

DiffSeq
目录
概
本文提出了一种用于 Seq2Seq 的不需要 classifier 引导的扩散模型, 且是在连续空间上讨论的.
虽然方法看起来很简单, 但是感觉很容易 work 和推广.
符号说明
- z0∼q(z)z0∼q(z), a real-world data distribution;
- zT∼N(0,I)zT∼N(0,I), Gaussian noise;
- q(zt|zt−1)=N(zt;√1−βtzt−1,βtI),t∈[1,2,…,T]q(zt|zt−1)=N(zt;1−βtzt−1,βtI),t∈[1,2,…,T];
- fθfθ, a diffusion model;
- wx=[wx1,…,wxm]wx=[w1x,…,wmx], m-length soure sequence (离散的);
- wy=[wy1,…,wyn]wy=[w1y,…,wny], n-length soure sequence (离散的).
流程
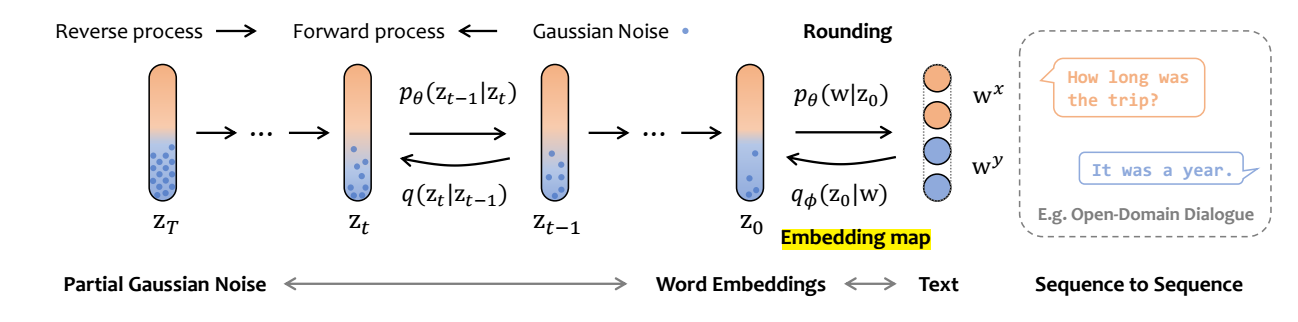
-
首先利用获取词的 embeddings:
z0=Emb(w)=[Emb(w1),Emb(w2),…],z0=Emb(w)=[Emb(w1),Emb(w2),…],这一步实际上是相当于构建从离散空间到连续空间的一个映射:
qϕ(z0|w)=δEmb(w)(z0).qϕ(z0|w)=δEmb(w)(z0). -
因为整个流程设计两个部分: source xx, target yy, 不妨令
x0=Emb(wx)=[Emb(wx1),Emb(wx2),…],y0=Emb(wy)=[Emb(wy1),Emb(wy2),…].x0=Emb(wx)=[Emb(w1x),Emb(w2x),…],y0=Emb(wy)=[Emb(w1y),Emb(w2y),…].于是
z0=x0⊕y0.z0=x0⊕y0.类似的之后的 ztzt 均可以分为 source 和 target 两部分, 即
zt=xt⊕yt.zt=xt⊕yt. -
前向过程: 如上图所示:
- 根据 qϕ(z0|w)qϕ(z0|w) 得到 z0z0 (这一步实际上是确定的);
- 此时我们依旧在连续空间中了, 故我们可以使用一般的高斯分布来加噪, 即:
z′t∼q(zt|zt−1)=N(zt;√1−βtzt−1,βtI).zt′∼q(zt|zt−1)=N(zt;1−βtzt−1,βtI).
但是特别地, 我们只对 target 部分加噪:
zt=x0⊕y′t.zt=x0⊕yt′.
-
反向过程: 同样如上图所示:
-
从标准的高斯分布中采样 z′TzT′, 并令
zT=x0⊕y′T.zT=x0⊕yT′. -
根据如下分布进行反向传递:
z′t−1∼N(zt−1;μθ(z,t),σθ(zt,t)),zt−1=x0⊕y′t−1,t≥2.zt−1′∼N(zt−1;μθ(z,t),σθ(zt,t)),zt−1=x0⊕yt−1′,t≥2.
-
-
最后的损失为如下:
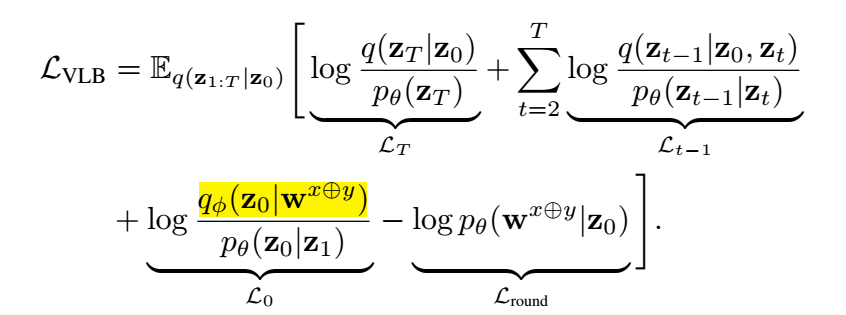
-
需要注意的是, 其中 qϕ(z0|wx⊕y)qϕ(z0|wx⊕y) 本身是一个确定的过程, 所以是不提供导数的, 可以省略. 整体的推导其实普通的 VLB 没什么差别, LroundLround 也只是原来的损失一部分, 只是被作者单拎了出来. 不过也有道理, 因为但看它, 其实就是希望训练一个分类网络, 将 z0z0 映射回词.
-
不过作者最后用的也不是上面的损失, 而是一个简化的版本 (即把原先的系数给去掉后的结果):
LVLB=[T∑t=2∥z0−fθ(z,t)∥2+∥Emb(wx⊕y)−fθ(z1,1)∥2−logpθ(wx⊕y|z0)]⇒[T∑t=2∥y0−