

软件工程第2次作业
作业地址:【https://edu.cnblogs.com/campus/nenu/2016CS/homework/2139】
一、效能分析
要求0:git地址:https://git.coding.net/NekoMia/wfAnalysis.git
要求1:
(1)连续运行三次的运行时间
1)运行时间:7.809s

2)运行时间:5.794s
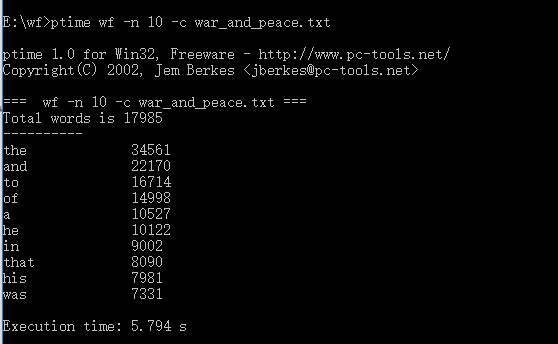
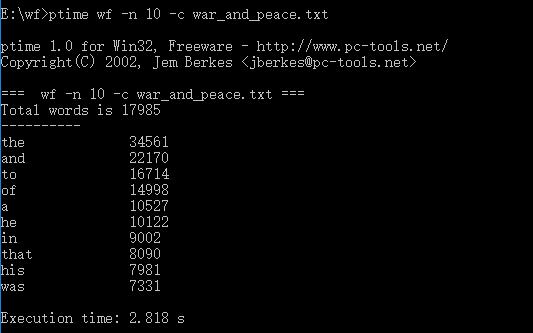
3)运行时间:2.818s
(2)猜测程序的瓶颈,为什么你认为此处会是瓶颈?你认为优化后的程序能得到怎样的效果?
由于wfMain.java里主要是对输入语句的处理以及if-else循环判断中调用wfDao.java中的函数。所以我个人认为时间大多还是耗费在了实现功能的函数上。我的wfDao.java中一共有isValid()函数、process_c()、process_f()、process()、readFile()这四个函数。由于本次测试仅测试功能3:wf -n 10 -c war_and_peace.txt这一条语句,则可以暂时不需要考虑process_c()、process_f()这两个函数,那么其实时间耗费就是isValid(),即合法单词的判断和process(),即对功能三语句的处理这两块儿。
1)Map.containsKey(wd[i])在for循环里重复调用
for(int i=0;i < len; i++) {
boolean contains = Map.containsKey(wd[i]);
if(isValid(wd[i])) {
if(contains) {
num = Map.get(wd[i]);
Map.put(wd[i], num+1);
}
else {
Map.put(wd[i], 1);
}
}
}
猜测依据:经过仔细审阅之后,我想起构建之法中效能分析这一块儿当初给出的例题,即在for循环里计算了大量次数的wordList.Count,由此我联想到自己写的那个部分,也是在for循环里面一直调用了Map.containsKey(wd[i]),上网搜索containsKey()的时间复杂度是O(n),所以这一块儿可能是瓶颈。
2)isValid()函数的外调
if(isValid(wd[i])) {
if(contains) {
num = Map.get(wd[i]);
Map.put(wd[i], num+1);
}
else {
Map.put(wd[i], 1);
}
public boolean isValid(String wd) {
//以字母开头,只接收大小写字母和数字的字符串
String reg = "^[a-zA-Z][a-zA-Z0-9]*$";
//Pattern类用于创建一个正则表达式,也可以说创建一个匹配模式,它的构造方法是私有的,不可以直接创建,但可以通过Pattern.complie(String regex)简单工厂方法创建一个正则表达式,
Pattern p = Pattern.compile(reg);
Matcher m = p.matcher(wd);
if(m.matches()) {
return true;
}else {
return false;
}
}
猜测依据:每一次外调isValid()时,都需要重新定义一遍reg,并重新compile()和matcher(),每次重新定义后有需要释放对象,势必会降低程序运行效率。
如果这两个问题能够得到解决,感觉程序运行时间能大大降低。
要求2:Profile 找出程序的瓶颈
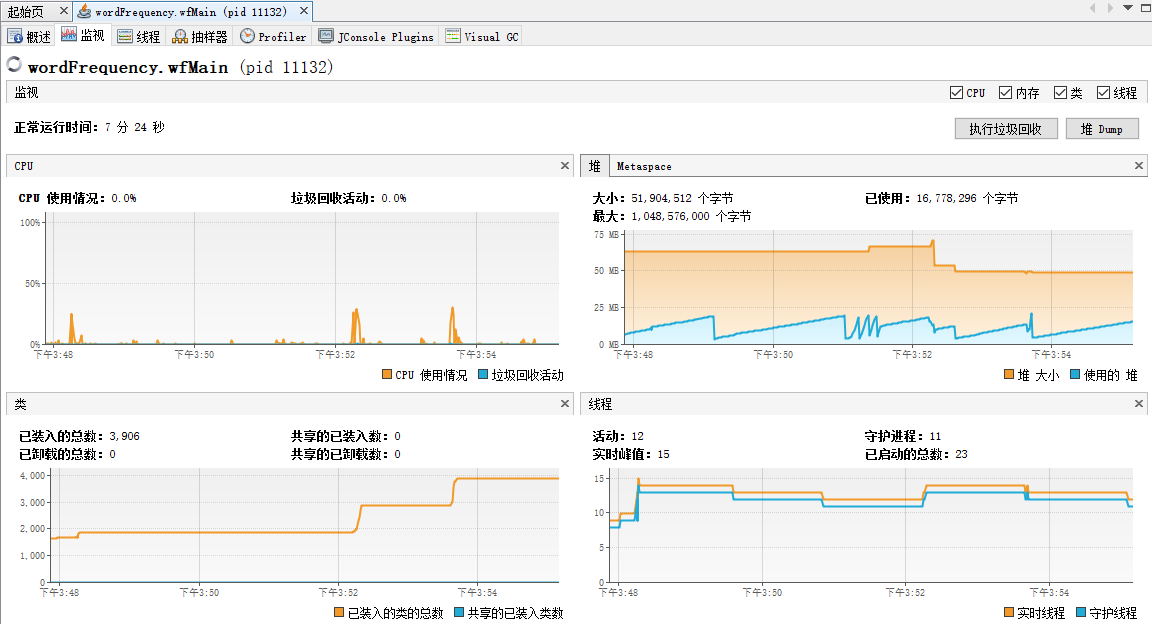
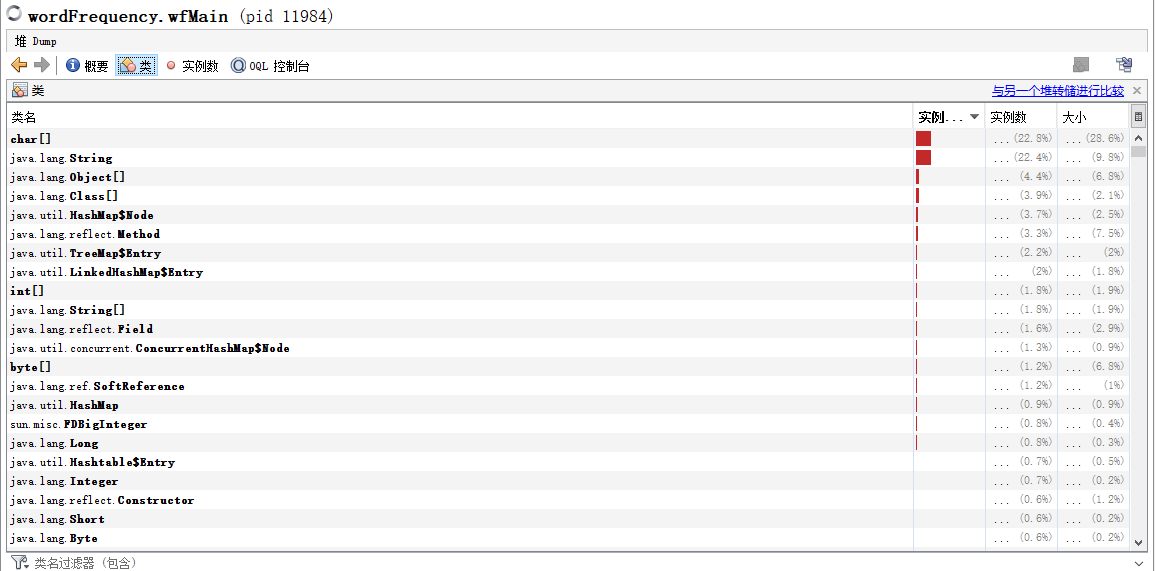
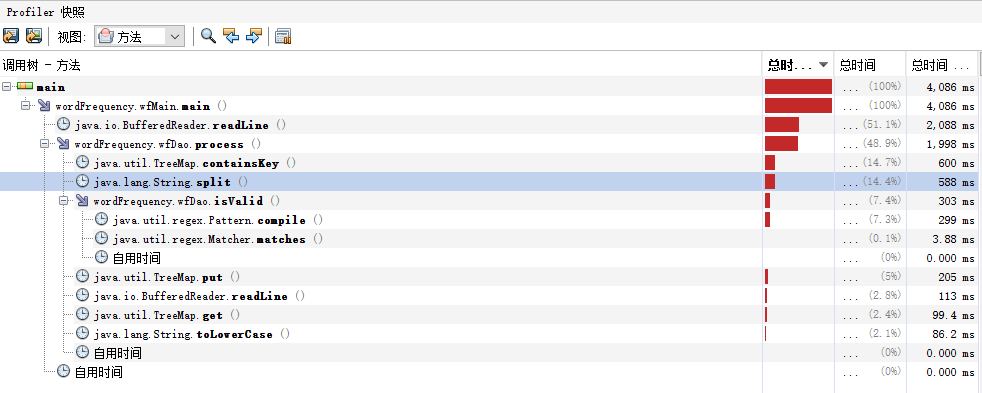
1.瓶颈发现:
使用jvisualVM工具,这是profile出来的截图,通过图可以发现process()函数下,containsKey()、split()函数、isValid()函数位居前三。continsKey()确实认真了我之前的想法,不过split()这样一个小函数,竟然也会占用那么多时间,我是真的没有想到的。于是在网上搜索了split()的使用与详解,发现了这样一篇博客(https://blog.csdn.net/sdauzyh/article/details/48137487),他详细说明了当处理大文件(例如我们这次的war_and_peace.txt(大约3.08MB)就算相对比较大的文件了)时,split、subString、stringTokenizer这三种分割字符串的效率,最终是split最慢,stringTokenizer最快。
2.解决方法:
1)containsKey()的优化方法:由于每个单词必须得判断是否已经加入Map,里面的参数wd[i]也与循环有关,暂时未找到有效的解决办法。。。
2)split()的优化方法:
既然前面已经说到stringTokenizer是最快的,于是我尝试将split处理改成用stringTokenizer来处理。
修改前代码为:
String[] wd = str.split("[^a-zA-Z0-9]|\\s");
修改后代码:
StringTokenizer tokenizer = new StringTokenizer(str,"\n\r\t .,\"?!:");
String key = tokenizer.nextToken();
int tLen = tokenizer.countTokens();
String[] wd = new String[tLen];
for(int i =0; i <tLen; i++ ) {
wd[i] = key;
key = tokenizer.nextToken();
}
3)isValid()的优化方法:
String reg = "^[a-zA-Z][a-zA-Z0-9]*$";
//Pattern类用于创建一个正则表达式,也可以说创建一个匹配模式,它的构造方法是私有的,不可以直接创建,但可以通过Pattern.complie(String regex)简单工厂方法创建一个正则表达式,
Pattern p = Pattern.compile(reg);
int len = wd.length;
for(int i=0;i < len; i++) {
boolean contains = Map.containsKey(wd[i]);
Matcher m = p.matcher(wd[i]);
if(m.matches()) { //isValid(wd[i]
if(contains) {
num = Map.get(wd[i]);
Map.put(wd[i], num+1);
}
else {
Map.put(wd[i], 1);
}
}
}
要求3:
1.耗时前三的函数消耗时间:
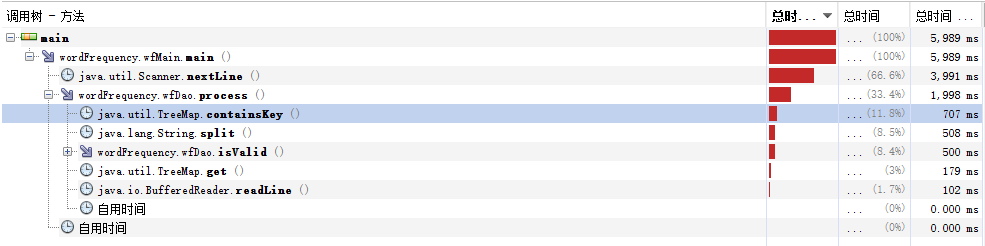
| 函数名 | 消耗时间 |
| containsKey() | 707ms |
| split() | 508ms |
| isValid() | 500ms |
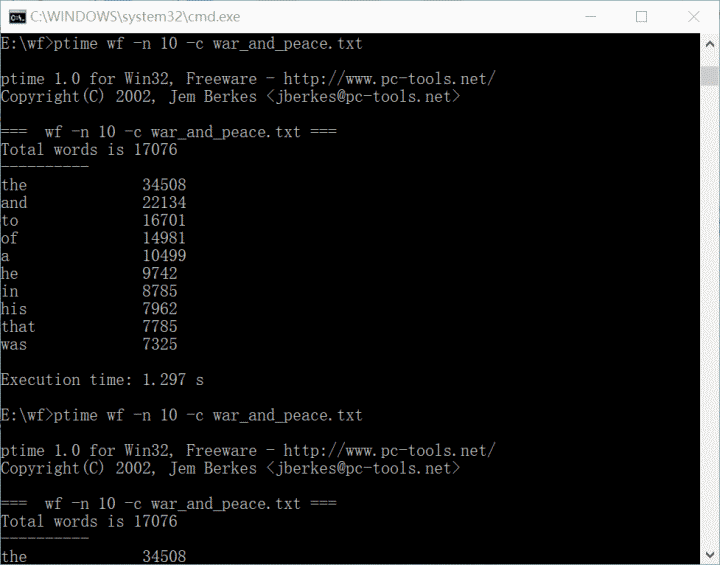
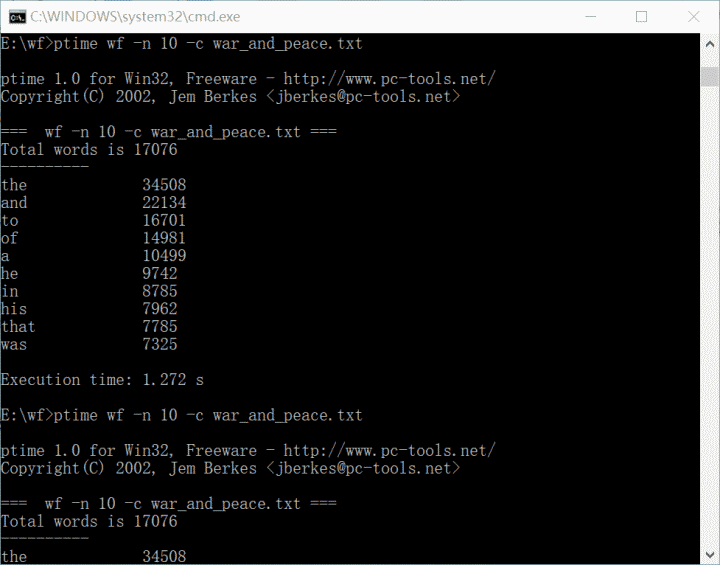
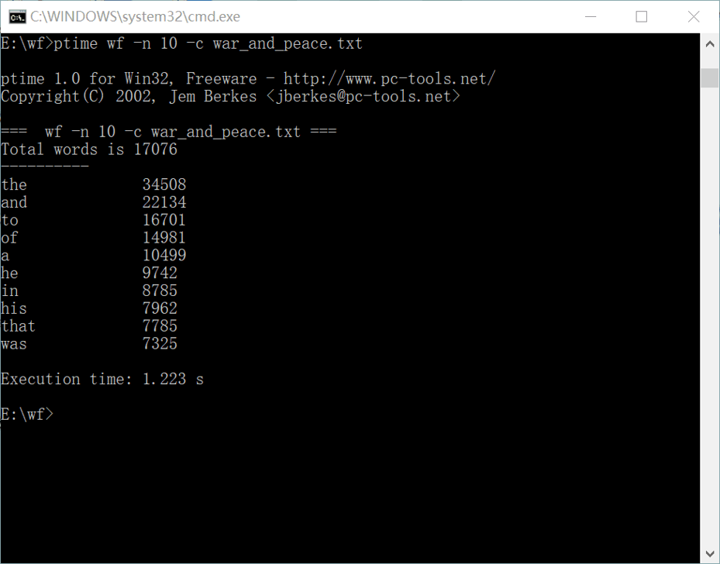
2.优化后连续三次运行时间
1)运行时间:1.297s
2)运行时间:1.272s
3)运行时间:1.223s
二、自我评估
作为计算机专业的学生,专业课程的学习是必不可少的,因为这是给我们打下理论基础的重要部分。从大一到如今的大三,我们已经学过了不少课程,如C/C++、Java、数据结构、算法设计与分析等等课程。但是即使学习了这么多课程,我却始终没有融会贯通,甚至该说是基本掌握,感觉每一个课程都只学到了一些皮毛,并不深入。加上自己是一学期结束了,就不会再去碰这些课程内容了,所以捡的一点芝麻也给扔的只剩下灰了。。。我已经上过了C/C++、Java、HTML、Python这么些语言,但是没有一项语言我是熟练掌握的,到要用时只能各种从网上查询相关内容,如此之不扎实,真的是很惭愧。
在大二上学期我们学校曾经有过一段时间的前端语言HTML+CSS+JS培训班,在那段时间真的就是纯实战教学,所以我感觉那时候真的是把HTML+CSS狠狠的巩固了一番,它也是我现在还能拿得出手的一点东西。前端语言虽然基础简单,但是它的领域很大,类似像angular.js、vue.js、Jquery等等都在他的范畴之内。我的几次比赛也是依靠着自己的前端水平,上学期的Android课就是因为没有熟练掌握Java,以至于无法用AndroidStudio完成期末大作业,而改用了Apicloud这种可以用前端语言实现APP开发的平台。在大作业的设计与开发中,我们是4人团队,前期大家一起设计原型,中期前后端合作开发,末期就是代码整合与改善。在这种过程中,第一是巩固了自己的HTML编程语言能力,第二是get'到了团队合作的重要,学会了如何进行与他人合作,互相改进,第三便是自我时间管理,因为当时的大作业期限很长,大家其他课程又多,很难兼顾过来,我们小组部分成员甚至为闲置状态,都需要我来通知性的分配任务以及时间期限才会开始去做,所以真的是了解到了自我管理是多么重要。只有自我管理高效,开发才会高效。
合格的 IT专业毕业生,真的很令我恐慌。还剩一年,这一年我该如何让自己的能力从现在的小碗汇聚成毕业时的湖泊,甚至只是池塘,这都是我需要去思考的问题。专业知识的原理与应用需要熟记,掌握一种编程语言(C/Java/Python),训练出较好的算法思维能力,熟练掌握前端开发框架。。。这些都还需要我从现在开始追起。在一次次的软件作业中才会愈发感受到自己能力的不足,愈发渴求掌握更多的知识。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号