
web自动化测试-元素定位(四)
对浏览器的控制,通过webdriver对象
对网页内容(元素)的控制,通过webElement对象
元素定位,实际上就是通过webdriver,获取webElement的过程
selenium提供了8个定位策略
1.什么是元素
元素:由标签头 + 标签尾 + 标签头和标签尾包括的文本内容;
元素的信息就是指元素的标签名及元素的属性;
元素的层级结构就是指元素之间相互嵌套的层级结构;
元素定位最终就是通过元素的信息或者元素的层级结构来进行元素定位;
2.元素定位的意义
- 计算机没有智能到人的程度。
- 计算机不能像手动测试人员一样通过眼看,手操作鼠标点击,操作键盘输入
- 计算机通过一系列计数手段找到元素(按钮、输入框、模拟键盘等)
3.查看元素信息
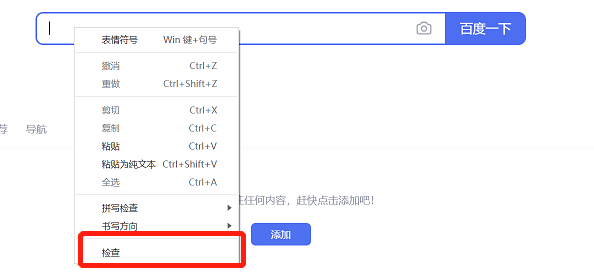
在谷歌浏览器中,选中元素,右键点击“检查”,即可在“Elements"中查看元素信息。
以百度首页搜索框为例,查看元素信息如下图所示:
4.元素定位的工具或手段有哪些?
selenium提供了8个定位策略
selenium 提供了一系列的对象定位方法,常用的有以下8种:
| 定位一个元素 | 定位多个元素 | 含义 |
|---|---|---|
| find_element_by_id | find_elements_by_id | 通过元素id定位 |
| find_element_by_name | find_elements_by_name | 通过元素name定位 |
| find_element_by_xpath | find_elements_by_xpath | 通过xpath表达式定位 |
| find_element_by_link_text | find_elements_by_link_text | 通过完整超链接定位 |
| find_element_by_partial_link_text | find_elements_by_partial_link_text | 通过部分链接定位 |
| find_element_by_tag_name | find_elements_by_tag_name | 通过标签定位 |
| find_element_by_class_name | find_elements_by_class_name | 通过类名进行定位 |
| find_element_by_css_selector | find_elements_by_css_selector | 通过css选择器进行定位 |
目前,由于selenium版本升级,使用find_element_by_*,会提示弃用警告,建议使用find_element()。
1.基于属性的定位
id
在HTML当中,id属性是唯一标识一个元素的属性,因此在selenium当中,通过id来进行元素的定位也作为首选。
百度搜索框的元素如图所示:

百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">元素定位:
element = web.find_element_by_id("kw") name
在HTML当中,name属性和id属性的功能基本相同,只是name属性并不是唯一的,如果遇到没有id标签的时候,我们可以考虑通过name标签来进行定位。
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">元素定位:
element = web.find_element_by_name("wd") class
我们也可以基于class属性来定位元素。通常当我们看到有多个并列的元素如list表单,class用的都是共用同一个。
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">元素定位:
element = web.find_element_by_class_name('s_ipt')注意:若class的值中有空格,则需要借助CSS Selector处理。
tag
HTML是通过tag来定义一类功能的,比如input是输入,table是表格,tbody是表格主体等。每个元素其实就是一个tag,由于一个tag用来定义一类功能,一个网页往往有很多同类tag,所以很难通过tag去区分不同的元素。
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">元素定位:
element = web.find_element_by_tag_name('input') 注意:由于百度首页有很多标签名字都是”input",因此上述代码只会定位到网页的第一个“input”标签。
2.基于文本的定位
link text
通过超链接的文本定位元素。link_text:只能定位链接。
百度上方超链接”新闻“元素如图所示:

百度上方超链接”新闻“元素元素html结构:
<a href="http://news.baidu.com" target="_blank" class="mnav c-font-normal c-color-t">新闻</a>元素定位:
element = web.find_element_by_link_text('新闻')partial link text定位
有时候一个超链接的文本很长,我们如果全部输入,既麻烦,又显得代码很不美观,这时候我们就可以只截取一部分字符串,进行模糊匹配。
百度上方超链接”新闻“元素html结构:
<a href="http://news.baidu.com" target="_blank" class="mnav c-font-normal c-color-t">新闻</a>元素定位:
element = web.find_element_by_partial_link_text('闻')
3.基于表达式的定位
通过copy里面的copy selector 这个选择器进行定位,这个就是css选择器
通过copy里面的copy xpath 这个来进行定位,这个就是xpath选择器
注意:
- xpath是文档查询语言,天生兼容HTML
- xpath很好根据文档的层级进行定位
- 支持灵活的语法和函数,完成定位
- css和xpath的层级要比id那些高一点
XPath定位
Xpath是一种在XML和HTML文档中查找信息的语言,通过Xpath路径来定位元素的时候也是分绝对路径和相对路径。
绝对路径
当我们想要描述某个地方时,我们常常用不同层次的节点名称串联起来,比如:你的收货地址是"江西省-南昌市-青山湖区-xx小区"。类似地,我们想要定位XML文档中某个节点时,也是这么层层递进。
绝对路径:表示页面元素在网页的HTML代码结构中,从根节点一层层地搜索到需要被定位的页面元素,绝对路径起始于正斜杠(/),每一步均被斜杠分割。
以百度搜索框元素为例,鼠标单机右键-Copy-Copy full XPath即可获取其XPath绝对路径。
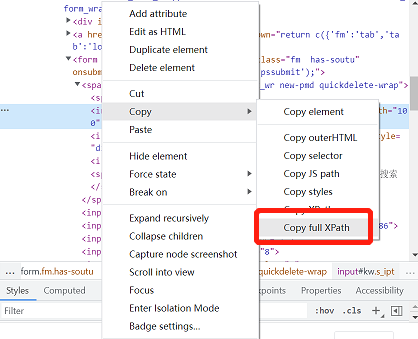
xpath定位表达式:
/html/body/div[1]/div[2]/div[5]/div[1]/div/form/span[1]/inputPython通过xpath定位语句:
element = web.find_element_by_xpath('/html/body/div[1]/div[2]/div[5]/div[1]/div/form/span[1]/input')上述xpath定位表达式从html dom树的根节点(html节点)开始逐层查找,最后定位到“input”节点。
特点:路径唯一,但是容易受页面改动影响,即便页面代码结构只发生了微小的变化,也可能会造成原先有效的xpath定位表达式定位失败。
相对路径
相对路径:从匹配选择的当前节点开始选择文档中的节点,而不考虑它们的位置,起始于双斜杠(//)。
以百度搜索框元素为例,鼠标单机右键-Copy-Copy XPath即可获取其XPath相对路径。
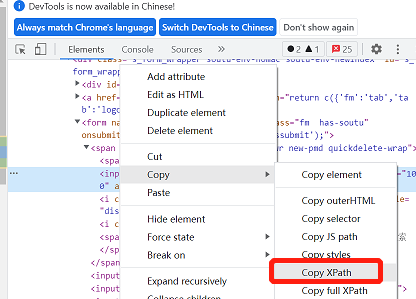
xpath定位表达式:
//*[@id="kw"]Python通过xpath定位语句:
element = web.find_element_by_xpath('//*[@id="kw"]')css selector定位
在Selenium官网当中是更加推荐Css Selector()方法来进行页面元素的定位的,Css定位可以通过id选择器、class选择器、标签选择器和属性选择器。
id选择器
通过 # 来定义,通过元素的id属性来定位
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">元素定位:
element = web.find_element_by_css_selector("#kw") class选择器
通过 .来定义,通过元素的class属性来定位
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">元素定位:
element = web.find_element_by_css_selector(".s_ipt") 标签选择器
通过标签的名字来定位元素
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">元素定位:
element = web.find_element_by_css_selector("input") 标签属性选择器
根据标签中的属性来定位元素, 格式: [属性名=”属性值”],或标签名[属性名=属性值]。如果属性是唯一的,那么标签名可以不用写。
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">元素定位:
element = web.find_element_by_css_selector('[id="kw"]')
element = web.find_element_by_css_selector('input[id="kw"]') 定位带空格的复合class属性
定位带空格的复合class属性一般采用css selector定位方法。
以百度上方栏目元素为例,其class属性带有空格。
class="s-top-left-new s-isindex-wrap"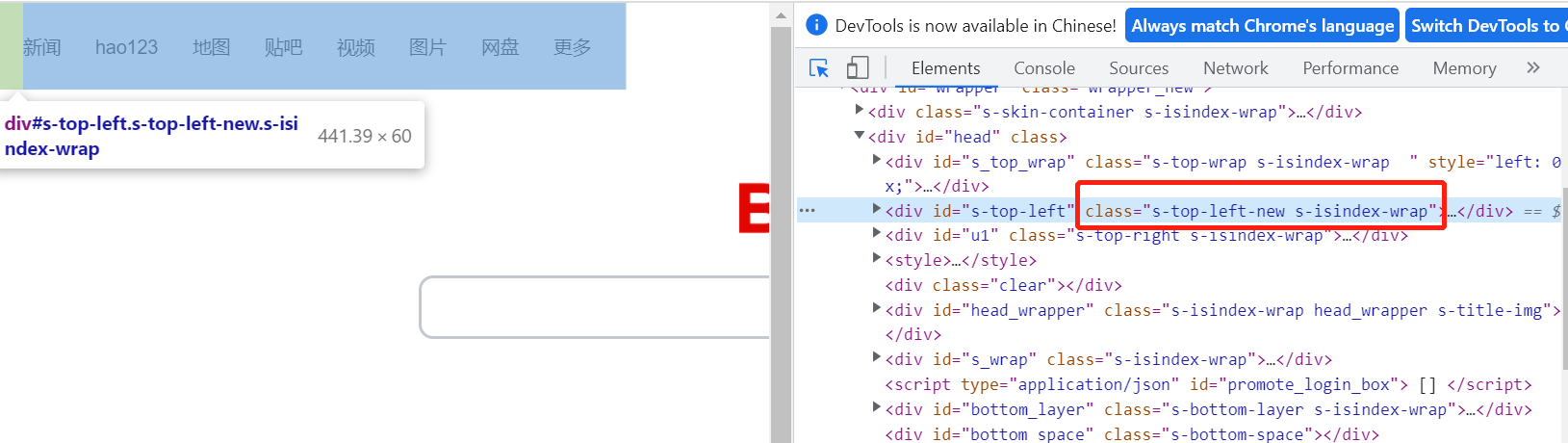
class属性带空格,如果直接通过class属性定位是会报错的,需要通过css selector按class属性定位。
element=web.find_element_by_class_name('s-top-left-new s-isindex-wrap')直接通过class属性定位是会报错的。
no such element: Unable to locate element: {"method":"css selector","selector":".s-top-left-new s-isindex-wrap"}
(Session info: chrome=99.0.4844.51)通过css selector按class属性定位,代码如下:
element=web.find_element_by_css_selector('[class="s-top-left-new s-isindex-wrap"]')直接在浏览器复制
css selector可以直接在浏览器中复制,鼠标单机右键-Copy-Copy selector即可获取。
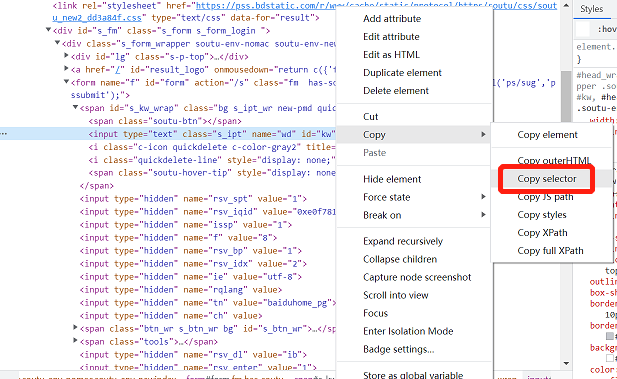
以上定位方式的区别:
共同点:只能通过一个属性定位
不同点:
1、find_element_by_id:通过id 定位元素
(1)id是唯一的,一般情况下id是给js用的
2、find_element_by_tag_name:通过标签名称定位元素
(1)标签名称不唯一
3、find_element_by_class_name:通过类名称定位元素(class')
(1)class 不唯一
(2)如果要通过class来定位,要确保你定位的这个元素class一定要唯一
4、find_element_by_name:通过元素name属性定位元素(需要元素有name属性)
(1)元素必须要有name属性
(2)name属性不一定唯一
5、find_element_by_link_text:a标签通过【精确匹配】超链接文本定位元素(超链接文本必须是唯一,不能有空格)
6、find_element_by_partial_link_text:a标签通过【模糊匹配】超链接文本定位元素(超链接文本必须是唯一)
可以通过多个属性组合定位
7、find_element_by_xpath:通过路径定位元素
(1)绝对路径定位【不用】
(2)相对路径定位【常用万能】4.定位方法的使用
定位方式选择
• 当页面元素有id属性时,尽量用id来定位;
• 当有链接需要定位时,可以考虑link text或partial link text方式;
• 当要定位一组元素相同元素时,可以考虑用tag name或class name;
• css selector定位速度比较快,效率高。
• 一般id>name>css>XPath
5.元素定位的另一种写法
除了上述的8种定位方法,Selenium还提供了一个通用的方法find_element()和find_elements(),这个方法有两个参数:定位方式和定位值。
使用的时候需要导入By模块
from selenium.webdriver.common.by import By以定位一个元素为例,两种定位方法写法差异如下:
| 定位元素 | find_element_by_* | find_element() |
| 通过元素id定位 | find_element_by_id(x) | find_element(By.ID,x) |
| 通过元素name定位 | find_element_by_name(x) | find_element(By.NAME,x) |
| 通过xpath表达式定位 | find_element_by_xpath(x) | find_element(By.XPATH,x) |
| 通过完整超链接定位 | find_element_by_link_text(x) | find_element(By.LINK_TEXT,x) |
| 通过部分链接定位 | find_element_by_partial_link_text(x) | find_element(By.PARTIAL_LINK_TEXT,x) |
| 通过标签定位 | find_element_by_tag_name(x) | find_element(By.TAG_NAME,x) |
| 通过类名进行定位 | find_element_by_class_name(x) | find_element(By.CLASS_NAME,x) |
| 通过css选择器进行定位 | find_element_by_css_selector(x) | find_element(By.CSS_SELECTOR,x) |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?