
数据科学之路
今天啊,咱们来做一个案例,Kaggle对它的用户关于数据科学方面的一些信息做的一个调查。
首先,我们来看一下这些调查信息包括哪些东西?
数据科学之路~

(一)数据领域的兄弟们的自身情况
- 性别比例
- 调查问卷国家分布
- 年龄分布
- 收入情况
- 所学专业
- 从事领域
- 工作满意度
- 最常使用工具
- 常用算法
- 计算平台选择
- 面临挑战
(二)Python和R哪家强

- 使用人数
- 常用工具
- 不同工种偏好
- 各大领域使用趋势
- 薪资待遇
- 用了多少年
- 重要程度
(三)数据科学家都在用什么
- 国家分布
- 使用Python or R
- 工资与学历
- 如何证明自己呢
- 遇到的问题
- 对可视化的重要程度
- 求职的途径
- 前一份工作和现在的对比
引入使用的包
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt plt.style.use('fivethirtyeight') import warnings warnings.filterwarnings('ignore') import numpy as np import plotly.offline as py py.init_notebook_mode(connected=True) import plotly.graph_objs as go import plotly.tools as tls import base64 import io from scipy.misc import imread import codecs from IPython.display import HTML
看看数据是什么样子
response=pd.read_csv('multipleChoiceResponses.csv',encoding='ISO-8859-1') response.head()
GenderSelect Country Age EmploymentStatus StudentStatus LearningDataScience CodeWriter CareerSwitcher CurrentJobTitleSelect TitleFit ... JobFactorExperienceLevel JobFactorDepartment JobFactorTitle JobFactorCompanyFunding JobFactorImpact JobFactorRemote JobFactorIndustry JobFactorLeaderReputation JobFactorDiversity JobFactorPublishingOpportunity 0 Non-binary, genderqueer, or gender non-conforming NaN NaN Employed full-time NaN NaN Yes NaN DBA/Database Engineer Fine ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 1 Female United States 30.0 Not employed, but looking for work NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN Somewhat important NaN NaN 2 Male Canada 28.0 Not employed, but looking for work NaN NaN NaN NaN NaN NaN ... Very Important Very Important Very Important Very Important Very Important Very Important Very Important Very Important Very Important Very Important 3 Male United States 56.0 Independent contractor, freelancer, or self-em... NaN NaN Yes NaN Operations Research Practitioner Poorly ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 4 Male Taiwan 38.0 Employed full-time NaN NaN Yes NaN Computer Scientist Fine ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
5 rows × 228 columns
列数有点多啊!看看整体情况吧!
print('调查对象总数',response.shape[0]) print('一共多少个国家参与了调查:',response['Country'].nunique()) print('参与人数最多的国家是',response['Country'].value_counts().index[0],'人数',response['Country'].value_counts().values[0]) print('最小的选手:',response['Age'].min(),' 最大的选手:',response['Age'].max())
调查对象总数 16716 一共多少个国家参与了调查: 52 参与人数最多的国家是 United States 人数 4197 最小的选手: 0.0 最大的选手: 100.0
我的天!居然最小年龄0岁,最大年龄100,肯定有瞎填的用户,这数据咱们只能信一半啦,哈哈!
看看性别的分布把吧!
import matplotlib matplotlib.rcParams.update({'font.size': 25}) plt.subplots(figsize=(22,12)) sns.countplot(y=response['GenderSelect'],order=response['GenderSelect'].value_counts().index) plt.show()
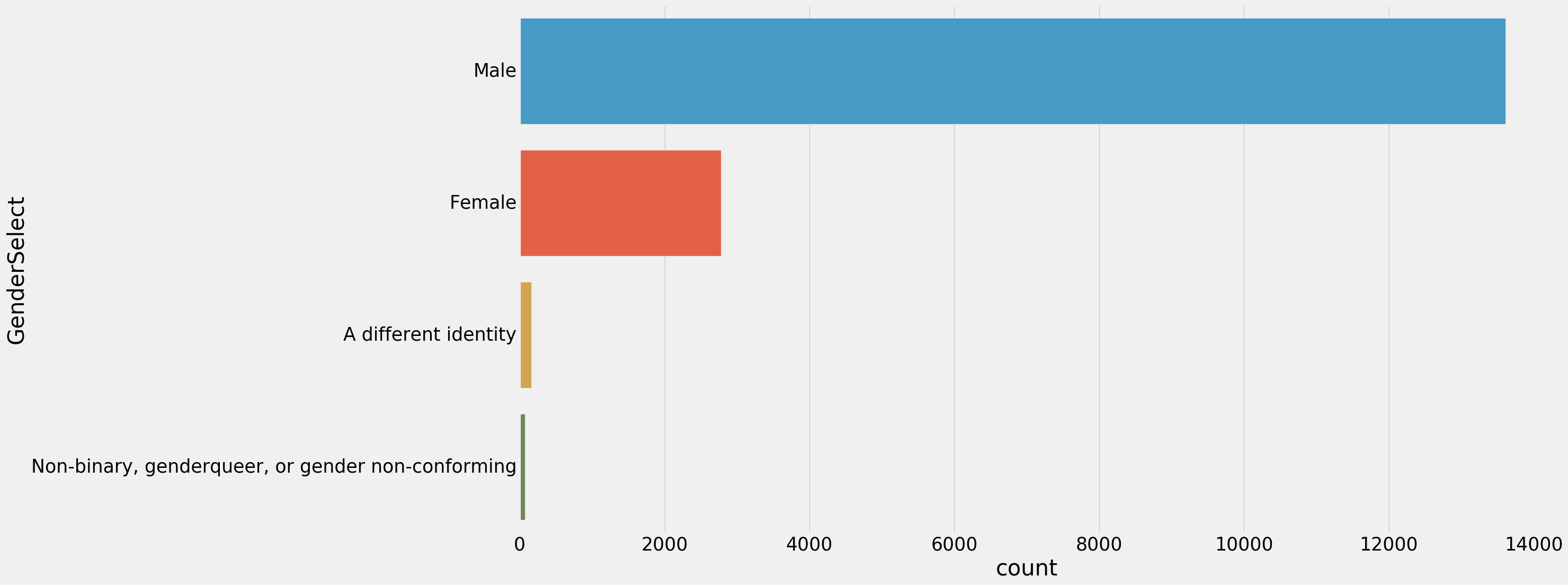
和我们想的差不多,男的占大多数!
看看排名最多的前十五个国家
resp_coun=response['Country'].value_counts()[:15].to_frame() sns.barplot(resp_coun['Country'],resp_coun.index,palette='inferno') plt.title('Top 15 Countries by number of respondents') plt.xlabel('') fig=plt.gcf()#获取当前图表对象 fig.set_size_inches(10,10)#设置尺寸大小 plt.show()
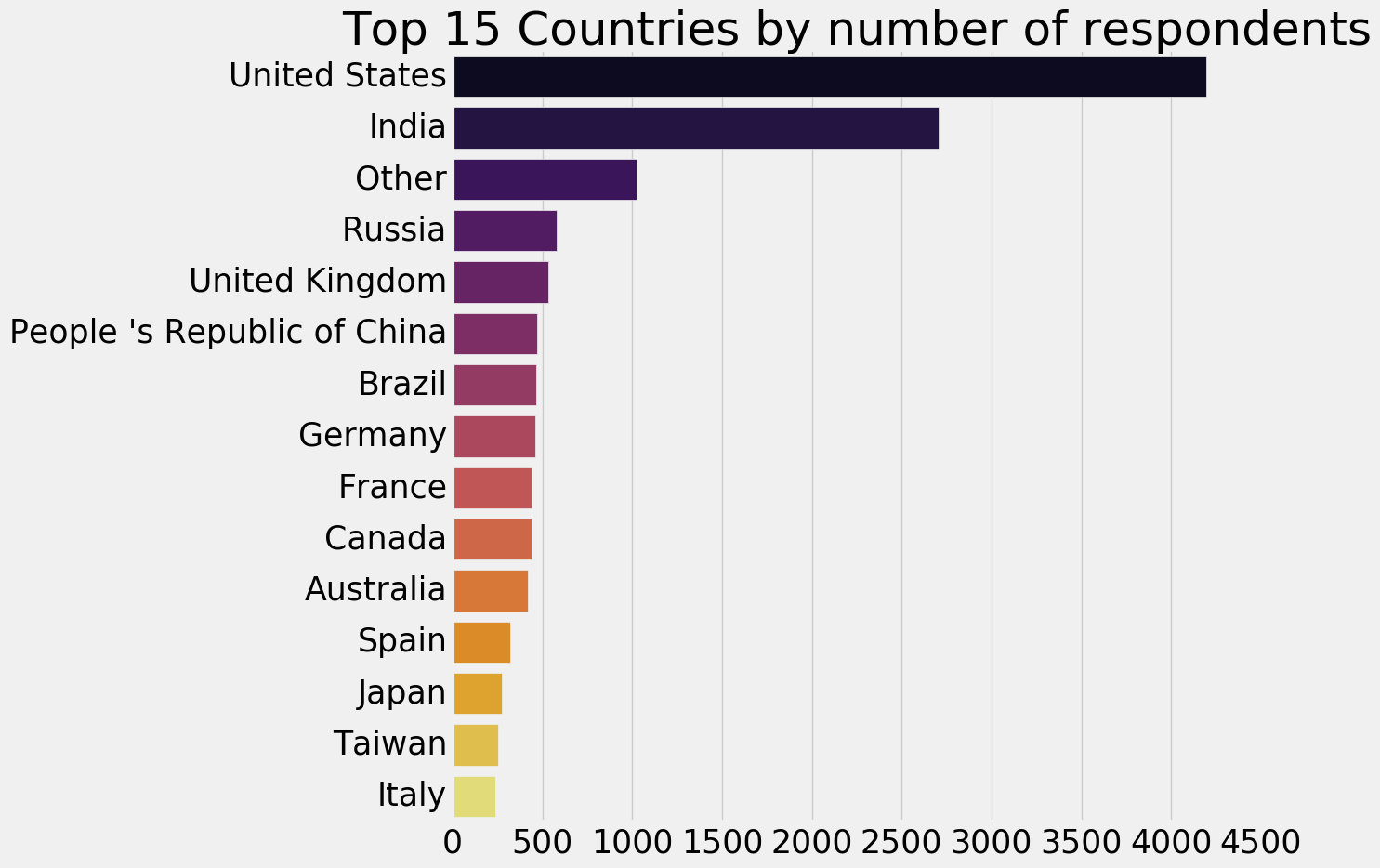
中国第六,你看到了吗?估计都在看论文,没时间来这吧。
看看各国的收入情况呗!
有些收入的写法比较特别 response['CompensationAmount']=response['CompensationAmount'].str.replace(',','') response['CompensationAmount']=response['CompensationAmount'].str.replace('-','') rates=pd.read_csv('conversionRates.csv') rates.head()

rates.drop('Unnamed: 0',axis=1,inplace=True) salary=response[['CompensationAmount','CompensationCurrency','GenderSelect','Country','CurrentJobTitleSelect']].dropna() salary.head()
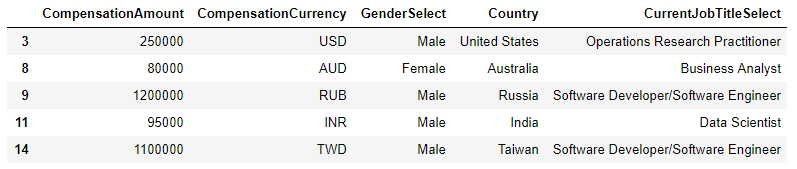
salary=salary.merge(rates,left_on='CompensationCurrency',right_on='originCountry',how='left') salary.head()

salary['Salary']=pd.to_numeric(salary['CompensationAmount'])*salary['exchangeRate'] print('Maximum Salary is USD $',salary['Salary'].dropna().astype(int).max()) print('Minimum Salary is USD $',salary['Salary'].dropna().astype(int).min()) print('Median Salary is USD $',salary['Salary'].dropna().astype(int).median())
aximum Salary is USD $ 208999999 Minimum Salary is USD $ -2147483648 Median Salary is USD $ 53812.0
看平均就好了,这个收入应该还不错吧。这最高工资谁写的?比阿富汗的GDP还高吧。。。
plt.subplots(figsize=(15,8)) salary=salary[salary['Salary']<1000000] sns.distplot(salary['Salary']) plt.title('Salary Distribution',size=15) plt.show()
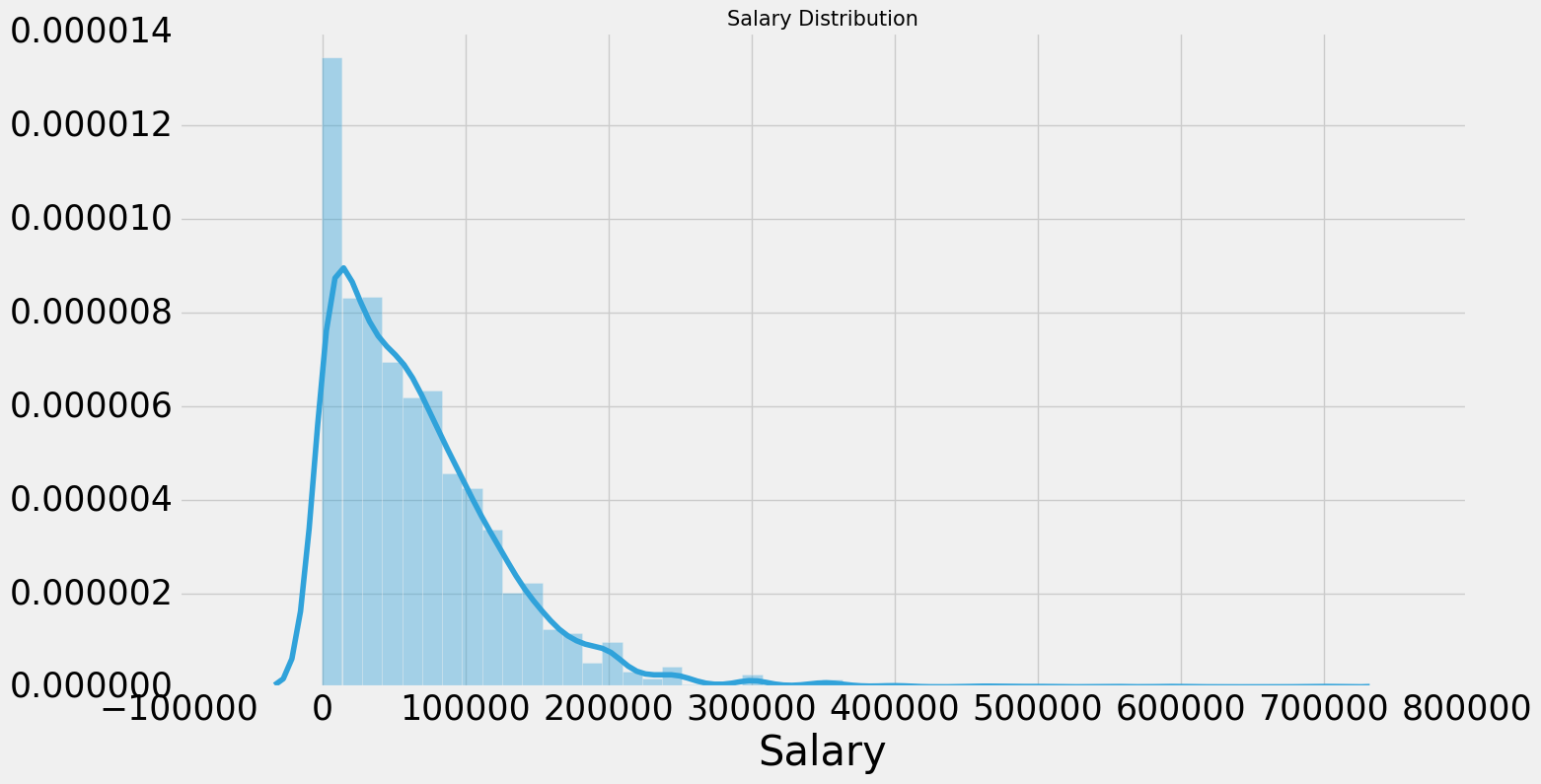
f,ax=plt.subplots(1,2,figsize=(28,8)) sal_coun=salary.groupby('Country')['Salary'].median().sort_values(ascending=False)[:15].to_frame() sns.barplot('Salary',sal_coun.index,data=sal_coun,palette='RdYlGn',ax=ax[0]) ax[0].axvline(salary['Salary'].median(),linestyle='dashed') ax[0].set_title('Highest Salary Paying Countries') ax[0].set_xlabel('') max_coun=salary.groupby('Country')['Salary'].median().to_frame() max_coun=max_coun[max_coun.index.isin(resp_coun.index)] max_coun.sort_values(by='Salary',ascending=True).plot.barh(width=0.8,ax=ax[1],color=sns.color_palette('RdYlGn')) ax[1].axvline(salary['Salary'].median(),linestyle='dashed') ax[1].set_title('Compensation of Top 15 Respondent Countries') ax[1].set_xlabel('') ax[1].set_ylabel('') plt.subplots_adjust(wspace=0.8) plt.show()
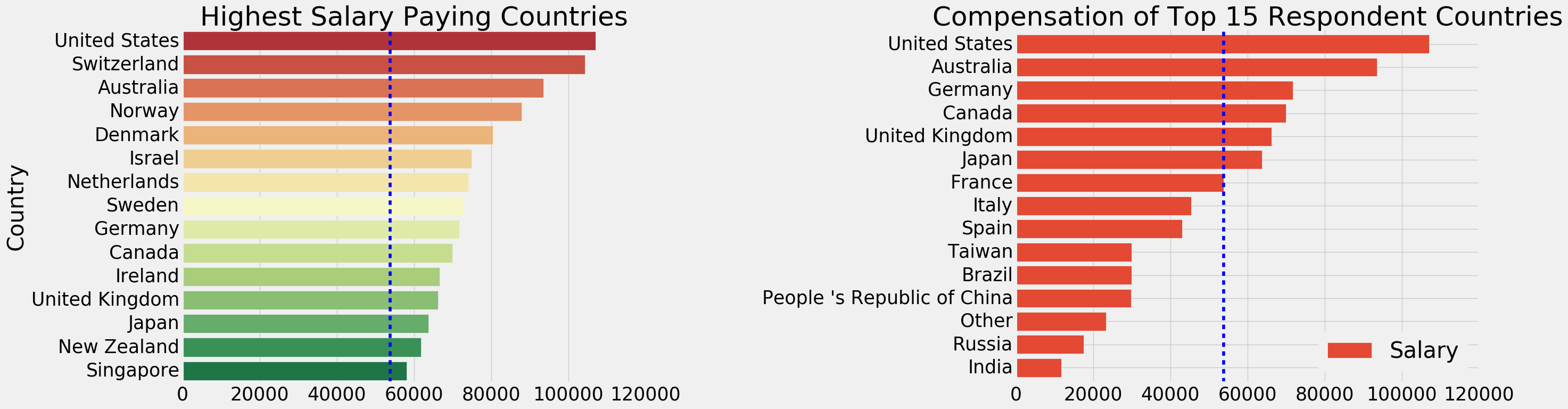
竖条的那个是整体的中位数,左边的图中工资排名前15的国家都超过中位数了,右边的图是参与人数最多的15个国家的情况,中国的薪资还是有点低啊
Python vs R or (Batman vs Superman)
Python和R是用于数据科学和机器学习的最广泛使用的开源语言。对于一个初露头角的数据科学家或分析师,最大和最棘手的疑问是:我的语言开始?虽然两种语言都有各自的优点和缺点,但在选择自己的语言时,这取决于个人的目的。这两种语言都能满足各种不同工作的需要。Python是一种通用的语言,因此,Web和应用集成更容易,而R是为了纯粹的统计和分析的目的。
(PHP是世界上最好的语言。。。)
resp=response.dropna(subset=['WorkToolsSelect']) resp=resp.merge(rates,left_on='CompensationCurrency',right_on='originCountry',how='left') python=resp[(resp['WorkToolsSelect'].str.contains('Python'))&(~resp['WorkToolsSelect'].str.contains('R'))] R=resp[(~resp['WorkToolsSelect'].str.contains('Python'))&(resp['WorkToolsSelect'].str.contains('R'))] both=resp[(resp['WorkToolsSelect'].str.contains('Python'))&(resp['WorkToolsSelect'].str.contains('R'))] response['LanguageRecommendationSelect'].value_counts()[:2].plot.bar() plt.show()
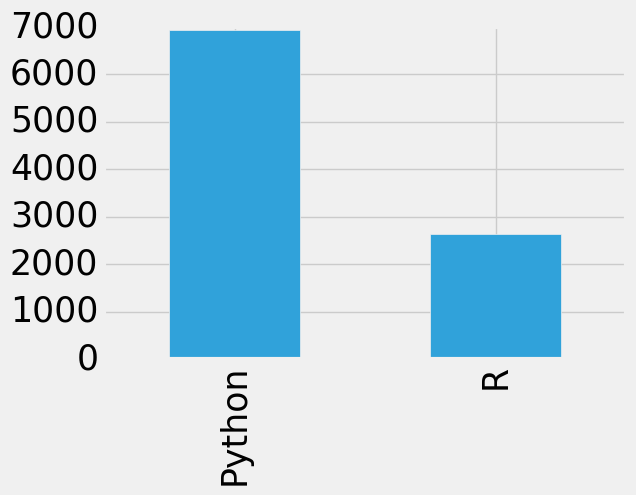
有多大用,看看大家咋说的吧!
f,ax=plt.subplots(1,2,figsize=(18,8)) response['JobSkillImportancePython'].value_counts().plot.pie(ax=ax[0],autopct='%1.1f%%',explode=[0.1,0,0],shadow=True,colors=['g','lightblue','r']) ax[0].set_title('Python Necessity') ax[0].set_ylabel('') response['JobSkillImportanceR'].value_counts().plot.pie(ax=ax[1],autopct='%1.1f%%',explode=[0,0.1,0],shadow=True,colors=['lightblue','g','r']) ax[1].set_title('R Necessity') ax[1].set_ylabel('') plt.show()
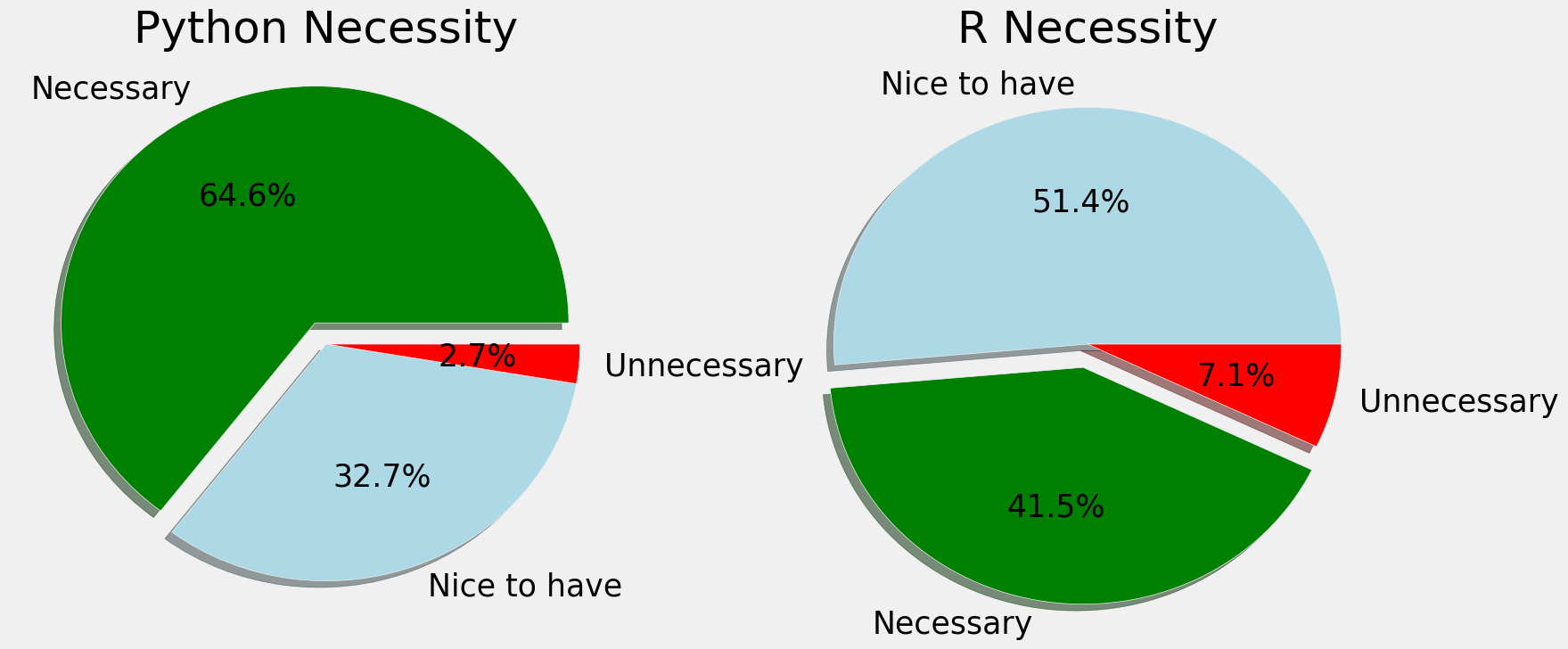
from matplotlib_venn import venn2 # pip install matplotlib_venn 画交集用的 f,ax=plt.subplots(1,2,figsize=(18,8)) pd.Series([python.shape[0],R.shape[0],both.shape[0]],index=['Python','R','Both']).plot.bar(ax=ax[0]) ax[0].set_title('Number of Users') venn2(subsets = (python.shape[0],R.shape[0],both.shape[0]), set_labels = ('Python Users', 'R Users')) plt.title('Venn Diagram for Users') plt.show()
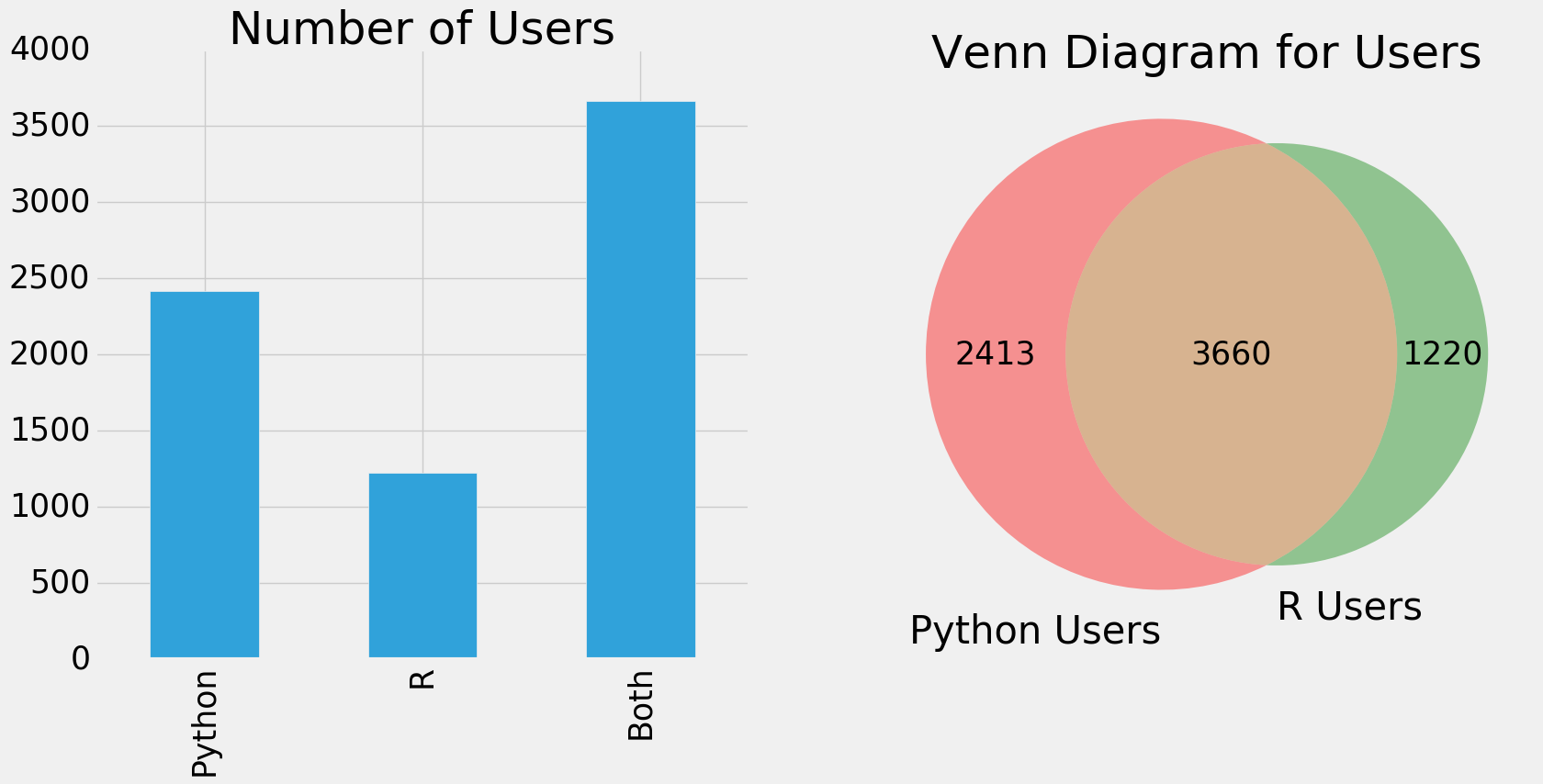
看来有这么多高手是通杀啊!
高手的薪资会不会更高呢!
py_sal=(pd.to_numeric(python['CompensationAmount'].dropna())*python['exchangeRate']).dropna() py_sal=py_sal[py_sal<1000000] R_sal=(pd.to_numeric(R['CompensationAmount'].dropna())*R['exchangeRate']).dropna() R_sal=R_sal[R_sal<1000000] both_sal=(pd.to_numeric(both['CompensationAmount'].dropna())*both['exchangeRate']).dropna() both_sal=both_sal[both_sal<1000000] trying=pd.DataFrame([py_sal,R_sal,both_sal]) trying=trying.transpose() trying.columns=['Python','R','Both'] print('Median Salary For Individual using Python:',trying['Python'].median()) print('Median Salary For Individual using R:',trying['R'].median()) print('Median Salary For Individual knowing both languages:',trying['Both'].median())
不同工种的偏好!
py1=python.copy() r=R.copy() py1['WorkToolsSelect']='Python' r['WorkToolsSelect']='R' r_vs_py=pd.concat([py1,r]) r_vs_py=r_vs_py.groupby(['CurrentJobTitleSelect','WorkToolsSelect'])['Age'].count().to_frame().reset_index() r_vs_py.pivot('CurrentJobTitleSelect','WorkToolsSelect','Age').plot.barh(width=0.8) fig=plt.gcf() fig.set_size_inches(10,15) plt.title('Job Title vs Language Used',size=15) plt.show()
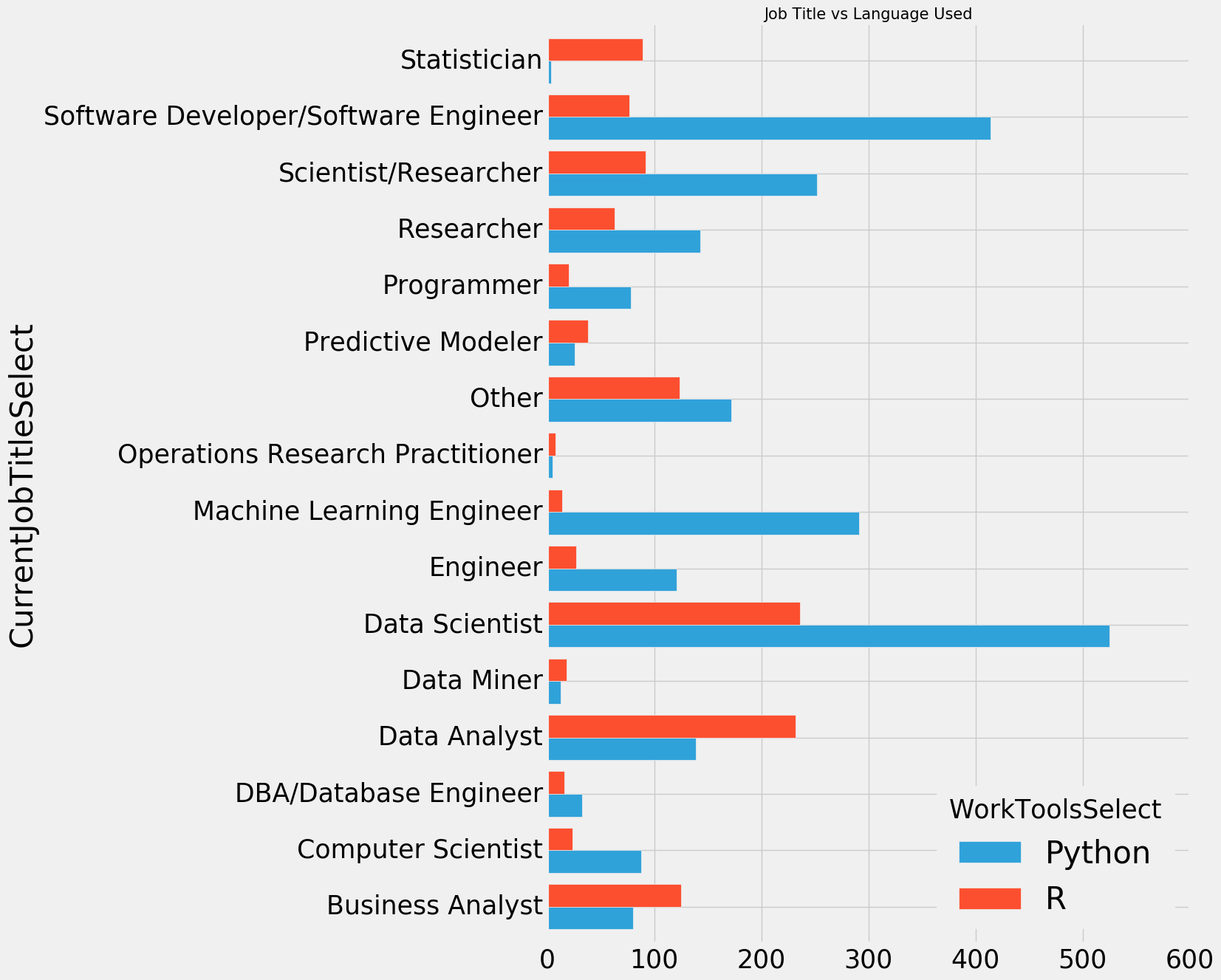
r在视觉上胜过Python。因此,拥有诸如数据分析师、业务分析师等职位头衔的人在图形和视觉上扮演着非常重要的角色,他们喜欢R而不是Python。同样,几乎90%的统计人员使用R,正如前面所述,Python在机器学习方面更好,因此机器学习工程师、数据科学家和DBA或程序员等其他人更喜欢Python。
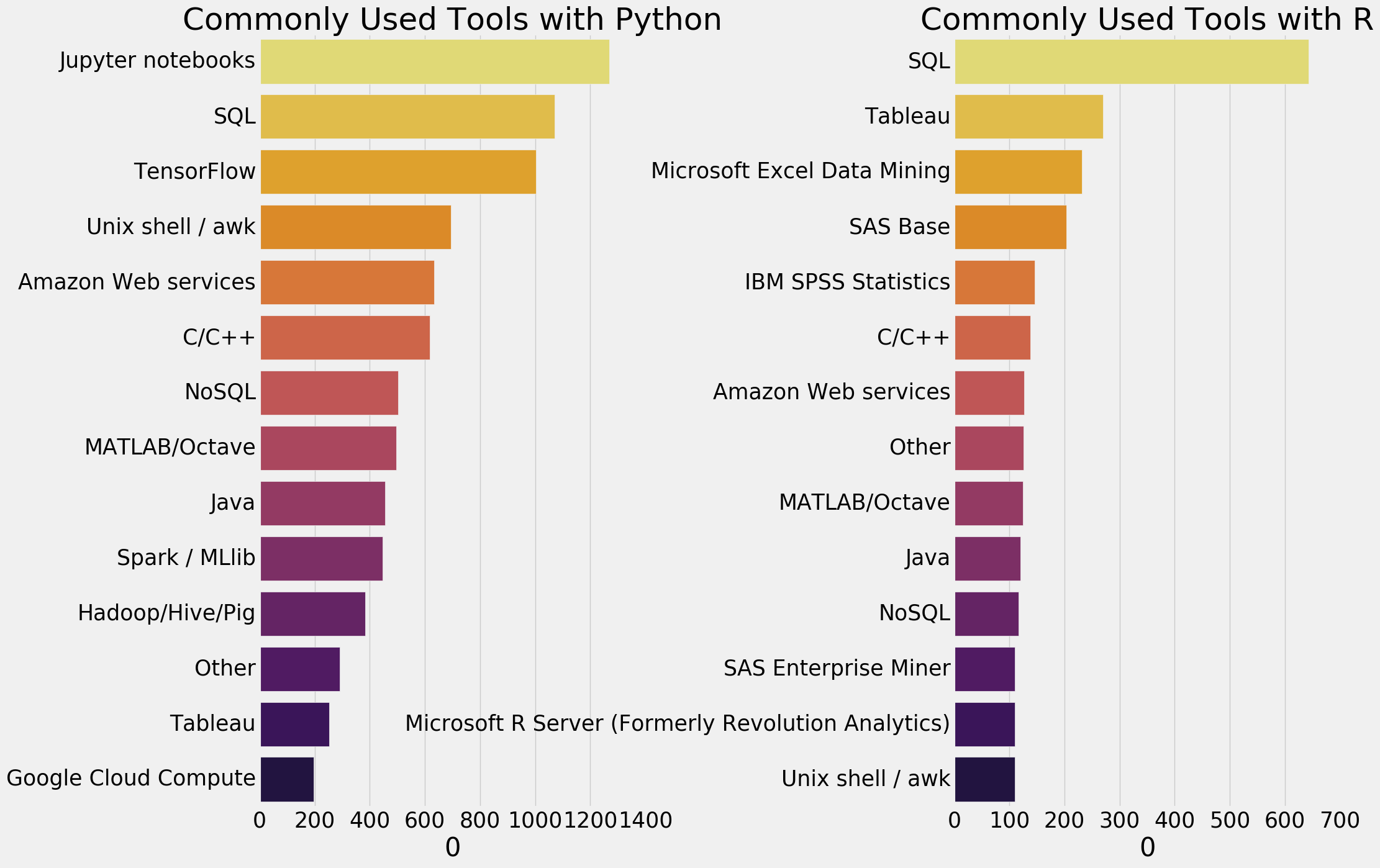
Python和R最常用的额工具是什么呢?
f,ax=plt.subplots(1,2,figsize=(20,15)) py_comp=python['WorkToolsSelect'].str.split(',') py_comp1=[] for i in py_comp: py_comp1.extend(i) plt1=pd.Series(py_comp1).value_counts()[1:15].sort_values(ascending=False).to_frame() sns.barplot(plt1[0],plt1.index,ax=ax[0],palette=sns.color_palette('inferno_r',15)) R_comp=R['WorkToolsSelect'].str.split(',') R_comp1=[] for i in R_comp: R_comp1.extend(i) plt1=pd.Series(R_comp1).value_counts()[1:15].sort_values(ascending=False).to_frame() sns.barplot(plt1[0],plt1.index,ax=ax[1],palette=sns.color_palette('inferno_r',15)) ax[0].set_title('Commonly Used Tools with Python') ax[1].set_title('Commonly Used Tools with R') plt.subplots_adjust(wspace=0.8) plt.show()
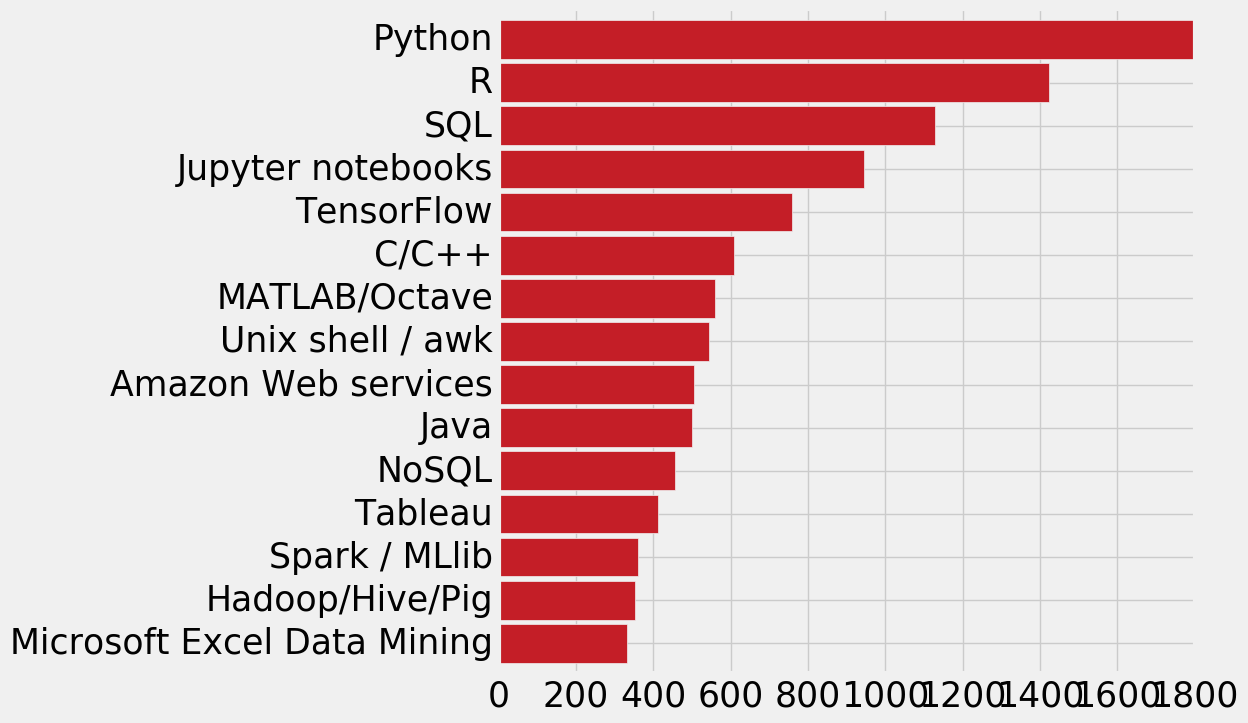
数据科学家都用什么?
plt.subplots(figsize=(8,8)) tools=scientist['WorkToolsSelect'].str.split(',') tools_work=[] for i in tools.dropna(): tools_work.extend(i) pd.Series(tools_work).value_counts()[:15].sort_values(ascending=True).plot.barh(width=0.9,color=sns.color_palette('RdYlGn',15)) plt.show()
Python和R中最常用的额是什么?
import nltk from nltk.corpus import stopwords stop_words=set(stopwords.words('english')) stop_words.update(',',';','!','?','.','(',')','$','#','+',':','...') free=pd.read_csv('freeformResponses.csv',encoding='ISO-8859-1') library=free['WorkLibrariesFreeForm'].dropna().apply(nltk.word_tokenize) lib=[] for i in library: lib.extend(i) lib=pd.Series(lib) lib=([i for i in lib.str.lower() if i not in stop_words]) lib=pd.Series(lib) lib=lib.value_counts().reset_index() lib.loc[lib['index'].str.contains('Pandas|pandas|panda'),'index']='Pandas' lib.loc[lib['index'].str.contains('Tensorflow|tensorflow|tf|tensor'),'index']='Tensorflow' lib.loc[lib['index'].str.contains('Scikit|scikit|sklearn'),'index']='Sklearn' lib=lib.groupby('index')[0].sum().sort_values(ascending=False).to_frame() R_packages=['dplyr','tidyr','ggplot2','caret','randomforest','shiny','R markdown','ggmap','leaflet','ggvis','stringr','tidyverse','plotly'] Py_packages=['Pandas','Tensorflow','Sklearn','matplotlib','numpy','scipy','seaborn','keras','xgboost','nltk','plotly'] f,ax=plt.subplots(1,2,figsize=(18,10)) lib[lib.index.isin(Py_packages)].sort_values(by=0,ascending=True).plot.barh(ax=ax[0],width=0.9,color=sns.color_palette('viridis',15)) ax[0].set_title('Most Frequently Used Py Libraries') lib[lib.index.isin(R_packages)].sort_values(by=0,ascending=True).plot.barh(ax=ax[1],width=0.9,color=sns.color_palette('viridis',15)) ax[1].set_title('Most Frequently Used R Libraries') ax[1].set_ylabel('') plt.show()
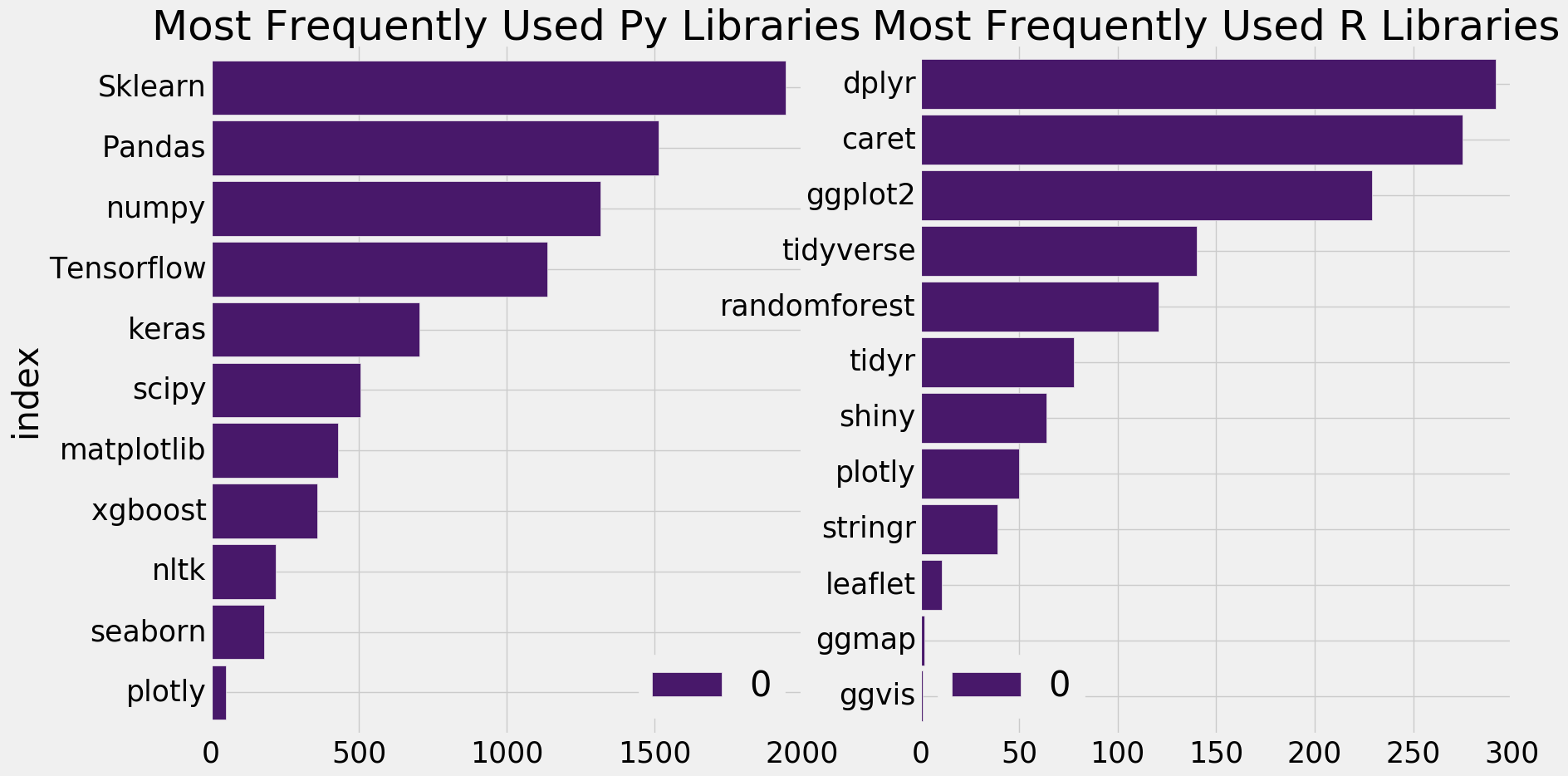
和我们所认识的差不多一样啊!
由于篇幅有限,这里只给出了一部分分析结果。更详细的分析代码和数据集大家可以在这里下载。
链接:https://pan.baidu.com/s/1qN69P6oQQmXRcwoNYcfOEQ 提取码:au7z
结论:
1)大多数受访者来自美国.
2)大多数的受访者在年龄20-35岁,这表明数据科学的年轻人是很著名的。
3)调查对象不仅限于计算机科学专业,还包括统计学、健康科学等专业,数据科学是一门跨学科的领域。
4)大多数被调查者都被充分雇用。
5)Kaggle,在线课程(Coursera,edX,等),项目和博客(kdnuggets,analyticsvidya,等)是学习数据科学的首选资源。
6)Kaggle数据采集与GitHub的代码共享是大家非常喜欢的
7)数据科学家的工作满意度最高,相反程序员的工作满意度最低。
8)数据科学家也从以前的工作中获得的提升大约6~20%。
1)学习Python、R和SQL,因为它们是数据科学家最常用的语言。Python和R将有助于分析和预测建模,而SQL最适合查询数据库。
2)学习机器学习技术,如逻辑回归,决策树,支持向量机等,因为它们是最常用的机器学习技术/算法。
3)深学习和神经网络将是未来最受欢迎的技术,因此,精通它们将是非常有益的。
4)掌握收集数据和清理数据的技能,因为它们是数据科学家工作流程中最耗时的过程。
5)可视化是非常重要的数据科学项目以及几乎所有的项目都需要了解数据的可视化。
6)数学和统计在数据科学中是非常重要的,所以我们应该对它有很好的理解,以便真正理解算法是如何工作的。
7)根据数据科学家们说,项目是学习数据科学的最佳途径,因此,研究项目将有助于更好地学习数据科学。


