
机器学习十讲——第四讲
第四讲——模型提升:
课程先分析了误差来源:
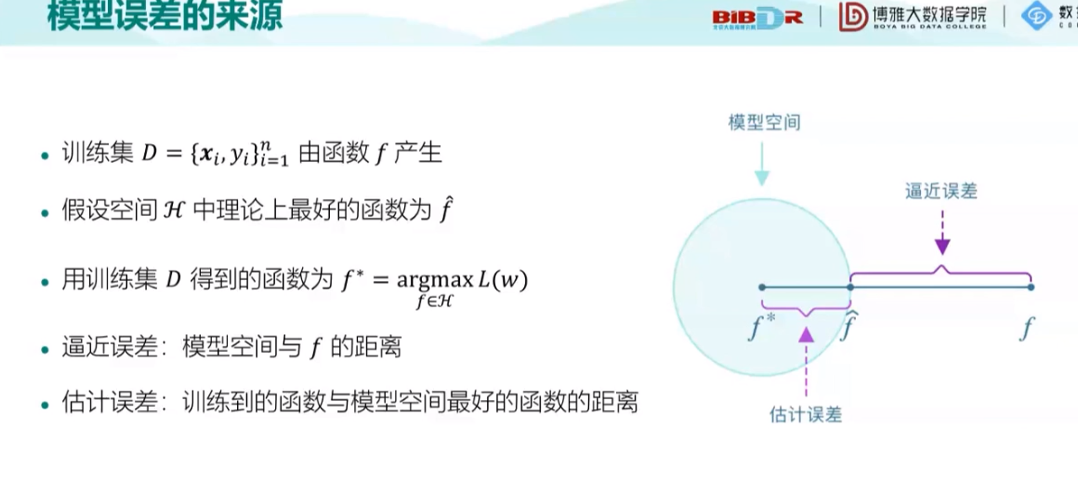
f*是通过训练集得到的一个函数,f^是这个空间H中理论最好的函数,而这个训练集背后是由f产生的,也就是说f是最好的函数,f^次之,f*是由训练集D得到的函数,他和空间H中理论最好的f^之间的误差叫做估计误差,f^与f之间的误差,叫做逼近误差。

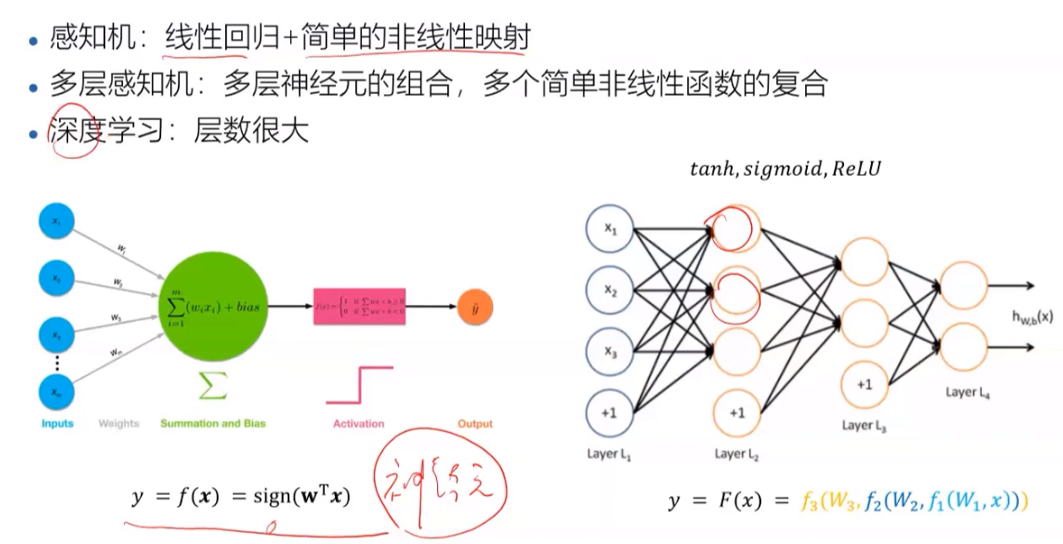
感知机看左边,只是一个简单的线性回归和一个简单的非线性映射;多层感知机看右图,由很多神经元组成(左边那个就可以看为一个神经元),也是多个简单非线性函数的复合;而当感知机很多的时候,神经元很多很多,就叫做深度学习。
之后提到了一个重要思想:模型集成:
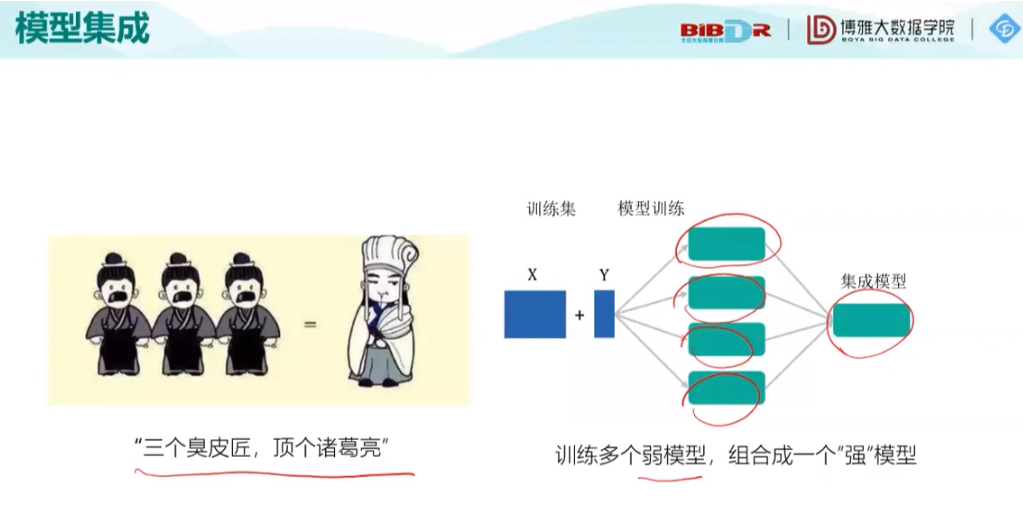
随后分析了模型集成为什么能提高效率:

补:其中K是正确的次数,t-k为犯错次数(前提:分类器之间相互独立)
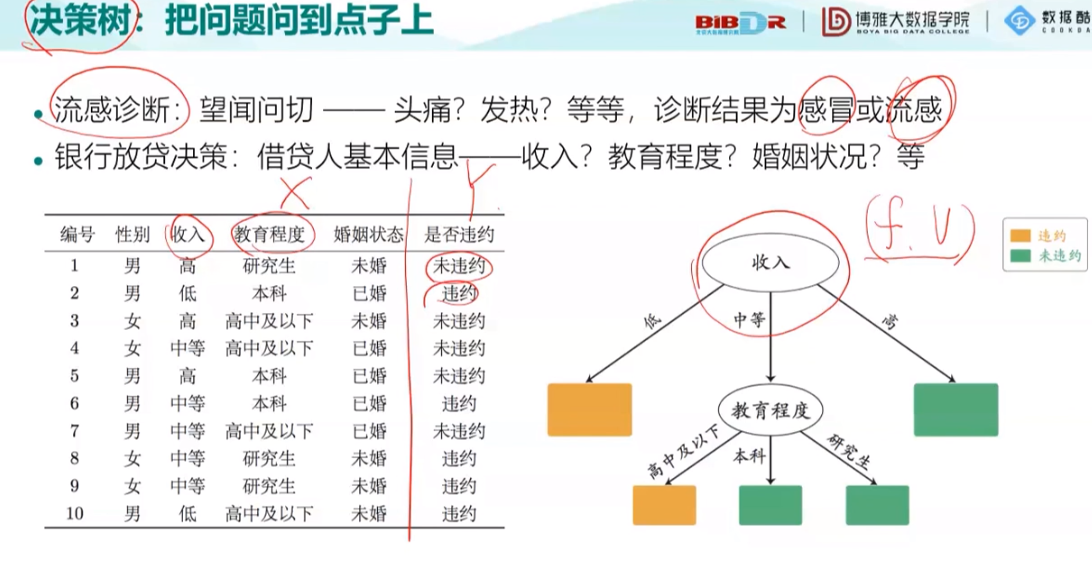
之后以一个小例子介绍了决策树的概念:
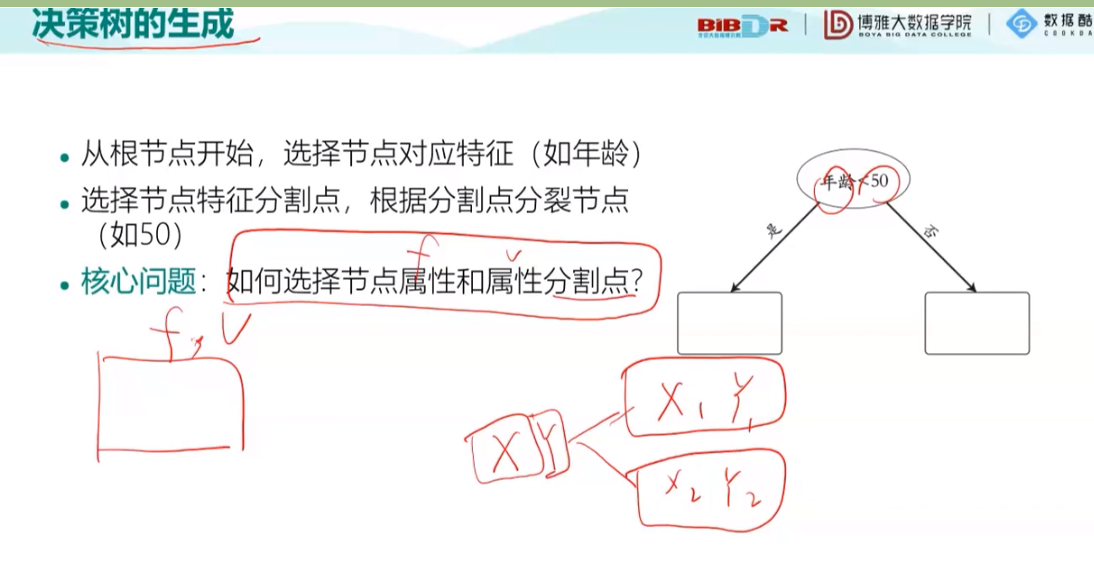
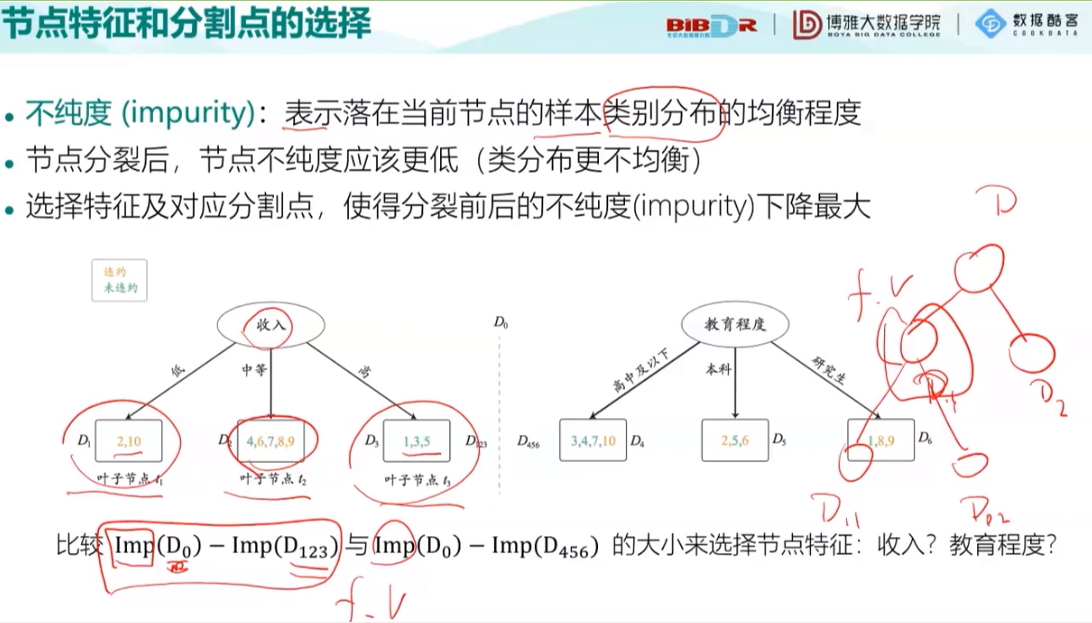
接下来就是节点不纯度的度量:分为三种方法:(后两种了解即可)
第一种Gini指数:
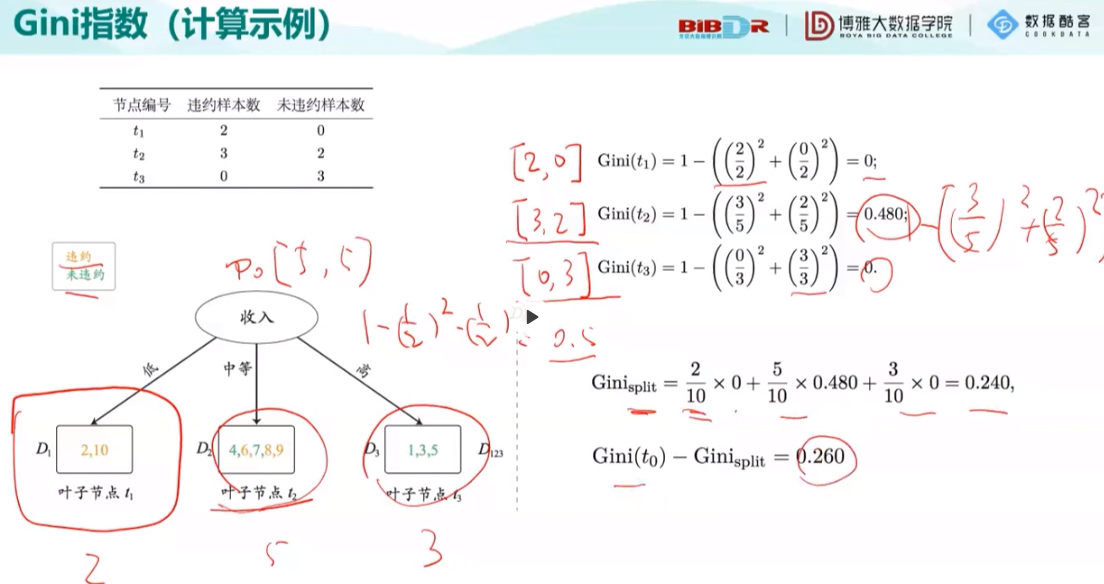
生成结果后还可以将下面能分的节点继续分解,继续求值,取最大值。
第二种信息熵:

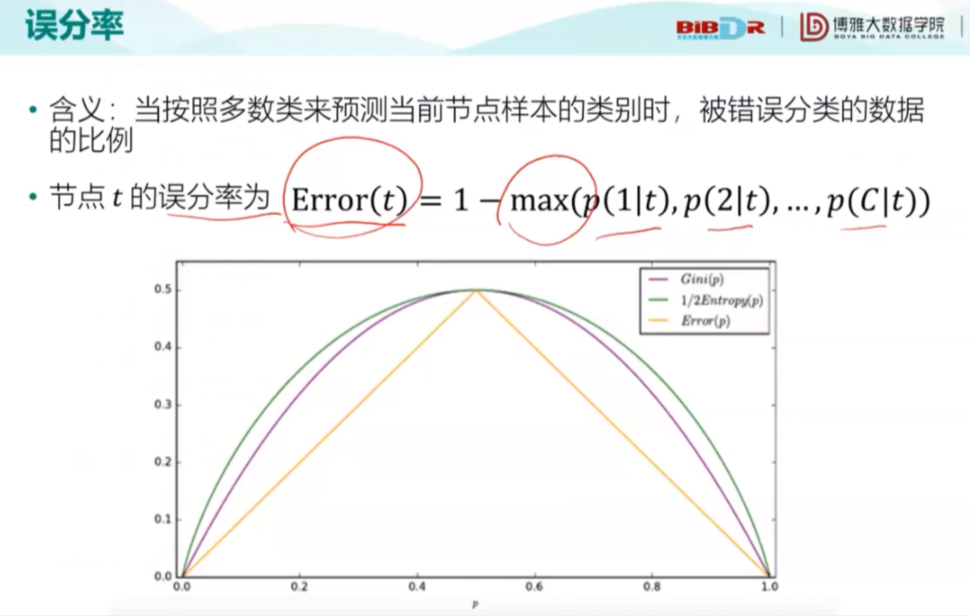
第三种误分率:
之后介绍了随机森林(这是第一种算法模型):

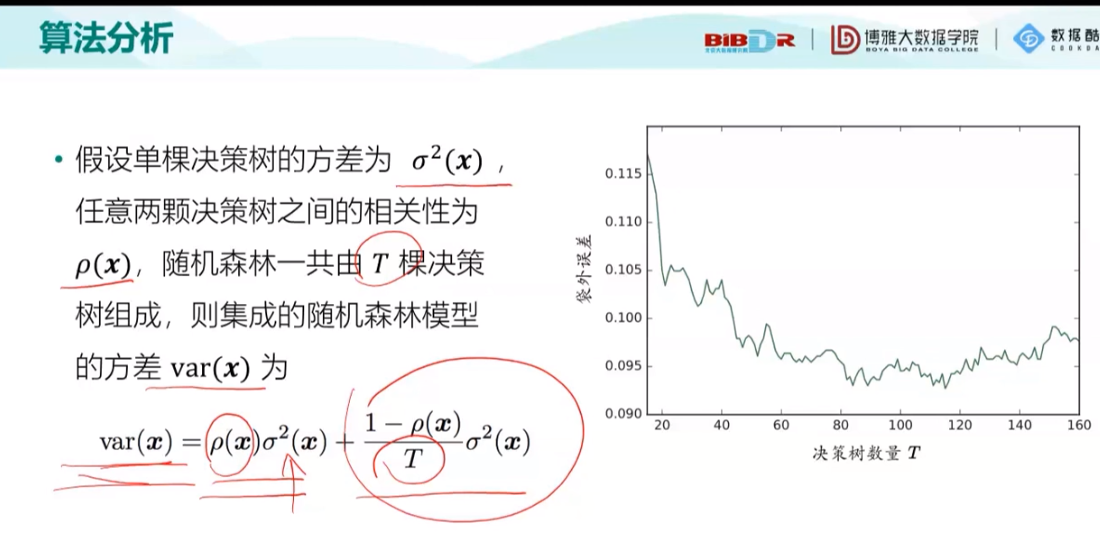
第二种模型:串型的训练

AdaBoost的训练误差:
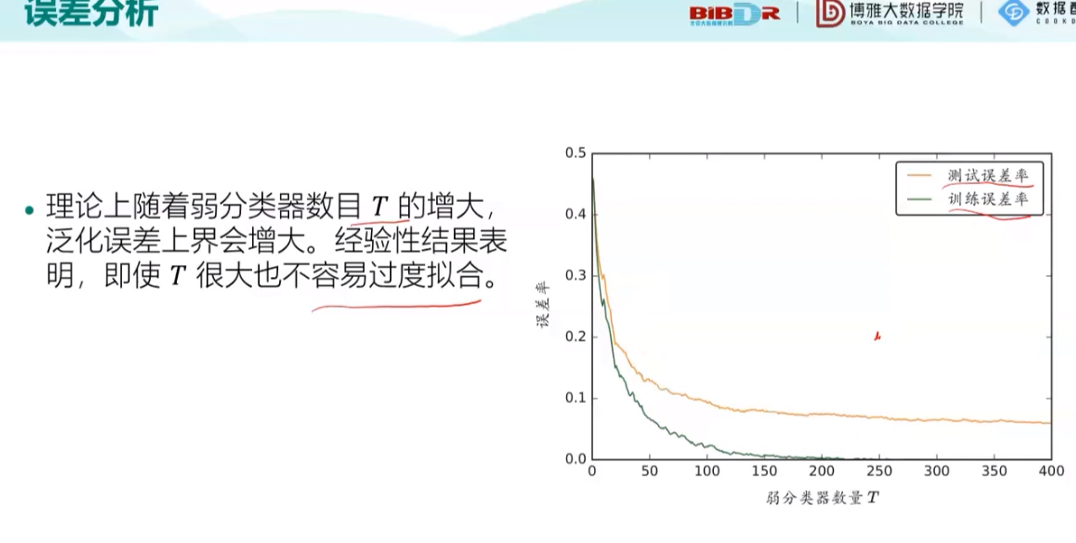
最后就是老师带领着去做了三个实验,以及一些资源的获取方式的介绍。


