
Web开发基本准则-55实录-缓存策略
郑昀 创建于2013年2月
郑昀 最后更新于2013年10月26日
提纲:
- Web访问安全
- 缓存策略
- 存储介质连接池
- 业务降级
- 并发请求的处理
关键词:
会话串号,Cache-Control头域,缓存穿透,缓存集体失效,缓存重建,缓存雪崩,缓存永不过期,缓存计数器,
二,缓存策略
这里的“缓存”概念不只限于服务器端的“缓存”。
2.1.防会话串号
如果你收到一个投诉,说访问“我的个人中心”页面时进入其他人的帐号,至少订单列表上显示的不是自己的。此时,技术支持人员可以提三个问题,第一,对页面上显示的信息是否有操作权限,如取消订单;第二,浏览器地址栏上给URL增加访问参数,如追加一个&111之类的字符串,看看页面是否还是显示别人的信息;第三,投诉者上网接入方式是什么,如铁通光纤宽带,如通过某款代理软件上网。
如果既无操作权限,追加URL参数后又能看到自己的帐号信息或页面提示处于未登录状态,那么说明是URL已被各级 HTTP Proxies 缓存:
即在服务器端收到 Request 之前,网络链路上的某一级代理已返回缓存数据。
2.1.1.简单办法,如利用Expiration Model
第一种:如果页面 Response 里设置了正确的 Last-modified 和 Expires 头域,那么 基本过期模型 已经能正常运转了,因此,头域里的 Cache-Control:private 声明就已经够了,HTTP Caches 和 User Agent 都会根据这两个字段检查缓存网页是否陈旧。
第二种:重要页面的URL上加时间戳参数。
第三种:像淘宝博文[注1]所描述的:“cookie 里增加一个值,用来记录通过关键 cookie 计算出来的签名,这个签名的算法非常简单。每次请求到服务端的时候 session 框架代码里会对此签名进行匹配,如果和服务端获取的数据签名出来的值是一致的,则认为合法,否则清空 session 信息和 cookie 信息,让用户重新登录。”
2.1.2.需要有更多背景知识的办法:利用 Cache-Control 头域控制
Web开发工程师都需要了解 Cache-control 头域背后的 HTTP 1.1缓存控制机制和缓存重验证机制。
先说处理办法是:含个人敏感信息的网页响应头里,声明 Cache-Control:must-revalidate,proxy-revalidate,no-store,private,no-cache 即可。
下面简单地介绍一下背景知识,详细信息请阅读 HTTP/1.1 RFC2616, section 13 HTTP里的缓存 和 HTTP/1.1 RFC2616, section 14 头域定义,或找到 HTTP 1.1协议中文版阅读。
HTTP1.1协议定义,Response 是可以被各种 HTTP caches 缓存的。
除非有 Cache-Control 控制指令的特殊约定,否则从浏览器端到源服务器(origin server)端之间链路上所存在的各种 Caching System 都完全有可能缓存一个成功的 response:
如果这个 cache entry 是 fresh 的,可能不会(去源服务器端)校验直接返回;也可能会做一个校验再返回。
一个状态码是200, 203, 206, 300, 301, 410的 response,可能会被缓存。
2.2.缓存穿透
- 目的
- 防止访问(短期内)必然不存在的数据导致请求穿透缓存直接打到 DB。
- 原因
- 可能是数据真的不存在,但也可能是第三方恶意构造大量不存在的 id 来冲击 DB。
- 多种手段结合
2.3.”半缓存“策略
缓存命中率低,其中一个原因是,你缓存的数据被人访问间隔长、几率低,于是在下次访问到来之前缓存早已失效。命中率低,为我们指出了优化方向。
如,用户在查询一个列表页时,我们可以把前6页的数据缓存起来,再往后的页码,访问频次很低,也许就不需要缓存了。(出处)
2.4.缓存集体失效
以下原因都会导致缓存集体失效,从而引发系统”抖动“甚至”雪崩“:
- 系统预热数据的缓存过期时间过于整齐划一;
- 缓存系统宕机或重启;
- 访问高峰期间种下了一大批缓存,过期时间非常接近。
处理手段:
- 缓存过期时间散列开:在过期时间基础上增加一个随机值,如1秒~120秒随机,将大家的过期时间尽量打散。
- 防范缓存节点暂不可用的缓存双写策略:
- memcache双写:向 memcahce 的 Master Ring 和 Backup Ring 双写,如下图1所示:
![http://images.cnblogs.com/cnblogs_com/zhengyun_ustc/255879/o_clipboard%20-45.png]() 图1 memcache 双写 原图出自点评技术PPT
图1 memcache 双写 原图出自点评技术PPT- Redis备份写:向 memcache 写入的同时,写一份到备份缓存 Redis 里,键值的缓存过期时间非常大,如原键值在 memcache 过期时间5分钟,在 Redis 里则8小时过期。当 memcache 集群节点暂不可用时,Web工程就切换读取备用缓存 Redis。这种思路是保证基本可用性,所以必要时刻可以给用户返回脏数据。
- 对于不同的业务场景,缓存的使用策略也不同:
- 当系统面临缓存异常的危险时,有些系统可以采用备份方案继续支撑服务。有些系统则会优雅降级,将某些依赖缓存的功能直接去除,保证主服务的正确性。所以这两种策略的选择需要根据实际的业务场景考虑并实施。(出处)
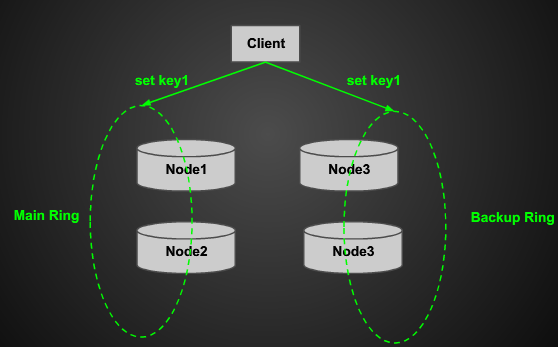 图1 memcache 双写 原图出自点评技术PPT
图1 memcache 双写 原图出自点评技术PPT2.5.分级缓存
有些业务场景里,应该把 DB 当成仅是一个存储而已,靠分级缓存策略来层层抵挡缓存失效,不让请求打到 DB。
- 手段:
- 由远及近分层建立缓存,越靠近前端,缓存片段越大(或存储粒度越大)。
- 上一层的缓存失效,可以靠下一级的缓存迅速重建。
- 目的:
- 避免系统产生抖动。
- 减少缓存雪崩,防止 DB 连接数暴涨、响应变慢,连累前端应用连接数持续高涨、最后宕机。

图2 缓存控制体系(图出自 http://www.alidata.org/archives/1789 )
2.6.缓存重建
既然有缓存过期,自然有缓存重建。
热点数据的缓存重建,无论是本地缓存还是远端缓存,都有必要加锁来确保进程内同一时刻只有一个 Worker 负责重建,甚至利用分布式锁保证集群环境下只有一个重建者,避免缓存雪崩时的 Race Condition。TimYang 早在2010年在《Memcache mutex设计模式》中描述过如下风险:”在大并发的场合,当cache失效时,大量并发同时取不到cache,会同一瞬间去访问db并回设cache,可能会给系统带来潜在的超负荷风险。我们曾经在线上系统出现过类似故障。“孙立将这种场景称为 cache key mutex 问题[注7]。

图3 cache key mutex 问题的解决(图出自 http://www.cnblogs.com/sunli/archive/2010/07/27/cache_key_mutex.html)
简而言之,缓存重建时,当多个 Client 对同一个缓存数据发起请求时,会在客户端采用加锁等待的方式,对同一个 CacheKey 的重建需要获取到相应的排他锁才行,只有拿到锁的 Client 才能访问数据库重建缓存,其他的 Client 都需要等待这个拿到锁的 Client 重建好缓存后直接读缓存。这样,对同一个缓存数据,只有一次数据库重建访问。但是如果访问分散比较严重,还是会瞬间对数据库造成非常大的压力。
当然也可以不加(悲观)锁,那么多线程并发读写同一个 cache key 可能会带来“ABA问题”。
解决方法很简单:memcached 1.2.5以及更高版本提供了 gets 和 cas 命令。如果使用 gets 命令查询某个键值,memcached 会返回该键值的唯一标识 casUnique。如果覆写了这个键值并想把它写回到 memcached 中,可以通过 cas 命令把那个 casUnique 一起发送给 memcached。如果该键值存放在 memcached 中的 casUnique 与提供的一致,写操作将会成功。如果另一个进程在这期间也修改了这个键值,那么该键值存放在 memcached 中的 casUnique 将会改变,写操作就会失败。
2.7.缓存永不过期
因为担心缓存失效带来的系统抖动,所以有些业务场景会让缓存永不过期,数据变化时,由后端负责维护缓存数据一致性。
2.8.电商场景里的缓存计数器:秒杀和超卖
我们在秒杀和防超卖场景里的实现逻辑类似于淘宝这篇博客[注3]所提及的”分布式缓存计数器“,所以我就直接照搬过来了:
|
分布式缓存的另一个应用场景是缓存计数器。 对于多服务器的系统,分布式缓存提供了统一的存储和原子操作,便于集群环境下的使用。库存计数器是分布式缓存的一个典型应用场景, 对于集群中的每一台机器,库存都应该是一个统一的值,因此使用本地缓存记录库存,数据肯定是不准确的(下面会陈述例外情况)。因此,统一的存储空间是必要 的条件。 由于库存数据被多台机器共享,因此,必须使用锁机制控制多个请求的并行并发问题。基于这样的机制就可以实行库存技术器的作用,防止货物超卖。最近的积分商城超值兑换就是使用的这种机制。 这种机制下,需要注意操作的逻辑顺序,错误的顺序会导致意想不到的结果。积分兑换的业务流程为,用户看到要抢兑的商品,如果库存大于0,则用户可以点击抢兑操作,这时用户会获得兑换该商品的权限,从而优惠购买,这时库存商品应该减一。 如果完全按照这个业务流程,我们会完成下面这三步操作:
乍一看这样的逻辑是很正常的,但是考虑一下异常情况,就会发现它防不住超卖。如果库存只有一件,那么多个用户并发验证库存时,都大于0。这样并发的多个用户都会获得优惠资格,产生了超卖。 正确的逻辑为:
这样的方法,无法保证缓存中的值一定大于等于0,因为并发的发生会把缓存减为负数,但是,真正能够优惠购买的用户一定是小于等于库存数的。因为,每次原子减操作后,只有返回的库存值大于等于零的用户才能够获得购买资格。无论并发量有多大,原子操作都会成功的防止超卖的发生。 |
|
对于上述的逻辑,可以应对绝大多数的情况。
但是随着量的增加,这种方式也有风险。当用户量极大、货物的库存极少时,就变成了秒杀。这个时候,大量的用户涌入分布式缓存减库存,对分布式缓存有极大冲击,一旦分布式缓存挂掉,秒杀活动也就宣告失败。使用分布式缓存,目的是为了让用户准确的看到剩余库存数 目,秒杀活动非常快,用户还没有看清楚库存,活动就结束了。其实用户只关心有没有秒到商品,并不关心库存的剩余数量,因此,库存减得准不准确并不是主要矛盾,这时就可以放弃分布式缓存的设计,转而使用本地缓存存储库存数,这也就是本地缓存使用的第二个场景。
比如,一共有10件商品,2台机器,可以设置每台机器的本地内存中库存等于10,那么对于外网的千万个用户,就可以有20个人抢到商品,剩下的人都 被挡在库存之外。当这20个人抢到后,就可以实现另一个处理逻辑,从20个人中选出10个真正中标的人,获得10个商品的购买权限。这个选择的逻辑非常灵活,可随意定制。但是从20选10的操作,无论如何也比从千千万万个人中选10要好的多,这样可以确保秒杀的安全完成。
如果秒杀的人继续增多,那么也可以通过客户端(即javascript)设置格挡率的方法,使少量的用户可以发出请求到服务器,绝大多数的用户都被挡在浏览器上。(注:一些技术人士在2013年吐槽小米网站抢购小米手机时,浏览器模拟排队等待其实没有发出任何网络请求,这就是客户端格挡率生效的结果。)
|
-未完待续-
备注参考资源:
1,2013,淘宝中间件团队,说说会话串号;
2,2012,腾讯Alloy团队,【Web缓存机制概述】2 – Web浏览器的缓存机制;
3,2013,淘宝搜索技术,关于缓存(上);
4,2013,范凯,Web应用的缓存设计模式;
5,2012,kenny,Cache Reload机制设计和实现(防止cache失效引发雪崩) (注:只看他的故障现象即可);
6,2010,timyang,Memcache mutex设计模式;
赠图几枚:
Lindsey Stirling的小提琴专辑 http://music.douban.com/programme/276131

Owl City专辑 http://music.douban.com/programme/57676

Lenka专辑 www.xiami.com/album/428785


 浙公网安备 33010602011771号
浙公网安备 33010602011771号