

变分自编码器(五):VAE + BN = 更好的VAE
本文我们继续之前的变分自编码器系列,分析一下如何防止NLP中的VAE模型出现“KL散度消失(KL Vanishing)”现象。本文受到参考文献是ACL 2020的论文《A Batch Normalized Inference Network Keeps the KL Vanishing Away》的启发,并自行做了进一步的完善。
值得一提的是,本文最后得到的方案还是颇为简洁的——只需往编码输出加入BN(Batch Normalization),然后加个简单的scale——但确实很有效,因此值得正在研究相关问题的读者一试。同时,相关结论也适用于一般的VAE模型(包括CV的),如果按照笔者的看法,它甚至可以作为VAE模型的“标配”。
最后,要提醒读者这算是一篇VAE的进阶论文,所以请读者对VAE有一定了解后再来阅读本文。
VAE简单回顾 #
这里我们简单回顾一下VAE模型,并且讨论一下VAE在NLP中所遇到的困难。关于VAE的更详细介绍,请读者参考笔者的旧作《变分自编码器(一):原来是这么一回事》、《变分自编码器(二):从贝叶斯观点出发》等。
VAE的训练流程 #
VAE的训练流程大概可以图示为
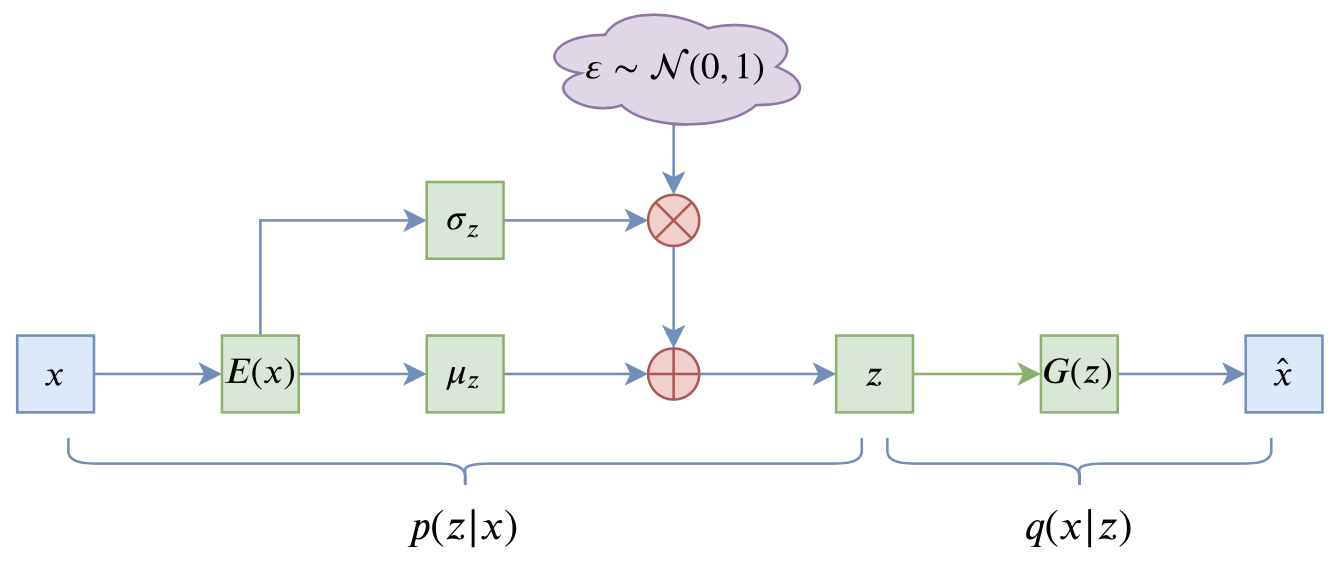
VAE训练流程图示
写成公式就是
其中第一项就是重构项,
NLP中的VAE #
在NLP中,句子被编码为离散的整数ID,所以
这种情况下的VAE模型并没有什么价值:KL散度为0说明编码器输出的是常数向量,而解码器则是一个普通的语言模型。而我们使用VAE通常来说是看中了它无监督构建编码向量的能力,所以要应用VAE的话还是得解决KL散度消失问题。事实上从2016开始,有不少工作在做这个问题,相应地也提出了很多方案,比如退火策略、更换先验分布等,读者Google一下“KL Vanishing”就可以找到很多文献了,这里不一一溯源。
BN的巧与妙 #
本文的方案则是直接针对KL散度项入手,简单有效而且没什么超参数。其思想很简单:
KL散度消失不就是KL散度项变成0吗?我调整一下编码器输出,让KL散度有一个大于零的下界,这样它不就肯定不会消失了吗?
这个简单的思想的直接结果就是:在
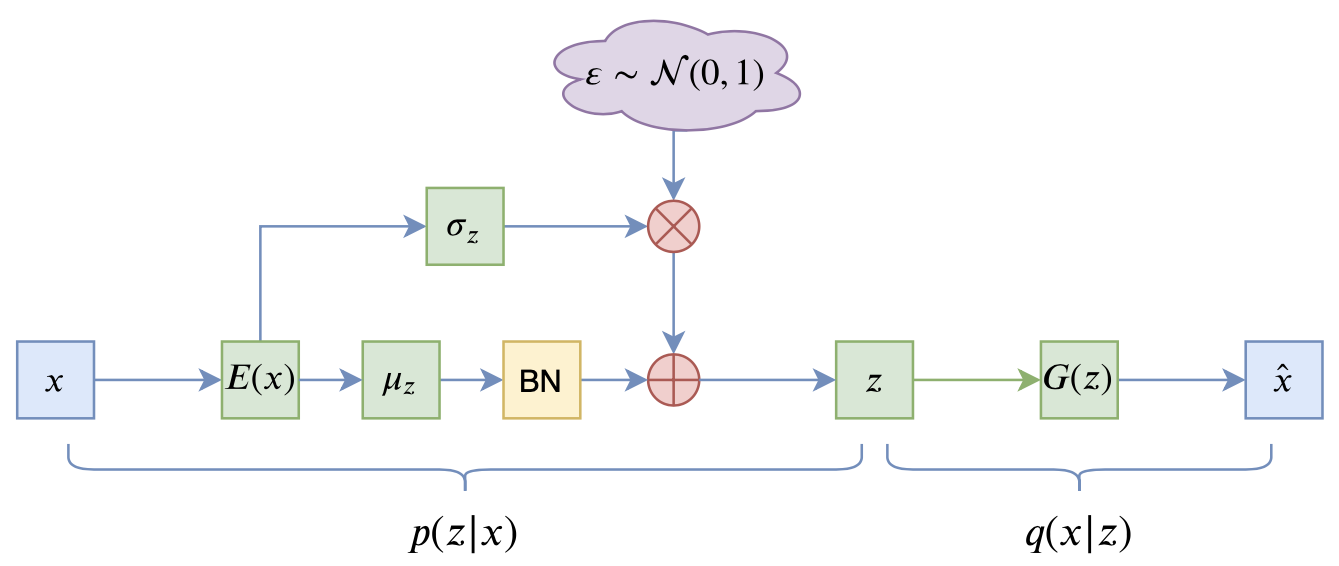
往VAE里加入BN
推导过程简述 #
为什么会跟BN联系起来呢?我们来看KL散度项的形式:
上式是采样了
留意到括号里边的量,其实它就是
所以只要控制好
为什么不是LN? #
善于推导的读者可能会想到,按照上述思路,如果只是为了让KL散度项有个正的下界,其实LN(Layer Normalization)也可以,也就是在式
那为什么用BN而不是LN呢?
这个问题的答案也是BN的巧妙之处。直观来理解,KL散度消失是因为
进一步的结果 #
事实上,原论文的推导到上面基本上就结束了,剩下的都是实验部分,包括通过实验来确定
经过笔者的推导,发现上面的结论可以进一步完善。
联系到先验分布 #
对于VAE来说,它希望训练好后的模型的隐变量分布为先验分布
两边乘以
两边乘以
如果往
所以现在我们知道
参考的实现方案 #
经过这样的推导,我们发现可以往
其中
关键代码参考(Keras):
class Scaler(Layer):
"""特殊的scale层
"""
def __init__(self, tau=0.5, **kwargs):
super(Scaler, self).__init__(**kwargs)
self.tau = tau
def build(self, input_shape):
super(Scaler, self).build(input_shape)
self.scale = self.add_weight(
name='scale', shape=(input_shape[-1],), initializer='zeros'
)
def call(self, inputs, mode='positive'):
if mode == 'positive':
scale = self.tau + (1 - self.tau) * K.sigmoid(self.scale)
else:
scale = (1 - self.tau) * K.sigmoid(-self.scale)
return inputs * K.sqrt(scale)
def get_config(self):
config = {'tau': self.tau}
base_config = super(Scaler, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
def sampling(inputs):
"""重参数采样
"""
z_mean, z_std = inputs
noise = K.random_normal(shape=K.shape(z_mean))
return z_mean + z_std * noise
def build(self, input_shape):
super(Scaler, self).build(input_shape)
self.scale = self.add_weight(
name='scale', shape=(input_shape[-1],), initializer='zeros'
)
def call(self, inputs, mode='positive'):
if mode == 'positive':
scale = self.tau + (1 - self.tau) * K.sigmoid(self.scale)
else:
scale = (1 - self.tau) * K.sigmoid(-self.scale)
return inputs * K.sqrt(scale)
def get_config(self):
config = {'tau': self.tau}
base_config = super(Scaler, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
e_outputs # 假设e_outputs是编码器的输出向量
scaler = Scaler()
z_mean = Dense(hidden_dims)(e_outputs)
z_mean = BatchNormalization(scale=False, center=False, epsilon=1e-8)(z_mean)
z_mean = scaler(z_mean, mode='positive')
z_std = Dense(hidden_dims)(e_outputs)
z_std = BatchNormalization(scale=False, center=False, epsilon=1e-8)(z_std)
z_std = scaler(z_std, mode='negative')
z = Lambda(sampling, name='Sampling')([z_mean, z_std])
文章内容小结 #
本文简单分析了VAE在NLP中的KL散度消失现象,并介绍了通过BN层来防止KL散度消失、稳定训练流程的方法。这是一种简洁有效的方案,不单单是原论文,笔者私下也做了简单的实验,结果确实也表明了它的有效性,值得各位读者试用。因为其推导具有一般性,所以甚至任意场景(比如CV)中的VAE模型都可以尝试一下。
转载到请包括本文地址:https://spaces.ac.cn/archives/7381
更详细的转载事宜请参考:《科学空间FAQ》


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧