
2021-2022-1-diocs-块设备I/O和缓冲区管理
20191205 2021-2022-1-diocs-块设备I/O和缓冲区管理(第11周学习笔记)
一、任务详情
自学教材第12章,提交学习笔记(10分)
知识点归纳以及自己最有收获的内容 (3分)
问题与解决思路(2分)
实践内容与截图,代码链接(3分)
...(知识的结构化,知识的完整性等,提交markdown文档,使用openeuler系统等)(2分)
二、知识点总结
本章讨论了块设备 I/O和缓冲区管理;解释了块设备I/O的原理和I/O缓冲的优点;论述了Unix 的缓冲区管理算法,并指出了其不足之处;还利用信号量设计了新的缓冲区管理算法,以提高 I/O缓冲区的缓存效率和性能;表明了简单的PV算法易于实现,缓存效果好,不存在死锁和饥饿问题;还提出了一个比较 Unix 缓冲区管理算法和 PV算法性能的编程方案。编程项目还可以帮助读者更好地理解文件系统中的I/O操作。
思维导图

1.块设备I/O缓冲区
I/O缓冲的基本原理非常简单。文件系统使用一系列I/O缓冲区作为块设备的缓存内存。当进程试图读取(dev,blk)标识的磁盘块时。它首先在缓冲区缓存中搜索分配给磁盘块的缓冲区。如果该缓冲区存在并且包含有效数据、那么它只需从缓冲区中读取数据、而无须再次从磁盘中读取数据块。如果该缓冲区不存在,它会为磁盘块分配一个缓冲区,将数据从磁盘读人缓冲区,然后从缓冲区读取数据。当某个块被读入时、该缓冲区将被保存在缓冲区缓存中,以供任意进程对同一个块的下一次读/写请求使用。同样,当进程写入磁盘块时,它首先会获取一个分配给该块的缓冲区。然后,它将数据写入缓冲区,将缓冲区标记为脏,以延迟写入,并将其释放到缓冲区缓存中。由于脏缓冲区包含有效的数据,因此可以使用它来满足对同一块的后续读/写请求,而不会引起实际磁盘I/O。脏缓冲区只有在被重新分配到不同的块时才会写人磁盘。
2.Unix I/O缓冲区管理算法
(1)I/O缓冲区:内核中的一系列NBUF 缓冲区用作缓冲区缓存。每个缓冲区用一个结构体表示。
typdef struct buf[ struct buf*next__free;// freelist pointer struct buf *next__dev;// dev_list pointer int dev.,blk; // assigmed disk block;int opcode; // READ|wRITE int dirty; // buffer data modified int async; // ASYNC write flag int valid; //buffer data valid int buay; // buffer is in use int wanted; // some process needs this buffer struct semaphore lock=1; / // buffer locking semaphore; value=1 struct semaphore iodone=0;// for process to wait for I/0 completion;// block data area char buf[BLKSIZE];) } BUFFER; BUFFER buf[NBUF],*freelist;// NBUF buffers and free buffer list
(2)设备表:每个块设备用一个设备表结构表示。
struct devtab{ u16 dev; // major device number // device buffer list BUFFER *dev_list;BUFFER*io_queue // device I/0 queue ) devtab[NDEV];
(3)缓冲区初始化:当系统启动时,所有I/O缓冲区都在空闲列表中,所有设备列表和I/O队列均为空。
(4)缓冲区列表:当缓冲区分配给(dev,blk)时,它会被插入设备表的 dev_list中。如果缓冲区当前正在使用,则会将其标记为 BUSY(繁忙)并从空闲列表中删除。繁忙缓冲区
也可能会在设备表的I/O队列中。
说明:
Unix算法的优点:1.数据的一致性;2.缓存效果;3.临界区;
Unix算法的缺点:1.效率低下;2.缓存效果不可预知;3.可能会出现饥饿;4.该算法使用只适用于单处理系统的休眠/唤醒操作。
3.新的I/O缓冲区管理算法
信号量的主要优点:
(1)计数信号量可用来表示可用资源的数量,例如∶空闲缓冲区的数量。
(2)当多个进程等待一个资源时,信号量上的V操作只会释放一个等待进程,该进程不必重试,因为它保证拥有资源。
这些信号量属性可用于设计更有效的缓冲区管理算法。我们正式对这个问题做以下详细说明。
使用信号量的缓冲区管理算法:
假设有一个单处理器内核(一次运行一个进程)。使用计数信号量上的P/V来设计满足以下要求的新的缓冲区管理算法∶
(1)保证数据一致性。
(2)良好的缓存效果。
(3)高效率∶没有重试循环,没有不必要的进程"唤醒"。
(4)无死锁和饥饿。
4.PV算法
BUFFER *getb1k(dev,blk): while(1){
(1). P(free); //get a free buffer first
if (bp in dev_1ist){
(2). if (bp not BUSY){ remove bp from freelist;P(bp); // lock bp but does not wait (3).return bp; // bp in cache but BUSY V(free); // give up the free buffer (4).P(bp); // wait in bp queue return bp;v // bp not in cache,try to create a bp=(dev,blk) (5).bp = frist buffer taken out of freelist;P(bp); // lock bp,no wait (6).if(bp dirty){ awzite(bp); // write bp out ASYNC,no wait continue; // continue from (1) (7).reassign bp to(dev,blk);1/ mark bp data invalid,not dir return bp;- // end of while(1); brelse(BUFFER *bp), { (8).iF (bp queue has waiter)( V(bp); return; ] (9).if(bp dirty && free queue has waiter){ awrite(bp);zeturn;}(10).enter bp into(tail of) freelist;V(bp);V(free); }
接下来,我们要证明PV算法是正确的,并且满足要求。
(1)缓冲区唯一性:在 getblk()中,如果有空闲缓冲区,则进程不会在(1)处等待,而是会搜索 dev list。如果所需的缓冲区已经存在,则进程不会重新创建同一个缓冲区。如果所需的缓冲区不存在。则进程会使用个空闲缓冲区来创建所需的缓冲区。而这个空闲缓冲区保证是存在的。如果没有空闲缓冲区,则需要同一个缓冲区的几个进程可能在(1)处阻塞。当在(10)处释放出一个空闲缓冲区时,它仅释放一个进程来创建所需的缓冲区。一旦创建了缓冲区,它就会存在于dev list中,这将防止其他进程再次创建同一个缓冲区。因此,分配的每个缓冲区都是唯一的。
(2)无重试循环:进程重新执行while(1)循环的唯一位置是在(6)处,但这不是重试,因为进程正在不断地执行。
(3)无不必要唤醒:在 getblk(中,进程可以在(1)处等待空闲缓冲区也可以在(4)处等待所需的缓冲区。在任意一种情况下,在有缓冲区之前,都不会唤醒进程重新运行。此外,当在(9)处有一个脏缓冲区即将被释放并且在(1)处有多个进程等待空闲缓冲区时,该缓冲区不会被释放而是直接被写入。这样可以避免不必要的进程唤醒。
(4)缓存效果:在 Unix算法中,每个释放的缓冲区都可被获取。而在新的算法中,始终保留含等待程序的缓冲区以供重用。只有缓冲区不含等待程序时,才会被释放为空闲。这样可以提高缓冲区的缓存效果。
(5)无死锁和饥饿:在 getblk()中,信号量锁定顺序始终是单向的,即 P(free),然后是P(bp),但决不会反过来,因此不会发生死锁。如果没有空闲缓冲区,所有请求进程都将在(1)处阻塞。这意味着,虽然有进程在等待空闲缓冲区,但所有正在使用的缓冲区都不能接纳任何新用户。这保证了繁忙缓冲区最终将被释放为空闲缓冲区。因此,不会发生空闲缓冲区饥饿的情况。
5.模拟系统的改进
Unix信号最初设计用于以下用途
(1)模拟系统可以扩展为支持多个磁盘控制器,而不是单独一个磁盘控制器,这样可通过一个数据信号来缓解I/O堵塞。
(2)可用非均匀分布生成输人命令,以改善实际系统中模型文件操作。例如,可以生成更多的读命令而不是写命令,以及一些设备上有更多的I/O需求等。
6.PV算法的改进
PV算法非常简单,易于实现,但是它有以下两个缺点。首先,它的缓存效果可能并非最佳。这是因为一旦没有空闲缓冲区,所有请求进程都将被阻塞在 getblk()中的(1)处,即使它们所需的缓冲区可能已经存在于缓冲区缓存中了。其次,当进程从空闲列表信号量队列中唤醒时,它可能会发现所需的缓冲区已经存在,但处于繁忙状态,在这种情况下,它将在(4)处再次被阻塞。严格地说,进程被不必要地唤醒了,因为它被阻塞了两次。
三、最有收获的内容
I/O缓冲区管理算法比较
(1)系统组织
用户界面:这是模拟系统的用户界面部分。它会提示输人命令、显示命令执行、显示系统状态和执行结果等。在开发过程中,读者可以手动输入命令来执行任务。在最后测试过程中,任务应该有自己的输入命令序列。例如,各任务可以读取包含命令的输入文件。
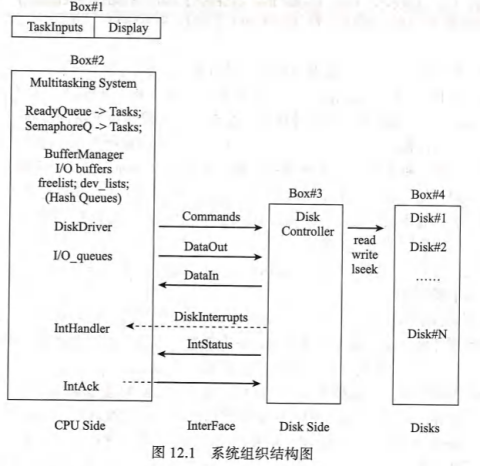
(1)多任务处理系统
这是多任务处理系统的CPU端,模拟单处理器(单CPU)文件系统的内核模式。实际上,它与第 4章中所述的用于用户级线程的多任务系统相同,只是以下修改除外。当系统启动时,它会创建并运行一个优先级最低的主任务,但它会创建 ntask 工作任务,所有任务的优先级都是1,并将它们输入 readyQueue。
由于主任务的优先级最低,所以如果没有可运行的任务或所有任务都已结束,它将再次运行。在后一种情况下,主任务执行end task(),在其中收集并显示模拟结果,然后终止,从而结束模拟运行。
所有工作任务都执行同一个body()函数,其中每个任务从输入文件中读取命令来执行读或写磁盘块操作,直到命令文件结束。
(2)磁盘驱动程序
(1)start io():维护设备I/O队列,并对I/O 队列中的缓冲区执行 I/O操作。
(2)中断处理程序:在每次I/O操作结束时,磁盘控制器会中断CPU。当接收到中断后,中断处理程序首先从 IntStatus中读取中断状态。
(4)磁盘中断
从磁盘控制器到CPU的中断由 SIGUSR1(#10)信号实现。在每次I/O操作结束时,磁盘控制器会发出kill(ppid,SIGUSR1)系统调用,向父进程发送 SIGUSR1信号,充当虚拟CPU中断。通常,虚拟CPU会在临界区屏蔽出/入磁盘中断(信号)。为防止竞态条件,磁盘控制器必须要从CPU接收一个中断确认,才能再次中断。
(5)虚拟磁盘
使用Linux系统调用lseek()、read()和 write(),我们可以支持虚拟磁盘上的任何块I/O操作。为了简单起见,将磁盘块大小设置为16字节。由于数据内容无关紧要,所以可以将它们设置为16个字符的固定序列。
(6)磁盘控制器
磁盘控制器是主进程的一个子进程。因此,它与CPU 端独立运行,除了它们之间的通信通道,通信通道是 CPU和磁盘控制器之间的接口。通信通道由主进程和子进程之间的管道实现。
命令:从 CPU到磁盘控制器的I/O命令。
DataOut:在写操作中从 CPU 到磁盘控制器的数据输出。
DataIn:在读操作中从磁盘控制器到CPU 的数据。
IntStatus:从磁盘控制器到CPU 的中断状态。
IntAck:从CPU到磁盘控制器的中断确认。
四、实践内容(截图、代码链接)
通过对信号量PV操作,消除父子进程间的竞争条件,使得其调用顺序可控。
代码链接:
pv.c
https://gitee.com/two_thousand_and_thirteen/zx-code/issues/I4IIE9
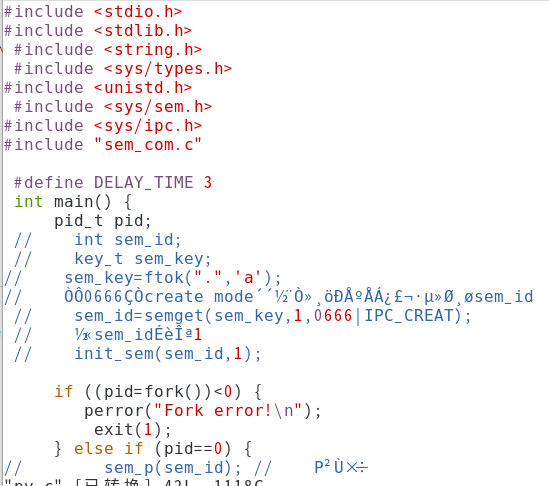
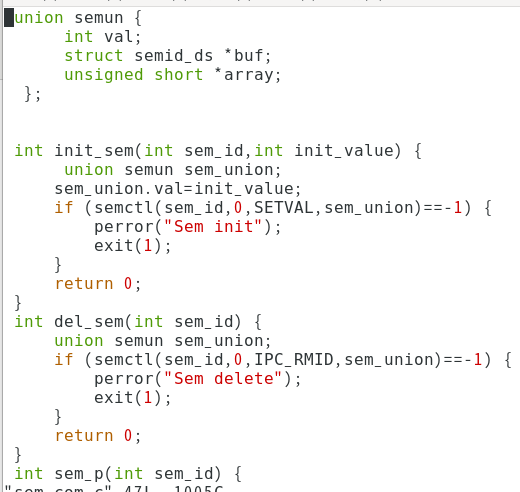
sem_com.c
https://gitee.com/two_thousand_and_thirteen/zx-code/issues/I4IIEB
编译运行截图:
在以上程序注释//未去掉时,即没用信号量机制时,其结果为:
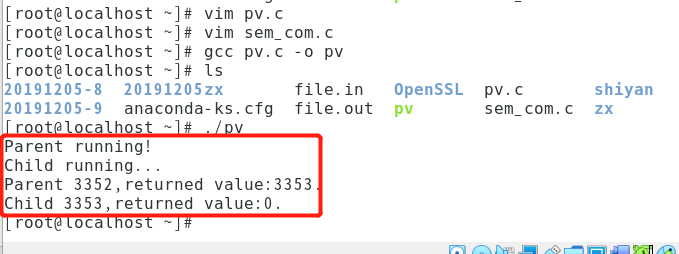
显然,此处存在竞争条件。
在以上程序注释//去掉后,即使用信号量机制,其结果为:
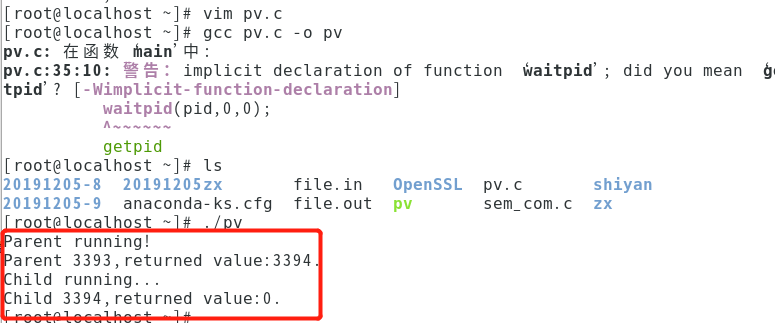
由于父子进程采用同一信号量且均执行各自PV操作,故必先等一个进程的V操作后,另一个进程才能工作。
五、问题与解决思路
问题1:
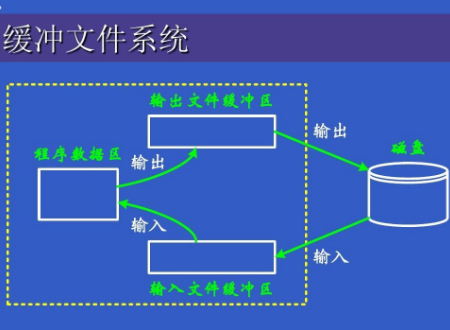
为什么要有输入输出缓冲区?
解决思路:
有输入输出缓冲区用以暂时存放读写期间的文件数据而在内存区预留的一定空间。即利用主存的存储空间来暂存从磁盘中输入输出的信息。目的是缓和CPU 与 I/O 设备间速度不匹配的矛盾。减少对 CPU 的中断频率,放宽对 CPU 中断响应时间的限制。提高 CPU和 I/O 设备之间的并行性。
问题2:
对比C语言中的setbuf()函数和setvbuf()函数的使用
思路:
C语言setbuf()函数:把缓冲区与流相关联
头文件:
#include <stdio.h>
函数setbuf()用于将指定缓冲区与特定的文件流相关联,实现操作缓冲区时直接操作文件流的功能。其原型如下:
void setbuf(FILE * stream, char * buf);
参数stream为文件流指针,buf为缓冲区的起始地址。
如果参数buf 为NULL 指针,则为无缓冲,setbuf()相当于调用setvbuf(stream, buf, buf ? _IOFBF : _IONBF, BUFSIZE)。
说明:在打开文件流后,读取内容之前,可以调用setbuf()来设置文件流的缓冲区(而且必须是这样)。
实例观察缓冲区与流关联后的影响。
#include <stdio.h> char outbuf; int main(void) { setbuf(stdout, outbuf); // 把缓冲区与流相连 puts("This is a test of buffered output.\n"); puts(outbuf); fflush(stdout); // 刷新 puts(outbuf); // 输出 return 0;
}
编译运行截图:
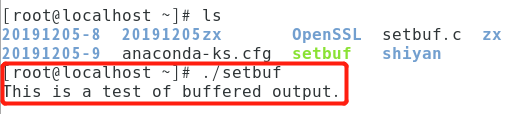
程序先把outbuf与输出流相连,然后输出一个字符串,这时因为缓冲区已经与流相连,所以outbuf中也保存着这个字符串,紧接着puts函数又输出一遍,所以现在outbuf中保存着两个一样的字符串。刷新输出流之后,再次puts,则又输出两个字符串。
C语言setvbuf()函数:设置文件流的缓冲区
头文件:
#include <stdio.h>
函数setvbuf()用来设定文件流的缓冲区,其原型为:
int setvbuf(FILE * stream, char * buf, int type, unsigned size);
参数stream为文件流指针,buf为缓冲区首地址,type为缓冲区类型,size为缓冲区内字节的数量。
参数类型type说明如下:
- _IOFBF (满缓冲):当缓冲区为空时,从流读入数据。或当缓冲区满时,向流写入数据。
- _IOLBF (行缓冲):每次从流中读入一行数据或向流中写入—行数据。
- _IONBF (无缓冲):直接从流中读入数据或直接向流中写入数据,而没有缓冲区。
返回值成功返回0,失败返回非0。
该函数涉及流和缓冲区的知识,请参考C语言流和缓冲区(缓存)专题。
如果您只是想简单的操作缓冲区,还可以使用setbuf()函数,请查看:C语言setbuf()函数
setbuf()和setvbuf()函数的实际意义在于:用户打开一个文件后,可以建立自己的文件缓冲区,而不必使用fopen()函数打开文件时设定的默认缓冲区。这样就可以让用户自己来控制缓冲区,包括改变缓冲区大小、定时刷新缓冲区、改变缓冲区类型、删除流中默认的缓冲区、为不带缓冲区的流开辟缓冲区等。
说明:在打开文件流后,读取内容之前,调用setvbuf()可以用来设置文件流的缓冲区(而且必须是这样)。
#include <stdio.h> int main(void) { FILE *input, *output; char bufr512; input = fopen("file.in", "w+"); /*打开文件*/ output = fopen("file.out", "w"); if (setvbuf(input, bufr512, _IOFBF, 512) != 0) /*失败*/printf("failed to set up buffer for input file\n");
else
printf("buffer set up for input file\n");
if (setvbuf(output, NULL, _IOLBF, 132) != 0) /为流指定特殊的缓冲区/
printf("failed to set up buffer for output file\n");
else
printf("buffer set up for output file\n");
fclose(input);
fclose(output);
return 0;
}
编译运行截图:

程序先打开两个文件,分别设置缓冲区,根据返回值判定是否成功,最后使用fclose函数关闭这两个文件。
