
ElasticSearch VS Solr
最近公司用到了ES搜索引擎,调研发现大公司常用的搜索引擎还有Solr。
鉴于 Lucene 强大的特性和稳定性,有很多种基于 Lucene 封装的企业级搜索平台。其中最流行有两个:Apache Solr 和 Elastic search。
Apache Solr:它本身是 Apache Lucene 项目下的开源企业搜索平台,算是 Lucene 的直系。美团、阿里搜索服务是基于 Solr 来搭建的。
Elastic Search:简称 ES,由 Elastic 公司开发。Elastic 成立于 2012 年,总部在阿姆斯特丹,不久前 Google 宣布与 Elastic 达成战略合作协议,为谷歌云提供新的搜索以及相关分析服务。 最近几年,ES 变得越来越普及,StackOverflow、Github、百度等都在使用。
一:数据源
Solr 支持添加多种格式的索引,比如:HTML、PDF、微软 Office 系列软件格式以及 JSON、XML、CSV 等文件格式,还支持 DB 数据源。而 Elastic Search 仅支持 JSON 数据源。
二:高并发的实时搜索
基于 Solr 和 ES 都有成熟高可用架构设计。高并发的实时搜索两者都没有太大问题。但是 Elastic Search 读写并发性能更优于 Solr。
需要注意的是,搜索引擎不推荐像 DB 一样做类似 like 的通配符查询,这样会导致性大大降低。之前线上有一个 ES 搜索集群,一段时间 8 核 CPU 的 load 飚到了 10 以上,后来排查,原来是用到了 wildcard query(通配符查询),出现了大量的慢查询,导致服务变得不可用。下面我具体介绍下。
当时的查询条件:
}},{"range":{"saleTime":{"from":"20170514000000000","to":"20170515000000000","include_lower":true,"include_upper":false}}},{"match":{"terminalNumber":{"query":"99996DEE5CB2","type":"boolean"}}}]}}}
监控每天 1min load、5 min load、15min load 统计情况:
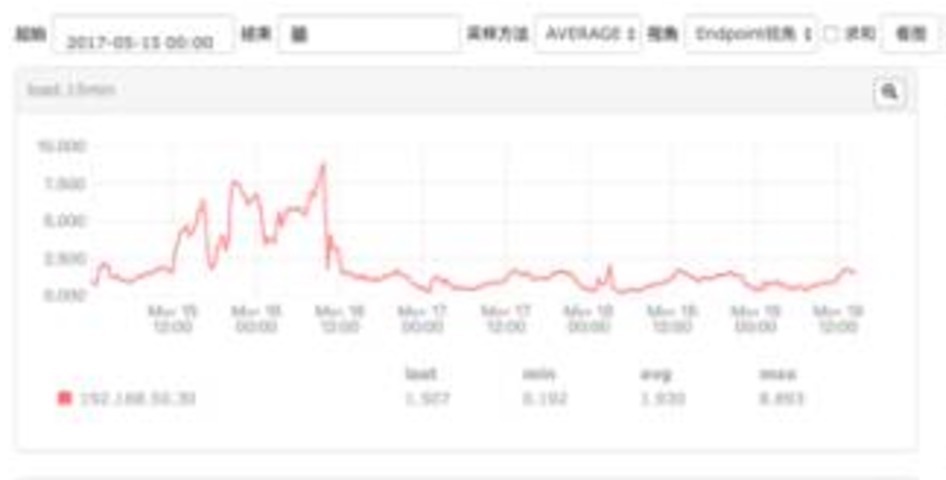
非常明显看出来,当我们去掉通配符(改用普通全匹配查询)后,load 立马降下来。可见通配符查询都 CPU 性能影响很大。而且,如果首尾通配符中间输入的字符串越长。 对应的 wildcard Query 执行更慢。性能越差。
这是什么原因呢?
在 Lucene 4.0 开始,为了加速通配符和正则表达式的匹配速度,将输入的字符串模式构建成一个 DFA (Deterministic Finite Automaton),带有通配符的 pattern 构造出来的 DFA 可能会很复杂,开销很大。具体原理可以了解下 DFA。
wildcard query 应杜绝使用通配符打头,改变实现方式:使用更廉价的 term query 来实现同等的模糊搜索功能。或者获取一个大的结果集,在内存里面匹配。
三:易用性
Solr 分布式基于 ZooKeeper,而 ES 自带分布式管理。两者在分布式管理和部署都比较成熟。
四:扩展性
Elastic 公司除了开发 ES 以外, 还基于此,开发了 Kinbana(针对 Elasticsearch 的开源分析及可视化平台,用来搜索、查看 Elasticsearch 索引中的数据)、Logstash(开源的具有实时输入数据能力的数据收集引擎, 主要方便分布式系统收集汇总日志) 等一整套服务产品。
目前,Kinbana、Logstash 在很多公司被使用。基于 Elastic + LogStash + Kinbana 的 ELK 框架成为了一种流行的分布式日志收集监控技术方案。
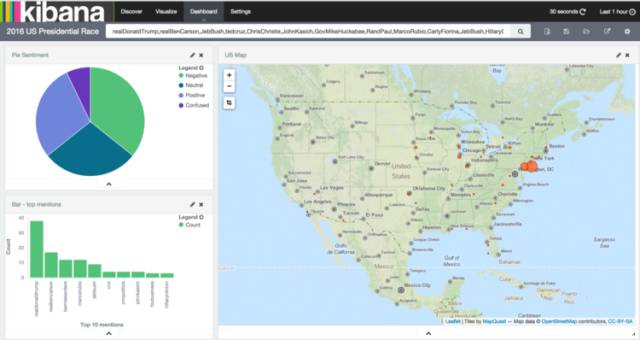
Solr 自带了管理索引的 Web 控制台,只专注在企业级搜索引擎。

