爬取贝壳网上的租房信息
首先说一下文件用到的库:
-
time :提供了与时间相关的功能,如延时等。
-
random :提供了生成随机数的功能,如生成随机整数、随机选择等。
-
requests :用于发送 HTTP 请求,可以用来获取网页内容。
-
pandas :是一个数据处理和分析库,提供了高效的数据结构和数据分析工具,可以方便地对数据进行处理和分析。
-
BeautifulSoup :是一个用于解析 HTML 和 XML 文件的库,可以方便地提取其中的数据。
-
faker :用于生成虚假数据,例如生成虚假的姓名、地址、电子邮件等。 这些库在爬虫开发中非常常用。
time 和 random 可以用来控制爬虫的访问速度,避免对目标网站造成过大的负载。 requests 可以用来发送 HTTP 请求,获取网页内容。 pandas 可以用来处理和分析爬取到的数据。 BeautifulSoup 可以用来解析网页内容,提取其中的数据。 faker 可以用来生成虚假的数据,用于测试或模拟爬虫程序。
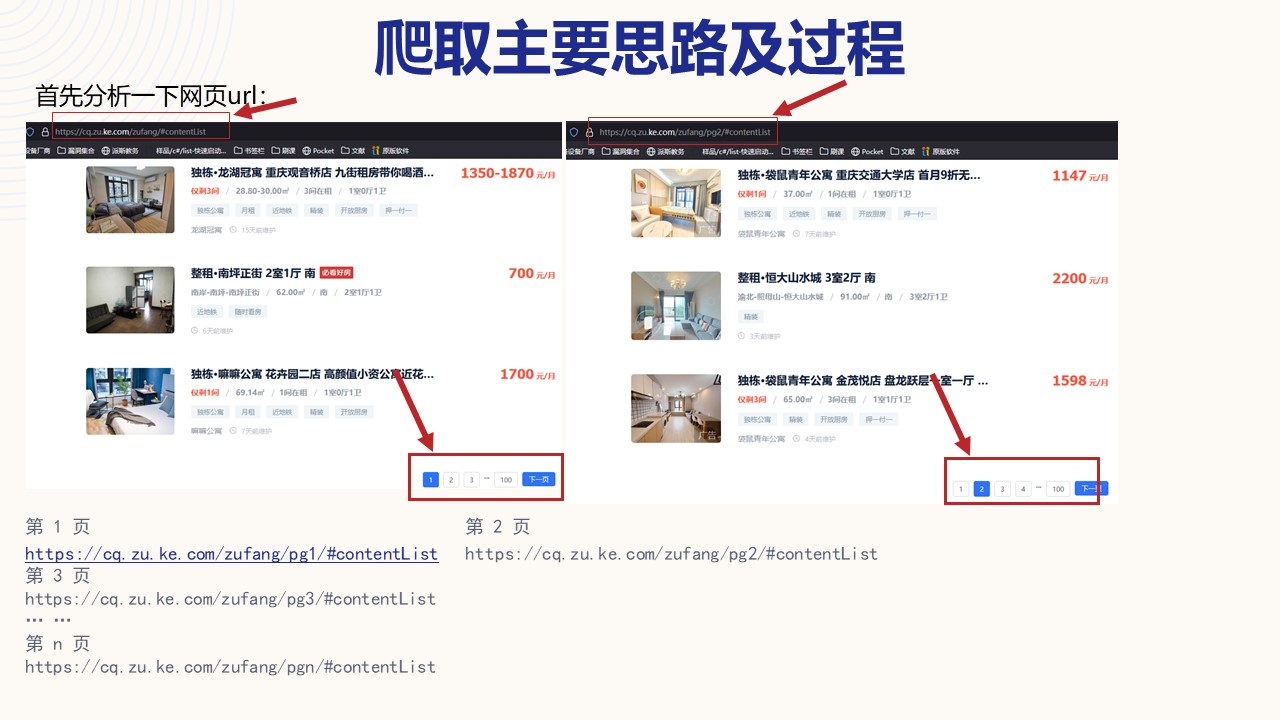
分析 “贝壳网站” 页面
第 1 页
https://cq.zu.ke.com/zufang/pg1/#contentList
第 2 页
https://cq.zu.ke.com/zufang/pg2/#contentList
第 3 页
https://cq.zu.ke.com/zufang/pg3/#contentList
… …
… …
第 n 页
https://cq.zu.ke.com/zufang/pgn/#contentList
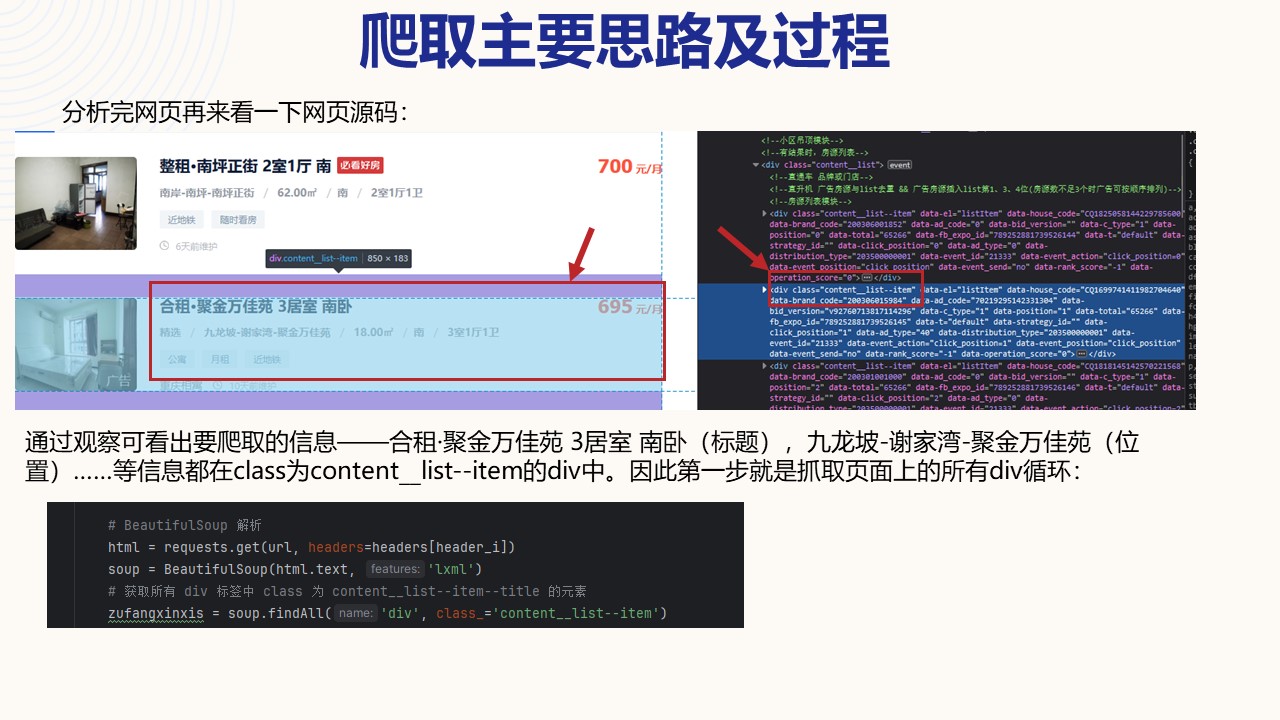
分析前端元素:
可发现目标在每个class为content__list--item的div中
首先获取此div:
zufangxinxis=soup.findAll('div', class_='content__list--item')这串代码就是找到页面上所有class为content_list--item的div
继续分析在此div下面还有个class为content__list--item--title的p标签,下一步就是找到此p标签下的名为twoline的a标签。
找到span标签
for xinxi in zufangxinxis:
# CSS 选择器
weizhi = soup.select("p[class='content__list--item--title'] a[class='twoline']")
jiage = soup.select("span[class='content__list--item-price']")
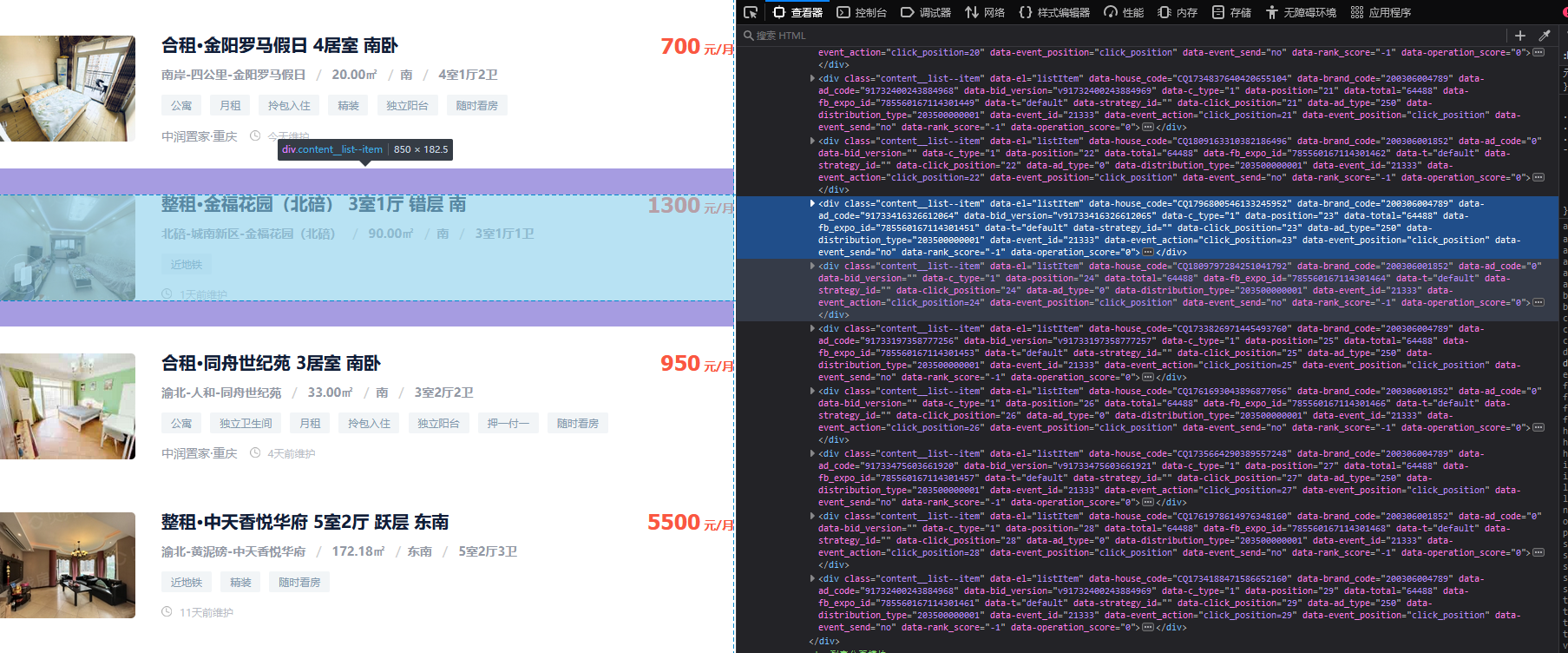

大家看图片吧。


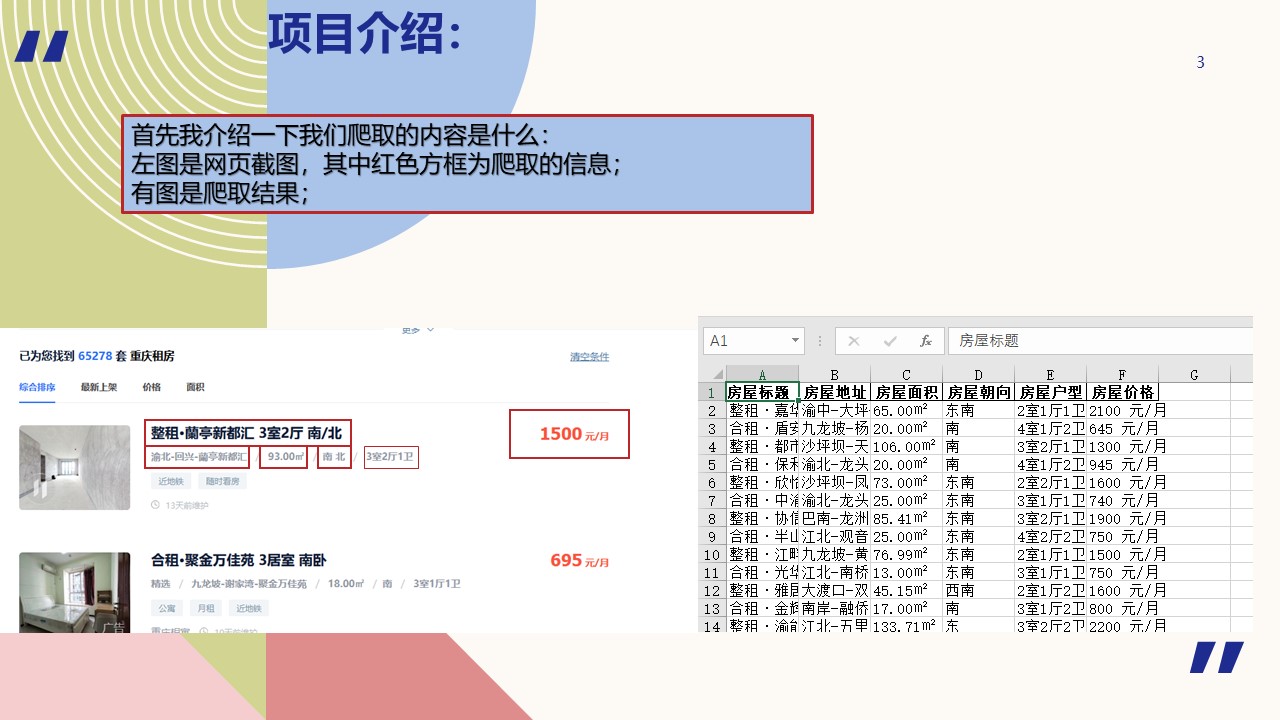



完整代码:
import time
import re
import random
import requests
import pandas as pd
from bs4 import BeautifulSoup
from faker import Factory
import datetime
def get_user_agent(num):
"""
生成不同的 user-agent
:param num: 生成个数
:return: list
"""
factory = Factory.create()
user_agent = []
for i in range(num):
user_agent.append({'User-Agent': factory.user_agent()})
return user_agent
def get_proxy(pages, ua_num):
#爬取数据,清洗整合
headers = get_user_agent(ua_num) # 请求头
proxy_list = [] # 最后需入库保存的房源数据
try:
for num in range(0, pages):
print('Start:第 %d 页请求' % (num + 1))
# 请求路径
url = 'https://cq.zu.ke.com/zufang/pg' + str(num + 1) + '/' + '#contentList'
# url = 'https://cq.zu.ke.com/zufang/pg1' +'/' + '#contentList'
# 随机延时(randint生成的随机数n: a <= n <= b ;random产生 0 到 1 之间的随机浮点数)
time.sleep(random.randint(1, 2) + random.random())
header_i = random.randint(0, len(headers) - 1) # 随机获取1个请求头
# BeautifulSoup 解析
html = requests.get(url, headers=headers[header_i])
soup = BeautifulSoup(html.text, 'lxml')
# 获取所有 div 标签中 class 为 content__list--item--title 的元素
zufangxinxis = soup.findAll('div', class_='content__list--item')
for xinxi in zufangxinxis:
# CSS 选择器
# 标题 位置 面积 朝向 户型 价格
biaoti = soup.select("p[class='content__list--item--title'] a[class='twoline']")
weizhi = soup.select("p[class='content__list--item--des']")
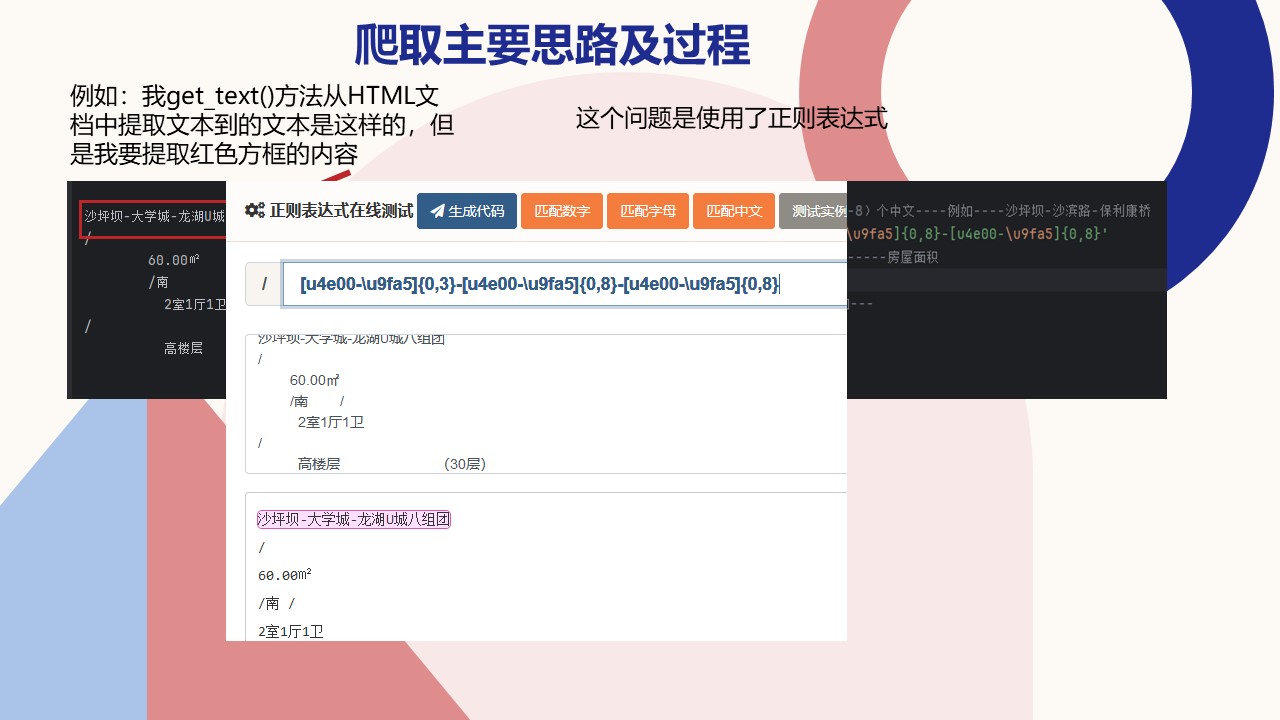
#正则表达式匹配(0-3)个中文-(0-8)个中文-(0-8)个中文----例如----沙坪坝-沙滨路-保利康桥
zz_weizhi = '[u4e00-\u9fa5]{0,3}-[u4e00-\u9fa5]{0,8}-[u4e00-\u9fa5]{0,8}'
mianji = soup.select("p[class='content__list--item--des']")
# 正则表达式匹配(0-3)个数字.(0-3)个数字㎡-------房屋面积
zz_mianji = '\\d{0,3}.\\d{0,3}㎡'
chaoxiang = soup.select("p[class='content__list--item--des']")
# 正则表达式匹配㎡/(0-2个中文)-------房屋朝向---
zz_changxiang = '㎡/[u4e00-\u9fa5]{0,2}'
huxing = soup.select("p[class='content__list--item--des']")
# 正则表达式匹配(数字)室(数字)厅(数字)卫
zz_huxing = '[0-9]室[0-9]厅[0-9]卫'
jiage = soup.select("span[class='content__list--item-price']")
for i1, i2, i3, i4, i5, i6 in zip(biaoti, weizhi, mianji, chaoxiang, huxing, jiage):
i_biaoti = str(i1.get_text())
i_biaoti = ''.join([i.strip(' ') for i in i_biaoti])
i_biaoti = str(i_biaoti)
i_weizhi = str(i2.get_text())
k_weizhi = re.findall(zz_weizhi, i_weizhi, re.I)
g_weizhi = str(k_weizhi)
g_weizhi = g_weizhi.replace("['", "").replace("']", "")
i_mianji = str(i3.get_text())
k_mianji = re.findall(zz_mianji, i_mianji, re.I)
g_mianji = str(k_mianji)
g_mianji = g_mianji.replace("['", "").replace("']", "")
i_chaoxiang = str(i4.get_text())
i_chaoxiang = ''.join([i.strip('\n') for i in i_chaoxiang])
i_chaoxiang = ''.join([i.strip(' ') for i in i_chaoxiang])
i_chaoxiang = str(i_chaoxiang)
k_chaoxiang = re.findall(zz_changxiang, i_chaoxiang, re.I)
g_chaoxiang = str(k_chaoxiang)
g_chaoxiang = g_chaoxiang.replace('㎡/', '')
g_chaoxiang = g_chaoxiang.replace("['", "").replace("']", "")
i_huxing = str(i5.get_text())
i_huxing = ''.join([i.strip('\n') for i in i_chaoxiang])
i_huxing = ''.join([i.strip(' ') for i in i_chaoxiang])
i_huxing = str(i_chaoxiang)
k_huxing = re.findall(zz_huxing, i_huxing, re.I)
g_huxing = str(k_huxing)
g_huxing = g_huxing.replace("['", "").replace("']", "")
i_jiege = str(i6.get_text())
proxy_list.append([i_biaoti,g_weizhi,g_mianji,g_chaoxiang,g_huxing,i_jiege])
#数据去重
proxy_list=pd.Series(proxy_list)
proxy_list=proxy_list.drop_duplicates()
proxy_list=list(proxy_list)
print('End:第 %d 页结束!==========================' % (num + 1))
except Exception as e:
print('程序 get_proxy 发生错误,Error:', e)
finally:
# 调用保存的方法
write_proxy(proxy_list)
return proxy_list
def write_proxy(proxy_list):
"""
将清洗好的列表数据,保存到xlsx文件
:param proxy_list: 房源信息数据列表
:return: bool
"""
aa = datetime.datetime.now().strftime('%m%d%H%M')
date_now ='租房信息表'+'-'+aa # 保存的文件名字
flag = True # 保存成功标志
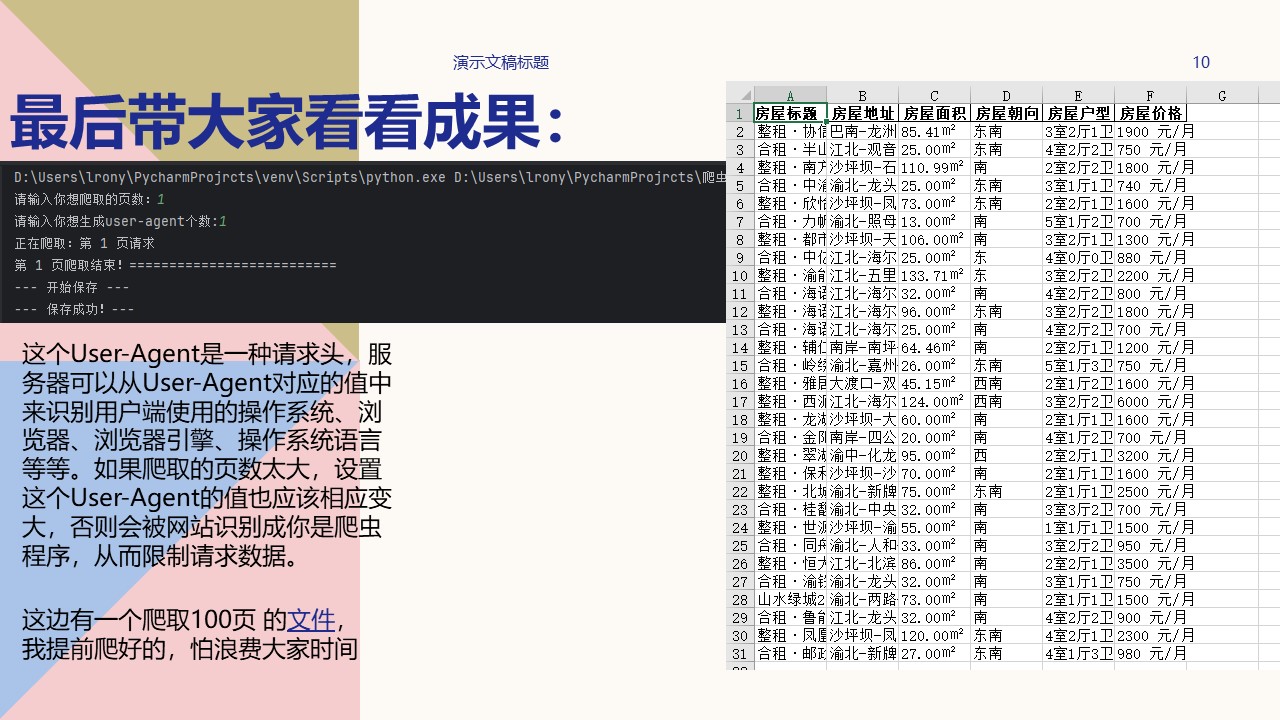
print('--- 开始保存 ---')
try:
df = pd.DataFrame(proxy_list,
columns=['房屋标题 ', '房屋地址', '房屋面积', '房屋朝向', '房屋户型', '房屋价格'])
df.to_excel(date_now + '.xlsx', index=False)
print('--- 保存成功!---')
except Exception as e:
print('--- 保存失败!---:', e)
flag = False
return flag
def main():
"""
主方法
"""
pa = input('请输入你想爬取的页数:')# 定义爬取页数
pages =int(pa)
ua = input('请输入你想生成user-agent个数:')# 定义需生成user-agent个数
ua_num = int(ua)
proxy_list = get_proxy(pages, ua_num)
print(proxy_list)
if __name__ == '__main__':
# 1.主方法
main()
作者:zhangxiaozhang001
出处:https://www.cnblogs.com/zhangxiaozhang001/p/17888735.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!