

PPLM:可控文本生成
最近一直捣鼓生成式模型的东西,特别是关于利用现有预训练模型的生成式,中间很多挺有意思的坑,先不说。生成式中一个比较大的需求是,可控文本生成,其中可控表示能让模型生成与所需主题相关的文本,这也涉及到文本的风格迁移。
往往即便是现有超大语言模型,如 GPT2,可以生成没有任何拼写和语法错误的句子,但却难以控制其生成的方向。而这样的语言模型就像一头巨象,完全没有方向地到处走,你只能指望它碰巧去了你需要的方向。
最近读到 Uber AI 的关于该主题的论文,Plug and Play Language Models: a Simple Approach to Controlled Text Generation,方法非常新颖,简单介绍一下。
我们以前都这样干
之前对于预训练语言模型(特别是超大型)可控生成的做法,主要如下三种
- 随缘法,就是直接拿着语言模型就用。可以给语言模型些字,让它基于这个续写,生成多个结果,之后挑最好的来展示(俗称 cherry-pick)。很多 GPT2 展示出的例子就大都 cheery-pick 出来的。
- 精调法,因为上面直接拿来用对于某些风格或主题的内容生成很难撞上,可能预训练时这方面的文本也少,于是可以先在需要的风格或主题文本上进行精调训练,或者用强化学习和人类反馈精调出想要的语言模型。
- 条件语言模型法,这个就是在预训练阶段就将各种风格主题标签加入进去,这些标签可以来自于训练数据的元数据,之后生成的时候,在生成所需要风格主题的文本时,只需要先给个标签就行,Salesforce 的 CTRL 模型个很典型的例子。
以上三种方法,除了第一种,因为需要对整体语言模型进行训练,所以都要大量计算资源,而第一种生成可控性又特别差。对此,PPLM 则是在使用少量计算资源的同时,又达到了比较好的可控生成性。
关于这几种方法简单比较如下:
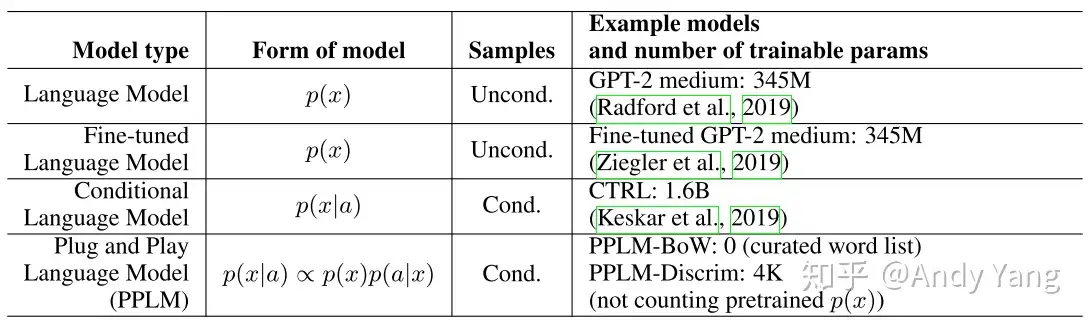
可见相比起之前的方法,PPLM 最大的不同在于建模形式不同了,然后需要训练参数也少了很多。PPLM-Discrim 的参数才 4k,相比起其控制的 345M 模型,差了百万倍,正所谓四两拨千斤。
何谓可控
其实所谓可控就是如何建模出 p(x|a) 这样的概率模型,也就是基于某个属性 a,生成文本 x,获得满意结果。
关于前面几种方法大概分别是这样获得 p(x|a):
- 直接拿语言模型来用的,只能直接获得 p(x),最多通过给出文本注入先验,尽量将生成范围缩小,然后选出满足要求的 p(x|a).
- 而精调法是,直接在预训练中对单个属性中的 p(x|a) 进行建模,因为 a 是隐含的,所以可以直接写成 p(x).
- 条件语言模型法,则是将各个属性的 p(x|a) 都直接在预训练中进行训练。
而 PPLM 最关键的是将 p(x|a) 通过贝叶斯公式改写成了下面形式:
其实这个很好理解,要获得所需基于属性 a 生成文本的 p(x|a)。我们已有一个语言模型 p(x) 能够很好地生成符合自然语言的文本,那么一个非常简单的方法就是用一个分类器(也能是人)来判断语言模型生成的文本 x 是否具有 a 属性,也就是 p(a|x),于是就能获得 p(x|a). 这其实就是文中提到的 rerank 法。
当然 PPLM 则用了更精巧的方法解决该问题。
P(a|x):先得赋予属性
首先解释一点背景知识,在每个 t 时间步上,语言模型 LM 干的活就是基于过去的历史信息 H 来生成当前的输出 o,同时也将当前时间步信息存入历史,用于下一个时间步的生成:
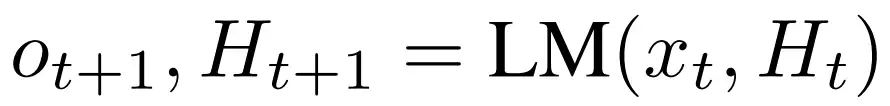
而 p(a|x) 在这的作用是,判断当前生成是否接近属性 a 的需求,根据反馈,去修改之前的历史 H,之后语言模型根据新历史来生成更接近属性 a 需求的句子。
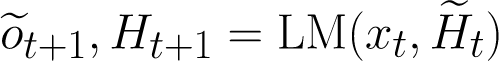
一个好玩的比方是把这个看作时间旅行,比如说大雄跑到未来瞅瞅静香是不是嫁给了他,如果没有就回去改变历史,然后得到一个基于新历史的结果。如何改变历史呢,现实中当然还未实现,但在这里,就可以用到我们的老朋友,反向传播。
通过每次 p(a|x) 的误差传播,可以获得一个梯度,之后用这个更新过去的历史,就可以获得一个新的历史:
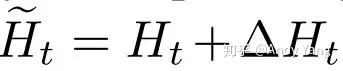
变更后的历史就能比较大的概率让语言模型生成我们想要的属性的句子,整个过程大致如下:
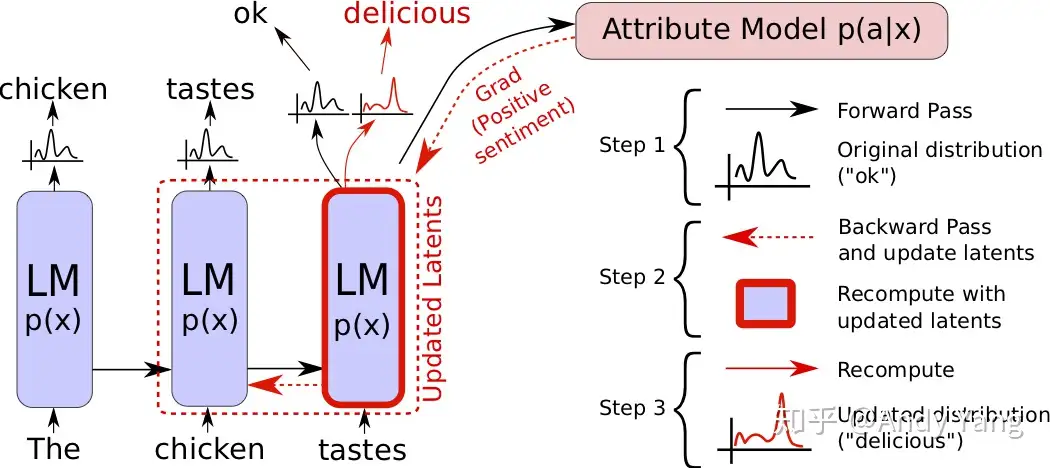
总共分三步:
- 前向过程,包括语言模型和之后的属性判别模型,之后预测出 p(a|x);
- 反向过程,根据属性判别模型回传的梯度,更新语言模型内部历史状态,使得实际预测更接近想要属性;
- 重新采样,根据获得的新输出概率分布,采样生成一个新的词。
补充一些关于历史 H,还有其梯度更新的其他信息。
- 论文中因为用的是 GPT2 语言模型,所以模型基本组件是 Transformer,所以历史 H 用的是每层 K 和 V 的值。而如果要用其他模型,也可以根据模型不同改变具体 H 实现。
- 还有实际 H 更新梯度计算时,会有数次迭代过程,其中还包括一些 normalization 和 scaling 的操作,以及很重要的强度参数 α (可调节属性影响强度),建议去读源码,更好理解。
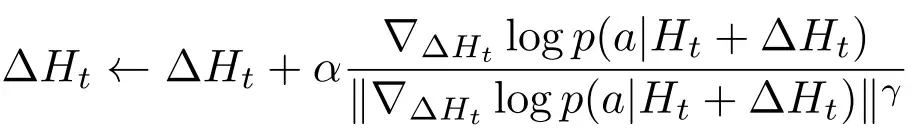
p(x) :但还得保证流利性
虽然上面赋予属性的操作很巧妙,也能保证让文本生成方向朝着属性判别器满意的方向生成,但判别器 p(a|x) 满意并不代表我们会满意。如果只用上面技巧,会导致生成一些有问题的句子,比如说要生成正面的话,那么说不定会疯狂重复,“好好好好好”,这当然不是我们想要的。
我们还是希望能够生成更多样性,并且符合语言模型的句子。因此文中采取了两个保证生成句子的语言模型尽量与原语言模型接近的方法:
- Kullback–Leibler(KL) 散度:在计算历史 H 更新值时,向其中加入一个 KL 散度损失,最小化改变前语言模型和改变后的预测概率分布的 KL 散度;
- Post-norm Geometric Mean Fusion(后范数几何平均融合?):其实就在上面训练时改变的同时,加入一个类似输出后处理的过程,直接让实际预测从下面式子中采样,让生成分布和语言模型直接绑定起来:
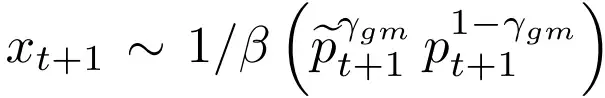
通过上面这些步骤实际上相当于完成了一个下图中的过程:
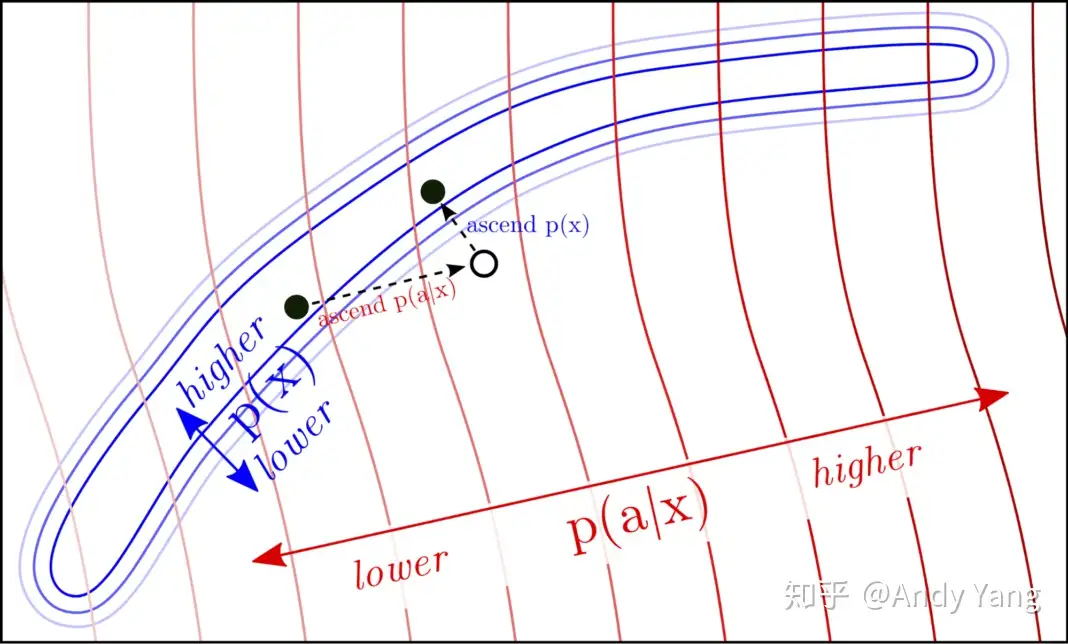
先通过 p(a|x) 让生成结果具有属性,之后让它生成接近自然语言的流畅 p(x).
属性判别器展示
关于具体的属性判别器 p(a|x),文中用了两种不同的方法。
第一种是BOW(词袋) 属性模型,没有额外参数。针对每个主题先总结一批有代表性的词,之后具体实现时只用在每个时间步上对输出概率分布取出对应词袋中词的位置,计算 loss,加和起来反向传播就行。方法虽然简单却意外有效,可以看些例子。

该方法和 weighted decoding 思想有些类似,论文中也有详细对比。
第二种是简单属性分类器,非常少参数。就是在 freeze 住大模型的情况下,拿已有的标注数据,先预训练一个分类器出来。比如文中就用感情分类数据集 SST-5,之后输入GPT2模型,最后一层向量取平均,接着输入分类器分类,训练分类器。

当然除了上面两种方法其实还能用其他分类器,毕竟 PPLM 只是提出一个大概的框架,判别器无论是什么,只要能回传梯度就行。
此外文中还做了很多实验来进行具体分析,包括特别搞笑的拿一个完全不相关词来生成具体领域的实验,看模型怎么强行生成相关文本。还有和之前的方法进行对比,也很值得一看。
能拿来干什么呢
很多了,首先控制情感的评论,还有各种具体领域文本生成,还有文中的文本去毒(detoxification),可控故事生成。
感兴趣还是看论文吧,满满的都是内容。另外关于之前有人用类似方法却没取得很好结果,根据论文作者说可能是当时语言模型还不够强大。
论文:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧