
第2次作业-titanic数据集练习
一、读入titanic.xlsx文件,按照教材示例步骤,完成数据清洗。
titanic数据集包含11个特征,分别是:
Survived:0代表死亡,1代表存活
Pclass:乘客所持票类,有三种值(1,2,3)
Name:乘客姓名
Sex:乘客性别
Age:乘客年龄(有缺失)
SibSp:乘客兄弟姐妹/配偶的个数(整数值)
Parch:乘客父母/孩子的个数(整数值)
Ticket:票号(字符串)
Fare:乘客所持票的价格(浮点数,0-500不等)
Cabin:乘客所在船舱(有缺失)
Embark:乘客登船港口:S、C、Q(有缺失)
1 import pandas as pd 2 titanic = pd.DataFrame(pd.read_excel(r'C:\Users\Administrator.PC-20180405YJVN\Desktop\titanic.xlsx')) 3 titanic.head()

1 #删除无效行与列 2 titanic.drop('embark_town',axis=1,inplace=True) 3 titanic.head()
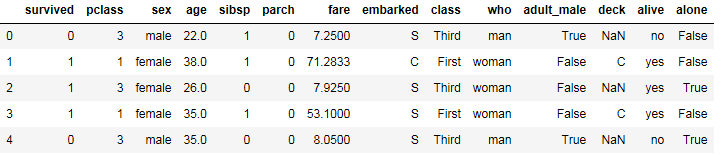
1 #查找重复值 2 titanic.duplicated()
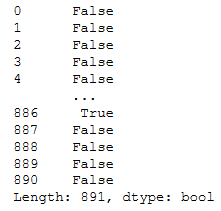
1 #重复值处理 2 titanic = titanic.drop_duplicates() 3 titanic.head()
1 #统计空值的个数 2 titanic['who'].isnull().value_counts()

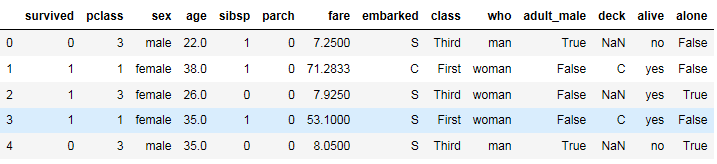
1 #使用fillna方法为“who”字段的空值填充数据“man” 2 titanic['who']=titanic['who'].fillna('man') 3 titanic.head()
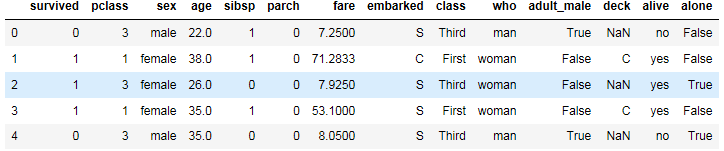
1 #对于数据表中“age”字段的空值,为其填充平均值 2 titanic['age']=titanic['age'].fillna(titanic['age'].mean()) 3 titanic.head()
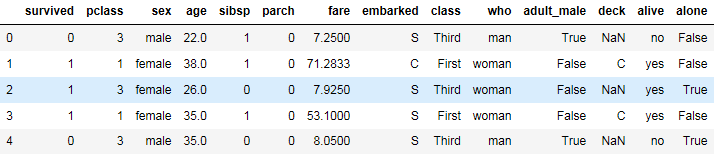
1 #判断是否存在异常值 2 titanic.describe()

1 #将异常值替换为平均值 2 titanic.replace([512.329200],titanic['fare'].mean()) 3 titanic.head()
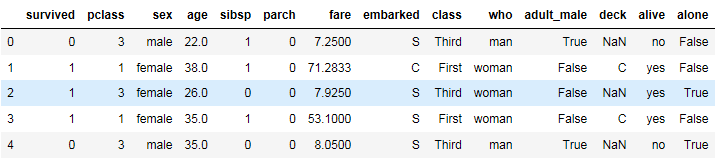
二、对titanic数据集完成以下统计操作
1.统计乘客死亡和存活人数
1 titanic['survived'].value_counts()

2.统计乘客中男女性别人数
1 titanic['sex'].value_counts()

3.统计男女获救的人数
1 survive = titanic['sex'][titanic['survived']==1].value_counts() 2 print(survive)

4.统计乘客所在的船舱等级的人数
1 titanic['pclass'].value_counts()

5.使用corr()函数,判断两个属性是否具有相关性,分析舱位的高低和存活率的关系
1 titanic['pclass'].corr(titanic['survived'])
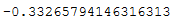
分析:根据数据可得,这是负相关,即舱位越高,存活率越高,反之亦然。
6.画出乘客票价与舱位等级的箱体图Boxplot,从图中能够得到哪些结论?
1 titanic.boxplot(['fare'],['pclass'])
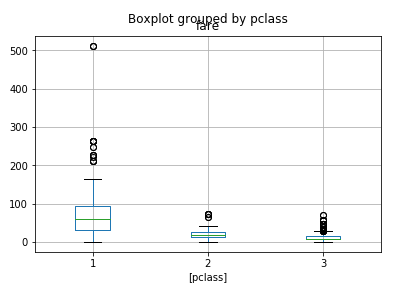
结论:舱位越高,价格越贵,存活率越高,反之亦然。

