

一篇deffusion的博客
[2021-09-19更新:强烈推荐Yang Song的这篇关于基于得分的生成建模的博文(几篇参考文献的主要作者)]。
[2022-08-27更新:添加了无分类器引导,GLIDE,unCLIP和Imagen。
[2022-08-31更新:添加了潜在扩散模型。
[2024-04-13更新:添加了渐进蒸馏,一致性模型,和模型架构部分。
到目前为止,我已经写了三种生成模型,GAN,VAE和基于流的模型。它们在生成高质量样本方面取得了巨大的成功,但每种模型都有其自身的局限性。由于对抗训练的性质,GAN模型的训练可能不稳定且生成的多样性较差。VAE依赖于代理损失函数。流模型必须使用专门的架构来构建可逆变换。
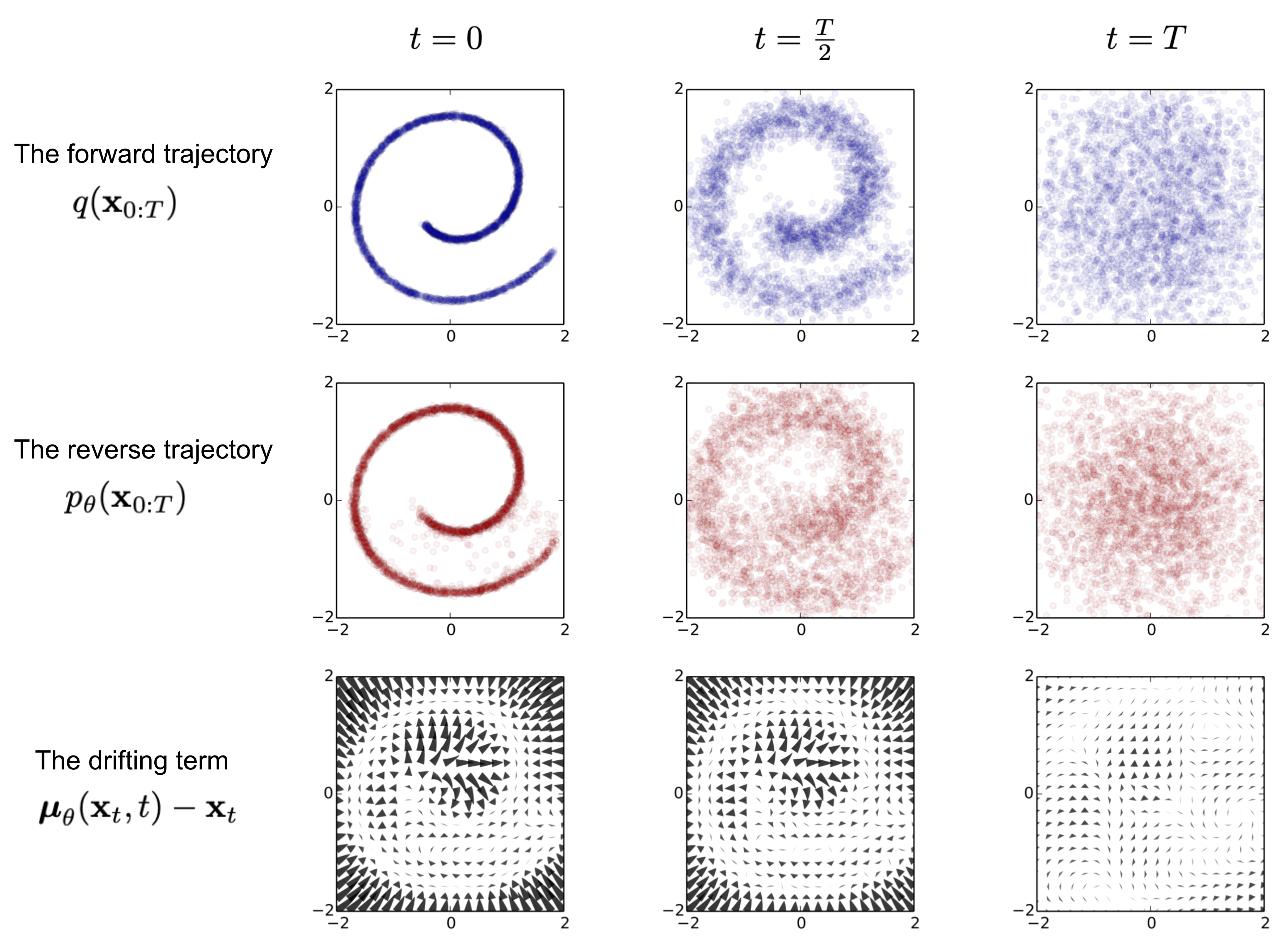
扩散模型受到非*衡热力学的启发。它们定义了一个马尔可夫链的扩散步骤,通过逐步向数据添加随机噪声,然后学习逆转扩散过程,从噪声中构造所需的数据样本。与VAE或流模型不同,扩散模型通过固定的程序进行学习,潜变量具有与原始数据相同的高维度。

什么是扩散模型?
已经提出了几种基于扩散的生成模型,它们具有相似的基本思想,包括扩散概率模型(Sohl-Dickstein等,2015)、噪声条件得分网络(NCSN;Yang & Ermon,2019)和去噪扩散概率模型(DDPM;Ho等,2020)。
正向扩散过程
给定一个从真实数据分布中采样的数据点
随着步骤
上述过程的一个好处是,我们可以使用重新参数化技巧在任何任意时间步
(*) 回想一下,当我们合并两个具有不同方差的高斯分布
通常,当样本变得更嘈杂时,我们可以负担得起更大的更新步长,所以
与随机梯度朗之万动力学的联系
朗之万动力学是物理学中的一个概念,专为统计建模分子系统而开发。结合随机梯度下降,随机梯度朗之万动力学(Welling & Teh 2011)可以使用马尔可夫链中的更新中的梯度
其中
与标准SGD相比,随机梯度朗之万动力学将高斯噪声注入参数更新中,以避免陷入局部最小值。
逆向扩散过程
如果我们能够逆转上述过程并从
值得注意的是,当以
使用贝叶斯规则,我们有:
其中
由于良好的性质,我们可以表示
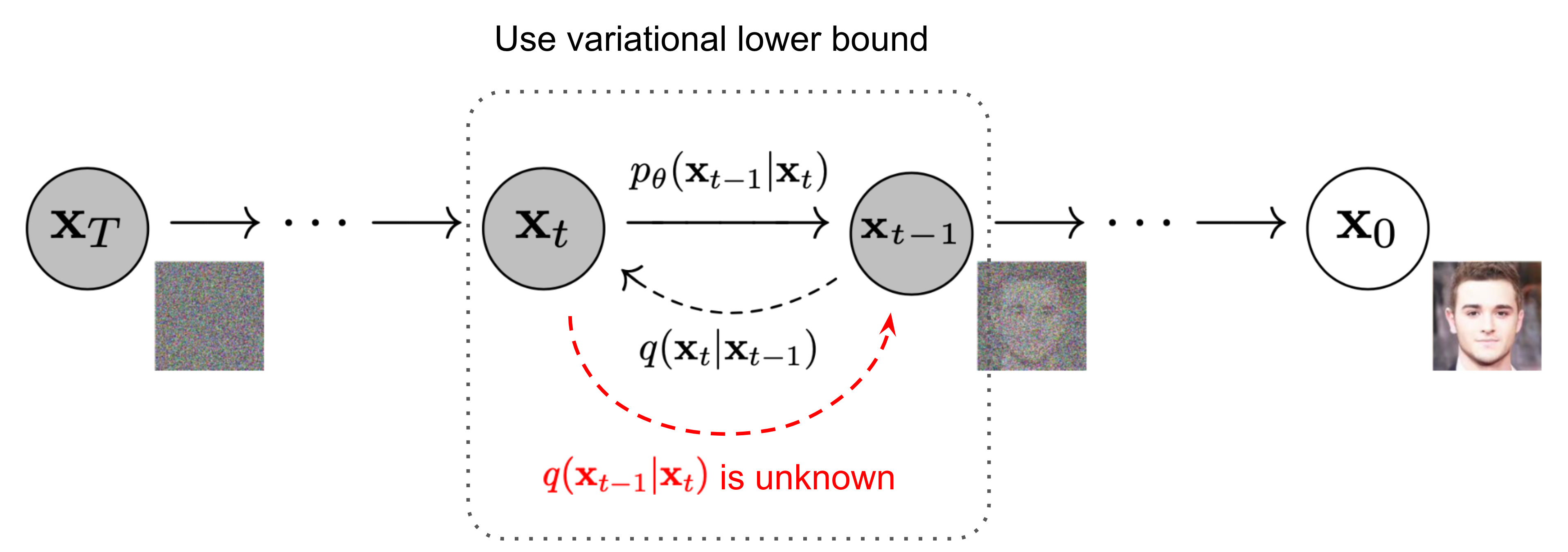
如图2所示,这种设置与VAE非常相似,因此我们可以使用变分下界优化负对数似然。
同样使用詹森不等式可以很容易得到相同的结果。假设我们希望将交叉熵最小化作为学习目标,
为了将方程中的每一项转换为可解析的,我们可以将目标进一步重写为若干KL散度和熵项的组合(详见Sohl-Dickstein等,2015的附录B中的详细步骤):
让我们分别标记变分下界损失中的每个组件:
用于训练损失的
回想一下,我们需要学习一个神经网络来*似逆向扩散过程中的条件概率分布,
损失项
简化
经验上,Ho等(2020)发现训练扩散模型在忽略加权项的简化目标下效果更好:
最终的简化目标是:
其中

与噪声条件得分网络(NCSN)的联系
Song & Ermon (2019) 提出了一种基于分数的生成建模方法,通过使用通过分数匹配估计的数据分布的梯度,通过Langevin动力学生成样本。每个样本
为了使其在深度学习环境下可扩展到高维数据,他们提出使用去噪分数匹配(Vincent, 2011)或切片分数匹配(使用随机投影;Song等,2019)。去噪分数匹配向数据添加预定的小噪声
回顾一下,Langevin动力学可以使用分数
然而,根据流形假设,大多数数据预计集中在低维流形中,尽管观察到的数据看起来可能是任意高维的。这对分数估计产生了负面影响,因为数据点无法覆盖整个空间。在数据密度较低的区域,分数估计不那么可靠。加入少量高斯噪声以使扰动数据分布覆盖整个空间
增加噪声级别的时间表类似于前向扩散过程。如果我们使用扩散过程的标注,分数*似为
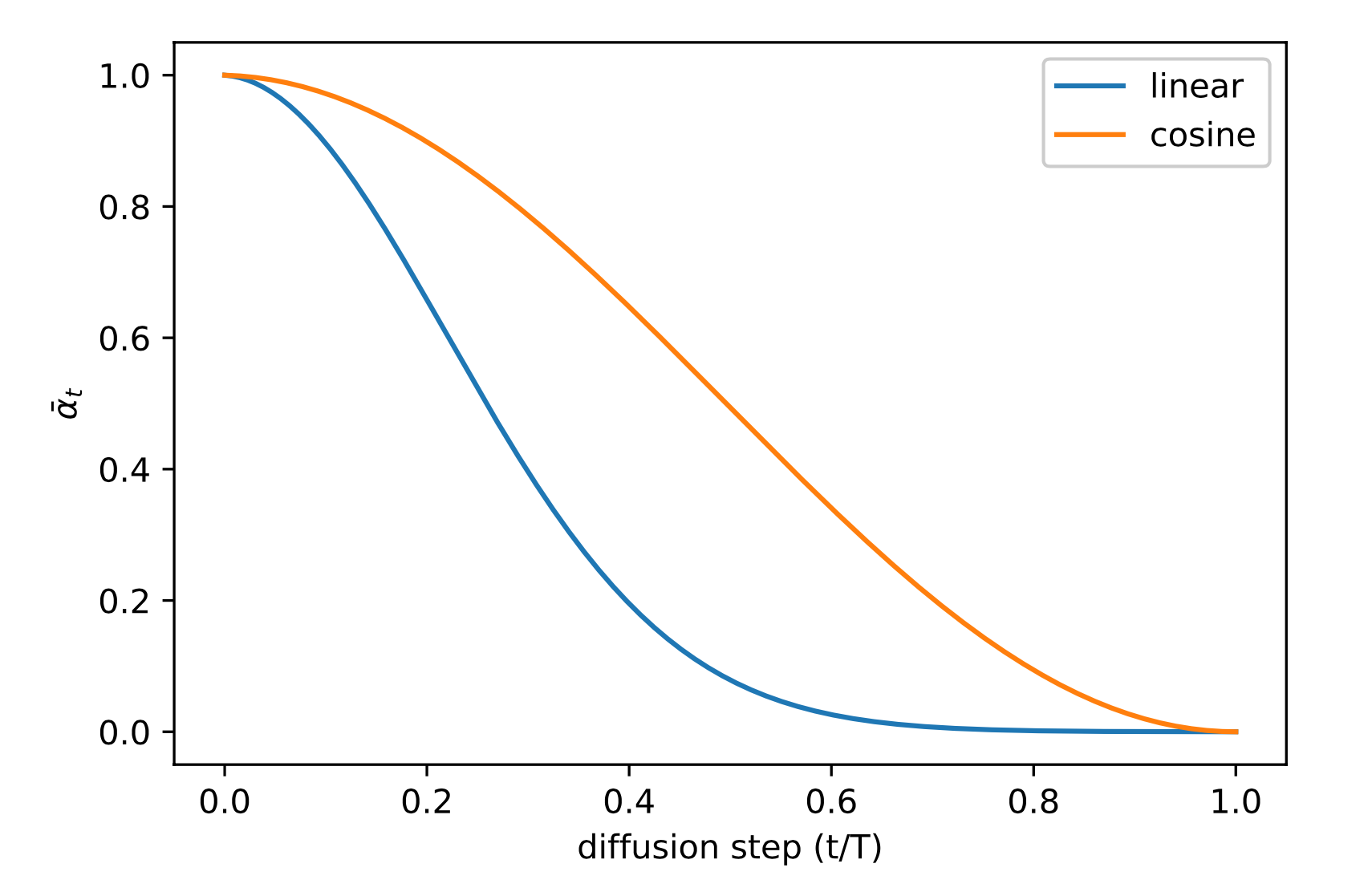
在Ho等人(2020)中,前向方差被设定为一系列线性增加的常数,从
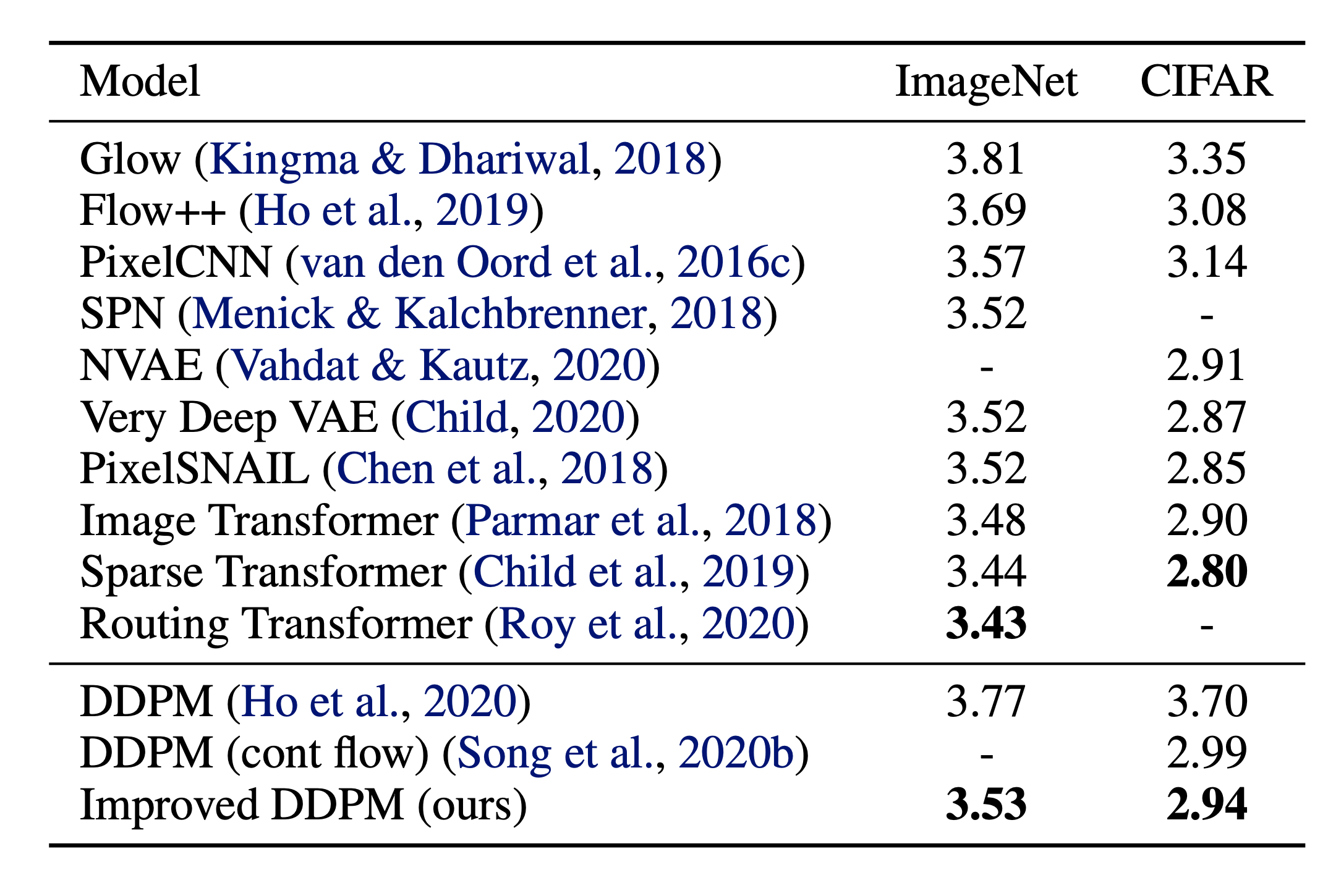
Nichol & Dhariwal(2021)提出了一些改进技术,以帮助扩散模型获得更低的NLL。其中一项改进是使用基于余弦的方差时间表。时间表函数的选择可以是任意的,只要它在训练过程中间提供接**滑的下降,并在
其中小偏移
反向过程方差
Ho等人(2020)选择将
Nichol & Dhariwal(2021)提出学习
然而,简单目标
条件生成
在带有条件信息(如ImageNet数据集)的图像上训练生成模型时,通常会生成条件在类别标签或一段描述性文本上的样本。
分类器引导的扩散
为了在扩散过程中显式地结合类别信息,Dhariwal & Nichol(2021)在带有噪声的图像
为了控制分类器引导的强度,我们可以在delta部分添加一个权重
得到的消融扩散模型(ADM)和带有附加分类器引导的模型(ADM-G)能够比现有最先进的生成模型(例如BigGAN)取得更好的结果。

此外,通过对U-Net架构的一些修改,Dhariwal & Nichol(2021)展示了在扩散模型上比GAN更好的表现。架构修改包括更大的模型深度/宽度,更多的注意头,多分辨率注意力,BigGAN残差块用于上/下采样,残差连接重新缩放为
无分类器引导
在没有独立分类器
隐式分类器的梯度可以通过条件和无条件分数估计器表示。一旦插入分类器引导的修改分数,分数就不再依赖于单独的分类器。
他们的实验表明,无分类器引导可以在FID(区分合成和生成图像)和IS(质量和多样性)之间实现良好的*衡。
引导扩散模型GLIDE(Nichol, Dhariwal & Ramesh, et al. 2022)探讨了两种引导策略,CLIP引导和无分类器引导,并发现后者更受欢迎。他们假设这是因为CLIP引导通过对CLIP模型的对抗性示例利用模型,而不是优化更匹配的图像生成。
加速扩散模型
通过遵循反向扩散过程的马尔可夫链从DDPM生成一个样本非常慢,因为
减少采样步骤与蒸馏
一种简单的方法是运行跨步采样计划(Nichol & Dhariwal, 2021),通过每隔
另一种方法是将
其中模型
回顾一下
让
在生成过程中,我们不必遵循整个链
在实验中,所有模型都使用
与DDPM相比,DDIM能够:
- 使用更少的步骤生成更高质量的样本。
- 具有“一致性”属性,因为生成过程是确定性的,这意味着多个样本在相同的潜在变量条件下应具有相似的高级特征。
- 由于一致性,DDIM可以在潜在变量中进行语义上有意义的插值。
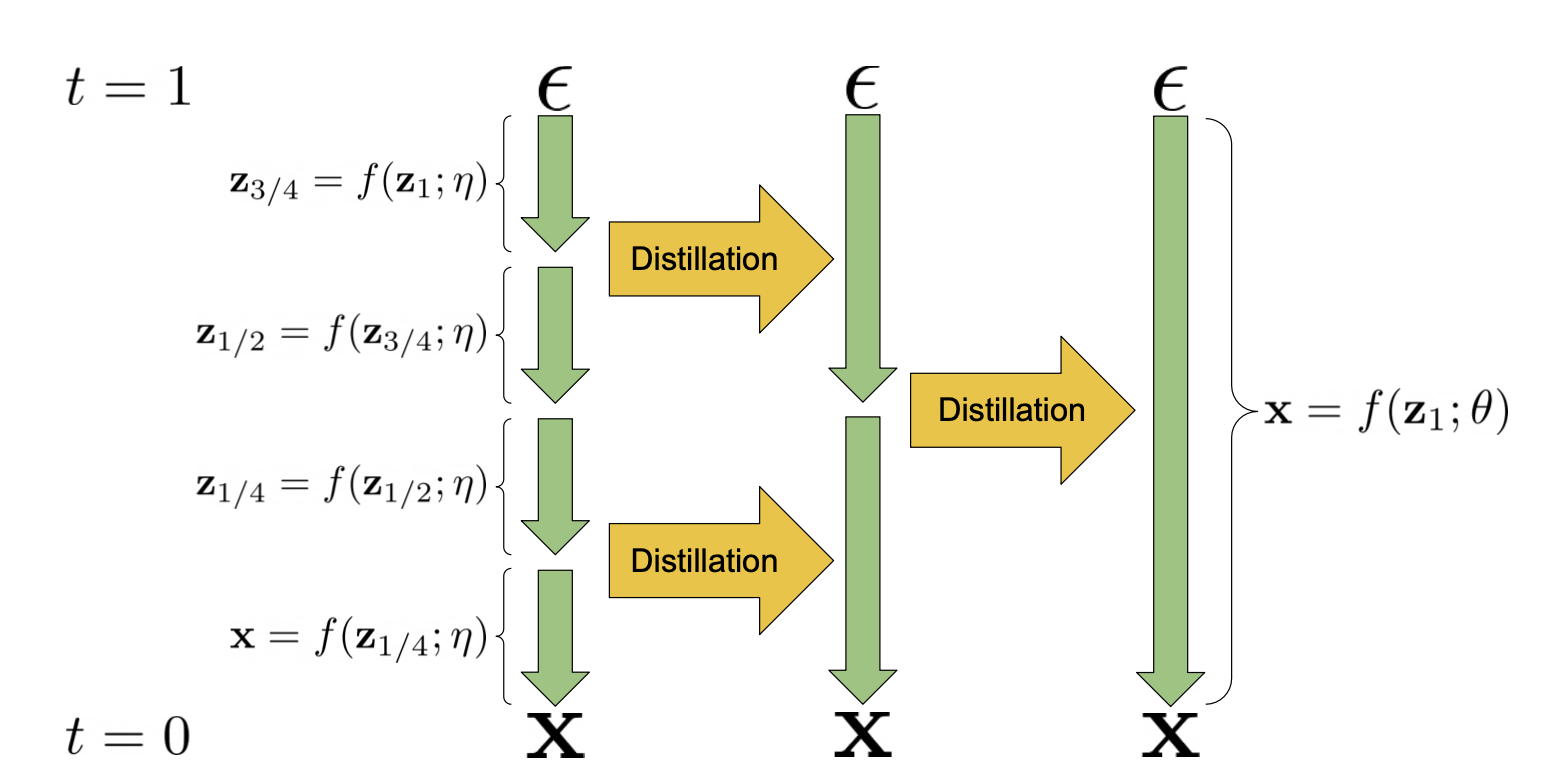
渐进蒸馏(Salimans & Ho, 2022)是一种将训练好的确定性采样器蒸馏到新的减少一半采样步骤的模型中的方法。学生模型从教师模型初始化并向目标去噪,其中一个学生DDIM步骤匹配2个教师步骤,而不是使用原始样本

(图片来源:Salimans & Ho, 2022)
一致性模型(Song等人,2023)学习将扩散采样轨迹上的任何中间噪声数据点

给定轨迹
一致性模型有可能在单步中生成样本,同时仍保持通过多步采样过程权衡计算与质量的灵活性。
论文介绍了两种训练一致性模型的方法:
-
一致性蒸馏(CD):通过最小化从相同轨迹生成的模型输出之间的差异,将扩散模型蒸馏到一致性模型中。这使得评估采样更加便宜。一致性蒸馏损失为:
其中
-
一致性训练(CT):另一种选择是独立训练一致性模型。注意,在CD中,使用预训练的分数模型
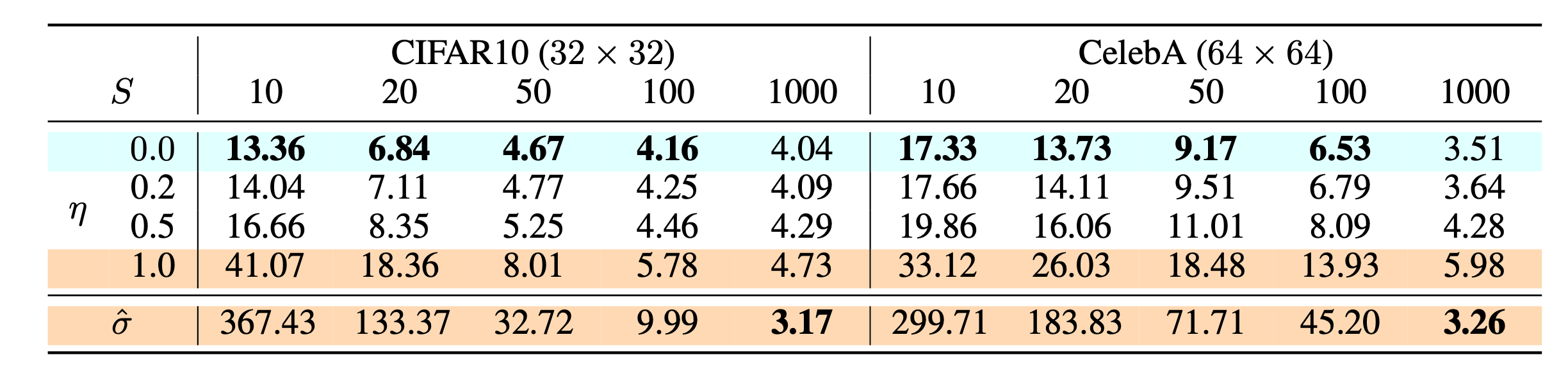
根据论文中的实验,他们发现,
- Heun ODE求解器比Euler的一阶求解器效果更好,因为高阶ODE求解器在相同
- 在不同选项的距离度量函数
- 较小的
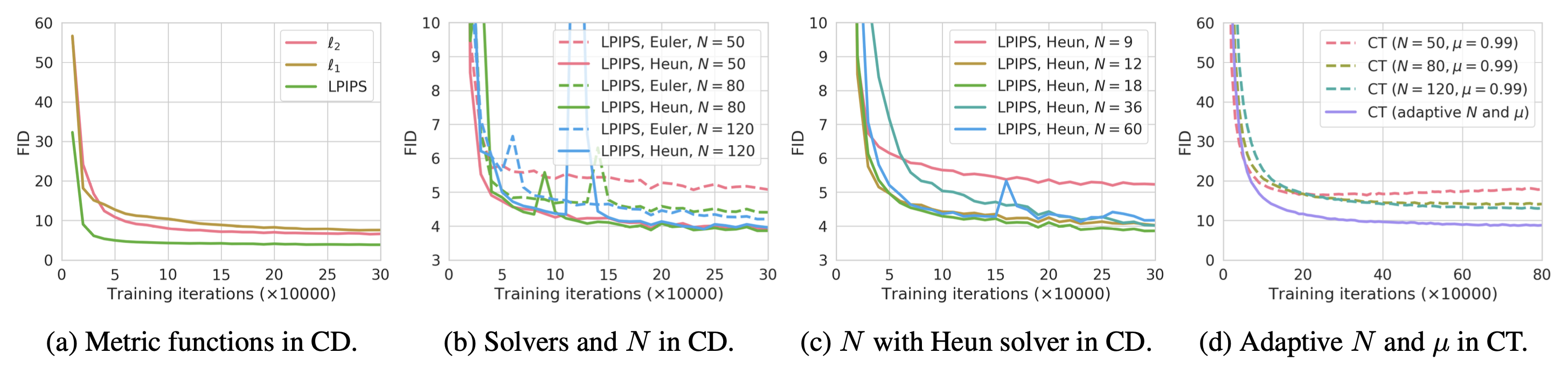
潜变量空间
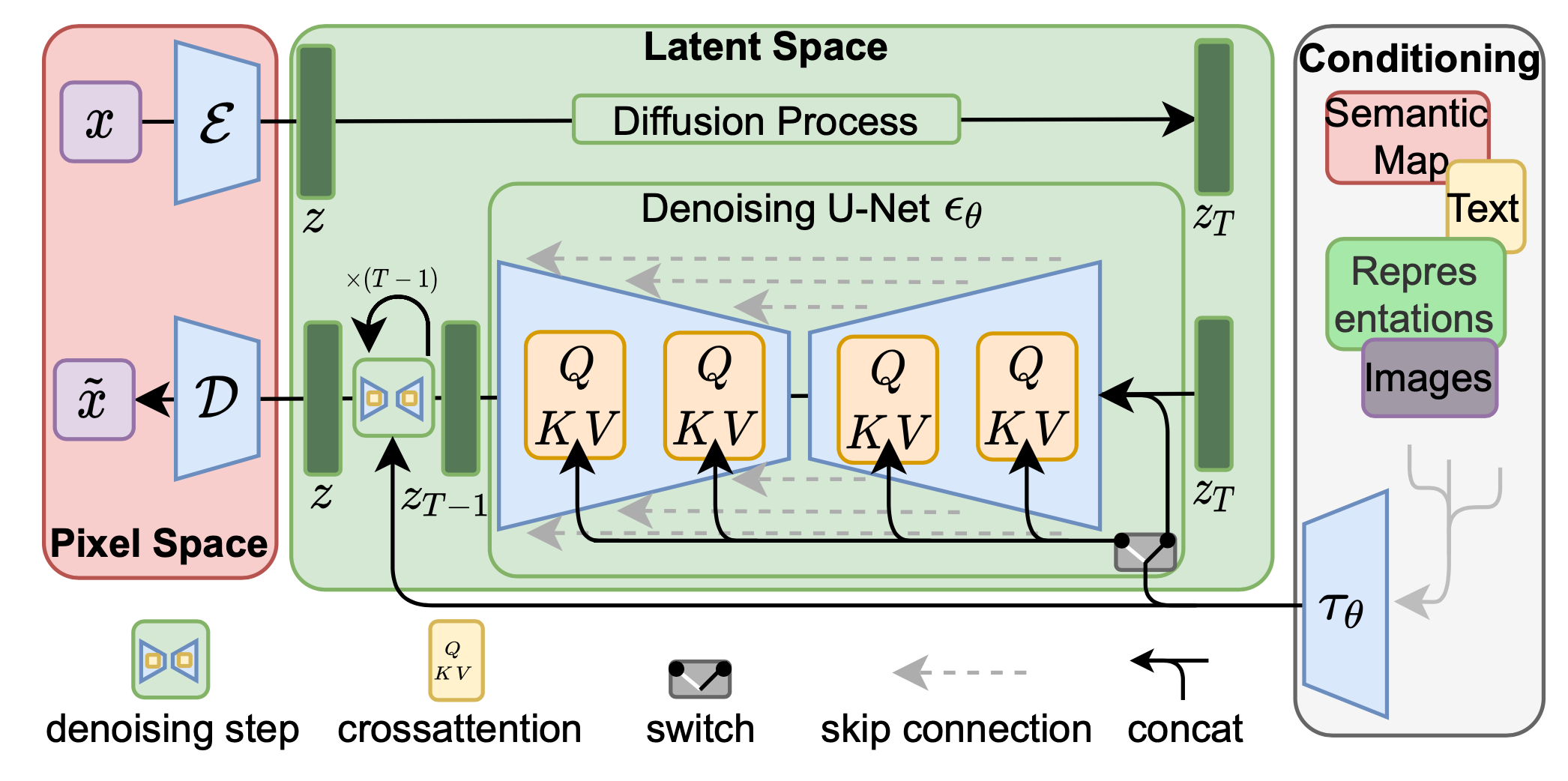
潜扩散模型(LDM;Rombach & Blattmann等人,2022)在潜空间而不是像素空间中运行扩散过程,从而降低训练成本并加快推理速度。其动机是观察到图像的大多数位元贡献于感知细节,而经过激进压缩后,语义和概念组成仍然保留。LDM通过首先用自编码器去除像素级冗余,然后在学习的潜变量上使用扩散过程进行语义概念的操纵/生成,松散地将感知压缩和语义压缩与生成建模学习分解。
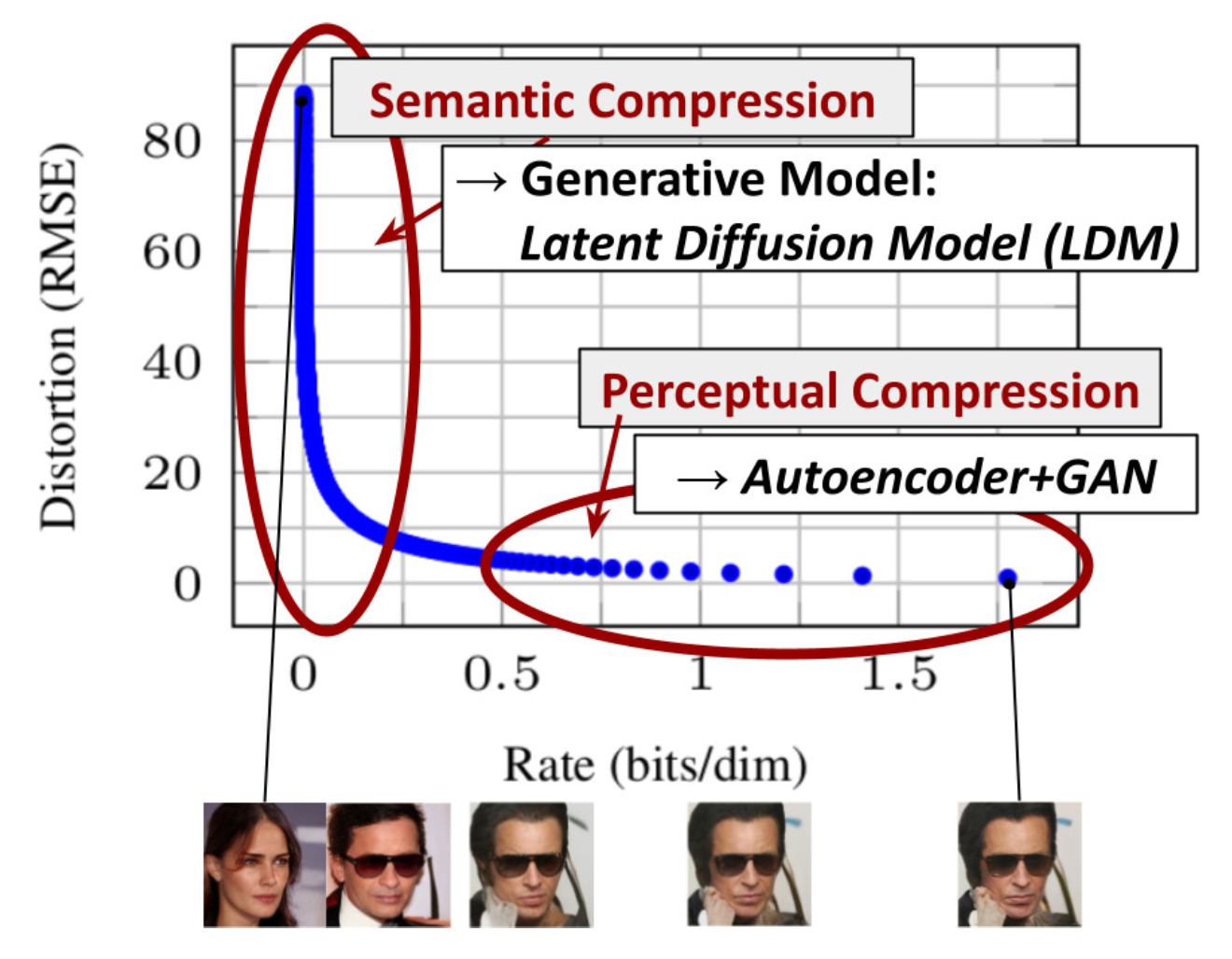
感知压缩过程依赖于自编码器模型。一个编码器
扩散和去噪过程发生在潜向量
扩大生成分辨率和质量
为了生成高分辨率的高质量图像,Ho等人(2021)提出了使用多个扩散模型在增加的分辨率下的流水线。噪声条件增强是流水线模型之间最有效的,旨在对每个超分辨率模型
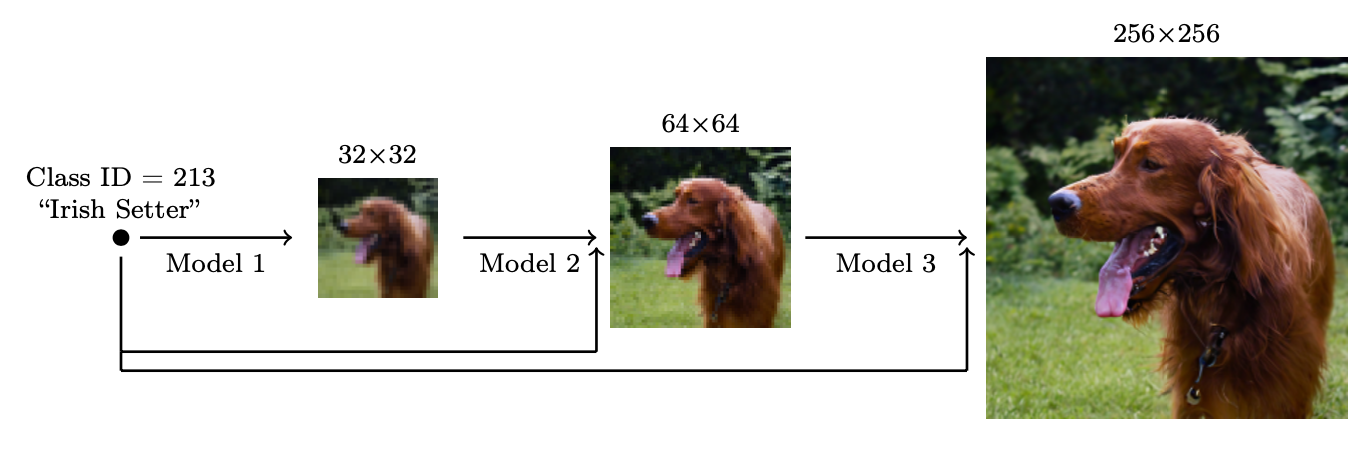
他们发现最有效的噪声是在低分辨率时应用高斯噪声,在高分辨率时应用高斯模糊。此外,他们还探索了两种需要对训练过程进行小修改的条件增强形式。注意,条件噪声仅在训练时应用,而不是在推理时。
- 截断条件增强在
- 非截断条件增强运行全低分辨率反向过程直到步骤0,然后通过
两阶段扩散模型unCLIP(Ramesh等人,2022)大量利用CLIP文本编码器来生成高质量的文本引导图像。给定预训练的CLIP模型
- 先验模型
- 解码器
这些模型使条件生成成为可能,因为
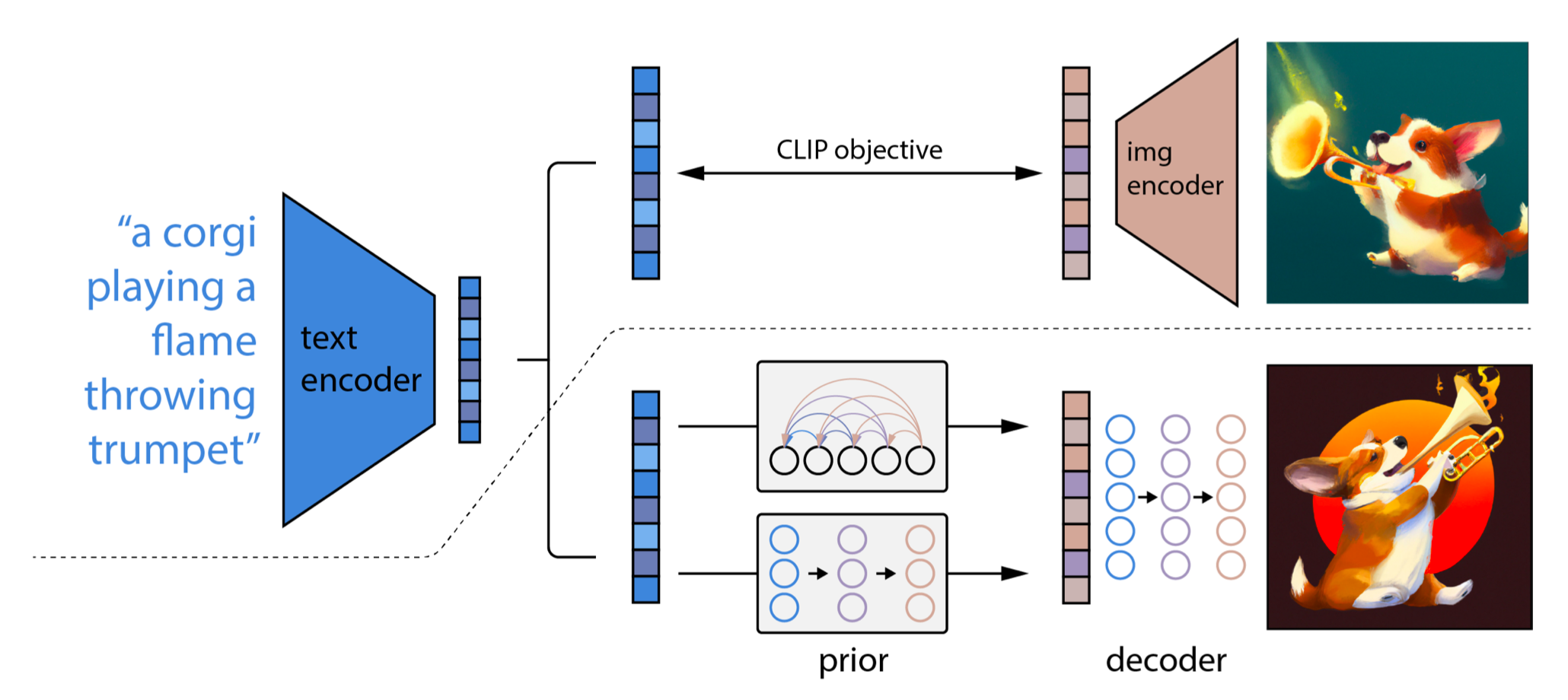
unCLIP遵循两阶段图像生成过程:
- 给定文本
- 扩散或自回归先验
与CLIP模型不同,Imagen(Saharia等人,2022)使用预训练的大型LM(即冻结的T5-XXL文本编码器)来编码用于图像生成的文本。通常,模型尺寸越大,图像质量和文本-图像对齐越好。他们发现T5-XXL和CLIP文本编码器在MS-COCO上的性能相似,但在DrawBench(涵盖11个类别的提示集合)上,人类评估更喜欢T5-XXL。
在应用无分类器引导时,增加
- 静态阈值:将
- 动态阈值:在每个采样步骤,计算
Imagen在U-net中修改了几种设计,使其成为高效U-Net。
- 通过为较低分辨率添加更多残差锁,将模型参数从高分辨率块移到低分辨率;
- 将跳跃连接缩放为
- 将下采样(在卷积之前)和上采样操作(在卷积之后)的顺序反转,以提高前向传递的速度。
他们发现噪声条件增强、动态阈值和高效U-Net对图像质量至关重要,但缩放文本编码器大小比U-Net大小更重要。
模型架构
扩散模型有两种常见的骨干架构选择:U-Net和Transformer。
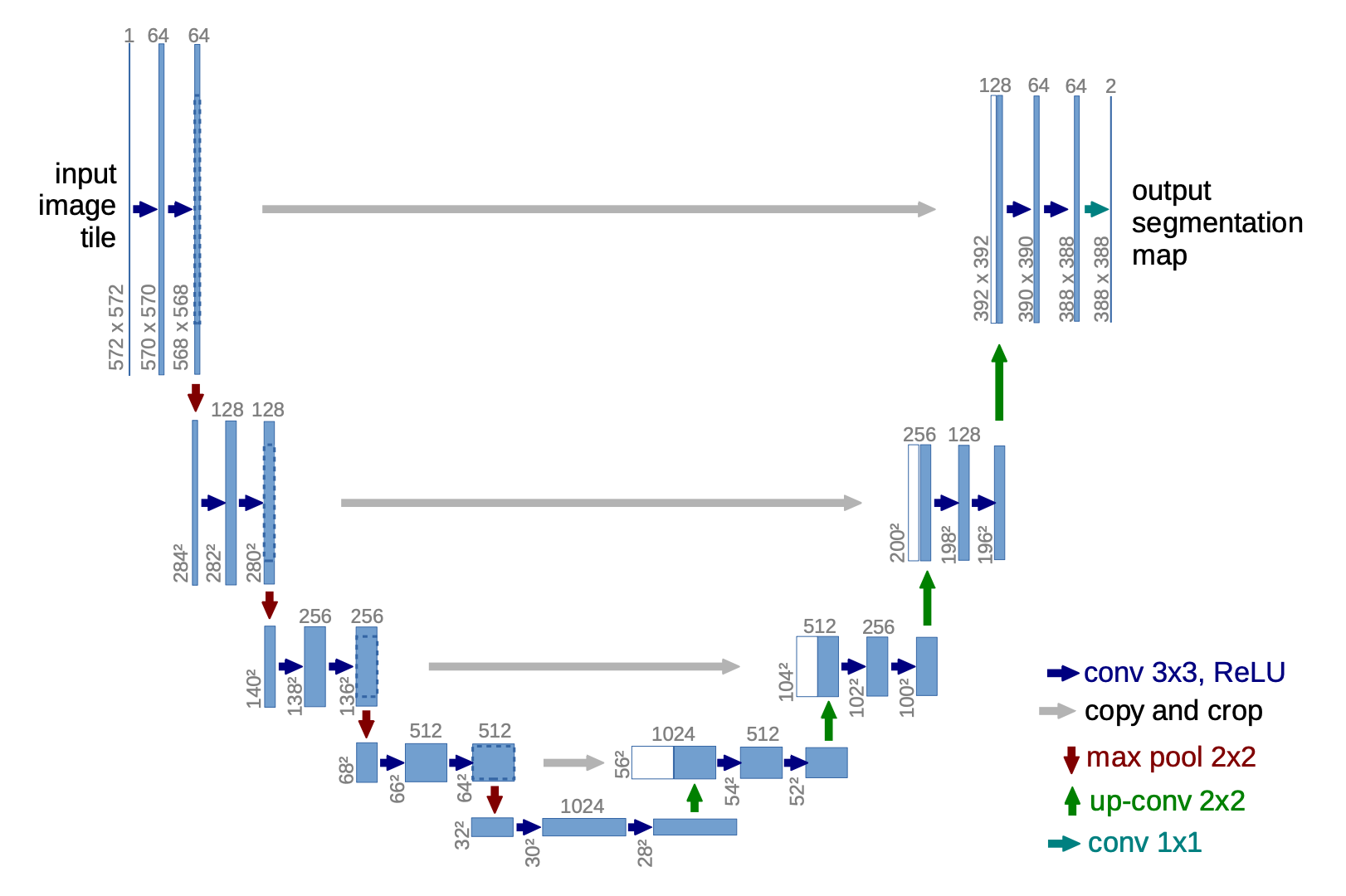
U-Net(Ronneberger等人,2015)由下采样堆栈和上采样堆栈组成。
- 下采样:每一步包括两次3x3卷积(无填充卷积)的重复应用,每次后跟一个ReLU和一个具有2步幅度的2x2最大池化。在每一步下采样时,特征通道的数量加倍。
- 上采样:每一步包括一个特征图的上采样,随后是一个2x2卷积,每次减半特征通道数量。
- 快捷方式:快捷连接将高分辨率特征提供给上采样过程。
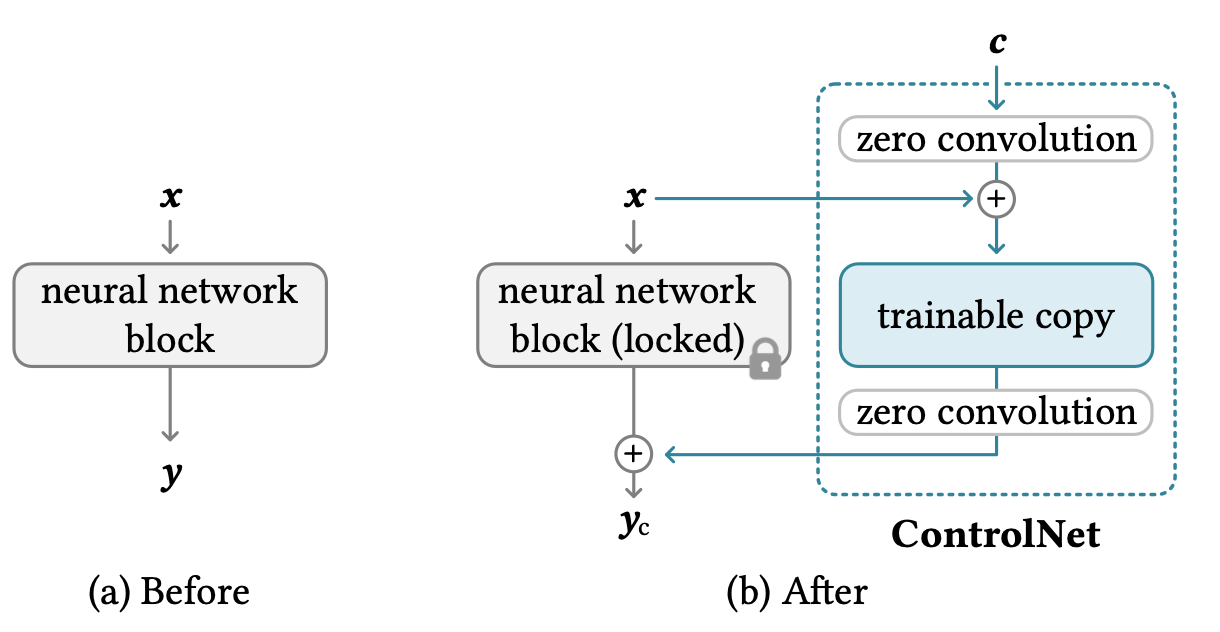
为了使图像生成以额外图像为条件进行组合信息如Canny边缘、Hough线、用户涂鸦、人体姿势骨架、分割图、深度和法线,ControlNet(Zhang等人,2023通过在U-Net的每个编码器层中添加“夹心”零卷积层,将原始模型权重的可训练副本引入架构中进行架构变化。具体而言,给定神经网络块
- 首先,冻结原始块的参数
- 将其克隆为带有可训练参数
- 使用两个零卷积层,表示为
- 最终输出为:
扩散Transformer(DiT;Peebles & Xie,2023)用于扩散建模在潜变量块上运行,使用与LDM(潜扩散模型)相同的设计空间。DiT有以下设置:
- 将输入的潜表示
- 将大小为
- 然后这个块序列通过Transformer块。他们在探索如何在时间步
- Transformer解码器输出噪声预测和输出对角协方差预测。
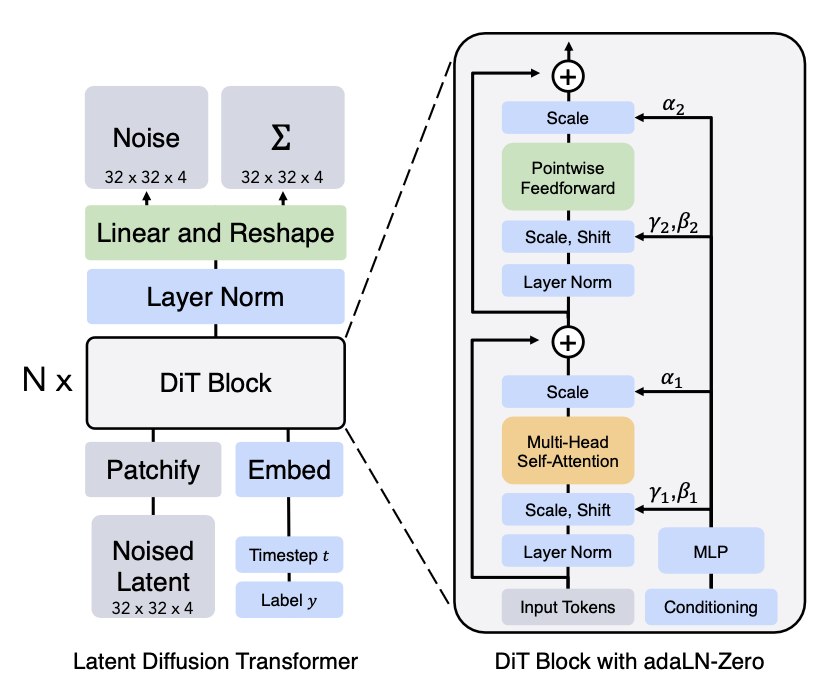
(图片来源:Peebles & Xie,2023)
Transformer架构可以轻松扩展,这是DiT的最大优点之一,因为其性能随着更多计算量的增加而提高,较大的DiT模型在实验中显示出更高的计算效率。
快速总结
-
优点:在生成建模中,可追溯性和灵活性是两个相互冲突的目标。可追溯的模型可以进行分析评估并廉价地拟合数据(例如通过高斯或拉普拉斯),但它们不能轻易描述丰富数据集中的结构。灵活的模型可以拟合数据中的任意结构,但评估、训练或从这些模型中采样通常非常昂贵。扩散模型既是可追溯的,又是灵活的。
-
缺点:扩散模型依赖于长的扩散步骤马尔可夫链生成样本,因此在时间和计算方面可能相当昂贵。已提出新的方法使这一过程更快,但采样仍然比GAN慢。
引用
引用为:
Weng, Lilian.(2021年7月)。什么是扩散模型?Lil’Log。https://lilianweng.github.io/posts/2021-07-11-diffusion-models/。
或者
@article{weng2021diffusion,
title = "What are diffusion models?",
author = "Weng, Lilian",
journal = "lilianweng.github.io",
year = "2021",
month = "Jul",
url = "https://lilianweng.github.io/posts/2021-07-11-diffusion-models/"
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧