

01_hugging_face
1.01_hugging_face
AI大模型
大模型
简单理解就是参数量比较多(10亿 (1B)以上)的AI模型
为什么是10亿 智能涌现 OpenAI 发现当参数量达到10亿以上,大模型的智能程度将达到指数级别的增长
AI模型
AI模型也称为人工神经网络,本质上就是做矩阵运算的
AI大模型分类
- 自然语义大模型:目前AI模型的核心技术
- 多模态大模型:除了文本以外,图片、视频、音频等
Hugging Face
简介
HuggingFace是一个提供先进自然语言处理(NLP)工具的平台,支持Transformer模型的开发和应用。它拥有庞大的模型库和社区资源,能够满足从研究到工业应用的各种需求。
安装
pip install transformers datasets tokenizers
使用
直接使用API调用
import requests MODEL_NAME = "uer/gpt2-chinese-cluecorpussmall" API_BASE_URL = "https://api-inference.huggingface.co/models/" API_TOKEN = "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" api_url = f"{API_BASE_URL}{MODEL_NAME}" headers = { "Authorization": f"Bearer {API_TOKEN}" } response = requests.post(api_url, headers=headers, json={"inputs": "你好,Hugging Face"}) print(response.json())
[{'generated_text': '你好,Hugging Face! 绝 对 超 级 无 聊 ( 优 酷 有 意 义 ) 本 文 为 广 告 信 息 , 拒 绝 商 用 ! 信 合 购 物 广 告 覆 盖 8000 + 人 ! ! 请 顺 序 点 下 小 编 个 人 微 信 号 : hlgb0722 , 请 不 要 分 享 到 微 信 朋 友 圈 ! 商 务 合 作 qq : 3436574072 / 902 / item. htm? spm = a244036729237bdpagetype1ssid0uid0puusm4002coa10500cdid0puusm4002coa13360eao1odid0puusm4002coa13360eao3if3juluyasao6seid0puusmstat0puusm4002coa127507e30f97703689234732100sae7isutmsredirect 吃 喝 玩 乐 全 在 这 里! 昨 日 黄 金 叶 星 人 体 验 团 , 勇 敢 的 原 创 老 外 换 壁 mix 同 款 鞋 ■ 女 性 更 好 美 鞋 ! 刘 晓 庆 都 开 淘 宝 店 智 能 vr 生 活 体 验 区 喷 漆 文 案 驿 马 一 场 春 ! 平 时 穿 的 高 跟 鞋 用 不 着 了 ! 【 内 部 组 织 与 选 址 】garden noworldhufu 商 场 就 在 光 谷 广 场 正 对 面 , 东 西 也 很 多 , 除 了 费 用 贵 , 光 谷 嘛 啥 也 做 得 起 atm 机 又 活 久 见 ! 有 cyberlake 高 手 帮 忙 ! 出 现 在 儿 童 乐 园 的 设 计 : 3 、 4 人 专 区 吧 ! 一 座 muji 风 格 的 家 居 大 楼 里 , 其 中 一 个 roomboard 广 告 时 间 为 28 天 ! 设 计 合 作 : 010 - 84625531 传 真 : 010 - 84625931 常 州 紫 天 阁 物 业 资 料 : 曹 育 华 微 信 号 : 13652785036 长 按 二 维 码 , 关 注 我 们 吧 ! 小 编 : liuyangmouswei 海 外 搜 罗 , 全 球 顶 级 沙 龙 小 编 拼 音 : shuhaihuanren @ 163. com 深 圳 生 活 惊 喜 , 惊 喜 刺 激 您 品 尝 福 彩 蓝 鲸 之 森 ! 满 满 荷 包 都 储 满 了 吗 ? 小 编 : 王 佳 2 小 时 店 租 400 元 包 邮 试 买 网 络 : www. kuauzzw. com 手 机 : 13652785036 qq : 1342351132 扫 一 扫 , 为 你 定 制 最 新 的 旅 行 攻 略 福 利 科 普 线 路 : 1 、 参 加 东 京 美 食 节 ( 金 田 潭 ) , 可 获 得 「 东 京 市 王 府 井 踏 青 团 体 券 」 : 「 最 美 日 剧 」 和 「 电 瓶 限 量 款 」 两 部 日 剧 作 品 ; 2 、 赴 日 留 学 生 用 订 制 旅 游 线 路 : 「 disney for card game 」 系 统 接 录 当 日 照 片 、 包 含 户 外 实 景 、 出 境 旅 游 日 程 的 照 片 ; 3 、 领 取 餐 券 免 费 参 观 东 京 艺 术 博 物 馆 、 karzakawa 免 税 店 , 东 京 【 影 视 基 地 】 carano din grilles 野 餐 室 、 无 酒 精 饮 料 最 佳 的 儿 童 餐 厅 、 自 助 烧 烤 和 烧 烤 晚 餐 ; 4 、 充 分 享 受 在 威 尼 斯 享 受 夜 生 活 、 参 观 圣 菲 尔 佛 大 教 堂 【 athensisfilm 】 ( 参 加 该 节 目 参 赛 前 , 请 登 录 秋 叶 原 旅 游 急 推 特 , 点 击 链 接 挑 选 精 品 小 店 , 即 可 免 费 获 得 秋 叶 原 - - - 伸 入 秋 叶 原 萤 火 虫 丛 中 的 秘 境 感 受 套 票 ) 以 上 就 是 正 在 忙 着 呢 的 各 位 溧 水 人 们 , 好 好 想 一 想 往 下 一 条 好 些 很 多 朋 友 没 有 吃 过 最 好 吃 的 猪 蹄 , 这 些 美 味 佳 肴 令 人 胃 口 大 开 , 时 间 久 了 也 容 易 饱 ! 没 有 一 点 晚 餐 要 吃 的 肉 , 这 一 切 就 像 一 场 绚 丽 的 大 餐 , 都 在 撑 得 慌 ▍ 柒 单 品 推 荐? 魔 力 杯 ( bangkokr ) ·? 屌 丝 雨 ( bangkokr ) ·?f 超 性 感 前 奏 ( 欢 乐 嗨 哒 ) · · 霸 屏 p 图 · · · 这 是 本 迪 士 尼 · · 花 自 驾 ( duang fan stop )'}]
本地运行
下载模型
from transformers import AutoModelForCausalLM, AutoTokenizer model_name = "uer/gpt2-chinese-cluecorpussmall" # 指定模型保存路径 cache_dir = f"./models/{model_name}" # 下载并加载模型和分词器到指定文件夹 model = AutoModelForCausalLM.from_pretrained(model_name, cache_dir=cache_dir) tokenizer = AutoTokenizer.from_pretrained(model_name, cache_dir=cache_dir)
很多模型都有分词器,需要一并下载
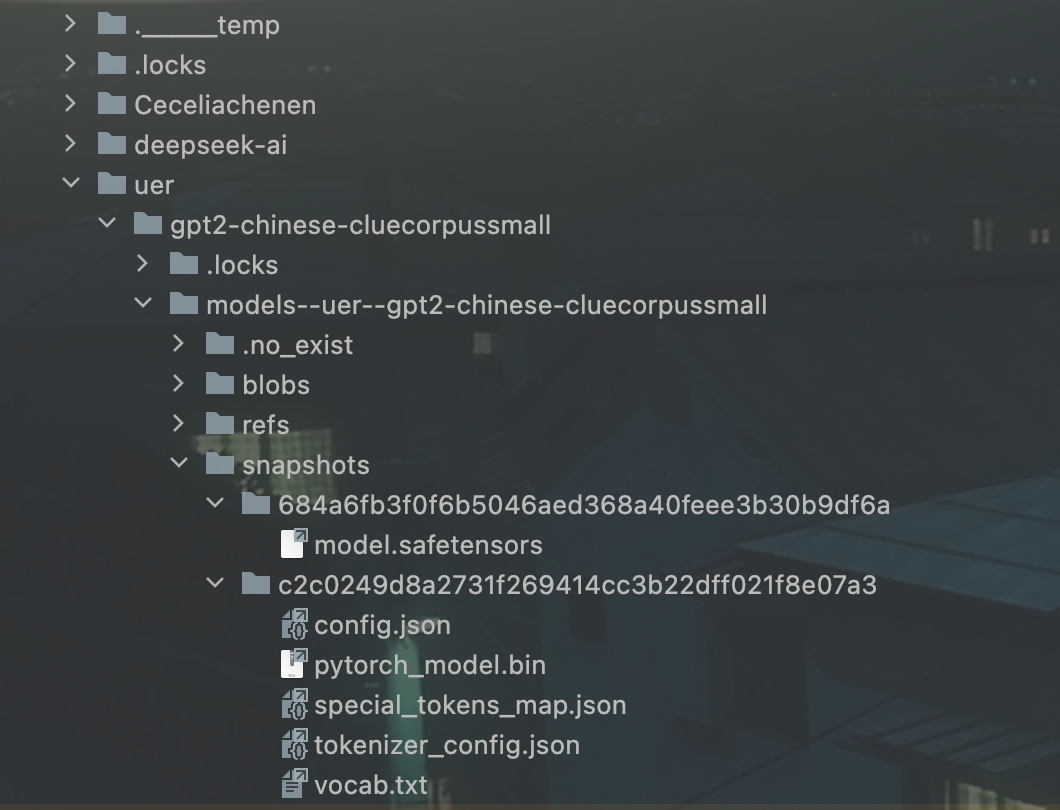
- .safetensors:大模型文件(hugging face格式)
- config.json;大模型配置文件
- .bin:大模型文件(transformers格式)
- tokenizer_config.json:分词器配置文件
- vocab.txt:字符集(大模型支持的字符),按照索引顺序存放,数量与配置文件
"vocab_size": 21128对应 - special_tokens_map.json:异常字符映射表
访问
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline model_dir = "./models/uer/gpt2-chinese-cluecorpussmall/models--uer--gpt2-chinese-" \ "cluecorpussmall/snapshots/c2c0249d8a2731f269414cc3b22dff021f8e07a3" model = AutoModelForCausalLM.from_pretrained(model_dir) tokenizer = AutoTokenizer.from_pretrained(model_dir) generator = pipeline("text-generation", model=model, tokenizer=tokenizer, device='cpu') output = generator("你好,我是一款语言模型,", max_length=50, num_return_sequences=1) print(output)
[{'generated_text': '你好,我是一款语言模型, 起 , 你 好 谢 谢! 我 想 让 我 们 的 语 言 模 型 有 更 多 人 喜 欢 用 , 当 然 , 是 很 广 泛 的 , 我 们'}]
语义分类模型
BERT(Bidirectional Encoder Representations from Transformers)
from transformers import BertTokenizer, BertForSequenceClassification, pipeline # 设置具体包含config.json的目录,只支持绝对路径 model_dir = r"./models/bert-base-chinese" # 加载模型和分词器 model = BertForSequenceClassification.from_pretrained("bert-base-chinese", cache_dir=model_dir) tokenizer = BertTokenizer.from_pretrained("bert-base-chinese", cache_dir=model_dir) # 创建分类pipline classifier = pipeline("text-classification", model=model, tokenizer=tokenizer, device="cpu") # 进行文本分类 result = classifier("你好,我是一款语言模型") print(result)
BertForSequenceClassification.from_pretrained("bert-base-chinese", cache_dir=model_dir)这种写法会先看本地是否已经下载,如果已经下载则使用本地,如果没有则从远程下载下来本地运行
模型结构查看
打印下模型的结构
print(model)
BertForSequenceClassification( (bert): BertModel( (embeddings): BertEmbeddings( (word_embeddings): Embedding(21128, 768, padding_idx=0) (position_embeddings): Embedding(512, 768) (token_type_embeddings): Embedding(2, 768) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) # 编码层(embeddings)文本 -> 模型可执行的词向量 (encoder): BertEncoder( (layer): ModuleList( (0-11): 12 x BertLayer( (attention): BertAttention( (self): BertSdpaSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (intermediate): BertIntermediate( (dense): Linear(in_features=768, out_features=3072, bias=True) (intermediate_act_fn): GELUActivation() ) (output): BertOutput( (dense): Linear(in_features=3072, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) ) ) # 编码层,特征提取,将向量代表的意思进行分析理解 词向量 -> 特征提取 (pooler): BertPooler( (dense): Linear(in_features=768, out_features=768, bias=True) (activation): Tanh() ) # 池化层,保持模型的适用性 ) (dropout): Dropout(p=0.1, inplace=False) # 防止模型过拟合 (classifier): Linear(in_features=768, out_features=2, bias=True) # 分类层bert模型真正干活的层 )



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· 因为Apifox不支持离线,我果断选择了Apipost!