

Python基础(一)
Python入门知识拾遗
一、进制
- 计算机中底层所有的数据都是以 `010101`的形式存在(图片、文本、视频等)。
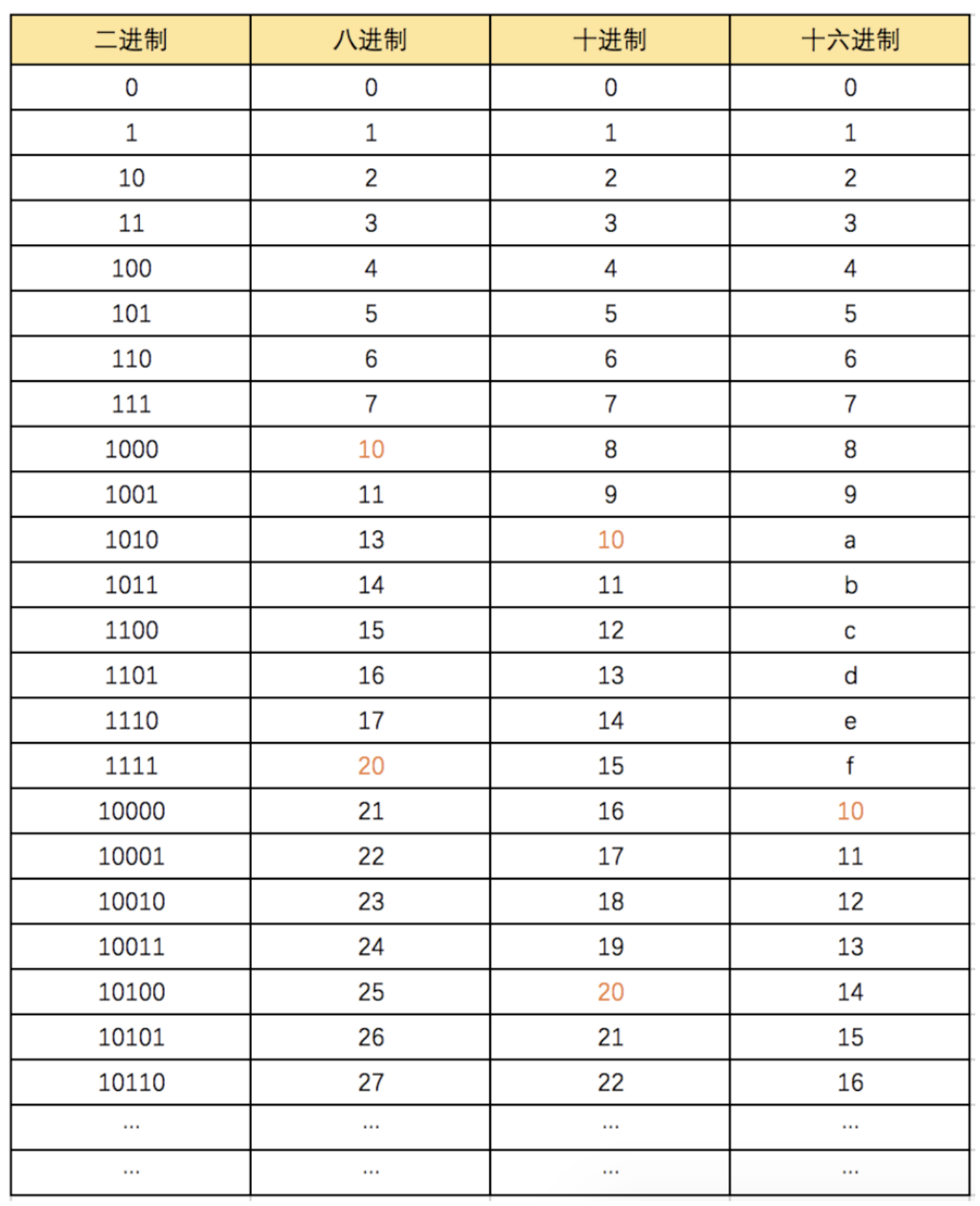
1. 进制介绍
-
二进制
0 1 10
-
八进制
-
十进制
-
十六进制
2. 进制转换
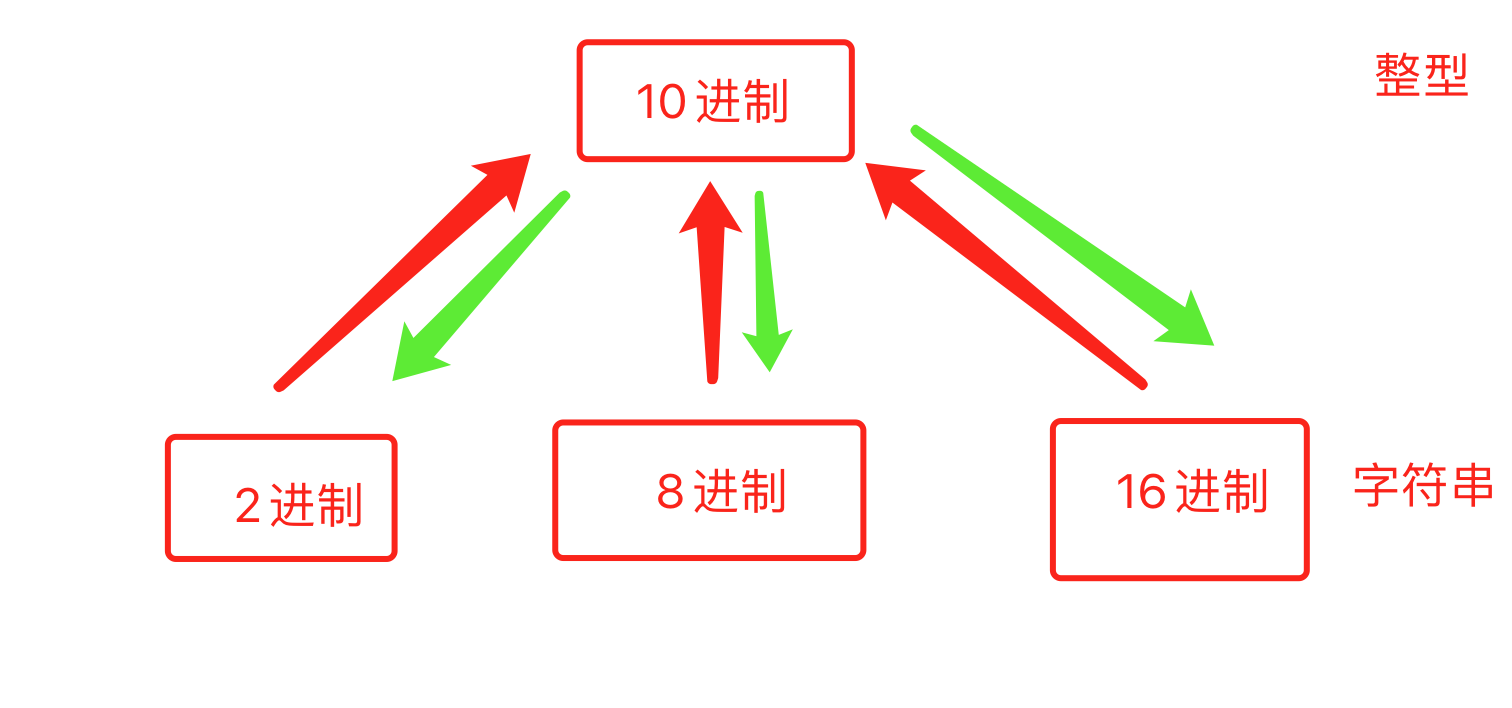
v1 = bin(25) # 十进制转换为二进制
print(v1) # "0b11001"
v2 = oct(23) # 十进制转换为八进制
print(v2) # "0o27"
v3 = hex(28) # 十进制转换为十六进制
print(v3) # "0x1c"
i1 = int("0b11001",base=2) # 25
i2 = int("0o27",base=8) # 23
i3 = int("0x1c",base=16) # 28
二、计算机中的单位
-
由于计算机中本质上所有的东西以为二进制存储和操作的,为了方便对于二进制值大小的表示,所以就搞了一些单位。
-
b(bit),位
1,1位 10,2位 111,3位 1001,4位
-
B(byte),字节
8位是一个字节。 10010110,1个字节 10010110 10010110,2个字节
-
KB(kilobyte),千字节
1024个字节就是1个千字节。 10010110 11010110 10010111 .. ,1KB 1KB = 1024B= 1024 * 8 b
-
M(Megabyte),兆
1024KB就是1M 1M= 1024KB = 1024 * 1024 B = 1024 * 1024 * 8 b
-
G(Gigabyte),千兆
1024M就是1G 1 G= 1024 M= 1024 *1024KB = 1024 * 1024 * 1024 B = 1024 * 1024 * 1024 * 8 b
-
T(Terabyte),万亿字节
1024个G就是1T
-
其他更大单位 PB/EB/ZB/YB/BB/NB/DB 不再赘述。
小练习:
-
假设1个汉字需要2个字节(2B=16位来表示,如:1000101011001100),那么1G流量可以通过网络传输多少汉字呢?(计算机传输本质上也是二进制)
1G = 1024M = 1024 * 1024KB = 1024 * 1024 * 1024 B 每个汉字需要2个字节表示 1024 * 1024 * 1024/2 = ?
-
假设1个汉字需要2个字节(2B=16位来表示,如:1000101011001100),那么500G硬盘可以存储多少个汉字?
500G = 500 * 1024M = 500 * 1024 * 1024KB = 500 * 1024 * 1024 * 1024 B 500 * 1024 * 1024 * 1024 / 2 = ?
三、编码
3.1 ASCII编码
-
ASCII(American Standard Code for Information Interchange,美国信息互换标准代码,ASCⅡ)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
-
ASCII规定使用1个字节来表示字母与二进制的对应关系。
00000000 00000001 w 00000010 B 00000011 a ... 11111111 2**8 = 256
ASCII对照表
| 二进制 | 十进制 | 十六进制 | 缩写 | 可以显示的表示法 | 名称/意义 |
|---|---|---|---|---|---|
| 0000 0000 | 0 | 00 | NUL | ␀ | 空字符(Null) |
| 0000 0001 | 1 | 01 | SOH | ␁ | 标题开始 |
| 0000 0010 | 2 | 02 | STX | ␂ | 本文开始 |
| 0000 0011 | 3 | 03 | ETX | ␃ | 本文结束 |
| 0000 0100 | 4 | 04 | EOT | ␄ | 传输结束 |
| 0000 0101 | 5 | 05 | ENQ | ␅ | 请求 |
| 0000 0110 | 6 | 06 | ACK | ␆ | 确认回应 |
| 0000 0111 | 7 | 07 | BEL | ␇ | 响铃 |
| 0000 1000 | 8 | 08 | BS | ␈ | 退格 |
| 0000 1001 | 9 | 09 | HT | ␉ | 水平定位符号 |
| 0000 1010 | 10 | 0A | LF | ␊ | 换行键 |
| 0000 1011 | 11 | 0B | VT | ␋ | 垂直定位符号 |
| 0000 1100 | 12 | 0C | FF | ␌ | 换页键 |
| 0000 1101 | 13 | 0D | CR | ␍ | 归位键 |
| 0000 1110 | 14 | 0E | SO | ␎ | 取消变换(Shift out) |
| 0000 1111 | 15 | 0F | SI | ␏ | 启用变换(Shift in) |
| 0001 0000 | 16 | 10 | DLE | ␐ | 跳出数据通讯 |
| 0001 0001 | 17 | 11 | DC1 | ␑ | 设备控制一(XON 启用软件速度控制) |
| 0001 0010 | 18 | 12 | DC2 | ␒ | 设备控制二 |
| 0001 0011 | 19 | 13 | DC3 | ␓ | 设备控制三(XOFF 停用软件速度控制) |
| 0001 0100 | 20 | 14 | DC4 | ␔ | 设备控制四 |
| 0001 0101 | 21 | 15 | NAK | ␕ | 确认失败回应 |
| 0001 0110 | 22 | 16 | SYN | ␖ | 同步用暂停 |
| 0001 0111 | 23 | 17 | ETB | ␗ | 区块传输结束 |
| 0001 1000 | 24 | 18 | CAN | ␘ | 取消 |
| 0001 1001 | 25 | 19 | EM | ␙ | 连接介质中断 |
| 0001 1010 | 26 | 1A | SUB | ␚ | 替换 |
| 0001 1011 | 27 | 1B | ESC | ␛ | 跳出 |
| 0001 1100 | 28 | 1C | FS | ␜ | 文件分割符 |
| 0001 1101 | 29 | 1D | GS | ␝ | 组群分隔符 |
| 0001 1110 | 30 | 1E | RS | ␞ | 记录分隔符 |
| 0001 1111 | 31 | 1F | US | ␟ | 单元分隔符 |
| 0111 1111 | 127 | 7F | DEL | ␡ | 删除 |
| 二进制 | 十进制 | 十六进制 | 图形 |
|---|---|---|---|
| 0010 0000 | 32 | 20 | (空格)(␠) |
| 0010 0001 | 33 | 21 | ! |
| 0010 0010 | 34 | 22 | " |
| 0010 0011 | 35 | 23 | # |
| 0010 0100 | 36 | 24 | $ |
| 0010 0101 | 37 | 25 | % |
| 0010 0110 | 38 | 26 | & |
| 0010 0111 | 39 | 27 | ' |
| 0010 1000 | 40 | 28 | ( |
| 0010 1001 | 41 | 29 | ) |
| 0010 1010 | 42 | 2A | * |
| 0010 1011 | 43 | 2B | + |
| 0010 1100 | 44 | 2C | , |
| 0010 1101 | 45 | 2D | - |
| 0010 1110 | 46 | 2E | . |
| 0010 1111 | 47 | 2F | / |
| 0011 0000 | 48 | 30 | 0 |
| 0011 0001 | 49 | 31 | 1 |
| 0011 0010 | 50 | 32 | 2 |
| 0011 0011 | 51 | 33 | 3 |
| 0011 0100 | 52 | 34 | 4 |
| 0011 0101 | 53 | 35 | 5 |
| 0011 0110 | 54 | 36 | 6 |
| 0011 0111 | 55 | 37 | 7 |
| 0011 1000 | 56 | 38 | 8 |
| 0011 1001 | 57 | 39 | 9 |
| 0011 1010 | 58 | 3A | : |
| 0011 1011 | 59 | 3B | ; |
| 0011 1100 | 60 | 3C | < |
| 0011 1101 | 61 | 3D | = |
| 0011 1110 | 62 | 3E | > |
| 0011 1111 | 63 | 3F | ? |
| 二进制 | 十进制 | 十六进制 | 图形 |
|---|---|---|---|
| 0100 0000 | 64 | 40 | @ |
| 0100 0001 | 65 | 41 | A |
| 0100 0010 | 66 | 42 | B |
| 0100 0011 | 67 | 43 | C |
| 0100 0100 | 68 | 44 | D |
| 0100 0101 | 69 | 45 | E |
| 0100 0110 | 70 | 46 | F |
| 0100 0111 | 71 | 47 | G |
| 0100 1000 | 72 | 48 | H |
| 0100 1001 | 73 | 49 | I |
| 0100 1010 | 74 | 4A | J |
| 0100 1011 | 75 | 4B | K |
| 0100 1100 | 76 | 4C | L |
| 0100 1101 | 77 | 4D | M |
| 0100 1110 | 78 | 4E | N |
| 0100 1111 | 79 | 4F | O |
| 0101 0000 | 80 | 50 | P |
| 0101 0001 | 81 | 51 | Q |
| 0101 0010 | 82 | 52 | R |
| 0101 0011 | 83 | 53 | S |
| 0101 0100 | 84 | 54 | T |
| 0101 0101 | 85 | 55 | U |
| 0101 0110 | 86 | 56 | V |
| 0101 0111 | 87 | 57 | W |
| 0101 1000 | 88 | 58 | X |
| 0101 1001 | 89 | 59 | Y |
| 0101 1010 | 90 | 5A | Z |
| 0101 1011 | 91 | 5B | [ |
| 0101 1100 | 92 | 5C | \ |
| 0101 1101 | 93 | 5D | ] |
| 0101 1110 | 94 | 5E | ^ |
| 0101 1111 | 95 | 5F | _ |
| 二进制 | 十进制 | 十六进制 | 图形 |
|---|---|---|---|
| 0110 0000 | 96 | 60 | ` |
| 0110 0001 | 97 | 61 | a |
| 0110 0010 | 98 | 62 | b |
| 0110 0011 | 99 | 63 | c |
| 0110 0100 | 100 | 64 | d |
| 0110 0101 | 101 | 65 | e |
| 0110 0110 | 102 | 66 | f |
| 0110 0111 | 103 | 67 | g |
| 0110 1000 | 104 | 68 | h |
| 0110 1001 | 105 | 69 | i |
| 0110 1010 | 106 | 6A | j |
| 0110 1011 | 107 | 6B | k |
| 0110 1100 | 108 | 6C | l |
| 0110 1101 | 109 | 6D | m |
| 0110 1110 | 110 | 6E | n |
| 0110 1111 | 111 | 6F | o |
| 0111 0000 | 112 | 70 | p |
| 0111 0001 | 113 | 71 | q |
| 0111 0010 | 114 | 72 | r |
| 0111 0011 | 115 | 73 | s |
| 0111 0100 | 116 | 74 | t |
| 0111 0101 | 117 | 75 | u |
| 0111 0110 | 118 | 76 | v |
| 0111 0111 | 119 | 77 | w |
| 0111 1000 | 120 | 78 | x |
| 0111 1001 | 121 | 79 | y |
| 0111 1010 | 122 | 7A | z |
| 0111 1011 | 123 | 7B | { |
| 0111 1100 | 124 | 7C | | |
| 0111 1101 | 125 | 7D | } |
| 0111 1110 | 126 | 7E | ~ |
3.2 gb-2312编码
-
gb-2312编码,由国家信息标准委员会制作(1980年)。 -
gbk编码,对gb2312进行扩展,包含了中日韩等文字(1995年)。 -
在与二进制做对应关系时,由如下逻辑:
-
单字节表示,用一个字节表示对应关系。2**8 = 256
-
双字节表示,用两个字节表示对应关系。2**16 = 65536中可能性,目前只用了2万多。
-
-
问题:如果我用
gbk编码来编写一个中文,转换成二进制的话用几个字节表示?
3.3 unicode
-
unicode也被称为万国码,为全球的每个文字都分配了一个码位(二进制表示)。 -
ucs2:用固定的2个字节去表示一个文字。
00000000 00000000 我 ... 2**16 = 65535
-
ucs4:用固定的4个字节去表示一个文字。
00000000 00000000 00000000 00000000 我 ... 2**32 = 4294967296
-
unicode官网:http://www.unicode.org/charts/
文字 十六进制 二进制 ȧ 0227 1000100111 ȧ 0227 00000010 00100111 ucs2 ȧ 0227 00000000 00000000 00000010 00100111 ucs4 乔 4E54 100111001010100 乔 4E54 01001110 01010100 ucs2 乔 4E54 00000000 00000000 01001110 01010100 ucs4 😆 1F606 11111011000000110 😆 1F606 00000000 00000001 11110110 00000110 ucs4
无论是ucs2和ucs4都有缺点:浪费空间?
文字 十六进制 二进制 A 0041 01000001 A 0041 00000000 01000001 A 0041 00000000 00000000 00000000 01000001
unicode的应用:在文件存储和网络传输时,不会直接使用unicode,而在内存中会unicode。
3.4 utf-8编码
-
包含所有文字和二进制的对应关系,全球应用最为广泛的一种编码(站在巨人的肩膀上功成名就)。
-
本质上:
utf-8是对unicode的压缩,用尽量少的二进制去与文字进行对应。
unicode码位范围 utf-8 0000 ~ 007F 用1个字节表示 0080 ~ 07FF 用2个字节表示 0800 ~ FFFF 用3个字节表示 10000 ~ 10FFFF 用4个字节表示
具体压缩的流程:
-
第一步:选择转换模板
码位范围(十六进制) 转换模板 0000 ~ 007F 0XXXXXXX 0080 ~ 07FF 110XXXXX 10XXXXXX 0800 ~ FFFF 1110XXXX 10XXXXXX 10XXXXXX 10000 ~ 10FFFF 11110XXX 10XXXXXX 10XXXXXX 10XXXXXX 例如: "B" 对应的unicode码位为 0042,那么他应该选择的一个模板。 "ǣ" 对应的unicode码位为 01E3,则应该选择第二个模板。 "张" 对应的unicode码位为 5F20,则应该选择第三个模板。 "亚" 对应的unicode码位为 4E9A,则应该选择第三个模板。 "飞" 对应的unicode码位为 98DE,则应该选择第三个模板。 😆 对应的unicode码位为 1F606,则应该选择第四个模板。
注意:一般中文都使用第三个模板(3个字节),这也就是平时大家说中文在utf-8中会占3个字节的原因了。 -
第二步:在模板中填入数据
- "张" -> 5F20 -> 101 111100 100000 - 根据模板去套入数据 1110XXXX 10XXXXXX 10XXXXXX 1110XXXX 10XXXXXX 10100000 1110XXXX 10111100 10100110 11100101 10101101 10100110 在UTF-8编码中 ”张“ 11100101 10101101 10100110 - 😆 -> 1F606 -> 11111 011000 000110 - 根据模板去套入数据 11110000 10011111 10011000 10000110
3.5 Python相关的编码
字符串(str) "夫轻诺必寡信" unicode处理 一般在内存
字节(byte) b"\xe5\xa4\xab\..." utf-8编码 or gbk编码 一般用于文件或网络处理
v1 = "张"
v2 = "张".encode("utf-8")
v2 = "张".encode("gbk")
将一个字符串写入到一个文件中。
text = "功高不自居,名高不自誉,位高不自傲"
data = text.encode("utf-8")
# 打开一个文件
file_object = open("log.txt",mode="wb")
# 在文件中写内容
file_object.write(data)
# 关闭文件
file_object.close()
四、作用域
在之前学习变量的作用域时,经常会提到局部变量和全局变量,之所有称之为局部、全局,就是因为他们的自作用的区域不同,这就是作用域
(1)Python无块级作用域
所谓块集作用域,需要先了解Python的代码块概念。Python遵从严格的缩进标准,可以认为处在同一缩进之间的代码即为一个代码块。如if判断,for,while循环等。
(2)Python以函数为作用域
Python语法中,函数体为单独的作用域。就行在运行代码时,遇到函数默认是不执行函数体里面的代码的,等待调用函数后才会执行。因此,函数内定义的变量只能在函数内调用。


1 #作用域链 2 3 name = "lzl" 4 def f1(): 5 name = "Eric" 6 def f2(): 7 name = "Snor" 8 print(name) 9 f2() 10 f1()
局部变量:函数里面定义的变量,只能在函数里面访问到,当超出其作用域时,将失去其作用
全局变量:函数外部定义的变量,无论在任何作用域都可以使用。当前作用域有相同变量名的局部变量时,局部变量生效。
全部变量定义的位置:函数定义之外,函数调用之前
(3)全局变量和局部变量名字相同时
1 当局部变量和全局变量名字相同时,默认对局部变量进行修改,若要对全局变量修改,需要声明global
1 ''' 2 def get_wendu(): 3 wendu = 33 4 return wendu 5 6 def print_wendu(wendu): 7 print("温度是%d"%wendu) 8 9 result = get_wendu() #如果一个函数有返回值,但是没有在调用函数之前 用个变量保存的话,那么没有任何意义 10 print_wendu(result) 11 ''' 12 13 #定义一个全局变量,wendu 14 wendu = 0 15 16 def get_wendu(): 17 #如果wendu这个变量已经在全局变量的位置定义了,此时还想在汉书中对全局变量进行进行修改的话 18 #那么 仅仅是wendu=一个值 这还不够,,此时这个wendu这个变量是一个局部变量,只不过与全局变量名字相同罢了 19 #wendu = 33 20 21 #使用global用来对一个全局变量的声明,那么这个函数中的wendu=33就不是定义一个局部变量, 22 #而是对全局变量进行修改 23 global wendu 24 wendu = 33 25 26 def print_wendu(): 27 print("温度是%d"%wendu) 28 29 get_wendu() 30 print_wendu()
1 a = 100 2 #建议 3 #g_a = 100 4 5 def test(): 6 a = 200#在函数中 如果对一个和全局变量名相同的变量进行=value的时候,默认是定义一个变量 7 #只不过这个变量的名字和全局变量的名字相同罢了 8 # 9 #如果想在执行a=value时,不是定义局部变量,而是对全局变量修改,那么可以添加global进行声明 10 print("a=%d"%a) 11 12 def test1(): 13 print("a=%d"%a)#如果这里打印了100就声明了test函数没有对全局变量修改,而是定义了一个局部变量 14 15 16 test() 17 test1()
1 In [15]: x = [lambda :x for x in range(10)] 2 3 In [16]: x.__class__ 4 Out[16]: list 5 6 In [17]: x[0].__class__ 7 Out[17]: function 8 9 In [18]: x[0]() 10 Out[18]: 9
(4)列表和字典当做全局变量时
字典和列表为全局变量时,在函数内部进行修改时不需要声明global,可以直接修改
(5)命名空间
命名空间 大约来说,命名空间就是一个容器,其中包含的是映射到不同对象的名称。你可能已经听说过了,Python中的一切——常量,列表,字典,函数,类,等等——都是对象。 这样一种“名称-对象”间的映射,使得我们可以通过为对象指定的名称来访问它。 我们可以把命名空间描述为一个Python字典结构,其中关键词代表名称,而字典值是对象本身(这也是目前Python中命名空间的实现方式),如: a_namespace = {'name_a':object_1, 'name_b':object_2, ...} 现在比较棘手的是,我们在Python中有多个独立的命名空间,而且不同命名空间中的名称可以重复使用(只要对象是独一无二的),比如: a_namespace = {'name_a':object_1, 'name_b':object_2, ...} b_namespace = {'name_a':object_3, 'name_b':object_4, ...} 举例来说,每次我们调用for循环或者定义一个函数的时候,就会创建它自己的命名空间。命名空间也有不同的层次(也就是所谓的“作用域”), 作用域:在上一节中,我们已经学习到命名空间可以相互独立地存在,而且它们被安排在某个特定层次,由此引出了“作用域”的概念。Python中的“作用域”定义了一个“层次”, 我们从其中的命名空间中查找特定的“名称-对象”映射对。 我们已经知道了多个命名空间可以独立存在,而且可以在不同的层次上包含相同的变量名。“作用域”定义了Python在哪一个层次上查找某个“变量名”对应的对象。接下来的问题就是:“Python在查找‘名称-对象’映射时,是按照什么顺序对命名空间的不同层次进行查找的?” 答案就是:使用的是LEGB规则,表示的是Local -> Enclosed -> Global -> Built-in,其中的箭头方向表示的是搜索顺序。 Local 可能是在一个函数或者类方法内部。 Enclosed 可能是嵌套函数内,比如说 一个函数包裹在另一个函数内部。 Global 代表的是执行脚本自身的最高层次。 Built-in 是Python为自身保留的特殊名称。 因此,如果某个name:object映射在局部(local)命名空间中没有找到,接下来就会在闭包作用域(enclosed)进行搜索,如果闭包作用域也没有找到,Python就会到全局(global)命名空间中进行查找,最后会在内建(built-in)命名空间搜索(注:如果一个名称在所有命名空间中都没有找到,就会产生一个NameError)。
Python基础
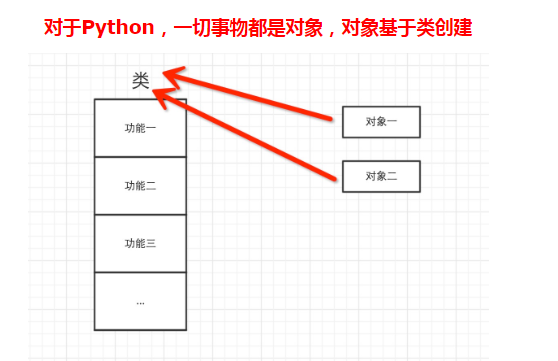
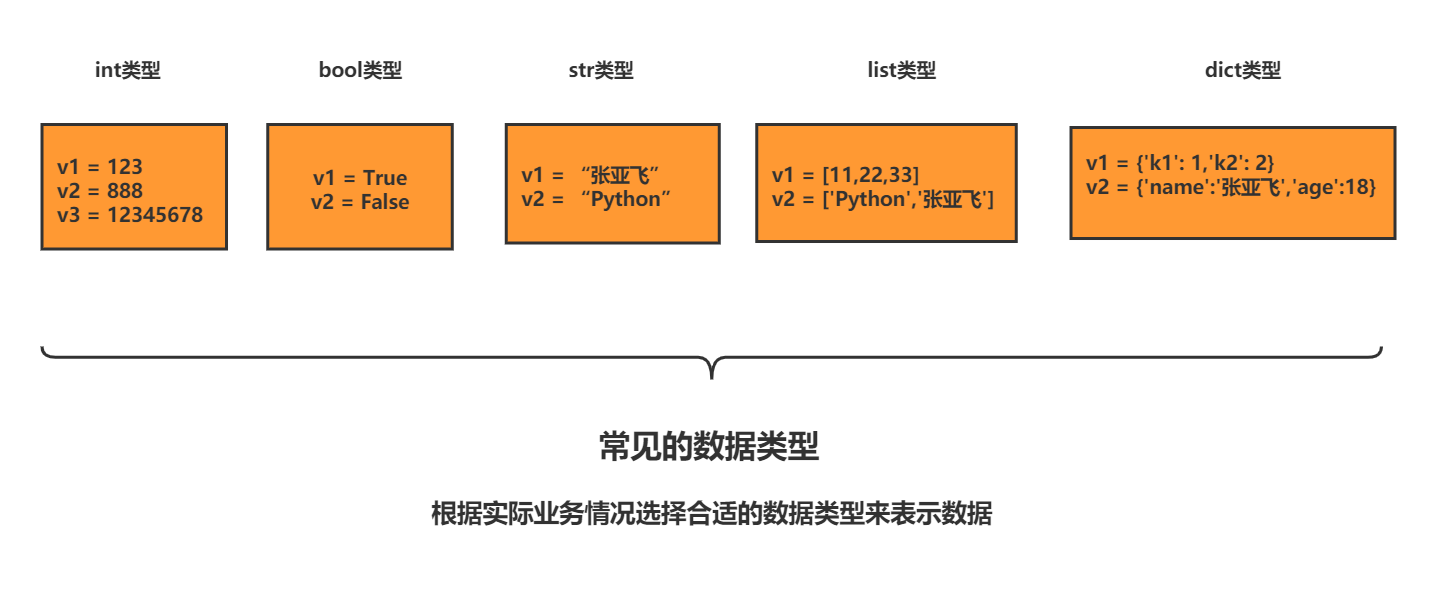
所以以下这些值都是对象: "zhangyafei"、23、['太原', '晋城', '北京'],并且是根据不同的类生成的对象。
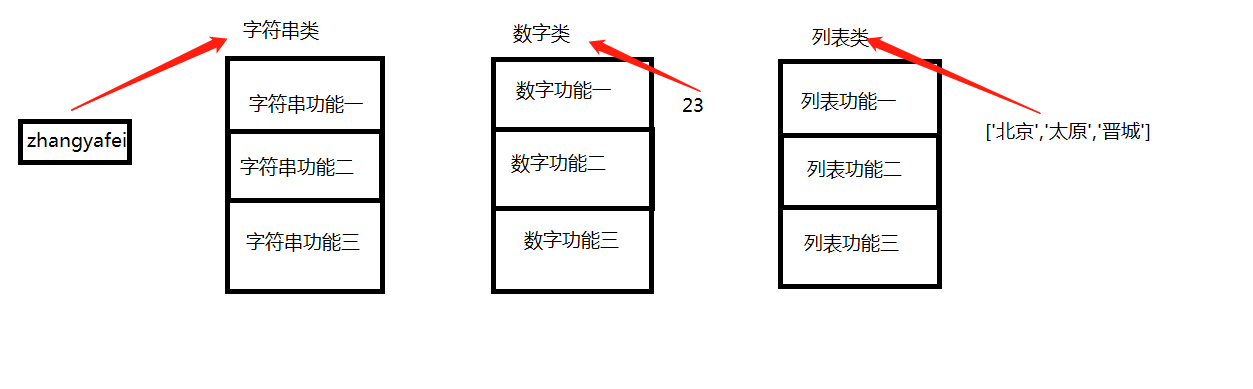
Python常见的数据类型
-
-
bool,布尔类型 -
str,字符串类型 -
list,列表类型 -
tuple,元组类型 -
dict,字典类型 -
set,集合类型 -
float
每种数据类型都有自己的特点及应用场景,以后的开发中需要根据实际的开发情况选择合适的数据类型。
一、整型
整型其实就是十进制整数的统称,比如:1、68、999都属于整型。他一般用于表示年龄、序号等。
1.1 定义
number = 10 age = 99
1.2 独有功能
class int(object): """ int([x]) -> integer int(x, base=10) -> integer Convert a number or string to an integer, or return 0 if no arguments are given. If x is a number, return x.__int__(). For floating point numbers, this truncates towards zero. If x is not a number or if base is given, then x must be a string, bytes, or bytearray instance representing an integer literal in the given base. The literal can be preceded by '+' or '-' and be surrounded by whitespace. The base defaults to 10. Valid bases are 0 and 2-36. Base 0 means to interpret the base from the string as an integer literal. >>> int('0b100', base=0) 4 """ def bit_length(self): # real signature unknown; restored from __doc__ """ Number of bits necessary to represent self in binary. >>> bin(37) '0b100101' >>> (37).bit_length() 6 """ pass def conjugate(self, *args, **kwargs): # real signature unknown """ Returns self, the complex conjugate of any int. """ pass @classmethod # known case def from_bytes(cls, *args, **kwargs): # real signature unknown """ Return the integer represented by the given array of bytes. bytes Holds the array of bytes to convert. The argument must either support the buffer protocol or be an iterable object producing bytes. Bytes and bytearray are examples of built-in objects that support the buffer protocol. byteorder The byte order used to represent the integer. If byteorder is 'big', the most significant byte is at the beginning of the byte array. If byteorder is 'little', the most significant byte is at the end of the byte array. To request the native byte order of the host system, use `sys.byteorder' as the byte order value. signed Indicates whether two's complement is used to represent the integer. """ pass def to_bytes(self, *args, **kwargs): # real signature unknown """ Return an array of bytes representing an integer. length Length of bytes object to use. An OverflowError is raised if the integer is not representable with the given number of bytes. byteorder The byte order used to represent the integer. If byteorder is 'big', the most significant byte is at the beginning of the byte array. If byteorder is 'little', the most significant byte is at the end of the byte array. To request the native byte order of the host system, use `sys.byteorder' as the byte order value. signed Determines whether two's complement is used to represent the integer. If signed is False and a negative integer is given, an OverflowError is raised. """ pass def __abs__(self, *args, **kwargs): # real signature unknown """ abs(self) """ pass def __add__(self, *args, **kwargs): # real signature unknown """ Return self+value. """ pass def __and__(self, *args, **kwargs): # real signature unknown """ Return self&value. """ pass def __bool__(self, *args, **kwargs): # real signature unknown """ self != 0 """ pass def __ceil__(self, *args, **kwargs): # real signature unknown """ Ceiling of an Integral returns itself. """ pass def __divmod__(self, *args, **kwargs): # real signature unknown """ Return divmod(self, value). """ pass def __eq__(self, *args, **kwargs): # real signature unknown """ Return self==value. """ pass def __float__(self, *args, **kwargs): # real signature unknown """ float(self) """ pass def __floordiv__(self, *args, **kwargs): # real signature unknown """ Return self//value. """ pass def __floor__(self, *args, **kwargs): # real signature unknown """ Flooring an Integral returns itself. """ pass def __format__(self, *args, **kwargs): # real signature unknown pass def __getattribute__(self, *args, **kwargs): # real signature unknown """ Return getattr(self, name). """ pass def __getnewargs__(self, *args, **kwargs): # real signature unknown pass def __ge__(self, *args, **kwargs): # real signature unknown """ Return self>=value. """ pass def __gt__(self, *args, **kwargs): # real signature unknown """ Return self>value. """ pass def __hash__(self, *args, **kwargs): # real signature unknown """ Return hash(self). """ pass def __index__(self, *args, **kwargs): # real signature unknown """ Return self converted to an integer, if self is suitable for use as an index into a list. """ pass def __init__(self, x, base=10): # known special case of int.__init__ """ int([x]) -> integer int(x, base=10) -> integer Convert a number or string to an integer, or return 0 if no arguments are given. If x is a number, return x.__int__(). For floating point numbers, this truncates towards zero. If x is not a number or if base is given, then x must be a string, bytes, or bytearray instance representing an integer literal in the given base. The literal can be preceded by '+' or '-' and be surrounded by whitespace. The base defaults to 10. Valid bases are 0 and 2-36. Base 0 means to interpret the base from the string as an integer literal. >>> int('0b100', base=0) 4 # (copied from class doc) """ pass def __int__(self, *args, **kwargs): # real signature unknown """ int(self) """ pass def __invert__(self, *args, **kwargs): # real signature unknown """ ~self """ pass def __le__(self, *args, **kwargs): # real signature unknown """ Return self<=value. """ pass def __lshift__(self, *args, **kwargs): # real signature unknown """ Return self<<value. """ pass def __lt__(self, *args, **kwargs): # real signature unknown """ Return self<value. """ pass def __mod__(self, *args, **kwargs): # real signature unknown """ Return self%value. """ pass def __mul__(self, *args, **kwargs): # real signature unknown """ Return self*value. """ pass def __neg__(self, *args, **kwargs): # real signature unknown """ -self """ pass @staticmethod # known case of __new__ def __new__(*args, **kwargs): # real signature unknown """ Create and return a new object. See help(type) for accurate signature. """ pass def __ne__(self, *args, **kwargs): # real signature unknown """ Return self!=value. """ pass def __or__(self, *args, **kwargs): # real signature unknown """ Return self|value. """ pass def __pos__(self, *args, **kwargs): # real signature unknown """ +self """ pass def __pow__(self, *args, **kwargs): # real signature unknown """ Return pow(self, value, mod). """ pass def __radd__(self, *args, **kwargs): # real signature unknown """ Return value+self. """ pass def __rand__(self, *args, **kwargs): # real signature unknown """ Return value&self. """ pass def __rdivmod__(self, *args, **kwargs): # real signature unknown """ Return divmod(value, self). """ pass def __repr__(self, *args, **kwargs): # real signature unknown """ Return repr(self). """ pass def __rfloordiv__(self, *args, **kwargs): # real signature unknown """ Return value//self. """ pass def __rlshift__(self, *args, **kwargs): # real signature unknown """ Return value<<self. """ pass def __rmod__(self, *args, **kwargs): # real signature unknown """ Return value%self. """ pass def __rmul__(self, *args, **kwargs): # real signature unknown """ Return value*self. """ pass def __ror__(self, *args, **kwargs): # real signature unknown """ Return value|self. """ pass def __round__(self, *args, **kwargs): # real signature unknown """ Rounding an Integral returns itself. Rounding with an ndigits argument also returns an integer. """ pass def __rpow__(self, *args, **kwargs): # real signature unknown """ Return pow(value, self, mod). """ pass def __rrshift__(self, *args, **kwargs): # real signature unknown """ Return value>>self. """ pass def __rshift__(self, *args, **kwargs): # real signature unknown """ Return self>>value. """ pass def __rsub__(self, *args, **kwargs): # real signature unknown """ Return value-self. """ pass def __rtruediv__(self, *args, **kwargs): # real signature unknown """ Return value/self. """ pass def __rxor__(self, *args, **kwargs): # real signature unknown """ Return value^self. """ pass def __sizeof__(self, *args, **kwargs): # real signature unknown """ Returns size in memory, in bytes. """ pass def __str__(self, *args, **kwargs): # real signature unknown """ Return str(self). """ pass def __sub__(self, *args, **kwargs): # real signature unknown """ Return self-value. """ pass def __truediv__(self, *args, **kwargs): # real signature unknown """ Return self/value. """ pass def __trunc__(self, *args, **kwargs): # real signature unknown """ Truncating an Integral returns itself. """ pass def __xor__(self, *args, **kwargs): # real signature unknown """ Return self^value. """ pass denominator = property(lambda self: object(), lambda self, v: None, lambda self: None) # default """the denominator of a rational number in lowest terms""" imag = property(lambda self: object(), lambda self, v: None, lambda self: None) # default """the imaginary part of a complex number""" numerator = property(lambda self: object(), lambda self, v: None, lambda self: None) # default """the numerator of a rational number in lowest terms""" real = property(lambda self: object(), lambda self, v: None, lambda self: None) # default """the real part of a complex number"""
- 求其二进制位的长度:bit_length()
v1 = 5 print(bin(v1)) # 0b101 # 调用v1(int)的独有功能,获取v1的二进制有多少个位组成。 result1 = v1.bit_length() print(result1) # 3 v2 = 10 print(bin(10)) # 0b1010 # 调用v2(int)的独有功能,获取v2的二进制有多少个位组成。 result2 = v2.bit_length() print(result2) # 4
1.3 公共功能
- 加减乘除求商取余幂运算
# 1. 加 print(1 + 2) # 2. 减 print(3 - 1) # 3. 乘 print(10 * 3) # 4. 除 print(10 / 3) print(10 // 3) # 商 print(10 % 3) # 余数 # 5. 幂 print(2 ** 10)
1.4 转换
# 布尔值转整型
n1 = int(True) # True转换为整数 1
n2 = int(False) # False转换为整数 0
# 字符串转整型
v1 = int("186",base=10) # 把字符串看成十进制的值,然后再转换为 十进制整数,结果:v1 = 186
v2 = int("0b1001",base=2) # 把字符串看成二进制的值,然后再转换为 十进制整数,结果:v1 = 9 (0b表示二进制)
v3 = int("0o144",base=8) # 把字符串看成八进制的值,然后转换为 十进制整数,结果:v1 = 100 (0o表示八进制)
v4 = int("0x59",base=16) # 把字符串看成十六进制的值,然后转换为 十进制整数,结果:v1 = 89 (0x表示十六进制)
# 浮点型(小数)
v1 = int(8.7) # 8
所以,如果以后别人给你一个按 二进制、八进制、十进制、十六进制 规则存储的字符串时,可以轻松的通过int转换为十进制的整数。
1.5 其他
-
长整型
-
Python3:整型(无限制)
-
Python2:整型、长整形
-
在python2中跟整数相关的数据类型有两种:int(整型)、long(长整型),他们都是整数只不过能表示的值范围不同。
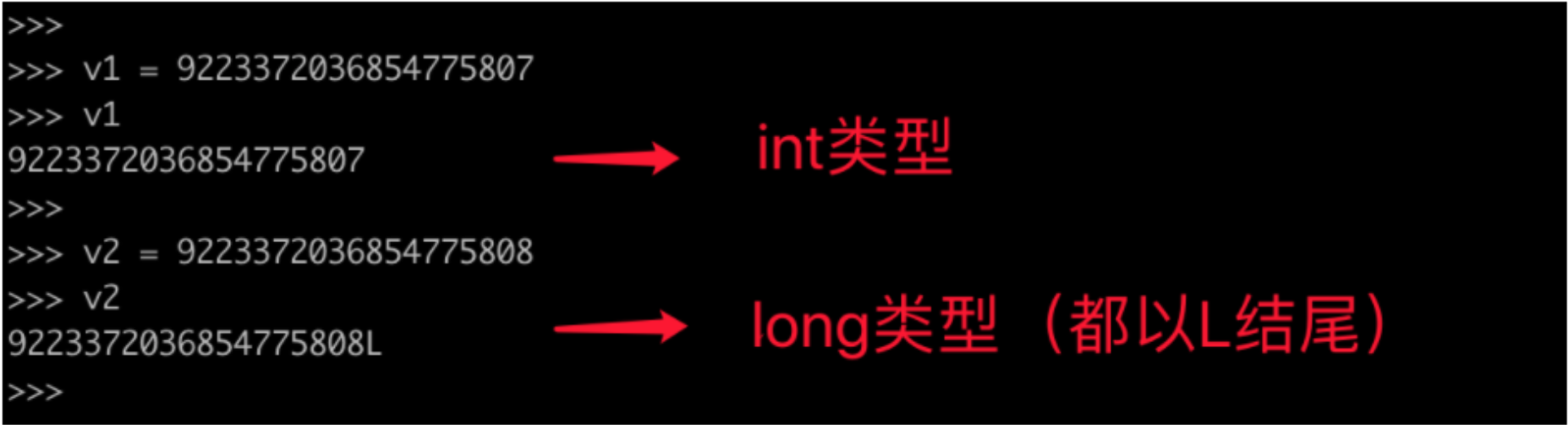
-
-
int,可表示的范围:-9223372036854775808~9223372036854775807 -
long,整数值超出int范围之后自动会转换为long类型(无限制)。
-
在python3中去除了long只剩下:int(整型),并且 int 长度不在限制。
-
除运算
-
Py3:
v1 = 9/2 print(v1) # 4.5
-
py2:
v1 = 9/2 print(v1) # 4 from __future__ import division v1 = 9/2 print(v1) # 4.5
-
二、布尔类型
布尔值,其实就是 “真”、“假” 。
2.1 定义
data = False alex_is_sb = True
2.2 独有功能
无
class bool(int): """ bool(x) -> bool Returns True when the argument x is true, False otherwise. The builtins True and False are the only two instances of the class bool. The class bool is a subclass of the class int, and cannot be subclassed. """ def __and__(self, *args, **kwargs): # real signature unknown """ Return self&value. """ pass def __init__(self, x): # real signature unknown; restored from __doc__ pass @staticmethod # known case of __new__ def __new__(*args, **kwargs): # real signature unknown """ Create and return a new object. See help(type) for accurate signature. """ pass def __or__(self, *args, **kwargs): # real signature unknown """ Return self|value. """ pass def __rand__(self, *args, **kwargs): # real signature unknown """ Return value&self. """ pass def __repr__(self, *args, **kwargs): # real signature unknown """ Return repr(self). """ pass def __ror__(self, *args, **kwargs): # real signature unknown """ Return value|self. """ pass def __rxor__(self, *args, **kwargs): # real signature unknown """ Return value^self. """ pass def __str__(self, *args, **kwargs): # real signature unknown """ Return str(self). """ pass def __xor__(self, *args, **kwargs): # real signature unknown """ Return self^value. """ pass
2.3 公共功能
无
v1 = True + True print(v1) # 2
2.4 转换
在以后的项目开发中,会经常使用其他类型转换为布尔值的情景,此处只要记住一个规律即可。
整数0、空字符串、空列表、空元组、空字典转换为布尔值时均为False 其他均为True
练习题:查看一些变量为True还是False
v1 = bool(0)
v2 = bool(-10)
v3 = bool(10)
v4 = bool("张亚飞")
v5 = bool("")
v6 = bool(" ")
v7 = bool([]) # [] 表示空列表
v8 = bool([11,22,33]) # [11,22,33] 表示非空列表
v9 = bool({}) # {} 表示空字典
v10 = bool({"name":"张亚飞","age":18}) # {"name":"张亚飞","age":18} 表示非空字典
2.5 其他
-
做条件自动转换
如果在 if 、while 条件后面写一个值当做条件时,他会默认转换为布尔类型,然后再做条件判断。
if 0:
print("太六了")
else:
print(999)
if "张亚飞":
print("你好")
while 1>9:
pass
if 值:
pass
while 值:
pass
三、字符串类型
字符串,我们平时会用他来表示文本信息。例如:姓名、地址、自我介绍等。
3.1 定义
v1 = "包治百病" v2 = '包治百病' v3 = "包'治百病" v4 = '包"治百病' v5 = """ 人生不得已,才当主角 """ # 三个引号,可以支持多行/换行表示一个字符串,其他的都只能在一行中表示一个字符串。
3.2 独有功能(18/48)
"xxxxx".功能(...) v1 = "xxxxx" v1.功能(...)
- 内建函数
| 方法 | 描述 |
|---|---|
|
把字符串的第一个字符大写 |
|
|
返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
|
|
返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
|
|
以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除非 errors 指 定 的 是 'ignore' 或 者'replace' |
|
|
以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace' |
|
|
检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. |
|
|
把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。 |
|
|
检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
|
|
格式化字符串 |
|
|
跟find()方法一样,只不过如果str不在 string中会报一个异常. |
|
|
如果 string 至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False |
|
|
如果 string 至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False |
|
|
如果 string 只包含十进制数字则返回 True 否则返回 False. |
|
|
如果 string 只包含数字则返回 True 否则返回 False. |
|
|
如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
|
|
如果 string 中只包含数字字符,则返回 True,否则返回 False |
|
|
如果 string 中只包含空格,则返回 True,否则返回 False. |
|
|
如果 string 是标题化的(见 title())则返回 True,否则返回 False |
|
|
如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
|
|
以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
|
|
返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
|
|
转换 string 中所有大写字符为小写. |
|
|
截掉 string 左边的空格 |
|
|
maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
|
|
返回字符串 str 中最大的字母。 |
|
|
返回字符串 str 中最小的字母。 |
|
|
有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把 字 符 串 string 分 成 一 个 3 元 素 的 元 组 (string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string. |
|
|
把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. |
|
|
类似于 find() 函数,返回字符串最后一次出现的位置,如果没有匹配项则返回 -1。 |
|
|
类似于 index(),不过是从右边开始. |
|
|
返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 |
|
|
类似于 partition()函数,不过是从右边开始查找 |
|
|
删除 string 字符串末尾的空格. |
|
|
以 str 为分隔符切片 string,如果 num 有指定值,则仅分隔 num+ 个子字符串 |
|
|
按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
|
|
检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查. |
|
|
在 string 上执行 lstrip()和 rstrip() |
|
|
翻转 string 中的大小写 |
|
|
返回"标题化"的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
|
|
根据 str 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 del 参数中 |
|
|
转换 string 中的小写字母为大写 |
|
|
返回长度为 width 的字符串,原字符串 string 右对齐,前面填充0 |
- 源码
class str(object): """ str(object='') -> str str(bytes_or_buffer[, encoding[, errors]]) -> str Create a new string object from the given object. If encoding or errors is specified, then the object must expose a data buffer that will be decoded using the given encoding and error handler. Otherwise, returns the result of object.__str__() (if defined) or repr(object). encoding defaults to sys.getdefaultencoding(). errors defaults to 'strict'. """ def capitalize(self, *args, **kwargs): # real signature unknown """ Return a capitalized version of the string. More specifically, make the first character have upper case and the rest lower case. """ pass def casefold(self, *args, **kwargs): # real signature unknown """ Return a version of the string suitable for caseless comparisons. """ pass def center(self, *args, **kwargs): # real signature unknown """ Return a centered string of length width. Padding is done using the specified fill character (default is a space). """ pass def count(self, sub, start=None, end=None): # real signature unknown; restored from __doc__ """ S.count(sub[, start[, end]]) -> int Return the number of non-overlapping occurrences of substring sub in string S[start:end]. Optional arguments start and end are interpreted as in slice notation. """ return 0 def encode(self, *args, **kwargs): # real signature unknown """ Encode the string using the codec registered for encoding. encoding The encoding in which to encode the string. errors The error handling scheme to use for encoding errors. The default is 'strict' meaning that encoding errors raise a UnicodeEncodeError. Other possible values are 'ignore', 'replace' and 'xmlcharrefreplace' as well as any other name registered with codecs.register_error that can handle UnicodeEncodeErrors. """ pass def endswith(self, suffix, start=None, end=None): # real signature unknown; restored from __doc__ """ S.endswith(suffix[, start[, end]]) -> bool Return True if S ends with the specified suffix, False otherwise. With optional start, test S beginning at that position. With optional end, stop comparing S at that position. suffix can also be a tuple of strings to try. """ return False def expandtabs(self, *args, **kwargs): # real signature unknown """ Return a copy where all tab characters are expanded using spaces. If tabsize is not given, a tab size of 8 characters is assumed. """ pass def find(self, sub, start=None, end=None): # real signature unknown; restored from __doc__ """ S.find(sub[, start[, end]]) -> int Return the lowest index in S where substring sub is found, such that sub is contained within S[start:end]. Optional arguments start and end are interpreted as in slice notation. Return -1 on failure. """ return 0 def format(self, *args, **kwargs): # known special case of str.format """ S.format(*args, **kwargs) -> str Return a formatted version of S, using substitutions from args and kwargs. The substitutions are identified by braces ('{' and '}'). """ pass def format_map(self, mapping): # real signature unknown; restored from __doc__ """ S.format_map(mapping) -> str Return a formatted version of S, using substitutions from mapping. The substitutions are identified by braces ('{' and '}'). """ return "" def index(self, sub, start=None, end=None): # real signature unknown; restored from __doc__ """ S.index(sub[, start[, end]]) -> int Return the lowest index in S where substring sub is found, such that sub is contained within S[start:end]. Optional arguments start and end are interpreted as in slice notation. Raises ValueError when the substring is not found. """ return 0 def isalnum(self, *args, **kwargs): # real signature unknown """ Return True if the string is an alpha-numeric string, False otherwise. A string is alpha-numeric if all characters in the string are alpha-numeric and there is at least one character in the string. """ pass def isalpha(self, *args, **kwargs): # real signature unknown """ Return True if the string is an alphabetic string, False otherwise. A string is alphabetic if all characters in the string are alphabetic and there is at least one character in the string. """ pass def isascii(self, *args, **kwargs): # real signature unknown """ Return True if all characters in the string are ASCII, False otherwise. ASCII characters have code points in the range U+0000-U+007F. Empty string is ASCII too. """ pass def isdecimal(self, *args, **kwargs): # real signature unknown """ Return True if the string is a decimal string, False otherwise. A string is a decimal string if all characters in the string are decimal and there is at least one character in the string. """ pass def isdigit(self, *args, **kwargs): # real signature unknown """ Return True if the string is a digit string, False otherwise. A string is a digit string if all characters in the string are digits and there is at least one character in the string. """ pass def isidentifier(self, *args, **kwargs): # real signature unknown """ Return True if the string is a valid Python identifier, False otherwise. Use keyword.iskeyword() to test for reserved identifiers such as "def" and "class". """ pass def islower(self, *args, **kwargs): # real signature unknown """ Return True if the string is a lowercase string, False otherwise. A string is lowercase if all cased characters in the string are lowercase and there is at least one cased character in the string. """ pass def isnumeric(self, *args, **kwargs): # real signature unknown """ Return True if the string is a numeric string, False otherwise. A string is numeric if all characters in the string are numeric and there is at least one character in the string. """ pass def isprintable(self, *args, **kwargs): # real signature unknown """ Return True if the string is printable, False otherwise. A string is printable if all of its characters are considered printable in repr() or if it is empty. """ pass def isspace(self, *args, **kwargs): # real signature unknown """ Return True if the string is a whitespace string, False otherwise. A string is whitespace if all characters in the string are whitespace and there is at least one character in the string. """ pass def istitle(self, *args, **kwargs): # real signature unknown """ Return True if the string is a title-cased string, False otherwise. In a title-cased string, upper- and title-case characters may only follow uncased characters and lowercase characters only cased ones. """ pass def isupper(self, *args, **kwargs): # real signature unknown """ Return True if the string is an uppercase string, False otherwise. A string is uppercase if all cased characters in the string are uppercase and there is at least one cased character in the string. """ pass def join(self, ab=None, pq=None, rs=None): # real signature unknown; restored from __doc__ """ Concatenate any number of strings. The string whose method is called is inserted in between each given string. The result is returned as a new string. Example: '.'.join(['ab', 'pq', 'rs']) -> 'ab.pq.rs' """ pass def ljust(self, *args, **kwargs): # real signature unknown """ Return a left-justified string of length width. Padding is done using the specified fill character (default is a space). """ pass def lower(self, *args, **kwargs): # real signature unknown """ Return a copy of the string converted to lowercase. """ pass def lstrip(self, *args, **kwargs): # real signature unknown """ Return a copy of the string with leading whitespace removed. If chars is given and not None, remove characters in chars instead. """ pass def maketrans(self, *args, **kwargs): # real signature unknown """ Return a translation table usable for str.translate(). If there is only one argument, it must be a dictionary mapping Unicode ordinals (integers) or characters to Unicode ordinals, strings or None. Character keys will be then converted to ordinals. If there are two arguments, they must be strings of equal length, and in the resulting dictionary, each character in x will be mapped to the character at the same position in y. If there is a third argument, it must be a string, whose characters will be mapped to None in the result. """ pass def partition(self, *args, **kwargs): # real signature unknown """ Partition the string into three parts using the given separator. This will search for the separator in the string. If the separator is found, returns a 3-tuple containing the part before the separator, the separator itself, and the part after it. If the separator is not found, returns a 3-tuple containing the original string and two empty strings. """ pass def replace(self, *args, **kwargs): # real signature unknown """ Return a copy with all occurrences of substring old replaced by new. count Maximum number of occurrences to replace. -1 (the default value) means replace all occurrences. If the optional argument count is given, only the first count occurrences are replaced. """ pass def rfind(self, sub, start=None, end=None): # real signature unknown; restored from __doc__ """ S.rfind(sub[, start[, end]]) -> int Return the highest index in S where substring sub is found, such that sub is contained within S[start:end]. Optional arguments start and end are interpreted as in slice notation. Return -1 on failure. """ return 0 def rindex(self, sub, start=None, end=None): # real signature unknown; restored from __doc__ """ S.rindex(sub[, start[, end]]) -> int Return the highest index in S where substring sub is found, such that sub is contained within S[start:end]. Optional arguments start and end are interpreted as in slice notation. Raises ValueError when the substring is not found. """ return 0 def rjust(self, *args, **kwargs): # real signature unknown """ Return a right-justified string of length width. Padding is done using the specified fill character (default is a space). """ pass def rpartition(self, *args, **kwargs): # real signature unknown """ Partition the string into three parts using the given separator. This will search for the separator in the string, starting at the end. If the separator is found, returns a 3-tuple containing the part before the separator, the separator itself, and the part after it. If the separator is not found, returns a 3-tuple containing two empty strings and the original string. """ pass def rsplit(self, *args, **kwargs): # real signature unknown """ Return a list of the words in the string, using sep as the delimiter string. sep The delimiter according which to split the string. None (the default value) means split according to any whitespace, and discard empty strings from the result. maxsplit Maximum number of splits to do. -1 (the default value) means no limit. Splits are done starting at the end of the string and working to the front. """ pass def rstrip(self, *args, **kwargs): # real signature unknown """ Return a copy of the string with trailing whitespace removed. If chars is given and not None, remove characters in chars instead. """ pass def split(self, *args, **kwargs): # real signature unknown """ Return a list of the words in the string, using sep as the delimiter string. sep The delimiter according which to split the string. None (the default value) means split according to any whitespace, and discard empty strings from the result. maxsplit Maximum number of splits to do. -1 (the default value) means no limit. """ pass def splitlines(self, *args, **kwargs): # real signature unknown """ Return a list of the lines in the string, breaking at line boundaries. Line breaks are not included in the resulting list unless keepends is given and true. """ pass def startswith(self, prefix, start=None, end=None): # real signature unknown; restored from __doc__ """ S.startswith(prefix[, start[, end]]) -> bool Return True if S starts with the specified prefix, False otherwise. With optional start, test S beginning at that position. With optional end, stop comparing S at that position. prefix can also be a tuple of strings to try. """ return False def strip(self, *args, **kwargs): # real signature unknown """ Return a copy of the string with leading and trailing whitespace removed. If chars is given and not None, remove characters in chars instead. """ pass def swapcase(self, *args, **kwargs): # real signature unknown """ Convert uppercase characters to lowercase and lowercase characters to uppercase. """ pass def title(self, *args, **kwargs): # real signature unknown """ Return a version of the string where each word is titlecased. More specifically, words start with uppercased characters and all remaining cased characters have lower case. """ pass def translate(self, *args, **kwargs): # real signature unknown """ Replace each character in the string using the given translation table. table Translation table, which must be a mapping of Unicode ordinals to Unicode ordinals, strings, or None. The table must implement lookup/indexing via __getitem__, for instance a dictionary or list. If this operation raises LookupError, the character is left untouched. Characters mapped to None are deleted. """ pass def upper(self, *args, **kwargs): # real signature unknown """ Return a copy of the string converted to uppercase. """ pass def zfill(self, *args, **kwargs): # real signature unknown """ Pad a numeric string with zeros on the left, to fill a field of the given width. The string is never truncated. """ pass def __add__(self, *args, **kwargs): # real signature unknown """ Return self+value. """ pass def __contains__(self, *args, **kwargs): # real signature unknown """ Return key in self. """ pass def __eq__(self, *args, **kwargs): # real signature unknown """ Return self==value. """ pass def __format__(self, *args, **kwargs): # real signature unknown """ Return a formatted version of the string as described by format_spec. """ pass def __getattribute__(self, *args, **kwargs): # real signature unknown """ Return getattr(self, name). """ pass def __getitem__(self, *args, **kwargs): # real signature unknown """ Return self[key]. """ pass def __getnewargs__(self, *args, **kwargs): # real signature unknown pass def __ge__(self, *args, **kwargs): # real signature unknown """ Return self>=value. """ pass def __gt__(self, *args, **kwargs): # real signature unknown """ Return self>value. """ pass def __hash__(self, *args, **kwargs): # real signature unknown """ Return hash(self). """ pass def __init__(self, value='', encoding=None, errors='strict'): # known special case of str.__init__ """ str(object='') -> str str(bytes_or_buffer[, encoding[, errors]]) -> str Create a new string object from the given object. If encoding or errors is specified, then the object must expose a data buffer that will be decoded using the given encoding and error handler. Otherwise, returns the result of object.__str__() (if defined) or repr(object). encoding defaults to sys.getdefaultencoding(). errors defaults to 'strict'. # (copied from class doc) """ pass def __iter__(self, *args, **kwargs): # real signature unknown """ Implement iter(self). """ pass def __len__(self, *args, **kwargs): # real signature unknown """ Return len(self). """ pass def __le__(self, *args, **kwargs): # real signature unknown """ Return self<=value. """ pass def __lt__(self, *args, **kwargs): # real signature unknown """ Return self<value. """ pass def __mod__(self, *args, **kwargs): # real signature unknown """ Return self%value. """ pass def __mul__(self, *args, **kwargs): # real signature unknown """ Return self*value. """ pass @staticmethod # known case of __new__ def __new__(*args, **kwargs): # real signature unknown """ Create and return a new object. See help(type) for accurate signature. """ pass def __ne__(self, *args, **kwargs): # real signature unknown """ Return self!=value. """ pass def __repr__(self, *args, **kwargs): # real signature unknown """ Return repr(self). """ pass def __rmod__(self, *args, **kwargs): # real signature unknown """ Return value%self. """ pass def __rmul__(self, *args, **kwargs): # real signature unknown """ Return value*self. """ pass def __sizeof__(self, *args, **kwargs): # real signature unknown """ Return the size of the string in memory, in bytes. """ pass def __str__(self, *args, **kwargs): # real signature unknown """ Return str(self). """ pass
-
判断字符串是否以 XX 开头?得到一个布尔值
v1 = "叨逼叨的一天,烦死了" # True result = v1.startswith("叨逼叨的一天") print(result) # 值为True # 案例 v1 = input("请输入住址:") if v1.startswith("北京市"): print("北京人口") else: print("非北京人口") -
判断字符串是否以 XX 结尾?得到一个布尔值
v1 = "叨逼叨的一天,烦死了"
result = v1.endswith("烦死了")
print(result) # 值为True
# 案例
address = input("请输入地址:")
if address.endswith('村'):
print("农业户口")
else:
print("非农户口")
-
判断字符串是否为十进制数?得到一个布尔值
v1 = "1238871" result = v1.isdecimal() print(result) # True # 案例,两个数相加。 v1 = input("请输入值:") # ”666“ v2 = input("请输入值:") # ”999“ if v1.isdecimal() and v2.isdecimal(): data = int(v1) + int(v2) print(data) else: print("请正确输入数字") v1 = "123" print(v1.isdecimal()) # True v2 = "①" print(v2.isdecimal()) # False v3 = "123" print(v3.isdigit()) # True v4 = "①" print(v4.isdigit()) # True -
去除字符串两边的 空格、换行符、制表符,得到一个新字符串
msg = " H e ll o啊,树哥 " data = msg.strip() print(data) # 将msg两边的空白去掉,得到"H e ll o啊,树哥" msg = " H e ll o啊,树哥 " data = msg.lstrip() print(data) # 将msg两边的空白去掉,得到"H e ll o啊,树哥 " msg = " H e ll o啊,树哥 " data = msg.rstrip() print(data) # 将msg两边的空白去掉,得到" H e ll o啊,树哥"
补充:去除 空格、换行符、制表符。
# 案例
code = input("请输入4位验证码:") # FB87
data = code.strip()
if data == "FB87":
print('验证码正确')
else:
print("验证码错误")
再补充:去除字符串两边指定的内容
msg = "哥H e ll o啊,树哥"
data = msg.strip("哥")
print(data) # 将msg两边的空白去掉,得到"H e ll o啊,树"
msg = "哥H e ll o啊,树哥"
data = msg.lstrip("哥")
print(data) # 将msg两边的空白去掉,得到"H e ll o啊,树哥"
msg = "哥H e ll o啊,树哥"
data = msg.rstrip("哥")
print(data) # 将msg两边的空白去掉,得到"哥H e ll o啊,树"
-
字符串变大写,得到一个新字符串
msg = "my name is oliver queen" data = msg.upper() print(msg) # my name is oliver queen print(data) # 输出为:MY NAME IS OLIVER QUEEN # 案例 code = input("请输入4位验证码:") # FB88 fb88 value = code.upper() # FB88 data = value.strip() # FB88 if data == "FB87": print('验证码正确') else: print("验证码错误") # 注意事项 """ code的值"fb88 " value的值"FB88 " data的值"FB88" """ -
字符串变小写,得到一个新字符串
msg = "My Name Is Oliver Queen" data = msg.lower() print(data) # 输出为:my name is oliver queen # 案例 code = input("请输入4位验证码:") value = code.strip().lower() if value == "fb87": print('验证码正确') else: print("验证码错误") -
字符串内容替换,得到一个新的字符串
data = "你是个好人,但是好人不合适我" value = data.replace("好人","贱人") print(data) # "你是个好人,但是好人不合适我" print(value) # "你是个贱人,但是贱人不合适我" # 案例 video_file_name = "大话西游之月光宝盒.mp4" new_file_name = video_file_name.replace("mp4","avi") final_file_name = new_file_name.replace("月光宝盒","仙履奇缘") print(final_file_name) # 案例 content = input("请输入评论信息") # xxx是一个SB content = content.replace("SB","**") # xxx是一个** content = content.replace("傻逼","***") # xxx是一个** print(content) # xxx是一个** char_list = ["傻逼", "SB", "草拟吗","逗比","二蛋","钢球"] content = input("请输入评论信息") for item in char_list: content = content.repalce(item,"**") print(content) -
字符串切割,得到一个列表
data = "张亚飞|root|zhangyafei@qq.com" result = data.split('|') # ["张亚飞","root","zhangyafei@qq.com"] print(data) # "张亚飞|root|zhangyafei@qq.com" print(result) # 输出 ["张亚飞","root","zhangyafei@qq.com"] 根据特定字符切开之后保存在列表中,方便以后的操作 # 案例:判断用户名密码是否正确 info = "张亚飞,root" # 备注:字符串中存储了用户名和密码 user_list = info.split(',') # 得到一个包含了2个元素的列表 [ "张亚飞" , "root" ] # user_list[0] # user_list[1] user = input("请输入用户名:") pwd = input("请输入密码:") if user == user_list[0] and pwd == user_list[1]: print("登录成功") else: print("用户名或密码错误")扩展
data = "张亚飞|root|zhangyafei@qq.com" v1 = data.split("|") # ["张亚飞","root","zhangyafei@qq.com"] print(v1) v2 = data.split("|", 1) # ['张亚飞', 'root|zhangyafei@qq.com'] print(v2)再扩展
data = "张亚飞|root|zhangyafei@qq.com" v1 = data.rsplit(',') print(v1) # ["张亚飞","root","zhangyafei@qq.com"] v2 = data.rsplit(',',1) print(v2) # ["张亚飞|root","zhangyafei@qq.com"]
- 应用场景:
file_path = "xxx/xxxx/xx.xx/xxx.mp4"
data_list = file_path.rsplit(".",1) # ["xxx/xxxx/xx.xx/xxx","mp4"]
data_list[0]
data_list[1]
-
字符串拼接,得到一个新的字符串
data_list = ["xiaoming","是","大烧饼"] v1 = "_".join(data_list) # xiaoming_是_大烧饼 print(v1)
-
格式化字符串,得到新的字符串
name = "{0}的喜欢干很多行业,例如有:{1}、{2} 等" data = name.format("老王","挖掘机","修电脑") print(data) # 老王的喜欢干很多行业,例如有:挖掘机、修电脑 等 print(name) # "{0}的喜欢干很多行业,例如有:{1}、{2} 等" name = "{}的喜欢干很多行业,例如有:{}、{} 等" data = name.format("老王","挖掘机","修电脑") print(data) # 老王的喜欢干很多行业,例如有:挖掘机、修电脑 等 name = "{name}的喜欢干很多行业,例如有:{h1}、{h2} 等" data = name.format(name="老王",h1="挖掘机",h2="修电脑") print(data) # 老王的喜欢干很多行业,例如有:挖掘机、修电脑 等 -
字符串转换为字节类型
data = "老大" # unicode,字符串类型 v1 = data.encode("utf-8") # utf-8,字节类型 v2 = data.encode("gbk") # gbk,字节类型 print(v1) # b'\xe8\x80\x81\xe5\xa4\xa7' print(v2) b'\xc0\xcf\xb4\xf3' s1 = v1.decode("utf-8") # 老大 s2 = v2.decode("gbk") # 老大 print(s1) print(s2) -
将字符串内容居中、居左、居右展示
v1 = "王老汉" # data = v1.center(21, "-") # print(data) #---------王老汉--------- # data = v1.ljust(21, "-") # print(data) # 王老汉------------------ # data = v1.rjust(21, "-") # print(data) # ------------------王老汉
-
帮助你填充0
data = "小明" v1 = data.zfill(10) print(v1) # 000000alex # 应用场景:处理二进制数据 data = "101" # "00000101" v1 = data.zfill(8) print(v1) # "00000101"
练习题
-
写代码实现判断用户输入的值否以 "al"开头,如果是则输出 "是的" 否则 输出 "不是的"
-
写代码实现判断用户输入的值否以"Nb"结尾,如果是则输出 "是的" 否则 输出 "不是的"
-
将 name 变量对应的值中的 所有的"l"替换为 "p",并输出结果
-
写代码实现对用户输入的值判断,是否为整数,如果是则转换为整型并输出,否则直接输出"请输入数字"
-
对用户输入的数据使用"+"切割,判断输入的值是否都是数字? 提示:用户输入的格式必须是以下+连接的格式,如 5+9 、86+999
-
写代码实现一个整数加法计算器(两个数相加) 需求:提示用户输入:5+9,计算出两个值的和(提示:先分割再转换为整型,再相加)
-
写代码实现一个整数加法计算器(两个数相加) 需求:提示用户输入:5 +9,计算出两个值的和(提示:先分割再去除空白、再转换为整型,再相加)
-
补充代码实现用户认证。 需求:提示用户输入手机号、验证码,全都验证通过之后才算登录成功(验证码大小写不敏感)
import random code = random.randrange(1000,9999) # 生成动态验证码 msg = "欢迎登录PythonNB系统,您的验证码为:{},手机号为:{}".format(code,"15131266666") print(msg) # 请补充代码 -
补充代码实现数据拼接
data_list = [] while True: hobby = input("请输入你的爱好(Q/q退出):") if hobby.upper() == 'Q': break # 把输入的值添加到 data_list 中,如:data_list = ["炒菜","读书","吹牛逼"] data_list.append(hobby) # 将所有的爱好通过符号 "、"拼接起来并输出
3.3 公共功能
-
相加:字符串 + 字符串
v1 = "Michael" + "大好人" print(v1)
-
相乘:字符串 * 整数
data = "老王" * 3 print(data) # 老王老王老王
-
长度
data = "老王满身大汉" value = len(data) print(value) # 6
-
获取字符串中的字符,索引
message = "来做点py交易呀" # 0 1 2345 6 7 # ... -3 -2 -1 print(message[0]) # "来" print(message[1]) # "做" print(message[2]) # "点" print(message[-1]) # 呀 print(message[-2]) # 呀 print(message[-3]) # 呀
注意:字符串中是能通过索引取值,无法修改值。【字符串在内部存储时不允许对内部元素修改,想修改只能重新创建。】
message = "在无人问津的地方训练,在万众瞩目的地方登场" index = 0 while index < len(message): value = message[index] print(value) index += 1 message = "在无人问津的地方训练,在万众瞩目的地方登场" index = len(message) - 1 while index >=0: value = message[index] print(value) index -= 1 -
获取字符串中的子序列,切片
message = "在无人问津的地方训练,在万众瞩目的地方登场" print(message[0:2]) # "在无" print(message[3:7]) # "问津的地" print( message[3:] ) # "问津的地方训练,在万众瞩目的地方登场" print( message[:5] ) # "在无人问津" print(message[4:-1]) # "津的地方训练,在万众瞩目的地方登" print(message[4:-2]) # "津的地方训练,在万众瞩目的地方" print( message[4:len(message)] ) # "津的地方训练,在万众瞩目的地方登场"
注意:字符串中的切片只能读取数据,无法修改数据。【字符串在内部存储时不允许对内部元素修改,想要修改只能重新创建】
message = "在无人问津的地方训练,在万众瞩目的地方登场" value = message[:8] + "学习Python" + message[10:19] + '惊艳所有人' print(value)
-
步长,跳着去字符串的内容
name = "生活不是电影,生活比电影苦" print( name[ 0:5:2 ] ) # 输出:生不电 【前两个值表示区间范围,最有一个值表示步长】 print( name[ :8:2 ] ) # 输出:生不电, 【区间范围的前面不写则表示起始范围为0开始】 print( name[ 2::3 ] ) # 输出:不电,活电苦 【区间范围的后面不写则表示结束范围为最后】 print( name[ ::2 ] ) # 输出:生不电,活电苦 【区间范围不写表示整个字符串】 print( name[ 8:1:-1 ] ) # 输出:活生,影电是不 【倒序】 name = "生活不是电影,生活比电影苦" print(name[8:1:-1]) # 输出:活生,影电是不 【倒序】 print(name[-1:1:-1]) # 输出:苦影电比活生,影电是不 【倒序】
试题:给你一个字符串,请将这个字符串翻转。value = name[-1::-1] print(value) # 苦影电比活生,影电是不活生
-
循环
-
while循环
message = "你打我呀" index = 0 while index < len(message): value = message[index] print(value) index += 1 -
for循环
message = "传统功夫讲四两拨千斤" for char in message: print(char) -
range,帮助我们创建一系列的数字
range(10) # [0,1,2,3,4,5,6,7,8,9] range(1,10) # [1,2,3,4,5,6,7,8,9] range(1,10,2) # [1,3,5,7,9] range(10,1,-1) # [10,9,8,7,6,5,4,3,2]
-
For + range
for i in range(10): print(i) message = "年轻人不讲武德" for i in range(5): # [0,1,2,3,4] print(message[i]) message = "传统功夫讲究接化发" for i in range( len(message) ): # [0,1,2,3,4,5,6,7,8] print(message[i])
一般应用场景:
-
while,一般在做无限制(未知)循环此处时使用。
while True: ... # 用户输入一个值,如果不是整数则一直输入,直到是整数了才结束。 num = 0 while True: data = input("请输入内容:") if data.isdecimal(): num = int(data) break else: print("输入错误,请重新输入!") -
for循环,一般应用在已知的循环数量的场景。
message = "我大意了,没有闪" for char in message: print(char) for i in range(30): print(message[i])
-
break和continue关键字
message = "传统功夫以点到为止" for char in message: if char == "点": continue print(char) message = "传统功夫以点到为止" for char in message: if char == "点": break print(char)
-
3.4 转换
num = 999 data = str(num) print(data) # "999" data_list = ["张三","喜欢",999] data = str(data_list) print(data) # "['张三', '喜欢', 999]"
一般情况下,只有整型转字符串才有意义。
3.5 其他
-
字符串不可被修改
name = "张亚飞" name[1] name[1:2] num_list = [11,22,33] num_list[0] num_list[0] = 666
四、字符串格式化
五、循环语句
-
while循环
-
for循环
5.1 while循环
while 条件:
...
...
...
print("123")
while 条件:
...
...
...
print(456)
5.1.1 循环语句基本使用
示例1:
print("开始")
while True:
print("小明是个小逗比")
print("结束")
# 输出:
开始
小明是个小逗比
小明是个小逗比
小明是个小逗比
小明是个小逗比
...
示例2:
print("开始")
while 1 > 2:
print("如果祖国遭受到侵犯,热血男儿当自强。")
print("结束")
# 输出:
开始
结束
示例3:
data = True
print("开始")
while data:
print("如果祖国遭受到侵犯,热血男儿当自强。")
print("结束")
# 输出:
开始
如果祖国遭受到侵犯,热血男儿当自强。
如果祖国遭受到侵犯,热血男儿当自强。
如果祖国遭受到侵犯,热血男儿当自强。
...
示例4:
print("开始")
flag = True
while flag:
print("滚滚黄河,滔滔长江。")
flag = False
print("结束")
# 输出:
开始
滚滚黄河,滔滔长江。
结束
示例5:
print("开始")
num = 1
while num < 3:
print("滚滚黄河,滔滔长江。")
num = 5
print("结束")
# 输出:
开始
滚滚黄河,滔滔长江。
结束
示例6:
print("开始")
num = 1
while num < 5:
print("给我生命,给我力量。")
num = num + 1
print("结束")
# 输出:
开始
给我生命,给我力量。
给我生命,给我力量。
给我生命,给我力量。
给我生命,给我力量。
结束
练习题:重复3次输出我爱我的祖国。
num = 1
while num < 4:
print("我爱我的祖国")
num = num + 1
我爱我的祖国
我爱我的祖国
我爱我的祖国
5.1.2 综合小案例
请实现一个用户登录系统,如果密码错误则反复提示让用户重新输入,直到输入正确才停止。
# 请实现一个用户登录系统,如果密码错误则反复提示让用户重新输入,直到输入正确才停止。
print("开始运行超级无敌系统")
flag = True
while flag:
user = input("请输入用户名:")
pwd = input("请输入密码:")
if user == "zhangyafei" and pwd == "666666":
print("登录成功")
flag = False
else:
print("用户名或密码错误")
print("系统结束")
练习题
-
补充代码实现 猜数字,设定一个理想数字比如:66,一直提示让用户输入数字,如果比66大,则显示猜测的结果大了;如果比66小,则显示猜测的结果小了;只有输入等于66,显示猜测结果正确,然后退出循环。
number = 66 flag = True while flag: ... -
使用循环输出1~100所有整数。
-
使用循环输出 1 2 3 4 5 6 8 9 10,即:10以内除7以外的整数。
-
输出 1~100 内的所有奇数。
-
输出 1~100 内的所有偶数。
-
求 1~100 的所有整数的和。
-
输出10 ~ 1 所有整数。
5.1.3 break
break,用于在while循环中帮你终止循环。
print("开始")
while True:
print("1")
break
print("2")
print("结束")
# 输出
开始
1
结束
通过示例来更深入理解break的应用。
示例1:
print("开始")
while True:
print("红旗飘飘,军号响。")
break
print("剑已出鞘,雷鸣电闪。")
print("从来都是狭路相逢勇者胜。")
print("结束")
示例2:
print("开始")
i = 1
while True:
print(i)
i = i + 1
if i == 101:
break
print("结束")
# 输出
开始
1
2
...
100
结束
示例3:
print("开始运行系统")
while True:
user = input("请输入用户名:")
pwd = input("请输入密码:")
if user == 'zhangyafei' and pwd = "666666":
print("登录成功")
break
else:
print("用户名或密码错误,请重新登录")
print("系统结束")
# 输出
开始运行系统
>>> 用户名
>>> 密码
正确,登录成功
系统结束
不正确,一直循环输出
所以,以后写代码时候,想要结束循环可以通过两种方式实现了,即:条件判断 和 break关键字,两种在使用时无好坏之分,只要能实现功能就行。
5.1.4 continue
continue,在循环中用于 结束本次循环,开始下一次循环。
print("开始")
while True:
print(1)
continue
print(2)
print(3)
print("结束")
示例1:
print("开始")
while True:
print("红旗飘飘,军号响。")
continue
print("剑已出鞘,雷鸣电闪。")
print("从来都是狭路相逢勇者胜。")
print("结束")
# 输出
开始
红旗飘飘,军号响。
红旗飘飘,军号响。
红旗飘飘,军号响。
红旗飘飘,军号响。
...
示例2:
print("开始")
i = 1
while i < 101:
if i == 7:
i = i + 1
continue
print(i)
i = i + 1
print("结束")
# 输出
开始
1
2
3
4
5
6
8
9
10
...
100
结束
示例3:
print("开始")
i = 1
while True:
if i == 7:
i = i + 1
continue
print(i)
i = i + 1
if i == 101:
break
print("结束")
# 输出
开始
1
2
3
4
5
6
8
9
10
...
100
结束
写在最后,对于break和continue都是放在循环语句中用于控制循环过程的,一旦遇到break就停止所有循环,一旦遇到continue就停止本次循环,开始下次循环。
当然,通过如果没有了break和continue,我们用while条件的判断以及其他协助也能完成很多功能,有了break和continue可以在一定程度上简化我们的代码逻辑。
5.1.5 while else
-
-
当while循环是因为表达式的布尔值为假终止循环时,执行else,可以理解为while正常结束循环,要执行else。
-
while 条件:
代码
else:
代码
while False:
pass
else:
print(123)
num = 1
while num < 5:
print(num)
num = num + 1
else:
print(666)
# 输出
1
2
3
4
666
while True:
print(123)
break
else:
print(666)
# 输出
123
示例
def fib(max): n, a, b = 1, 0, 1 while n < max: # print(b) a, b = b, a + b n = n + 1 return b print(fib(10))
ticket = 1 #q表示有车票 0表示没有车票 knifeLenght = 48 #cm #先判断是都有车票 if ticket==1: print("通过了车票的检测,进入到了车站,接下来要安检了") #盘DAU拿到的长度是否合法 if knifeLenght<=10: print("通过了安检,进入了候车厅") print("马上就要见到她了,好开心……") else: print("安检没有通过,等待公安处理") else: print("兄弟,你还没有买票呢,先去买票,才能进站……") 上火车
""" 打印矩形 """ i = 1 while i <= 5: j = 1 while j <= 5: print("*", end="") # j=j+1 #c语言中向j+1的方式j++ ++j j+=1 j=j+1 j += 1 print("") i = i + 1
""" 打印三角形 """ i = 1 while i <= 5: ''' j = 1 num = input("请输入这个行里的*的个数") while j<num: print("*") ''' j = 1 while j <= i: print("*", end="") j += 1 print("") i += 1
""" 打印100之内前20个偶数 """ i = 1 num = 0 while i <= 100: # if i是个偶数 if i % 2 == 0: print(i) num += 1 if num == 20: break i += 1
# -*- coding: utf-8 -*- """ DateTime : 2020/11/29 18:18 Author : ZhangYafei Description: """ import random num = random.randint(1, 100) times = 4 while True: num2 = int(input('请输入数字【1-100】(共五次机会):')) if times <= 0: print(f'很遗憾,您浪费了太多机会了,正确的数字是{num}, 请下次再来吧。') break if num2 == num: print('恭喜你猜对了') break elif num2 < num: print(f'{num2} 小了,还剩{times}次机会') else: print(f'{num2} 大了,还剩{times}次机会') times -= 1
i = 1 while i <= 9: j = 1 while j <= i: print(f'{j}*{i}={i * j}\t', end=' ') # print(f'{j}*{i}={i * j:<2}', end=' ') # print("%d*%d=%d\t" % (j, i, i * j), end=" ") j += 1 print() i += 1
5.2 for循环
for循环使用的语法:
for 变量 in 序列:
循环要执行的动作
序列即可迭代对象,内部实现了__iter__方法,for循环会遍历其中的每个值。常见的可迭代对象包含:字符串、列表、字典、元组、集合以及range等。
- range的用法
range(stop): 0 - stop-1 range(start,stop): start - stop-1 range(start,stop,step): start - stop-1 step(步长)
- 例子
for item in range(5):
print(item)
print('\n')
for num in range(10,15):
print(num)
print('\n')
for a in range(20,30,2):
print(a)
- 例子
##求1、3、5...99的和 sum = 0 for i in range(1,101,2): sum += i print(sum)
#用户输入一个整型数,求该数的阶乘 num = int(input('Num:')) res = 1 for i in range(1,num+1): res *= i print('%d 阶乘的结果是: %d' %(num,res))
- 神奇的for_else
英文原文
A break statement executed in the first suite terminates the loop without executing the else clause’s suite. A continue statement executed in the first suite skips the rest of the suite and continues with the next item, or with the else clause if there is no next item.
中文译文
用 break 关键字终止当前循环就不会执行当前的 else 语句,而使用 continue 关键字快速进入下一论循环,或者没有使用其他关键字,循环的正常结束后,就会触发 else 语句。
#触发else
list = [1,2,3,4,5]
for x in list:
print(x)
else:
print("else")
list = [1,2,3,4,5]
i = 0
for x in list:
continue
print(x)
else:
print("else")
#不触发else:
list = [1,2,3,4,5]
for x in list:
print(x)
break
else:
print("else")
- 总结
for else语句可以总结成以下。 如果我依次做完了所有的事情(for正常结束),我就去做其他事(执行else),若做到一半就停下来不做了(中途遇到break),我就不去做其他事了(不执行else)。 只有循环完所有次数,才会执行 else 。 break 可以阻止 else 语句块的执行。
六、列表(list):
6.1 定义
列表(list),是一个有序且可变的容器,在里面可以存放多个不同类型的元素。
user_list = ["范冰冰","赵薇","杨幂"]
number_list = [98,88,666,12,-1]
data_list = [1,True,"Michael","宝强","贾乃亮"]
user_list = []
user_list.append("铁锤")
user_list.append(123)
user_list.append(True)
print(user_list) # ["铁锤",123,True]
- 特点
- 数据元素的类型可以是不相同
- 以逗号为分隔符
不可变类型:字符串、布尔、整型(已最小,内部数据无法进行修改)
可变类型:列表(内部数据元素可以修改)
6.2 独有功能
class list(object): """ Built-in mutable sequence. If no argument is given, the constructor creates a new empty list. The argument must be an iterable if specified. """ def append(self, *args, **kwargs): # real signature unknown """ Append object to the end of the list. """ pass def clear(self, *args, **kwargs): # real signature unknown """ Remove all items from list. """ pass def copy(self, *args, **kwargs): # real signature unknown """ Return a shallow copy of the list. """ pass def count(self, *args, **kwargs): # real signature unknown """ Return number of occurrences of value. """ pass def extend(self, *args, **kwargs): # real signature unknown """ Extend list by appending elements from the iterable. """ pass def index(self, *args, **kwargs): # real signature unknown """ Return first index of value. Raises ValueError if the value is not present. """ pass def insert(self, *args, **kwargs): # real signature unknown """ Insert object before index. """ pass def pop(self, *args, **kwargs): # real signature unknown """ Remove and return item at index (default last). Raises IndexError if list is empty or index is out of range. """ pass def remove(self, *args, **kwargs): # real signature unknown """ Remove first occurrence of value. Raises ValueError if the value is not present. """ pass def reverse(self, *args, **kwargs): # real signature unknown """ Reverse *IN PLACE*. """ pass def sort(self, *args, **kwargs): # real signature unknown """ Stable sort *IN PLACE*. """ pass def __add__(self, *args, **kwargs): # real signature unknown """ Return self+value. """ pass def __contains__(self, *args, **kwargs): # real signature unknown """ Return key in self. """ pass def __delitem__(self, *args, **kwargs): # real signature unknown """ Delete self[key]. """ pass def __eq__(self, *args, **kwargs): # real signature unknown """ Return self==value. """ pass def __getattribute__(self, *args, **kwargs): # real signature unknown """ Return getattr(self, name). """ pass def __getitem__(self, y): # real signature unknown; restored from __doc__ """ x.__getitem__(y) <==> x[y] """ pass def __ge__(self, *args, **kwargs): # real signature unknown """ Return self>=value. """ pass def __gt__(self, *args, **kwargs): # real signature unknown """ Return self>value. """ pass def __iadd__(self, *args, **kwargs): # real signature unknown """ Implement self+=value. """ pass def __imul__(self, *args, **kwargs): # real signature unknown """ Implement self*=value. """ pass def __init__(self, seq=()): # known special case of list.__init__ """ Built-in mutable sequence. If no argument is given, the constructor creates a new empty list. The argument must be an iterable if specified. # (copied from class doc) """ pass def __iter__(self, *args, **kwargs): # real signature unknown """ Implement iter(self). """ pass def __len__(self, *args, **kwargs): # real signature unknown """ Return len(self). """ pass def __le__(self, *args, **kwargs): # real signature unknown """ Return self<=value. """ pass def __lt__(self, *args, **kwargs): # real signature unknown """ Return self<value. """ pass def __mul__(self, *args, **kwargs): # real signature unknown """ Return self*value. """ pass @staticmethod # known case of __new__ def __new__(*args, **kwargs): # real signature unknown """ Create and return a new object. See help(type) for accurate signature. """ pass def __ne__(self, *args, **kwargs): # real signature unknown """ Return self!=value. """ pass def __repr__(self, *args, **kwargs): # real signature unknown """ Return repr(self). """ pass def __reversed__(self, *args, **kwargs): # real signature unknown """ Return a reverse iterator over the list. """ pass def __rmul__(self, *args, **kwargs): # real signature unknown """ Return value*self. """ pass def __setitem__(self, *args, **kwargs): # real signature unknown """ Set self[key] to value. """ pass def __sizeof__(self, *args, **kwargs): # real signature unknown """ Return the size of the list in memory, in bytes. """ pass __hash__ = None
Python中为所有的列表类型的数据提供了一批独有的功能。
在开始学习列表的独有功能之前,先来做一个字符串和列表的对比:
-
字符串,不可变,即:创建好之后内部就无法修改。【独有功能都是新创建一份数据】
name = "Michael" data = name.upper() print(name) print(data)
-
列表,可变,即:创建好之后内部元素可以修改。【独有功能基本上都是直接操作列表内部,不会创建新的一份数据】
user_list = ["车子","房子"] user_list.append("票子") print(user_list) # ["车子","房子","票子"]
列表中的常见独有功能如下:
创建新列表 列表名 = [] 列表名 = list() 添加新的元素 列表名.append()--------->添加到最后一个 列表名.insert(插入的内容)--------->根据内容添加 列表名.extend(添加的表名)--------->将新表添加到表的末尾 删除元素 列表名.pop()------------->删除最后一个 列表名.remove(删除的内容)---------->根据内容删除 del 列表名[下标]----->根据下标删除 修改 列表名[下标]=new值---->根据下标进行修改 查询 列表名[索引] 列表名[start:end] 切片 if 查询的内容 in 列表名: 列表名.index(value) 根据值获取索引 清空表 列表名.clear() 长度 len(列表名) 排序 list.sort(cmp=None, key=None, reverse=False) list.reverse() 反转 循环:可迭代对象 包含:in
-
追加,在原列表中尾部追加值。
append示例data_list = [] v1 = input("请输入姓名") data_list.append(v1) v2 = input("请输入姓名") data_list.append(v2) print(data_list) # 案例1 user_list = [] while True: user = input("请输入用户名(Q退出):") if user == "Q": break user_list.append(user) print(user_list) # 案例2 welcome = "欢迎使用NB游戏".center(30, '*') print(welcome) user_count = 0 while True: count = input("请输入游戏人数:") if count.isdecimal(): user_count = int(count) break else: print("输入格式错误,人数必须是数字。") message = "{}人参加游戏NB游戏。".format(user_count) print(message) user_name_list = [] for i in range(1, user_count + 1): tips = "请输入玩家姓名({}/{}):".format(i, user_count) name = input(tips) user_name_list.append(name) print(user_name_list)
-
批量追加,将一个列表中的元素逐一添加另外一个列表。
批量追加示例tools = ["搬砖","菜刀","榔头"] tools.extend( [11,22,33] ) # weapon中的值逐一追加到tools中 print(tools) # ["搬砖","菜刀","榔头",11,22,33] tools = ["搬砖","菜刀","榔头"] weapon = ["AK47","M6"] #tools.extend(weapon) # weapon中的值逐一追加到tools中 #print(tools) # ["搬砖","菜刀","榔头","AK47","M6"] weapon.extend(tools) print(tools) # ["搬砖","菜刀","榔头"] print(weapon) # ["AK47","M6","搬砖","菜刀","榔头"] # 等价于(扩展) weapon = ["AK47","M6"] for item in weapon: print(item) # 输出: # AK47 # M6 tools = ["搬砖","菜刀","榔头"] weapon = ["AK47","M6"] for item in weapon: tools.append(item) print(tools) # ["搬砖","菜刀","榔头","AK47","M6"]
-
插入,在原列表的指定索引位置插入值
插入示例user_list = ["刘翔","苏炳添","孙杨"] user_list.insert(0,"姚明") user_list.insert(2,"邓亚萍") print(user_list) # 案例 name_list = [] while True: name = input("请输入购买火车票用户姓名(Q/q退出):") if name.upper() == "Q": break if name.startswith("***"): name_list.insert(0, name) else: name_list.append(name) print(name_list)
-
在原列表中根据值删除(从左到右找到第一个删除)【慎用,里面没有会报错】
删除示例user_list = ["王宝强","陈羽凡","Michael","贾乃亮","Michael"] user_list.remove("Michael") print(user_list) user_list = ["王宝强","陈羽凡","Michael","贾乃亮","Michael"] if "Michael" in user_list: user_list.remove("Michael") print(user_list) user_list = ["王宝强","陈羽凡","Michael","贾乃亮","Michael"] while True: if "Michael" in user_list: user_list.remove("Michael") else: break print(user_list)
自动抽奖程序# 案例:自动抽奖程序 import random data_list = ["iphone12", "经典女朋友", "成熟男朋友", "1个亿", "一瓶矿泉水"] while data_list: name = input("自动抽奖程序,请输入自己的姓名:") # 随机从data_list抽取一个值出来 value = random.choice(data_list) print( "恭喜{},抽中{}.".format(name, value) ) data_list.remove(value)
-
在原列表中根据索引踢出某个元素(根据索引位置删除)
根据索引删除示例user_list = ["王宝强","陈羽凡","Michael","贾乃亮","Michael"] # 0 1 2 3 4 user_list.pop(1) print(user_list) # ["王宝强","Michael","贾乃亮","Michael"] user_list.pop() print(user_list) # ["王宝强","Michael","贾乃亮"] item = user_list.pop(1) print(item) # "Michael" print(user_list) # ["王宝强","贾乃亮"]
排队买火车票# 案例:排队买火车票 # ["Michael","李连杰","成龙","张亚飞","老王","李云龙"] user_queue = [] while True: name = input("北京~上海火车票,购买请输入姓名排队(Q退出):") if name == "Q": break user_queue.append(name) ticket_count = 3 for i in range(ticket_count): username = user_queue.pop(0) message = "恭喜{},购买火车票成功。".format(username) print(message) # user_queue = ["张亚飞","老梁","老赵"] faild_user = "、".join(user_queue) # "张亚飞、老梁、老赵" faild_message = "非常抱歉,票已售完,以下几位用户请选择其他出行方式,名单:{}。".format(faild_user) print(faild_message)
-
清空原列表
清空原列表clearuser_list = ["王宝强","陈羽凡","Michael","贾乃亮","Michael"] user_list.clear() print(user_list) # []
-
根据值获取索引(从左到右找到第一个删除)【慎用,找不到报错】
根据值获取索引user_list = ["王宝强","陈羽凡","Michael","贾乃亮","Michael"] # 0 1 2 3 4 if "Michael" in user_list: index = user_list.index("Michael") print(index) # 2 else: print("不存在")
-
列表元素排序
列表排序# 数字排序 num_list = [11, 22, 4, 5, 11, 99, 88] print(num_list) num_list.sort() # 让num_list从小到大排序 num_list.sort(reverse=True) # # 让num_list从大到小排序 print(num_list) # 字符串排序 user_list = ["王宝强", "Ab陈羽凡", "Michael", "贾乃亮", "贾乃", "1"] # [29579, 23453, 24378] # [65, 98, 38472, 32701, 20961] # [65, 108, 101, 120] # [49] print(user_list) """ sort的排序原理 [ "x x x" ," x x x x x " ] """ user_list.sort() print(user_list)
注意:排序时内部元素无法进行比较时,程序会报错(尽量数据类型统一)。
-
反转原列表
反转列表user_list = ["王宝强","陈羽凡","Michael","贾乃亮","Michael"] user_list.reverse() print(user_list)
6.3 公共功能
-
相加,两个列表相加获取生成一个新的列表。
列表相加data = ["赵四","刘能"] + ["宋晓峰","范德彪"] print(data) # ["赵四","刘能","宋晓峰","范德彪"] v1 = ["赵四","刘能"] v2 = ["宋晓峰","范德彪"] v3 = v1 + v2 print(v3) # ["赵四","刘能","宋晓峰","范德彪"]
-
相乘,列表*整型 将列表中的元素再创建N份并生成一个新的列表。
列表相乘data = ["赵四","刘能"] * 2 print(data) # ["赵四","刘能","赵四","刘能"] v1 = ["赵四","刘能"] v2 = v1 * 2 print(v1) # ["赵四","刘能"] print(v2) # ["赵四","刘能","赵四","刘能"]
-
运算符in包含 由于列表内部是由多个元素组成,可以通过in来判断元素是否在列表中。
列表In示例1user_list = ["狗子","二蛋","沙雕","Michael"] result = "Michael" in user_list # result = "Michael" not in user_list print(result) # True if "Michael" in user_list: print("在,把他删除") user_list.remove("Michael") else: print("不在") user_list = ["狗子","二蛋","沙雕","Michael"] if "Michael" in user_list: print("在,把他删除") user_list.remove("Michael") else: print("不在") text = "打倒小日本" data = "日" in text
列表In示例2# 案例 user_list = ["狗子","二蛋","沙雕","Michael"] if "Michael" in user_list: print("在,把他删除") user_list.remove("Michael") else: print("不在")
注意:列表检查元素是否存在时,是采用逐一比较的方式,效率会比较低。
-
获取长度
user_list = ["范德彪","刘华强",'尼古拉斯赵四'] print( len(user_list) )
-
索引,一个元素的操作
索引操作示例# 读 user_list = ["范德彪","刘华强",'尼古拉斯赵四'] print( user_list[0] ) print( user_list[2] ) print( user_list[3] ) # 报错 # 改 user_list = ["范德彪","刘华强",'尼古拉斯赵四'] user_list[0] = "张亚飞" print(user_list) # ["张亚飞","刘华强",'尼古拉斯赵四'] # 删 user_list = ["范德彪","刘华强",'尼古拉斯赵四'] del user_list[1] user_list.remove("刘华强") ele = user_list.pop(1)
注意:超出索引范围会报错。 提示:由于字符串是不可变类型,所以他只有索引读的功能,而列表可以进行 读、改、删
-
切片,多个元素的操作(很少用)
切片操作# 读 user_list = ["范德彪","刘华强",'尼古拉斯赵四'] print( user_list[0:2] ) # ["范德彪","刘华强"] print( user_list[1:] ) print( user_list[:-1] ) # 改 user_list = ["范德彪", "刘华强", '尼古拉斯赵四'] user_list[0:2] = [11, 22, 33, 44] print(user_list) # 输出 [11, 22, 33, 44, '尼古拉斯赵四'] user_list = ["范德彪", "刘华强", '尼古拉斯赵四'] user_list[2:] = [11, 22, 33, 44] print(user_list) # 输出 ['范德彪', '刘华强', 11, 22, 33, 44] user_list = ["范德彪", "刘华强", '尼古拉斯赵四'] user_list[3:] = [11, 22, 33, 44] print(user_list) # 输出 ['范德彪', '刘华强', '尼古拉斯赵四', 11, 22, 33, 44] user_list = ["范德彪", "刘华强", '尼古拉斯赵四'] user_list[10000:] = [11, 22, 33, 44] print(user_list) # 输出 ['范德彪', '刘华强', '尼古拉斯赵四', 11, 22, 33, 44] user_list = ["范德彪", "刘华强", '尼古拉斯赵四'] user_list[-10000:1] = [11, 22, 33, 44] print(user_list) # 输出 [11, 22, 33, 44, '刘华强', '尼古拉斯赵四'] # 删 user_list = ["范德彪", "刘华强", '尼古拉斯赵四'] del user_list[1:] print(user_list) # 输出 ['范德彪']
-
步长
步长示例user_list = ["范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能"] # 0 1 2 3 4 print( user_list[1:4:2] ) print( user_list[0::2] ) print( user_list[1::2] ) print( user_list[4:1:-1] ) # 案例:实现列表的翻转 user_list = ["范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能"] new_data = user_list[::-1] print(new_data) data_list = ["范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能"] data_list.reverse() print(data_list) # 给你一个字符串请实现字符串的翻转? name = "张亚飞" name[::-1]
-
for循环
for循环示例user_list = ["范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能"] for item in user_list: print(item) user_list = ["范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能"] for index in range( len(user_list) ): item = user_index[index] print(item)
切记,循环的过程中对数据进行删除会踩坑【面试题】。
for循环示例2# 错误方式, 有坑,结果不是你想要的。 user_list = ["刘的话", "范德彪", "刘华强", '刘尼古拉斯赵四', "宋小宝", "刘能"] for item in user_list: if item.startswith("刘"): user_list.remove(item) print(user_list) # 正确方式,倒着删除。 user_list = ["刘的话", "范德彪", "刘华强", '刘尼古拉斯赵四', "宋小宝", "刘能"] for index in range(len(user_list) - 1, -1, -1): item = user_list[index] if item.startswith("刘"): user_list.remove(item) print(user_list)
6.4 转换
-
int、bool无法转换成列表
-
str
name = "张亚飞" data = list(name) # ["张","亚","飞"] print(data)
-
元组和集合转换列表
v1 = (11,22,33,44) # 元组 vv1 = list(v1) # 列表 [11,22,33,44] v2 = {"Michael","james","john"} # 集合 vv2 = list(v2) # 列表 ["Michael","james","john"]
6.5. 其他
6.5.1 嵌套
列表属于容器,内部可以存放各种数据,所以他也支持列表的嵌套,如:
data = [ "谢广坤",["海燕","赵本山"],True,[11,22,[999,123],33,44],"宋小宝" ]
对于嵌套的值,可以根据之前学习的索引知识点来进行学习,例如:
data = [ "谢广坤",["海燕","赵本山"],True,[11,22,33,44],"宋小宝" ] print( data[0] ) # "谢广坤" print( data[1] ) # ["海燕","赵本山"] print( data[0][2] ) # "坤" print( data[1][-1] ) # "赵本山" data.append(666) print(data) # [ "谢广坤",["海燕","赵本山"],True,[11,22,33,44],"宋小宝",666] data[1].append("谢大脚") print(data) # [ "谢广坤",["海燕","赵本山","谢大脚"],True,[11,22,33,44],"宋小宝",666 ] del data[-2] print(data) # [ "谢广坤",["海燕","赵本山","谢大脚"],True,[11,22,33,44],666 ] data[-2][1] = "Michael" print(data) # [ "谢广坤",["海燕","赵本山","谢大脚"],True,[11,"Michael",33,44],666 ] data[1][0:2] = [999,666] print(data) # [ "谢广坤",[999,666,"谢大脚"],True,[11,"Michael",33,44],666 ] # 创建用户列表 # 用户列表应该长: [ ["Michael","123"],["Rose","666"] ] # user_list = [["Michael","123"],["Rose","666"],] # user_list.append(["Michael","123"]) # user_list.append(["Rose","666"]) user_list = [] while True: user = input("请输入用户名:") pwd = input("请输入密码:") data = [] data.append(user) data.append(pwd) user_list.append(data) user_list = [] while True: user = input("请输入用户名(Q退出):") if user == "Q": break pwd = input("请输入密码:") data = [user,pwd] user_list.append(data) print(user_list)
6.5.2 列表生成式
[exp for iter_var in iterable]
工作过程:
- 迭代iterable中的每个元素;
- 每次迭代都先把结果赋值给iter_var,然后通过exp得到一个新的计算值;
- 最后把所有通过exp得到的计算值以一个新列表的形式返回。
In [6]: lists = [i for i in range(10)] In [7]: lists Out[7]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] In [8]: list(range(10)) Out[8]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
带过滤功能的列表生成式
[exp for iter_var in iterable [if exp]]
In [12]: lists = [i for i in range(10) if i<6] In [13]: lists Out[13]: [0, 1, 2, 3, 4, 5]
循环嵌套语法格式
[exp for iter_var_A in iterable_A for iter_var_B in iterable_B]
L1 = ['香蕉', '苹果', '橙子']
L2 = ['可乐', '牛奶']
# 不使用列表生成式实现
list7 = []
for x in L1:
for y in L2:
list7.append((x, y))
# 使用列表生成式实现
list8 = [(x, y) for x in L1 for y in L2]
In [16]: list8
Out[16]:
[('香蕉', '可乐'),
('香蕉', '牛奶'),
('苹果', '可乐'),
('苹果', '牛奶'),
('橙子', '可乐'),
('橙子', '牛奶')]
6.5.3 列表生成器
即把列表生成式的[]改为(),其内部实现了__next__方法,所以可通过next方法迭代,注意,迭代完之后将取不到值。其设计也是为了节省内存
In [18]: lists = (i for i in range(10)) In [19]: lists Out[19]: <generator object <genexpr> at 0x0000009BD7BC4E08> In [20]: lists.__next__ Out[20]: <method-wrapper '__next__' of generator object at 0x0000009BD7BC4E08> In [21]: lists.__next__() Out[21]: 0 In [22]: next(lists) Out[22]: 1
6.6 列表阶段作业
-
写代码,有如下列表,按照要求实现每一个功能。
li = ["Michael", "Robert", "James", "William", "David"]-
计算列表的长度并输出
-
列表中追加元素"seven",并输出添加后的列表
-
请在列表的第1个索引位置插入元素"Tony",并输出添加后的列表
-
请修改列表第2个索引位置的元素为"Kelly",并输出修改后的列表
-
请将列表的第3个位置的值改成 "妖怪",并输出修改后的列表
-
请将列表
data=[1,"a",3,4,"heart"]的每一个元素追加到列表li中,并输出添加后的列表 -
请将字符串
s = "qwert"的每一个元素到列表li中。 -
请删除列表中的元素"Thomas",并输出添加后的列表
-
请删除列表中的第2个元素,并输出删除元素后的列表
-
请删除列表中的第2至第4个元素,并输出删除元素后的列表
-
-
写代码,有如下列表,利用切片实现每一个功能
li = [1, 3, 2, "a", 4, "b", 5,"c"]-
通过对li列表的切片形成新的列表 [1,3,2]
-
通过对li列表的切片形成新的列表 ["a",4,"b"]
-
通过对li列表的切片形成新的列表 [1,2,4,5]
-
通过对li列表的切片形成新的列表 [3,"a","b"]
-
通过对li列表的切片形成新的列表 [3,"a","b","c"]
-
通过对li列表的切片形成新的列表 ["c"]
-
通过对li列表的切片形成新的列表 ["b","a",3]
-
-
写代码,有如下列表,按照要求实现每一个功能。
lis = [2, 3, "k", ["qwe", 20, ["k1", ["tt", 3, "1"]], 89], "ab", "adv"]-
将列表lis中的第2个索引位置的值变成大写,并打印列表。
-
将列表中的数字3变成字符串"100"
-
将列表中的字符串"tt"变成数字 101
-
在 "qwe"前面插入字符串:"火车头"
-
-
请用代码实现循环输出元素和值:users = ["张亚飞","英雄","女神","大侠","侠肝义胆","两肋插刀"] ,如:
0 张亚飞 1 英雄 2 女神 3 大侠 ...
-
写代码实现以下功能
-
如有变量 goods = ['汽车','飞机','火箭'] 提示用户可供选择的商品:
0,汽车 1,飞机 2,火箭
-
用户输入索引后,将指定商品的内容拼接打印,如:用户输入0,则打印 您选择的商品是汽车。
-
-
利用for循环和range 找出 0 ~ 50 以内能被3整除的数,并追加到一个列表。
-
利用for循环和range 找出 0 ~ 50 以内能被3整除的数,并插入到列表的第0个索引位置,最终结果如下:
[48,45,42...]
-
查找列表li中的元素,移除每个元素的空格,并找出以"a"开头,并添加到一个新列表中,最后循环打印这个新列表。
li = ["MichaelC", "AbC ", "egon", " John", "James", " aqc"]
-
将以下车牌中所有
京的车牌搞到一个列表中,并输出京牌车辆的数量。data = ["京1231", "冀8899", "京166631", "晋989"]
综合示例
# 打印功能提示 print("=" * 50) print("名字管理系统v0.1") print(" 1:添加一个新的名字:") print(" 2:删除一个名字") print(" 3:修改一个名字") print(" 4:查询一个名字") print(" 5:退出系统") print("=" * 50) names = [] # 定义一个空的列表用来存储添加的名字 while True: # 2.获取用户的选择 num = int(input("请输入功能序号:")) # 3根据用户的选择,执行相应的功能 if num == 1: new_name = input("请输入名字:") names.append(new_name) print(names) elif num == 2: del_name = input("你要删除的名字是:") names.remove(del_name) print(names) elif num == 3: name = input("你想要修改的名字是:") n = len(names) i = 0 while names[i] != name and i < n: i += 1 if i >= n: print("查无此人") else: new_name = input("新名字是:") names[i] = new_name print(names) elif num == 4: find_name = input("请输入要查询的名字:") if find_name in names: print("找到了你要找的人") else: print("查无此人") elif num == 5: break else: print("输入有误,请重新输入。")
# -*- coding: utf-8 -*- """ DateTime : 2020/12/06 9:15 Author : ZhangYafei Description: 王者荣耀购买武器装备 1.选择人物 2.购买武器 金币 3.打仗 赢得金币 4.选择删除武器 5.查看武器 6.退出游戏 """ import random print('*' * 40) print('欢迎来到王者荣耀'.center(33, ' ')) print('*' * 40) role_list = ['鲁班', '后羿', '李白', '孙尚香', '貂蝉', '诸葛亮'] print('游戏人物菜单:', end='') for index, role in enumerate(role_list, start=1): print(f'{index}.{role}', end=' ') role = input('\n请选择游戏人物: ') role = role_list[int(role) - 1] if role.isdecimal() else role coins = 1000 # 保存自己武器容器 weapon_list = [] # print('欢迎{}来到王者荣耀,当前的金币是{}'.format(role,coins)) print('欢迎{}来到王者荣耀,当前金币是:{}'.format(role, coins)) while True: choice = int(input('系统菜单:1.购买武器 2.打仗 3.删除武器 4.查看武器 5.退出游戏\n请选择: ')) if choice == 1: # 购买武器 print('欢迎来到武器库:') weapons = [['屠龙刀', 500], ['樱花枪', 400], ['98k', 1000], ['手榴弹', 800], ['饮血剑', 700], ['鹅毛扇', 800]] for weapon in weapons: print(weapon[0], weapon[1], sep=' ') # 提示输入要购买武器 weaponname = input('请输入要购买武器名称:') # 1.原来有没有买过武器 2.输入的武器是否在武器库 if weaponname not in weapon_list: # 是否在武器库 for weapon in weapons: if weaponname == weapon[0]: # 购买武器 if coins >= weapon[1]: coins -= weapon[1] weapon_list.append(weapon[0]) print('{}购买武器{}成功!'.format(role, weaponname)) break else: print('金币不足,去打仗挣钱吧') else: print('输入错误') else: print('已拥有该武器') elif choice == 2: # 打仗 假设你有多个武器 print('进入战场。。。。') if len(weapon_list) > 0: # 选择武器 print('{}拥有的武器如下:'.format(role)) for weapon in weapon_list: print(weapon) while True: weaponname = input('请选择:') if weaponname in weapon_list: # 进入战争状态 默认跟张飞 ran1 = random.randint(1, 20) ran2 = random.randint(1, 20) if ran1 > ran2: print('此局对战张飞胜!!') else: print('此局对战{}胜'.format(role)) coins += 200 print('您的金币是{}'.format(coins)) break else: print('还没有武器请购买') elif choice == 3: # 删除武器 print('武器太多,很沉,扔几个。。。') if len(weapon_list) > 0: print('{}拥有的武器如下:'.format(role)) for weapon in weapon_list: print(weapon) while True: weaponname = input('请选择要删除的武器') if weaponname in weapon_list: # 删除武器 remove pop weapon_list.remove(weaponname) # 返金币 for weapon in weapons: if weaponname == weapon[0]: coins += weapon[1] print('删除成功,还剩{}金币'.format(coins)) break break else: print('武器名称输入有误!') else: print('你都没武器,删空气?') elif choice == 4: print('{}拥有的武器如下:'.format(role)) for weapon in weapon_list: print(weapon) print('总金币:', coins) elif choice == 5: answer = input('确定要离开王者荣耀游戏吗?(yes/no)') if answer == 'yes': print('game over') break else: print('输入错误,请重新选择')
七、元组(tuple)
7.1 定义
列表(list),是一个有序且可变的容器,在里面可以存放多个不同类型的元素。
元组(tuple),是一个有序且不可变的容器,在里面可以存放多个不同类型的元素。
特点:元组不能增删改,只能查,可以看做内部元素不可改变的列表。
如何体现不可变呢? 记住一句话:《"我儿子永远不能换成是别人,但我儿子可以长大"》
v1 = (11,22,33)
v2 = ("李连杰","Michael")
v3 = (True,123,"Michael",[11,22,33,44])
# 建议:议在元组的最后多加一个逗v3 = ("李连杰","Michael",)
d1 = (1) # 1
d2 = (1,) # (1,)
d3 = (1,2)
d4 = (1,2)
注意:建议在元组的最后多加一个逗号,用于标识他是一个元组。
# 面试题
1. 比较值 v1 = (1) 和 v2 = 1 和 v3 = (1,) 有什么区别?
2. 比较值 v1 = ( (1),(2),(3) ) 和 v2 = ( (1,) , (2,) , (3,),) 有什么区别?
(1,2,3)
7.2 独有功能
无
- 基本操作
查(切片):
元组[索引]
元组[start:end:len] 切片
元组.count(value1)
循环:可迭代对象
长度:len()
包含:in
# 创建元组 a = tuple(range(10)) a Out[39]: (0, 1, 2, 3, 4, 5, 6, 7, 8, 9) # 查询某个值的索引 a.index(3) Out[40]: 3 # 查询某个值出现的个数 a.count(5) Out[44]: 1 # 切片 a[1] Out[45]: 1 a[1:4] Out[46]: (1, 2, 3) a[1:4:2] Out[47]: (1, 3) # 增加 a.__add__((10,)) Out[42]: (0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10) # 删除 无 # 修改 无
class tuple(object): """ Built-in immutable sequence. If no argument is given, the constructor returns an empty tuple. If iterable is specified the tuple is initialized from iterable's items. If the argument is a tuple, the return value is the same object. """ def count(self, *args, **kwargs): # real signature unknown """ Return number of occurrences of value. """ pass def index(self, *args, **kwargs): # real signature unknown """ Return first index of value. Raises ValueError if the value is not present. """ pass def __add__(self, *args, **kwargs): # real signature unknown """ Return self+value. """ pass def __contains__(self, *args, **kwargs): # real signature unknown """ Return key in self. """ pass def __eq__(self, *args, **kwargs): # real signature unknown """ Return self==value. """ pass def __getattribute__(self, *args, **kwargs): # real signature unknown """ Return getattr(self, name). """ pass def __getitem__(self, *args, **kwargs): # real signature unknown """ Return self[key]. """ pass def __getnewargs__(self, *args, **kwargs): # real signature unknown pass def __ge__(self, *args, **kwargs): # real signature unknown """ Return self>=value. """ pass def __gt__(self, *args, **kwargs): # real signature unknown """ Return self>value. """ pass def __hash__(self, *args, **kwargs): # real signature unknown """ Return hash(self). """ pass def __init__(self, seq=()): # known special case of tuple.__init__ """ Built-in immutable sequence. If no argument is given, the constructor returns an empty tuple. If iterable is specified the tuple is initialized from iterable's items. If the argument is a tuple, the return value is the same object. # (copied from class doc) """ pass def __iter__(self, *args, **kwargs): # real signature unknown """ Implement iter(self). """ pass def __len__(self, *args, **kwargs): # real signature unknown """ Return len(self). """ pass def __le__(self, *args, **kwargs): # real signature unknown """ Return self<=value. """ pass def __lt__(self, *args, **kwargs): # real signature unknown """ Return self<value. """ pass def __mul__(self, *args, **kwargs): # real signature unknown """ Return self*value. """ pass @staticmethod # known case of __new__ def __new__(*args, **kwargs): # real signature unknown """ Create and return a new object. See help(type) for accurate signature. """ pass def __ne__(self, *args, **kwargs): # real signature unknown """ Return self!=value. """ pass def __repr__(self, *args, **kwargs): # real signature unknown """ Return repr(self). """ pass def __rmul__(self, *args, **kwargs): # real signature unknown """ Return value*self. """ pass
7.3 公共功能
-
相加,两个元组相加获取生成一个新的元组。
元组相加data = ("赵四","刘能") + ("宋晓峰","范德彪") print(data) # ("赵四","刘能","宋晓峰","范德彪") v1 = ("赵四","刘能") v2 = ("宋晓峰","范德彪") v3 = v1 + v2 print(v3) # ("赵四","刘能","宋晓峰","范德彪")
-
相乘,元组*整型 将元组中的元素再创建N份并生成一个新的元组。
元组相乘data = ("赵四","刘能") * 2 print(data) # ("赵四","刘能","赵四","刘能") v1 = ("赵四","刘能") v2 = v1 * 2 print(v1) # ("赵四","刘能") print(v2) # ("赵四","刘能","赵四","刘能")
-
获取长度
元组获取长度user_list = ("范德彪","刘华强",'尼古拉斯赵四',) print( len(user_list) )
-
索引
元组索引user_list = ("范德彪","刘华强",'尼古拉斯赵四',) print( user_list[0] ) print( user_list[2] ) print( user_list[3] )
-
切片
元组切片user_list = ("范德彪","刘华强",'尼古拉斯赵四',) print( user_list[0:2] ) print( user_list[1:] ) print( user_list[:-1] )
-
步长
元组步长示例user_list = ("范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能") print( user_list[1:4:2] ) print( user_list[0::2] ) print( user_list[1::2] ) print( user_list[4:1:-1] ) # 字符串 & 元组。 user_list = ("范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能") data = user_list[::-1] # 列表 user_list = ["范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能"] data = user_list[::-1] user_list.reverse() print(user_list)
-
for循环
元组for循环user_list = ("范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能") for item in user_list: print(item) user_list = ("范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能") for item in user_list: if item == '刘华强': continue print(name)
目前:只有 str、list、tuple 可以被for循环。 "xxx" [11,22,33] (111,22,33)
元组for循环示例2# len + range + for + 索引 user_list = ("范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能") for index in range(len(user_list)): item = user_list[index] print(item)
7.4 转换
其他类型转换为元组,使用tuple(其他类型),目前只有字符串和列表可以转换为元组。
data = tuple(其他)
# str / list
name = "张亚飞"
data = tuple(name)
print(data) # 输出 ("张","亚","飞")
name = ["张亚飞",18,"python"]
data = tuple(name)
print(data) # 输出 ("张亚飞",18,"python")
7.5 其他
-
嵌套
由于元组和列表都可以充当容器,他们内部可以放很多元素,并且也支持元素内的各种嵌套。
tu = ( '今天妈妈在厨房做饭', '我和爸爸在客厅聊天', ('爸爸问我考了多少分','我说我考了不到90') )
tu1 = tu[0]
tu2 = tu[1]
tu3 = tu[2][0]
tu4 = tu[2][1]
tu5 = tu[2][1][3]
print(tu1)
print(tu2)
print(tu3)
print(tu4)
练习题1:判断是否可以实现,如果可以请写代码实现。
li = ["Michael", [11,22,(88,99,100,),33], "James", ("John", "Thomas",), "David"]
# 0 1 2 3 4
# 1.请将 "James" 修改成 "张亚飞"
li[2] = "张亚飞"
index = li.index("James")
li[index] = "张亚飞"
# 2.请将 ("John", "Thomas",) 修改为 ['日天','日地']
li[3] = ['日天','日地']
# 3.请将 88 修改为 87
li[1][2][0] = 87 # (报错,)
# 4.请将 "David" 删除,然后再在列表第0个索引位置插入 "Paul"
# li.remove("David")
# del li[-1]
li.insert(0,"Paul")
练习题2:记住一句话:《"我儿子永远不能换成是别人,但我儿子可以长大"》
data = ("123",666,[11,22,33], ("Michael","李连杰",[999,666,(5,6,7)]) )
# 1.将 “123” 替换成 9 报错
# 2.将 [11,22,33] 换成 "张亚飞" 报错
# 3.将 11 换成 99
data[2][0] = 99
print(data) # ("123",666,[99,22,33], ("Michael","李连杰",[999,666,(5,6,7)]) )
# 4.在列表 [11,22,33] 追加一个44
data[2].append(44)
print(data) # ("123",666,[11,22,33,44], ("Michael","李连杰",[999,666,(5,6,7)]) )
练习题3:动态的创建用户并添加到用户列表中。
# 创建用户 5个
# user_list = [] # 用户信息
user_list = [ ("Michael","132"),("admin","123"),("Rose","123") ]
while True:
user = input("请输入用户名:")
if user == "Q":
brek
pwd = input("请输入密码:")
item = (user,pwd,)
user_list.append(item)
# 实现:用户登录案例
print("登录程序")
username = input("请输入用户名:")
password = input("请输入密码:")
is_success = False
for item in user_list:
# item = ("Michael","132") ("admin","123") ("Rose","123")
if username == item[0] and password == item[1]:
is_success = True
break
if is_success:
print("登录成功")
else:
print("登录失败")
八、集合(set)
集合是一个 无序 、可变、不允许数据重复的容器。
8.1 定义
v1 = { 11, 22, 33, "Michael" }
-
无序,无法通过索引取值。
-
可变,可以添加和删除元素。
v1 = {11,22,33,44} v1.add(55) print(v1) # {11,22,33,44,55} -
不允许数据重复。
v1 = {11,22,33,44} v1.add(22) print(v1) # {11,22,33,44} - 数据类型可以不同
一般什么时候用集合呢?
就是想要维护一大堆不重复的数据时,就可以用它。比如:做爬虫去网上找图片的链接,为了避免链接重复,可以选择用集合去存储链接地址。
注意:定义空集合时,只能使用v = set(),不能使用 v={}(这样是定义一个空字典)。
v1 = []
v11 = list()
v2 = ()
v22 = tuple()
v3 = set()
v4 = {} # 空字典
v44 = dict()
8.2 独有功能
class set(object): """ set() -> new empty set object set(iterable) -> new set object Build an unordered collection of unique elements. """ def add(self, *args, **kwargs): # real signature unknown """ Add an element to a set. This has no effect if the element is already present. """ pass def clear(self, *args, **kwargs): # real signature unknown """ Remove all elements from this set. """ pass def copy(self, *args, **kwargs): # real signature unknown """ Return a shallow copy of a set. """ pass def difference(self, *args, **kwargs): # real signature unknown """ Return the difference of two or more sets as a new set. (i.e. all elements that are in this set but not the others.) """ pass def difference_update(self, *args, **kwargs): # real signature unknown """ Remove all elements of another set from this set. """ pass def discard(self, *args, **kwargs): # real signature unknown """ Remove an element from a set if it is a member. If the element is not a member, do nothing. """ pass def intersection(self, *args, **kwargs): # real signature unknown """ Return the intersection of two sets as a new set. (i.e. all elements that are in both sets.) """ pass def intersection_update(self, *args, **kwargs): # real signature unknown """ Update a set with the intersection of itself and another. """ pass def isdisjoint(self, *args, **kwargs): # real signature unknown """ Return True if two sets have a null intersection. """ pass def issubset(self, *args, **kwargs): # real signature unknown """ Report whether another set contains this set. """ pass def issuperset(self, *args, **kwargs): # real signature unknown """ Report whether this set contains another set. """ pass def pop(self, *args, **kwargs): # real signature unknown """ Remove and return an arbitrary set element. Raises KeyError if the set is empty. """ pass def remove(self, *args, **kwargs): # real signature unknown """ Remove an element from a set; it must be a member. If the element is not a member, raise a KeyError. """ pass def symmetric_difference(self, *args, **kwargs): # real signature unknown """ Return the symmetric difference of two sets as a new set. (i.e. all elements that are in exactly one of the sets.) """ pass def symmetric_difference_update(self, *args, **kwargs): # real signature unknown """ Update a set with the symmetric difference of itself and another. """ pass def union(self, *args, **kwargs): # real signature unknown """ Return the union of sets as a new set. (i.e. all elements that are in either set.) """ pass def update(self, *args, **kwargs): # real signature unknown """ Update a set with the union of itself and others. """ pass def __and__(self, *args, **kwargs): # real signature unknown """ Return self&value. """ pass def __contains__(self, y): # real signature unknown; restored from __doc__ """ x.__contains__(y) <==> y in x. """ pass def __eq__(self, *args, **kwargs): # real signature unknown """ Return self==value. """ pass def __getattribute__(self, *args, **kwargs): # real signature unknown """ Return getattr(self, name). """ pass def __ge__(self, *args, **kwargs): # real signature unknown """ Return self>=value. """ pass def __gt__(self, *args, **kwargs): # real signature unknown """ Return self>value. """ pass def __iand__(self, *args, **kwargs): # real signature unknown """ Return self&=value. """ pass def __init__(self, seq=()): # known special case of set.__init__ """ set() -> new empty set object set(iterable) -> new set object Build an unordered collection of unique elements. # (copied from class doc) """ pass def __ior__(self, *args, **kwargs): # real signature unknown """ Return self|=value. """ pass def __isub__(self, *args, **kwargs): # real signature unknown """ Return self-=value. """ pass def __iter__(self, *args, **kwargs): # real signature unknown """ Implement iter(self). """ pass def __ixor__(self, *args, **kwargs): # real signature unknown """ Return self^=value. """ pass def __len__(self, *args, **kwargs): # real signature unknown """ Return len(self). """ pass def __le__(self, *args, **kwargs): # real signature unknown """ Return self<=value. """ pass def __lt__(self, *args, **kwargs): # real signature unknown """ Return self<value. """ pass @staticmethod # known case of __new__ def __new__(*args, **kwargs): # real signature unknown """ Create and return a new object. See help(type) for accurate signature. """ pass def __ne__(self, *args, **kwargs): # real signature unknown """ Return self!=value. """ pass def __or__(self, *args, **kwargs): # real signature unknown """ Return self|value. """ pass def __rand__(self, *args, **kwargs): # real signature unknown """ Return value&self. """ pass def __reduce__(self, *args, **kwargs): # real signature unknown """ Return state information for pickling. """ pass def __repr__(self, *args, **kwargs): # real signature unknown """ Return repr(self). """ pass def __ror__(self, *args, **kwargs): # real signature unknown """ Return value|self. """ pass def __rsub__(self, *args, **kwargs): # real signature unknown """ Return value-self. """ pass def __rxor__(self, *args, **kwargs): # real signature unknown """ Return value^self. """ pass def __sizeof__(self): # real signature unknown; restored from __doc__ """ S.__sizeof__() -> size of S in memory, in bytes """ pass def __sub__(self, *args, **kwargs): # real signature unknown """ Return self-value. """ pass def __xor__(self, *args, **kwargs): # real signature unknown """ Return self^value. """ pass __hash__ = None
增:集合.add(元素)
删:集合.pop() 按顺序删除元素,先进先出
集合.remove(val) 删除指定元素,若不存在报错
集合.discard(val) 删除指定元素,若不存在不报错
清空:集合.clear()
求交集:集合1.intersection(集合2) &
求并集:集合1.union(集合2) |
求补集:集合1.difference(集合2)
长度:len()
循环:可迭代对象
包含:in
-
添加元素
添加元素adddata = {"刘嘉玲", '关之琳', "王祖贤"} data.add("郑裕玲") print(data) data = set() data.add("周杰伦") data.add("林俊杰") print(data) -
删除元素
删除元素discarddata = {"刘嘉玲", '关之琳', "王祖贤","张曼⽟", "李若彤"} data.discard("关之琳") print(data) -
交集
交集intersections1 = {"刘能", "赵四", "⽪⻓⼭"} s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"} s4 = s1.intersection(s2) # 取两个集合的交集 print(s4) # {"⽪⻓⼭"} s3 = s1 & s2 # 取两个集合的交集 print(s3) -
并集
并集unions1 = {"刘能", "赵四", "⽪⻓⼭"} s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"} s4 = s1.union(s2) # 取两个集合的并集 {"刘能", "赵四", "⽪⻓⼭","刘科⻓", "冯乡⻓", } print(s4) s3 = s1 | s2 # 取两个集合的并集 print(s3) -
差集
differences1 = {"刘能", "赵四", "⽪⻓⼭"} s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"} s4 = s1.difference(s2) # 差集,s1中有且s2中没有的值 {"刘能", "赵四"} s6 = s2.difference(s1) # 差集,s2中有且s1中没有的值 {"刘科⻓", "冯乡⻓"} s3 = s1 - s2 # 差集,s1中有且s2中没有的值 s5 = s2 - s1 # 差集,s2中有且s1中没有的值 print(s5,s6)
8.3 公共功能
-
减,计算差集
减-差集s1 = {"刘能", "赵四", "⽪⻓⼭"} s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"} s3 = s1 - s2 s4 = s2 - s1 print(s3) print(s4) -
&,计算交集
&-交集s1 = {"刘能", "赵四", "⽪⻓⼭"} s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"} s3 = s1 & s2 print(s3) -
|,计算并集
|-并集s1 = {"刘能", "赵四", "⽪⻓⼭"} s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"} s3 = s1 | s2 print(s3) -
长度
长度v = {"刘能", "赵四", "尼古拉斯"} data = len(v) print(data) -
for循环
for循环v = {"刘能", "赵四", "尼古拉斯"} for item in v: print(item)
8.4 转换
其他类型如果想要转换为集合类型,可以通过set进行转换,并且如果数据有重复自动剔除。
提示:int/list/tuple/dict都可以转换为集合。
v1 = "张亚飞"
v2 = set(v1)
print(v2) # {"张","亚","飞"}
v1 = [11,22,33,11,3,99,22]
v2 = set(v1)
print(v2) # {11,22,33,3,99}
v1 = (11,22,3,11)
v2 = set(v1)
print(v2) # {11,22,3}
提示:这其实也是去重的一个手段。
data = {11,22,33,3,99}
v1 = list(data) # [11,22,33,3,99]
v2 = tuple(data) # (11,22,33,3,99)
8.5 其他
8.5.1 集合的存储原理

8.5.2 元素必须可哈希
因存储原理,集合的元素必须是可哈希的值,即:内部通过通过哈希函数把值转换成一个数字。
目前可哈希的数据类型:int、bool、str、tuple,而list、set是不可哈希的。
总结:集合的元素只能是 int、bool、str、tuple 。
-
转换成功
v1 = [11,22,33,11,3,99,22] v2 = set(v1) print(v2) # {11,22,33,3,99} -
转换失败
v1 = [11,22,["Michael","eric"],33] v2 = set(v1) # 报错 print(v2)
8.5.3 查找速度特别快
因存储原理特殊,集合的查找效率非常高(数据量大了才明显)。
-
低
user_list = ["张亚飞","Michael","刘翔"] if "Michael" in user_list: print("在") else: print("不在") user_tuple = ("张亚飞","Michael","刘翔") if "Michael" in user_tuple: print("在") else: print("不在") -
效率高
user_set = {"张亚飞","Michael","刘翔"} if "Michael" in user_set: print("在") else: print("不在")
8.5.4 对比和嵌套
| 类型 | 是否可变 | 是否有序 | 元素要求 | 是否可哈希 | 转换 | 定义空 |
|---|---|---|---|---|---|---|
| list | 是 | 是 | 无 | 否 | list(其他) | v=[]或v=list() |
| tuple | 否 | 是 | 无 | 是 | tuple(其他) | v=()或v=tuple() |
| set | 是 | 否 | 可哈希 | 否 | set(其他) | v=set() |
data_list = [
"Michael",
11,
(11, 22, 33, {"Michael", "eric"}, 22),
[11, 22, 33, 22],
{11, 22, (True, ["中国", "北京"], "沙河"), 33}
]
注意:由于True和False本质上存储的是 1 和 0 ,而集合又不允许重复,所以在整数 0、1和False、True出现在集合中会有如下现象:
v1 = {True, 1}
print(v1) # {True}
v2 = {1, True}
print(v2) # {1}
v3 = {0, False}
print(v3) # {0}
v4 = {False, 0}
print(v4) # {False}
8.5.5 集合生成式
{exp for iter_var in iterable}
# for in 循环实现 S = set() for i in range(1,7): S.add(i * i) print(S) # {1, 4, 36, 9, 16, 25} # 集合生成式 S = { i * i for i in range(1,7)} print(S) # {1, 4, 36, 9, 16, 25}
# for in 循环嵌套if S = set() for i in range(1,7): if i % 2: S.add(i * i) print(S) # 集合生成式 S = { i * i for i in range(1,7) if i % 2} print(S)
# for in 循环 S = set() for i in range(1,4): for j in range(1,4): S.add((i,j)) print(S) # 集合生成式 S = { (i,j) for i in range(1,4) for j in range(1,4)} print(S)
练习题
-
写代码实现
v1 = {'Michael','张sir','武松'} v2 = [] # 循环提示用户输入,如果输入值在v1中存在,则追加到v2中,如果v1中不存在,则添加到v1中。(如果输入N或n则停止循环) while True: name = input("请输入姓名(N/n退出):") if name.upper() == "Q": break if name in v1: v2.append(name) else: v1.add(name) -
下面那些值不能做集合的元素
"" 0 [11,22,33] # 不能 [] # 不能 (123) {1,2,3} # 不能 -
模拟用户信息录入程序,已录入则不再创建。
user_info_set = set() while True: name = input("请输入姓名:") age = input("请输入年龄:") item = (name,age,) if item in user_info_set: print("该用户已录入") else: user_info_set.add(item) -
给你个列表去重。
v = [11,22,11,22,44455] data = set(v) # {11,22,44455} result = list(data) # [11,22,44455]
九、字典(dict):Python中应用非常广泛的一个数据类型
字典是 无序、键不重复 且 元素只能是键值对的可变的容器。
-
容器
-
元素必须键值对
-
键不重复,重复则会被覆盖
data = { "k1":1, "k1":2 } print(data) # {"k1":2} -
无序(在Python3.6+字典就是有序了,之前的字典都是无序。)
data = { "k1":1, "k2":2 } print(data)
9.1 定义
v1 = {}
v2 = dict()
data = {
"k1":1,
"k2":2
}
info = {
"age":12,
"status":True,
"name":"zhangyafei",
"hobby":['篮球','足球']
}
字典中对键值得要求:
-
键:必须可哈希。 目前为止学到的可哈希的类型:int/bool/str/tuple;不可哈希的类型:list/set/dict。(集合)
-
值:任意类型。
data_dict = {
"张亚飞":29,
True:5,
123:5,
(11,22,33):["Michael","eric"]
}
# 不合法
v1 = {
[1, 2, 3]: '周杰伦',
"age" : 18
}
v2 = {
{1,2,3}: "哈哈哈",
'name':"Michael"
}
v3 = {
{"k1":123,"k2":456}: '呵呵呵',
"age":999
}
data_dict = {
1: 29,
True: 5
}
print(data_dict) # {1: 5}
一般在什么情况下会用到字典呢?
当我们想要表示一组固定信息时,用字典可以更加的直观,例如:
# 用户列表
user_list = [ ("Michael","123"), ("admin","666") ]
...
# 用户列表
user_list = [ {"name":"Michael","pwd":"123"}, {"name":"eric","pwd":"123"} ]
9.2 独有功能
创建字典
字典名= {键:值,键:值……}
字典名 = dict()
添加
字典名[新的key] = value
字典更新
字典A.update(字典B)
删除
del 字典名[key] 无返回值
字典A.pop(key) 删除指定键值对,有返回值
字典名.popitem() 按顺序删除 后进先出
设置默认值
字典名.setdefault(键,值)
修改
字典名[已存在的key]=new_value
查询
字典名[key]
字典名.get(key, defualt) # 不会报错
字典名.keys()
字典名.values()
字典名.items():items把字典中每一个元素看成一个元组,查看元组值的时候,我们可以根据下标,同时也可以根据相等个数的变量值系统自动赋相应位置上的值
清空字典
字典名.clear()
长度:len()
循环:可迭代对象
包含: in
-
获取值
获取值示例info = { "age":12, "status":True, "name":"张亚飞", "data":None } data1 = info.get("name") print(data1) # 输出:张亚飞 data2 = info.get("age") print(data2) # 输出:12 data = info.get("email") # 键不存在,默认返回 None """ if data == None: print("此键不存在") else: print(data) if data: print(data) else: print("键不存在") """ """ # 字典的键中是否存在 email if "email" in info: data = info.get("email") print(data) else: print("不存在") """ data = info.get("hobby",123) print(data) # 输出:123
获取值案例1# 案例: user_list = { "zhangyafei": "123", "Michael": "uk87", } username = input("请输入用户名:") password = input("请输入密码:") # None,用户名不存在 # 密码,接下来比较密码 pwd = user_list.get(username) if pwd == None: print("用户名不存在") else: if password == pwd: print("登录成功") else: print("密码错误")
获取值案例2# 案例: user_list = { "zhangyafei": "123", "Michael": "uk87", } username = input("请输入用户名:") password = input("请输入密码:") # None,用户名不存在 # 密码,接下来比较密码 pwd = user_list.get(username) if pwd: if password == pwd: print("登录成功") else: print("密码错误") else: print("用户名不存在")
获取值案例3# 案例: user_list = { "zhangyafei": "123", "Michael": "uk87", } username = input("请输入用户名:") password = input("请输入密码:") # None,用户名不存在 # 密码,接下来比较密码 pwd = user_list.get(username) if not pwd: print("用户名不存在") else: if password == pwd: print("登录成功") else: print("密码错误") # 写代码的准则:简单的逻辑处理放在前面;复杂的逻辑放在后面。
-
所有的键
获取所有键keysinfo = {"age":12, "status":True, "name":"zhangyafei","email":"xx@live.com"} data = info.keys() print(data) # 输出:dict_keys(['age', 'status', 'name', 'email']) py2 -> ['age', 'status', 'name', 'email'] result = list(data) print(result) # ['age', 'status', 'name', 'email']注意:在Python2中 字典.keys()直接获取到的是列表,而Python3中返回的是
高仿列表,这个高仿的列表可以被循环显示。
循环和判断是否存在# 循环 info = {"age":12, "status":True, "name":"zhangyafei","email":"xx@live.com"} for ele in info.keys(): print(ele) # 是否存在 info = {"age":12, "status":True, "name":"zhangyafei","email":"xx@live.com"} # info.keys() # dict_keys(['age', 'status', 'name', 'email']) if "age" in info.keys(): print("age是字典的键") else: print("age不是")
-
所有的值
获取所有值valuesinfo = {"age":12, "status":True, "name":"zhangyafei","email":"xx@live.com"} data = info.values() print(data) # 输出:dict_values([12, True, 'zhangyafei', 'xx@live.com'])注意:在Python2中 字典.values()直接获取到的是列表,而Python3中返回的是高仿列表,这个高仿的列表可以被循环显示。
循环和判断是否存在# 循环 info = {"age":12, "status":True, "name":"zhangyafei","email":"xx@live.com"} for val in info.values(): print(val) # 是否存在 info = {"age":12, "status":True, "name":"zhangyafei","email":"xx@live.com"} if 12 in info.values(): print("12是字典的值") else: print("12不是")
-
所有的键值
获取所有键值itemsinfo = {"age":12, "status":True, "name":"zhangyafei","email":"xx@live.com"} data = info.items() print(data) # 输出 dict_items([ ('age', 12), ('status', True), ('name', 'zhangyafei'), ('email', 'xx@live.com') ]) for item in info.items(): print(item[0],item[1]) # item是一个元组 (键,值) for key,value in info.items(): print(key,value) # key代表键,value代表值,将兼职从元组中直接拆分出来了。 info = {"age":12, "status":True, "name":"zhangyafei","email":"xx@live.com"} data = info.items() if ('age', 12) in data: print("在") else: print("不在") -
设置值
设置值setdefaultdata = { "name": "张亚飞", "email": 'xxx@live.com' } data.setdefault("age", 18) print(data) # {'name': '张亚飞', 'email': 'xxx@live.com', 'age': 18} data.setdefault("name", "Michael") print(data) # {'name': '张亚飞', 'email': 'xxx@live.com', 'age': 18}
-
更新字典键值对
更新键值对info = {"age":12, "status":True} info.update( {"age":14,"name":"张亚飞"} ) # info中没有的键直接添加;有的键则更新值 print(info) # 输出:{"age":14, "status":True,"name":"张亚飞"} -
移除指定键值对
移除键值对info = {"age":12, "status":True,"name":"张亚飞"} data = info.pop("age") print(info) # {"status":True,"name":"张亚飞"} print(data) # 12 -
按照顺序移除(后进先出)
按照顺序移除info = {"age":12, "status":True,"name":"张亚飞"} data = info.popitem() # ("name","张亚飞" ) print(info) # {"age":12, "status":True} print(data) # ("name","张亚飞") py3.6后,popitem移除最后的值。 py3.6之前,popitem随机删除。
练习题
"""
结合下面的两个变量 header 和 stock_dict实现注意输出股票信息,格式如下:
SH601778,股票名称:中国晶科、当前价:6.29、涨跌额:+1.92。
SH688566,股票名称:吉贝尔、当前价:... 。
...
"""
header = ['股票名称', '当前价', '涨跌额']
stock_dict = {
'SH601778': ['中国晶科', '6.29', '+1.92'],
'SH688566': ['吉贝尔', '52.66', '+6.96'],
'SH688268': ['华特气体', '88.80', '+11.72'],
'SH600734': ['实达集团', '2.60', '+0.24']
}
""" 结合下面的两个变量 header 和 stock_dict 实现注意输出股票信息,格式如下: SH601778,股票名称:中国晶科、当前价:6.29、涨跌额:+1.92。 SH688566,股票名称:吉贝尔、当前价:... ... """ header = ['股票名称', '当前价', '涨跌额'] stock_dict = { 'SH601778': ['中国晶科', '6.29', '+1.92'], 'SH688566': ['吉贝尔', '52.66', '+6.96'], 'SH688268': ['华特气体', '88.80', '+11.72'], 'SH600734': ['实达集团', '2.60', '+0.24'] } for key, value in stock_dict.items(): # print(key, value) # 'SH601778': ['中国晶科', '6.29', '+1.92'], text_list = [] # ["股票名称:中国晶科", "当前价:6.29" , "涨跌额:+1.92"] for index in range(len(value)): text = "{}:{}".format(header[index], value[index]) # text_list.append(text) data = "、".join(text_list) # "股票名称:中国晶科、当前价:6.29、涨跌额:+1.92" result = "{},{}。".format(key, data) print(result)
9.3 公共功能
-
求
并集(Python3.9新加入)
字典并集v1 = {"k1": 1, "k2": 2} v2 = {"k2": 22, "k3": 33} v3 = v1 | v2 print(v3) # {'k1': 1, 'k2': 22, 'k3': 33} -
长度
字典长度info = {"age":12, "status":True,"name":"张亚飞"} data = len(info) print(data) # 输出:3 -
是否包含
是否包含info = { "age":12, "status":True,"name":"张亚飞" } v1 = "age" in info print(v1) v2 = "age" in info.keys() print(v2) if "age" in info: pass else: pass info = {"age":12, "status":True,"name":"张亚飞"} v1 = "张佩奇" in info.values() print(v1) info = {"age": 12, "status": True, "name": "张亚飞"} # 输出info.items()获取到的 dict_items([ ('age', 12), ('status', True), ('name', 'zhangyafei'), ('email', 'xx@live.com') ]) v1 = ("age", 12) in info.items() print(v1) -
索引(键) 字典不同于元组和列表,字典的索引是
键,而列表和元组则是0、1、2等数值。
索引info = { "age":12, "status":True, "name":"张亚飞"} print( info["age"] ) # 输出:12 print( info["name"] ) # 输出:张亚飞 print( info["status"] ) # 输出:True print( info["xxxx"] ) # 报错,通过键为索引去获取之后时,键不存在会报错(以后项目开发时建议使用get方法根据键去获取值) value = info.get("xxxxx") # None print(value) -
根据键 修改值 和 添加值 和 删除键值对 上述示例通过键可以找到字典中的值,通过键也可以对字典进行添加和更新操作
通过键修改字典info = {"age":12, "status":True,"name":"张亚飞"} info["gender"] = "男" print(info) # 输出: {"age":12, "status":True,"name":"张亚飞","gender":"男"} info = {"age":12, "status":True,"name":"张亚飞"} info["age"] = "18" print(info) # 输出: {"age":"18", "status":True,"name":"张亚飞"} info = {"age":12, "status":True,"name":"张亚飞"} del info["age"] # 删除info字典中键为age的那个键值对(键不存在则报错) print(info) # 输出: {"status":True,"name":"张亚飞"} info = {"age": 12, "status": True, "name": "张亚飞"} if "agea" in info: del info["age"] data = info.pop("age") print(info) print(data) else: print("键不存在") -
for循环 由于字典也属于是容器,内部可以包含多个键值对,可以通过循环对其中的:键、值、键值进行循环;
for循环info = {"age":12, "status":True,"name":"张亚飞"} for item in info: print(item) # 所有键 info = {"age":12, "status":True,"name":"张亚飞"} for item in info.key(): print(item) info = {"age":12, "status":True,"name":"张亚飞"} for item in info.values(): print(item) info = {"age":12, "status":True,"name":"张亚飞"} for key,value in info.items(): print(key,value)
7. 扩展:对字典排序的几种方式
d = {'a':1,'b':4,'c':2}
# 根据键排序
sorted(d.items())
[('a', 1), ('b', 4), ('c', 2)]
# 根据value进行排序
# 方式一
sorted(d.items(),key = lambda x:x[1],reverse = True)
[('b', 4), ('c', 2), ('a', 1)]
sorted(d.items(),key = lambda x:x[1],reverse = False)
[('a', 1), ('c', 2), ('b', 4)]
# 方法二
import operator
sorted(d.items(),key = operator.itemgetter(1))
[('a', 1), ('c', 2), ('b', 4)]
# 方法三
sorted(d, key=d.__getitem__)
['a', 'c', 'b']
for k in sorted(d, key=d.__getitem__):
print(k, d.get(k))
a 1
c 2
b 4
9.4 转换
想要转换为字典.
v = dict( [ ("k1", "v1"), ["k2", "v2"] ] )
print(v) # { "k1":"v1", "k2":"v2" }
info = { "age":12, "status":True, "name":"张亚飞" }
v1 = list(info) # ["age","status","name"]
v2 = list(info.keys()) # ["age","status","name"]
v3 = list(info.values()) # [12,True,"张亚飞"]
v4 = list(info.items()) # [ ("age",12), ("status",True), ("name","张亚飞") ]
9.5 其他
9.5.1 存储原理

9.5.2 速度快
info = {
"Michael":["肝胆","铁锤"],
"老男孩":["二蛋","缺货"]
}
for "Michael" in info:
print("在")
info = {
"Michael":["肝胆","铁锤"],
"老男孩":["二蛋","缺货"]
}
v1 = info["Michael"]
v2 = info.get("Michael")
9.5.3 嵌套
我们已学了很多数据类型,在涉及多种数据类型之间的嵌套时,需注意一下几点:
-
字典的键必须可哈希(list/set/dict不可哈希)。
info = { (11,22):123 } info = { (11,[11,22,],22):"Michael" } -
字典的值可以是任意类型。
info = { "k1":{12,3,5}, "k2":{"xx":"x1"} } -
字典的键和集合的元素在遇到 布尔值 和 1、0 时,需注意重复的情况。
-
元组的元素不可以被替换。
dic = { 'name':'汪峰', 'age':48, 'wife':[ {'name':'国际章','age':38},{'name':'李杰','age':48} ], 'children':['第一个娃','第二个娃'] } """ 1. 获取汪峰的妻子名字 d1 = dic['wife'][0]['name'] print(d1) 2. 获取汪峰的孩子们 d2 = dic['children'] print(d2) 3. 获取汪峰的第一个孩子 d3 = dic['children'][0] print(d3) 4. 汪峰的媳妇姓名变更为 章子怡 dic['wife'][0]['name] = "章子怡" print(dic) 5. 汪峰再娶一任妻子 dic['wife'].append( {"name":"铁锤","age":19} ) print(dic) 6. 给汪峰添加一个爱好:吹牛逼 dic['hobby'] = "吹牛逼" print(dic) 7. 删除汪峰的年龄 del dic['age'] 或 dic.pop('age') print(dic) """
9.5.4 字典生成式
{key:value for iter_var in iterable}
d = dict(a=1,b=2) print("小写的字典:", d) # 1. 需求1: 将所有的key值变为大写; # 1-1. 传统方法: new_d = {} for i in d: # 'a' 'b' new_d[i.upper()] = d[i] print("key转化为大写的字典:", new_d) # 1-2. 升级 print({k.upper():v for k,v in d.items()}) # 需求2:大小写key值合并, 统一以小写key值输出; d = dict(a=2, b=1, c=2, B=9, A=5) # 2-2. 字典生成式: print({k.lower():d.get(k.lower(),0)+d.get(k.upper(),0) for k in d}) # 2-1. 传统方法: # {'a':2, 'b':1, 'c':2} new_d = {} for k, v in d.items(): low_k = k.lower() if low_k not in new_d: new_d[low_k] = v else: new_d[low_k] += v print(new_d) new_d = {} for k,v in d.items(): lower_k = k.lower() if lower_k in new_d: new_d[lower_k] += d[k] else: new_d[lower_k] = d[k] print(new_d) new_d = {k.lower():d.get(k.lower(),0)+d.get(k.upper(),0) for k in d} print(new_d) # 需求3: 把字典的key和value值调换; d = {'a':'1', 'b':'2'} print({v:k for k,v in d.items()})
综合示例
# 1. 打印功能提示 print("=" * 50) print(" 名片管理系统 v0.1") print(" 1.添加一个名片") print(" 2.删除一个名片") print(" 3.修改一个名片") print(" 4.查询一个名片") print(" 5.显示所有名片") print(" 6.退出系统") print("=" * 50) # 用来存储名片(列表) card_infors = [] while True: # 2.获取用户的输入 num = int(input("请输入操作序列:")) # 3.根据用户的输入执行相应的功能 if num == 1: new_name = input("请输入新的名字:") new_qq = input("请输入新的qq:") new_weixin = input("请输入新的微信:") new_addr = input("请输入新的住址:") # 定义一个新的字典,用来存储一个新的名片 new_infor = {} new_infor['name'] = new_name new_infor['qq'] = new_qq new_infor['weixin'] = new_weixin new_infor['addr'] = new_addr # 将一个字典添加到列表中 card_infors.append(new_infor) print(card_infors) elif num == 2: find_flag = 0 del_name = input("删除的姓名是:") for temp in card_infors: if del_name == temp['name']: card_infors.remove(temp) find_flag = 1 print(card_infors) break if find_flag == 0: print("查无此人") elif num == 3: find_flag = 0 name = input("你要修改的名片的姓名是:") for temp in card_infors: if name == temp['name']: temp['name'] = input("姓名:") temp['qq'] = input("qq:") temp['weixin'] = input("微信:") temp['addr'] = input("地址:") print("姓名\tQQ\t微信\t住址") print("%s\t%s\t%s\t%s\t" % (temp['name'], temp['qq'], temp['weixin'], temp['addr'])) find_flag = 1 break if find_flag == 0: print("查无此人") elif num == 4: find_name = input("请输入要查找的名字:") find_flag = 0 # 默认表示没有找到 for temp in card_infors: if find_name == temp['name']: print("%s\t%s\t%s\t%s\t" % (temp['name'], temp['qq'], temp['weixin'], temp['addr'])) find_flag = 1 break # else: # print("查无此人") # p判断是否找到了 if find_flag == 0: print("查无此人") elif num == 5: for temp in card_infors: print("%s\t%s\t%s\t%s\t" % (temp['name'], temp['qq'], temp['weixin'], temp['addr'])) elif num == 6: break else: print("你输入的信息有误,请重新输入!")
# -*- coding: utf-8 -*- """ DateTime : 2020/11/21 9:58 Author : ZhangYafei Description: 需求:三级菜单 三级菜单,依次进入子菜单 """ City = { '北京':{ '大兴区':[ '亦庄','黄村','中信新城','B返回','Q退出' ], '丰台区':[ '岳各庄','五棵松','丰台路口','B返回','Q退出' ], '朝阳区':[ '劲松','双井','国贸','B返回','Q退出' ], 'B返回':'返回', 'Q退出':'退出' }, '上海':{ '浦东区':[ '世纪大道','陆家嘴','盛世年华','B返回','Q退出' ], '普陀区':[ '东方汽配城','金沙社区','东锦国际大厦','B返回','Q退出' ], '徐汇区':[ '上海应用技术大学','上海长途客运南站','上海东方体育中心','B返回','Q退出' ], 'B返回': '返回', 'Q退出': '退出' }, '广州':{ '天河区':[ '珠江公园','天河体育场','广东师范大学','B返回','Q退出' ], '白云区':[ '广州体育馆','白云文化广场','广州百信广场','B返回','Q退出' ], '海珠区':[ '中山大学','城市职业学院','南方医科大学','B返回','Q退出' ], 'B返回': '返回', 'Q退出': '退出' } } # print(City) Choice_of_city = list(City.keys())#字典转换为列表 # print(City.keys()) # print(City.values()) #打印字典使用format函数格式化 # print('{0[0]} {0[1]} {0[2]}'.format(Choice_of_city)) def menu():#使用函数def while True:#只要为真就无限循环 print('{0[0]} {0[1]} {0[2]}'.format(Choice_of_city))#将列表Choice_of_city以函数format格式化打印 User_input_City = input('请选择城市:').strip()#用户输入,次数strip为移除空白 if User_input_City in Choice_of_city:#判断用户输入的信息是否在列表User_input_City中 District = list(City[User_input_City])#获取用户输入信息并根据用户输入信息取出字典City的values, # 此处用户输入信息User_input_City相当于字典City的keys,并且把获取的values转换为列表District while True:#只要为真就无限循环 # if User_input_City in Choice_of_city: print('{0[0]} {0[1]} {0[2]} {0[3]} {0[4]}'.format(District))#将列表District以函数format格式化打印 User_input_District = input('请选择区县:').strip()#用户输入 if User_input_District not in District:#判断用户输入不在于列表District中 print('输入错误,请重新输入!!') continue#退出当前循环继续下一次循环 if User_input_District in District:#判断用户输入是否在列表District中 if User_input_District == District[3]:#判断用户输入是否等于District中第4个元素 break#跳出当前循环 elif User_input_District == District[4]:#判断用户输入是否等于District中第4个元素 return#退出整个函数,这里用来退出所有循环 else: while True: Township = (City[User_input_City][User_input_District]) print('{0[0]} {0[1]} {0[2]} {0[3]} {0[4]}'.format(Township)) User_input_township = input('选择乡镇:').strip() if User_input_township not in Township: print('输入错误,请重新输入!!') continue if User_input_township in Township: if User_input_township == Township[3]: break if User_input_township == Township[4]: return else: print('Bingo!!!') return else: continue else: break else: continue else: print('输入错误,请重新输入!!') continue # else: # continue # else: # print('输入不正确,请重新输入!!') menu()
三级菜单2
# -*- coding: utf-8 -*- """ @Datetime: 2019/5/21 @Author: Zhang Yafei account.txt shanshan,shanshan,杜姗姗,22,Model,PR,22 alex,abc123,Alexander Li,222,CEO,IT,1333 rain,raindsf,RainWang,27, Engineer ,IT ,133542453453 """ def print_personal_info(account_dic, username): """ print user info :param account_dic: all account's data :param username: username :return: None """ person_data = account_dic[username] info = ''' ------------------ Name: %s Age : %s Job : %s Dept: %s Phone: %s ------------------ ''' % (person_data[1], person_data[2], person_data[3], person_data[4], person_data[5], ) print(info) def save_back_to_file(account_dic): """ 把account dic 转成字符串格式 ,写回文件 :param account_dic: :return: """ f.seek(0) # 回到文件头 f.truncate() # 清空原文件 for k in account_dic: row = ",".join(account_dic[k]) f.write("%s\n" % row) f.flush() def change_personal_info(account_dic, username): """ change user info ,思路如下 1. 把这个人的每个信息打印出来, 让其选择改哪个字段,用户选择了的数字,正好是字段的索引,这样直接 把字段找出来改掉就可以了 2. 改完后,还要把这个新数据重新写回到account.txt,由于改完后的新数据 是dict类型,还需把dict转成字符串后,再写回硬盘 :param account_dic: all account's data :param username: username :return: None """ person_data = account_dic[username] print("person data:", person_data) column_names = ['Username', 'Password', 'Name', 'Age', 'Job', 'Dept', 'Phone'] for index, k in enumerate(person_data): if index > 1: # 0 is username and 1 is password print("%s. %s: %s" % (index, column_names[index], k)) choice = input("[select column id to change]:").strip() if choice.isdigit(): choice = int(choice) if choice > 0 and choice < len(person_data): # index不能超出列表长度边界 column_data = person_data[choice] # 拿到要修改的数据 print("current value>:", column_data) new_val = input("new value>:").strip() if new_val: # 不为空 person_data[choice] = new_val print(person_data) save_back_to_file(account_dic) # 改完写回文件 else: print("不能为空。。。") account_file = "account.txt" f = open(account_file, "r+", encoding='utf-8') raw_data = f.readlines() accounts = {} # 把账户数据从文件里读书来,变成dict,这样后面就好查询了 for line in raw_data: line = line.strip() if not line.startswith("#"): items = line.split(",") accounts[items[0]] = items menu = ''' 1. 打印个人信息 2. 修改个人信息 3. 修改密码 ''' count = 0 while count < 3: username = input("Username:").strip() password = input("Password:").strip() if username in accounts: if password == accounts[username][1]: # print("welcome %s ".center(50, '-') % username) while True: # 使用户可以一直停留在这一层 print(menu) user_choice = input(">>>").strip() if user_choice.isdigit(): user_choice = int(user_choice) if user_choice == 1: print_personal_info(accounts, username) elif user_choice == 2: change_personal_info(accounts, username) elif user_choice == 'q': exit("bye.") else: print("Wrong username or password!") else: print("Username does not exist.") count += 1 else: print("Too many attempts.")
# -*- coding: utf-8 -*- ''' Datetime: 2019/12/11 author: Zhang Yafei description: 世界杯足球赛共有32支球队,分为8个小组,每组4支球队。小组赛采取循环赛,一场比赛后,获胜方得3分,失败方得0分, 若为平局,双方各得1分。试编写一个程序输出小组赛比赛所有可能的结果,要求如下: 1)按小组总得分从高到低排序输出; 2)每个小组输出成绩的格式为: 总得分=第一名得分+第二名得分+第三名得分+第四名得分 ''' from itertools import combinations, product def print_group_game_case(): game_situation = [(3, 0), (1, 1), (0, 3)] A,B,C,D = 0,0,0,0 game_score_dict = {} group_game_score_list = [] for game1, game2, game3, game4, game5, game6 in product(game_situation, repeat=6): game1A,game1B = game1 game2C,game2D = game2 game3A,game3C = game3 game4B,game4D = game4 game5A,game5D = game5 game6B,game6C = game6 A = game1A + game3A + game5A B = game1B + game4B + game6B C = game2C + game3C + game6C D = game2D + game4D + game5D group_score_list = [A,B,C,D] group_score_list.sort(reverse=True) score_sum = sum(group_score_list) if score_sum not in game_score_dict: game_score_dict[score_sum] = group_score_list group_game_score_list.append(score_sum) for group_score_prob in game_score_dict: first,second,third,fourth = game_score_dict[group_score_prob] print(f'{group_score_prob} = {first} + {second} + {third} + {fourth}') if __name__ == "__main__": print_group_game_case()
十、浮点型(float)
浮点型,一般在开发中用于表示小数。
v1 = 3.14 v2 = 9.89
关于浮点型的其他知识点如下:
-
在类型转换时需要,在浮点型转换为整型时,会将小数部分去掉。
v1 = 3.14 data = int(v1) print(data) # 3
-
想要保留小数点后N位
v1 = 3.1415926 result = round(v1,3) print(result) # 3.142
-
浮点型的坑(所有语言中)

在项目中如果遇到精确的小数计算应该怎么办?
import decimal
v1 = decimal.Decimal("0.1")
v2 = decimal.Decimal("0.2")
v3 = v1 + v2
print(v3) # 0.3
十一、None类型
Python的数据类型中有一个特殊的值None,意味着这个值啥都不是 或 表示空。 相当于其他语言中 null作用一样。
在一定程度上可以帮助我们去节省内存。例如:
v1 = None v2 = None .. v1 = [11,22,33,44] v2 = [111,22,43] v3 = [] v4 = [] ... v3 = [11,22,33,44] v4 = [111,22,43]
注意:暂不要考虑Python内部的缓存和驻留机制。
目前所有转换为布尔值为False的值有:
0
""
[] or list()
() or tuple()
set()
None
if None:
pass

