

Diffusion|DDIM 理解、数学、代码
DIFFUSION 系列笔记|DDIM 数学、思考与 ppdiffuser 代码探索
论文:DENOISING DIFFUSION IMPLICIT MODELS
参考 博客; 参考 aistudio notebook 链接,其中包含详细的公式与代码探索: link
该文章主要对 DDIM 论文中的公式进行小白推导,同时笔者将使用 ppdiffuser 中的 DDIM 与 DDPM 探索两者之间的联系。读者能够对论文中的大部分公式如何得来,用在了什么地方有初步的了解。
本文将包括以下部分:
- 总结 DDIM。
- Non-Markovian Forward Processes: 从 DDPM 出发,记录论文中公式推导
- 探索与思考:
- 验证当
- DDIM 的加速采样过程
- DDIM 采样的确定性
- INTERPOLATION IN DETERMINISTIC GENERATIVE PROCESSES
- 验证当
DDIM 总览
- 不同于 DDPM 基于马尔可夫的 Forward Process,DDIM 提出了 NON-MARKOVIAN FForward Processes。(见 Forward Process)
- 基于这一假设,DDIM 推导出了相比于 DDPM 更快的采样过程。(见探索与思考)
- 相比于 DDPM,DDIM 的采样是确定的,即给定了同样的初始噪声
- DDIM 和 DDPM 的训练方法相同 ,因此在 DDPM 基础上加上 DDIM 采样方案即可。(见探索与思考)
Forward process
DDIM 论文中公式的符号与 DDPM 不相同,如 DDIM 论文中的
相当于 DDPM 中的 ,而 DDPM 中的 则在 DDIM 中记成 ,但是运算思路一致,如 DDIM 论文中的公式 都在 DDPM 中能找到对应公式。 以下我们统一采用 DDPM 中的符号进行标记。即
在 DDPM 笔记 扩散模型探索:DDPM 笔记与思考 中,我们总结了 DDPM 的采样公式推导过程为:
而后我们用
论文作者提到了
公式
推导得来。至于如何推导,生成扩散模型漫谈(四):DDIM = 高观点 DDPM 中通过待定系数法给出了详细的解释,由于解释计算过程较长,此处就不展开介绍了。
根据
带入,我们能写出采样公式(即论文中的核心公式
其中,
如果
论文中指出, 当
将
上式的推导过程
因此
因此,根据推导,
探索与思考
接下来将根据飞桨开源的 PaddleNLP/ppdiffusers,探索以下四个内容:
- 验证当
- DDIM 的加速采样过程
- DDIM 采样的确定性
- INTERPOLATION IN DETERMINISTIC GENERATIVE PROCESSES
读者可以在 Aistudio 上使用免费 GPU 体验以下的代码内容。链接:扩散模型探索:DDIM 笔记与思考
DDIM 与 DDPM 探索
验证当
我们使用 DDPM 模型训练出来的 google/ddpm-celebahq-256 人像模型权重进行测试,根据上文的推导,当 DDPMPipeline 加载模型权重 google/ddpm-celebahq-256 ,而后采用 DDIMScheduler() 进行图片采样,并将采样结果与 DDPMPipeline 原始输出对比。如下:
# DDPM 生成图片
pipe = DDPMPipeline.from_pretrained("google/ddpm-celebahq-256")
paddle.seed(33)
ddpm_output = pipe() # 原始 ddpm 输出
# 我们采用 DDPM 的训练结果,通过 DDIM Scheduler 来进行采样。
pipe.scheduler = DDIMScheduler()
# 设置与 DDPM 相同的采样结果,令 DDIM 采样过程中的 eta = 1.
paddle.seed(33)
ddim_output = pipe(num_inference_steps=1000, eta=1)
imgs = [ddpm_output.images[0], ddim_output.images[0]]
titles = ["ddpm", "ddim"]
compare_imgs(imgs, titles) # 该函数在 notebook_utils.py 声明
输出结果:

通过运行以上代码,我们可以看出
- 计算机浮点数精度问题
- Scheduler 采样过程中存在的 clip 操作导致偏差。
尝试去除 Clip 操作
Scheduler 采样过程中存在的 clip 操作导致偏差。Clip 操作对采样过程中生成的 x_0 预测结果进行了截断,尽管 DDPM, DDIM 均在预测完
将 clip 配置设置成 False 后, DDPM 与 DDIM(
pipe = DDPMPipeline.from_pretrained("google/ddpm-celebahq-256")
pipe.progress_bar = lambda x:x # uncomment to see progress bar
# 我们采用 DDPM 的训练结果,通过 DDIM Scheduler 来进行采样。
# print("Default setting for DDPM:\t",pipe.scheduler.config.clip_sample) # True
pipe.scheduler.config.clip_sample = False
paddle.seed(33)
ddpm_output = pipe()
pipe.scheduler = DDIMScheduler()
# print("Default setting for DDIM:\t",pipe.scheduler.config.clip_sample) # True
pipe.scheduler.config.clip_sample = False
paddle.seed(33)
ddim_output = pipe(num_inference_steps=1000, eta=1)
imgs = [ddpm_output.images[0], ddim_output.images[0]]
titles = ["DDPM no clip", "DDIM no clip"]
compare_imgs(imgs, titles)
可以验证得到 DDPM 与 DDIM 论文中提出的

DDIM 加速采样
论文附录 C 有对这一部分进行详细阐述。DDIM 优化时与 DDPM 一样,对噪声进行拟合,但 DDIM 提出了通过一个更短的 Forward Processes 过程,通过减少采样的步数,来加快采样速度:
从原先的采样序列 arange(1, 1000, 100))。抽取方式不固定。在生成时同样采用公式 1, 100, 200, ... 1000 中的第二个样本,则使用训练时候采用的 alphas_cumprod alpha 参数
参考论文中的 Figure 3,在加速生成的情况下,
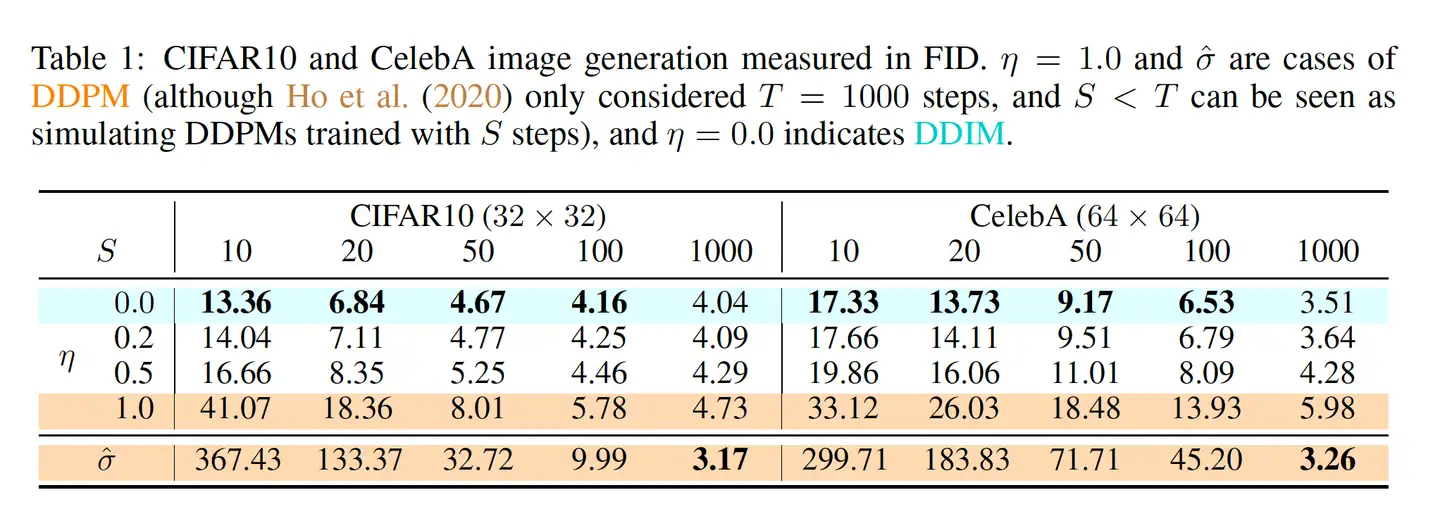
我们尝试对论文中提到的上述方法进行复现:
pipe.progress_bar = lambda x:x # cancel process bar
etas = [0, 0.4, 0.8]
steps = [10, 50, 100, 1000]
fig = plt.figure(figsize=(7, 7))
for i in range(len(etas)):
for j in range(len(steps)):
plt.subplot(len(etas), len(steps), j+i*len(steps) + 1)
paddle.seed(77)
sample1 = pipe(num_inference_steps=steps[j], eta=etas[i])
plt.imshow(sample1.images[0])
plt.axis("off")
plt.title(f"eta {etas[i]}|step {steps[j]}")
plt.show()

通过论文中的示例说明,以及上述实现结果可以发现几点:
DDIM 采样的确定性
由于 DDIM 在生成过程中
paddle.seed(77)
x_t = paddle.randn((1, 3, 256, 256))
paddle.seed(8)
sample1 = pipe(num_inference_steps=50,eta=0,x_t=x_t)
paddle.seed(9)
sample2 = pipe(num_inference_steps=50,eta=0,x_t=x_t)
compare_imgs([sample1.images[0], sample2.images[0]], ["sample(seed 8)", "sample(seed 9)"])

图像重建
在 DDIM 论文中,其作者提出了可以将一张原始图片
大致推导过程
而后进行换元,令
于是,基于这个 ODE 结果,能通过
根据 github - openai/improved-diffusion,其实现根据 ODE 反向采样的方式为:直接根据公式
而参考公式
以下我们尝试对自定义的输入图片进行反向采样(reverse sampling)和原图恢复,我们导入本地图片:

根据公式 12 编写反向采样过程。ppdiffusers 中不存在 reverse_sample 方案,因此我们根据本文中的公式 reverse_sample 过程,具体为:
def reverse_sample(self, model_output, x, t, prev_timestep):
"""
Sample x_{t+1} from the model and x_t using DDIM reverse ODE.
"""
alpha_bar_t_next = self.alphas_cumprod[t]
alpha_bar_t = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
inter = (
((1-alpha_bar_t_next)/alpha_bar_t_next)** (0.5)- \
((1-alpha_bar_t)/alpha_bar_t)** (0.5)
)
x_t_next = alpha_bar_t_next** (0.5) * (x/ (alpha_bar_t ** (0.5)) + \
(
model_output * inter
)
)
return x_t_next
而后进行不断的迭代采样与图片重建(具体的方式可以查看 扩散模型探索:DDIM 笔记与思考)。以下右图为根据原图进行反向 ODE 加噪后的结果,可以看出加噪后和电视没信号画面相当。以下左图为根据噪声图片采样得来的结果,基本上采样的结果还原了 90%以上原图的细节,不过还有如右上角部分的一些颜色没有被还原。

潜在的风格融合方式
通过两个能够生成不同图片的噪声
paddle.seed(77)
pipe.scheduler.config.clip_sample = False
z_0 = paddle.randn((1, 3, 256, 256))
sample1 = pipe(num_inference_steps=50,eta=0,x_t=z_0)
paddle.seed(2707)
z_1 = paddle.randn((1, 3, 256, 256))
sample2 = pipe(num_inference_steps=50,eta=0,x_t=z_1)
compare_imgs([sample1.images[0], sample2.images[0]], ["sample from z_0", "sample from z_1"])
输出结果:

以上选择 seed 为 77 和 2707 的噪声进行采样,他们的采样结果分别展示在上方。
以下参考 ermongroup/ddim/blob/main/runners/diffusion.py ,对噪声进行插值,方式大致为:
def slerp(z1, z2, alpha):
theta = torch.acos(torch.sum(z1 * z2) / (torch.norm(z1) * torch.norm(z2)))
return (
torch.sin((1 - alpha) * theta) / torch.sin(theta) * z1
+ torch.sin(alpha * theta) / torch.sin(theta) * z2
)

可以看出,当
那根据前两节的阐述,我们可以实现一个小的 pipeline, 具备接受使用 DDIM 接受两张图片,而后输出一张两者风格融合之后的图片。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
2021-07-27 NLP(三十):BertForSequenceClassification:Kaggle的bert文本分类,基于transformers的BERT分类
2021-07-27 NLP(二十九):BertForSequenceClassification的新闻标题分类,基于pytorch_pretrained_bert
2021-07-27 NLP(二十八):BertForSequenceClassification进行文本分类,基于transformers