

Python基础(二)
一、内置函数

如何查看Python内置函数?
方式一:官方文档查看
方式二:所有内置函数:dir(__builtin__)
查看某个内置函数的用法:help(函数名),比如:help(str)
查看某个函数的位置:random.__file__
random.__file__ 'd:\\pytho3.6\\lib\\random.py'
二、collection系列
1.计数器(Counter)
"""
Counter
Counter是一个简单的计数器,例如,统计字符出现的个数:
"""
from collections import Counter
c = Counter('programming')
print(c)
a = Counter({'a':12,'b':43})
# Counter具有字典所有的功能+自己的功能
a = Counter({'name':'zhangyafei','age':23})
a['name']
Out[108]: 'zhangyafei'
2、有序字典(orderedDict )
orderdDict是对字典类型的补充,他记住了字典元素添加的顺序
"""
OrderedDict
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
"""
from collections import OrderedDict
d = dict([('a', 1), ('b', 2), ('c', 3)])
d # dict的Key是无序的
od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
od # OrderedDict的Key是有序的
# 注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
3、默认字典(defaultdict)
""" defaultdict 使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict: """ from collections import defaultdict dd = defaultdict(lambda: 'N/A') dd['key1'] = 'abc' dd['key1'] # key1存在 dd['key2'] # key2不存在,返回默认值
4、可命名元组(namedtuple)
根据nametuple可以创建一个包含tuple所有功能以及其他功能的类型。
"""
namedtuple是一个函数,它用来创建一个自定义的tuple对象,并且规定了tuple元素的个数,并可以用属性而不是索引来引用tuple的某个元素。
这样一来,我们用namedtuple可以很方便地定义一种数据类型,它具备tuple的不变性,又可以根据属性来引用,使用十分方便。
"""
from collections import namedtuple
Point = namedtuple('Point', ['x', 'y'])
p = Point(1, 2)
p.x
p.y
Circle = namedtuple('Circle', ['x', 'y', 'r'])
5、双向队列(deque)
一个线程安全的双向队列
"""
deque
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
"""
from collections import deque
q = deque(['a', 'b', 'c'])
q.append('x')
q.appendleft('y')
q
三、可变类型和不可变类型
可变类型:列表、字典、集合
不可变类型:数字、布尔、字符串、元组
这里的可变不可变,是指内存中的那块内容(value)是否可以被改变
- 不可变类型
# 数字 In [93]: id(a) Out[93]: 1850764656 In [94]: a += 1 In [95]: id(a) Out[95]: 1850764688 # 字符串 In [88]: a = '123' In [89]: id(a) Out[89]: 942746951216 In [90]: a += '456' In [91]: id(a) Out[91]: 942746981576 # 元组 In [79]: a = (1,2,3) In [80]: b = (4,5,6) In [81]: id(a) Out[81]: 942746089296 In [82]: id(b) Out[82]: 942746396784 In [83]: a[1] Out[83]: 2 In [84]: a[1] = 3 --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-84-23f2cf2bdf70> in <module>() ----> 1 a[1] = 3 TypeError: 'tuple' object does not support item assignment
可变类型
# 列表
In [29]: a = [1,2,3]
In [30]: id(a)
Out[30]: 942745728456
In [31]: a.append(4)
In [32]: id(a)
Out[32]: 942745728456
# 字典
In [33]: c = {'k1':'v1','k2':'v2'}
In [34]: id(c)
Out[34]: 942746626232
In [35]: c['k3'] = 'v3'
In [36]: c
Out[36]: {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
In [37]: id(c)
Out[37]: 942746626232
字典的key只能是不可变类型,可变类型不可哈希
In [96]: dic = {1:'v1',2:'v2'}
In [97]: dic = {'k1':'v1','k2':'v2'}
In [98]: dic = {(1,2):'v1',(2,3):'v2'}
In [99]: dic = {[1,2]:'v1',[2,3]:'v2'}
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-99-4e27abb80f56> in <module>()
----> 1 dic = {[1,2]:'v1',[2,3]:'v2'}
TypeError: unhashable type: 'list'
In [100]: dic = {{'k':'v'}:'v1',{'k1':'v1'}:'v2'}
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-100-25f010250cc4> in <module>()
----> 1 dic = {{'k':'v'}:'v1',{'k1':'v1'}:'v2'}
TypeError: unhashable type: 'dict'
四、迭代器、生成器、可迭代对象
关于此部分内容大家请看我这篇文章
五、深浅拷贝
何为深浅拷贝?
In [49]: a = [1,2,3] In [50]: b = a In [51]: a.append(4) In [52]: a Out[52]: [1, 2, 3, 4] In [53]: b Out[53]: [1, 2, 3, 4]
唉?我们把a赋值给了b,结果a添加了一个元素,b也跟着添加了。这是为什么,我复制了一份不就和原来的没关系了吗?
这其实就是浅拷贝,b = a其实是把a指向的那个列表的内存的引用给了b,当a指向的那个内存发生改变时,b也会同时发生变化。这就是浅拷贝。
那我们不想拷贝它的引用,我们只想拷贝值怎么办?a.copy()就搞定了
In [54]: a = [1,2,3] In [55]: b = a.copy() # 深拷贝,只拷贝当前变量所在内存中存储的值,而不是引用 In [56]: b Out[56]: [1, 2, 3] In [57]: a.append(4) In [58]: a Out[58]: [1, 2, 3, 4] In [59]: b Out[59]: [1, 2, 3]
六、文件IO操作
1. 打开和关闭文件
- 打开文件:open 函数
"你必须先用Python内置的open()函数打开一个文件,创建一个file对象,相关的方法才可以调用它进行读写。"
语法: file object = open(file_name [, access_mode][, buffering]) 各个参数的细节如下: file_name:file_name变量是一个包含了你要访问的文件名称的字符串值。 access_mode:access_mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。 buffering:如果buffering的值被设为0,就不会有寄存。如果buffering的值取1,访问文件时会寄存行。如果将buffering的值设为大于1的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。 不同模式打开文件的完全列表: 模式 描述 r 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 rb 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 r+ 打开一个文件用于读写。文件指针将会放在文件的开头。 rb+ 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 w 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 wb 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 w+ 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 wb+ 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 a 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 ab 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 a+ 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 ab+ 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 以下是和file对象相关的所有属性的列表: 属性 描述 file.closed 返回true如果文件已被关闭,否则返回false。 file.mode 返回被打开文件的访问模式。 file.name 返回文件的名称。 """
示例
open(文件名,访问模式)
f = open("test.txt","w")
- 关闭文件: close()方法
File 对象的 close()方法刷新缓冲区里任何还没写入的信息,并关闭该文件,这之后便不能再进行写入。
当一个文件对象的引用被重新指定给另一个文件时,Python 会关闭之前的文件。用 close()方法关闭文件是一个很好的习惯。
语法:
fileObject.close()
2. 读写文件
4.1 write()方法
write()方法可将任何字符串写入一个打开的文件。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
write()方法不会在字符串的结尾添加换行符('\n'):
语法:
fileObject.write(string)
在这里,被传递的参数是要写入到已打开文件的内容。
例子:
f = open(file,'w',encoding='utf-8')
f.write('ip_type,ip,port,speed,position,live_time,update_time\n')
# 关闭打开的文件
fo.close()
4.2 read()方法:
"从一个打开的文件中读取一个字符串。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。"
语法:
fileObject.read([count])
在这里,被传递的参数是要从已打开文件中读取的字节计数。该方法从文件的开头开始读入,如果没有传入count,它会尝试尽可能多地读取更多的内容,很可能是直到文件的末尾。
# 打开一个文件
fo = open("foo.txt", "r+")
str = fo.read(10)
print("读取的字符串是 : ", str)
# 关闭打开的文件
fo.close()
以上实例输出结果:
读取的字符串是 : www.runoob
4.3 readline()方法:一次读取一行
4.4 readlines()方法:读取所有内容,以列表形式返回,每一行作为列表中的一个元素。
4.5 文件位置:
文件定位
tell()方法告诉你文件内的当前位置, 换句话说,下一次的读写会发生在文件开头这么多字节之后。
seek(offset [,from])方法改变当前文件的位置。Offset变量表示要移动的字节数。From变量指定开始移动字节的参考位置。
如果from被设为0,这意味着将文件的开头作为移动字节的参考位置。如果设为1,则使用当前的位置作为参考位置。如果它被设为2,那么该文件的末尾将作为参考位置。
Python的os模块给我们提供执行文件处理操作的方法
3. 删除文件
remove()方法
你可以用remove()方法删除文件,需要提供要删除的文件名作为参数。
语法:
os.remove(file_name)
例子:
下例将删除一个已经存在的文件test2.txt。
import os
# 删除一个已经存在的文件test2.txt
os.remove("test2.txt")
4. 文件重命名
rename()方法需要两个参数,当前的文件名和新文件名。 语法: os.rename(current_file_name, new_file_name) 例子: 下例将重命名一个已经存在的文件test1.txt。 import os # 重命名文件test1.txt到test2.txt。 os.rename( "test1.txt", "test2.txt" )
5. 创建和删除文件夹
创建文件夹
mkdir()方法
可以使用os模块的mkdir()方法在当前目录下创建新的目录们。你需要提供一个包含了要创建的目录名称的参数。
语法:
os.mkdir("newdir")
例子:
下例将在当前目录下创建一个新目录test。
import os
# 创建目录test
os.mkdir("test")
删除文件夹
r、mdir()方法
rmdir()方法删除目录,目录名称以参数传递。
在删除这个目录之前,它的所有内容应该先被清除。
语法:
os.rmdir('dirname')
例子:
以下是删除" /tmp/test"目录的例子。目录的完全合规的名称必须被给出,否则会在当前目录下搜索该目录。
import os
# 删除”/tmp/test”目录
os.rmdir( "/tmp/test" )
6. 获取和切换目录
获取当前目录
getcwd()方法:
getcwd()方法显示当前的工作目录。
语法:
os.getcwd()
切换指定目录
chdir()方法
可以用chdir()方法来改变当前的目录。chdir()方法需要的一个参数是你想设成当前目录的目录名称。
语法:
os.chdir("newdir")
7. 获取当前目录下的所有文件列表
获取当前目录下所有文件列表 os.listdir() os.walk(top[, topdown=True[, onerror=None[, followlinks=False]]])
示例


#1.获取文件名 old_file_name = input("请输入要备份的文件名(需要后缀):") #2。打开这个文件("r") f_read = open(old_file_name,"r") #new_file_name = old_file_name+"[复件]" position = old_file_name.rfind(".") new_file_name = old_file_name[0:position]+"[复件]"+old_file_name[position:] #3.创建一个文件,xxx[复件].txt f_write = open(new_file_name,"w") #4.往源文件中读取内容,写入备份的文件中 #content = f_read.read() #f_write.write(content) while True: content = f_read.read(1024) if len(content)==0: break f_write.write(content) #5.关闭两个文件 f_read.close() f_write.close() 文件备份
import os #1. 获取一个要重命名的文件夹的名字 folder_name = input("请输入要重命名的文件夹:") #2.获取文件夹中所有的文件名字 file_names = os.listdir(folder_name) ''' 第一种方法 os.chdir(folder_name) 3.对获取的名字进行重命名即可 for name in file_names: print(name) os.rename(name,"[京东出品]-"+name) ''' #第二种方法 for name in file_names: #print(name) old_file_name = "./"+folder_name+"/"+name new_file_name = "./"+folder_name+"/"+"[京东出品]"+name os.rename(old_file_name,new_file_name) print(new_file_name) 批量文件重命名
自定义函数
一、为什么要有函数
while True:
if cpu利用率 > 90%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
if 硬盘使用空间 > 90%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
if 内存占用 > 80%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
我们发现,if下面的相同的内容被被多次调用,代码很冗余,于是,我们可以这样写
def 发送邮件(内容)
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
while True:
if cpu利用率 > 90%:
发送邮件('CPU报警')
if 硬盘使用空间 > 90%:
发送邮件('硬盘报警')
if 内存占用 > 80%:
上述的两种实现方式,第二次必然比第一次的重用性和可读性要好,其实这就是函数式编程和面向过程编程的区别:
- 函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可
- 面向对象:对函数进行分类和封装,让开发“更快更好更强...”
函数式编程最重要的是增强代码的重用性和可读性
二、函数的定义和调用
函数定义 def 函数名(参数):
函数体
return 返回值
函数调用 函数名()
函数的定义主要有如下要点:
def:表示函数的关键字 函数名:函数的名称,日后根据函数名调用函数 函数体:函数中进行一系列的逻辑计算,如:发送邮件、计算出 [11,22,38,888,2]中的最大数等... 参数:为函数体提供数据 返回值:当函数执行完毕后,可以给调用者返回数据。
以上要点中,比较重要有参数和返回值:
1.返回值:函数是一个功能块,该功能到底执行成功与否,需要通过返回值来告知调用者。
def 发送短信():
发送短信的代码...
if 发送成功:
return True
else:
return False
while True:
# 每次执行发送短信函数,都会将返回值自动赋值给result
# 之后,可以根据result来写日志,或重发等操作
result = 发送短信()
if result == False:
记录日志,短信发送失败...
2. 参数
·为什么要有参数?
def CPU报警邮件() #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 def 硬盘报警邮件() #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 def 内存报警邮件() #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 while True: if cpu利用率 > 90%: CPU报警邮件() if 硬盘使用空间 > 90%: 硬盘报警邮件() if 内存占用 > 80%: 内存报警邮件() 上例,无参数实现
def 发送邮件(邮件内容) #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 while True: if cpu利用率 > 90%: 发送邮件("CPU报警了。") if 硬盘使用空间 > 90%: 发送邮件("硬盘报警了。") if 内存占用 > 80%: 发送邮件("内存报警了。") 上列,有参数实现
函数的有三中不同的参数:
- 普通参数
- 默认参数
- 动态参数
def sum_2_nums(a,b): #a = 10 #b = 20 result = a+b print("%d + %d = %d"%(a,b,result)) num1 = int(input("请输入第一个数字:")) num2 = int(input("请输入第二个数字:")) #调用函数 sum_2_nums(num1,num2)
def test(a,d,b=22,c=33): result = a+b+c print(a) print(b) print(c) print(d) print("result=%d"%result) test(11,22,b=12) test(33,33) test(d=44,a=11,c=44)
def sum_2_nums(a,b,c=33,*args,**kwargs): print("-"*30) print(a) print(b) print(c) print(args) print(kwargs) #result = a+b+args #print("result=%d"%result) sum_2_nums(11,22,33,44,55,66,77,task=99,done=89) #sum_2_nums(11)#错误,因为形参中至少要2个实参
def test(a,b,c=33,*args,**kwargs): print("-"*30) print(a) print(b) print(c) print(args) print(kwargs) #result = a+b+args #print("result=%d"%result) #test(11,22,33,44,55,66,77,task=99,done=89) A=(44,55,66) B={"name":"laowang","age":18} test(11,22,33,*A,**B) #sum_2_nums(11)#错误,因为形参中至少要2个实参
def test_kwargs(actions=None, **kwargs): print('actions:', actions) print('kwargs:', kwargs) def test_args(actions=None, *args): print('actions:', actions) print('args:', args) test_args([1,2,3]) # actions: [1, 2, 3] # args: () test_args(1,2,3) # actions: 1 # args: (2, 3) test_args(*[1, 2, 3]) # actions: 1 # args: (2, 3) test_kwargs({'get':'list', 'post': 'create'}) # actions: {'get': 'list', 'post': 'create'} # kwargs: {} test_kwargs(get='list', post='create') # actions: None # kwargs: {'get': 'list', 'post': 'create'} test_kwargs(**{'get':'list', 'post': 'create'}) # actions: None # kwargs: {'get': 'list', 'post': 'create'}
实例:打印佛祖
def print_fuzu(): print(" _ooOoo_ ") print(" o8888888o ") print(" 88 . 88 ") print(" (| -_- |) ") print(" O\\ = /O ") print(" ____/`---'\\____ ") print(" . ' \\| |// `. ") print(" / \\||| : |||// \\ ") print(" / _||||| -:- |||||- \\ ") print(" | | \\\\\\ - /// | | ") print(" | \\_| ''\\---/'' | | ") print(" \\ .-\\__ `-` ___/-. / ") print(" ___`. .' /--.--\\ `. . __ ") print(" ."" '< `.___\\_<|>_/___.' >'"". ") print(" | | : `- \\`.;`\\ _ /`;.`/ - ` : | | ") print(" \\ \\ `-. \\_ __\\ /__ _/ .-` / / ") print(" ======`-.____`-.___\\_____/___.-`____.-'====== ") print(" `=---=' ") print(" ") print(" ............................................. ") print(" 佛祖镇楼 BUG辟易 ") print(" 佛曰: ") print(" 写字楼里写字间,写字间里程序员; ") print(" 程序人员写程序,又拿程序换酒钱。 ") print(" 酒醒只在网上坐,酒醉还来网下眠; ") print(" 酒醉酒醒日复日,网上网下年复年。 ") print(" 但愿老死电脑间,不愿鞠躬老板前; ") print(" 奔驰宝马贵者趣,公交自行程序员。 ") print(" 别人笑我忒疯癫,我笑自己命太贱; ") print(" 不见满街漂亮妹,哪个归得程序员?") print_fuzu()
扩展:发送邮件实例
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
msg = MIMEText('邮件内容', 'plain', 'utf-8')
msg['From'] = formataddr(["张亚飞",'1271570224@qq.com'])
msg['To'] = formataddr(["走人",'2464392538@qq.com'])
msg['Subject'] = "主题"
server = smtplib.SMTP_SSL("smtp.qq.com", 465)
server.login("1271570224@qq.com", "euvtrglugggubagj")
server.sendmail('1271570224@qq.com', ['2464392538@qq.com',], msg.as_string())
server.quit()
三、lambda表达式
匿名函数:lambda 参数:式子
作用:书写比较简单,不需要声明函数的名称,当功能为一些比较简单的加加减减时,用lambda匿名函数,否则用def
注:匿名函数默认带有返回值
实例:对字母排序
s = 'string' s = "".join((lambda x: (x.sort(), x)[1])(list(s))) s Out[4]: 'ginrst'
应用:列表元素为字典时按照字典的value值排序,list.sort(key x:x['age'])
实例:
def test(a,b,func): result = func(a,b) print(result) test(11,22,lambda x,y:x+y)
lambda存在意义就是对简单函数的简洁表示
Python高级特性
一、 map
求一个序列或者多个序列进行函数映射(遍历)之后的值,就该想到map这个函数,它是python自带的函数,在python3.*之后返回的是迭代器,同filter,需要进行列表转换.

调用: map(function,iterable1,iterable2),function中的参数值不一定是一个x,也可以是x和y,甚至多个;后面的iterable表示需要参与function运算中的参数值,有几个参数值
就传入几个iterable
map函数的原型是map(function, iterable, …),它的返回结果是一个列表。
参数function传的是一个函数名,可以是python内置的,也可以是自定义的。
参数iterable传的是一个可以迭代的对象,例如列表,元组,字符串这样的。
这个函数的意思就是将function应用于iterable的每一个元素,结果以列表的形式返回。注意到没有,iterable后面还有省略号,意思就是可以传很多个iterable,如果有额外的
iterable参数,并行的从这些参数中取元素,并调用function。如果一个iterable参数比另外的iterable参数要短,将以None扩展该参数元素。
map()函数接收两个参数,一个是函数,一个是序列,map将传入的函数依次作用到序列的每个元素,并把结果作为新的list返回。
# 1.map自定义函数 def f(x): return x*x a = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9]) list(a) # 2.map复杂函数 list(map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9])) == [str(x) for x in [1,2,3,4,5,6,7,8,9]] # 3.实例 def add(x,y,z): return x,y,z list1 = [1,2,3] list2 = [1,2,3,4] list3 = [1,2,3,4,5] list4 = [1,2,3,4,5,6] res = map(add, list1, list2, list3) list(res) def add(x,y,z): return x+y+z list1=[1,2,3] list2=[1,2,3] list3=[1,2,3] list(map(add,list1,list2,list3)) func = lambda x,y,z:x+y+z func(list1,list2,list3) def format_name(s): return s.capitalize() list(map(lambda x:x.capitalize(), ['adam', 'LISA', 'barT'])) foo = [2, 18, 9, 22, 17, 24, 8, 12, 27] list(map(lambda x: x * 2 + 10, foo)) print ([x * 2 + 10 for x in foo])
二、filter
filter的功能是过滤掉序列中不符合函数条件的元素,当序列中要删减的元素可以用某些函数描述时,就应该想起filter函数。
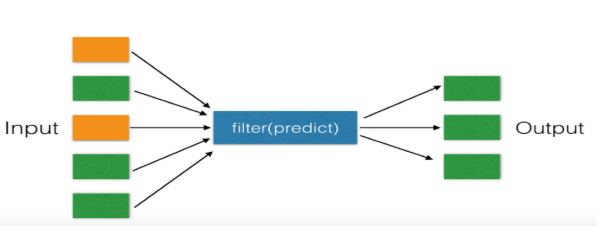
调用: filter(function,sequence),function可以是匿名函数或者自定义函数,它会对后面的sequence序列的每个元素判定是否符合函数条件,返回TRUE或者FALSE,从而只留下TRUE
的元素;sequence可以是列表、元组或者字符串
Python内建的filter()函数用于过滤序列。和map()类似,filter()也接收一个函数和一个序列。和map()不同的时,filter()把传入的函数依次作用于每个元素,然后根据返回值是True
还是False决定保留还是丢弃该元素。
例1,在一个list中,删掉偶数,只保留奇数,可以这么写: def is_old(x): return x%2 == 0 list(filter(is_old,[1,2,3,4,5,6,7,8,9,10])) print([x for x in foo if x%3==0]) 例2:在一个list中,只保留能被三整除的数字 list(filter(lambda x: x % 3 == 0, foo))) print ([x for x in foo if x % 3 == 0])
三、reduce
对一个序列进行压缩运算,得到一个值。但是reduce在python2的时候是内置函数,到了python3移到了functools模块,所以使用之前需要 from functools import reduce
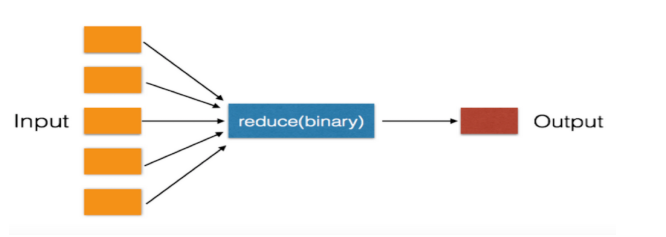

调用: reduce(function,iterable),其中function必须传入两个参数,iterable可以是列表或者元组 reduce() 函数会对参数序列中元素进行累积。 函数将一个数据集合(链表,元组等)中的所有数据进行下列操作:用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数 据用 function 函数运算,最后得到一个结果。 reduce(function, iterable[, initializer]) function -- 函数,有两个参数 iterable -- 可迭代对象 initializer -- 可选,初始参数
from functools import reduce print (reduce(lambda x, y: x + y, foo)) def char2num(s): return {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}[s] def str2int(s): return reduce(lambda x,y: x*10+y, map(char2num, s)) print(str2int('12345')) def kfactorial(k): """求k的阶乘""" if k == 0 or k == 1: return 1 from functools import reduce return reduce(lambda x,y:x*y,list(range(1,k+1))) def kfactorial2(k): a = 1 for i in range(1,k+1): a *= i return a def kfactorial3(k): if k == 0 or k == 1: return 1 else: return kfactorial3(k-1) kfactorial(5) kfactorial2(6) kfactorial3(7)
四、闭包
定义:在函数内部再定义⼀个函数, 并且这个函数⽤到了外边函数的变量, 那么将这个函数成为闭包
- 示例
def test(number):
print("-----1------")
#在函数内部再定义⼀个函数, 并且这个函数⽤到了外边函数的变量, 那么将这个函数成为闭包
def test_in(number2):
print("-----2-----")
print(number+number2)
print("---3---")
#其实这⾥返回的就是闭包的结果
return test_in
#给test函数赋值, 这个100就是给参数number
ret = test(100)
print("-"*30)
#注意这⾥的1其实给参数number2
ret(1)
ret(100)
ret(200)
def test(a,b): def test_in(x): print(a*x+b) return test_in line1 =test(1,1) line1(0) line2 = test(10,4) line2(0) line1(0)
"""闭包中修改外部函数变量应声明nonlocal""" def test(): x = 10 def test_in(): nonlocal x x += 1 print(x) return test_in c = test() c() # 不声明nonlocal UnboundLocalError: local variable 'x' referenced before assignment # 声明之后 11
五、装饰器
装饰器是函数,只不过该函数可以具有特殊的含义,装饰器用来装饰函数或类,使用装饰器可以在函数执行前和执行后添加相应操作。换句话说,Decorator 通过返回包装对象实现间接调用,以此插入额外逻辑。应该算是言简意赅了。
def w1(func): def inner(): print("---正在验证权限---") if True: func() else: print("没有权限") return inner @w1 def f1(): print("---f1---") @w1 def f2(): print("---f2---") #innerFunc = w1(f1) #innerFunc() #f1 = w1(f1) f1() f2()
#定义函数: 完成包裹数据 def makeBold(fn): def wrapped(): print("-----1-----") return "<b>" + fn() + "</b>" return wrapped #定义函数: 完成包裹数据 def makeItalic(fn): def wrapped(): print("-------2-----") return "<i>" + fn() + "</i>" return wrapped @makeBold @makeItalic def test3(): print("-------3------") return "hello world-3" print(test3())
def w1(func): print("----正在装饰1----") def wrpped(): print("----正在验证权限1------") return func() return wrpped def w2(func): print("----正在装饰2----") def wrpped(): print("----正在验证权限2------") return func() return wrpped #只要python解释器执行到了这个代码,那么就会自动的进行装饰,而不是等到调用的时候才装饰的 @w1 #f1 = w1(w2(f1())) @w2 #f1 = w2(f1()) def f1(): print("-----f1-----") #在调用f1之前,已经进行装饰了 f1()
def func(functionName): print("-----func---1----") def func_in(): print("----func_in---1--") functionName() print("---func_in---2---") print("----func---2---") return func_in @func def test(): print("---test---") #test = func(test) test()
def func(functionName): print("-----func---1----") def func_in(a,b): print("----func_in---1--") functionName(a,b) print("---func_in---2---") print("----func---2---") return func_in @func def test(a,b): print("---test- a=%d,b=%d---"%(a,b)) #test = func(test) test(11,22)
def func(functionName): print("-----func---1----") def func_in(*args,**kwargs): print("----func_in---1--") functionName(*args,**kwargs) print("---func_in---2---") print("----func---2---") return func_in @func def test(a,b,c): print("---test- a=%d,b=%d,c=%d---"%(a,b,c)) @func def test1(a,b,c,d): print("---test- a=%d,b=%d,c=%d,d=%d---"%(a,b,c,d)) #test = func(test)
def func(functionName): print("-----func---1----") def func_in(): print("----func_in---1--") return functionName() print("---func_in---2---") print("----func---2---") return func_in @func def test(): print("---test----") return "haha" ret = test() print("test return value is %s"%ret)
def func(functionName): def func_in(*args,**kwargs): print("---记录日志------") ret = functionName(*args,**kwargs) return ret return func_in @func def test(): print("---test----") return "haha" @func def test2(): print("----test2---") @func def test3(a): print("----test3--a=%d--"%a) ret = test() print("test return value is %s"%ret) a = test2() print("test2 return value is %s"%a) test3(11)
def func_arg(arg): def func(functionName): def func_in(): print("---记录日志--arg=%s----"%arg) if arg=="heihei": functionName() functionName() else: functionName() return func_in return func #1.先执行func_arg("heihei")函数,这个函数return 的结果是func这个函数的引用 #2.@func #3使用@func对test进行装饰 @func_arg("heihei") def test(): print("---test----") @func_arg("haha") def test2(): print("-----test2------") test() test2()
class Eat(object): # 装饰器 Eta # :return def __init__(self,func): self.func = func def __call__(self, *args, **kwargs): print('i am eating') return self.func(*args,**kwargs) @Eat def wash(): # 洗手 # :return: print('i am washing') wash() print(wash.__class__) # # class Eat(object): # """ # 装饰器 Eta # :return # """ # def __call__(self, func): # @wraps(func) # def eat(*args,**kwargs): # print('i am eating') # return func(*args,**kwargs) # return eat # # # @Eat() # def wash(): # """ # 洗手 # :return: # """ # print('i am washing') # # # wash() # print(wash.__name__)
from functools import wraps def decorator_name(f): @wraps(f) def decorated(*args, **kwargs): if not can_run: return "Function will not run" return f(*args, **kwargs) return decorated @decorator_name def func(): return("Function is running") can_run = True print(func()) # Output: Function is running can_run = False print(func()) # Output: Function will not run
from functools import wraps def auth(func): @wraps(func) # 伪装的更彻底 def inner(*args,**kwargs): print('前') ret = func(*args,**kwargs) print('后') return ret return inner @auth def index(): print('index') @auth def detail(): print('index') print(index.__name__) print(detail.__name__)
def timeit(func): """ 装饰器: 判断函数执行时间 :param func: :return: """ @wraps(func) def inner(*args, **kwargs): start = time.time() ret = func(*args, **kwargs) end = time.time() - start if end < 60: print(f'花费时间:\t{round(end, 2)}秒') else: min, sec = divmod(end, 60) print(f'花费时间\t{round(min)}分\t{round(sec, 2)}秒') return ret return inner
六、递归
利用函数编写如下数列:
斐波那契数列指的是这样一个数列 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233,377,610,987,1597,2584,4181,6765,10946,17711,28657,46368
# 子问题的重复计算
def fabnacci_rec(n):
if n == 1 or n == 2:
return 1
return fabnacci_rec(n - 1) + fabnacci_rec(n - 2)
def fibonacci_no_rec1(max):
n, a, b = 1, 0, 1
while n < max:
# print(b)
a, b = b, a + b
n = n + 1
return b
# 动态规划 DP 的思想 = 最优子结构递推式 重复子问题
def fibonacci_no_rec2(n):
f = [0, 1, 1]
if n > 2:
for i in range(n - 2):
num = f[-1] + f[-2]
f.append(num)
return f[n]
if __name__ == '__main__':
print(fabnacci_rec(10))
print(fibonacci_no_rec1(10))
print(fibonacci_no_rec2(10))
七、可变、不可变类型
可变类型:字典,列表
不可变类型:数字,字符串,元组,集合
注:字典中的key值可以位数字,字母,元组,但不可为列表,不符合哈希函数规则
案例
#用来存储名片(列表) card_infors = [] def print_menu(): """完成打印功能菜单""" print("="*50) print(" 名片管理系统 v0.1") print(" 1.添加一个名片") print(" 2.删除一个名片") print(" 3.修改一个名片") print(" 4.查询一个名片") print(" 5.显示所有名片") print(" 6.保存信息") print(" 7.退出系统") print("="*50) def add_new_card_infor(): """完成添加一个新的名片""" new_name = input("请输入新的名字:") new_qq = input("请输入新的qq:") new_weixin = input("请输入新的微信:") new_addr = input("请输入新的住址:") #定义一个新的字典,用来存储一个新的名片 new_infor ={} new_infor['name'] = new_name new_infor['qq'] = new_qq new_infor['weixin'] = new_weixin new_infor['addr'] = new_addr #将一个字典添加到列表中 global card_infors card_infors.append(new_infor) print(card_infors) def del_card_infor(): """用来查询一个名片""" global card_infors find_flag=0 del_name = input("删除的姓名是:") for temp in card_infors: if del_name == temp['name']: card_infors.remove(temp) find_flag = 1 print(card_infors) break #判断是否找到了 if find_flag==0: print("查无此人") def show_all_infor(): """显示所有的名片信息""" global card_infors print("姓名\tQQ\t微信\t住址") for temp in card_infors: print("%s\t%s\t%s\t%s\t"%(temp['name'],temp['qq'],temp['weixin'],temp['addr'])) def chang_card_infor(): """完成对名片信息的修改""" global card_infors find_flag=0 name = input("你要修改的名片的姓名是:") for temp in card_infors: if name==temp['name']: temp['name'] = input("姓名:") temp['qq'] = input("qq:") temp['weixin'] = input("微信:") temp['addr'] = input("地址:") print("姓名\tQQ\t微信\t住址") print("%s\t%s\t%s\t%s\t"%(temp['name'],temp['qq'],temp['weixin'],temp['addr'])) find_flag=1 break if find_flag==0: print("查无此人") def find_card_infor(): """查找名片上的信息""" global card_infors find_name = input("请输入要查找的名字:") find_flag = 0 #默认表示没有找到 for temp in card_infors: if find_name == temp['name']: print("%s\t%s\t%s\t%s\t"%(temp['name'],temp['qq'],temp['weixin'],temp['addr'])) find_flag = 1 break #else: #print("查无此人") #p判断是否找到了 if find_flag==0: print("查无此人") def save_2_file(): """把已经添加的信息保存到文件中""" #f = open("backup.data","w") f = open("backup.data", "w") #f.write(str(card_infors) f.write(str(card_infors)) f.close() def load_infor(): global card_infors try: f = open("backup.data","r") card_infors = eval(f.read()) f.close() except Exception: pass def main(): """完成对整个程序的控制""" #恢复(加载)之前的数据到程序中 load_infor() #1. 打印功能提示 print_menu() while True: #2.获取用户的输入 num = int(input("请输入操作序列:")) #3.根据用户的输入执行相应的功能 if num==1: add_new_card_infor() elif num==2: del_card_infor() elif num==3: chang_card_infor() elif num==4: find_card_infor() elif num==5: show_all_infor() elif num==6: save_2_file() elif num==7: break else: print("你输入的信息有误,请重新输入!") if __name__=="__main__": main()

