
Python高级应用程序设计任务
Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
爬取豆瓣图书Top250
2.主题式网络爬虫爬取的内容与数据特征分析
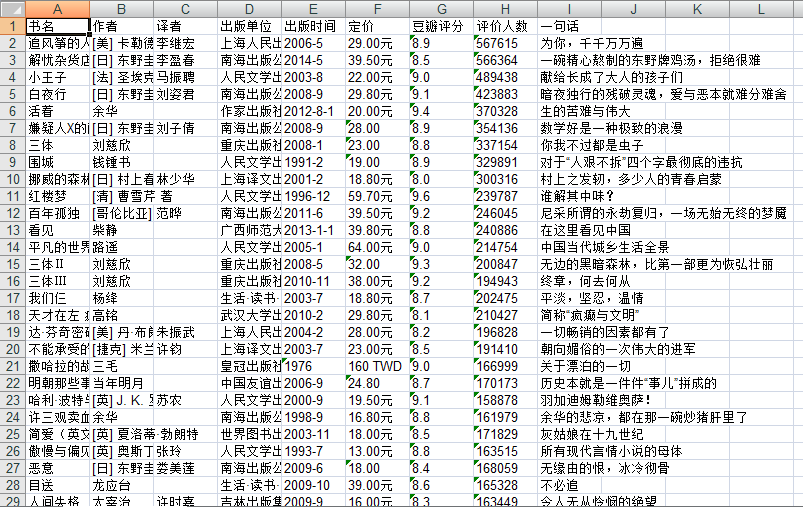
爬取的内容:获取书籍名称,作者,译者,出版单位,出版时间,定价,豆瓣评分,评价人数,书籍里的一句话
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:
(1)利用requests库中的get()进行网页请求,观察输出状态码
(2)使用etree进行网页解析
(3)使用循环实现翻页获取数据
(4)通过循环beautiful soup获取所需的每本图书的基础信息
(5)通过xlwt将数据保存到Excel中,以便于后面的数据清洗和数据分析
技术难点:
(1)在访问页面,进行请求时,要加User-Agent请求的头部信息
(2)在获取出版单位和出版时间等,没有灵活应用split进行分割
(3)之前输出文件为csv文件,后因出现乱码,改为输出xls文件
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
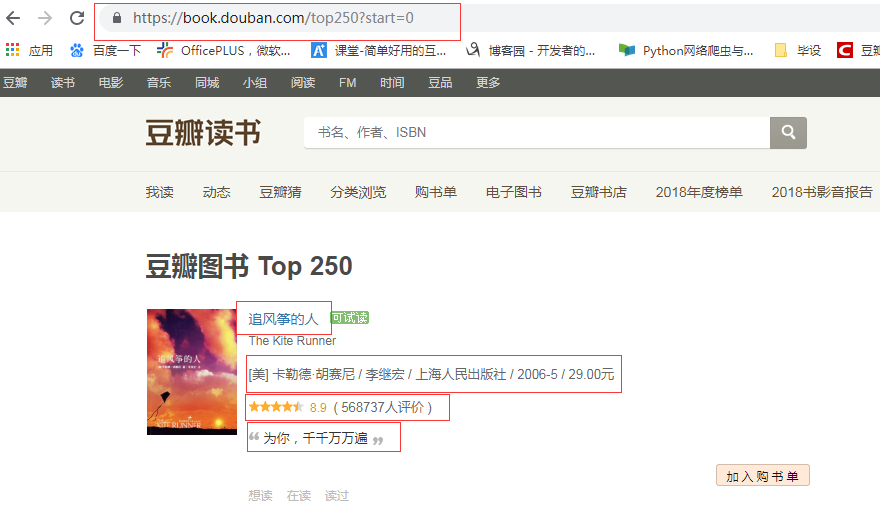
2.Htmls页面解析

3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
使用bs4库,正则表达式,观察页面代码中的标签上下节点。遍历方法使用for循环实现对标签的全部遍历,使用select和split获取所需的信息。
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
1 import re 2 import xlwt 3 import requests 4 from lxml import html 5 etree = html.etree 6 from bs4 import BeautifulSoup 7 from collections import namedtuple 8 9 #验证请求头部信息,获取HTML页面分析 10 def getHtml(url): 11 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'} 12 #获取页面数据 13 page = requests.get(url, headers=headers) 14 #解析网页 15 html = page.text 16 return html 17 18 #利用BeautifulSoup爬取网页内容 19 def get_book_info_bs4(): 20 #创建列表 21 Book_list = [] 22 # 利用正则表达式表示不转义 23 reg = re.compile(r'\d+') 24 #循环实现翻页,爬取250本图书所需的信息 25 urls = [f'https://book.douban.com/top250?start={page}' for page in range(0, 250, 25)] 26 for url in urls: 27 #html之间用get请求访问获取url中的值 28 html = getHtml(url) 29 #使用Beautiful_lxml解析 30 soup = BeautifulSoup(html, 'lxml') 31 # 在html中使用select标签,获取图书名 32 book_names = soup.select('td[valign="top"] ~ td[valign="top"]') 33 for book_name in book_names: 34 #定义一个namedtuple类型Book,并包含书名,作者,译者,出版单位,出版时间,定价,豆瓣评分,评价人数,一句话属性 35 Book = namedtuple('Book', '书名,作者,译者,出版单位,出版时间,定价,豆瓣评分,评价人数,一句话') 36 Book.书名 = book_name.select_one('div.pl2 > a').get('title') 37 #选择p.pl标签获取作者信息 38 author_info = book_name.select_one('p.pl').text 39 # 利用split实现切割功能,将作者提取出来 40 author_split = re.split('\s/+\s', author_info) 41 author_len = len(author_split) 42 # 利用split实现切割功能,将出版单位、出版时间、定价提取出来 43 Book.出版单位 = author_split[-3] 44 Book.出版时间 = author_split[-2] 45 Book.定价 = author_split[-1] 46 # 利用split实现切割功能,将作者提取出来 47 Book.作者 = author_split[0] if author_len > 3 else '' 48 Book.译者 = author_split[1] if author_len > 4 else '' 49 #选择span.rating_nums获取豆瓣评分标签 50 Book.豆瓣评分 = book_name.select_one('span.rating_nums').text 51 person = book_name.select_one('span.pl').text 52 Book.评价人数 = reg.search(person).group() 53 #选择span.inq获取图书一句话标签 54 one_sentence = book_name.select_one('span.inq') 55 Book.一句话 = one_sentence.text if one_sentence else '' 56 #将书本信息插入列表中 57 Book_list.append(Book) 58 return Book_list 59 60 #将爬取到存储到Excel中,注意输出格式 61 def write_info_xls(Book_list): 62 #创建一个workbook 63 Workbook = xlwt.Workbook() 64 #在workbook中新建一个名字为豆瓣图书Top250Excel文件 65 sheet = Workbook.add_sheet('豆瓣图书Top250') 66 infos = '书名,作者,译者,出版单位,出版时间,定价,豆瓣评分,评价人数,一句话'.split(',') 67 #定义输出格式,及放置在哪一行哪一列 68 for i in range(0, len(infos) + 0): 69 sheet.write(0, i, infos[i - 0]) 70 for i in range(1, len(Book_list) + 1): 71 sheet.write(i, 0, Book_list[i - 1].书名) 72 sheet.write(i, 1, Book_list[i - 1].作者) 73 sheet.write(i, 2, Book_list[i - 1].译者) 74 sheet.write(i, 3, Book_list[i - 1].出版单位) 75 sheet.write(i, 4, Book_list[i - 1].出版时间) 76 sheet.write(i, 5, Book_list[i - 1].定价) 77 sheet.write(i, 6, Book_list[i - 1].豆瓣评分) 78 sheet.write(i, 7, Book_list[i - 1].评价人数) 79 sheet.write(i, 8, Book_list[i - 1].一句话) 80 Workbook.save('豆瓣图书Top250.xls') 81 82 #主函数 83 if __name__ == '__main__': 84 Book_list = get_book_info_bs4() 85 write_info_xls(Book_list)
2.对数据进行清洗和处理
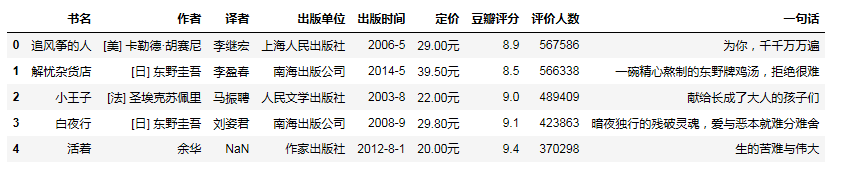
1 #输出爬取豆瓣图书数据文件的前5行 2 import pandas as pd 3 douban_book = pd.DataFrame(pd.read_excel(r'C:\Users\Administrator.PC-20180405YJVN\Desktop\douban_book.xls')) 4 douban_book.head()
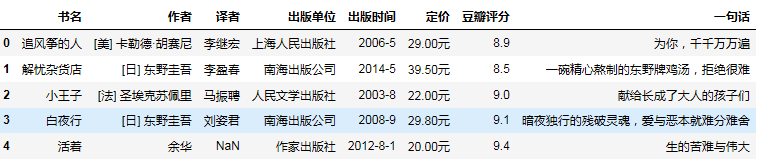
1 #删除无效列,即评价人数 2 douban_book.drop('评价人数',axis = 1,inplace = True) 3 douban_book.head()

1 #查找重复值 2 douban_book.duplicated()

1 #删除数据表中的重复值 2 douban_book = douban_book.drop_duplicates() 3 douban_book.head()
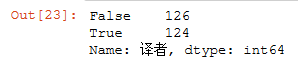
1 #对数据中译者一列的数据进行空值处理 2 douban_book['译者'].isnull().value_counts()
1 douban_book['译者'] = douban_book['译者'].fillna('无') 2 douban_book.head()
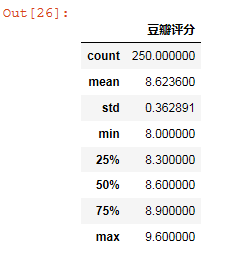
1 #异常值处理 2 douban_book.describe()
3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
1 #因之前列名是中文,后改为英文 2 import seaborn as sns 3 import pandas as pd 4 import matplotlib.pyplot as plt 5 import matplotlib 6 df = pd.read_excel(r'C:\Users\Administrator.PC-20180405YJVN\Desktop\douban_book.xls') 7 df.sample(5)
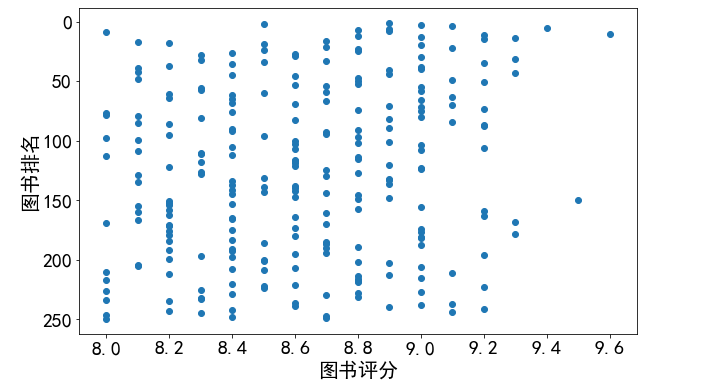
1 #查看排名和评分的关系 2 #配置中文字体和修改字体大小 3 matplotlib.rcParams['font.family'] = 'SimHei' 4 matplotlib.rcParams['font.size'] = 20 5 6 #显示大小,宽高 7 plt.figure(figsize=(10,6)) 8 plt.scatter(df['score'],df['rank']) 9 plt.xlabel('图书评分') 10 plt.ylabel('图书排名') 11 #修改y轴为倒叙 12 plt.gca().invert_yaxis() 13 14 plt.show()
1 #评分集中趋势的直方图 2 plt.hist(df['score'],bins=15) 3 plt.show()
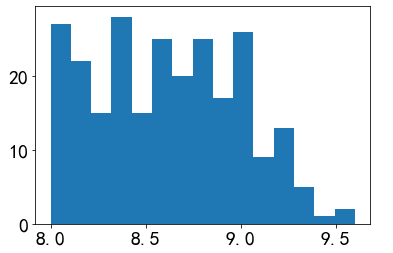
1 #年份集中趋势的直方图 2 plt.hist(df['time'],bins=15) 3 plt.show()
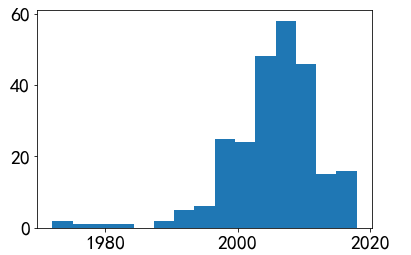
1 #时间和评分的散点分布图 2 sns.set(style="white") 3 sns.jointplot(x="time",y='score',data=df)
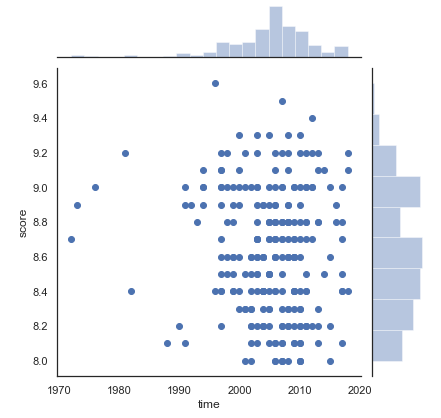
1 #评分和排名的盒图关系 2 sns.boxplot(x='score',y='rank',data=df)
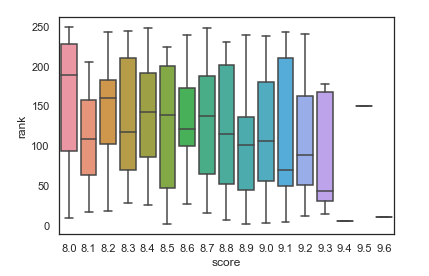
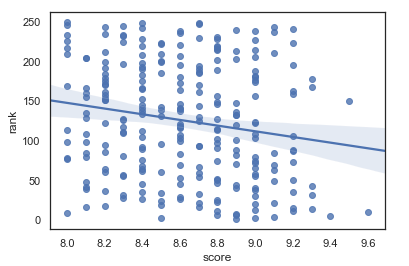
1 #根据排名和评分绘制回归图 2 sns.regplot(x='score',y='rank',data=df)
5.数据持久化
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
(1)豆瓣图书排名前250的评分主要集中在8.0 - 9.2之间
(2)豆瓣图书排名前250的出书时间大部分也是在1990 - 2018之间
(3)大部分情况下,排名越靠前的图书,评价人数越多
2.对本次程序设计任务完成的情况做一个简单的小结。
通过这次程序设计,我更了解python的爬虫功能,对requests库和BeautifulSoup库有初步的认识,对爬虫的过程也有了初步的了解。

