

Python爬虫
一、环境配置
Python+pip 的安装
请求库:urllib,requests,selenium,scrapy 解析库:beautifulsoup4,pyquery,lxml,scrapy,re 数据库:redis,pymysql,pymongo MongoDB的安装和配置+robot 3t (27017) Redis 的安装和配置 +RedisDesktopManager (6379) Mysql的安装和配置 + Navicat for mysql (3306) pip install requests selenium beautifulsoup4 pyquery pymysql pymongo redis flask django jupyter
二、爬虫基本原理
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
爬虫基本流程
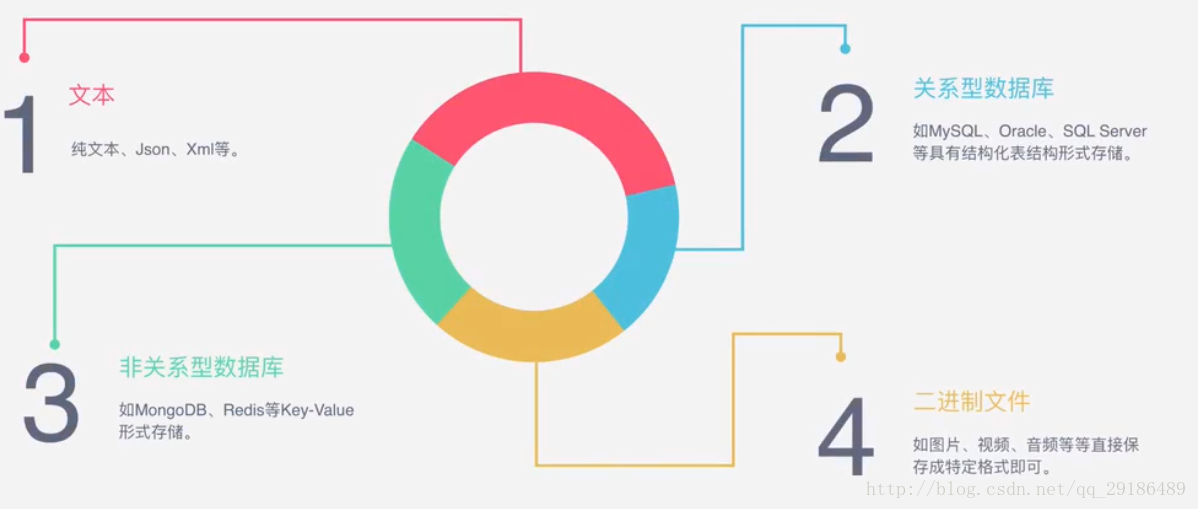
1:向服务器发起请求 通过HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,等待服务器的响应。 2:获取响应内容 如果服务器正常响应,会得到一个Response,Response的内容便是所要获取的页面内容,类型可能有HTML、JSON、二进制文件(如图片、视频等类型)。 3:解析内容 得到的内容可能是HTML,可以用正则表达式、网页解析库进行解析。可能是JSON,可以直接转成JOSN对象进行解析,可能是二进制数据,可以保存或者进一步处理 4:保存内容 保存形式多样,可以保存成文本,也可以保存至数据库,或者保存成特定格式的文件。
requests和response

Request中包含哪些内容?
- 1:请求方式
主要是GET、POST两种类型,另外还有HEAD、PUT、DELETE、OPTIONS等。
- 2:请求URL
URL全称是统一资源定位符,如一个网页文档、一张图片、一个视频等都可以用URL来唯一来确定
- 3:请求头
包含请求时的头部信息,如User-Agent、Host、Cookies等信息
- 4:请求体
请求时额外携带的数据,如表单提交时的表单数据
Response中包含哪些内容?
- 1:响应状态
有多种响应状态,如200代表成功,301代表跳转,404代表找不到页面,502代表服务器错误等
- 2:响应头
如内容类型、内容长度、服务器信息、设置cookies等等
- 3:响应体
最主要的部分,包含了请求资源的内容,如网页HTML、图片二进制数据等。
实例代码
from fake_useragent import UserAgent
import requests
ua=UserAgent()
#请求的网址
url="http://www.baidu.com"
#请求头
headers={"User-Agent":ua.random}
#请求网址
response=requests.get(url=url,headers=headers)
#响应体内容
print(response.text)
#响应状态信息
print(response.status_code)
#响应头信息
print(response.headers)


- 请求和响应: - 请求: "GET /index http1.1\r\nhost:c1.com\r\nContent-type:asdf\r\nUser-Agent:aa\r\nreferer:www.xx.com;cookie:k1=v1;k2=v2;\r\n\r\n" - 响应: "HTTP/1.1 200 \r\nSet-Cookies:k1=v1;k2=v2,Connection:Keep-Alive\r\nContent-Encoding:gzip\r\n\r\n<html>asdfasdfasdfasdfdf</html>" - 携带常见请求头 - user-agent - referer - host - content-type - cookie - csrf
- 原因1: - 需要浏览器+爬虫先访问登录页面,获取token,然后再携带token去访问。 - 原因2: - 两个tab打开的同时,其中一个tab诱导你对另外一个tab提交非法数据。
能抓到怎样的数据?
- 1:网页文本
如HTML文档、JSON格式文本等
- 2:图片文件
获取的是二进制文件,保存为图片格式
- 3:视频
同为二进制文件,保存为视频格式即可
- 4:其他
只要能够请求到的,都能够获取到
import requests #下载百度的LOGO response=requests.get("https://www.baidu.com/img/bd_logo1.png") with open("1.jpg","wb") as f: f.write(response.content) f.close()
解析方式

为什么我们抓到的有时候和浏览器看到的不一样?
有时候,网页返回是JS动态加载的,直接用请求库访问获取到的是JS代码,不是渲染后的结果。

怎样保存数据?
好了,有了这些基础知识以后,就开始咱们的学习之旅吧!
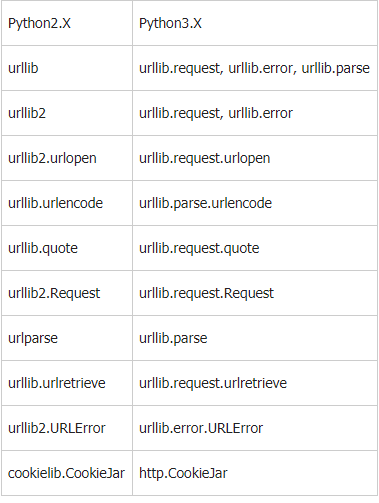
三、urllib- 内置请求库

urllib库对照速查表
1.请求
urllib.request.urlopen(url.data=None,[timeout,]*cafile=None,capath=None,cadefault=False,context=None) In [1]: import urllib.request In [2]: response = urllib.request.urlopen('http://www.baidu.com') In [3]: print(response.read().decode('utf-8')) import urllib.parse import urllib.request data = bytes(urllib.parse.urlencode({'world':'hello'}),encoding='utf8') response = urllib.request.urlopen('http://httpbin.org/post',data=data) print(response.read()) import urllib.request response = urllib.request.urlopen('http://httpbin.org/get',timeout=1) print(response.read()) import socket import urllib.request import urllib.error try: response = urllib.request.urlopen('http://httpbin.org/get',timeout=0.1) except urllib.error.URLError as e: if isinstance(e.reason,socket.timeout): print('TIME OUT')
In [38]: urllib.request.quote('张亚飞') Out[38]: '%E5%BC%A0%E4%BA%9A%E9%A3%9E' In [39]: urllib.request.quote('zhang') Out[39]: 'zhang'
urllib.request.urlretrieve(url)
In [41]: urllib.request.urljoin('http://www.zhipin.com',"/job_detail/a53756b0e6 ...: 5b7a5f1HR_39m0GFI~.html") Out[41]: 'http://www.zhipin.com/job_detail/a53756b0e65b7a5f1HR_39m0GFI~.html'
2.响应
In [1]: import urllib.request In [2]: response = urllib.request.urlopen('https://pytorch.org/') In [3]: response.__class__ Out[3]: http.client.HTTPResponse
3.状态码
HTTP状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型,后两个数字没有分类的作用。HTTP状态码共分为5种类型

更详细的信息请点击 http://www.runoob.com/http/http-status-codes.html
In [1]: import urllib.request In [2]: response = urllib.request.urlopen('https://pytorch.org/') In [3]: response.__class__ Out[3]: http.client.HTTPResponse In [4]: response.status Out[4]: 200 In [6]: response.getheaders() Out[6]: [('Server', 'GitHub.com'), ('Content-Type', 'text/html; charset=utf-8'), ('Last-Modified', 'Sat, 15 Dec 2018 19:40:33 GMT'), ('ETag', '"5c1558b1-6e22"'), ('Access-Control-Allow-Origin', '*'), ('Expires', 'Sun, 16 Dec 2018 12:10:41 GMT'), ('Cache-Control', 'max-age=600'), ('X-GitHub-Request-Id', 'D0E4:46D5:2655CC0:2F6CE98:5C163E69'), ('Content-Length', '28194'), ('Accept-Ranges', 'bytes'), ('Date', 'Sun, 16 Dec 2018 12:00:42 GMT'), ('Via', '1.1 varnish'), ('Age', '0'), ('Connection', 'close'), ('X-Served-By', 'cache-hkg17924-HKG'), ('X-Cache', 'MISS'), ('X-Cache-Hits', '0'), ('X-Timer', 'S1544961642.791954,VS0,VE406'), ('Vary', 'Accept-Encoding'), ('X-Fastly-Request-ID', '7fdcbfe552a9b6f694339f8870b448184e60b210')] In [8]: response.getheader('server') Out[8]: 'GitHub.com'
In [15]: from urllib.parse import urlencode In [16]: data = urlencode({'username':'zhangyafei','password':123455678}) In [17]: data Out[17]: 'username=zhangyafei&password=123455678' In [18]: data.encode('utf-8') Out[18]: b'username=zhangyafei&password=123455678'
In [19]: headers = {'User-Agent':ua.random}
In [25]: data = data.encode('utf-8')
In [27]: req = urllib.request.Request(url='http://httpbin.org/post',data=data,headers=headers,method='POST')
In [28]: response = urllib.request.urlopen(req)
In [29]: response.read().decode('utf-8')
Out[29]: '{\n "args": {}, \n "data": "", \n "files": {}, \n "form": {\n "
password": "123455678", \n "username": "zhangyafei"\n }, \n "headers": {\n
"Accept-Encoding": "identity", \n "Connection": "close", \n "Content-Le
ngth": "38", \n "Content-Type": "application/x-www-form-urlencoded", \n "H
ost": "httpbin.org", \n "User-Agent": "Mozilla/5.0 (Windows NT 6.2) AppleWebK
it/537.36 (KHTML, like Gecko) Chrome/28.0.1467.0 Safari/537.36"\n }, \n "json"
: null, \n "origin": "111.53.196.6", \n "url": "http://httpbin.org/post"\n}\n'
添加报头
req.add_header(headers)
4.Handler代理
import urllib.request proxy_handler = urllib.request.ProxyHandler({ 'http':'http://127.0.0.1:9743', 'https':'https://127.0.0.1:9743' }) opener = urllib.request.build_opener(proxy_handler) response = opener.open('http://httpbin.org/get') print(response.read())
5.Cookie
import http.cookiejar,urllib.request cookie = http.cookiejar.CookieJar() handler = urllib.request.HTTPCookieProcessor(cookie) opener = urllib.request.build_opener(handler) response = opener.open('http://www.baidu.com') for item in cookie: print(item.name+"="+item.value) import http.cookiejar,urllib.request filename = "cookie.txt" cookie = http.cookiejar.MozillaCookieJar(filename) handler = urllib.request.HTTPCookieProcessor(cookie) opener = urllib.request.build_opener(handler) response = opener.open('http://www.baidu.com') cookie.save(ignore_discard=True,ignore_expires=True)
6.异常处理
from urllib import request,error try: response = request.urlopen('http://cuiqingcai.com/index.html') except error.URLError as e: print(e.reason) from urllib import request,error try: response = request.urlopen('http://cuiqingcai.com/index.html') except error.HTTPError as e: print(e.reason,e.code,e.headers,sep='\n') except error.URLError as e: print(e.reason) else: print('Request successfully')
7.url解析
In [31]: from urllib.parse import urlparse In [32]: result=urlparse('http://www.baidu.com/index.html;user?id=5#comment',sc ...: heme='https',allow_fragments=False) In [33]: result Out[33]: ParseResult(scheme='http', netloc='www.baidu.com', path='/index.html', params='user', query='id=5#comment', fragment='')
urllib.parse.rlunparse
from urllib.parse import urljoin print(urljoin('http://www.baidu.com','FAQ.html')) http://www.baidu.com/FAQ.html print(urljoin('http://www.baidu.com/about.html','https://cuiqingcai.com/FAQ.html')) https://cuiqingcai.com/FAQ.html print(urljoin('www.baidu.com?wd=abc','https://cuiqingcai.com/index.php ')) https://cuiqingcai.com/index.php print(urljoin('www.baidu.com','?category=2#comment')) www.baidu.com?category=2#comment print('www.baidu.com#comment','?category=2') www.baidu.com#comment ?category=2
from urllib.parse import urljoin print(urljoin('http://www.baidu.com','FAQ.html')) http://www.baidu.com/FAQ.html print(urljoin('http://www.baidu.com/about.html','https://cuiqingcai.com/FAQ.html')) https://cuiqingcai.com/FAQ.html print(urljoin('www.baidu.com?wd=abc','https://cuiqingcai.com/index.php ')) https://cuiqingcai.com/index.php print(urljoin('www.baidu.com','?category=2#comment')) www.baidu.com?category=2#comment print('www.baidu.com#comment','?category=2') www.baidu.com#comment ?category=2
案例:抓取贴吧图片
# -*- coding: utf-8 -*- """ Created on Sat Jul 28 19:54:15 2018 @author: Zhang Yafei """ import urllib.request import re import time import os import pymongo import requests client = pymongo.MongoClient('localhost') DB = client['tieba_img'] MONGO_TABLE = 'IMGS' def spider(): url = "https://tieba.baidu.com/p/1879660227" req = urllib.request.Request(url) response = urllib.request.urlopen(req) html = response.read().decode('utf-8') imgre = re.compile(r'src="(.*?.jpg)" pic_ext',re.S) imglist = re.findall(imgre,html) return imglist def download(imglist): rootdir = os.path.dirname(__file__)+'/download/images' #os.mkdir(os.getcwd()+'/download/images') if not os.path.exists(rootdir): os.mkdir(rootdir) x = 1 for img_url in imglist: print("正在下载第{}张图片".format(x)) try: urllib.request.urlretrieve(img_url,rootdir+'\\{}.jpg'.format(x)) print("第{}张图片下载成功!".format(x)) except Exception as e: print('第{}张图片下载失败'.format(x),e) finally: x += 1 time.sleep(1) print('下载完成') def download2(imglist): x = 0 for url in imglist: x += 1 print('正在下载第{}个图片'.format(x)) try: response = requests.get(url) save_image(response.content,x) except Exception as e: print('请求图片错误!',e) print('下载完成') def save_image(content,x): file_path = '{0}/download/images1/{1}.{2}'.format(os.path.dirname(__file__),x,'jpg') if not os.path.exists(file_path): with open(file_path,'wb') as f: if f.write(content): print('下载第{}个图片成功'.format(x)) else: print('下载第{}个图片失败'.format(x)) f.close() else: print('此图片已下载') def save_to_mongo(imglist): for url in imglist: imgs = {'img_url':url} if DB[MONGO_TABLE].insert_one(imgs): print('存储到mongo_db数据库成功!') else: print('存储到mongo_db数据库失败!') def main(): imglist = spider() download(imglist) save_to_mongo(imglist) # download2(imglist) if __name__ == "__main__": main()
四、requests
实例引入
import requests
response = requests.get('http://www.baidu.com/')
print(type(response))
print(response.status_code)
print(response.text)
print(type(response.text))
print(response.cookies)
<class 'requests.models.Response'> 200 <!DOCTYPE html> <!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-。。。 <class 'str'> <RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
1,.请求
import requests requests.post('http://www.httpbin.org/post') requests.put('http://www.httpbin.org/put') requests.delete('http://www.httpbin.org/delete') requests.head('http://www.httpbin.org/get') requests.options('http://www.httpbin.org/get')
# 基本get请求 import requests response = requests.get('http://www.httpbin.org/get') print(response.text) #带参数的get请求 import requests data ={ 'name':'germey', 'age':22 } response = requests.get('http://www.httpbin.org/get',params=data) print(response.text) 解析json import requests,json response = requests.get('http://www.httpbin.org/get') print(type(response.text)) print(response.text) print(response.json()) print(json.loads(response.text)) 添加headers import requests response = requests.get('https://www.zhihu.com/explore') print(response.text) import requests headers = { "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0" } response = requests.get('https://www.zhihu.com/explore',headers=headers) print(response.text) 获取二进制数据 import requests response = requests.get('https://github.com/favicon.ico') print(type(response.text),type(response.content)) print(response.content) print(response.text) import requests response = requests.get('https://github.com/favicon.ico') with open('.\images\logo.gif','wb') as f: f.write(response.content) f.close() 基本post请求 import requests data = {'name':'kobe','age':'23'} response = requests.post('http://www.httpbin.org/post',data=data) print(response.text)
# post方式 import requests data = {'name':'kobe','age':'23'} headers = { 'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Mobile Safari/537.36' } response = requests.post('http://www.httpbin.org/post',data=data,headers=headers) print(response.json())
2.响应
import requests response= requests.get('http://www.jianshu.com') response.encoding = response.apparent_encoding print(type(response.status_code),response.status_code) print(type(response.headers),response.headers) print(type(response.cookies),response.cookies) print(type(response.url),response.url) print(type(response.history),response.history)
import requests response = requests.get('http://www.jianshu.com') exit()if not response.status_code == requests.codes.ok else print('requests succfully') import requests response = requests.get('http://www.jianshu.com') exit() if not response.status_code == 200 else print('requests succfully')
3.高级操作
import requests files = {'file':open('images/logo.gif','rb')} response = requests.post('http://www.httpbin.org/post',files=files) print(response.text)
import requests response = requests.get('http://www.baidu.com') print(response.cookies) for key,value in response.cookies.items(): print(key+'='+value)
import requests requests.get('http://www.httpbin.org/cookies/set/number/123456789') response = requests.get('http://www.httpbin.org/cookies') print(response.text) import requests s = requests.Session() s.get('http://www.httpbin.org/cookies/set/number/123456789') response = s.get('http://www.httpbin.org/cookies') print(response.text)
import requests response = requests.get('https://www.12306.cn') print(response.status_code) import requests from requests.packages import urllib3 urllib3.disable_warnings() response = requests.get('https://www.12306.cn',verify=False) print(response.status_code) import requests response = requests.get('https://www.12306.cn',cert=) print(response.status_code)
import requests proxies = { 'http':'http://101.236.35.98:8866', 'https':'https://14.118.254.153:6666', } response = requests.get('https://www.taobao.com',proxies=proxies) print(response.status_code)
import requests response = requests.get('https://www.taobao.com',timeout=1) print(response.status_code) import requests from requests.exceptions import ReadTimeout try: response = requests.get('http://www.httpbin.org',timeout=0.1) print(response.status_code) except: print('TIME OUT')
import requests from requests.exceptions import Timeout from requests.auth import HTTPBasicAuth try: response = requests.get('http://120.27.34.24:9001',auth=HTTPBasicAuth('user','123')) print(response.status_code) except Timeout: print('time out') import requests response = requests.get('http://120.27.34.24:9001',auth=('user','123')) print(response.status_code) import requests from requests.exceptions import ReadTimeout,HTTPError,ConnectionError,RequestException try: response = requests.get('http://www.httpbin.org/get',timeout=0.5) print(response.status_code) except ReadTimeout: print('TIME OUT') except ConnectionError: print('Connect error') except RequestException:
五、正则表达式
1.re.match
1.re.match re.match尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none. Re.match(pattern,string,flags=0) 最常规的匹配 import re content = ‘Hello 123 4567 World_This is a Regex Demo’ 泛匹配 import re content = 'Hello 123 4567 World_This is a Regex Demo' result = re.match('^Hello.*Demo$',content) print(result) print(result.group()) print(result.span()) 匹配目标 import re content = 'Hello 1234567 World_This is a Regex Demo' result = re.match('^Hello\s(\d+)\sWorld.*Demo$',content) print(result) print(result.group(1)) print(result.span()) 贪婪匹配 import re content = 'Hello 123 4567 World_This is a Regex Demo' result = re.match('^He.*(\d+).*Demo$',content) print(result) print(result.group(1)) print(result.span()) 非贪婪匹配 import re content = 'Hello 1234567 World_This is a Regex Demo' result = re.match('^He.*?(\d+).*Demo$',content) print(result) print(result.group(1)) print(result.span()) 匹配模式 import re content = """Hello 1234567 World_This is a Regex Demo""" result = re.match('^He.*?(\d+).*?Demo$',content,re.S) print(result.group(1)) 转义 import re content = 'price is $5.00' result = re.match('^price is \$5\.00$',content) print(result)
2.re,search()
re.search re.search扫描整个字符串,然后返回第一个成功的匹配 import re content = 'Extra strings Hello 1234567 World_This is a Regex Demo Extra strings' result = re.search('Hello.*?(\d+).*Demo',content) print(result.groups())
print(result.group(1)) 总结:为匹配方便,能用re.rearch就不用re.match
3.re.findall(pattern, string, flags=0)
regular_v1 = re.findall(r"docs","https://docs.python.org/3/whatsnew/3.6.html") print (regular_v1) # ['docs']
regular_v9 = re.findall(r"\W","https://docs.python.org/3/whatsnew/3.6.html")print (regular_v9)# [':', '/', '/', '.', '.', '/', '/', '/', '.', '.']4.re.sub(substr,new_str,content)
re.sub 替换字符串中每一个匹配的字符串后返回匹配的字符串 import re content = 'Extra strings Hello 1234567 World_This is a Regex Demo Extra strings' result = re.sub('\d+','',content) print(result) import re content = 'Extra strings Hello 1234567 World_This is a Regex Demo Extra strings' result = re.sub('\d+','replacement',content) print(result) import re content = 'Extra strings Hello 1234567 World_This is a Regex Demo Extra strings' result = re.sub('(\d+)',r'\1 8901',content) print(result)
5.re.compile(pattern,re.S)
re.compile import re content = '''Hello 1234567 World_This is a Regex Demo''' pattern = re.compile('^He.*Demo',re.S) result = re.match(pattern,content) result1 = re.match('He.*Demo',content,re.S) print(result) print(result1)
# 实例:爬取豆瓣读书 import requests import re content = requests.get('https://book.douban.com/').text pattern=re.compile('<li.*?cover.*?href="(.*?)".*?title="(.*?)".*?more-meta.*?author>(.*?)</span>.*?year>(.*?)</span>.*?publisher>(.*?)</span>.*?abstract(.*?)</p>.*?</li>',re.S) results = re.findall(pattern,content) for result in results: url,name,author,year,publisher,abstract=result name = re.sub('\s','',name) author = re.sub('\s', '', author) year = re.sub('\s', '', year) publisher = re.sub('\s', '', publisher) print(url,name,author,year,publisher,abstract)
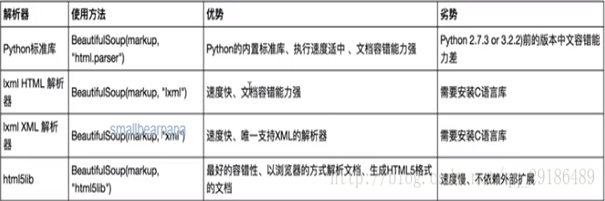
六、BeautifulSoup
解析库
1.基本使用
from bs4 import BeautifulSoup import requests r = requests.get('https://m.weibo.cn') soup = BeautifulSoup(r.text,'lxml') print(soup.prettify()) print(soup.title.string)
2.选择器
标签选择器 from bs4 import BeautifulSoup import requests r = requests.get('https://m.weibo.cn') soup = BeautifulSoup(r.text,'lxml') print(soup.title) print(type(soup.title)) print(soup.head) print(soup.p) 获取名称 from bs4 import BeautifulSoup import requests r = requests.get('https://m.weibo.cn') soup = BeautifulSoup(r.text,'lxml') print(soup.title.name) 获取属性 from bs4 import BeautifulSoup import requests r = requests.get('https://m.weibo.cn') soup = BeautifulSoup(r.text,'lxml') print(soup.p.attrs['class']) print(soup.p['class']) 获取内容 from bs4 import BeautifulSoup import requests r = requests.get('https://m.weibo.cn') soup = BeautifulSoup(r.text,'lxml') print(soup.title.string) 嵌套选择 from bs4 import BeautifulSoup import requests r = requests.get('https://m.weibo.cn') soup = BeautifulSoup(r.text,'lxml') print(soup.head.title.string) 子节点和子孙节点 from bs4 import BeautifulSoup import requests r = requests.get('https://m.weibo.cn') soup = BeautifulSoup(r.text,'lxml') print(soup.div.contents) from bs4 import BeautifulSoup import requests r = requests.get('https://m.weibo.cn') soup = BeautifulSoup(r.text,'lxml') print(soup.div.children) for i,child in enumerate(soup.div.children): print(i,child) from bs4 import BeautifulSoup import requests r = requests.get('https://m.weibo.cn') soup = BeautifulSoup(r.text,'lxml') print(soup.div.descendants) for i,child in enumerate(soup.div.descendants): print(i,child) 父节点和祖先节点 from bs4 import BeautifulSoup import requests r = requests.get('https://m.weibo.cn') soup = BeautifulSoup(r.text,'lxml') print(soup.p.parent) from bs4 import BeautifulSoup import requests r = requests.get('https://m.weibo.cn') soup = BeautifulSoup(r.text,'lxml') print(list(enumerate(soup.p.parents))) 兄弟节点 from bs4 import BeautifulSoup import requests r = requests.get('https://m.weibo.cn') soup = BeautifulSoup(r.text,'lxml') print(list(enumerate(soup.p.next_siblings))) print(list(enumerate(soup.p.previous_siblings)))
标准选择器 find_all(name,attrs,recursive,text,**kwargs) 可根据标签名,属性,内容查找文档 from bs4 import BeautifulSoup import requests r = requests.get('https://m.weibo.cn') soup = BeautifulSoup(r.text,'lxml') print(soup.find_all('p')) print(type(soup.find_all('p')[0])) from bs4 import BeautifulSoup import requests r = requests.get('https://m.weibo.cn') soup = BeautifulSoup(r.text,'lxml') for div in soup.find_all('div'): print(div.find_all('p')) attrs from bs4 import BeautifulSoup import requests r = requests.get('https://m.weibo.cn') soup = BeautifulSoup(r.text,'lxml') print(soup.find_all(attrs={'id':'app'})) from bs4 import BeautifulSoup import requests r = requests.get('https://m.weibo.cn') soup = BeautifulSoup(r.text,'lxml') print(soup.find_all(id='app')) print(soup.find_all(class_='wb-item')) from bs4 import BeautifulSoup import requests r = requests.get('https://m.weibo.cn') soup = BeautifulSoup(r.text,'lxml') print(soup.find_all(text='赞')) find(name,attrs,recursive,text,**kwagrs) find返回单个元素,find_all返回所有元素 from bs4 import BeautifulSoup import requests r = requests.get('https://m.weibo.cn') soup = BeautifulSoup(r.text,'lxml') print(soup.find('p')) print(type(soup.find('p'))) find_parents() 和find_parent() find_next_siblings()和find_next_silbing() find_previous_siblings()和find_previous_sibling() find_all_next()和find_next() find_all_previous()和find_previous()
css选择器 通过select()直接传给选择器即可完成传值 ID选择器,标签选择器,类选择器 from bs4 import BeautifulSoup import requests r = requests.get('https://m.weibo.cn') soup = BeautifulSoup(r.text,'lxml') print(soup.select('#app')) print(soup.select('p')) print(soup.select('.surl-text')) from bs4 import BeautifulSoup import requests r = requests.get('https://m.weibo.cn') soup = BeautifulSoup(r.text,'lxml') divs = soup.select('div') for div in divs: print(div.select('p')) 获取属性 from bs4 import BeautifulSoup import requests r = requests.get('https://m.weibo.cn') soup = BeautifulSoup(r.text,'lxml') for div in soup.select('div'): print(div['class']) print(div.attrs['class']) 获取内容 from bs4 import BeautifulSoup import requests r = requests.get('https://m.weibo.cn') soup = BeautifulSoup(r.text,'lxml') for div in soup.select('div'): print(div.get_text())
总结:
1.推介使用lxml解析器,必要时选择html.parser 2.标签选择功能弱但是速度快 3.建议使用find和find_all查询选择单个或多个结果 4.如果对css选择器熟悉使用select() 5.记住常用的获取属性和文本值的方法
七、Pyquery
强大又灵活的网页解析库,如果你嫌正则太麻烦,beautifulsoup语法太难记,又熟悉jQuery,pyquery是最好的选择
1,.初始化
字符串初始化 from pyquery import PyQuery as pq import requests html = requests.get('https://www.taobao.com') doc = pq(html.text) print(doc('a')) url初始化 from pyquery import PyQuery as pq doc = pq(url='https://www.baidu.com') print(doc('head')) 文件初始化 from pyquery import PyQuery as pq doc = pq(filename='weibo.html') print(doc('li'))
2.基本css选择器
from pyquery import PyQuery as pq headers = { 'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Mobile Safari/537.36' } doc = pq(url='https://www.baidu.com',headers=headers) print(doc('a'))
3.查找元素
子元素 from pyquery import PyQuery as pq import requests html = requests.get('https://www.taobao.com') doc = pq(html.text) items = doc('.nav-bd') print(items) li = items.find('li') print(type(li)) print(li) lis = items.children() print(type(lis)) print(lis) lis = items.children('.active') print(type(lis)) print(lis) 父元素 from pyquery import PyQuery as pq import requests html = requests.get('https://www.baidu.com') doc = pq(html.text) print(doc) items = doc('.pipe') parent = items.parent() print(type(parent)) print(parent) from pyquery import PyQuery as pq import requests html = requests.get('https://www.taobao.com') doc = pq(html.text) items = doc('.pipe') parents = items.parents() print(type(parents)) print(parents) 兄弟元素 li = doc('.nav-bd .pipe') print(li.siblings()) print(li.siblings('.active'))
4.遍历
from pyquery import PyQuery as pq import requests html = requests.get('https://www.taobao.com') doc = pq(html.text) lis = doc('.pipe').items() print(lis) for li in lis: print(li)
5.获取信息
获取属性 from pyquery import PyQuery as pq import requests html = requests.get('https://www.taobao.com') doc = pq(html.text) a = doc('a') print(a) for a1 in a.items(): print(a1.attr('href')) print(a1.attr.href) 获取文本 from pyquery import PyQuery as pq import requests html = requests.get('https://www.taobao.com') doc = pq(html.text) items = doc('.nav-bd') print(items.text()) 获取html from pyquery import PyQuery as pq import requests html = requests.get('https://www.taobao.com') doc = pq(html.text) items = doc('.nav-bd') print(items) print(items.html())
6.dom操作
addclass,removeclass from pyquery import PyQuery as pq import requests html = requests.get('https://www.taobao.com') doc = pq(html.text) li = doc('.nav-bd .active') li.removeClass('.active') print(li) li.addClass('.active') print(li) attr,css from pyquery import PyQuery as pq import requests html = requests.get('https://www.taobao.com') doc = pq(html.text) lis = doc('.nav-bd li') lis.attr('name','link') print(lis) lis.css('font','14px') print(lis) remove from pyquery import PyQuery as pq import requests html = requests.get('https://www.taobao.com') doc = pq(html.text) items = doc('.nav-bd a') print(items.text()) items.find('p').remove() print(items.text()) 其他dom方法 http://pyquery.readthedocs.io/en/latest/api.html 其它伪类选择器 http://jquery.cuishifeng.cn
八、Selenium
自动化测试工具,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题
1.基本使用
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait browser = webdriver.Chrome() try: browser.get('https://www.baidu.com') input = browser.find_element_by_id('kw') input.send_keys('Python') input.send_keys(Keys.ENTER) wait = WebDriverWait(browser,10) wait.until(EC.presence_of_element_located((By.ID,'content_left'))) print(browser.current_url) print(browser.get_cookies) print(browser.page_source) finally: browser.close()
2.声明浏览器对象
from selenium import webdriver browser = webdriver.Chrome() browser = webdriver.Firefox() browser = webdriver.PhantomJS() browser = webdriver.Edge() browser = webdriver.Safari()
3.访问页面
from selenium import webdriver browser = webdriver.Chrome() browser.get('https://www.taobao.com') print(browser.page_source) browser.close()
4.查找元素
单个元素 from selenium import webdriver browser = webdriver.Chrome() browser.get('https://www.taobao.com') input_first = browser.find_element_by_id('q') input_second = browser.find_element_by_css_selector('#q') input_third = browser.find_element_by_xpath('//*[@id="q"]') print(input_first,input_second,input_third) browser.close() find_element_by_id find_element_by_name find_element_by_xpath find_element_by_css_selector find_element_by_link_text find_element_by_partial_link_text find_element_by_tag_name find_element_by_class_name from selenium import webdriver from selenium.webdriver.common.by import By browser = webdriver.Chrome() browser.get('https://www.baidu.com') input_first = browser.find_element(By.ID,'kw') print(input_first) browser.close() 多个元素 from selenium import webdriver browser = webdriver.Chrome() browser.get('https://www.taobao.com') lis = browser.find_elements(By.CSS_SELECTOR,'.service-bd li') print(lis) browser.close() from selenium import webdriver browser = webdriver.Chrome() browser.get('https://www.taobao.com') lis = browser.find_elements_by_css_selector('.service-bd li') print(lis) browser.close() find_elements_by_id find_elements_by_name find_elements_by_xpath find_elements_by_css_selector find_elements_by_link_text find_elements_by_partial_link_text find_elements_by_tag_name find_elements_by_class_name
5.元素交互操作
对元素进行获取的操作 交互操作 将动作附加到动作链中串行执行 from selenium import webdriver from selenium.webdriver import ActionChains browser = webdriver.Chrome() url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable' browser.get(url) browser.switch_to_frame('iframeResult') source = browser.find_element_by_css_selector('#draggable') target = browser.find_element_by_css_selector('#droppable') actions = ActionChains(browser) actions.drag_and_drop(source,target) actions.perform() 执行JavaScript from selenium import webdriver browser = webdriver.Chrome() browser.get('https://www.zhihu.com/explore') browser.execute_script('window.scrollTo(0,document.body.scrollHeight)') browser.execute_script('alert("to button")') 获取元素信息 from selenium import webdriver from selenium.webdriver import ActionChains browser = webdriver.Chrome() url = "https://www.zhihu.com/explore" browser.get(url) logo = browser.find_element_by_id('zh-top-link-logo') print(logo) print(logo.get_attribute('class')) from selenium import webdriver from selenium.webdriver import ActionChains browser = webdriver.Chrome() url = "https://www.zhihu.com/explore" browser.get(url) input = browser.find_element_by_class_name('zu-top-add-question') print(input.text) print(input.id) print(input.location) print(input.tag_name) print(input.size) frame from selenium import webdriver from selenium.webdriver import ActionChains browser = webdriver.Chrome() url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable' browser.get(url) browser.switch_to.frame('iframeResult') source = browser.find_element_by_css_selector('#draggable') print(source) try: logo = browser.find_element_by_class_name('logo') except Exception as e: print(e) browser.switch_to.parent_frame() logo = browser.find_element_by_class_name('logo') print(logo) print(logo.text)
6.等待
隐式等待 from selenium import webdriver browser = webdriver.Chrome() browser.implicitly_wait(10) browser.get('https://www.zhihu.com/explore') input = browser.find_element_by_class_name('zu-top-add-question') print(input) browser.close() 显式等待 from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC browser = webdriver.Chrome() browser.get('https://www.taobao.com/') wait = WebDriverWait(browser,10) input = wait.until(EC.presence_of_element_located((By.ID,'q'))) button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'.btn-search'))) print(input,button) browser.close()
7.前进后退
import time from selenium import webdriver browser = webdriver.Chrome() browser.get('https://www.baidu.com/') browser.get('https://www.taobao.com/') browser.get('https://www.python.org/') browser.back() time.sleep(1) browser.forward() browser.close()
8.选项卡管理
from selenium import webdriver import time browser = webdriver.Chrome() browser.get('https://www.baidu.com') browser.execute_script('window.open()') print(browser.window_handles) browser.switch_to_window(browser.window_handles[1]) browser.get('https://www.taobao.com') time.sleep(1) browser.switch_to_window(browser.window_handles[0]) browser.get('https://www.python.org') print(browser.page_source)
9.cookies
from selenium import webdriver browser = webdriver.Chrome() browser.get('https://www.zhihu.com/explore') print(browser.get_cookies()) browser.add_cookie({'name':'name','domian':'www.zhihu.com','value':'kobe'}) print(browser.get_cookies()) browser.delete_all_cookies() print(browser.get_cookies()) browser.close()
10.异常处理
from selenium import webdriver from selenium.common.exceptions import TimeoutException,NoSuchElementException browser = webdriver.Chrome() try: browser.get('https://www.baidu.com') except TimeoutException: print('TIME OUT') try: browser.find_element_by_id('hello') except NoSuchElementException: print('No Element') finally: browser.close()
# -*- coding: utf-8 -*- """ Created on Tue Jul 31 16:41:13 2018 @author: Zhang Yafei """ from selenium import webdriver import time import selenium.webdriver.support.ui as ui from selenium.webdriver import ActionChains from selenium.common.exceptions import UnexpectedAlertPresentException browser = webdriver.Chrome() browser.get('https://www.taobao.com') #1.登录淘宝 #browser.find_element_by_xpath('//li[@id="J_SiteNavLogin"]/div[1]/div[1]/a[1]').click() #browser.find_element_by_xpath('//div[@id="J_QRCodeLogin"]/div[5]/a[1]').click() #browser.find_element_by_name('TPL_username').send_keys('xxxx') #browser.find_element_by_name('TPL_password').send_keys('xxx') #browser.find_element_by_id('J_SubmitStatic').click() #browser.find_element_by_name('TPL_username').send_keys('xxxx') #browser.find_element_by_name('TPL_password').send_keys('xxx') #dragger=browser.find_element_by_id('nc_1_n1z')#.滑块定位 #action=ActionChains(browser) #for index in range(500): # try: # action.drag_and_drop_by_offset(dragger, 300, 0).perform()#平行移动鼠标,此处直接设一个超出范围的值,这样拉到头后会报错从而结束这个动作 # except UnexpectedAlertPresentException: # break # time.sleep(5) #等待停顿时间 #browser.find_element_by_id('J_SubmitStatic').click() #搜索商品 browser.find_element_by_id('q').send_keys('爬虫') browser.find_element_by_xpath('//*[@id="J_TSearchForm"]/div[1]/button').click() #js事件,打开一个新的窗口 browser.execute_script('window.open()') #js事件,选择窗口 browser.switch_to_window(browser.window_handles[1]) browser.get('https://www.baidu.com') print(browser.window_handles) time.sleep(1) browser.switch_to_window(browser.window_handles[0]) browser.get('http://china.nba.com/') browser.switch_to_window(browser.window_handles[1]) #time.sleep(1) browser.find_element_by_name('wd').send_keys('张亚飞') browser.find_element_by_class_name('s_ipt').click() #browser.find_element_by_xpath('#page > a.n').click() #解决方案1:显式等待 wait = ui.WebDriverWait(browser,10) wait.until(lambda browser: browser.find_element_by_xpath('//div[@id="page"]/a[@class="n"]')) ##解决方案2: #while 1: # start = time.clock() # try: # browser.find_element_by_xpath('//div[@id="page"]/a[@class="n"]').click() # print('已定位到元素') # end=time.clock() # break # except: # print("还未定位到元素!") #print('定位耗费时间:'+str(end-start)) for i in range(1,10): wait = ui.WebDriverWait(browser,10) wait.until(lambda browser: browser.find_element_by_xpath('//div[@id="page"]/a[3]')) browser.find_element_by_xpath('//div[@id="page"]/a[{}]'.format(i)).click() time.sleep(2) browser.close() browser.switch_to_window(browser.window_handles[0]) browser.close() #browser.find_element_by_xpath('//div[@id="page"]/a[3]').click() #print(browser.page_source) #browser = webdriver.Chrome() ##browser.get('https://www.baidu.com') ##browser.execute_script('window.open()') #js操作 from selenium import webdriver browser = webdriver.Chrome() browser.get('https://www.zhihu.com/explore') browser.execute_script('window.scrollTo(0,document.body.scrollHeight)') browser.execute_script('alert("to button")') 示例 综合示例
# -*- coding: utf-8 -*- """ Created on Tue Jul 31 20:59:41 2018 @author: Zhang Yafei """ from selenium import webdriver import time import re import urllib.request import os import traceback #id='531501718059' def spider(id): rootdir = os.path.dirname(__file__)+'/images' browser = webdriver.Chrome() browser.get('https://detail.tmall.com/item.htm?id={}'.format(id)) time.sleep(20) b = browser.find_elements_by_css_selector('#J_DetailMeta > div.tm-clear > div.tb-property > div > div.tb-key > div > div > dl.tb-prop.tm-sale-prop.tm-clear.tm-img-prop > dd > ul > li > a') i=1 for a in b: style = a.get_attribute('style') try: image = re.match('.*url\((.*?)\).*',style).group(1) image_url = 'http:'+image image_url = image_url.replace('"','') except: pass name = a.text print('正在下载{}'.format(a.text)) try: name = name.replace('/','') except: pass try: urllib.request.urlretrieve(image_url,rootdir+'/{}.jpg'.format(name)) print('{}下载成功'.format(a.text)) except Exception as e: print('{}下载失败'.format(a.text)) print(traceback.format_exc()) pass finally: i+=1 print('下载完成') def main(): # id = input('请输入商品id:') ids = ['570725693770','571612825133','565209041287'] for id in ids: spider(id) if __name__ == '__main__': main()
九、scrapy框架
关于scrapy的xpath和css选择器,请点击这篇文章爬虫解析之css和xpath语法
建立项目:Scrapy startproject quotestutorial 创建爬虫:Cd quotestutorial Scrapy genspider quotes quotes.toscrape.com scrapy genspider -t crawl weisuen sohu.com 运行:Scrapy crawl quotes Scrapy runspider quote scrapy crawl lagou -s JOBDIR=job_info/001 暂停与重启 保存文件:Scrapy crawl quotes –o quotes.json
# -*- coding: utf-8 -*- from urllib import parse import scrapy from scrapy import signals # 信号量 # from scrapy.xlib.pydispatch import dispatcher # 分发器 from ArticleSpider.items import JobboleArticleItem, ArticleItemLoader from ArticleSpider.utils.common import get_md5 class JobboleSpider(scrapy.Spider): name = 'jobbole' allowed_domains = ['blog.jobbole.com'] start_urls = ['http://blog.jobbole.com/all-posts/'] # start_urls = ['http://blog.jobbole.com/boby/'] # def __init__(self): # self.browser = webdriver.Chrome() # super(JobboleSpider, self).__init__() # dispatcher.connect(self.spider_closed,signals.spider_closed) # # def spider_closed(self): # #当爬虫退出的时候关闭Chrome # print('spider closed') # self.browser.quit() # 收集伯乐在线所有404页面的url以及404页面数 handle_httpstatus_list = [404] def __init__(self): self.fail_urls = [] # dispatcher.connect(self.handle_failed_url, signals.spider_closed) @classmethod def from_crawler(cls, crawler, *args, **kwargs): spider = super(JobboleSpider, cls).from_crawler(crawler, *args, **kwargs) spider.fail_urls = [] crawler.signals.connect(spider.handle_failed_url, signals.spider_closed) return spider def handle_failed_url(self, spider, reason): self.crawler.stats.set_value('failed_urls', ','.join(self.fail_urls)) def parse(self, response): """ 1.获取文章列表页的文章url交给scrapy下载后并进行解析 2.获取下一页的url交给scrapy进行下载,下载完成后交给parse解析 """ """ 解析文章列表页中的所有文章url交给scrapy下载并进行解析 """ if response.status == 404: self.fail_urls.append(response.url) self.crawler.stats.inc_value("failed_urls") post_nodes = response.css('#archive .post-thumb a') for post_node in post_nodes: img_url = post_node.css('img::attr(src)').extract_first() # img_url = [img_url if 'http:' in img_url else ('http:' + img_url)] post_url = post_node.css('::attr(href)').extract_first() yield scrapy.Request(url=parse.urljoin(response.url, post_url), meta={'img_url': img_url}, callback=self.parse_detail) next_url = response.css('.next.page-numbers::attr(href)').extract_first() # 获取下一页的url交给scrapy下载并进行解析 if next_url: yield scrapy.Request(url=next_url, callback=self.parse) def parse_detail(self, response): # items = JobboleArticleItem() # title = response.xpath('//div[@class="entry-header"]/h1/text()')[0].extract() # create_date = response.xpath('//p[@class="entry-meta-hide-on-mobile"]/text()').extract()[0].strip().replace('·','').strip() # praise_nums = int(response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()").extract_first()) # fav_nums = response.xpath("//span[contains(@class,'bookmark-btn')]/text()").extract_first() # try: # if re.match('.*?(\d+).*', fav_nums).group(1): # fav_nums = int(re.match('.*?(\d+).*', fav_nums).group(1)) # else: # fav_nums = 0 # except: # fav_nums = 0 # comment_nums = response.xpath('//a[contains(@href,"#article-comment")]/span/text()').extract()[0] # try: # if re.match('.*?(\d+).*',comment_nums).group(1): # comment_nums = int(re.match('.*?(\d+).*',comment_nums).group(1)) # else: # comment_nums = 0 # except: # comment_nums = 0 # contente = response.xpath('//div[@class="entry"]').extract()[0] # tag_list = response.xpath('//p[@class="entry-meta-hide-on-mobile"]/a/text()').extract() # tag_list = [tag for tag in tag_list if not tag.strip().endswith('评论')] # tags = ",".join(tag_list) # items['title'] = title # try: # create_date = datetime.datetime.strptime(create_date,'%Y/%m/%d').date() # except: # create_date = datetime.datetime.now() # items['date'] = create_date # items['url'] = response.url # items['url_object_id'] = get_md5(response.url) # items['img_url'] = [img_url] # items['praise_nums'] = praise_nums # items['fav_nums'] = fav_nums # items['comment_nums'] = comment_nums # items['content'] = contente # items['tags'] = tags # 通过item loader加载item front_image_url = response.meta.get("front_image_url", "") # 文章封面图 item_loader = ArticleItemLoader(item=JobboleArticleItem(), response=response) item_loader.add_css("title", ".entry-header h1::text") item_loader.add_value("url", response.url) item_loader.add_value("url_object_id", get_md5(response.url)) item_loader.add_css("create_date", "p.entry-meta-hide-on-mobile::text") item_loader.add_value("front_image_url", [front_image_url]) item_loader.add_css("praise_nums", ".vote-post-up h10::text") item_loader.add_css("comment_nums", "a[href='#article-comment'] span::text") item_loader.add_css("fav_nums", ".bookmark-btn::text") item_loader.add_css("tags", "p.entry-meta-hide-on-mobile a::text") item_loader.add_css("content", "div.entry") article_item = item_loader.load_item() yield article_item # title = response.css('.entry-header h1::text')[0].extract() # create_date = response.css('p.entry-meta-hide-on-mobile::text').extract()[0].strip().replace('·','').strip() # praise_nums = int(response.css(".vote-post-up h10::text").extract_first() # fav_nums = response.css(".bookmark-btn::text").extract_first() # if re.match('.*?(\d+).*', fav_nums).group(1): # fav_nums = int(re.match('.*?(\d+).*', fav_nums).group(1)) # else: # fav_nums = 0 # comment_nums = response.css('a[href="#article-comment"] span::text').extract()[0] # if re.match('.*?(\d+).*', comment_nums).group(1): # comment_nums = int(re.match('.*?(\d+).*', comment_nums).group(1)) # else: # comment_nums = 0 # content = response.css('.entry').extract()[0] # tag_list = response.css('p.entry-meta-hide-on-mobile a::text') # tag_list = [tag for tag in tag_list if not tag.strip().endswith('评论')] # tags = ",".join(tag_list) # xpath选择器 /@href /text()
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from ArticleSpider import settings from ArticleSpider.items import LagouJobItemLoader,LagouJobItem from utils.common import get_md5 from datetime import datetime import random class LagouSpider(CrawlSpider): name = 'lagou' allowed_domains = ['www.lagou.com'] start_urls = ['https://www.lagou.com/'] custom_settings = { "COOKIES_ENABLED": True } rules = ( Rule(LinkExtractor(allow=('zhaopin/.*',)), follow=True), Rule(LinkExtractor(allow=('gongsi/j\d+.html',)), follow=True), Rule(LinkExtractor(allow=r'jobs/\d+.html'), callback='parse_job', follow=True), ) def parse_start_url(self, response): yield scrapy.Request(url=self.start_urls[0], cookies=settings.COOKIES, callback=self.parse) def process_results(self, response, results): return results def parse_job(self, response): #解析拉勾网的逻辑 item_loader = LagouJobItemLoader(item=LagouJobItem(),response=response) item_loader.add_css('title', '.job-name::attr(title)') item_loader.add_value('url',response.url) item_loader.add_value('url_object_id', get_md5(response.url)) item_loader.add_css('salary_min', '.job_request .salary::text') item_loader.add_css('salary_max', '.job_request .salary::text') item_loader.add_xpath('job_city',"//dd[@class='job_request']/p/span[2]/text()") item_loader.add_xpath('work_years',"//dd[@class='job_request']/p/span[3]/text()") item_loader.add_xpath('degree_need',"//dd[@class='job_request']/p/span[4]/text()") item_loader.add_xpath('job_type',"//dd[@class='job_request']/p/span[5]/text()") item_loader.add_css('tags','.position-label li::text') item_loader.add_css('publish_time','.publish_time::text') item_loader.add_css('job_advantage','.job-advantage p::text') item_loader.add_css('job_desc','.job_bt div') item_loader.add_css('job_addr','.work_addr') item_loader.add_css('company_name','.job_company dt a img::attr(alt)') item_loader.add_css('company_url','.job_company dt a::attr(href)') item_loader.add_value('crawl_time', datetime.now()) job_item = item_loader.load_item() return job_item
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy from scrapy.loader.processors import MapCompose,TakeFirst,Join import datetime from scrapy.loader import ItemLoader import re from utils.common import extract_num from settings import SQL_DATETIME_FORMAT, SQL_DATE_FORMAT from w3lib.html import remove_tags def add_jobbole(value): return value+'zhangyafei' def date_convert(value): try: value = value.strip().replace('·','').strip() create_date = datetime.datetime.strptime(value, "%Y/%m/%d").date() except Exception as e: create_date = datetime.datetime.now().date return create_date def get_nums(value): try: if re.match('.*?(\d+).*', value).group(1): nums = int(re.match('.*?(\d+).*', value).group(1)) else: nums = 0 except: nums = 0 return nums def remove_comment_tags(value): if "评论" in value: return '' return value def return_value(value): return value class ArticleItemLoader(ItemLoader): #自定义itemloader default_output_processor = TakeFirst() class JobboleArticleItem(scrapy.Item): title = scrapy.Field( input_processor=MapCompose(lambda x:x+'-jobbole',add_jobbole) ) date = scrapy.Field( input_processor=MapCompose(date_convert), output_processor=TakeFirst() ) url = scrapy.Field() url_object_id = scrapy.Field() img_url = scrapy.Field( output_processor=MapCompose(return_value) ) img_path = scrapy.Field() praise_nums = scrapy.Field( input_processor=MapCompose(get_nums) ) fav_nums = scrapy.Field( input_processor=MapCompose(get_nums) ) comment_nums = scrapy.Field( input_processor=MapCompose(get_nums) ) content = scrapy.Field() tags = scrapy.Field( input_processor=MapCompose(remove_comment_tags), output_processor = Join(',') ) def get_insert_sql(self): insert_sql = """ insert into article(title, url, create_date, fav_nums, img_url, img_path,praise_nums, comment_nums, tags, content) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s) ON DUPLICATE KEY UPDATE content=VALUES(fav_nums) """ img_url = "" # content = remove_tags(self["content"]) if self["img_url"]: img_url = self["img_url"][0] params = (self["title"], self["url"], self["date"], self["fav_nums"], img_url, self["img_path"], self["praise_nums"], self["comment_nums"], self["tags"], self["content"]) return insert_sql, params def replace_splash(value): return value.replace("/", "") def handle_strip(value): return value.strip() def handle_jobaddr(value): addr_list = value.split("\n") addr_list = [item.strip() for item in addr_list if item.strip() != "查看地图"] return "".join(addr_list) def get_salary_min(value): salary = value.split('-') salary_min = salary[0] return salary_min def get_publish_time(value): time = value.split(' ') return time[0] def get_salary_max(value): salary = value.split('-') salary_max = salary[1] return salary_max class LagouJobItemLoader(ItemLoader): #自定义itemloader default_output_processor = TakeFirst() class LagouJobItem(scrapy.Item): title = scrapy.Field() url = scrapy.Field() url_object_id = scrapy.Field() salary_min = scrapy.Field( input_processor=MapCompose(get_salary_min), ) salary_max = scrapy.Field( input_processor=MapCompose(get_salary_max), ) job_city = scrapy.Field( input_processor=MapCompose(replace_splash), ) work_years = scrapy.Field( input_processor=MapCompose(replace_splash), ) degree_need = scrapy.Field( input_processor=MapCompose(replace_splash), ) job_type = scrapy.Field() publish_time = scrapy.Field( input_processor=MapCompose(get_publish_time), ) job_advantage = scrapy.Field() job_desc = scrapy.Field( input_processor=MapCompose(handle_strip), ) job_addr = scrapy.Field( input_processor=MapCompose(remove_tags, handle_jobaddr), ) company_name = scrapy.Field( input_processor=MapCompose(handle_strip), ) company_url = scrapy.Field() tags = scrapy.Field() crawl_time = scrapy.Field() def get_insert_sql(self): insert_sql = """ insert into lagou_job(title, url, url_object_id,salary_min,salary_max, job_city, work_years, degree_need, job_type, publish_time, job_advantage, job_desc, job_addr, company_url, company_name, tags,crawl_time,job_id) VALUES (%s, %s,%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s,%s,%s,%s) ON DUPLICATE KEY UPDATE job_desc=VALUES(job_desc) """ job_id = extract_num(self["url"]) params = (self["title"], self["url"], self['url_object_id'],self["salary_min"],self['salary_max'],self["job_city"], self["work_years"], self["degree_need"], self["job_type"], self["publish_time"], self["job_advantage"], self["job_desc"], self["job_addr"], self["company_url"], self["company_name"], self['tags'],self['crawl_time'].strftime(SQL_DATETIME_FORMAT),job_id) return insert_sql, params
# -*- coding: utf-8 -*- # Define here the models for your spider middleware # # See documentation in: # https://doc.scrapy.org/en/latest/topics/spider-middleware.html import logging import time from fake_useragent import UserAgent from scrapy.http import HtmlResponse from tools.crawl_xici_ip import GetIP logger = logging.getLogger(__name__) class RandomUserAgentMiddleware(object): def __init__(self, crawler): super(RandomUserAgentMiddleware, self).__init__() self.ua = UserAgent() self.per_proxy = crawler.settings.get('RANDOM_UA_PER_PROXY', False) self.ua_type = crawler.settings.get('RANDOM_UA_TYPE', 'random') self.proxy2ua = {} @classmethod def from_crawler(cls, crawler): return cls(crawler) def process_request(self, request, spider): def get_ua(): '''Gets random UA based on the type setting (random, firefox…)''' return getattr(self.ua, self.ua_type) if self.per_proxy: proxy = request.meta.get('proxy') if proxy not in self.proxy2ua: self.proxy2ua[proxy] = get_ua() logger.debug('Assign User-Agent %s to Proxy %s' % (self.proxy2ua[proxy], proxy)) request.headers.setdefault('User-Agent', self.proxy2ua[proxy]) else: ua = get_ua() request.headers.setdefault('User-Agent', ua) class RandomProxyMiddleware(object): def process_request(self, request, spider): # get_ip = GetIP() # proxy = get_ip.get_random_ip() request.meta["proxy"] = 'http://118.190.95.35:9001' class JspageMiddleware(object): #通过Chrome方式请求 def process_request(self,request,spider): if spider.name == 'jobbole': # browser = webdriver.Chrome() spider.browser.get(request.url) time.sleep(3) print("访问:{}".format(request.url)) return HtmlResponse(url=spider.browser.current_url,body=spider.page_source,encoding='utf-8',request=request) #windows下有问题,在linux下试一试 # sudo apt-get install xvfb # pip install xvfbwrapper # from pyvirtualdisplay import Display # from selenium import webdriver # # display = Display(visible=0, size=(800, 600)) # display.start() # # browser = webdriver.Chrome() # browser.get('https://www.taobao.com')
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html from scrapy.pipelines.images import ImagesPipeline import scrapy import codecs import json from scrapy.exporters import JsonItemExporter import pymysql from twisted.enterprise import adbapi import re class ArticlespiderPipeline(object): def process_item(self, item, spider): return item class MysqlPipeline(object): def __init__(self): self.conn = pymysql.connect('localhost', 'root','0000', 'crawed', charset='utf8', use_unicode=True) self.cursor = self.conn.cursor() def process_item(self, item, spider): insert_sql = """insert into article(title,url,create_date,fav_nums) values (%s,%s,%s,%s)""" self.cursor.execute(insert_sql,(item['title'],item['url'],item['date'],item['fav_nums'])) self.conn.commit() class MysqlTwistePipeline(object): def __init__(self, dbpool): self.dbpool = dbpool @classmethod def from_settings(cls,settings): dbparms = dict( host=settings['MYSQL_HOST'], db=settings['MYSQL_DB'], user=settings['MYSQL_USER'], password=settings['MYSQL_PASSWORD'], charset='utf8', cursorclass=pymysql.cursors.DictCursor, use_unicode=True, ) dbpool = adbapi.ConnectionPool('pymysql',**dbparms) return cls(dbpool) def process_item(self, item, spider): #使用twisted将mysql插入变异步执行 query = self.dbpool.runInteraction(self.do_insert,item) # query.addErrorback(self.handle_error) #处理异常 query.addErrback(self.handle_error) #处理异常 def handle_error(self,failure): #处理异步插入的异常 print(failure) def do_insert(self,cursor,item): insert_sql, params = item.get_insert_sql() try: cursor.execute(insert_sql,params) print('插入成功') except Exception as e: print('插入失败') class ArticleImagesPipeline(ImagesPipeline): #调用scrapy提供的imagepipeline下载图片 def item_completed(self, results, item, info): if "img_url" in item: for ok,value in results: img_path = value['path'] item['img_path'] = img_path return item def get_media_requests(self, item, info): # 下载图片 if "img_url" in item: for img_url in item['img_url']: yield scrapy.Request(img_url, meta={'item': item, 'index': item['img_url'].index(img_url)}) # 添加meta是为了下面重命名文件名使用 def file_path(self, request, response=None, info=None): item = request.meta['item'] if "img_url" in item:# 通过上面的meta传递过来item index = request.meta['index'] # 通过上面的index传递过来列表中当前下载图片的下标 # 图片文件名,item['carname'][index]得到汽车名称,request.url.split('/')[-1].split('.')[-1]得到图片后缀jpg,png image_guid = item['title'] + '.' + request.url.split('/')[-1].split('.')[-1] # 图片下载目录 此处item['country']即需要前面item['country']=''.join()......,否则目录名会变成\u97e9\u56fd\u6c7d\u8f66\u6807\u5fd7\xxx.jpg filename = u'full/{0}'.format(image_guid) return filename class JsonExporterPipeline(JsonItemExporter): #调用scrapy提供的json export 导出json文件 def __init__(self): self.file = open('articleexpoter.json','wb') self.exporter = JsonItemExporter(self.file, encoding='utf-8', ensure_ascii=False) self.exporter.start_exporting()#开始导出 def close_spider(self): self.exporter.finish_exporting() #停止导出 self.file.close() def process_item(self, item, spider): self.exporter.export_item(item) return item class JsonWithEncodingPipeline(object): #自定义json文件的导出 def __init__(self): self.file = codecs.open('article.json','w',encoding='utf-8') def process_item(self,item,spider): lines = json.dumps(dict(item), ensure_ascii=False) + '\n' self.file.write(lines) return item def spider_closed(self): self.file.close()
# -*- coding: utf-8 -*- """ @Datetime: 2018/8/4 @Author: Zhang Yafei """ import hashlib import re def get_md5(url): if isinstance(url,str): url = url.encode('utf-8') m = hashlib.md5() m.update(url) return m.hexdigest() def extract_num(text): #从字符串中提取出数字 match_re = re.match(".*?(\d+).*", text) if match_re: nums = int(match_re.group(1)) else: nums = 0 return nums if __name__ == '__main__': url = input("请输入要加密的url地址:") print('md5:', get_md5(url))
# -*- coding: utf-8 -*- # Scrapy settings for step8_king project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # http://doc.scrapy.org/en/latest/topics/settings.html # http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html # http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html # 1. 爬虫名称 BOT_NAME = 'step8_king' # 2. 爬虫应用路径 SPIDER_MODULES = ['step8_king.spiders'] NEWSPIDER_MODULE = 'step8_king.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent # 3. 客户端 user-agent请求头 # USER_AGENT = 'step8_king (+http://www.yourdomain.com)' # Obey robots.txt rules # 4. 禁止爬虫配置 # ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16) # 5. 并发请求数 # CONCURRENT_REQUESTS = 4 # Configure a delay for requests for the same website (default: 0) # See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs # 6. 延迟下载秒数 # DOWNLOAD_DELAY = 2 # The download delay setting will honor only one of: # 7. 单域名访问并发数,并且延迟下次秒数也应用在每个域名 # CONCURRENT_REQUESTS_PER_DOMAIN = 2 # 单IP访问并发数,如果有值则忽略:CONCURRENT_REQUESTS_PER_DOMAIN,并且延迟下次秒数也应用在每个IP # CONCURRENT_REQUESTS_PER_IP = 3 # Disable cookies (enabled by default) # 8. 是否支持cookie,cookiejar进行操作cookie # COOKIES_ENABLED = True # COOKIES_DEBUG = True # Disable Telnet Console (enabled by default) # 9. Telnet用于查看当前爬虫的信息,操作爬虫等... # 使用telnet ip port ,然后通过命令操作 # TELNETCONSOLE_ENABLED = True # TELNETCONSOLE_HOST = '127.0.0.1' # TELNETCONSOLE_PORT = [6023,] # 10. 默认请求头 # Override the default request headers: # DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', # } # Configure item pipelines # See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html # 11. 定义pipeline处理请求 # ITEM_PIPELINES = { # 'step8_king.pipelines.JsonPipeline': 700, # 'step8_king.pipelines.FilePipeline': 500, # } # 12. 自定义扩展,基于信号进行调用 # Enable or disable extensions # See http://scrapy.readthedocs.org/en/latest/topics/extensions.html # EXTENSIONS = { # # 'step8_king.extensions.MyExtension': 500, # } # 13. 爬虫允许的最大深度,可以通过meta查看当前深度;0表示无深度 # DEPTH_LIMIT = 3 # 14. 爬取时,0表示深度优先Lifo(默认);1表示广度优先FiFo # 后进先出,深度优先 # DEPTH_PRIORITY = 0 # SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleLifoDiskQueue' # SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.LifoMemoryQueue' # 先进先出,广度优先 # DEPTH_PRIORITY = 1 # SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleFifoDiskQueue' # SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.FifoMemoryQueue' # 15. 调度器队列 # SCHEDULER = 'scrapy.core.scheduler.Scheduler' # from scrapy.core.scheduler import Scheduler # 16. 访问URL去重 # DUPEFILTER_CLASS = 'step8_king.duplication.RepeatUrl' # Enable and configure the AutoThrottle extension (disabled by default) # See http://doc.scrapy.org/en/latest/topics/autothrottle.html """ 17. 自动限速算法 from scrapy.contrib.throttle import AutoThrottle 自动限速设置 1. 获取最小延迟 DOWNLOAD_DELAY 2. 获取最大延迟 AUTOTHROTTLE_MAX_DELAY 3. 设置初始下载延迟 AUTOTHROTTLE_START_DELAY 4. 当请求下载完成后,获取其"连接"时间 latency,即:请求连接到接受到响应头之间的时间 5. 用于计算的... AUTOTHROTTLE_TARGET_CONCURRENCY target_delay = latency / self.target_concurrency new_delay = (slot.delay + target_delay) / 2.0 # 表示上一次的延迟时间 new_delay = max(target_delay, new_delay) new_delay = min(max(self.mindelay, new_delay), self.maxdelay) slot.delay = new_delay """ # 开始自动限速 # AUTOTHROTTLE_ENABLED = True # The initial download delay # 初始下载延迟 # AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies # 最大下载延迟 # AUTOTHROTTLE_MAX_DELAY = 10 # The average number of requests Scrapy should be sending in parallel to each remote server # 平均每秒并发数 # AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: # 是否显示 # AUTOTHROTTLE_DEBUG = True # Enable and configure HTTP caching (disabled by default) # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings """ 18. 启用缓存 目的用于将已经发送的请求或相应缓存下来,以便以后使用 from scrapy.downloadermiddlewares.httpcache import HttpCacheMiddleware from scrapy.extensions.httpcache import DummyPolicy from scrapy.extensions.httpcache import FilesystemCacheStorage """ # 是否启用缓存策略 # HTTPCACHE_ENABLED = True # 缓存策略:所有请求均缓存,下次在请求直接访问原来的缓存即可 # HTTPCACHE_POLICY = "scrapy.extensions.httpcache.DummyPolicy" # 缓存策略:根据Http响应头:Cache-Control、Last-Modified 等进行缓存的策略 # HTTPCACHE_POLICY = "scrapy.extensions.httpcache.RFC2616Policy" # 缓存超时时间 # HTTPCACHE_EXPIRATION_SECS = 0 # 缓存保存路径 # HTTPCACHE_DIR = 'httpcache' # 缓存忽略的Http状态码 # HTTPCACHE_IGNORE_HTTP_CODES = [] # 缓存存储的插件 # HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' """ 19. 代理,需要在环境变量中设置 from scrapy.contrib.downloadermiddleware.httpproxy import HttpProxyMiddleware 方式一:使用默认 os.environ { http_proxy:http://root:woshiniba@192.168.11.11:9999/ https_proxy:http://192.168.11.11:9999/ } 方式二:使用自定义下载中间件 def to_bytes(text, encoding=None, errors='strict'): if isinstance(text, bytes): return text if not isinstance(text, six.string_types): raise TypeError('to_bytes must receive a unicode, str or bytes ' 'object, got %s' % type(text).__name__) if encoding is None: encoding = 'utf-8' return text.encode(encoding, errors) class ProxyMiddleware(object): def process_request(self, request, spider): PROXIES = [ {'ip_port': '111.11.228.75:80', 'user_pass': ''}, {'ip_port': '120.198.243.22:80', 'user_pass': ''}, {'ip_port': '111.8.60.9:8123', 'user_pass': ''}, {'ip_port': '101.71.27.120:80', 'user_pass': ''}, {'ip_port': '122.96.59.104:80', 'user_pass': ''}, {'ip_port': '122.224.249.122:8088', 'user_pass': ''}, ] proxy = random.choice(PROXIES) if proxy['user_pass'] is not None: request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port']) encoded_user_pass = base64.encodestring(to_bytes(proxy['user_pass'])) request.headers['Proxy-Authorization'] = to_bytes('Basic ' + encoded_user_pass) print "**************ProxyMiddleware have pass************" + proxy['ip_port'] else: print "**************ProxyMiddleware no pass************" + proxy['ip_port'] request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port']) DOWNLOADER_MIDDLEWARES = { 'step8_king.middlewares.ProxyMiddleware': 500, } """ """ 20. Https访问 Https访问时有两种情况: 1. 要爬取网站使用的可信任证书(默认支持) DOWNLOADER_HTTPCLIENTFACTORY = "scrapy.core.downloader.webclient.ScrapyHTTPClientFactory" DOWNLOADER_CLIENTCONTEXTFACTORY = "scrapy.core.downloader.contextfactory.ScrapyClientContextFactory" 2. 要爬取网站使用的自定义证书 DOWNLOADER_HTTPCLIENTFACTORY = "scrapy.core.downloader.webclient.ScrapyHTTPClientFactory" DOWNLOADER_CLIENTCONTEXTFACTORY = "step8_king.https.MySSLFactory" # https.py from scrapy.core.downloader.contextfactory import ScrapyClientContextFactory from twisted.internet.ssl import (optionsForClientTLS, CertificateOptions, PrivateCertificate) class MySSLFactory(ScrapyClientContextFactory): def getCertificateOptions(self): from OpenSSL import crypto v1 = crypto.load_privatekey(crypto.FILETYPE_PEM, open('/Users/wupeiqi/client.key.unsecure', mode='r').read()) v2 = crypto.load_certificate(crypto.FILETYPE_PEM, open('/Users/wupeiqi/client.pem', mode='r').read()) return CertificateOptions( privateKey=v1, # pKey对象 certificate=v2, # X509对象 verify=False, method=getattr(self, 'method', getattr(self, '_ssl_method', None)) ) 其他: 相关类 scrapy.core.downloader.handlers.http.HttpDownloadHandler scrapy.core.downloader.webclient.ScrapyHTTPClientFactory scrapy.core.downloader.contextfactory.ScrapyClientContextFactory 相关配置 DOWNLOADER_HTTPCLIENTFACTORY DOWNLOADER_CLIENTCONTEXTFACTORY """ """ 21. 爬虫中间件 class SpiderMiddleware(object): def process_spider_input(self,response, spider): ''' 下载完成,执行,然后交给parse处理 :param response: :param spider: :return: ''' pass def process_spider_output(self,response, result, spider): ''' spider处理完成,返回时调用 :param response: :param result: :param spider: :return: 必须返回包含 Request 或 Item 对象的可迭代对象(iterable) ''' return result def process_spider_exception(self,response, exception, spider): ''' 异常调用 :param response: :param exception: :param spider: :return: None,继续交给后续中间件处理异常;含 Response 或 Item 的可迭代对象(iterable),交给调度器或pipeline ''' return None def process_start_requests(self,start_requests, spider): ''' 爬虫启动时调用 :param start_requests: :param spider: :return: 包含 Request 对象的可迭代对象 ''' return start_requests 内置爬虫中间件: 'scrapy.contrib.spidermiddleware.httperror.HttpErrorMiddleware': 50, 'scrapy.contrib.spidermiddleware.offsite.OffsiteMiddleware': 500, 'scrapy.contrib.spidermiddleware.referer.RefererMiddleware': 700, 'scrapy.contrib.spidermiddleware.urllength.UrlLengthMiddleware': 800, 'scrapy.contrib.spidermiddleware.depth.DepthMiddleware': 900, """ # from scrapy.contrib.spidermiddleware.referer import RefererMiddleware # Enable or disable spider middlewares # See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html SPIDER_MIDDLEWARES = { # 'step8_king.middlewares.SpiderMiddleware': 543, } """ 22. 下载中间件 class DownMiddleware1(object): def process_request(self, request, spider): ''' 请求需要被下载时,经过所有下载器中间件的process_request调用 :param request: :param spider: :return: None,继续后续中间件去下载; Response对象,停止process_request的执行,开始执行process_response Request对象,停止中间件的执行,将Request重新调度器 raise IgnoreRequest异常,停止process_request的执行,开始执行process_exception ''' pass def process_response(self, request, response, spider): ''' spider处理完成,返回时调用 :param response: :param result: :param spider: :return: Response 对象:转交给其他中间件process_response Request 对象:停止中间件,request会被重新调度下载 raise IgnoreRequest 异常:调用Request.errback ''' print('response1') return response def process_exception(self, request, exception, spider): ''' 当下载处理器(download handler)或 process_request() (下载中间件)抛出异常 :param response: :param exception: :param spider: :return: None:继续交给后续中间件处理异常; Response对象:停止后续process_exception方法 Request对象:停止中间件,request将会被重新调用下载 ''' return None 默认下载中间件 { 'scrapy.contrib.downloadermiddleware.robotstxt.RobotsTxtMiddleware': 100, 'scrapy.contrib.downloadermiddleware.httpauth.HttpAuthMiddleware': 300, 'scrapy.contrib.downloadermiddleware.downloadtimeout.DownloadTimeoutMiddleware': 350, 'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': 400, 'scrapy.contrib.downloadermiddleware.retry.RetryMiddleware': 500, 'scrapy.contrib.downloadermiddleware.defaultheaders.DefaultHeadersMiddleware': 550, 'scrapy.contrib.downloadermiddleware.redirect.MetaRefreshMiddleware': 580, 'scrapy.contrib.downloadermiddleware.httpcompression.HttpCompressionMiddleware': 590, 'scrapy.contrib.downloadermiddleware.redirect.RedirectMiddleware': 600, 'scrapy.contrib.downloadermiddleware.cookies.CookiesMiddleware': 700, 'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': 750, 'scrapy.contrib.downloadermiddleware.chunked.ChunkedTransferMiddleware': 830, 'scrapy.contrib.downloadermiddleware.stats.DownloaderStats': 850, 'scrapy.contrib.downloadermiddleware.httpcache.HttpCacheMiddleware': 900, } """ # from scrapy.contrib.downloadermiddleware.httpauth import HttpAuthMiddleware # Enable or disable downloader middlewares # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html # DOWNLOADER_MIDDLEWARES = { # 'step8_king.middlewares.DownMiddleware1': 100, # 'step8_king.middlewares.DownMiddleware2': 500, # } #23 Logging日志功能 Scrapy提供了log功能,可以通过 logging 模块使用 可以修改配置文件settings.py,任意位置添加下面两行 LOG_FILE = "mySpider.log" LOG_LEVEL = "INFO" Scrapy提供5层logging级别: CRITICAL - 严重错误(critical) ERROR - 一般错误(regular errors) WARNING - 警告信息(warning messages) INFO - 一般信息(informational messages) DEBUG - 调试信息(debugging messages) logging设置 通过在setting.py中进行以下设置可以被用来配置logging: LOG_ENABLED 默认: True,启用logging LOG_ENCODING 默认: 'utf-8',logging使用的编码 LOG_FILE 默认: None,在当前目录里创建logging输出文件的文件名 LOG_LEVEL 默认: 'DEBUG',log的最低级别 LOG_STDOUT 默认: False 如果为 True,进程所有的标准输出(及错误)将会被重定向到log中。例如,执行 print "hello" ,其将会在Scrapy log中显示 settings
# -*- coding: utf-8 -*- """ @Datetime: 2018/8/31 @Author: Zhang Yafei """ class RepeatFilter(object): def __init__(self): self.visited_urls = set() @classmethod def from_settings(cls, settings): return cls() def request_seen(self, request): if request.url in self.visited_urls: return True else: print(request.url) self.visited_urls.add(request.url) return False def open(self): # can return deferred print('open') pass def close(self, reason): # can return a deferred print('close') pass def log(self, request, spider): # log that a request has been filtered pass
# -*- coding: utf-8 -*- """ @Datetime: 2018/8/31 @Author: Zhang Yafei """ from scrapy import signals class MyExtend(): def __init__(self,crawler): self.crawler = crawler #钩子上挂障碍物 #在指定信息上注册操作 crawler.signals.connect(self.start,signals.engine_started) crawler.signals.connect(self.close,signals.engine_stopped) @classmethod def from_crawler(cls,crawler): return cls(crawler) def start(self): print('signals.engine_started start') def close(self): print('signals.engine_stopped close')
# -*- coding: utf-8 -*- """ @Datetime: 2018/8/31 @Author: Zhang Yafei """ from scrapy.cmdline import execute import sys import os sys.path.append(os.path.dirname(__file__)) # execute(['scrapy','crawl','spiderchouti','--nolog']) # os.system('scrapy crawl xiaohua') os.system('scrapy crawl choutilike')
# -*- coding: utf-8 -*- """ @Datetime: 2018/9/1 @Author: Zhang Yafei """ from twisted.internet import reactor #事件循环(终止条件:所有的socket都已经移除) from twisted.web.client import getPage #socket对象(如果下载完成,自动从事件循环中移出。。。) from twisted.internet import defer #defer.Deferred 特殊的socket对象(不会发请求,手动移出) class Request(object): def __init__(self,url,callback): self.url = url self.callback = callback class HttpResponse(object): def __init__(self,content,request): self.content = content self.request = request self.url = request.url self.text = str(content,encoding='utf-8') class ChoutiSpider(object): name = 'chouti' def start_requests(self): start_url = ['http://www.baidu.com','https://v.qq.com/',] for url in start_url: yield Request(url,self.parse) def parse(self,response): # print(response.text) #response是HttpResponse对象 print(response.url) # print(response.content) # print(response.request) # yield Request('http://www.cnblogs.com',callback=self.parse) #无限循环 #1.crawling 移除 #2.获取parse yield值 #3.再次去队列中获取 import queue Q = queue.Queue() class Engine(object): def __init__(self): self._close = None self.max = 5 self.crawling = [] def get_response_callback(self,content,request): self.crawling.remove(request) rep = HttpResponse(content,request) result = request.callback(rep) #调用parse方法 import types if isinstance(result,types.GeneratorType): for ret in result: Q.put(ret) #再次去队列中取值 def _next_request(self): """ 去取request对象,并发送请求 最大并发限制 :return: """ if Q.qsize() == 0 and len(self.crawling) == 0: self._close.callback(None) return if len(self.crawling) >= self.max: return while len(self.crawling) < self.max: try: req = Q.get(block=False) self.crawling.append(req) d = getPage(req.url.encode('utf-8')) #页面下载完成,get_response_callback,调用用户spider中定义的parse方法,并且将新请求添加到调度器 d.addCallback(self.get_response_callback,req) #未达到最大并发数,可以再次去调度器中获取Request d.addCallback(lambda _:reactor.callLater(0,self._next_request)) except Exception as e: return @defer.inlineCallbacks def crawl(self,spider): #将初始Request对象添加到调度器 start_requests = iter(spider.start_requests()) #生成器转迭代器 while True: try: request = next(start_requests) Q.put(request) except StopIteration as e: break #去调度器里面取request,并发送请求 # self._next_request() reactor.callLater(0, self._next_request) self._close = defer.Deferred() yield self._close #yield一个defer对象或getPage对象 _active = set() engine = Engine()#创建一个引擎对象 spider = ChoutiSpider() d = engine.crawl(spider) #把每一个spider放入到引擎中 _active.add(d) #将每一个引擎放入到集合中 dd = defer.DeferredList(_active) dd.addBoth(lambda _:reactor.stop()) #自动终止事件循环 reactor.run()
补充:关于scrapy.selector选择器和lxml选择的用法
# lxml选择器 response = requests.get(url, headers=headers).text result = etree.HTML(response) hrefs = result.xpath('//div[@class="info-primary"]/h3/a/@href') # scrapy的selector选择器 response = requests.get(url,headers=headers) selector = Selector(response) job_name = selector.css('.name h1::text')[0].extract()
十、多线程和异步开发
# -*- coding: utf-8 -*- """ @Datetime: 2018/8/30 @Author: Zhang Yafei """ """ 可以实现并发 但是,请求发送之后和返回之前,中间时间线程空闲 编写方式: -直接返回处理 -编写回调函数处理 """ ######## 编写方式一 ##### """ import requests from concurrent.futures import ThreadPoolExecutor pool = ThreadPoolExecutor() def task(url): response = requests.get(url) print(url,response) url_list = [ 'https://www.zhihu.com/', 'https://www.sina.com.cn/', 'https://v.qq.com/', 'http://www.sohu.com/', 'https://www.163.com/', ] for url in url_list: pool.submit(task,url) pool.shutdown(wait=True) """ #########编写方式二######### import requests from concurrent.futures import ThreadPoolExecutor pool = ThreadPoolExecutor() def task(url): response = requests.get(url) return response def done(future,*args,**kwargs): response = future.result() # print(future.result(),args,kwargs) print(response.status_code) url_list = [ 'https://www.zhihu.com/', 'https://www.sina.com.cn/', 'https://v.qq.com/', 'http://www.sohu.com/', 'https://www.163.com/', ] for url in url_list: v = pool.submit(task,url) v.add_done_callback(done) pool.shutdown(wait=True)
# -*- coding: utf-8 -*- """ @Datetime: 2018/8/30 @Author: Zhang Yafei """ """ 可以实现并发 但是,请求发送之后和返回之前,中间时间线程空闲 编写方式: -直接返回处理 -编写回调函数处理 """ ######## 编写方式一 ##### """ import requests from concurrent.futures import ProcessPoolExecutor pool = ProcessPoolExecutor() def task(url): response = requests.get(url) print(url,response) url_list = [ 'https://www.zhihu.com/', 'https://www.sina.com.cn/', 'https://v.qq.com/', 'http://www.sohu.com/', 'https://www.163.com/', ] for url in url_list: pool.submit(task,url) pool.shutdown(wait=True) """ #########编写方式二######### import requests from concurrent.futures import ProcessPoolExecutor pool = ProcessPoolExecutor() def task(url): response = requests.get(url) return response def done(future,*args,**kwargs): response = future.result() # print(future.result(),args,kwargs) print(response.status_code) url_list = [ 'https://www.zhihu.com/', 'https://www.sina.com.cn/', 'https://v.qq.com/', 'http://www.sohu.com/', 'https://www.163.com/', 'https://www.douban.com/', ] for url in url_list: v = pool.submit(task,url) v.add_done_callback(done) pool.shutdown(wait=True)
# -*- coding: utf-8 -*- """ @Datetime: 2018/8/30 @Author: Zhang Yafei """ """ import asyncio @asyncio.coroutine def task(): print('before...task...') yield from asyncio.sleep(5) #发送HTTP请求,支持TCP,获取结果 print('end...task...') tasks = [task(),task()] loop = asyncio.get_event_loop() loop.run_until_complete(asyncio.gather(*tasks)) loop.close() """ """ import asynico @asyncio.coroutine def task(host, url='/'): print('start',host, url) reader, writer = yield from asyncio.open_connection(host, 80) request_header_content = "GET %s HTTP/1.0\r\nHost: %s\r\n\r\n" % (url, host,) request_header_content = bytes(request_header_content, encoding='utf-8') writer.write(request_header_content) yield from writer.drain() text = yield from reader.read() print('end',host, url, text) writer.close() tasks = [ task('www.cnblogs.com', '/wupeiqi/'), task('dig.chouti.com', '/pic/show?nid=4073644713430508&lid=10273091') ] loop = asyncio.get_event_loop() results = loop.run_until_complete(asyncio.gather(*tasks)) loop.close() """ """ import aiohttp import asyncio @asyncio.coroutine def fetch_async(url): print(url) response = yield from aiohttp.request('GET', url) print(url, response) response.close() tasks = [fetch_async('http://www.baidu.com/'), fetch_async('http://www.chouti.com/')] event_loop = asyncio.get_event_loop() results = event_loop.run_until_complete(asyncio.gather(*tasks)) event_loop.close() """ """ import asyncio import requests @asyncio.coroutine def fetch_async(func, *args): print(func,args) loop = asyncio.get_event_loop() future = loop.run_in_executor(None, func, *args) response = yield from future print(response.url, response.content) tasks = [ fetch_async(requests.get, 'http://www.cnblogs.com/wupeiqi/'), fetch_async(requests.get, 'http://dig.chouti.com/pic/show?nid=4073644713430508&lid=10273091') ] loop = asyncio.get_event_loop() results = loop.run_until_complete(asyncio.gather(*tasks)) loop.close() """ import gevent import requests from gevent import monkey monkey.patch_all() def fetch_async(method, url, req_kwargs): print(method, url, req_kwargs) response = requests.request(method=method, url=url, **req_kwargs) print(response.url, response.content) # # ##### 发送请求 ##### # gevent.joinall([ # gevent.spawn(fetch_async, method='get', url='https://www.python.org/', req_kwargs={}), # gevent.spawn(fetch_async, method='get', url='https://www.yahoo.com/', req_kwargs={}), # gevent.spawn(fetch_async, method='get', url='https://github.com/', req_kwargs={}), # ]) ##### 发送请求(协程池控制最大协程数量) ##### from gevent.pool import Pool pool = Pool(None) gevent.joinall([ pool.spawn(fetch_async, method='get', url='https://www.python.org/', req_kwargs={}), pool.spawn(fetch_async, method='get', url='https://www.yahoo.com/', req_kwargs={}), pool.spawn(fetch_async, method='get', url='https://www.github.com/', req_kwargs={}), ])
# -*- coding: utf-8 -*- """ @Datetime: 2018/8/30 @Author: Zhang Yafei """ import grequests request_list = [ grequests.get('http://httpbin.org/delay/1', timeout=0.001), grequests.get('http://www.baidu.com/'), grequests.get('https://www.cnblogs.com/wupeiqi/articles/6216618.html') ] ##### 执行并获取响应列表 ##### response_list = grequests.map(request_list) for response in response_list: if response: response.encoding = response.apparent_encoding print(response.text) # print(response_list) # ##### 执行并获取响应列表(处理异常) ##### # def exception_handler(request, exception): # print(request,exception) # print("Request failed") # response_list = grequests.map(request_list, exception_handler=exception_handler) # print(response_list)
#!/usr/bin/env python # -*- coding:utf-8 -*- from twisted.internet import defer from twisted.web.client import getPage from twisted.internet import reactor def one_done(arg): print(arg) def all_done(arg): print('done') reactor.stop() @defer.inlineCallbacks def task(url): res = getPage(bytes(url, encoding='utf8')) # 发送Http请求 res.addCallback(one_done) yield res url_list = [ 'http://www.cnblogs.com', 'http://www.cnblogs.com', 'http://www.cnblogs.com', 'http://www.cnblogs.com', ] defer_list = [] # [特殊,特殊,特殊(已经向url发送请求)] for url in url_list: v = task(url) defer_list.append(v) d = defer.DeferredList(defer_list) d.addBoth(all_done) reactor.run() # 死循环
#!/usr/bin/env python # -*- coding:utf-8 -*- from tornado.httpclient import AsyncHTTPClient from tornado.httpclient import HTTPRequest from tornado import ioloop COUNT = 0 def handle_response(response): global COUNT COUNT -= 1 if response.error: print("Error:", response.error) else: print(response.body) # 方法同twisted # ioloop.IOLoop.current().stop() if COUNT == 0: ioloop.IOLoop.current().stop() def func(): url_list = [ 'http://www.baidu.com', 'http://www.bing.com', ] global COUNT COUNT = len(url_list) for url in url_list: print(url) http_client = AsyncHTTPClient() http_client.fetch(HTTPRequest(url), handle_response) ioloop.IOLoop.current().add_callback(func) ioloop.IOLoop.current().start() # 死循环
# -*- coding: utf-8 -*- """ @Datetime: 2018/8/31 @Author: Zhang Yafei """ import socket import select """ ########http请求本质,IO阻塞######## sk = socket.socket() #1.连接 sk.connect(('www.baidu.com',80,)) #阻塞 print('连接成功了') #2.连接成功后发送消息 sk.send(b"GET / HTTP/1.0\r\nHost: baidu.com\r\n\r\n") #3.等待服务端响应 data = sk.recv(8096)#阻塞 print(data) #\r\n\r\n区分响应头和影响体 #关闭连接 sk.close() """ """ ########http请求本质,IO非阻塞######## sk = socket.socket() sk.setblocking(False) #1.连接 try: sk.connect(('www.baidu.com',80,)) #非阻塞,但会报错 print('连接成功了') except BlockingIOError as e: print(e) #2.连接成功后发送消息 sk.send(b"GET / HTTP/1.0\r\nHost: baidu.com\r\n\r\n") #3.等待服务端响应 data = sk.recv(8096)#阻塞 print(data) #\r\n\r\n区分响应头和影响体 #关闭连接 sk.close() """ class HttpRequest: def __init__(self,sk,host,callback): self.socket = sk self.host = host self.callback = callback def fileno(self): return self.socket.fileno() class HttpResponse: def __init__(self,recv_data): self.recv_data = recv_data self.header_dict = {} self.body = None self.initialize() def initialize(self): headers, body = self.recv_data.split(b'\r\n\r\n', 1) self.body = body header_list = headers.split(b'\r\n') for h in header_list: h_str = str(h,encoding='utf-8') v = h_str.split(':',1) if len(v) == 2: self.header_dict[v[0]] = v[1] class AsyncRequest: def __init__(self): self.conn = [] self.connection = [] # 用于检测是否已经连接成功 def add_request(self,host,callback): try: sk = socket.socket() sk.setblocking(0) sk.connect((host,80)) except BlockingIOError as e: pass request = HttpRequest(sk,host,callback) self.conn.append(request) self.connection.append(request) def run(self): while True: rlist,wlist,elist = select.select(self.conn,self.connection,self.conn,0.05) for w in wlist: print(w.host,'连接成功...') # 只要能循环到,表示socket和服务器端已经连接成功 tpl = "GET / HTTP/1.0\r\nHost:%s\r\n\r\n" %(w.host,) w.socket.send(bytes(tpl,encoding='utf-8')) self.connection.remove(w) for r in rlist: # r,是HttpRequest recv_data = bytes() while True: try: chunck = r.socket.recv(8096) recv_data += chunck except Exception as e: break response = HttpResponse(recv_data) r.callback(response) r.socket.close() self.conn.remove(r) if len(self.conn) == 0: break def f1(response): print('保存到文件',response.header_dict) def f2(response): print('保存到数据库', response.header_dict) url_list = [ {'host':'www.youku.com','callback': f1}, {'host':'v.qq.com','callback': f2}, {'host':'www.cnblogs.com','callback': f2}, ] req = AsyncRequest() for item in url_list: req.add_request(item['host'],item['callback']) req.run()
补充:headers的获取
In [1]: from fake_useragent import UserAgent In [2]: ua = UserAgent() # ua = UserAgent(cache=False) ua = UserAgent(use_cache_server=False) In [3]: ua.random Out[3]: 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4 SLCC2; .NET CLR 2.0.50727; InfoPath.3; .NET4.0C; .NET4.0E; .NET CLR 3.5.3072 NET CLR 3.0.30729; MS-RTC LM 8)' In [4]: ua.chrome Out[4]: 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) ome/27.0.1453.93 Safari/537.36' In [5]: ua.firefox Out[5]: 'Mozilla/5.0 (Windows NT 6.1; rv:27.3) Gecko/20130101 Firefox/27.3' In [6]: ua.ie Out[6]: 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5 SLCC2; Media Center PC 6.0; InfoPath.3; MS-RTC LM 8; Zune 4.7)' In [7]: ua.opera Out[7]: 'Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14' In [8]: ua.safari Out[8]: 'Mozilla/5.0 (Windows; U; Windows NT 6.1; zh-HK) AppleWebKit/533.18. HTML, like Gecko) Version/5.0.2 Safari/533.18.5' In [9]: ua.google Out[9]: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 ML, like Gecko) Chrome/41.0.2227.1 Safari/537.36' In [10]: ua.msie Out[10]: 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/ SLCC2; Media Center PC 6.0; InfoPath.3; MS-RTC LM 8; Zune 4.7)' from fake_useragent import UserAgent ua = UserAgent() ua.update()
案例:
# -*- coding: utf-8 -*- """ @Datetime: 2018/8/29 @Author: Zhang Yafei """ import json import requests from fake_useragent import UserAgent from proxy import GetIP ua = UserAgent() session = requests.Session() headers = { 'referer': 'https://dig.chouti.com/', 'User-Agent':ua.random, } def read_cookies(): with open('chouti_cookies.json','r') as f: # cookies = json.loads(f.read()) cookies = json.load(f) return cookies def get_cookies(): url = 'https://dig.chouti.com/login' data = { 'phone': '8615735177116', 'password': 'zyf123', 'oneMonth': '', } session.headers = headers response = session.post(url,data=data) cookies_dict = response.cookies.get_dict() cookies = requests.utils.cookiejar_from_dict(cookies_dict) # session.cookies = cookies return cookies_dict.get('gpsd') # with open('chouti_cookies.json','w') as f: # json.dump(cookies_dict,f) def spider(): # cookies = read_cookies() url = 'https://dig.chouti.com/user/link/saved/1' response = session.get(url) print(response.text) def like(): url = 'https://dig.chouti.com/link/vote?linksId=21771756' cookies = {'gpsd':get_cookies()} response = session.post(url,cookies=cookies) print(response.text) if __name__ == '__main__': """登录获取cookies""" get_cookies() # spider() like()
# -*- coding: utf-8 -*- __date__ = 2018-8-8 __author__ = 'ZhangYafei' import requests from scrapy.selector import Selector import pymysql conn = pymysql.connect(host="localhost", user="root", passwd="0000", db="crawed", charset="utf8") cursor = conn.cursor() def crawl_ips(): #爬取西刺的免费ip代理 headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0"} for i in range(1568): re = requests.get("http://www.xicidaili.com/nn/{0}".format(i), headers=headers) selector = Selector(text=re.text) all_trs = selector.css("#ip_list tr") ip_list = [] for tr in all_trs[1:]: speed_str = tr.css(".bar::attr(title)").extract()[0] if speed_str: speed = float(speed_str.split("秒")[0]) all_texts = tr.css("td::text").extract() ip = all_texts[0] port = all_texts[1] try: position = tr.xpath('td[4]/a/text()').extract()[0] except Exception as e: print(e) position = '未知' proxy_type = all_texts[5] live_time = all_texts[10] try: update_time = all_texts[11] except Exception as e: print(e) update_time = '未知' ip_list.append((ip, port, position,proxy_type, speed,live_time,update_time)) for ip_info in ip_list: try: cursor.execute( "insert proxy_ip(ip, port, position,speed, proxy_type,live_time,update_time) VALUES('{0}', '{1}', '{2}', '{3}','HTTP','{4}','{5}') ON DUPLICATE KEY UPDATE proxy_type=VALUES(proxy_type)".format( ip_info[0], ip_info[1], ip_info[2],ip_info[4],ip_info[5],ip_info[6] ) ) print('插入成功') conn.commit() except Exception as e: print('插入失败',e) class GetIP(object): def delete_ip(self, ip): #从数据库中删除无效的ip delete_sql = """ delete from proxy_ip where ip='{0}' """.format(ip) cursor.execute(delete_sql) conn.commit() return True def judge_ip(self, ip, port): #判断ip是否可用 headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0"} http_url = "https://www.lagou.com/" proxy_url = "http://{0}:{1}".format(ip, port) try: proxy_dict = { "http":proxy_url, } response = requests.get(http_url, headers=headers,proxies=proxy_dict) except Exception as e: print ("invalid ip and port") self.delete_ip(ip) return False else: code = response.status_code if code >= 200 and code < 300: print ("effective ip") return True else: print ("invalid ip and port") self.delete_ip(ip) return False def get_random_ip(self): #从数据库中随机获取一个可用的ip random_sql = """ SELECT ip, port FROM proxy_ip ORDER BY RAND() LIMIT 1 """ result = cursor.execute(random_sql) for ip_info in cursor.fetchall(): ip = ip_info[0] port = ip_info[1] judge_re = self.judge_ip(ip, port) if judge_re: return "http://{0}:{1}".format(ip, port) else: return self.get_random_ip() if __name__ == "__main__": crawl_ips() # get_ip = GetIP() # ip = get_ip.get_random_ip() # print(ip)
# -*- coding: utf-8 -*- """ @Datetime: 2018/10/15 @Author: Zhang Yafei """ import re import logging import requests import os import time from retrying import retry from urllib.request import urljoin from urllib.parse import urlsplit # from scrapy import Selector from lxml import etree # from fake_useragent import UserAgent from multiprocessing import Pool from ids import Diabetes_ids # ua = UserAgent() # headers = {'User-Agent':ua.random} headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'} proxies = {'http':'http://61.135.217.7:80','https':'http://171.113.156.168:8010'} BASE_DIR = os.path.dirname(os.path.abspath(__file__)) # DOWNLOAD_DIR = os.path.join(BASE_DIR,'药品') DOWNLOAD_DIR = os.path.join(BASE_DIR,'糖尿病') file_path = os.path.join(BASE_DIR,'drug_ruls.txt') RUN_LOG_FILE = os.path.join(BASE_DIR,'log','run.log') ERROR_LOG_FILE = os.path.join(BASE_DIR,'log','error_log') if not os.path.exists(DOWNLOAD_DIR): os.makedirs(DOWNLOAD_DIR) class Logger(object): """ logger对象:打印日志 """ def __init__(self): self.run_log_file = RUN_LOG_FILE self.error_log_file = ERROR_LOG_FILE self.run_log = None self.error_log = None self.initialize_run_log() self.initialize_error_log() @staticmethod def check_path_exist(log_abs_file): log_path = os.path.split(log_abs_file)[0] if not os.path.exists(log_path): os.mkdir(log_path) def initialize_run_log(self): self.check_path_exist(self.run_log_file) fh = logging.FileHandler(self.run_log_file, 'a', encoding='utf-8') sh = logging.StreamHandler() # fmt = logging.Formatter(fmt="%(asctime)s - %(levelname)s : %(message)s") # fh.setFormatter(fmt) # sh.setFormatter(fmt) logger1 = logging.Logger('run_log', level=logging.INFO) logger1.addHandler(fh) logger1.addHandler(sh) self.run_logger = logger1 def initialize_error_log(self): self.check_path_exist(self.error_log_file) fh = logging.FileHandler(self.error_log_file, 'a', encoding='utf-8') sh = logging.StreamHandler() # fmt = logging.Formatter(fmt="%(asctime)s - %(levelname)s : %(message)s") # fh.setFormatter(fmt) # sh.setFormatter(fmt) logger1 = logging.Logger('error_log', level=logging.ERROR) logger1.addHandler(fh) logger1.addHandler(sh) self.error_logger = logger1 def log(self, message, mode=True): """ 写入日志 :param message: 日志信息 :param mode: True表示运行信息,False表示错误信息 :return: """ if mode: self.run_logger.info(message) else: self.error_logger.error(message) logger = Logger() class Drug(object): """ self.base_url 药物抓取基础url=药品概述url self.manual_url 药品详细说明书url self.comment_url 药品用药经验url self.ask_url 药品咨询url self.logger 打印日志 """ def __init__(self,base_url): self.base_url = base_url self.drug_id = self.base_url.split('/')[-2] self.manual_url = urljoin(base_url,'manual') self.comment_url = urljoin(base_url,'comment') self.ask_url = urljoin(base_url,'ask') self.make_drug_dir() method_list = [self.summary,self.manual,self.comment,self.ask] map(lambda x:x,[x() for x in method_list]) def make_drug_dir(self): """ 创建每一种药品所有网页文件文件夹 :return: """ # self.check_download_dir() response = requests.get(self.base_url,headers=headers) response.encoding = response.apparent_encoding html = etree.HTML(response.text) # selector = Selector(response) # drug_name = selector.css('.t1 h1 a::text').extract_first() try: drug_name = html.xpath('//div[@class="t1"]/h1/a/text()')[0] except IndexError: drug_name = html.xpath('//div[@class="t1"]/h1/text()')[0] self.drug_name = self.validateTitle(drug_name) self.drug_dir_path = os.path.join(DOWNLOAD_DIR,'{}[{}]'.format(self.drug_name,self.drug_id)) if not os.path.exists(self.drug_dir_path): os.mkdir(self.drug_dir_path) def validateTitle(self,title): rstr = r"[\/\\\:\*\?\"\<\>\|]" # '/ \ : * ? " < > |' new_title = re.sub(rstr, "_", title) # 替换为下划线 return new_title @retry(stop_max_attempt_number=3) def retry_download(self, url): """ 通过装饰器封装重试下载模块,最多重试三次 :param url_str: 下载网页的最终地址 :param data: Post传输数据 :param method: 下载方法GET或POST :param proxies: 代理服务器 :return: 下载结果 """ result = requests.get(url, headers=headers, proxies=proxies,timeout=3) assert result.status_code == 200 # 使用断言判断下载状态,成功则返回结果,失败抛出异常 return result def download(self, url): """ 真正的下载类,代理模式 :param url_str:下载的链接 :param data:post需要传输的数据 :param method:请求方法 :param proxies:代理 :return:下载的结果 """ try: result = self.retry_download(url) except Exception as e: # 异常处理尽量使用具体的异常 print(e) # logger.log(url,False) result = None return result def summary(self): """ 抓取药品概述页 :return: """ summary_path = os.path.join(self.drug_dir_path,'{}[{}]-药品概述.html'.format(self.drug_name,self.drug_id)) if os.path.exists(summary_path): print('{}药品概述已经下载过了'.format(self.drug_name)) else: response = requests.get(self.base_url,headers=headers) if response.status_code != 200: response = self.download(self.base_url) if not response: # self.logger.log('{}[{}]-药品概述下载失败-{}'.format(self.drug_name,self.drug_id,self.base_url),False) logger.log('{}'.format(self.base_url),False) return response = response.content.decode('gb2312','ignore') with open(summary_path,'w',encoding='gb2312') as file: file.write(response) logger.log('{}[{}]-药品概述下载完成'.format(self.drug_name,self.drug_id)) def manual(self): """ 抓取药品详细说明书 :return: """ manual_path = os.path.join(self.drug_dir_path,'{}[{}]-详细说明书.html'.format(self.drug_name,self.drug_id)) if os.path.exists(manual_path): print('{}详细说明书已经下载过了'.format(self.drug_name)) else: response = requests.get(self.manual_url,headers=headers) if response.status_code != 200: response = self.download(self.base_url) if not response: # self.logger.log('{}[{}]-详细说明书下载失败-{}'.format(self.drug_name,self.drug_id,self.manual_url),False) logger.log('{}'.format(self.manual_url),False) return response = response.content.decode('gb2312','ignore') with open(manual_path,'w',encoding='gb2312') as file: file.write(response) logger.log('{}[{}]-详细说明书下载完成'.format(self.drug_name,self.drug_id)) def comment(self): """ 药品用药经验页 :return: """ response = requests.get(self.comment_url,headers=headers) if response.status_code != 200: response = self.download(self.base_url) if not response: # self.logger.log('{}[{}]-用药经验下载失败'.format(self.drug_name,self.drug_id,self.comment_url),False) logger.log('{}'.format(self.comment_url),False) return response = response.content.decode('gb2312','ignore') html = etree.HTML(response) try: comment_nums = int(html.xpath('//div[@class="dps"]/cite/font/text()')[0]) except IndexError as e: logger.log('{}[{}]-用药经验页评论数为零'.format(self.drug_name,self.drug_id)) comment_nums = 0 # selector = Selector(response) # comment_nums = int(selector.css('.dps cite font::text').extract_first()) num,remainder = divmod(comment_nums,20) for x in range(1,num+2): url = urljoin(self.base_url,'comment/k0_p{}'.format(x)) self.comment_page(url) def comment_page(self,url): """ 抓取用药经验详情页 :param url: :return: """ comment_path = os.path.join(self.drug_dir_path,'{}[{}]-用药经验{}.html'.format(self.drug_name,self.drug_id,url[-1])) if os.path.exists(comment_path): print('{}[{}]-用药经验{}已经下载过了'.format(self.drug_name,self.drug_id,url[-1])) else: response = requests.get(url,headers=headers) if response.status_code != 200: response = self.download(self.base_url) if not response: # self.logger.log('{}[{}]-用药经验{}下载失败-{}'.format(self.drug_name,self.drug_id,url[-1],url),False) logger.log('{}'.format(url),False) return response = response.content.decode('gb2312','ignore') with open(comment_path,'w',encoding='gb2312') as file: file.write(response) logger.log('{}[{}]-用药经验{}下载完成'.format(self.drug_name,self.drug_id,url[-1])) def ask(self): """ 药品用药咨询页 :return: """ response = requests.get(self.ask_url) if response.status_code != 200: response = self.download(self.base_url) if not response: # self.logger.log('{}[{}]-用药咨询下载失败-{}'.format(self.drug_name,self.drug_id,self.ask_url),False) logger.log('{}'.format(self.ask_url),False) return response = response.content.decode('gb2312','ignore') html = etree.HTML(response) try: ask_nums = html.xpath('//span[@class="pages"]/span[@class="pgleft"]/b/text()')[0] ask_nums = int(re.match('.*?(\d+).*',ask_nums).group(1)) except Exception as e: ask_nums = 0 logger.log('{}[{}]-用药咨询页无人提问'.format(self.drug_name,self.drug_id)) # selector = Selector(response) # ask_nums = int(selector.css('.pages .pgleft b::text').re('\d+')[0]) num,remainder = divmod(ask_nums,5) for x in range(1,num+2): url = urljoin(self.base_url,'ask/p{}'.format(x)) self.ask_page(url) def ask_page(self,url): """ 抓取用药咨询详情页 :param url: :return: """ ask_path = os.path.join(self.drug_dir_path,'{}[{}]-用药咨询{}.html'.format(self.drug_name,self.drug_id,url[-1])) if os.path.exists(ask_path): print('{}[{}]-用药咨询{}已经下载过了'.format(self.drug_name,self.drug_id,url[-1])) else: response = requests.get(url,headers=headers) if response.status_code != 200: response = self.download(self.base_url) if not response: # self.logger.log('{}[{}]-用药咨询{}下载失败-{}'.format(self.drug_name,self.drug_id,url[-1],url),False) logger.log('{}'.format(url),False) return response = response.content.decode('gb2312','ignore') with open(ask_path,'w',encoding='gb2312') as file: file.write(response) logger.log('{}[{}]-用药咨询{}下载完成'.format(self.drug_name,self.drug_id,url[-1])) def transform_urls(filename): drug_id = re.findall(r'.*?\[(\d+)\]', filename)[-1] drug_url = 'http://ypk.39.net/{}/'.format(drug_id) return drug_url def check_downloaded(func): def inner(drug_urls): file_list = os.listdir(DOWNLOAD_DIR) file_list = map(transform_urls,[filename for filename in file_list]) # print(len(list(file_list))) files = set(drug_urls)-set(file_list) # print(len(drug_urls)) # print(len(files)) func(list(files)) return inner def get_drug_urls(): """读取所有要抓取药品的url地址""" with open(file_path,'r',encoding='utf-8') as f: drug_urls = f.readlines() drug_urls = list(map(lambda x: x.strip(), list(drug_urls))) return drug_urls def get_diabetes_urls(): return list(set(list(map(lambda x:'http://ypk.39.net/{}/'.format(x),Diabetes_ids)))) def main(drug_base_url): """创建Drug类实例,进行每一种药品的抓取""" Drug(drug_base_url) def validateTitle(title): rstr = r"[\/\\\:\*\?\"\<\>\|]" # '/ \ : * ? " < > |' new_title = re.sub(rstr, "_", title) # 替换为下划线 return new_title def spider(url): url_path = urlsplit(url) drug_id = url_path.path.strip('/') try: response = requests.get(url=url,headers=headers,timeout=3) # response.encoding = response.apparent_encoding response = response.content.decode('gb2312','ignore') html = etree.HTML(response) drug_name = html.xpath('//div[@class="t1"]/h1/text()')[0] drug_name = validateTitle(drug_name) except Exception as e: print(e) logger.log(url,False) return drug_dir_path = os.path.join(DOWNLOAD_DIR, '{}[{}]'.format(drug_name, drug_id)) if not os.path.exists(drug_dir_path): os.mkdir(drug_dir_path) drug_html_detail = os.path.join(drug_dir_path,'{}[{}].html'.format(drug_name,drug_id)) if not os.path.exists(drug_html_detail): with open(drug_html_detail,'w',encoding='gb2312') as file: file.write(response) print(drug_name,'下载成功') @check_downloaded def run(drug_urls): """创建进程池""" print(drug_urls) print(len(drug_urls)) pool = Pool(5) pool.map(main,drug_urls) #drug_urls[7010:12000] # pool.map(spider,drug_urls) pool.close() pool.join() if __name__ == '__main__': # drug_urls = get_drug_urls() # run(drug_urls) urls = get_diabetes_urls() run(urls)
# -*- coding: utf-8 -*- """ @Datetime: 2018/8/31 @Author: Zhang Yafei """ import requests from fake_useragent import UserAgent ua = UserAgent() class Music(): def __init__(self,name,type): self.name = name self.type = type def search(self): # name = quote(name) url = 'http://www.qmdai.cn/yinyuesou/' headers = { 'Accept': 'application/json, text/javascript, */*; q=0.01', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Connection': 'keep-alive', 'Content-Length': '102', 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 'Cookie': 'Hm_lvt_0388e27ad00b627fe43bd8d8dea61a0b=1535724845; Hm_lpvt_0388e27ad00b627fe43bd8d8dea61a0b=1535727734', 'Host': 'www.qmdai.cn', 'Origin': 'http://www.qmdai.cn', 'Referer': 'http://www.qmdai.cn/yinyuesou/?name=%E6%88%91%E4%BB%AC%E4%B8%8D%E4%B8%80%E6%A0%B7%20%E5%A4%A7%E5%A3%AE&type=netease', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36', 'X-Requested-With': 'XMLHttpRequest', } data = { 'input': self.name, 'filter': 'name', 'type': self.type, 'page': '1', } response = requests.post(url,headers=headers,data=data) result = response.json() songs = result['data'] item = {} for n,song in enumerate(songs): music = {} title = song['title'] author = song['author'] song_name = title+"-"+author url = song['url'] music[song_name] = url print('{}:{} {}'.format(n,title,author)) item[n] = music return item def download(self,song): name = list(song.keys())[0] url = song.get(name) response = requests.get(url).content filename = 'mp3/'+name+'.mp3' with open(filename,'wb') as f: f.write(response) print(name+'\t下载成功\n\n') def music_type(type): song_class = {'1':'netease','2':'qq','3':'kugou','4':'kuwo','5':'xiami'} return song_class[type] def show(): print('===============欢迎使用音乐下载器v1.0===============') print('1.网易云音乐\t2.QQ音乐\t3.酷狗\t4.酷我\t5.虾米\tq.退出') print('==================================================') if __name__ == '__main__': while True: # name = '我们不一样' show() num = input('请选择搜索平台序号(q退出):') if num not in '12345q': print('您选择有误,请重新选择\n\n') continue if num == 'q': print('谢谢您的使用,再见!') break type = music_type(num) name = input('请输入歌曲信息(歌名或歌手):') get = Music(name,type) item = get.search() if item == None: print('该歌曲查询不到任何信息,请重新输入关键字') continue n = int(input('请输入下载歌曲的序号:')) get.download(item[n])
# -*- coding: utf-8 -*- """ @Datetime: 2018/8/23 @Author: Zhang Yafei """ """ 列表生成式 生成器(元祖生成器):惰性计算,只使用一次 In [1]: a = [i for i in range(10)] In [2]: list(a) Out[2]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] In [3]: list(a) Out[3]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] In [4]: b = (i for i in range(10)) In [5]: list(b) Out[5]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] In [6]: list(b) Out[6]: [] """ import os import time from PIL import Image def pullPicture(): os.system('adb shell screencap -p /sdcard/screen.png') os.system('adb pull /sdcard/screen.png') def getDistance(): #读取图片 image = Image.open('screen.png') #返回元祖 width = image.size[0] height = image.size[1] # print(width,height) for i in range(914,915): for j in range(height): #颜色值(RGB),透明度 if image.getpixel((i, j))[:3] == (255, 207, 216): yield j if __name__ == '__main__': # pullPicture() for _ in range(10): xposition = getDistance() for x in xposition: # 点击屏幕 os.system('adb shell input tap 915 {}'.format(x)) print("正在关注……………………") #向上滑 坐标 滑动时间 os.system('adb shell input swipe 785 1900 785 500 500') time.sleep(0.5) print('正在翻页')
# -*- coding: utf-8 -*- """ Created on Mon Jul 30 19:19:35 2018 @author: Zhang Yafei """ import requests import json import string import time import hashlib import json import execjs import urllib.request import sys class Py4Js(): def __init__(self): self.ctx = execjs.compile(""" function TL(a) { var k = ""; var b = 406644; var b1 = 3293161072; var jd = "."; var $b = "+-a^+6"; var Zb = "+-3^+b+-f"; for (var e = [], f = 0, g = 0; g < a.length; g++) { var m = a.charCodeAt(g); 128 > m ? e[f++] = m : (2048 > m ? e[f++] = m >> 6 | 192 : (55296 == (m & 64512) && g + 1 < a.length && 56320 == (a.charCodeAt(g + 1) & 64512) ? (m = 65536 + ((m & 1023) << 10) + (a.charCodeAt(++g) & 1023), e[f++] = m >> 18 | 240, e[f++] = m >> 12 & 63 | 128) : e[f++] = m >> 12 | 224, e[f++] = m >> 6 & 63 | 128), e[f++] = m & 63 | 128) } a = b; for (f = 0; f < e.length; f++) a += e[f], a = RL(a, $b); a = RL(a, Zb); a ^= b1 || 0; 0 > a && (a = (a & 2147483647) + 2147483648); a %= 1E6; return a.toString() + jd + (a ^ b) }; function RL(a, b) { var t = "a"; var Yb = "+"; for (var c = 0; c < b.length - 2; c += 3) { var d = b.charAt(c + 2), d = d >= t ? d.charCodeAt(0) - 87 : Number(d), d = b.charAt(c + 1) == Yb ? a >>> d: a << d; a = b.charAt(c) == Yb ? a + d & 4294967295 : a ^ d } return a } """) def getTk(self, text): return self.ctx.call("TL", text) class Translation(object): def __init__(self,word): self.word = word def google(self): js = Py4Js() tk = js.getTk(self.word) if len(self.word) > 4891: print("翻译的长度超过限制!!!") return lower_case = list(string.ascii_lowercase) # 小写字母,大写字母为string.ascii_uppercase if list(self.word)[0] in lower_case: content = urllib.parse.quote(self.word) url = "http://translate.google.cn/translate_a/single?client=t&sl=en&tl=zh-CN&hl=zh-CN&dt=at&dt=bd&dt=ex&dt=ld&dt=md&dt=qca&dt=rw&dt=rm&dt=ss&dt=t&ie=UTF-8&oe=UTF-8&clearbtn=1&otf=1&pc=1&srcrom=0&ssel=0&tsel=0&kc=2&tk=%s&q=%s" % ( tk, content) else: content = urllib.parse.quote(self.word) url = "http://translate.google.cn/translate_a/single?client=t&sl=zh-CN&tl=en&hl=zh-CN&dt=at&dt=bd&dt=ex&dt=ld&dt=md&dt=qca&dt=rw&dt=rm&dt=ss&dt=t&ie=UTF-8&oe=UTF-8&clearbtn=1&otf=1&pc=1&srcrom=0&ssel=0&tsel=0&kc=2&tk=%s&q=%s" % ( tk, content) headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'} req = urllib.request.Request(url=url, headers=headers) response = urllib.request.urlopen(req) result = response.read().decode('utf-8') end = result.find("\",") if end > 4: return result[4:end] def baidu(self): api_url = "http://api.fanyi.baidu.com/api/trans/vip/translate" my_appid = '20180813000193912' cyber = 'r9e3KwSvyvvVcZ7hxdI2' lower_case = list(string.ascii_lowercase) #小写字母,大写字母为string.ascii_uppercase # init salt and final_sign salt = str(time.time())[:10] final_sign = str(my_appid) + self.word + salt + cyber final_sign = hashlib.md5(final_sign.encode("utf-8")).hexdigest() # 区别en,zh构造请求参数 if list(self.word)[0] in lower_case: paramas = { 'q': self.word, 'from': 'en', 'to': 'zh', 'appid': '%s' % my_appid, 'salt': '%s' % salt, 'sign': '%s' % final_sign } my_url = api_url + '?appid=' + str(my_appid) + '&q=' + self.word + '&from=' + 'en' + '&to=' + 'zh' + '&salt=' + salt + '&sign=' + final_sign else: paramas = { 'q': self.word, 'from': 'zh', 'to': 'en', 'appid': '%s' % my_appid, 'salt': '%s' % salt, 'sign': '%s' % final_sign } my_url = api_url + '?appid=' + str(my_appid) + '&q=' + self.word + '&from=' + 'zh' + '&to=' + 'en' + '&salt=' + salt + '&sign=' + final_sign response = requests.get(my_url, params=paramas).content content = str(response, encoding="utf-8") json_reads = json.loads(content) result = json_reads['trans_result'][0]['dst'] return result def youdao(self): url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule' headers = { 'Accept': 'application/json, text/javascript, */*; q=0.01', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Connection': 'keep-alive', 'Content-Length': '253', 'Content-Type': 'application/x-www-form-urlencoded;charset=ascii',#删掉 charset=UTF-8 或改成charset=ascii 'Cookie': 'OUTFOX_SEARCH_USER_ID=1973183821@10.168.8.76; OUTFOX_SEARCH_USER_ID_NCOO=1949291136.690128; JSESSIONID=aaaJaNxzIwncvgCt66Qtw; ___rl__test__cookies=1532949724489', 'Host': 'fanyi.youdao.com', 'Origin': 'http://fanyi.youdao.com', 'Referer': 'http://fanyi.youdao.com/', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36', 'X-Requested-With': 'XMLHttpRequest' } data={ 'i': self.word, 'from': 'AUTO', 'to': 'AUTO', 'smartresult': 'dict', 'client': 'fanyideskweb', 'salt': '1532949724498', 'sign': '7fe0405a4e3bb5ad5974ee89eec40bbc', 'doctype': 'json', 'version': '2.1', 'keyfrom': 'fanyi.web', 'action': 'FY_BY_REALTIME', 'typoResult': 'false' } response = requests.post(url,headers=headers,data=data) html = json.loads(response.text) result = html['translateResult'][0][0]['tgt'] return result#注:这里的列表有两层嵌套,需要取出两次 if __name__ == "__main__": print('欢迎使用迷你翻译官,下面开始我们的翻译之旅吧!(注:若想退出,请输入q)') while True: word = input('请输入需要翻译的语句:') if word != 'q': get = Translation(word) result = get.youdao() result1 = get.baidu() result2 = get.google() # print("原文:{0}\n结果:{1}".format(word,result)) print('原文:{0}\n百度翻译:{1}\n谷歌翻译:{2}\n有道翻译:{3}'.format(word,result1,result2,result)) else: break

