络往返 + n次命令执行
pipeline解决了2中不同同时批量命令操作的问题。
pipeline(流水线)能将一组redis命令进行组装,通过一次RTT传输给redis,再将这组redis命令的执行结果按顺序返回给客户端。
-
4. pipeline的优缺点
优点:
- 可以同时操作多条命令
- 速度快
缺点:
- 命令个数要有节制,不能数据量太大(可能会造成网络拥塞,太多可拆分多个小pipeline)
- 只能操作一个节点,不能同时操作多个节点,在分布式中,要注意使用
六、python连接redis
1. 安装
pip install redis
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类
2. 创建连接
from redis import Redis, ConnectionPool # 创建连接 result = Redis(host='127.0.0.1', port=6379) print(result.keys())
3. 使用连接池
from redis import Redis, ConnectionPool
# 连接池
pool = ConnectionPool(host='127.0.0.1', port=6379)
conn = Redis(connection_pool=pool)
# print(conn.keys())
# print(conn.smembers('visited_urls'))
print(conn.smembers('dupefilter:test_scrapy_redis'))
注意:连接池只创建一次
import redis
# 最简单的单例模式:写一个py文件导入
from redis_pool import POOL
while True:
key = input('请输入key:')
value = input('请输入value:')
# 去连接池中获取连接
conn = redis.Redis(connection_pool=POOL)
# 设置值
conn.set(key, value)
4. 数据操作
- 五大数据类型
redis = {
k1:'123', 字符串
k2:[1,2,3,4,5], 列表
k3:{1,2,3,4}, 集合
k4:{name:'root','age':23}, 字典
k5:{('alex',60),('eva-j',80),('rt',70),},有序集合
}
a.使用字典
- 基本操作
# HASH COMMANDS # 创建字典
# 将字典name的key设置为value hset(self, name, key, value):
# 若字典name的key不存在时将value设置给key,否则不设置 hsetnx(self, name, key, value): hmset(self, name, mapping): # 获取字典的值
# 获取单个key的值 hget(self, name, key):
# 获取多个key的值 hmget(self, name, keys, *args):
# 获取字典name所有的值 hgetall(self, name):
# 获取字典name所有的key hkeys(self, name):
# 获取字典name所有的value hvals(self, name): # 判断某个key是否存在 hexists(self, name, key): # 获取字典name元素的长度 hlen(self, name):
# 获取字典name的指定key的value的长度 hstrlen(self, name, key): # 删除字典的key hdel(self, name, *keys): # 计数器 hincrby(self, name, key, amount=1): hincrbyfloat(self, name, key, amount=1.0): # 性能相关:迭代器 hscan(self, name, cursor=0, match=None, count=None): hscan_iter(self, name, match=None, count=None):


# -*- coding: utf-8 -*- """ @Datetime: 2019/1/25 @Author: Zhang Yafei """ import redis pool = redis.ConnectionPool(host='192.168.137.191', port=6379, password='0000', max_connections=1000) conn = redis.Redis(connection_pool=pool) # 字典 """ redis = { k4:{ 'username': 'zhangyafei', 'age': 23, } } """ # 1. 创建字典 # conn.hset('k4','username','zhangyafei') # conn.hset('k4','age',23) # conn.hsetnx('k4','username','root') # 若key不存在则将value赋值给key, 如果赋值成功则返回1,否则返回0 # conn.hsetnx('k4', 'hobby', 'basketball') # conn.hmset('k4',{'username':'zhangyafei','age':23}) # 2. 获取字典的值 # 获取一个值 val = conn.hget('k4', 'username') # b'zhangyafei' # print(val) # 获取多个值 # vals = conn.mget('k4', ['username','age']) # vals = conn.mget('k4', 'username','age') # {b'username': b'zhangyafei', b'age': b'23'} # 获取所有值 vals = conn.hgetall('k4') # {b'username': b'zhangyafei', b'age': b'23'} print(vals) # 获取长度 lens = conn.hlen('k4') # 2 str_lens = conn.hstrlen('k4', 'username') # 10 keys = conn.hkeys('k4') # [b'username', b'age'] values = conn.hvals('k4') # [b'zhangyafei', b'23'] judge = conn.hexists('k4', 'username') # True # conn.hdel('k4', 'age', 'username') # print(conn.hkeys('k4')) # [] # 计算器 # print(conn.hget('k4', 'age')) # conn.hincrby('k4','age',amount=2) # conn.hincrbyfloat('k4','age',amount=-1.5) # print(conn.hget('k4', 'age')) # 问题:如果redis的k4对应的字典中有1000w条数据,请打印所有数据 # 不可取:redis取到数据之后,服务器内存无法承受,爆栈 # result = conn.hgetall('k4') # print(result) for item in conn.hscan_iter('k4'): print(item)
b. 使用列表
def blpop(self, keys, timeout=0): """ LPOP a value off of the first non-empty list named in the ``keys`` list. If none of the lists in ``keys`` has a value to LPOP, then block for ``timeout`` seconds, or until a value gets pushed on to one of the lists. If timeout is 0, then block indefinitely. """ if timeout is None: timeout = 0 if isinstance(keys, basestring): keys = [keys] else: keys = list(keys) keys.append(timeout) return self.execute_command('BLPOP', *keys) def brpop(self, keys, timeout=0): """ RPOP a value off of the first non-empty list named in the ``keys`` list. If none of the lists in ``keys`` has a value to RPOP, then block for ``timeout`` seconds, or until a value gets pushed on to one of the lists. If timeout is 0, then block indefinitely. """ if timeout is None: timeout = 0 if isinstance(keys, basestring): keys = [keys] else: keys = list(keys) keys.append(timeout) return self.execute_command('BRPOP', *keys) def brpoplpush(self, src, dst, timeout=0): """ Pop a value off the tail of ``src``, push it on the head of ``dst`` and then return it. This command blocks until a value is in ``src`` or until ``timeout`` seconds elapse, whichever is first. A ``timeout`` value of 0 blocks forever. """ if timeout is None: timeout = 0 return self.execute_command('BRPOPLPUSH', src, dst, timeout) def lindex(self, name, index): """ Return the item from list ``name`` at position ``index`` Negative indexes are supported and will return an item at the end of the list """ return self.execute_command('LINDEX', name, index) def linsert(self, name, where, refvalue, value): """ Insert ``value`` in list ``name`` either immediately before or after [``where``] ``refvalue`` Returns the new length of the list on success or -1 if ``refvalue`` is not in the list. """ return self.execute_command('LINSERT', name, where, refvalue, value) def llen(self, name): "Return the length of the list ``name``" return self.execute_command('LLEN', name) def lpop(self, name): "Remove and return the first item of the list ``name``" return self.execute_command('LPOP', name) def lpush(self, name, *values): "Push ``values`` onto the head of the list ``name``" return self.execute_command('LPUSH', name, *values) def lpushx(self, name, value): "Push ``value`` onto the head of the list ``name`` if ``name`` exists" return self.execute_command('LPUSHX', name, value) def lrange(self, name, start, end): """ Return a slice of the list ``name`` between position ``start`` and ``end`` ``start`` and ``end`` can be negative numbers just like Python slicing notation """ return self.execute_command('LRANGE', name, start, end) def lrem(self, name, count, value): """ Remove the first ``count`` occurrences of elements equal to ``value`` from the list stored at ``name``. The count argument influences the operation in the following ways: count > 0: Remove elements equal to value moving from head to tail. count < 0: Remove elements equal to value moving from tail to head. count = 0: Remove all elements equal to value. """ return self.execute_command('LREM', name, count, value) def lset(self, name, index, value): "Set ``position`` of list ``name`` to ``value``" return self.execute_command('LSET', name, index, value) def ltrim(self, name, start, end): """ Trim the list ``name``, removing all values not within the slice between ``start`` and ``end`` ``start`` and ``end`` can be negative numbers just like Python slicing notation """ return self.execute_command('LTRIM', name, start, end) def rpop(self, name): "Remove and return the last item of the list ``name``" return self.execute_command('RPOP', name) def rpoplpush(self, src, dst): """ RPOP a value off of the ``src`` list and atomically LPUSH it on to the ``dst`` list. Returns the value. """ return self.execute_command('RPOPLPUSH', src, dst) def rpush(self, name, *values): "Push ``values`` onto the tail of the list ``name``" return self.execute_command('RPUSH', name, *values) def rpushx(self, name, value): "Push ``value`` onto the tail of the list ``name`` if ``name`` exists" return self.execute_command('RPUSHX', name, value) def sort(self, name, start=None, num=None, by=None, get=None, desc=False, alpha=False, store=None, groups=False): """ Sort and return the list, set or sorted set at ``name``. ``start`` and ``num`` allow for paging through the sorted data ``by`` allows using an external key to weight and sort the items. Use an "*" to indicate where in the key the item value is located ``get`` allows for returning items from external keys rather than the sorted data itself. Use an "*" to indicate where int he key the item value is located ``desc`` allows for reversing the sort ``alpha`` allows for sorting lexicographically rather than numerically ``store`` allows for storing the result of the sort into the key ``store`` ``groups`` if set to True and if ``get`` contains at least two elements, sort will return a list of tuples, each containing the values fetched from the arguments to ``get``. """ if (start is not None and num is None) or \ (num is not None and start is None): raise RedisError("``start`` and ``num`` must both be specified") pieces = [name] if by is not None: pieces.append(Token.get_token('BY')) pieces.append(by) if start is not None and num is not None: pieces.append(Token.get_token('LIMIT')) pieces.append(start) pieces.append(num) if get is not None: # If get is a string assume we want to get a single value. # Otherwise assume it's an interable and we want to get multiple # values. We can't just iterate blindly because strings are # iterable. if isinstance(get, basestring): pieces.append(Token.get_token('GET')) pieces.append(get) else: for g in get: pieces.append(Token.get_token('GET')) pieces.append(g) if desc: pieces.append(Token.get_token('DESC')) if alpha: pieces.append(Token.get_token('ALPHA')) if store is not None: pieces.append(Token.get_token('STORE')) pieces.append(store) if groups: if not get or isinstance(get, basestring) or len(get) < 2: raise DataError('when using "groups" the "get" argument ' 'must be specified and contain at least ' 'two keys') options = {'groups': len(get) if groups else None} return self.execute_command('SORT', *pieces, **options)
# 左插入 conn.lpush('k1', 11) conn.lpush('k1', 22) # 右插入 conn.rpush('k1', 33) # 左获取 val = conn.lpop('k1') val = conn.blpop('k1', timeout=10) # 夯住 # 右获取 val = conn.rpop('k1') val = conn.brpop('k1', timeout=10) # 夯住
conn.blpop()
conn.brpop()
def list_iter(key, count=3): index = 0 while True: data_list = conn.lrange(key, index, index+count-1) if not data_list: return index += count for item in data_list: yield item result = conn.lrange('k1', 0, 100) print(result) # [b'22', b'11', b'33'] for item in list_iter('k1', 3): print(item)
c. 使用字符串
添加 def set(self, name, value, ex=None, px=None, nx=False, xx=False): def append(self, key, value): def mset(self, *args, **kwargs): def msetnx(self, *args, **kwargs): def setex(self, name, value, time): def setnx(self, name, value): 删除 def delete(self, *names): 修改 def setrange(self, name, offset, value): def decr(self, name, amount=1): def incr(self, name, amount=1): def incrbyfloat(self, name, amount=1.0): def expire(self, name, time): 查询 def mget(self, keys, *args): def exists(self, name): def get(self, name): def getrange(self, key, start, end): def getset(self, name, value): def keys(self, pattern='*'): def strlen(self, name):
# -*- coding: utf-8 -*- """ @Datetime: 2019/2/1 @Author: Zhang Yafei """ import redis pool = redis.ConnectionPool(host='127.0.0.1', port=6379, password='0000', max_connections=1000) conn = redis.Redis(connection_pool=pool) # 添加 conn.set('str_k', 'hello') # 为指定key设置value # {'str_k':'hello'} conn.mset({'str_k':'hello','str_k1':'world'}) # 设置多个key/value # {'str_k':'hello', 'str_k1':'world'} conn.msetnx({'str_k':'msetnx_hello'}) # 若当前key未设定, 则基于mapping设置key/value,结果返回True或False # {'str_k':'hello'} conn.setex('str_k2', 'str_v2', 2) # 秒 conn.decr('num', amount=1) conn.incr('num', amount=1) conn.incrbyfloat('num', amount='1.5') # 删除 conn.delete('str_k1') # 修改 conn.append('str_k', ' world') # 为指定key添加value # {'str_k':'hello world'} conn.setrange('str_k', 5, 'world') # 在key对应的的value指定位置上设置值 # b'helloworld' # 查询 print(conn.get('str_k')) print(conn.get('num')) print(conn.getrange('str_k', 0, 100)) print(conn.keys()) print(conn.strlen('str_k')) # 长度 print(conn.exists('str_k')) conn.expire('str_k1', 5) print(conn.get('str_k1')) # 添加并查询 print(conn.getset('str_k2', 'str_v2')) # b'str_v2'
d. 集合
添加 def sadd(self, name, *values): 删除 def spop(self, name): def srem(self, name, *values): 修改 def smove(self, src, dst, value): 查询 # 判断value是否在key的value中 def sismember(self, name, value): # 取出key为name的所有元素 def smembers(self, name): # 随机取出key为name的指定个数元素 def srandmember(self, name, number=None): # 元素个数 def scard(self, name): # 差集 def sdiff(self, keys, *args): def sdiffstore(self, dest, keys, *args): # 交集 def sinter(self, keys, *args): def sinterstore(self, dest, keys, *args): # 并集 def sunion(self, keys, *args): def sunionstore(self, dest, keys, *args):
# -*- coding: utf-8 -*- """ @Datetime: 2019/2/1 @Author: Zhang Yafei """ import redis pool = redis.ConnectionPool(host='127.0.0.1', port=6379, password='0000', max_connections=1000) conn = redis.Redis(connection_pool=pool) """ { 'set_k':{v1,v2,v3}, } """ # 添加 # conn.sadd('set_k', 3, 4, 5, 6) # conn.sadd('set_k1', 3, 4, 5, 6) # 删除 # print(conn.spop('set_k')) # conn.srem('set_k', 2) # 修改 # conn.smove('set_k', 'set_k1', 1) # 查询 print(conn.smembers('set_k')) print(conn.smembers('set_k1')) # print(conn.srandmember('set_k', 3)) # print(conn.scard('set_k')) # print(conn.sismember('set_k', 2)) print(conn.sdiff('set_k','set_k1')) # 集合之差 conn.sdiffstore('set_k_k1', 'set_k', 'set_k1') print(conn.smembers('set_k_k1')) print(conn.sinter('set_k', 'set_k1')) # 集合交集 conn.sinterstore('set_k_k1_inter', 'set_k', 'set_k1') print(conn.smembers('set_k_k1_inter')) print(conn.sunion('set_k', 'set_k1')) # 集合并集 conn.sunionstore('set_k_k1_union', 'set_k', 'set_k1') print(conn.smembers('set_k_k1_union'))
e. 有序集合
添加 def zadd(self, name, *args, **kwargs): 删除 def zrem(self, name, *values): def zremrangebyrank(self, name, min, max): # 删除等级最大者 def zremrangebyscore(self, name, min, max): # 删除分数最小者 查询 # 查询start-end个数,按分数从小到大 def zrange(self, name, start, end, desc=False, withscores=False, score_cast_func=float): # 查询分数在Min,max之间的元素 def zrangebyscore(self, name, min, max, start=None, num=None, withscores=False, score_cast_func=float): def zrank(self, name, value): # 等级 def zcard(self, name): # 个数 def zscore(self, name, value): # 得分 def zrevrange(self, name, start, end, withscores=False, score_cast_func=float): # 逆序:分数从大到小排序 def zrevrangebyscore(self, name, max, min, start=None, num=None, withscores=False, score_cast_func=float): # 分数处于Min,max之间的从大到小排序
# -*- coding: utf-8 -*- """ @Datetime: 2019/2/1 @Author: Zhang Yafei """ import redis pool = redis.ConnectionPool(host='127.0.0.1', port=6379, password='0000', max_connections=1000) conn = redis.Redis(connection_pool=pool) """ { 'set_k':{ {v1: score1}, {v2: score2}, {v3: score3}, }, } """ # # 添加 # conn.zadd('zset_k', 'math', 99, 'english', 80, 'chinese', 85, 'sport', 100, 'music', 60) # # # 删除 # conn.zrem('zset_k', 'music') # conn.zremrangebyrank('zset_k', 0, 0) # 按等级大小删除, 删除等级在第min-max个值 # conn.zremrangebyscore('zset_k', 0, 90) # 按分数范围删除, Min < x < max之间的删除 # 查询 print(conn.zrange('zset_k', 0, 100)) print(conn.zrevrange('zset_k', 0, 100)) # score从小到大排序, 默认小值先出, 广度优先 results = conn.zrangebyscore('zset_k', 0, 100) print(results) print(conn.zcard('zset_k')) print(conn.zcount('zset_k', 0, 90)) print(conn.zrank('zset_k', 'chinese')) print(conn.zscore('zset_k', 'chinese')) print(conn.zrange('zset_k', 0, 100))
七、基于redis实现队列和栈
# -*- coding: utf-8 -*- """ @Datetime: 2019/1/8 @Author: Zhang Yafei """ import redis class FifoQueue(object): def __init__(self): """ 先进先出队列:利用redis中的列表,双端队列改为先进先出队列 """ self.server = redis.Redis(host='127.0.0.1', port=6379) def push(self, request): """Push a request""" self.server.lpush('USERS', request) def pop(self, timeout=0): """Pop a request""" data = self.server.rpop('USERS') return data if __name__ == '__main__': q = FifoQueue() q.push(11) q.push(22) q.push(33) print(q.pop()) print(q.pop()) print(q.pop())
# -*- coding: utf-8 -*- """ @Datetime: 2019/1/8 @Author: Zhang Yafei """ import redis class LifoQueue(object): """Per-spider LIFO queue.""" def __init__(self): self.server = redis.Redis(host='127.0.0.1', port=6379) def push(self, request): """Push a request""" self.server.lpush("USERS", request) def pop(self, timeout=0): """Pop a request""" data = self.server.lpop('USERS') return data if __name__ == '__main__': q = LifoQueue() q.push(11) q.push(22) q.push(33) print(q.pop()) print(q.pop()) print(q.pop())
# -*- coding: utf-8 -*- """ @Datetime: 2019/1/8 @Author: Zhang Yafei """ import redis class PriorityQueue(object): """Per-spider priority queue abstraction using redis' sorted set""" def __init__(self): self.server = redis.Redis(host='127.0.0.1', port=6379) def push(self, request,score): """Push a request""" # data = self._encode_request(request) # score = -request.priority # We don't use zadd method as the order of arguments change depending on # whether the class is Redis or StrictRedis, and the option of using # kwargs only accepts strings, not bytes. self.server.execute_command('ZADD', 'xxxxxx', score, request) def pop(self, timeout=0): """ Pop a request timeout not support in this queue class """ # use atomic range/remove using multi/exec pipe = self.server.pipeline() pipe.multi() pipe.zrange('xxxxxx', 0, 0).zremrangebyrank('xxxxxx', 0, 0) results, count = pipe.execute() if results: return results[0] if __name__ == '__main__': q = PriorityQueue() # q.push('alex',99) # 广度优先:分值小的优先 # q.push('oldboy',56) # q.push('eric',77) q.push('alex',-99) # 深度优先:分值大的优先 q.push('oldboy',-56) q.push('eric',-77) v1 = q.pop() print(v1) v2 = q.pop() print(v2) v3 = q.pop() print(v3)
# -*- coding: utf-8 -*- """ @Datetime: 2019/1/8 @Author: Zhang Yafei """ from scrapy_redis import queue import redis conn = redis.Redis(host='127.0.0.1', port=6379) conn.zadd('score',alex=79, oldboy=33,eric=73) # print(conn.keys()) v = conn.zrange('score',0,8,desc=True) print(v) pipe = conn.pipeline() pipe.multi() pipe.zrange("score", 0, 0).zremrangebyrank('score', 0, 0) results, count = pipe.execute() print(results,count)
八、Django应用
1.自定义使用redis
import redis POOL = redis.ConnectionPool(host='127.0.0.1', port=6379, max_connections=1000)
from django.shortcuts import render, HttpResponse from app01.utils.redis_pool import POOL from redis import Redis def index(request): conn = Redis(connection_pool=POOL) conn.hset('kkk', 'age', 18) return HttpResponse('设置成功') def order(request): conn = Redis(connection_pool=POOL) val = conn.hget('kkk','age') return HttpResponse('获取成功{}'.format(val))
2.使用第三方组件
pip install django-redis
CACHES = { "default": { "BACKEND": "django_redis.cache.RedisCache", "LOCATION": "redis://127.0.0.1:6379", "OPTIONS": { "CLIENT_CLASS": "django_redis.client.DefaultClient", "CONNECTION_POOL_KWARGS": {"max_connections": 100}, # "PASSWORD": "密码", } }, "back": { "BACKEND": "django_redis.cache.RedisCache", "LOCATION": "redis://192.168.137.191:6379", "OPTIONS": { "CLIENT_CLASS": "django_redis.client.DefaultClient", "CONNECTION_POOL_KWARGS": {"max_connections": 100}, "PASSWORD": "0000", } }, }
from django.shortcuts import render,HttpResponse from django_redis import get_redis_connection def index(request): conn = get_redis_connection('back') conn.hset('kkk', 'age', 18) return HttpResponse('设置成功') def order(request): conn = get_redis_connection('back') val = conn.hget('kkk','age') return HttpResponse('获取成功{}'.format(val))
3.高级使用
a. 全站缓存
使用中间件,经过一系列的认证等操作,如果内容在缓存中存在,则使用FetchFromCacheMiddleware获取内容并返回给用户,当返回给用户之前,判断缓存中是否已经存在,如果不存在则UpdateCacheMiddleware会将缓存保存至缓存,从而实现全站缓存
MIDDLEWARE = [ 'django.middleware.cache.UpdateCacheMiddleware', # 其他中间件... 'django.middleware.cache.FetchFromCacheMiddleware', ] CACHE_MIDDLEWARE_ALIAS = "" CACHE_MIDDLEWARE_SECONDS = "" CACHE_MIDDLEWARE_KEY_PREFIX = ""
b.单视图
from django.views.decorators.cache import cache_page
@cache_page(60 * 15)
def index(request):
# conn = Redis(connection_pool=POOL)
conn = get_redis_connection('back')
conn.hset('kkk', 'age', 18)
return HttpResponse('设置成功')
c,局部页面缓存
<body>
<h1>asdfasdfasdf</h1>
<div>
asdf
</div>
{# 将指定局部页面放到缓存中的key中#}
{% cache 5000 key %}
<div></div>
{% endcache %}
</body>
# 缓存放在redis配置 CACHES = { "default": { "BACKEND": "django_redis.cache.RedisCache", "LOCATION": "redis://127.0.0.1:6379", "OPTIONS": { "CLIENT_CLASS": "django_redis.client.DefaultClient", "CONNECTION_POOL_KWARGS": {"max_connections": 100}, # "PASSWORD": "密码", } }, } # 缓存放在文件 CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.filebased.FileBasedCache', 'LOCATION': '/var/tmp/django_cache', } } # 缓存放在MemcachedCache CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache', 'LOCATION': '127.0.0.1:11211', } }
更多详细内容请见
官方教程:http://www.redis.net.cn/tutorial/3501.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号