2021-2022-1-diocs-Linux系统编程第四周学习笔记
20191205 2021-2022-1-diocs-文件操作&使用系统调用进行文件操作(第四周学习笔记)
一、任务详情
自学教材第7,8章,提交学习笔记(10分)
知识点归纳以及自己最有收获的内容 (3分)
问题与解决思路(2分)
实践内容与截图,代码链接(3分)
...(知识的结构化,知识的完整性等,提交markdown文档,使用openeuler系统等)(2分)
二、教材内容归纳整理
第七章:文件操作
思维导图

知识归纳
基本概念
本章讨论了多种文件系统;解释了操作系统中的各种操作级别,包括为文件存储准备存储设备、内核中的文件系统支持函数、系统调用、文件流上的I/O库函数、用户命令和各种操作的sh脚本;系统性概述了各种操作,包括从用户空间的文件流读/写到内核空间的系统调用,直到底层的设备I/O驱动程序级别;描述了低级别的文件操作,包磁盘分区、显示分区表的示例程序、文件系统的格式化分区以及挂载磁盘分区;介绍了Linux系统的EXT2文件系统,包括EXT2文件系统的系统数据结构、显示超级块、组描述符、块和索引节点位图以及目录内容的示例程序。
文件操作级别
(1)硬件级别:硬件级别的文件操作包括:
Fdisk:将磁盘、U盘或SDC盘分区。
mkfs:格式化磁盘分区,为系统做好准备。
fsck:检查和维修系统。
碎片整理:压缩文件系统中的文件。
(2)操作系统内核中的文件系统函数:
每个操作系统内核均可为基本文件操作提供支持。
(3)系统调用
用户模式程序使用系统调用来访问内核函数:
open()、read()、lseek()和close()函数都是c语言库函数,每个库函数都会发出一个系统调用,使进程进入内核模式来执行相应的内核函数,例如open可以进入kopen(),read可进入kread()函数等。
(4)I/O库函数
除了读/写内存位置的sscanf()/sprintf()函数之外,所有其他I/O库函数都建立在系统调用之上,它们会最终通过系统内核发出实际数据传输的系统调用。
I/O库函数包括:
FILE mode I/O:fopen(),fread();fwrite(),fseek(),fclose(),fflush()
char mode I/O:getc(),getchar() ugetc();putc(),putchar()
line mode I/O:gets(),fgets();puts(),fputs()
formatted I/O:scanf(),fscanf(),scanf();printf(),fprintf(),sprintf()
(5)用户命令
用户可以使用Unix/Linux命令来执行文件操作,而不是编写程序。用户命令的示例如下:
mkdir,rmdir,cd,pwd,ls,link,unlink,rm,cat,cp,mv,chmod,etc.
(6)sh脚本
sh语言包含所有的有效Unix/Linux命令,它还支持变量和控制语句,如if、do、for、while、case等。除此之外,Perl和Tcl等其他许多脚本语言也使用广泛。
文件I/O操作
(1)用户模式下的程序执行操作
FILE *fp = fopen(“file”,”r”);or FILE *fp = fopen(“file”,”w”);
可以打开一个读/写文件流。
(2)fopen()在用户(heap)空间中创建一个FILE结构体,包含一个文件描述符fd、一个fbuf[BLKSIZE]和一些控制变量。
(3)fread(ubuf,size,nitem,fp):将nitem个size字节读取到ubuf上,通过:将数据从FILE结构体的fbuf上复制到ubuf上,若数据足够,则返回。
(4)内核中的文件系统函数
假设非特殊文件的read(fd,fbuf[],BLKSIZE)系统调用。
(5)设备I/O:I/O缓冲区上的物理I/O最终会仔细检查设备驱动程序,设备驱动程序由上半部分的start_io()和下半部分的磁盘中断处理程序组成。
低级别文件操作
分区
定义:一个块存储设备,如硬盘、U盘、SD卡等,可以分为几个逻辑单元。各分区均可以格式化为特定的文件系统,也可以安装在不同的操作系统上。分区表位于第一个扇区的字节偏移446(0xLBE)处,该扇区称为设备的主引导记录。表有4个条目,每个条目由一个16字节的分区结构体定义,即:
struct partition { u8 drive; u8 head; u8 sector; u8 cylinder; u8 sys_type; u8 end_head; u8 end_sector; u8 end_cylinder; u32 start_sector; u32 nr_sectors; };
每个扩展分区的第一个扇区是一个本地MBR。每个本地MBR在字节偏移量0xLBE处也有一个分区表,只包含两个条目。
例题:编写一个c程序,显示虚拟磁盘映像的分区和扩展分区,其格式与fdisk相同:
(1)访问MBR中的分区表:
#include<stdio.h>
#include<fcntl.h>
Char buf[512];
Int fd=open(“mydisk”, o_RDONLY);
Read(fd,buf,512);
Struct partition *p=(struct partition *)&buf[0x1BE];
Printf(“p->start_sector=%d\n”,p->start_sector);
p++;
(2)假设P4是start_sector=n的扩展类型(类型=5)
Lseek(fd,(long)(n*512),SEEK_SET);
read(fd,char buf[],512);
P = (struct partition *)&buf[0x1BE]);
(3)扩展分区形成一个“链表”,以一个NULL“指针”结束。
挂载分区
(1)用dd命令创建一个虚拟磁盘映像
dd if =/dev/zero of=vdisk bs=1024 count=32768
(2)在vdisk上运行fdisk来创建一个分区P1:
Fdisk vdisk
(3)使用扇区数在vdisk的分区1上创建一个循环设备:
Losetup -o $(expr 2048 \* 512) --sizelimit $(expr 65535 \* 512) /dev/loopl vdisk
(4)格式化/dev/loopl,它是一个EXT2文件系统:
Mke2fs -b 4096 /dev/loop1 7936
(5)挂载循环设备:
Mount /dev/loop1c/ mnt
(6)访问作为文件系统一部分的挂在设备:
(cd /mnt; mkdir bin boot dev etc user)
(7)设备使用完毕后,将其卸载。
Umount /mnt
(8)循环设备使用完毕后,通过以下命令将其断开:
Losetup -d /dev/loop1
EXT2文件系统简介
Block#0:引导块 B0是引导块,文件系统不会使用它。它用于容纳从磁盘引导操作系统的引导程序。
Block#1:超级块(在硬盘分区中字节偏移量为1024) B1是超级块,用于容纳关于整个文件系统的信息。
Block#2:块组描述块(硬盘上的s_first_data_blocks-1) EXT2将磁盘块分成几个组。每个组有8192个块(硬盘上的大小为32K)。每组用一个块组描述符结构体描述。
Block#8:块位图是用来表示某种项的位序列,例如:磁盘块或索引节点。
Block#9:索引节点位图,一个索引节点就是用来代表一个文件的数据结构。
Block#10:索引(开始)节点块,每个文件都用一个128节点的独特索引节点结构体表示。
直接块:指向直接磁盘块;
间接块:每个块编号指向一个磁盘块;
双重间接块:每个块指向256个磁盘块;
三重间接块:对于小型的“EXT2”文件系统,可以忽略这个块。
数据块:紧跟在索引节点块后面的是文件存储块。
EXT2目录条目:
struct ext2_dir_entry_2{ u32 inode; u16 rec_len; u8 name_len; u8 file_type; char name[EXT2_NAME_LEN]; };
说明:dir_entry是一种可扩充结构。
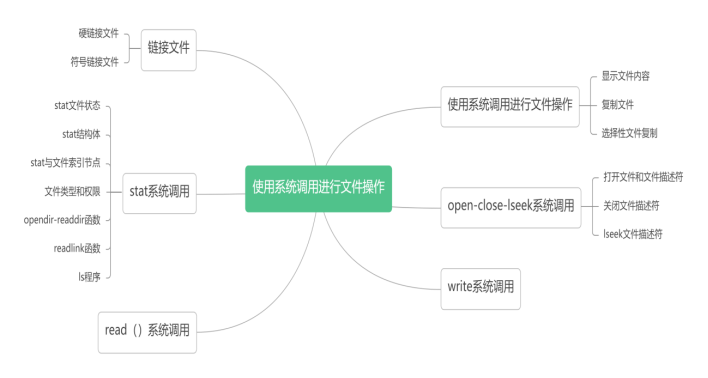
第八章:使用系统调用进行文件操作
思维导图
基本概念
本章论述了如何使用系统调用进行文件操作;解释了系统调用的作用和Linux的在线手册页;展示了如何使用系统调用进行文件操作;列举并解释了文件操作中最常用的系统调用;阐明了硬链接和符号链接文件;具体解释了stat 系统调用;基于 stat信息,开发了一个类似于ls 的程序来显示目录内容和文件信息;接着,讲解了open-close-lseek系统调用和文件描述符;然后,展示了如何使用读写系统调用来读写文件内容;在此基础上,说明了如何使用系统调用来显示和复制文件;还演示了如何开发选择性文件复制程序,其行为类似于一个简化的Linux dd 实用程序。
使用系统调用进行文件操作
系统调用必须由程序发出。他们的用法就像普通函数调用一样。每个系统调用都是一个库函数,它汇集系统调用参数,并最终向操作系统内核发出一个系统调用。
int syscall(int a,int b,int c,int d);
示例程序:mkdir、chdir、getcwd系统调用。
#include <gtdio.h> #include <errno.h> int main() { char buf [256],*g; Int r; r = mkdir("newdir",0766);// mkdir syscall if(r <0) printf("errno=%d : %\n",errno,strerror(errno)); r= chdir("newdir"); // cd into newdir g = getcwd(buf,256); // get CWD string into buf[ ] printf("CWD= %8\n",a); }
该程序发出一个mkdir()系统调用来创建新目录。mkdir()系统调用需要一个路径名和一个权限(八进制的0766)。如果没有新目录,则系统调用成功。返回值为0。如果不止一次运行该程序,由于目录已经存在,则在第二次或后续任何运行时会失败,返回值为-1。在这种情况下,该程序会打印消息∶
errno=17 : File exits
简单的系统调用:
access:检查对某个文件的权限
chdir:更改目录
chmod:更改某个文件的权限
chown:更改文件所有人
chroot:将(逻辑)根目录更改为路径名
getcwd:获取CWD的绝对路径名
mkdir:创建目录
rmdir:移除目录(必须为空)
link:将新文件名硬链接到旧文件名
unlink:减少文件的链接数;如果链接数达到0,则删除文件
symlink:为文件创建一个符号链接
rename:更改文件名称
utime:更改文件的访问和修改时间
以下系统调用需要超级用户权限。
mount:将文件系统添加到挂载点目录上
umount:分离挂载的文件系统
mknod:创建特殊文件
stat:获取文件状态信息
open:打开一个文件进行读、写、追加
close:关闭打开的文件描述符
read:读取打开的文件描述符
write:写入打开的文件描述符
link:将新文件硬链接到旧文件
unlink:取消某个文件的链接;如果链接文件链接数为0,则删除文件
readlink:读取符号链接文件的内容;
symlink:创建一个符号链接
链接文件
硬链接文件命令:
In oldpath newpath
软连接文件命令:
in -s oldpath newpath
stat结构体
所有的stat系统调用都以stat结构体形式返回信息,其中包含以下片段:
struct stat{ dev_t st_dev; ino_t st_ino; mode_t st_mode; st_nlink; nlink_t uid_t st_uid; gia_t st_gid; dev_t st_rdev; off_t st_size; u32 st_blksize; u32 st_block8; time_t st_atime;time_E st_mtime time_t st_ctime; }
open-close-lseek系统调用
open:打开一个文件进行读、写、追加
close:关闭打开的文件描述符
read:读取打开的文件描述符
write:写入打开的文件描述符
lseek:将文件描述符的字节偏移量重新定位成偏移量
umask:设置文件创建掩码;文件权限(mask&~umask)
read()系统调用
#include<unistd.h> int read(int fd,void *buf,int nbytes);
write()系统调用
#include<unistd.h> int write(int fd,void *buf, int nbytes);
三、最有收获的内容
库函数与系统调用的区别联系
1.区别
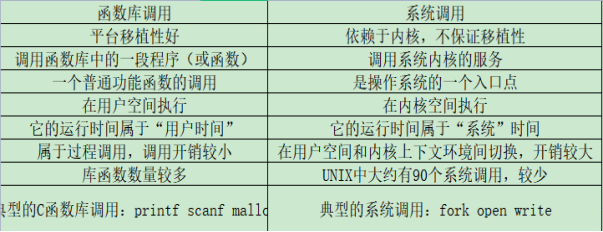
2.联系
一般而言,跟内核功能与操作系统特性紧密相关的服务,由系统调用提供;具有共通特性的功能一般需要较好的平台移植性,故而由库函数提供。
库函数与系统调用在功能上相互补充,如进程间通信资源的管理,进程控制等功能与平台特性和内核息息相关,必须由系统调用来实现。
文件 I/O操作等各平台都具有的共通功能一般采用库函数,也便于跨平台移植。某些情况下,库函数与系统调用也有交集,如 库函数中的I/O操作的内部实现依然需要调用系统的I/O方能实现。
四、实践过程(基于华为云OpenEuler系统下实现操作)
问题1:为什么会出现系统调用的效率比库函数要低很多?
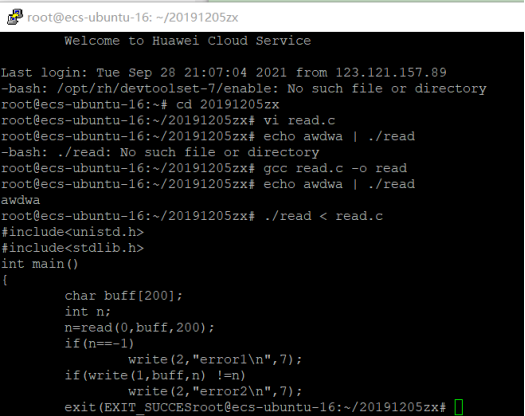
首先我编译了两个代码copy_system实现的是系统调用,copy_stdio实现的是利用标准I/O库函数调用的,在linux下用time命令查看各自的运行时间来进行比较。
内容代码链接:
系统调用:
https://gitee.com/two_thousand_and_thirteen/codes/c0j49ueqpd7v6sf3gylzo81
I/O库函数调用
https://gitee.com/two_thousand_and_thirteen/codes/8ibgxos01jd6wyql7ctf456
截图如下:
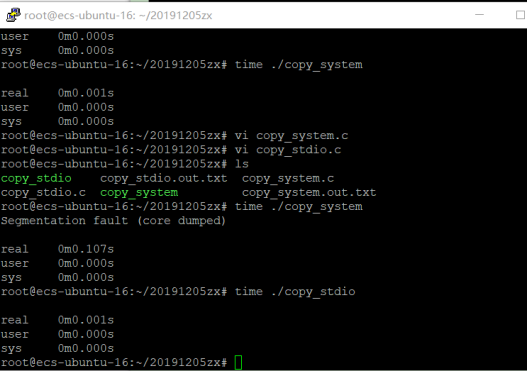
从测试结果可以看出,系统调用的效率比库函数要低很多。所以这为什么?
我在网络上找到了相关论述:这是因为使用系统调用会影响系统的性能。与函数调用相比,系统调用时,Linux必须从运行用户代码切换到执行内核代码,然后再返回用户代码,所以系统调用的开销要比普通函数调用大一些。然而也是有办法减少这种开销的,就是在程序中尽量减少系统调用的次数,并且让每次系统调用完成尽量多的工作。
紧接着我产生第二个疑问:库函数为什么做同样的事情效率却会高这么多呢?这是因为库函数在数据满足数据块长度(或buffer长度)要求时才安排执行底层系统调用,从而减少了系统调用的次数,也让每次的系统调用做了尽量多的事情,所以效率就比较高。
以上就是我的解决思路。
接下来是实践过程:编写代码提高系统调用的简单方法,例如一次读1024字节提高效率:
内容代码链接:
修改后的系统调用:
https://gitee.com/two_thousand_and_thirteen/codes/vak068de154hbfrnc72zj70
截图:
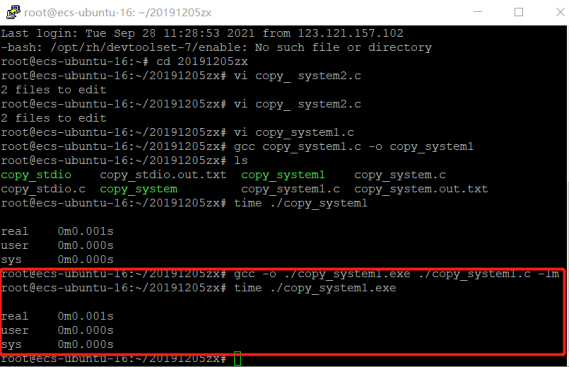
可以看出,其性能改善了一个数量级,效率大大提高了。
问题2:Linux下如何利用系统调用进行文件操作
解决思路:
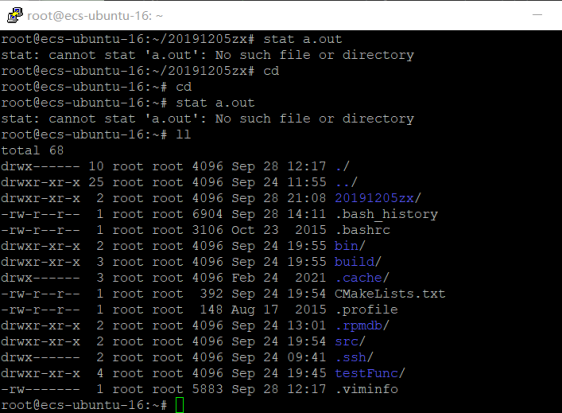
1.目录 ll
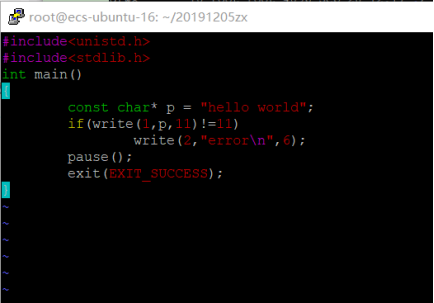
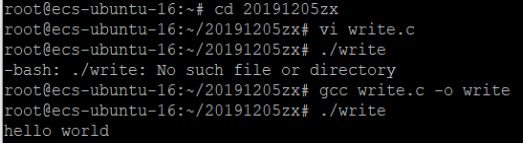
2.write系统调用
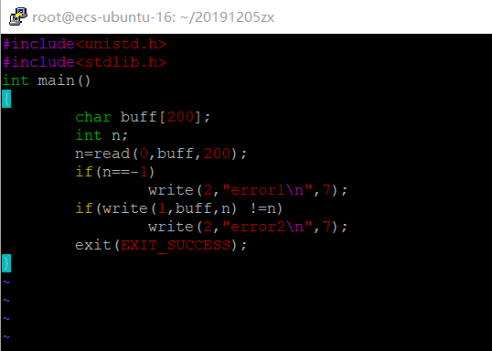
#include <unistd.h> size_t write(int fildes,const void* buf,size_t nbytes);
代码内容链接:
https://gitee.com/two_thousand_and_thirteen/codes/k564sxj8vwdqzciutf2br29
3.read系统调用
#include <unistd.h> size_t read(int fildes,void* buf,size_t nbytes);
代码内容链接:
https://gitee.com/two_thousand_and_thirteen/codes/2vlwtpr53b1ha79jco4gd82