

Django基础
一、常用命令
1. django-admin startproject mysite
2. python manage.py startapp blog 建立一个app应用
3. mysite.settings 中INSTALLED_APPS[]中添加blog
4 .python manage.py runserver 8080 开启服务器
5. python manage.py shell 进入当前django环境
6 python manage.py makemigrations
7.python manage.py migrate
二、配置文件
配置
模板文件路径: 'DIRS': [os.path.join(BASE_DIR,'templates')],
静态文件路径: STATIC_URL = '/static/' #别名
STATICFILES_DIRS = (
os.path.join(BASE_DIR,'blog','static'),
)
输出台打印ORM执行的sql语句
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
配置数据库: 1.sqlite
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
2.mysql
'ENGINE': 'django.db.backends.mysql',
'NAME': 'sxmu',
'USER': 'root',
'PASSWORD': '0000',
'HOST': 'localhost',
'PORT': '3306',
数据库连接MySql(使用ORM必须配置)
在项目的__init__.py中配置:import pymysql
pymysql.install_as_MySQLdb()
LANGUAGE_CODE = 'zh-hans' #'en-us'
TIME_ZONE = 'Asia/Shanghai'
注:import pytz
pytz.common_timezones_set #获取所有时区
pytz.country_timezones('cn') #获取中国时区
重新加载css/js文件,删除浏览器缓存
读取配置文件


class Settings: def __init__(self, settings_module): # update this dict from global settings (but only for ALL_CAPS settings) for setting in dir(global_settings): if setting.isupper(): setattr(self, setting, getattr(global_settings, setting)) # store the settings module in case someone later cares self.SETTINGS_MODULE = settings_module mod = importlib.import_module(self.SETTINGS_MODULE) tuple_settings = ( "INSTALLED_APPS", "TEMPLATE_DIRS", "LOCALE_PATHS", ) self._explicit_settings = set() for setting in dir(mod): if setting.isupper(): setting_value = getattr(mod, setting) if (setting in tuple_settings and not isinstance(setting_value, (list, tuple))): raise ImproperlyConfigured("The %s setting must be a list or a tuple. " % setting) setattr(self, setting, setting_value) self._explicit_settings.add(setting) if not self.SECRET_KEY: raise ImproperlyConfigured("The SECRET_KEY setting must not be empty.") if self.is_overridden('DEFAULT_CONTENT_TYPE'): warnings.warn('The DEFAULT_CONTENT_TYPE setting is deprecated.', RemovedInDjango30Warning) if hasattr(time, 'tzset') and self.TIME_ZONE: # When we can, attempt to validate the timezone. If we can't find # this file, no check happens and it's harmless. zoneinfo_root = '/usr/share/zoneinfo' if (os.path.exists(zoneinfo_root) and not os.path.exists(os.path.join(zoneinfo_root, *(self.TIME_ZONE.split('/'))))): raise ValueError("Incorrect timezone setting: %s" % self.TIME_ZONE) # Move the time zone info into os.environ. See ticket #2315 for why # we don't do this unconditionally (breaks Windows). os.environ['TZ'] = self.TIME_ZONE time.tzset() def is_overridden(self, setting): return setting in self._explicit_settings def __repr__(self): return '<%(cls)s "%(settings_module)s">' % { 'cls': self.__class__.__name__, 'settings_module': self.SETTINGS_MODULE, }
补充:根据字符串的形式,自动导入模块并使用反射找到模块中的类,执行指定的方法
步骤:
1. rsplit('.',maxsplit=1) 分割字符串为模块和类
2. importlib导入模块
3. 用反射获取模块中指定的类
4. 将该类实例化成对象
5. 执行对象指定的方法
import importlib # 字符串路径 path = "auth.crsf.CORS" # 分割字符串 module_path,class_name = path.rsplit('.',maxsplit=1) # 根据字符串的形式导入模块 m = importlib.import_module(module_path) # 获取模块中指定的类 cls = getattr(m,class_name) # 类实例化 obj = cls() # 执行对象指定的方法 obj.process_request()
django入口
from django.core.wsgi import WSGIHandler
三、urls:路由分发
URL配置(URLconf)就像Django 所支撑网站的目录。它的本质是URL模式以及要为该URL模式调用的视图函数之间的映射表;你就是以这种方式告诉Django,对于这个URL调用这段代码,
对于那个URL调用那段代码。
urlpatterns = [
url(regex, view, kwargs=None, name=None)
path(route, view, kwargs=None, name=None),
re_path(regex, view, kwargs=None, name=None)
]
参数说明:
roote: url路径
regex: 一个正则表达式字符串
view: 一个可调用对象,通常为一个视图函数或一个指定视图函数路径的字符串
这里的view可以是include(arg, namespace=None) 命名空间,用于不同app别名相同时的路径分流,注意:当配置namespace时,app的urls.py中也要配置app_name
kwargs: 可选的要传递给视图函数的默认参数(字典形式)
name: url的别名,一个可选的name参数, 用于反向解析
例子
1.项目.urls.py
from django.contrib import admin
from django.urls import path,include
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
path('app01/',include('app01.urls',namespace='app01')), # namespace: 命名空间,1. 起到路径分流的作用 2. 别名重复时反向解析的问题
path('login/',views.login,name='login'), # name: 给url起别名,用于反向解析
path('',views.index),
path('index/',views.index1,name='index'),
path('logout/', views.logout,name='logout'),
]
2.app.urls.py
from django.conf.urls import url
from . import views
app_name = 'app01'
urlpatterns = [
url(r'^article/(?P<year>\d{4})/(?P<month>\d{2})/(?P<day>\d+)$', views.article_year_month, name='article'),
url(r'addbook', views.addbook, name='addbook'),
url(r'update', views.update, name='update'),
url(r'delete', views.delete, name='delete'),
url(r'select', views.select, name='select'),
]
django2.0版的path
使用尖括号(<>)从url中捕获值。
捕获值中可以包含一个转化器类型(converter type),比如使用 捕获一个整数变量。若果没有转化器,将匹配任何字符串,当然也包括了 / 字符。

<int:year>这种写法直接会对取值进行转换,转换成数值类型(这个int跟python内置的int方法不一样,这是django
带的转换方法),而且指明了接收参数的名称为year,所以视图函数写法如下。
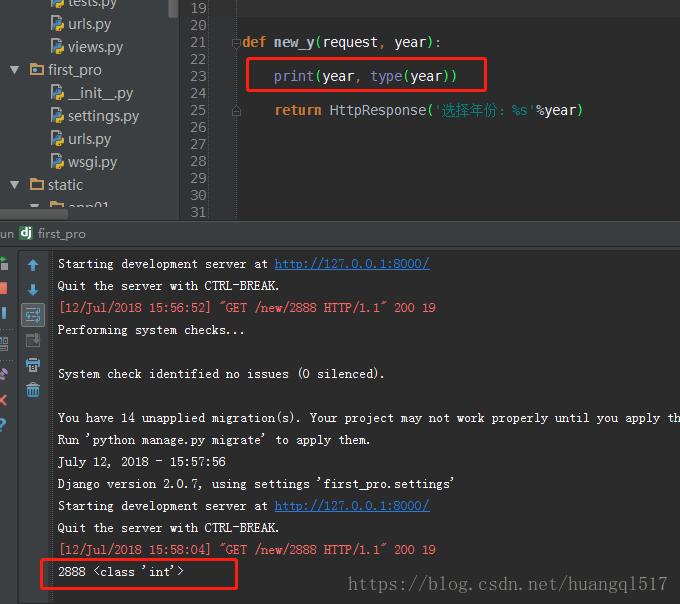
除了int转换器,还有其他的,如下

四、视图函数(views)
http请求中产生两个核心对象:
http请求:HttpRequest对象
http响应:HttpResponse对象
所在位置:django.http
之前我们用到的参数request就是HttpRequest 检测方法:isinstance(request,HttpRequest)
1 HttpRequest对象的属性和方法:
# path: 请求页面的全路径,不包括域名
#
# method: 请求中使用的HTTP方法的字符串表示。全大写表示。例如
#
# if req.method=="GET":
#
# do_something()
#
# elseif req.method=="POST":
#
# do_something_else()
#
# GET: 包含所有HTTP GET参数的类字典对象
#
# POST: 包含所有HTTP POST参数的类字典对象
#
# 服务器收到空的POST请求的情况也是可能发生的,也就是说,表单form通过
# HTTP POST方法提交请求,但是表单中可能没有数据,因此不能使用
# if req.POST来判断是否使用了HTTP POST 方法;应该使用 if req.method=="POST"
#
#
#
# COOKIES: 包含所有cookies的标准Python字典对象;keys和values都是字符串。
#
# FILES: 包含所有上传文件的类字典对象;FILES中的每一个Key都是<input type="file" name="" />标签中 name属性的值,FILES中的每一个value同时也是一个标准的python字典对象,包含下面三个Keys:
#
# filename: 上传文件名,用字符串表示
# content_type: 上传文件的Content Type
# content: 上传文件的原始内容
#
#
# user: 是一个django.contrib.auth.models.User对象,代表当前登陆的用户。如果访问用户当前
# 没有登陆,user将被初始化为django.contrib.auth.models.AnonymousUser的实例。你
# 可以通过user的is_authenticated()方法来辨别用户是否登陆:
# if req.user.is_authenticated();只有激活Django中的AuthenticationMiddleware
# 时该属性才可用
#
# session: 唯一可读写的属性,代表当前会话的字典对象;自己有激活Django中的session支持时该属性才可用。
#方法
get_full_path(), 比如:http://127.0.0.1:8000/index33/?name=123 ,req.get_full_path()得到的结果就是/index33/?name=123
req.path:/index33
注意一个常用方法:request.POST.getlist('hooby'),取多个值,常用于取多选框中的值
2 HttpResponse对象:
对于HttpRequest对象来说,是由django自动创建的,但是,HttpResponse对象就必须我们自己创建。每个view请求处理方法必须返回一个HttpResponse对象。
HttpResponse类在django.http.HttpResponse
在HttpResponse对象上扩展的常用方法:
返回内容: HttpResponse('内容')
页面渲染: render(request,'模板路径',{})(推荐)
render_to_response(’模板路径',{}),
页面跳转: redirect("路径")
locals(): 可以直接将函数中所有的变量传给模板
context={} 将字典对象传递给模板
注:本质--f = open('templates/index.html','r')
data = f.read()
f.close()
return HttpResponse(data)
===================================
#打开index.html读取数据,含有特殊标记
#替换渲染 ==>新字符串
#返回给用户
return render(request,'index.html,{'k1':'k2')
五、models
model(数据库模型) ---> ORM(object relation mapping)对象关系映射
一些重要概念:
1.类 -> 数据库表 class Student():
2.类属性 -> 数据库表的一列 username = models.CharFiled(...)
3.类的对象 -> 数据库表的一行记录 student = Student()
4.一对多 ==> PK字段代指关联表中的一行数据(类的对象)
5.多对多 ==> M2M字段,自动生成第三张表,依赖关联表对第三张表间接操作。
6.数据库获取数据
--[obj,obj,obj...] .all,.filter
--[{},{},{}...] .values
--[(),(),()...] .values_list
--[obj(value1, value2), obj(value1,value2)], only(value1, value2) / defer(value3,..)
1.创建类
<1> CharField #字符串字段, 用于较短的字符串. #CharField 要求必须有一个参数 max_length, 用于从数据库层和Django校验层限制该字段所允许的最大字符数. <2> IntegerField 4个字节 0-4294967296 #用于保存一个整数. SmallIntegerField 2个字节 0-65535 <3> FloatField # 一个浮点数. 必须 提供两个参数: # # 参数 描述 # max_digits 总位数(不包括小数点和符号) # decimal_places 小数位数 # 举例来说, 要保存最大值为 999 (小数点后保存2位),你要这样定义字段: # # models.FloatField(..., max_digits=5, decimal_places=2) # 要保存最大值一百万(小数点后保存10位)的话,你要这样定义: # # models.FloatField(..., max_digits=19, decimal_places=10) # admin 用一个文本框(<input type="text">)表示该字段保存的数据. <4> AutoField # 一个 IntegerField, 添加记录时它会自动增长. 你通常不需要直接使用这个字段; # 自定义一个主键:my_id=models.AutoField(primary_key=True) # 如果你不指定主键的话,系统会自动添加一个主键字段到你的 model. <5> BooleanField # A true/false field. admin 用 checkbox 来表示此类字段. <6> TextField # 一个容量很大的文本字段. # admin 用一个 <textarea> (文本区域)表示该字段数据.(一个多行编辑框). <7> EmailField # 一个带有检查Email合法性的 CharField,不接受 maxlength 参数. <8> DateField # 一个日期字段. 共有下列额外的可选参数: # Argument 描述 # auto_now 当对象被保存时,自动将该字段的值设置为当前时间.通常用于表示 "last-modified" 时间戳. # auto_now_add 当对象首次被创建时,自动将该字段的值设置为当前时间.通常用于表示对象创建时间. #(仅仅在admin中有意义...) <9> DateTimeField # 一个日期时间字段. 类似 DateField 支持同样的附加选项. <10> ImageField # 类似 FileField, 不过要校验上传对象是否是一个合法图片.#它有两个可选参数:height_field和width_field, # 如果提供这两个参数,则图片将按提供的高度和宽度规格保存. <11> FileField # 一个文件上传字段. #要求一个必须有的参数: upload_to, 一个用于保存上载文件的本地文件系统路径. 这个路径必须包含 strftime #formatting, #该格式将被上载文件的 date/time #替换(so that uploaded files don't fill up the given directory). # admin 用一个<input type="file">部件表示该字段保存的数据(一个文件上传部件) . #注意:在一个 model 中使用 FileField 或 ImageField 需要以下步骤: #(1)在你的 settings 文件中, 定义一个完整路径给 MEDIA_ROOT 以便让 Django在此处保存上传文件. # (出于性能考虑,这些文件并不保存到数据库.) 定义MEDIA_URL 作为该目录的公共 URL. 要确保该目录对 # WEB服务器用户帐号是可写的. #(2) 在你的 model 中添加 FileField 或 ImageField, 并确保定义了 upload_to 选项,以告诉 Django # 使用 MEDIA_ROOT 的哪个子目录保存上传文件.你的数据库中要保存的只是文件的路径(相对于 MEDIA_ROOT). # 出于习惯你一定很想使用 Django 提供的 get_<#fieldname>_url 函数.举例来说,如果你的 ImageField # 叫作 mug_shot, 你就可以在模板中以 {{ object.#get_mug_shot_url }} 这样的方式得到图像的绝对路径. <12> URLField # 用于保存 URL. 若 verify_exists 参数为 True (默认), 给定的 URL 会预先检查是否存在( 即URL是否被有效装入且 # 没有返回404响应). # admin 用一个 <input type="text"> 文本框表示该字段保存的数据(一个单行编辑框) <13> NullBooleanField # 类似 BooleanField, 不过允许 NULL 作为其中一个选项. 推荐使用这个字段而不要用 BooleanField 加 null=True 选项 # admin 用一个选择框 <select> (三个可选择的值: "Unknown", "Yes" 和 "No" ) 来表示这种字段数据. <14> SlugField # "Slug" 是一个报纸术语. slug 是某个东西的小小标记(短签), 只包含字母,数字,下划线和连字符.#它们通常用于URLs # 若你使用 Django 开发版本,你可以指定 maxlength. 若 maxlength 未指定, Django 会使用默认长度: 50. #在 # 以前的 Django 版本,没有任何办法改变50 这个长度. # 这暗示了 db_index=True. # 它接受一个额外的参数: prepopulate_from, which is a list of fields from which to auto-#populate # the slug, via JavaScript,in the object's admin form: models.SlugField # (prepopulate_from=("pre_name", "name"))prepopulate_from 不接受 DateTimeFields. <13> XMLField #一个校验值是否为合法XML的 TextField,必须提供参数: schema_path, 它是一个用来校验文本的 RelaxNG schema #的文件系统路径. <14> FilePathField # 可选项目为某个特定目录下的文件名. 支持三个特殊的参数, 其中第一个是必须提供的. # 参数 描述 # path 必需参数. 一个目录的绝对文件系统路径. FilePathField 据此得到可选项目. # Example: "/home/images". # match 可选参数. 一个正则表达式, 作为一个字符串, FilePathField 将使用它过滤文件名. # 注意这个正则表达式只会应用到 base filename 而不是 # 路径全名. Example: "foo.*\.txt^", 将匹配文件 foo23.txt 却不匹配 bar.txt 或 foo23.gif. # recursive可选参数.要么 True 要么 False. 默认值是 False. 是否包括 path 下面的全部子目录. # 这三个参数可以同时使用. # match 仅应用于 base filename, 而不是路径全名. 那么,这个例子: # FilePathField(path="/home/images", match="foo.*", recursive=True) # ...会匹配 /home/images/foo.gif 而不匹配 /home/images/foo/bar.gif <15> IPAddressField # 一个字符串形式的 IP 地址, (i.e. "24.124.1.30"). <16>CommaSeparatedIntegerField # 用于存放逗号分隔的整数值. 类似 CharField, 必须要有maxlength参数.
Field重要参数 <1> null : 数据库中字段是否可以为空 <2> default:设定缺省值 <3> primary_key:加速查找,数据唯一,且不为空。 设置主键,如果没有设置django创建表时会自动加上: id = meta.AutoField('ID', primary_key=True) primary_key=True implies blank=False, null=False and unique=True. Only one primary key is allowed on an object. <4> unique:加速查找,数据唯一 unique_for_date 数据库中字段【日期】部分是否可以建立唯一索引 unique_for_month 数据库中字段【月】部分是否可以建立唯一索引 unique_for_year 数据库中字段【年】部分是否可以建立唯一索引 <5> db_column:自定义数据库中存储列名, db_index:加速查找(创建一个二叉树存储的表)二叉树查找速度快 时间复杂度 O(log2(n)) <6> verbose_name Admin中字段的显示名称 <7> blank: django的 Admin 中添加数据时是否可允许空值 <8> editable:如果为假,admin模式下将不能改写。缺省为真 <9>choices:一个用来选择值的2维元组。第一个值是实际存储的值,第二个用来方便进行选择。 如SEX_CHOICES= (( ‘F’,'Female’),(‘M’,'Male’),) gender = models.CharField(max_length=2,choices = SEX_CHOICES) (10)help_text Admin中该字段的提示信息 <11> validator_list:有效性检查。非有效产生 django.core.validators.ValidationError 错误 (12)error_messages 自定义错误信息(字典类型),从而定制想要显示的错误信息; 字典健:null, blank, invalid, invalid_choice, unique, and unique_for_date 如:{'null': "不能为空.", 'invalid': '格式错误'} (13)validators 自定义错误验证(列表类型),从而定制想要的验证规则 from django.core.validators import RegexValidator from django.core.validators import EmailValidator,URLValidator,DecimalValidator,\ MaxLengthValidator,MinLengthValidator,MaxValueValidator,MinValueValidator 如: test = models.CharField( max_length=32, error_messages={ 'c1': '优先错信息1', 'c2': '优先错信息2', 'c3': '优先错信息3', }, validators=[ RegexValidator(regex='root_\d+', message='错误了', code='c1'), RegexValidator(regex='root_112233\d+', message='又错误了', code='c2'), EmailValidator(message='又错误了', code='c3'), ] )
ForeignKey(ForeignObject) # ForeignObject(RelatedField) to, # 要进行关联的表名 to_field=None, # 要关联的表中的字段名称 on_delete=None, # 当删除关联表中的数据时,当前表与其关联的行的行为 - models.CASCADE,删除关联数据,与之关联也删除 - models.DO_NOTHING,删除关联数据,引发错误IntegrityError - models.PROTECT,删除关联数据,引发错误ProtectedError - models.SET_NULL,删除关联数据,与之关联的值设置为null(前提FK字段需要设置为可空) - models.SET_DEFAULT,删除关联数据,与之关联的值设置为默认值(前提FK字段需要设置默认值) - models.SET,删除关联数据, a. 与之关联的值设置为指定值,设置:models.SET(值) b. 与之关联的值设置为可执行对象的返回值,设置:models.SET(可执行对象) def func(): return 10 class MyModel(models.Model): user = models.ForeignKey( to="User", to_field="id" on_delete=models.SET(func),) related_name=None, # 反向操作时,使用的字段名,用于代替 【表名_set】 如: obj.表名_set.all() related_query_name=None, # 反向操作时,使用的连接前缀,用于替换【表名】 如: models.UserGroup.objects.filter(表名__字段名=1).values('表名__字段名') limit_choices_to=None, # 在Admin或ModelForm中显示关联数据时,提供的条件: # 如: - limit_choices_to={'nid__gt': 5} - limit_choices_to=lambda : {'nid__gt': 5} from django.db.models import Q - limit_choices_to=Q(nid__gt=10) - limit_choices_to=Q(nid=8) | Q(nid__gt=10) - limit_choices_to=lambda : Q(Q(nid=8) | Q(nid__gt=10)) & Q(caption='root') db_constraint=True # 是否在数据库中创建外键约束 parent_link=False # 在Admin中是否显示关联数据 OneToOneField(ForeignKey) to, # 要进行关联的表名 to_field=None # 要关联的表中的字段名称 on_delete=None, # 当删除关联表中的数据时,当前表与其关联的行的行为 ###### 对于一对一 ###### # 1. 一对一其实就是 一对多 + 唯一索引 # 2.当两个类之间有继承关系时,默认会创建一个一对一字段 # 如下会在A表中额外增加一个c_ptr_id列且唯一: class C(models.Model): nid = models.AutoField(primary_key=True) part = models.CharField(max_length=12) class A(C): id = models.AutoField(primary_key=True) code = models.CharField(max_length=1) ManyToManyField(RelatedField) to, # 要进行关联的表名 related_name=None, # 反向操作时,使用的字段名,用于代替 【表名_set】 如: obj.表名_set.all() related_query_name=None, # 反向操作时,使用的连接前缀,用于替换【表名】 如: models.UserGroup.objects.filter(表名__字段名=1).values('表名__字段名') limit_choices_to=None, # 在Admin或ModelForm中显示关联数据时,提供的条件: # 如: - limit_choices_to={'nid__gt': 5} - limit_choices_to=lambda : {'nid__gt': 5} from django.db.models import Q - limit_choices_to=Q(nid__gt=10) - limit_choices_to=Q(nid=8) | Q(nid__gt=10) - limit_choices_to=lambda : Q(Q(nid=8) | Q(nid__gt=10)) & Q(caption='root') symmetrical=None, # 仅用于多对多自关联时,symmetrical用于指定内部是否创建反向操作的字段 # 做如下操作时,不同的symmetrical会有不同的可选字段 models.BB.objects.filter(...) # 可选字段有:code, id, m1 class BB(models.Model): code = models.CharField(max_length=12) m1 = models.ManyToManyField('self',symmetrical=True) # 可选字段有: bb, code, id, m1 class BB(models.Model): code = models.CharField(max_length=12) m1 = models.ManyToManyField('self',symmetrical=False) through=None, # 自定义第三张表时,使用字段用于指定关系表 through_fields=None, # 自定义第三张表时,使用字段用于指定关系表中那些字段做多对多关系表 from django.db import models class Person(models.Model): name = models.CharField(max_length=50) class Group(models.Model): name = models.CharField(max_length=128) members = models.ManyToManyField( Person, through='Membership', through_fields=('group', 'person'), ) class Membership(models.Model): group = models.ForeignKey(Group, on_delete=models.CASCADE) person = models.ForeignKey(Person, on_delete=models.CASCADE) inviter = models.ForeignKey( Person, on_delete=models.CASCADE, related_name="membership_invites", ) invite_reason = models.CharField(max_length=64) db_constraint=True, # 是否在数据库中创建外键约束 db_table=None, # 默认创建第三张表时,数据库中表的名称
2.操作类
class Book(models.Model):
name = models.CharField(max_length=20,verbose_name='姓名')
price = models.IntegerField('价格')
pub_date = models.DateField('出版日期')
publish = models.ForeignKey('Publish',on_delete='CASCADE',verbose_name='出版商')
authors = models.ManyToManyField('Author',verbose_name='作者')
def __str__(self):
return self.name
class Publish(models.Model):
name = models.CharField(max_length=32)
city = models.CharField(max_length=32)
def __str__(self):
return self.name
class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField(default=20)
def __str__(self):
return self.name
class Classes(models.Model):
"""
班级表
"""
title = models.CharField(max_length=32)
teachers = models.ManyToManyField('Teachers')
schools = models.ForeignKey(Schools)
class Teachers(models.Model):
"""
老师表
"""
name = models.CharField(max_length=32)
class Students(models.Model):
"""
学生表
"""
username = models.CharField(max_length=32)
age = models.IntegerField()
gender = models.BooleanField()
cs = models.ForeignKey(Classes,on_delete='CASCADE') #cs是classes表的一个对象
b = Book() 实例化一个类,代表创建一条记录
表与表之间的关系:
一对一:在一对多的基础上给外键加一个唯一约束
一对多:比如员工与部门,通过外键连接
多对多:书籍信息表与作者表,再加一个书籍与作者关系表,分别建立书籍与作者的外键关联
表记录的添加
1.Book()
b = Book(name='python基础',price=99,author='fei',pub_date='2017-12-12')
b.save()
2.Book.objects.create(name='python核心', price=199, author='oldboy', pub_date='2017-12-12')
Book.objects.create(**dic)
表记录的更改
1. Book.objects.filter(author='fei').update(price=999)
2. b = Book.objects.get(author='oldboy')
b.price = 120
b.save()
表记录的删除
Book.objects.filter(author='oldboy').delete()
表记录的查询(重点)
book_list = Book.objects.all() [obj1(),obj2(),obj3(),obj4(),...]--取每一个对象可以用for循环
print(book_list[0])
book_list = Book.objects.all()[:2]
book_list = Book.objects.all()[::2]
book_list = Book.objects.all()[::-1]
first,last,get取到的是一个实例对象,不是querySet对象
book_list = Book.objects.first()
book_list = Book.objects.last()
book_list = Book.objects.get(id=2) #只能取出一条记录的时候才不报错
name = Book.objects.filter(author='fei').values('name','price')
name = Book.objects.filter(author='fei').values_list('name','price')
book_list = Book.objects.exclude(author='fei')
book_list = Book.objects.all().values('name').distinct()
num = Book.objects.all().values('name').distinct().count()
模糊匹配 双下划线__
book_list = Book.objects.filter(price__gt=50).values('name','price')
book_list = Book.objects.filter(price__lt=50).values('name','price')
book_list = Book.objects.filter(name__icontains='p').values('name','price') # icontains大小写不敏感
models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and
models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据
models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in
startswith,istartswith, endswith, iendswith,
注:id_range = [],id_in = []
多表操作(一对多)
创建表关联:publish = models.ForeignKey('Publish',on_delete='CASCADE',verbose_name='出版商') #默认在Book表中添加一个publish_id字段
添加记录:
1.#publish_id=2
Book.objects.create(name='linux运维', price=77, pub_date='2017-12-12',publish_id=2)
2.publish_obj = Publish.objects.filter(name='人民出版社')[0]
Book.objects.create(name='linux运维', price=77, pub_date='2017-12-12',publish=publish_obj)
查询记录(通过对象):正向:通过fk字段关联另一张表
反向:若不存在fk字段,通过小写类名_set(默认)关联另一张表==>可设置related_name='cls',修改关联表名称
正向查询:book_obj = Book.objects.get(name='python')
pub_obj = book_obj.publish ==>书籍对象对应的出版社对象
pub_obj.city,pub_obj.name
反向查询:publish_obj = Publish.objects.get(name='人民出版社')
book_obj = publish_obj.book_set.all()) ==>出版社对象对应的所有书籍对象的querySet集合
book_obj = publish_obj.book_set.values('name','price'))
查询记录(filter,values,双下划线__)
正向查询:book_obj = Book.objects.filter(publish__name='人民出版社').values('name','price')
反向查询: 1.python这本书出版社的名字
pub_name = Publish.objects.filter(book__name='python').values('name')
pub_name = Book.objects.filter(name='python').values('publish__name')
2.查询北京出版的所有书籍名称
book__name = Book.objects.filter(publish__city='北京').values('name')
book__name = Publish.objects.filter(city='北京').values('book__name')
3.查询在2017-2018之间出版过书籍的出版社
publish__name = Book.objects.filter(pub_date__lt='2018-01-01',pub_date__gt='2017-01-01').values('publish__name')
例:students_list = Students.objects.all()
for item in students_list:
print(item.id)
print(item.username)
print(item.age)
print(item.gender)
print(item.cs_id)
print(item.cs.id)
print(item.cs.name)
student_obj = Students.objects.filter(cs__title='一班') #[student1,student2,...]
student_obj.values('username')
注:取属性跨表可以用.,但filter跨表必須用__
补充:-查询所有学生姓名和所在班级名称,QuerySet
stu_list = Student.objects.all()
for row in stu_list:
row.username,row.age,row.gender,row.cs_id,row.cs.title
select * from Student
[obj,obj,obj,obj]
stu_list = Student.objects.all().values('id','username')
select id,username from Student
[{'id':1,'username':'xx'},{'id':2,username:'']
stu_list = Student.objects.all().values_list('id','username')
[(1,'root'),(2,'alex')]
stu_list = Student.objects.all().values('username','cs__name')
for row in stu_list:
print(row['username'],row['cs__name'])
-找到所有学生所在班级以及校区名称
Student.objects.all().values('username','cs__name','cs__schools__name')
-找到三班的所有学生
正向:Student.objects.filter(cs__name='三班')
反向:obj = Classes.objects.filter(title='三班').first() #obj = Classes.objects.get(title='三班')
obj.student_set.all()
自关联:评论表
pid content article_id user_id reply_id
0 好 1 1 null
1 hjsa 1 2 null
2 ds 1 3 0
3 dsd 1 4 2
多表查询(多对多):1.自动 2.手动 3.手动+自动 方式一:创建多对多的关系:authors = models.ManyToManyField(to='Author')#推荐 authors = models.ManyToManyField(to='Author',through='BookToAuthor',through_fields=['Book','Author']) #使用ManyToManyField只能在第三张表中创建三列数据 书籍对象它的所有关联作者:obj = book_obj.authors.all() 绑定多对多的关系:obj.add(*querySet) obj.remove(author_obj) 查询id为1的书籍的所有作者 book_obj = Book.objects.get(id=3) print(book_obj.authors.all()) 查询作者id为3的所有书籍的名称 author_obj = Author.objects.get(id=3) print(author_obj.book_set.values('name')) 给第4本书加上几个作者 book_obj1 = Book.objects.get(id=4) author_objs = Author.objects.all() # book_obj1.authors.add(*author_objs) #参数为集合加一个*,字典加** 给第4本书移除某些作者 # book_obj1.authors.remove(1) #通过id book_obj1.authors.remove(author_objs) #通过作者对象 查询alex写过的书籍名称和价格 book_obj2 = Book.objects.filter(authors__name='alex').values('name','price') 注:外键是沟通多张表的桥梁 cls_obj = Classes.objects.get(id=1) #增加 cls_obj.teachers.add(1) cls_obj.teachers.add([2,3]) #删除 cls_obj.teachers.remove([1,3]) #清空 cls_obj.teachers.clear() #重置 cls_obj.teachers.set([1,2,3]) #查询属性 teachers_obj = cls_obj.teachers.all() #[teacher1(id,name),teacher2(id,name),...] cls_obj.teachers.all().values('name') 方式二:创建第三张表,关联Book表和Author表 class BookToAuthor(models.Model): book = models.ForeignKey('Book',on_delete='CASCADE') author = models.ForeignKey('Author',on_delete='CASCADE') ctime = models.DateField() #ManyToManyField字段默认生成联合唯一 class Meta: unique_together = [('book','author'],] Book_to_Author.objects.create(book_id=2,author_id=3) 自关联:用处--好友、互粉、关注等 class UserInfo(models.Model): username = models.CharField(max_length=32) email = models.EmailField(max_length=32) friends = models.ManyToManyField(to='UserInfo',related_name='f') #ForeignKey,ManyToManyField字段如涉及反向操作,建议加上related_name字段 def __str__(self): return self.username 补充: for obj in classes_list: print(obj.id,obj.title) for teacher in obj.teachers.all(): print(teacher.name) teacher_obj = Teachers.objects.filter(id=2).first() teacher_obj.classes_set.add(2) cls = Classes.objects.filter(id=2).first() cls.teachers.set([1,2]) class_list = Classes.objects.all().values('id','title','teachers','teachers__name') print(class_list) # t_list = Teachers.objects.all().values('name','cls__title') #related_name = 'cls' t_list = Teachers.objects.all().values('name','classes__title') print(t_list) 找出当前班级任课老师的id列表 teachers_obj = Classes.objects.filter(id=nid).values_list('teachers') id_list = list(zip(*teachers_obj))[0] teachers_obj = Classes.objects.filter(id=nid).values('teachers') id_list = list(zip(*teacher_obj))[1] 模板语言里执行方法不需要加() 例:在模板里展示当前班级的所有老师 {% for row in classes_list %} <td> {% for item in row.teachers.all %} <span>{{ item.name }}</span> {% endfor %} </td> {% endfor %} 注:zip函数: v = [(1,'sa'),(2,'sas')] list(zip(*v))[0] out:<<(1, 2)
聚合函数和分组查询
from django.db.models import Avg,Min,Sum,Max,Count
聚合查询:
查询所有书籍的平均价格
book_avg = Book.objects.all().aggregate(Avg('price'))
查询所有书籍的总价格
book_sum = Book.objects.all().aggregate(Sum('price'))
查询alex出版书的总价格
alex_sum = Book.objects.filter(authors__name='alex').aggregate(alex_money=Sum('price'))
查询alex出版书的数量
alex_count = Book.objects.filter(authors__name='alex').aggregate(Count('id'))
分组查询:
每个作者书的总价格
ret7 = Book.objects.values('authors__name').annotate(Sum('price'))
每个出版社最便宜的书
ret8 = Publish.objects.values('name').annotate(Min('book__price'))
F 和 Q函数
Book.objects.all().update(price=F('price')+10)
ret = Book.objects.filter(Q(price=97)|Q(name='Go'))
ret1 = Book.objects.filter(~Q(name='Go'))
ret2 = Book.objects.filter(Q(name__contains='G'))
ret3 = Book.objects.filter(Q(name='Go'),price='97')
cache机制:当你遍历queryset时,所有匹配的记录会从数据库获取,然后转换成Django的model。这被称为执行
(evaluation).这些model会保存在queryset内置的cache中,这样如果你再次遍历这个queryset,
你不需要重复运行通用的查询。
ret4 = Book.objects.filter(price=97)
for i in ret4:
print(i)
for i in ret4:
print(i)
ret4赋值的时候只会赋值一条sql语句,放入缓存,不会去执行,只有当使用的时候才会去执行sql语句,且多次使用sql语句只执行一次
exists: 简单的使用if语句进行判断也会完全执行整个queryset并且把数据放入cache,虽然你并不需要这些数据!为了避免这个,可以用exists()方法来检查是否有数据:
if ret4.exists():
print('ok')
迭代器:减少缓存。当查询的数据很大时,cache会有很大压力,迭代器可以使数据用多少取多少
ret4 = Book.objects.filter(price=97)
ret4 = ret4.iterator()
print(ret4)
for i in ret4:
print(i)
#这个for循环不输出结果
for i in ret4:
print(i)
补充:# 查询相关API: # <1>filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 # <2>all(): 查询所有结果 # <3>get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。 #-----------下面的方法都是对查询的结果再进行处理:比如 objects.filter.values()-------- # <4>values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列 model的实例化对象,而是一个可迭代的字典序列 # <5>exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象 # <6>order_by(*field): 对查询结果排序 # <7>reverse(): 对查询结果反向排序 # <8>distinct(): 从返回结果中剔除重复纪录 # <9>values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 # <10>count(): 返回数据库中匹配查询(QuerySet)的对象数量。 # <11>first(): 返回第一条记录 # <12>last(): 返回最后一条记录 # <13>exists(): 如果QuerySet包含数据,就返回True,否则返回False。 #扩展查询,有时候DJANGO的查询API不能方便的设置查询条件,提供了另外的扩展查询方法extra: #extra(select=None, where=None, params=None, tables=None,order_by=None, select_params=None (1) Entry.objects.extra(select={'is_recent': "pub_date > '2006-01-01'"}) (2) Blog.objects.extra( select=SortedDict([('a', '%s'), ('b', '%s')]), select_params=('one', 'two')) (3) q = Entry.objects.extra(select={'is_recent': "pub_date > '2006-01-01'"}) q = q.extra(order_by = ['-is_recent']) (4) Entry.objects.extra(where=['headline=%s'], params=['Lennon']) 高级操作:all,filter,exclude,annotate,distinct,order_by, extra,reverse,only,defer,using,row等等 select_related(self, *fields) 性能相关:表之间进行join连表操作,一次性获取关联的数据。 model.tb.objects.all().select_related() model.tb.objects.all().select_related('外键字段') model.tb.objects.all().select_related('外键字段__外键字段') prefetch_related(self, *lookups) 性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。 models.UserInfo.objects.prefetch_related('外键字段') # 获取所有用户表 # 计算获取搭配所有用户类型ID(1,2,...) # 获取用户类型表where id in (用户表中的查到的所有用户ID[1,2,...) select * from UserInfo where id <20 select * from UserType where id in [1,2,...] defer(self, *fields): models.UserInfo.objects.defer('username','id') 或 models.UserInfo.objects.filter(...).defer('username','id') #映射中排除某列数据 only(self, *fields): #仅取某个表中的数据 models.UserInfo.objects.only('username','id') 或 models.UserInfo.objects.filter(...).only('username','id') using(self, alias): 指定使用的数据库,参数为别名(setting中的设置) 自己写sql语句 from django.db import connection,connections cursor = connection.cursor() #connections['default'].cursor() cursor.execute(“”“SELECT * FROM auth_user where id = %s""",[1]) row = cursor.fetchone() models.UserInfo.objects.raw('select id,name from userinfo') Entry.objects.extra(select=('new_id':'select col from sometable where othercol > %s'),select_params=(1,))
总结:1.索引
2.一对多:on_delete
3.一对一和一对多什么关系?unique=True #一对一其实就是 一对多 + 唯一索引
4.多对多
a.自动创建 b.手动创建 c.自动+手动
-#自关联:互粉、好友#
PS:related_name
必须要记住的:
创建数据库:related_name
related_query_name
#表和表之间可以关联
多对多自关联 -->互粉
一对多自关联 -->评论楼
操作数据库 .all
.values
.values_list
.filter
.delete
.update
.create
m.add
m.set
m.clear
m.remove
.only
.defer
.extra
.raw
原生sql
select_related
prefetch_related
更多请关注:https://www.cnblogs.com/zhangyafei/p/10350281.html
六、admin:后台管理工具
后台管理的特点
- 权限管理
- 少前端样式
- 快速开发
创建超级用户
python manage.py createsuperuser
username:root
email:root@qq.com
password: xxxxxxx
password: xxxxxxx
admin注册
# admin.py中自定制
from django.contrib import admin
from app01 import models
class BookAdmin(admin.ModelAdmin):
list_display = ['id','name','price','pub_date'] #每个表首页显示每一条记录的字段
list_editable = ['name','price'] #那些字段可编辑
filter_horizontal = ['authors'] #详细页水平过滤字段 主要针对多对多字段
# filter_vertical =[] #垂直过滤
list_per_page = 3 #分页,每页显示多少条记录
search_fields = ['name','authors__name','publish__name'] #检索框
list_filter = ('pub_date','publish','authors') #表首页过滤字段
ordering = ['price','id'] #按照某字段排序
fieldsets = [
(None, {'fields': ['name']}), #显示字段
('price information', {'fields': ['price', "publish"], 'classes': ['collapse']}), # 隐藏字段,隐藏样式
]
# 自定制显示字段名称:
models.py
class Book(models.Model):
name = models.CharField(max_length=20,verbose_name='姓名')
price = models.IntegerField('价格')
pub_date = models.DateField('出版日期')
publish = models.ForeignKey('Publish',on_delete='CASCADE',verbose_name='出版商')
authors = models.ManyToManyField('Author',verbose_name='作者')
admin.site.register(models.Author)
admin.site.register(models.Book,BookAdmin)
admin.site.register(models.Publish)
注:settings中设置:LANGUAGE_CODE = 'zh-hans' #中文 #'en-us'
补充:对django内置auth表自定义扩展
from django.db import models
from django.contrib.auth.models import AbstractUser
class UserProfile(AbstractUser):
""" 用户信息表 """
nickname = models.CharField(max_length=50, verbose_name='昵称', default='')
birthday = models.DateField(verbose_name='生日', null=True, blank=True)
gender = models.CharField(choices=(('male', '男'),('female', '女')), max_length=5, default='female')
address = models.CharField(max_length=100, default='')
mobile = models.CharField(max_length=11, null=True, blank=True)
image = models.ImageField(upload_to='image/%Y/%m', default='image/default.png', max_length=100)
class Meta:
verbose_name = '用户信息'
verbose_name_plural = verbose_name
def __str__(self):
return self.username
settings配置
AUTH_USER_MODEL = 'users.UserProfile'
七、后台管理工具之xadmin
1. 下载安装xadmin
下载源码: https://github.com/sshwsfc/xadmin
然后把下载的文件夹中的xadmin移到项目根目录
2. 安装依赖包
requirements.txt
xlwt==1.3.0 six==1.12.0 Django==2.1.7 httplib2==0.12.1 future==0.17.1 django_crispy_forms==1.7.2 django_formtools==2.1 django_reversion==3.0.3 xlsxwriter==1.1.5
安装
pip install -r requirements.txt
3. settings配置
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'xadmin', # 新增
'crispy_forms', # 新增
]
4. urls配置
from django.urls import path
import xadmin
urlpatterns = [
path('xadmin/', xadmin.site.urls),
]
5. adminx注册
在每个app内新建一个adminx.py的文件
基础配置
# -*- coding: utf-8 -*- """ @Datetime: 2019/2/26 @Author: Zhang Yafei """ import xadmin from xadmin import views from users import models class BaseSetting(object): """ 主题功能设置 """ enable_themes = True use_bootswatch = True class GlogalSettings(object): site_title = '幕学后台管理系统' site_footer = '幕学在线网' menu_style = 'accordion' class EmailVerifyRecordAdmin(object): list_display = ['code', 'email', 'send_type', 'send_time'] search_fields = ['code', 'email', 'send_type'] list_filter = ['code', 'email', 'send_type', 'send_time'] class BannerAdmin(object): list_display = ['title', 'image', 'url', 'index', 'add_time'] search_fields = ['title', 'image', 'url', 'index'] list_filter = ['title', 'image', 'url', 'index', 'add_time'] xadmin.site.register(models.EmailVerifyRecond, admin_class=EmailVerifyRecordAdmin) xadmin.site.register(models.Banner, admin_class=BannerAdmin) xadmin.site.register(views.BaseAdminView, BaseSetting) xadmin.site.register(views.CommAdminView, GlogalSettings)

