

变分自编码器(四):一步到位的聚类方案
由于VAE中既有编码器又有解码器(生成器),同时隐变量分布又被近似编码为标准正态分布,因此VAE既是一个生成模型,又是一个特征提取器。在图像领域中,由于VAE生成的图片偏模糊,因此大家通常更关心VAE作为图像特征提取器的作用。提取特征都是为了下一步的任务准备的,而下一步的任务可能有很多,比如分类、聚类等。本文来关心“聚类”这个任务。
一般来说,用AE或者VAE做聚类都是分步来进行的,即先训练一个普通的VAE,然后得到原始数据的隐变量,接着对隐变量做一个K-Means或GMM之类的。但是这样的思路的整体感显然不够,而且聚类方法的选择也让我们纠结。本文介绍基于VAE的一个“一步到位”的聚类思路,它同时允许我们完成无监督地完成聚类和条件生成。
理论 #
一般框架 #
回顾VAE的loss(如果没印象请参考《变分自编码器(二):从贝叶斯观点出发》):
通常来说,我们会假设
然而,也没有谁规定隐变量一定是连续变量吧?这里我们就将隐变量定为
这就是用来做聚类的VAE的loss了。
分步假设 #
啥?就完事了?呃,是的,如果只考虑一般化的框架,
不过落实到实践中,
代入
其实
1、从原始数据中采样到
,然后通过 可以得到编码特征 ,然后通过分类器 对编码特征进行分类,从而得到类别; 2、从分布
中选取一个类别 ,然后从分布 中选取一个随机隐变量 ,然后通过生成器 解码为原始样本。
具体模型 #
最后,可以形象地将
其中
1、
希望重构误差越小越好,也就是 尽量保留完整的信息; 2、
希望 能尽量对齐某个类别的“专属”的正态分布,就是这一步起到聚类的作用; 3、
希望每个类的分布尽量均衡,不会发生两个几乎重合的情况(坍缩为一个类)。当然,有时候可能不需要这个先验要求,那就可以去掉这一项。
实验 #
实验代码自然是Keras完成的了(^_^),在mnist和fashion-mnist上做了实验,表现都还可以。实验环境:Keras 2.2 + tensorflow 1.8 + Python 2.7。
代码实现 #
代码位于:https://github.com/bojone/vae/blob/master/vae_keras_cluster.py
其实注释应该比较清楚了,而且相比普通的VAE改动不大。可能稍微有难度的是
得到
注意其实第二项是多余的,因为重参数操作告诉我们
然后因为
其他的话,读者应该清楚普通的VAE的实现过程,然后才看本文的内容和代码,不然估计是一脸懵的。
mnist #
这里是mnist的实验结果图示,包括类内样本图示和按类采样图示。最后还简单估算了一下,以每一类对应的数目最多的那个真实标签为类标签的话,最终的test准确率大约有83%,对比这篇文章《Unsupervised Deep Embedding for Clustering Analysis》的结果(最高也是84%左右),感觉应该很不错了。
聚类图示 #

聚类类别_0
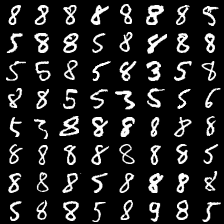
聚类类别_1
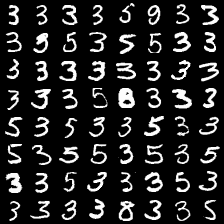
聚类类别_2
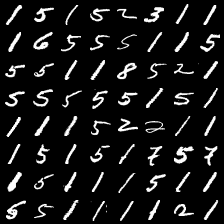
聚类类别_3
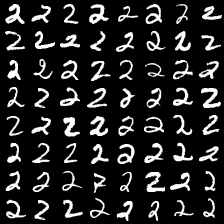
聚类类别_4
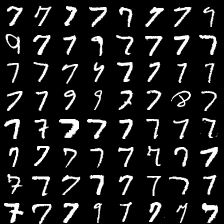
聚类类别_5
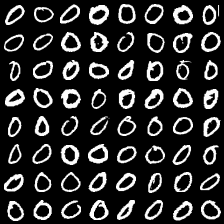
聚类类别_6

聚类类别_7

聚类类别_8
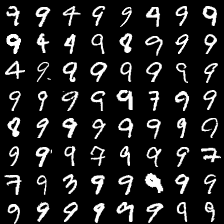
聚类类别_9
按类采样 #

类别采样_0

类别采样_1

类别采样_2

类别采样_3

类别采样_4

类别采样_5

类别采样_6

类别采样_7

类别采样_8

类别采样_9
fashion-mnist #
这里是fashion-mnist的实验结果图示,包括类内样本图示和按类采样图示,最终的test准确率大约有58.5%。
聚类图示 #

聚类类别_0
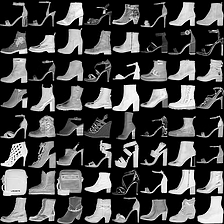
聚类类别_1

聚类类别_2

聚类类别_3

聚类类别_4

聚类类别_5
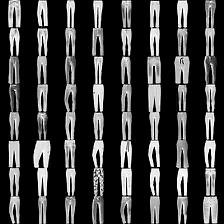
聚类类别_6

聚类类别_7

聚类类别_8

聚类类别_9
按类采样 #
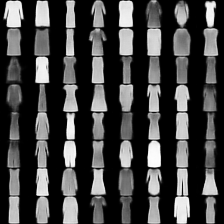
类别采样_0
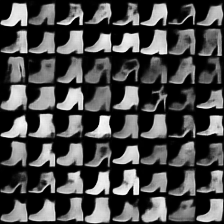
类别采样_1

类别采样_2

类别采样_3

类别采样_4

类别采样_5

类别采样_6

类别采样_7
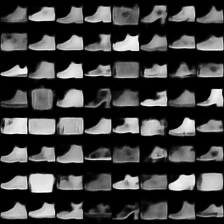
类别采样_8

类别采样_9
总结 #
文章简单地实现了一下基于VAE的聚类算法,算法的特点就是一步到位,结合“编码”、“聚类”和“生成”三个任务同时完成,思想是对VAE的loss的一般化。
感觉还有一定的提升空间,比如式
转载到请包括本文地址:https://spaces.ac.cn/archives/5887
更详细的转载事宜请参考:《科学空间FAQ》


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧