
第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业
4.提供图片或网站显示的学习进度,证明学习的过程。

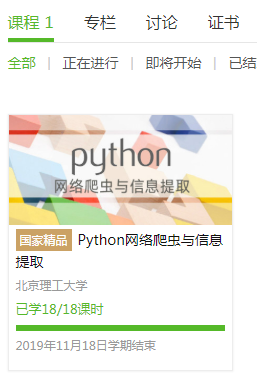
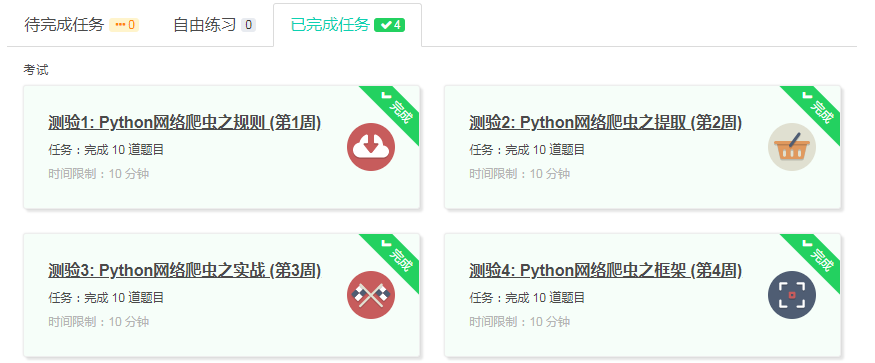
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
学习网络爬虫与信息提取的课程中,前四周分别从网络爬虫的四个方面进行学习,分别是网络爬虫规则,提取,实战和框架,下面我从四个方面记录我在学习中的体会和收获。
在第一周的课件“网络爬虫之规则”中,分别介绍了requests库,网络爬虫的弊端与解决方法,运用requests库的五个实例。网络爬虫很方便和高效的从HTML网页中提取信息,并且多线程,进程模块成熟稳定,提升整个系统和分析能力。但是,网络爬虫也存在一定的弊端,首先,受限于编写水平和目的,网络爬虫将会为web服务器带来巨大的资源开销;其次,网络爬虫的法律风险;最后,网络爬虫泄露隐私,但总体来说,利仍大于弊。在最后老师提出的五个实例中,其中,从亚马逊抓取一个商品信息的实例中,很好的体现了requests库的应用。
在第二周的课件“网络爬虫的提取”中,先是详细的介绍了Beautiful Soup库,然后再介绍信息标记的三种方法,最后介绍信息提取的方法,并给出实例。三种信息标记分别是:一、XML,Internet上的应用信息交互与传递;二、JSON,移动应用云端和节点的信息通信,无法注释;三、YAML,各类系统的配置文件,有注释易读。信息提取的一般方法:一、完整解析信息的标记形式,再提取关键信息;二、无视标记形式,直接搜索关键信息;三、融合方法,结合形式解析与搜索方法,提取关键信息。最后实例中采用requests-bs4路线实现中国大学排名定向爬虫。
在第三周的课件“网络爬虫之实战”中,首先对正则表达式进行了详解,在之前的学习中,我一直对正则表达式这一知识点很困惑,通过这次的学习,让我对这个知识点理解的更透彻。在老师讲解的课程中,让我对正则表达式也有了新的认识,利用正则表达式和re库的结合提取页面的关键信息,并把此应用到淘宝商品的实例中。在股票数据定向爬虫中,采用requests-bs4-re路线实现了股票信息爬取和存储,实现了展示爬取进程的动态滚动条。
在第四周的课件“网络爬虫之框架”中,主要讲解了Scrapy爬虫框架。与requests库相比较,Scrapy是网站级爬虫,并且是一个框架,并发性好,性能较高,requests重点在页面下载,而Scrapy重点在于爬虫结构,一般定制灵活,深度定制困难。完整配置并实现Scrapy爬虫的主要过程:1.建立工程和Spider模板;2.编写Spider;3.编写Pipeline:处理spider提取信息的后续的功能;4.配置优化:使得爬虫运行的更好。并着重详述了yield关键字的使用,使用yield可以更节省存储空间,响应更加迅速,使用更加灵活。
通过这次的网络课程学习,更加清楚的认识到网络爬虫,以前只是听说有这样的技术,一直没有付诸行动。通过这次的网络课程学习,课程中的实例让我更直观发现自己的错误,自己的不足。

