

in memory computing 存内计算是学术圈自娱自乐还是真有价值?
朋友们可以关注下我的公众号,获得最及时的更新:

或者关注我的知乎账号 : https://www.zhihu.com/people/zhangyachen
如果单从初衷和预想的价值来看,还是很诱人的。在冯诺依曼体系中,cpu计算和memory存储是分离的,而两者之间的data movement会造成高延迟和高耗能。
关于PIM类似的思想在50年前曾有人提出过,比如1969年WILLIAM H. KAUTZ发表的论文Cellular Logic-in-Memory Arrays和1970年在斯坦福大学工作的HAROLD S. STONE发表的论文A Logic-in-Memory Computer ,不过因为当时memory scaling不大,耗能瓶颈还没有出现,人们更多的是对CPU性能的关注,所以这些想法并没有被实现。


而随着近年AI等访存密集和计算密集应用的发展,高延迟和高耗能的问题成为急需解决的问题。
Nvidia的Chief Scientist——Bill Dally在2015年的一个演讲Nvidia's Path to Exascale给了一组数据:DRAM与CPU之间的date movement耗能是单纯double precise浮点数加法耗能的1000倍。

2018年的一篇论文Google Workloads for Consumer Devices: Mitigating Data Movement Bottlenecks 统计了Google常见产品(Chome/Tensorflow Mobile/video playback/video capture)的耗能情况,发现62.7%浪费在cpu和memory之间的data movement上。

2015年Google和哈佛大学联合发表了论文Profiling a warehouse-scale computer,研究人员在Google不同数据中心的20000多台机器上做了为期三年的实验,发现只有20%左右的cycles在做【userful work】,而50% - 60%的cycles是因为Back-end bound而被浪费,在Back-end bound中,80%是【serving data cache request】

严格来说,题主说的in memory computing可以分成两类:
- process using memory : 偏向于电路革新,比如让存储器本身具有计算能力,但是这种方法目前计算精度较为有限。
- process near memory : 存储器内部集成额外的计算单元,比如3D-stacked memory、logic in memory controllers.
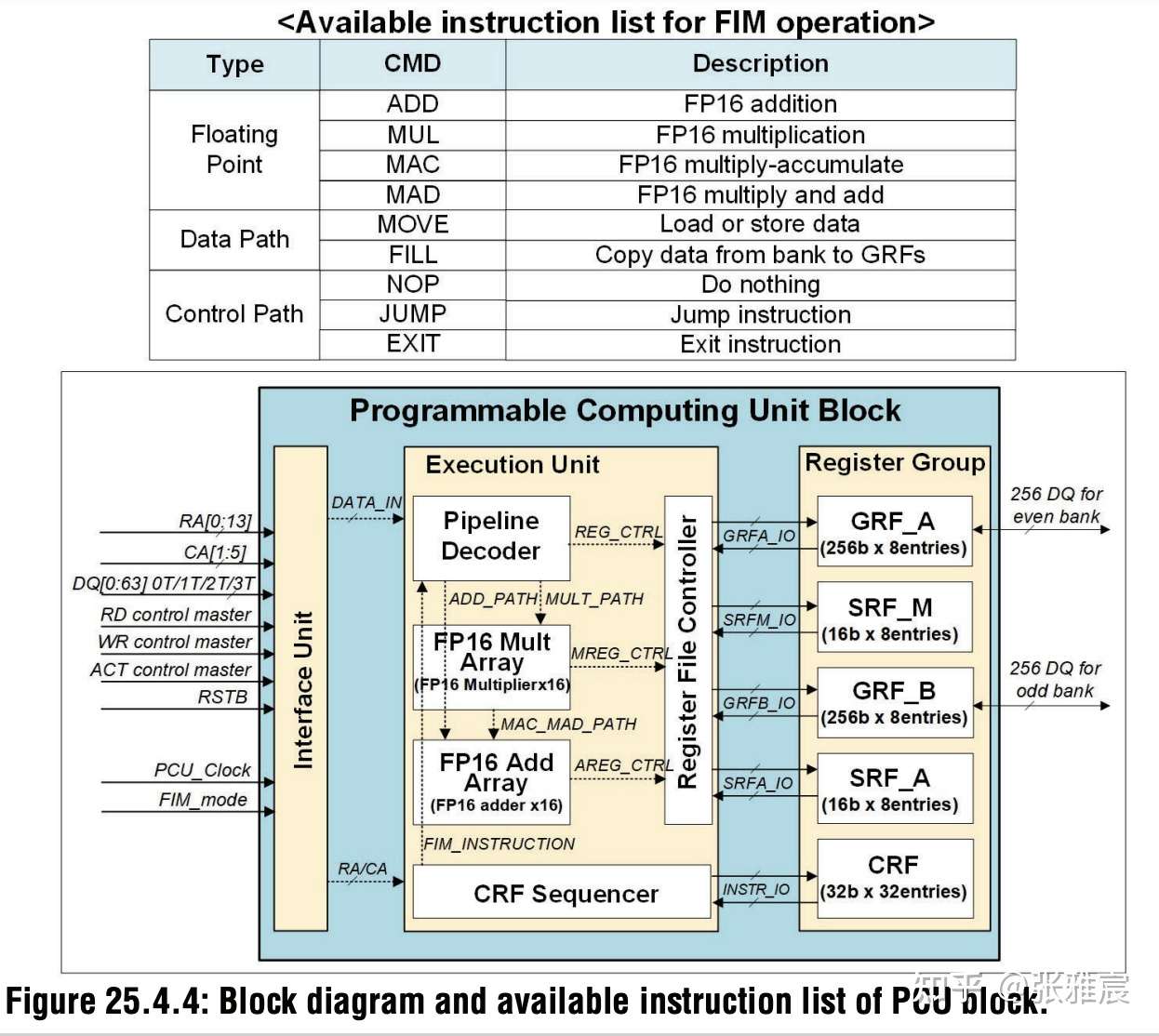
2021年Samsung发布了基于HBM-PIM的Function-in-Memory DRAM,主要针对AI场景,使用20nm DRAM工艺,并且实现了1.2TOPS的浮点数算力。可以将整体计算性能提升两倍、耗能降低70%。

Samsung在HBM-PIM中集成了额外的Programmable Computint Unit —— PCU,也就是上面说的process near memory。从下图可以看出,PCU包含了浮点数计算阵列FP16 Mult Array、流水线解码单元Pipeline Decoder、寄存器Register Group。PCU直接从邻近的DRAM中直接读取相关数据,在FP16 Mult Array中完成计算,并且根据指令进一步把结果存储到寄存器中,同时主控制器也可以根据需要把结果从寄存器读出。
另外一个比较出名的是UPMEM在2019 Hot Chips上发布的Processing-in-DRAM Engine。与Samsung的不同,这个属于process using memory,在DRAM上开发了内置于DRAM芯片本身的DPU,每个DPU可以访问64 MB的DRAM。UPMEM预计大多数应用需要几百行代码,少数人组成的团队只需2-4周就可以更新软件。


Samsung于2022年1月12号(上上周)在Nature上发布了业内首个基于 MRAM(磁性随机存储器)的存内计算芯片。这个我没细研究过,但是用MRAM来做存内计算,也算是一个巨大的飞跃。

不过还是有很多因素阻碍的PIM,比如:
- memory interleave的问题,现代memory都是按照channel去interleave,用PIM后,比如3D-stacked memory后,如何去分布数据
- 如何更方便的编程,什么操作用PIM,什么操作用CPU
- cache coherence
- 工艺的复杂程度
- ......
Onur Mutlu在ETH Zürich的Fall 2021Computer Architecture课程里也讲过之前关于PIM论文在ISCA 2016、MICRO 2016、HPCA 2017和ISCA 2017被Reject的历史,Reviewer当时给出的comment意思基本是This Will Never Get Implemented、Not practical:


Onur Mutlu对Reviewers的建议 : )

我们一般都是根据过去的经验去评价未来,没价值也没人去做了,这个价值不单单指钱 ,而且真的改变世界了呢 : )
(完)



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异