

一个简单的多线程Python爬虫
最近想要抓取拉勾网的数据,最开始是使用Scrapy的,但是遇到了下面两个问题:
- 前端页面是用JS模板引擎生成的
- 接口主要是用POST提交参数的
目前不会处理使用JS模板引擎生成的HTML页面,用POST的提交参数的话,接口统一,也没有必要使用Scrapy,所以就萌生了自己写一个简单的Python爬虫的想法。
本文中的部分链接可能需要FQ。
参考资料:
- http://www.ibm.com/developerworks/aix/library/au-threadingpython/
- http://stackoverflow.com/questions/10525185/python-threading-how-do-i-lock-a-thread
一个爬虫的简单框架
一个简单的爬虫框架,主要就是处理网络请求,Scrapy使用的是Twisted(一个事件驱动网络框架,以非阻塞的方式对网络I/O进行异步处理),这里不使用异步处理,等以后再研究这个框架。如果使用的是Python3.4及其以上版本,到可以使用asyncio这个标准库。
这个简单的爬虫使用多线程来处理网络请求,使用线程来处理URL队列中的url,然后将url返回的结果保存在另一个队列中,其它线程在读取这个队列中的数据,然后写到文件中去。
该爬虫主要用下面几个部分组成。
1 URL队列和结果队列
将将要爬去的url放在一个队列中,这里使用标准库Queue。访问url后的结果保存在结果队列中
初始化一个URL队列
from Queue import Queue
urls_queue = Queue()
out_queue = Queue()2 请求线程
使用多个线程,不停的取URL队列中的url,并进行处理:
import threading
class ThreadCrawl(threading.Thread):
def __init__(self, queue, out_queue):
threading.Thread.__init__(self)
self.queue = queue
self.out_queue = out_queue
def run(self):
while True:
item = self.queue.get()
self.queue.task_down()下面是部分标准库Queue的使用方法:
Queue.get([block[, timeout]])
Remove and return an item from the queue. If optional args block is true and timeout is None (the default), block if necessary until an item is available.
Queue.task_done()
Indicate that a formerly enqueued task is complete. Used by queue consumer threads. For each get() used to fetch a task, a subsequent call to task_done() tells the queue that the processing on the task is complete.
如果队列为空,线程就会被阻塞,直到队列不为空。处理队列中的一条数据后,就需要通知队列已经处理完该条数据。
处理线程
处理结果队列中的数据,并保存到文件中。如果使用多个线程的话,必须要给文件加上锁。
lock = threading.Lock()
f = codecs.open('out.txt', 'w', 'utf8')当线程需要写入文件的时候,可以这样处理:
with lock:
f.write(something)程序的执行结果
运行状态: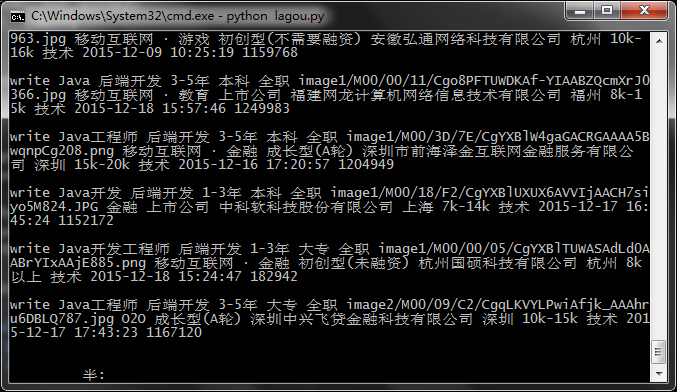
抓取结果: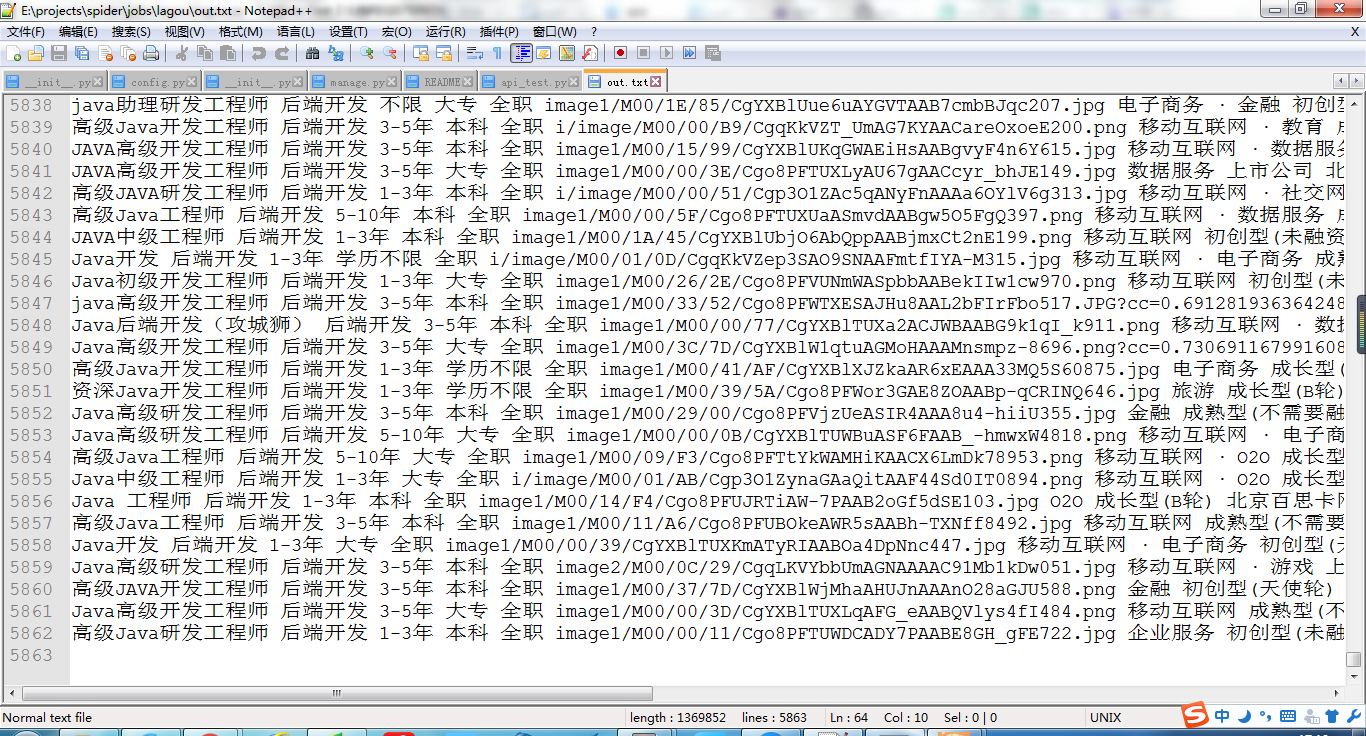
源码
代码还不完善,将会持续修改中。
# coding: utf-8
'''
Author mr_zys
Email myzysv5@sina.com
'''
from Queue import Queue
import threading
import urllib2
import time
import json
import codecs
from bs4 import BeautifulSoup
urls_queue = Queue()
data_queue = Queue()
lock = threading.Lock()
f = codecs.open('out.txt', 'w', 'utf8')
class ThreadUrl(threading.Thread):
def __init__(self, queue):
threading.Thread.__init__(self)
self.queue = queue
def run(self):
pass
class ThreadCrawl(threading.Thread):
def __init__(self, url, queue, out_queue):
threading.Thread.__init__(self)
self.url = url
self.queue = queue
self.out_queue = out_queue
def run(self):
while True:
item = self.queue.get()
data = self._data_post(item)
try:
req = urllib2.Request(url=self.url, data=data)
res = urllib2.urlopen(req)
except urllib2.HTTPError, e:
raise e.reason
py_data = json.loads(res.read())
res.close()
item['first'] = 'false'
item['pn'] = item['pn'] + 1
success = py_data['success']
if success:
print 'Get success...'
else:
print 'Get fail....'
print 'pn is : %s' % item['pn']
result = py_data['content']['result']
if len(result) != 0:
self.queue.put(item)
print 'now queue size is: %d' % self.queue.qsize()
self.out_queue.put(py_data['content']['result'])
self.queue.task_done()
def _data_post(self, item):
pn = item['pn']
first = 'false'
if pn == 1:
first = 'true'
return 'first=' + first + '&pn=' + str(pn) + '&kd=' + item['kd']
def _item_queue(self):
pass
class ThreadWrite(threading.Thread):
def __init__(self, queue, lock, f):
threading.Thread.__init__(self)
self.queue = queue
self.lock = lock
self.f = f
def run(self):
while True:
item = self.queue.get()
self._parse_data(item)
self.queue.task_done()
def _parse_data(self, item):
for i in item:
l = self._item_to_str(i)
with self.lock:
print 'write %s' % l
self.f.write(l)
def _item_to_str(self, item):
positionName = item['positionName']
positionType = item['positionType']
workYear = item['workYear']
education = item['education']
jobNature = item['jobNature']
companyName = item['companyName']
companyLogo = item['companyLogo']
industryField = item['industryField']
financeStage = item['financeStage']
companyShortName = item['companyShortName']
city = item['city']
salary = item['salary']
positionFirstType = item['positionFirstType']
createTime = item['createTime']
positionId = item['positionId']
return positionName + ' ' + positionType + ' ' + workYear + ' ' + education + ' ' + \
jobNature + ' ' + companyLogo + ' ' + industryField + ' ' + financeStage + ' ' + \
companyShortName + ' ' + city + ' ' + salary + ' ' + positionFirstType + ' ' + \
createTime + ' ' + str(positionId) + '\n'
def main():
for i in range(4):
t = ThreadCrawl(
'http://www.lagou.com/jobs/positionAjax.json', urls_queue, data_queue)
t.setDaemon(True)
t.start()
datas = [
{'first': 'true', 'pn': 1, 'kd': 'Java'}
#{'first': 'true', 'pn': 1, 'kd': 'Python'}
]
for d in datas:
urls_queue.put(d)
for i in range(4):
t = ThreadWrite(data_queue, lock, f)
t.setDaemon(True)
t.start()
urls_queue.join()
data_queue.join()
with lock:
f.close()
print 'data_queue siez: %d' % data_queue.qsize()
main()
总结
主要是熟悉使用Python的多线程编程,以及一些标准库的使用Queue、threading。

