

Diffusion Model
介绍
Diddusion Model 是2020年出现的一种新模型,论文中将其用于生成任务中。与GAN模型不同的是,他不需要使用判别器来进行训练。其训练过程与通常的生成器有很大的不同,他并不是直接训练一个生产模型,而是训练一个正态分布,并使用其对原始噪声图片去噪来生成图片。至于如何为什么使用这个正态分布能生成图像后面将会简要讲解。
需要提前说明的是,有一部分的公式需要严密的概率论推导,较困难,而实际使用只需要理解其意思就行所以就直接使用结论。
生成过程
Diffusion Model的个过程分为前向过程和反向过程。前向过程是将图片进行加噪,后向过程是将其去噪。其中前向过程的公式是通过概率论直接推导,这里直接使用。后向过程则是通过前向过程公式推导出来。

前向过程
噪声:

噪声因子:
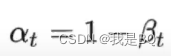
前向公式:
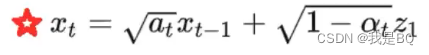
讲解:
1、前向公式中的x_t表示的是t时刻的图像,因为噪声是随这时间逐渐增大的,因此图像也中的噪声也逐渐增大。
2、z是标准正态分布生产的噪声图像,形状是跟原图像一样的,所以可以直接相加。x,z前面的可以看作系数,是已知的。
3、这里的z是不需要训练的,就是一个普通的标准正态分布。
3、这里表示的是相邻两个时刻的前向推到公式,后面需要推到0时刻到任意t时刻的推导公式。
t-2时刻-t时刻前向推导公式:

讲解:
1、这里z1和z2都是标准正态分布只是乘了一个系数,乘上的这个系数仍是正态分布。
2、使用正态分布的性质融合成新的正态分布。
0时刻-t时刻前向推导公式:
这里是根据上面的特性推到出来的。
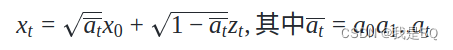
总结:
在前行过程中只要知道了时刻t即原始图像x_0就能直接算出任意时刻的加噪图像,但在反向过程并不能直接算出。
反向过程
因为反向过程并不好求,所以是利用条件概率公式建立t-1时刻和t时刻的公式再整理成反向推导公式。

先不考虑X_0的条件进行里理解,理解后加入x_0的条件计算分子项和分母项。
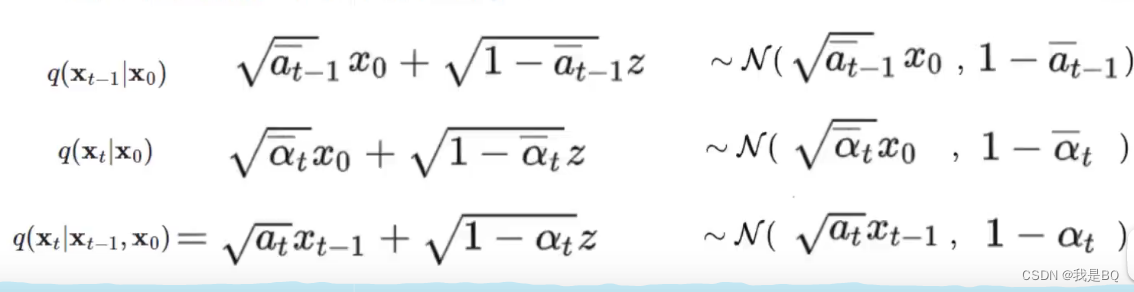
可以看到3项都是符合正态分布,根据正态分布特效进行融合.
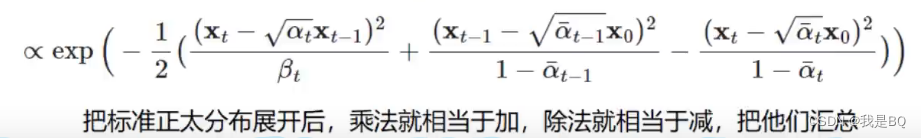
化简:
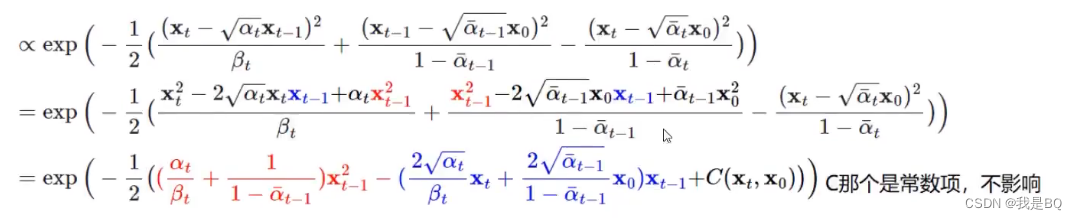
根据下面公式算出融合后正态分布的期望和方差:
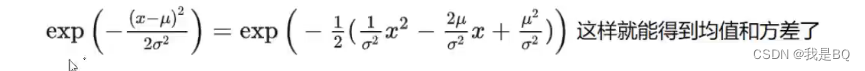
算出的期望和方差(这里取系数项做等式即可,常数项不用):
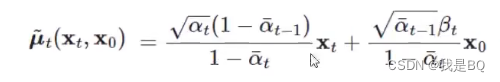
这里出现一个问题,因为这是反向过程X_0是位置的,所以需要带入前向过程的公式将x_0变成x_t,带入后得到:
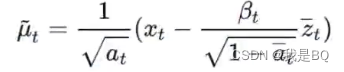
需要注意这里的z_t是一个未知的正态分布,也是模型唯一需要训练的内容。
反向推导公式:
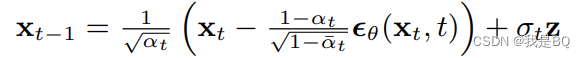
从计算出期望到得到最后的公式,视频中并未讲解,本人也不清楚,估计是使用概率论中的特性得出的。
训练过程

1、算法一:训练的是反向过程用到正态分布函数
2、算法二:是使用训练好的正态分布函数生成的噪声与前一时刻图像相加,loop得到生成图像。说是噪声并不严谨,可以说是生成一个蒙版,有去噪功能的蒙版。
提供的视频有详细的代码实现。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧