

从Autoencoder to Beta-VAE
[更新于2019-07-18:添加了关于VQ-VAE & VQ-VAE-2的部分。]
[更新于2019-07-26:添加了关于TD-VAE的部分。]
自动编码器是通过中间具有窄瓶颈层的神经网络模型来重构高维数据的(哦,这对于变分自动编码器可能不适用,我们将在后面的部分详细探讨)。一个很好的副产品是维度减少:瓶颈层捕获了压缩的潜在编码。这种低维表示可以用作各种应用中的嵌入向量(例如搜索)、帮助数据压缩或揭示底层数据生成因素。
符号表示
| 符号 | 含义 |
|---|---|
| $\mathcal{D}$ | 数据集,$\mathcal{D} = \{ \mathbf{x}^{(1)}, \mathbf{x}^{(2)}, \dots, \mathbf{x}^{(n)} \}$,包含$n$个数据样本;$\vert\mathcal{D}\vert =n $。 |
| $\mathbf{x}^{(i)}$ | 每个数据点是一个$d$维的向量,$\mathbf{x}^{(i)} = [x^{(i)}_1, x^{(i)}_2, \dots, x^{(i)}_d]$。 |
| $\mathbf{x}$ | 数据集中的一个数据样本,$\mathbf{x} \in \mathcal{D}$。 |
| $\mathbf{x}’$ | $\mathbf{x}$的重构版本。 |
| $\tilde{\mathbf{x}}$ | $\mathbf{x}$的损坏版本。 |
| $\mathbf{z}$ | 在瓶颈层中学习到的压缩代码。 |
| $a_j^{(l)}$ | 第$l$层隐藏层中第$j$个神经元的激活函数。 |
| $g_{\phi}(.)$ | 由$\phi$参数化的编码函数。 |
| $f_{\theta}(.)$ | 由$\theta$参数化的解码函数。 |
| $q_{\phi}(\mathbf{z}\vert\mathbf{x})$ | 估计的后验概率函数,也称为概率编码器。 |
| $p_{\theta}(\mathbf{x}\vert\mathbf{z})$ | 给定潜在代码生成真实数据样本的可能性,也称为概率解码器。 |
自动编码器
自动编码器是一种设计用于以无监督方式学习身份函数以重构原始输入的神经网络,同时在此过程中压缩数据,以发现更有效和更压缩的表示。这个想法起源于20世纪80年代,后来由Hinton & Salakhutdinov, 2006的开创性论文推广。
它包含两个网络:
- 编码器网络:它将原始高维输入翻译成潜在的低维代码。输入大小大于输出大小。
- 解码器网络:解码器网络从代码中恢复数据,输出层可能越来越大。

编码器网络本质上完成了降维,就像我们使用主成分分析(PCA)或矩阵分解(MF)一样。此外,自动编码器明确优化了从代码重建数据。一个好的中间表示不仅可以捕获潜在变量,还可以促进完整的解压缩过程。
该模型包含由$\phi$参数化的编码函数$g(.)$和由$\theta$参数化的解码函数$f(.)$。在瓶颈层中为输入$\mathbf{x}$学习的低维代码是$\mathbf{z} = g_\phi(\mathbf{x})$,重构的输入是$\mathbf{x}’ = f_\theta(g_\phi(\mathbf{x}))$。
参数$(\theta, \phi)$一起学习以输出与原始输入相同的重构数据样本,$\mathbf{x} \approx f_\theta(g_\phi(\mathbf{x}))$,或者换句话说,学习身份函数。有各种度量方法来量化两个向量之间的差异,例如当激活函数为sigmoid时的交叉熵,或者像MSE损失那样简单:
$$ L_\text{AE}(\theta, \phi) = \frac{1}{n}\sum_{i=1}^n (\mathbf{x}^{(i)} - f_\theta(g_\phi(\mathbf{x}^{(i)})))^2 $$
去噪自动编码器
由于自动编码器学习的是身份函数,当网络参数多于数据点时,我们面临“过拟合”的风险。
为了避免过拟合并提高鲁棒性,去噪自动编码器(Vincent等人,2008)提出了一种对基本自动编码器的修改。输入部分被通过以随机方式向输入向量添加噪声或屏蔽一些值来部分破坏,$\tilde{\mathbf{x}} \sim \mathcal{M}_\mathcal{D}(\tilde{\mathbf{x}} \vert \mathbf{x})$。然后模型被训练来恢复原始输入(注意:不是损坏的输入)。
$$ \begin{aligned} \tilde{\mathbf{x}}^{(i)} &\sim \mathcal{M}_\mathcal{D}(\tilde{\mathbf{x}}^{(i)} \vert \mathbf{x}^{(i)})\\ L_\text{DAE}(\theta, \phi) &= \frac{1}{n} \sum_{i=1}^n (\mathbf{x}^{(i)} - f_\theta(g_\phi(\tilde{\mathbf{x}}^{(i)})))^2 \end{aligned} $$
其中$\mathcal{M}_\mathcal{D}$定义了从真实数据样本到噪声或损坏样本的映射。
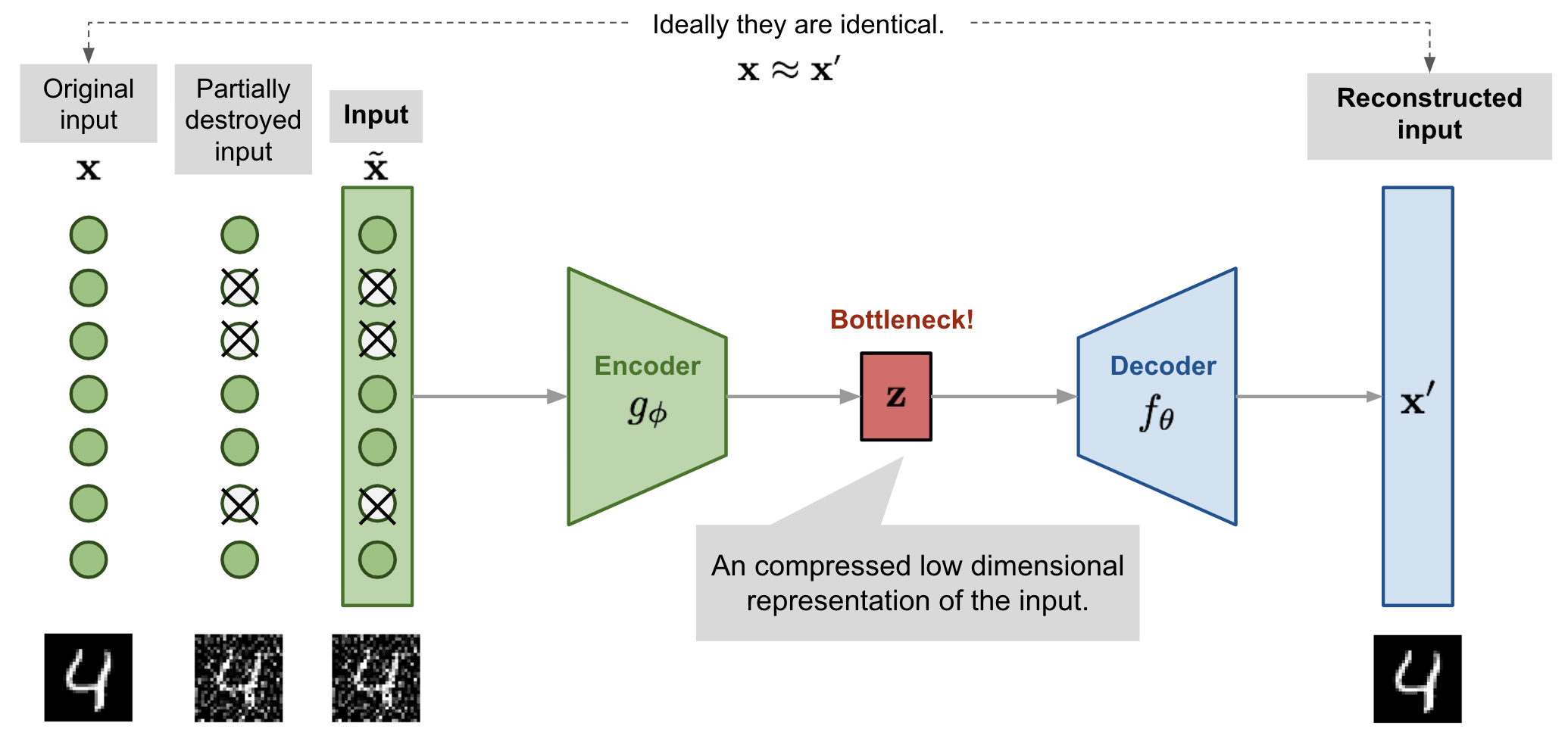
这种设计的动机是人类即使在视图部分遮挡或破坏的情况下也能轻松识别对象或场景。为了“修复”部分破坏的输入,去噪自动编码器必须发现并捕捉输入各维度之间的关系,以推断缺失部分。
对于具有高冗余度的高维输入,例如图像,模型可能依赖于从许多输入维度组合中收集的证据来恢复去噪版本,而不是过度拟合某一个维度。这为学习鲁棒的潜在表示奠定了良好的基础。
噪声由一个随机映射$\mathcal{M}_\mathcal{D}(\tilde{\mathbf{x}} \vert \mathbf{x})$控制,并且它不特定于某种类型的损坏过程(例如屏蔽噪声、高斯噪声、盐和胡椒噪声等)。自然地,损坏过程可以配备先验知识
在原始DAE论文的实验中,噪声是这样施加的:随机选择固定比例的输入维度,并将它们的值强制为0。听起来很像dropout,对吧?好吧,去噪自动编码器是在2008年提出的,比dropout论文(Hinton等人,2012)早4年 ;)。
稀疏自动编码器
稀疏自动编码器在隐藏单元激活上应用了“稀疏”约束,以避免过拟合并提高鲁棒性。它迫使模型在同一时间内只有少量隐藏单元被激活,或者换句话说,一个隐藏神经元大部分时间应该是未激活状态。
回想一下常见的激活函数包括sigmoid、tanh、relu、leaky relu等。当值接近1时神经元被激活,当值接近0时未激活。
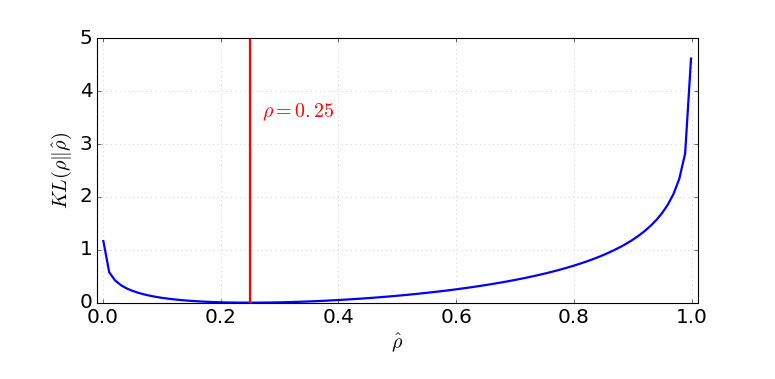
假设在第$l$层隐藏层中有$s_l$个神经元,这层中第$j$个神经元的激活函数标记为$a^{(l)}_j(.)$,$j=1, \dots, s_l$。该神经元的激活分数$\hat{\rho}_j$预期是一个小数$\rho$,称为稀疏参数;一个常见的配置是$\rho = 0.05$。
$$ \hat{\rho}_j^{(l)} = \frac{1}{n} \sum_{i=1}^n [a_j^{(l)}(\mathbf{x}^{(i)})] \approx \rho $$
这种约束通过在损失函数中添加一个惩罚项来实现。KL散度$D_\text{KL}$测量两个伯努利分布之间的差异,一个均值为$\rho$,另一个均值为$\hat{\rho}_j^{(l)}$。超参数$\beta$控制我们希望在稀疏损失上施加的惩罚力度。
$$ \begin{aligned} L_\text{SAE}(\theta) &= L(\theta) + \beta \sum_{l=1}^L \sum_{j=1}^{s_l} D_\text{KL}(\rho \| \hat{\rho}_j^{(l)}) \\ &= L(\theta) + \beta \sum_{l=1}^L \sum_{j=1}^{s_l} \rho\log\frac{\rho}{\hat{\rho}_j^{(l)}} + (1-\rho)\log\frac{1-\rho}{1-\hat{\rho}_j^{(l)}} \end{aligned} $$
$k$-稀疏自动编码器
在$k$-稀疏自动编码器(Makhzani 和 Frey, 2013)中,通过仅保留瓶颈层中线性激活函数的前k个最高激活来强制稀疏性。 首先我们通过编码器网络进行前向传递以获取压缩代码:$\mathbf{z} = g(\mathbf{x})$。 对代码向量$\mathbf{z}$中的值进行排序。仅保留k个最大值,而其他神经元设置为0。这也可以在具有可调阈值的ReLU层中完成。现在我们有了稀疏化的代码:$\mathbf{z}’ = \text{Sparsify}(\mathbf{z})$。 计算输出和稀疏代码的损失,$L = |\mathbf{x} - f(\mathbf{z}’) |_2^2$。 并且,反向传播仅通过前k个激活的隐藏单元!

收缩自动编码器
与稀疏自动编码器类似,收缩自动编码器(Rifai等人,2011)鼓励学习到的表示保持在一个收缩空间中,以提高鲁棒性。
它在损失函数中添加一个项以惩罚表示对输入的敏感性,从而提高对训练数据点周围小扰动的鲁棒性。敏感性通过编码器激活相对于输入的雅可比矩阵的Frobenius范数来测量:
$$ \|J_f(\mathbf{x})\|_F^2 = \sum_{ij} \Big( \frac{\partial h_j(\mathbf{x})}{\partial x_i} \Big)^2 $$
其中$h_j$是压缩代码$\mathbf{z} = f(x)$中的一个单元输出。
这一惩罚项是所有学习到的编码相对于输入维度的偏导数的平方和。作者声称,经验上发现这一惩罚雕刻出一个表示,对应于更低维的非线性流形,同时对与流形正交的大多数方向保持更不变。
VAE:变分自动编码器
变分自动编码器(Kingma & Welling, 2014),简称VAE,实际上与上述所有自动编码器模型相似度较低,但深深植根于变分贝叶斯和图模型的方法中。
我们希望将输入映射到一个分布中,而不是固定向量。让我们将这个分布标记为$p_\theta$,由$\theta$参数化。数据输入$\mathbf{x}$与潜在编码向量$\mathbf{z}$之间的关系可以完全由以下三者定义:
- 先验$p_\theta(\mathbf{z})$
- 似然$p_\theta(\mathbf{x}\vert\mathbf{z})$
- 后验$p_\theta(\mathbf{z}\vert\mathbf{x})$
假设我们知道这个分布的真实参数$\theta^{*}$。为了生成一个看起来像真实数据点$\mathbf{x}^{(i)}$的样本,我们按照以下步骤进行:
- 首先,从先验分布$p_{\theta^*}(\mathbf{z})$中采样一个$\mathbf{z}^{(i)}$。
- 然后,从条件分布$p_{\theta^*}(\mathbf{x} \vert \mathbf{z} = \mathbf{z}^{(i)})$中生成一个值$\mathbf{x}^{(i)}$。
最佳参数$\theta^{*}$是使生成真实数据样本的概率最大的参数:
$$ \theta^{*} = \arg\max_\theta \prod_{i=1}^n p_\theta(\mathbf{x}^{(i)}) $$
我们通常使用对数概率将右侧的乘积转换为和:
$$ \theta^{*} = \arg\max_\theta \sum_{i=1}^n \log p_\theta(\mathbf{x}^{(i)}) $$
现在让我们更新这个方程,以更好地展示数据生成过程,以便涉及编码向量:
$$ p_\theta(\mathbf{x}^{(i)}) = \int p_\theta(\mathbf{x}^{(i)}\vert\mathbf{z}) p_\theta(\mathbf{z}) d\mathbf{z} $$
不幸的是,这种方式计算$p_\theta(\mathbf{x}^{(i)})$并不容易,因为检查所有可能的$\mathbf{z}$值并将它们相加非常昂贵。为了缩小值空间以便于更快的搜索,我们希望引入一个新的近似函数,输出给定输入$\mathbf{x}$时可能的编码,$q_\phi(\mathbf{z}\vert\mathbf{x})$,由$\phi$参数化。
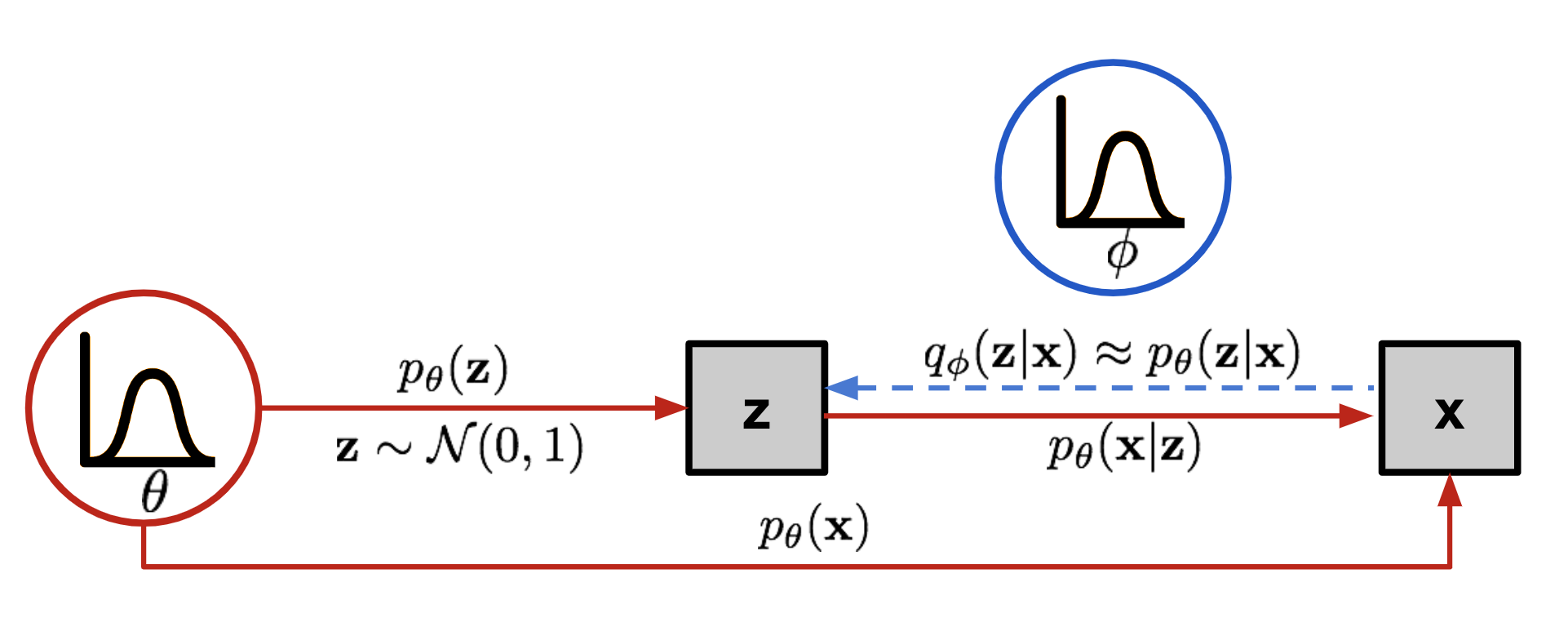
现在的结构看起来很像自动编码器:
- 条件概率$p_\theta(\mathbf{x} \vert \mathbf{z})$定义了一个生成模型,类似于上面介绍的解码器$f_\theta(\mathbf{x} \vert \mathbf{z})$。$p_\theta(\mathbf{x} \vert \mathbf{z})$也被称为概率解码器。
- 近似函数$q_\phi(\mathbf{z} \vert \mathbf{x})$是概率编码器,扮演与上面的$g_\phi(\mathbf{z} \vert \mathbf{x})$相似的角色。
损失函数:ELBO
估计的后验$q_\phi(\mathbf{z}\vert\mathbf{x})$应该非常接近真实后验$p_\theta(\mathbf{z}\vert\mathbf{x})$。我们可以使用Kullback-Leibler散度来量化这两个分布之间的距离。KL散度$D_\text{KL}(X|Y)$测量如果用分布Y表示X丢失了多少信息。
在我们的情况下,我们希望最小化$D_\text{KL}( q_\phi(\mathbf{z}\vert\mathbf{x}) | p_\theta(\mathbf{z}\vert\mathbf{x}) )$相对于$\phi$。
但为什么使用$D_\text{KL}(q_\phi | p_\theta)$(反向KL)而不是$D_\text{KL}(p_\theta | q_\phi)$(前向KL)?Eric Jang在他的贝叶斯变分方法博文中对此有很好的解释。快速回顾一下:
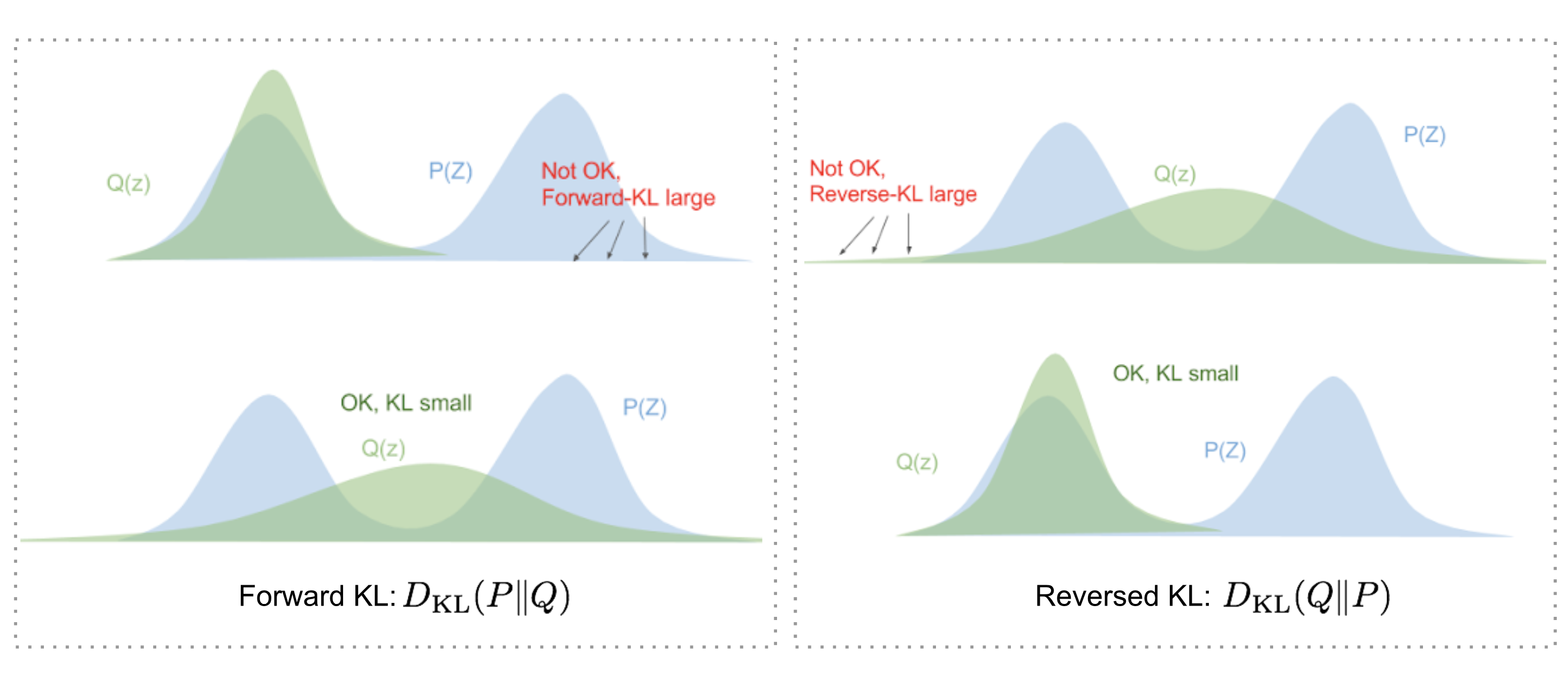
- 前向KL散度:$D_\text{KL}(P|Q) = \mathbb{E}_{z\sim P(z)} \log\frac{P(z)}{Q(z)}$;我们必须确保Q(z)>0,在P(z)>0的任何地方。优化后的变分分布$q(z)$必须覆盖整个$p(z)$。
- 反向KL散度:$D_\text{KL}(Q|P) = \mathbb{E}_{z\sim Q(z)} \log\frac{Q(z)}{P(z)}$;最小化反向KL散度将$Q(z)$挤在$P(z)$下。
现在让我们展开方程:
$$ \begin{aligned} & D_\text{KL}( q_\phi(\mathbf{z}\vert\mathbf{x}) \| p_\theta(\mathbf{z}\vert\mathbf{x}) ) & \\ &=\int q_\phi(\mathbf{z} \vert \mathbf{x}) \log\frac{q_\phi(\mathbf{z} \vert \mathbf{x})}{p_\theta(\mathbf{z} \vert \mathbf{x})} d\mathbf{z} & \\ &=\int q_\phi(\mathbf{z} \vert \mathbf{x}) \log\frac{q_\phi(\mathbf{z} \vert \mathbf{x})p_\theta(\mathbf{x})}{p_\theta(\mathbf{z}, \mathbf{x})} d\mathbf{z} & \scriptstyle{\text{; 因为 }p(z \vert x) = p(z, x) / p(x)} \\ &=\int q_\phi(\mathbf{z} \vert \mathbf{x}) \big( \log p_\theta(\mathbf{x}) + \log\frac{q_\phi(\mathbf{z} \vert \mathbf{x})}{p_\theta(\mathbf{z}, \mathbf{x})} \big) d\mathbf{z} & \\ &=\log p_\theta(\mathbf{x}) + \int q_\phi(\mathbf{z} \vert \mathbf{x})\log\frac{q_\phi(\mathbf{z} \vert \mathbf{x})}{p_\theta(\mathbf{z}, \mathbf{x})} d\mathbf{z} & \scriptstyle{\text{; 因为 }\int q(z \vert x) dz = 1}\\ &=\log p_\theta(\mathbf{x}) + \int q_\phi(\mathbf{z} \vert \mathbf{x})\log\frac{q_\phi(\mathbf{z} \vert \mathbf{x})}{p_\theta(\mathbf{x}\vert\mathbf{z})p_\theta(\mathbf{z})} d\mathbf{z} & \scriptstyle{\text{; 因为 }p(z, x) = p(x \vert z) p(z)} \\ &=\log p_\theta(\mathbf{x}) + \mathbb{E}_{\mathbf{z}\sim q_\phi(\mathbf{z} \vert \mathbf{x})}[\log \frac{q_\phi(\mathbf{z} \vert \mathbf{x})}{p_\theta(\mathbf{z})} - \log p_\theta(\mathbf{x} \vert \mathbf{z})] &\\ &=\log p_\theta(\mathbf{x}) + D_\text{KL}(q_\phi(\mathbf{z}\vert\mathbf{x}) \| p_\theta(\mathbf{z})) - \mathbb{E}_{\mathbf{z}\sim q_\phi(\mathbf{z}\vert\mathbf{x})}\log p_\theta(\mathbf{x}\vert\mathbf{z}) & \end{aligned} $$
所以我们有:
$$ D_\text{KL}( q_\phi(\mathbf{z}\vert\mathbf{x}) \| p_\theta(\mathbf{z}\vert\mathbf{x}) ) =\log p_\theta(\mathbf{x}) + D_\text{KL}(q_\phi(\mathbf{z}\vert\mathbf{x}) \| p_\theta(\mathbf{z})) - \mathbb{E}_{\mathbf{z}\sim q_\phi(\mathbf{z}\vert\mathbf{x})}\log p_\theta(\mathbf{x}\vert\mathbf{z}) $$
一旦将方程左右两边重新排列,
$$ \log p_\theta(\mathbf{x}) - D_\text{KL}( q_\phi(\mathbf{z}\vert\mathbf{x}) \| p_\theta(\mathbf{z}\vert\mathbf{x}) ) = \mathbb{E}_{\mathbf{z}\sim q_\phi(\mathbf{z}\vert\mathbf{x})}\log p_\theta(\mathbf{x}\vert\mathbf{z}) - D_\text{KL}(q_\phi(\mathbf{z}\vert\mathbf{x}) \| p_\theta(\mathbf{z})) $$
方程的左边正是我们在学习真实分布时希望最大化的:我们希望最大化生成真实数据的(对数)似然(即$\log p_\theta(\mathbf{x})$),同时最小化真实后验分布和估计后验分布之间的差异($D_\text{KL}$项起到正则化的作用)。注意$p_\theta(\mathbf{x})$相对于$q_\phi$是固定的。
上述定义了我们的损失函数的负值:
$$ \begin{aligned} L_\text{VAE}(\theta, \phi) &= -\log p_\theta(\mathbf{x}) + D_\text{KL}( q_\phi(\mathbf{z}\vert\mathbf{x}) \| p_\theta(\mathbf{z}\vert\mathbf{x}) )\\ &= - \mathbb{E}_{\mathbf{z} \sim q_\phi(\mathbf{z}\vert\mathbf{x})} \log p_\theta(\mathbf{x}\vert\mathbf{z}) + D_\text{KL}( q_\phi(\mathbf{z}\vert\mathbf{x}) \| p_\theta(\mathbf{z}) ) \\ \theta^{*}, \phi^{*} &= \arg\min_{\theta, \phi} L_\text{VAE} \end{aligned} $$
在变分贝叶斯方法中,这个损失函数被称为变分下界,或证据下界。名称中的“下界”部分来自KL散度始终为非负值,因此$-L_\text{VAE}$是$\log p_\theta (\mathbf{x})$的下界。
$$ -L_\text{VAE} = \log p_\theta(\mathbf{x}) - D_\text{KL}( q_\phi(\mathbf{z}\vert\mathbf{x}) \| p_\theta(\mathbf{z}\vert\mathbf{x}) ) \leq \log p_\theta(\mathbf{x}) $$
因此,通过最小化损失,我们是在最大化生成真实数据样本的概率的下界。
重参数化技巧
损失函数中的期望项涉及从$q_\phi(\mathbf{z}\vert\mathbf{x})$中生成样本。采样是一个随机过程,因此我们无法反向传播梯度。为了使其可训练,引入了重参数化技巧:通常可以将随机变量$\mathbf{z}$表示为一个确定性变量$\mathbf{z} = \mathcal{T}_\phi(\mathbf{x}, \boldsymbol{\epsilon})$,其中$\boldsymbol{\epsilon}$是一个辅助独立随机变量,变换函数$\mathcal{T}_\phi$由$\phi$参数化,将$\boldsymbol{\epsilon}$转换为$\mathbf{z}$。
例如,$q_\phi(\mathbf{z}\vert\mathbf{x})$的常见形式选择是具有对角协方差结构的多元高斯分布:
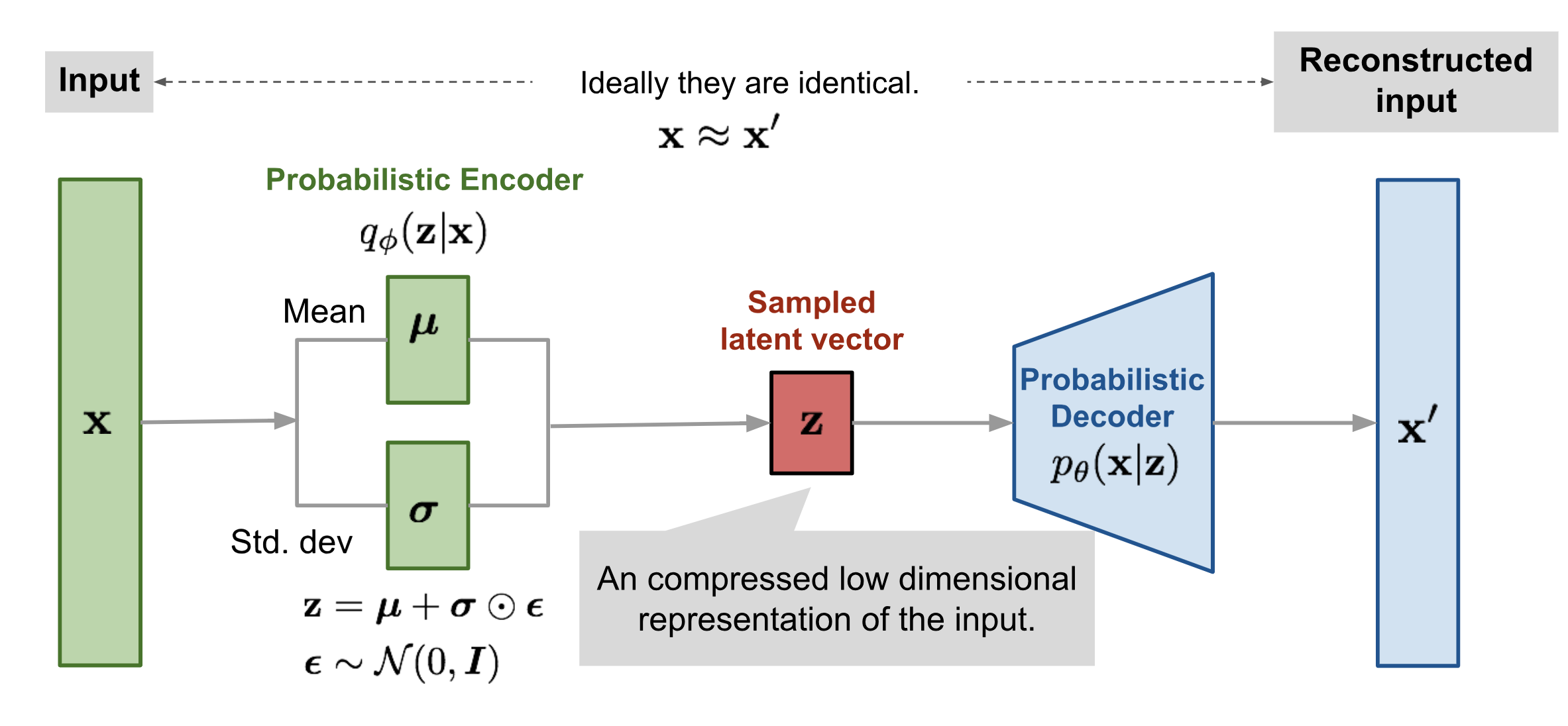
$$ \begin{aligned} \mathbf{z} &\sim q_\phi(\mathbf{z}\vert\mathbf{x}^{(i)}) = \mathcal{N}(\mathbf{z}; \boldsymbol{\mu}^{(i)}, \boldsymbol{\sigma}^{2(i)}\boldsymbol{I}) & \\ \mathbf{z} &= \boldsymbol{\mu} + \boldsymbol{\sigma} \odot \boldsymbol{\epsilon} \text{, 其中 } \boldsymbol{\epsilon} \sim \mathcal{N}(0, \boldsymbol{I}) & \scriptstyle{\text{; 重参数化技巧。}} \end{aligned} $$
其中$\odot$指的是逐元素乘积。
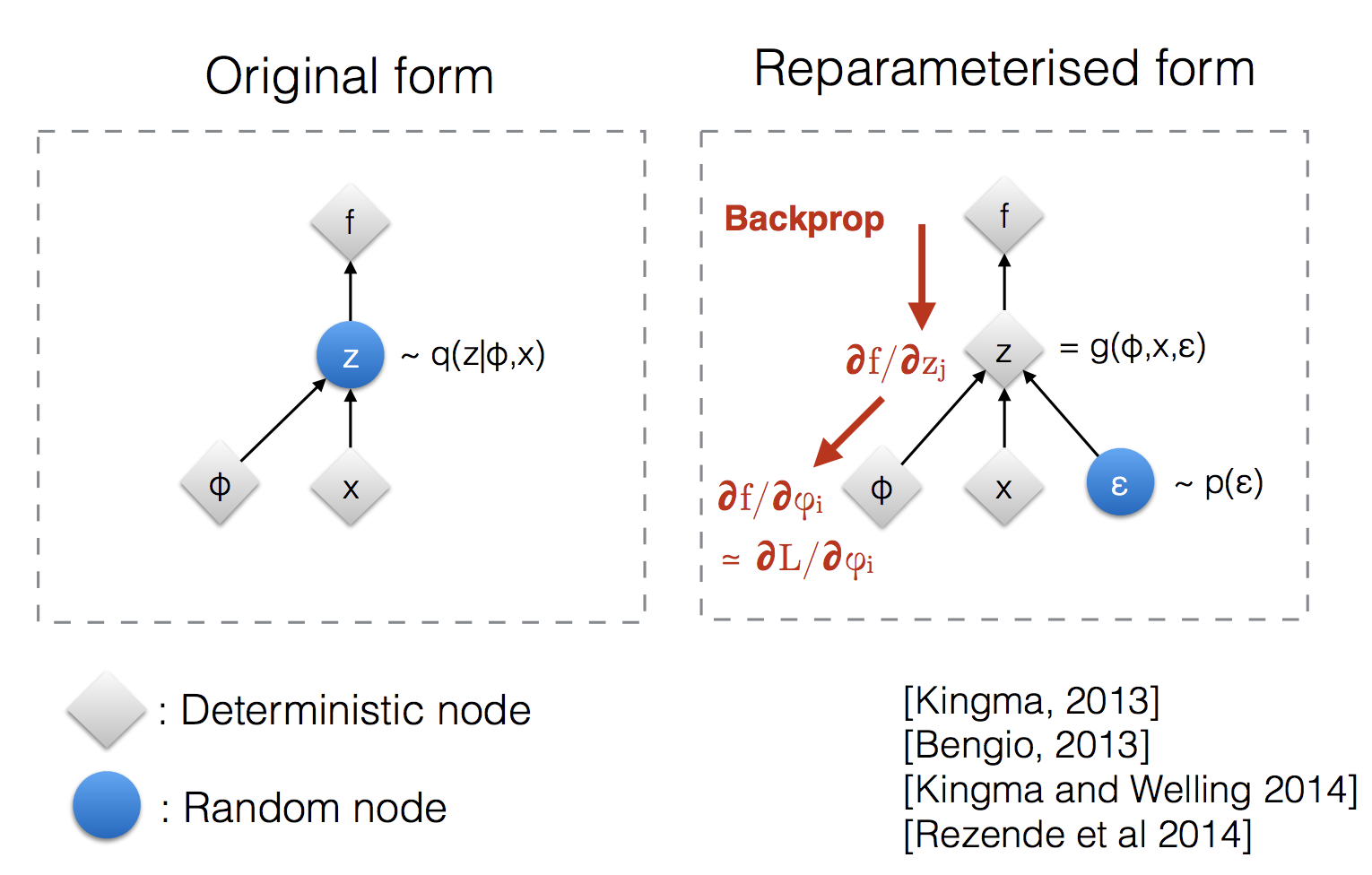
重参数化技巧也适用于其他类型的分布,不仅限于高斯分布。 在多元高斯分布的情况下,我们通过学习分布的均值和方差$\mu$和$\sigma$显式地使用重参数化技巧,使模型可训练,同时随机性仍在随机变量$\boldsymbol{\epsilon} \sim \mathcal{N}(0, \boldsymbol{I})$中。
Beta-VAE
如果推断的潜在表示$\mathbf{z}$中的每个变量仅对一个生成因素敏感并且对其他因素相对不变,我们将称这种表示为解耦或因子化。解耦表示带来的一个好处是良好的可解释性,并且易于推广到各种任务。
例如,一个在人的面部照片上训练的模型可能在不同维度上分别捕获性别、肤色、发色、发长、情绪、是否戴眼镜等许多相对独立的因素。这种解耦表示对面部图像生成非常有益。
β-VAE(Higgins等人,2017)是变分自动编码器的一种修改,特别强调发现解耦的潜在因素。遵循与VAE相同的动机,我们希望最大化生成真实数据的概率,同时保持真实和估计后验分布之间的距离较小(例如,小于一个常数$\delta$):
$$ \begin{aligned} &\max_{\phi, \theta} \mathbb{E}_{\mathbf{x}\sim\mathcal{D}}[\mathbb{E}_{\mathbf{z} \sim q_\phi(\mathbf{z}\vert\mathbf{x})} \log p_\theta(\mathbf{x}\vert\mathbf{z})]\\ &\text{subject to } D_\text{KL}(q_\phi(\mathbf{z}\vert\mathbf{x})\|p_\theta(\mathbf{z})) < \delta \end{aligned} $$
我们可以根据KKT条件,使用拉格朗日乘数$\beta$将其重写为拉格朗日方程。上述只有一个不等式约束的优化问题等价于最大化以下方程$\mathcal{F}(\theta, \phi, \beta)$:
$$ \begin{aligned} \mathcal{F}(\theta, \phi, \beta) &= \mathbb{E}_{\mathbf{z} \sim q_\phi(\mathbf{z}\vert\mathbf{x})} \log p_\theta(\mathbf{x}\vert\mathbf{z}) - \beta(D_\text{KL}(q_\phi(\mathbf{z}\vert\mathbf{x})\|p_\theta(\mathbf{z})) - \delta) & \\ & = \mathbb{E}_{\mathbf{z} \sim q_\phi(\mathbf{z}\vert\mathbf{x})} \log p_\theta(\mathbf{x}\vert\mathbf{z}) - \beta D_\text{KL}(q_\phi(\mathbf{z}\vert\mathbf{x})\|p_\theta(\mathbf{z})) + \beta \delta & \\ & \geq \mathbb{E}_{\mathbf{z} \sim q_\phi(\mathbf{z}\vert\mathbf{x})} \log p_\theta(\mathbf{x}\vert\mathbf{z}) - \beta D_\text{KL}(q_\phi(\mathbf{z}\vert\mathbf{x})\|p_\theta(\mathbf{z})) & \scriptstyle{\text{; 因为 }\beta,\delta\geq 0} \end{aligned} $$
β-VAE的损失函数定义为:
$$ L_\text{BETA}(\phi, \beta) = - \mathbb{E}_{\mathbf{z} \sim q_\phi(\mathbf{z}\vert\mathbf{x})} \log p_\theta(\mathbf{x}\vert\mathbf{z}) + \beta D_\text{KL}(q_\phi(\mathbf{z}\vert\mathbf{x})\|p_\theta(\mathbf{z})) $$
其中拉格朗日乘数$\beta$被视为一个超参数。
由于$L_\text{BETA}(\phi, \beta)$的负值是拉格朗日$\mathcal{F}(\theta, \phi, \beta)$的下界。最小化损失等价于最大化拉格朗日,从而适用于我们的初始优化问题。
当$\beta=1$时,与VAE相同。当$\beta > 1$时,它对潜在瓶颈施加了更强的约束,限制了$\mathbf{z}$的表示能力。对于某些条件独立的生成因素,使它们解耦是最有效的表示。因此,较高的$\beta$鼓励更有效的潜在编码,并进一步鼓励解耦。同时,较高的$\beta$可能在重构质量和解耦程度之间产生权衡。
Burgess等人(2017)深入讨论了β-VAE中的解耦,灵感来自信息瓶颈理论,并进一步提出了对β-VAE的修改,以更好地控制编码表示能力。
VQ-VAE 和 VQ-VAE-2
VQ-VAE(“向量量化-变分自动编码器”;van den Oord等人,2017)模型通过编码器学习离散潜在变量,因为离散表示可能更适合语言、语音、推理等问题。
向量量化(VQ)是一种将$K$维向量映射到有限集合“代码”向量的方法。这个过程非常类似于KNN算法。样本应映射到的最佳中心代码向量是欧几里得距离最小的那个。
设$\mathbf{e} \in \mathbb{R}^{K \times D}, i=1, \dots, K$为VQ-VAE中的潜在嵌入空间(也称为“代码簿”),其中$K$是潜在变量类别的数量,$D$是嵌入大小。单个嵌入向量为$\mathbf{e}_i \in \mathbb{R}^{D}, i=1, \dots, K$。
编码器输出$E(\mathbf{x}) = \mathbf{z}_e$通过最近邻查找匹配到$K$个嵌入向量中的一个,然后这个匹配的代码向量成为解码器$D(.)$的输入:
$$ \mathbf{z}_q(\mathbf{x}) = \text{Quantize}(E(\mathbf{x})) = \mathbf{e}_k \text{ where } k = \arg\min_i \|E(\mathbf{x}) - \mathbf{e}_i \|_2 $$
请注意,不同应用中的离散潜在变量可以具有不同的形状;例如,语音是1D,图像是2D,视频是3D。
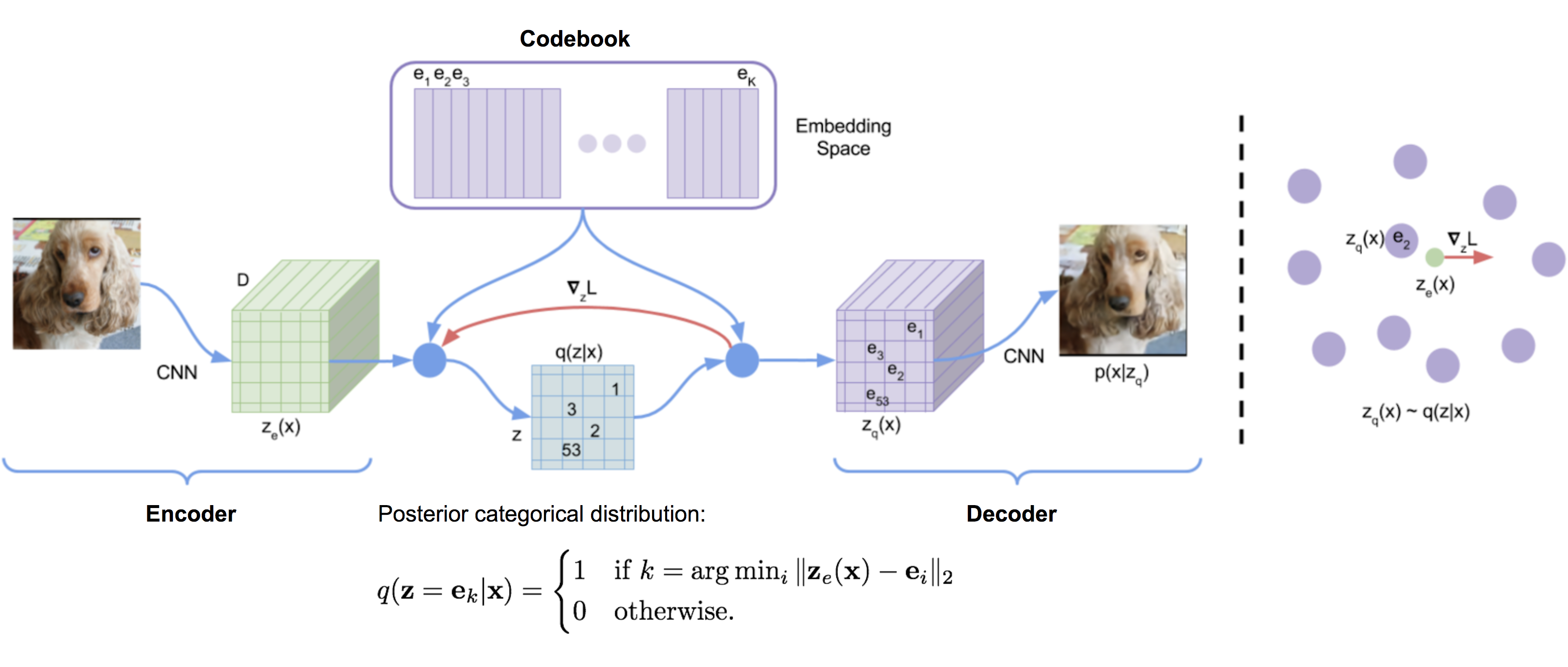
由于argmin()在离散空间上是不可微的,解码器输入$\mathbf{z}_q$的梯度$\nabla_z L$被复制到编码器输出$\mathbf{z}_e$。除了重构损失外,VQ-VAE还优化:
- VQ损失:嵌入空间和编码器输出之间的L2误差。
- 承诺损失:一种鼓励编码器输出接近嵌入空间并防止其在一个代码向量和另一个之间频繁波动的度量。
$$ L = \underbrace{\|\mathbf{x} - D(\mathbf{e}_k)\|_2^2}_{\textrm{reconstruction loss}} + \underbrace{\|\text{sg}[E(\mathbf{x})] - \mathbf{e}_k\|_2^2}_{\textrm{VQ loss}} + \underbrace{\beta \|E(\mathbf{x}) - \text{sg}[\mathbf{e}_k]\|_2^2}_{\textrm{commitment loss}} $$
其中$\text{sq}[.]$是stop_gradient操作符。
代码簿中的嵌入向量通过EMA(指数移动平均)更新。给定一个代码向量$\mathbf{e}_i$,假设我们有$n_i$个编码器输出向量$\{\mathbf{z}_{i,j}\}_{j=1}^{n_i}$,这些向量被量化为$\mathbf{e}_i$:
$$ N_i^{(t)} = \gamma N_i^{(t-1)} + (1-\gamma)n_i^{(t)}\;\;\; \mathbf{m}_i^{(t)} = \gamma \mathbf{m}_i^{(t-1)} + (1-\gamma)\sum_{j=1}^{n_i^{(t)}}\mathbf{z}_{i,j}^{(t)}\;\;\; \mathbf{e}_i^{(t)} = \mathbf{m}_i^{(t)} / N_i^{(t)} $$
其中$(t)$指的是时间上的批处理序列。$N_i$和$\mathbf{m}_i$分别是累积的向量计数和体积。
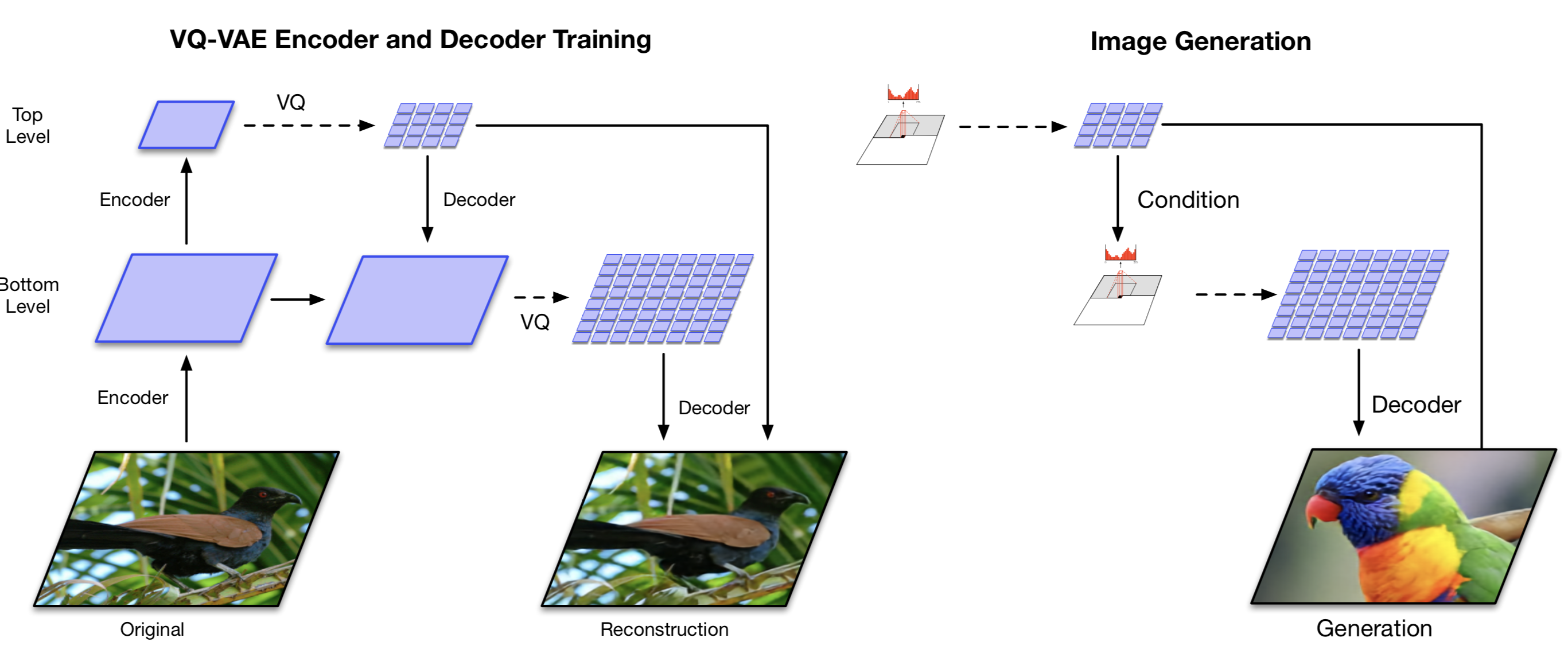
VQ-VAE-2(Ali Razavi等人,2019)是一个结合了自注意力自回归模型的两级层次VQ-VAE。
- 第一阶段是训练一个层次VQ-VAE:层次潜变量的设计旨在分离局部模式(例如,纹理)和全局信息(例如,对象形状)。较大的底层代码簿的训练也以较小的顶层代码为条件,因此不必从头开始学习。
- 第二阶段是学习潜在离散代码簿的先验,以便我们从中采样并生成图像。通过这种方式,解码器可以接收从训练中采样的类似分布的输入向量。一个强大的自回归模型结合了多头自注意力层,用于捕捉先验分布(如PixelSNAIL;Chen等人,2017)。
考虑到VQ-VAE-2依赖于在简单的层次设置中配置的离散潜变量,其生成图像的质量非常惊人。

TD-VAE
TD-VAE(“时差VAE”;Gregor等人,2019)处理序列数据。它依赖于以下三个主要思想。
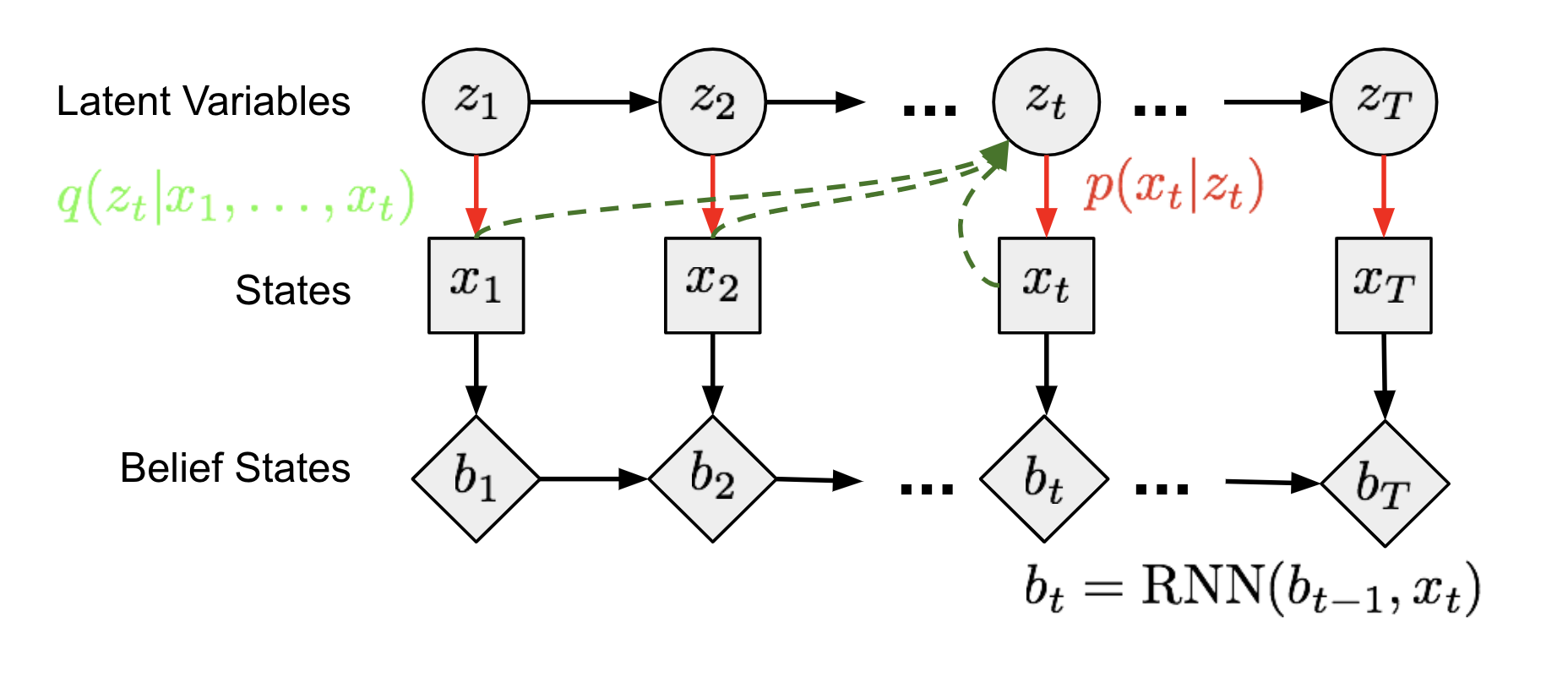
1. 状态空间模型
在(潜在的)状态空间模型中,一系列未观察到的隐藏状态$\mathbf{z} = (z_1, \dots, z_T)$决定了观察状态$\mathbf{x} = (x_1, \dots, x_T)$。图13中的每个时间步可以类似于图6中的方法进行训练,其中不可解的后验$p(z \vert x)$由一个函数$q(z \vert x)$近似。
2. 信念状态
一个智能体应该学会编码所有的过去状态来推理未来,称为信念状态,$b_t = belief(x_1, \dots, x_t) = belief(b_{t-1}, x_t)$。基于此,过去条件下的未来状态分布可以写为$p(x_{t+1}, \dots, x_T \vert x_1, \dots, x_t) \approx p(x_{t+1}, \dots, x_T \vert b_t)$。在TD-VAE中,循环策略中的隐藏状态被用作智能体的信念状态。因此我们有$b_t = \text{RNN}(b_{t-1}, x_t)$。
3. 跳跃预测
此外,一个智能体应能够根据迄今收集的所有信息来想象遥远的未来,这表明它具有进行跳跃预测的能力,即预测几步后的状态。
回想我们从上文的方差下界中学到的知识:
$$ \begin{aligned} \log p(x) &\geq \log p(x) - D_\text{KL}(q(z|x)\|p(z|x)) \\ &= \mathbb{E}_{z\sim q} \log p(x|z) - D_\text{KL}(q(z|x)\|p(z)) \\ &= \mathbb{E}_{z \sim q} \log p(x|z) - \mathbb{E}_{z \sim q} \log \frac{q(z|x)}{p(z)} \\ &= \mathbb{E}_{z \sim q}[\log p(x|z) -\log q(z|x) + \log p(z)] \\ &= \mathbb{E}_{z \sim q}[\log p(x, z) -\log q(z|x)] \\ \log p(x) &\geq \mathbb{E}_{z \sim q}[\log p(x, z) -\log q(z|x)] \end{aligned} $$
现在让我们将状态$x_t$的分布建模为一个概率函数,该函数以所有过去状态$x_{<t}$和当前时间步及前一步的两个潜变量$z_t$和$z_{t-1}$为条件:
$$ \log p(x_t|x_{<{t}}) \geq \mathbb{E}_{(z_{t-1}, z_t) \sim q}[\log p(x_t, z_{t-1}, z_{t}|x_{<{t}}) -\log q(z_{t-1}, z_t|x_{\leq t})] $$
继续展开这个方程:
$$ \begin{aligned} & \log p(x_t|x_{<{t}}) \\ &\geq \mathbb{E}_{(z_{t-1}, z_t) \sim q}[\log p(x_t, z_{t-1}, z_{t}|x_{<{t}}) -\log q(z_{t-1}, z_t|x_{\leq t})] \\ &\geq \mathbb{E}_{(z_{t-1}, z_t) \sim q}[\log p(x_t|\color{red}{z_{t-1}}, z_{t}, \color{red}{x_{<{t}}}) + \color{blue}{\log p(z_{t-1}, z_{t}|x_{<{t}})} -\log q(z_{t-1}, z_t|x_{\leq t})] \\ &\geq \mathbb{E}_{(z_{t-1}, z_t) \sim q}[\log p(x_t|z_{t}) + \color{blue}{\log p(z_{t-1}|x_{<{t}})} + \color{blue}{\log p(z_{t}|z_{t-1})} - \color{green}{\log q(z_{t-1}, z_t|x_{\leq t})}] \\ &\geq \mathbb{E}_{(z_{t-1}, z_t) \sim q}[\log p(x_t|z_{t}) + \log p(z_{t-1}|x_{<{t}}) + \log p(z_{t}|z_{t-1}) - \color{green}{\log q(z_t|x_{\leq t})} - \color{green}{\log q(z_{t-1}|z_t, x_{\leq t})}] \end{aligned} $$
注意两件事:
- 根据马尔可夫假设,红色项可以忽略。
- 根据马尔可夫假设,蓝色项被展开。
- 绿色项被展开以包括一个回到过去的单步预测,作为平滑分布。
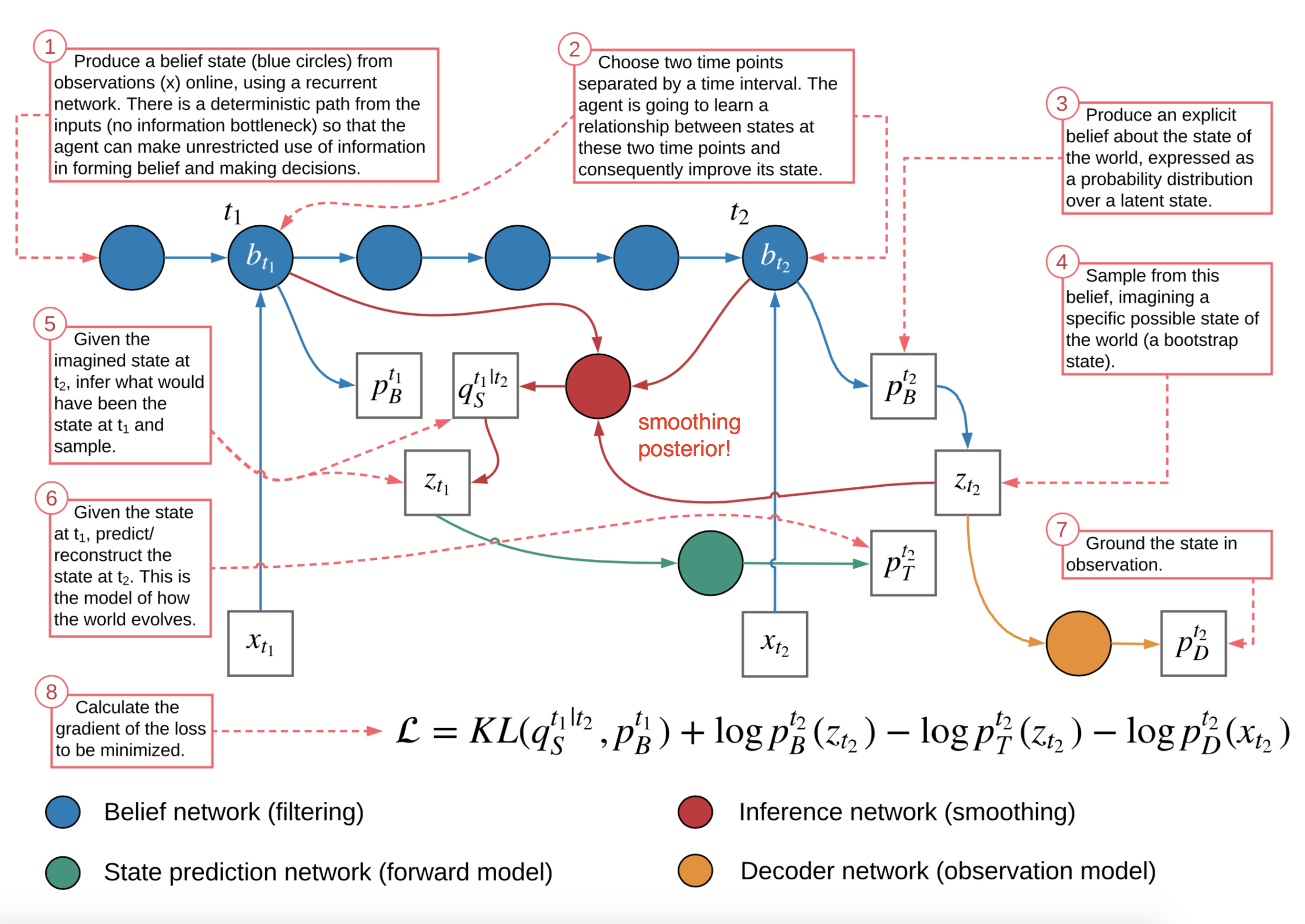
具体来说,有四种类型的分布需要学习:
- $p_D(.)$是解码器分布:
- $p(x_t \mid z_t)$按常见定义是编码器;
- $p(x_t \mid z_t) \to p_D(x_t \mid z_t)$;
- $p_T(.)$是转移分布:
- $p(z_t \mid z_{t-1})$捕捉潜变量之间的序列依赖性;
- $p(z_t \mid z_{t-1}) \to p_T(z_t \mid z_{t-1})$;
- $p_B(.)$是信念分布:
- $p(z_{t-1} \mid x_{<t})$和$q(z_t \mid x_{\leq t})$都可以使用信念状态来预测潜变量;
- $p(z_{t-1} \mid x_{<t}) \to p_B(z_{t-1} \mid b_{t-1})$;
- $q(z_{t} \mid x_{\leq t}) \to p_B(z_t \mid b_t)$;
- $p_S(.)$是平滑分布:
- 回到过去的平滑项$q(z_{t-1} \mid z_t, x_{\leq t})$也可以依赖于信念状态;
- $q(z_{t-1} \mid z_t, x_{\leq t}) \to p_S(z_{t-1} \mid z_t, b_{t-1}, b_t)$;
为了融入跳跃预测的想法,顺序ELBO不仅要在$t, t+1$上工作,还要在两个时间戳$t_1 < t_2$上工作。这是最终的TD-VAE目标函数,以最大化:
$$ J_{t_1, t_2} = \mathbb{E}[ \log p_D(x_{t_2}|z_{t_2}) + \log p_B(z_{t_1}|b_{t_1}) + \log p_T(z_{t_2}|z_{t_1}) - \log p_B(z_{t_2}|b_{t_2}) - \log p_S(z_{t_1}|z_{t_2}, b_{t_1}, b_{t_2})] $$
引用如下:
@article{weng2018VAE,
title = "From Autoencoder to Beta-VAE",
author = "Weng, Lilian",
journal = "lilianweng.github.io",
year = "2018",
url = "https://lilianweng.github.io/posts/2018-08-12-vae/"
}
参考文献
[1] Geoffrey E. Hinton, and Ruslan R. Salakhutdinov.

