
动手学强化学习(三):马尔可夫决策过程
转载自:https://hrl.boyuai.com/chapter/1/马尔可夫决策过程
3.1 简介
马尔可夫决策过程(Markov decision process,MDP)是强化学习的重要概念。要学好强化学习,我们首先要掌握马尔可夫决策过程的基础知识。前两章所说的强化学习中的环境一般就是一个马尔可夫决策过程。与多臂老胡机问题不同,马尔可夫决策过程包含状态信息以及状态之间的转移机制。如果要用强化学习去解决一个实际问题,第一步要做的事情就是把这个实际问题抽象为一个马尔可夫决策过程,也就是明确马尔可夫决策过程的各个组成要素。本章将从马尔可夫过程出发,一步一步地进行介绍,最后引出马尔可夫决策过程。
3.2 马尔可夫过程
3.2.1 随机过程
随机过程(stochastic process)是概率论的“动力学”部分。概率论的研究对象是静态的随机现象,而随机过程的研究对象是随时间演变的随机现象(例如天气随时间的变化、城市交通随时间的变化)。在随机过程中,随机现象在某时刻\(t\)的取值是一个向量随机变量,用\(S_t\)表示,所有可能的状态组成状态集合\(S\)。随机现象便是状态的变化过程。在某时刻\(t\)的状态\(S_{t}\)通常取决于\(t\) 时刻之前的状态。我们将已知历史信息\((S_1,\ldots,S_t)\)时下一个时刻状态为\(S_{t+1}\)的概率表示成\(P(S_{t+1}|S_1,\ldots,S_t)\)。
3.2.2 马尔可夫性质
当且仅当某时刻的状态只取决于上一时刻的状态时,一个随机过程被称为具有马尔可夫性质(Markov property), 用公式表示为\(P(S_{t+1}|S_t)=P(S_{t+1}|S_1,\ldots,S_t)\)。也就是说,当前状态是未来的充分统计量,即下一个状态只取决于当前状态,而不会受到过去状态的影响。需要明确的是,具有马尔可夫性并不代表这个随机过程就和历史完全没有关系。因为虽然\(t+1\)时刻的状态只与\(t\)时刻的状态有关,但是\(t\)时刻的状态其实包含了\(t-1\)时刻的状态的信息,通过这种链式的关系,历史的信息被传递到了现在。马尔可夫性可以大大简化运算,因为只要当前状态可知,所有的历史信息都不再需要了,利用当前状态信息就可以决定末来。
3.2.3 马尔可夫过程
马尔可夫过程(Markov process)指具有马尔可夫性质的随机过程,也被称为马尔可夫链(Markov chain)。我们通常用元组\(\langle S,P\rangle\)描述一个马尔可夫过程,其中\(S\)是有限数量的状态集合,\(P\)是状态转移矩阵(state transition matrix) 。假设一共有\(n\)个状态,此时\(S=\{s_1,s_2,\ldots,s_n\}\)。状态转移矩阵\(P\)定义了所有状态对之间的转移概率,即
矩阵\(P\)中第\(i\)行第\(j\)列元素\(P(s_j|s_i)=P(S_{t+1}=s_j|S_t=s_i)\)表示从状态\(s_i\)转移到状态\(s_j\)的概率,我们称\(P(s^{\prime}|s)\)为状态转移函数。从某个状态出发,到达其他状态的概率和必须为 1, 即状态转移矩阵\(P\)的每一行的和为 1。
图 3-1 是一个具有 6 个状态的马尔可夫过程的简单例子。其中每个绿色圆圈表示一个状态,每个状态都有一定概率 (包括概率 为 0) 转移到其他状态,其中\(s_{6}\)通常被称为终止状态 (terminal state),因为它不会再转移到其他状态,可以理解为它永远以概率 1 转移到自己。状态之间的虚线箭头表示状态的转移,箭头旁的数字表示该状态转移发生的概率。从每个状态出发转移到其他状态的概率总和为 1。例如,\(s_1\)有 90%概率保持不变,有 10%概率转移到\(s_{2/}\) 而在\(s_{2}\)又有 50%概率回到\(s_{11}\) 有 50%概率转移到\(s_{3}\).
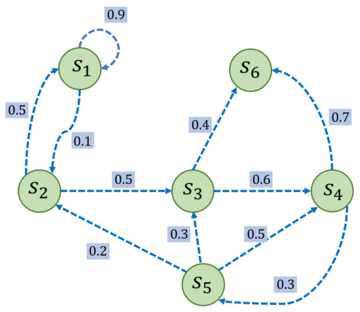
图3-1 马尔可夫过程的一个简单例子
我们可以写出这个马尔可夫过程的状态转移矩阵:
其中第\(i\)行\(j\)列的值\(\mathcal{P}_{i,j}\)则代表从状态\(s_i\)转移到\(s_j\)的概率。
给定一个马尔可夫过程,我们就可以从某个状态出发,根据它的状态转移矩阵生成一个状态序列 (episode),这个步骤也被叫做采样 (sampling) 。例如,从\(s_1\)出发,可以生成序列\(s_1\to s_2\to s_3\to s_6\) 或序列
\(s_1\to s_1\to s_2\to s_3\to s_4\to s_5\to s_3\to s_6\)等。生成这些序列的概率和状态转移矩阵有关。
3.3 马尔可夫奖励过程
在马尔可夫过程的基础上加入奖励函数 和折扣因子,就可以得到马尔可夫奖励过程(Markov reward process)。一个马尔可夫奖励过程由\(\langle S,\mathcal{P},r,\gamma\rangle\)构成,各个组成元素的含义如下所示。
· \(S\)是有限状态的集合。
· \(\mathcal{P}\)是状态转移矩阵。·\(r\)是奖励函数,某个状态\(s\)的奖励 \(r(s)\)指转移到该状态时可以获得奖励的期望。
·γ是折扣因子(discount factor),γ的取值范围为[0,1)。引入折扣因子的理由为远期利益具有一定不确定性,有时我们
更希望能够尽快获得一些奖励,所以我们需要对远期利益打一些折扣。接近 1 的\(\gamma\)更关注长期的累计奖励,接近 0 的\(\gamma\)更考虑短期奖励。
3.3.1 回报
在一个马尔可夫奖励过程中,从第\(t\)时刻状态\(S_t\)开始,直到终止状态时,所有奖励的衰减之和称为回报\(G_t\) (Return),公式如下:
\(G_t=R_t+\gamma R_{t+1}+\gamma^2R_{t+2}+\cdots=\sum_{l=0}^\infty\gamma^kR_{t+k}\)
其中,\(R_t\)表示在时刻\(t\)获得的奖励。在图 3-2 中,我们继续沿用图 3-1 马尔可夫过程的例子,并在其基础上添加奖励函数,构建成一个马尔可夫奖励过程。例如,进入状态\(s_{2}\)可以得到奖励-2,表明我们不希望进入\(s_2\),进入\(s_4\)可以获得最高的奖励10, 但是进入\(s_{6}\)之后奖励为零,并且此时序列也终止了。
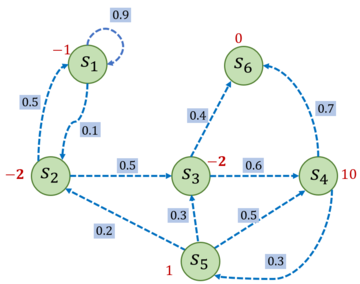
图3-2 马尔可夫奖励过程的一个简单例子
比如选取\(s_{1}\)为起始状态,设置\(\gamma=0.5\),采样到一条状态序列为\(s_1\to s_2\to s_3\to s_6\),就可以计算\(s_1\)的回报\(G_1\),得到\(G_1=-1+0.5\times(-2)+0.5^2\times(-2)=-2.5\)。
接下来我们用代码表示图 3-2 中的马尔可夫奖励过程,并且定义计算回报的函数。
import numpy as np
np.random.seed(0)
# 定义状态转移概率矩阵P
P = [
[0.9, 0.1, 0.0, 0.0, 0.0, 0.0],
[0.5, 0.0, 0.5, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.6, 0.0, 0.4],
[0.0, 0.0, 0.0, 0.0, 0.3, 0.7],
[0.0, 0.2, 0.3, 0.5, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0, 1.0],
]
P = np.array(P)
rewards = [-1, -2, -2, 10, 1, 0] # 定义奖励函数
gamma = 0.5 # 定义折扣因子
# 给定一条序列,计算从某个索引(起始状态)开始到序列最后(终止状态)得到的回报
def compute_return(start_index, chain, gamma):
G = 0
for i in reversed(range(start_index, len(chain))):
G = gamma * G + rewards[chain[i] - 1]
return G
# 一个状态序列,s1-s2-s3-s6
chain = [1, 2, 3, 6]
start_index = 0
G = compute_return(start_index, chain, gamma)
print("根据本序列计算得到回报为:%s。" % G)
根据本序列计算得到回报为:-2.5。
3.3.2 价值函数
在马尔可夫奖励过程中,一个状态的期望回报 (即从这个状态出发的未来累积奖励的期望) 被称为这个状态的价值(value) 。所有状态的价值就组成了价值函数 (value function), 价值函数的输入为某个状态,输出为这个状态的价值。我们将价值函数写成\(V(s)=\mathbb{E}[G_t|S_t=s]\),展开为
\(\begin{aligned} V(s)& =\mathbb{E}[G_t|S_t=s] \\ &=\mathbb{E}[R_t+\gamma R_{t+1}+\gamma^2R_{t+2}+\ldots|S_t=s] \\ &=\mathbb{E}[R_t+\gamma(R_{t+1}+\gamma R_{t+2}+\ldots)|S_t=s] \\ &=\mathbb{E}[R_t+\gamma G_{t+1}|S_t=s] \\ &=\mathbb{E}[R_t+\gamma V(S_{t+1})|S_t=s] \end{aligned}\)
在上式的最后一个等号中,一方面,即时奖励的期望正是奖励函数的输出,即\(\mathbb{E}[R_t|S_t=s]=r(s)\);另一方面,等式中剩余部分\(\mathbb{E}[\gamma V(S_{t+1})|S_t=s]\)可以根据从状态\(s\)出发的转移概率得到,即可以得到
\(V(s)=r(s)+\gamma\sum_{s^{\prime}\in S}p(s^{\prime}|s)V(s^{\prime})\)
上式就是马尔可夫奖励过程中非常有名的贝尔曼方程(Bellman equation),对每一个状态都成立。若一个马尔可夫奖励过程一共有\(n\)个状态,即\(S=\{s_1,s_2,\ldots,s_n\}\),我们将所有状态的价值表示成一个列向量\(\mathcal{V}=[V(s_1),V(s_2),\ldots,V(s_n)]^T\),同理,将奖励函数写成一个列向量\(\mathcal{R}=[r(s_1),r(s_2),\ldots,r(s_n)]^T\)。于是我们可以将贝尔曼方程写成矩阵的形式:
我们可以直接根据矩阵运算求解,得到以下解析解:
\(\begin{aligned}\mathcal{V}&=\mathcal{R}+\gamma\mathcal{P}\mathcal{V}\\(I-\gamma\mathcal{P})\mathcal{V}&=\mathcal{R}\\\mathcal{V}&=(I-\gamma\mathcal{P})^{-1}\mathcal{R}\end{aligned}\)
以上解析解的计算复杂度是\(O(n^3)\),其中\(n\)是状态个数,因此这种方法只适用很小的马尔可夫奖励过程。求解较大规模的马尔可夫奖励过程中的价值函数时,可以使用动态规划 (dynamic programming) 算法、蒙特卡洛方法 (Monte-Carlo method) 和时序差分 (temporal difference) , 这些方法将在之后的章节介绍。
接下来编写代码来实现求解价值函数的解析解方法,并据此计算该马尔可夫奖励过程中所有状态的价值。
def compute(P, rewards, gamma, states_num):
''' 利用贝尔曼方程的矩阵形式计算解析解,states_num是MRP的状态数 '''
rewards = np.array(rewards).reshape((-1, 1)) #将rewards写成列向量形式
value = np.dot(np.linalg.inv(np.eye(states_num, states_num) - gamma * P),
rewards)
return value
V = compute(P, rewards, gamma, 6)
print("MRP中每个状态价值分别为\n", V)
MRP中每个状态价值分别为
[[-2.01950168]
[-2.21451846]
[ 1.16142785]
[10.53809283]
[ 3.58728554]
[ 0. ]]
根据以上代码,求解得到各个状态的价值\(V(s)\), 具体如下:
\(\begin{bmatrix}V(s_1)\\V(s_2)\\V(s_3)\\V(s_4)\\V(s_5)\\V(s_6)\end{bmatrix}=\begin{bmatrix}-2.02\\-2.21\\1.16\\10.54\\3.59\\0\end{bmatrix}\)
我们现在用贝尔曼方程来进行简单的验证。例如,对于状态\(s_{4}\)来说,当\(\gamma=0.5\)时,有
可以发现左右两边的值几乎是相等的,说明我们求解得到的价值函数是满足状态为\(s_{4}\)时的贝尔曼方程。读者可以自行验证在其他状态时贝尔曼方程是否也成立。若贝尔曼方程对于所有状态都成立,就可以说明我们求解得到的价值函数是正确的。除了使用动态规划算法,马尔可夫奖励过程中的价值函数也可以通过蒙特卡洛方法估计得到,我们将在 3.5 节中介绍该方法。
3.4. 马尔可夫决策过程
3.2 节和 3.3 节讨论到的马尔可夫过程和马尔可夫奖励过程都是自发改变的随机过程;而如果有一个外界的“刺激”来共同改变这个随机过程,就有了马尔可夫决策过程(Markov decision process,MDP)。我们将这个来自外界的刺激称为智能体(agent)的动作,在马尔可夫奖励过程(MRP)的基础上加入动作,就得到了马尔可夫决策过程(MDP)。马尔可夫决策过程由元组\(\langle S,\mathcal{A},P,r,\gamma\rangle\)构成,其中:
· \(S\)是状态的集合;
· \(A\)是动作的集合;
· \(\gamma\)是折扣因子;
·\(r(s,a)\)是奖励函数,此时奖励可以同时取决于状态\(s\)和动作\(a\),在奖励函数只取决于状态\(s\)时,则退化为\(r(s)\);
·\(P(s^{\prime}|s,a)\)是状态转移函数,表示在状态\(s\)执行动作\(a\)之后到达状态\(s^{\prime}\)的概率。
我们发现 MDP 与 MRP 非常相像,主要区别为 MDP 中的状态转移函数和奖励函数都比 MRP 多了动作\(a\)作为自变量。注意, 在上面 MDP 的定义中,我们不再使用类似 MRP 定义中的状态转移矩阵方式,而是直接表示成了状态转移函数。这样做一是因为此时状态转移与动作也有关,变成了一个三维数组,而不再是一个矩阵(二维数组); 二是因为状态转移函数更具有一般意义,例如,如果状态集合不是有限的,就无法用数组表示,但仍然可以用状态转移函数表示。我们在之后的课程学习中会遇到连续状态的 MDP 环境,那时状态集合都不是有限的。现在我们主要关注于离散状态的 MDP 环境,此时状态集合是有限的。
不同于马尔可夫奖励过程,在马尔可夫决策过程中,通常存在一个智能体来执行动作。例如,一艘小船在大海中随着水流自由飘荡的过程就是一个马尔可夫奖励过程,它如果凭借运气漂到了一个目的地,就能获得比较大的奖励;如果有个水手在控制着这条船往哪个方向前进,就可以主动选择前往目的地获得比较大的奖励。马尔可夫决策过程是一个与时间相关的不断进行的过程,在智能体和环境 MDP 之间存在一个不断交互的过程。一般而言,它们之间的交互是如图 3-3 循环过程:智能体根据当前状态\(S_t\)选择动作\(A_t;\) 对于状态\(S_t\)和动作\(A_t\),MDP 根据奖励函数和状态转移函数得到\(S_{t+1}\)和\(R_t\)并反馈给智能体。智能体的目标是最大化得到的累计奖励。智能体根据当前状态从动作的集合\(A\)中选择一个动作的函数,被称为策略。
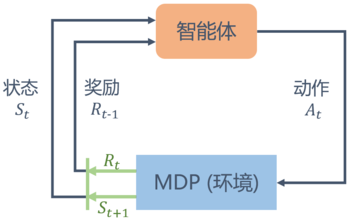
图3-3 智能体与环境MDP的交互示意图
3.4.1 策略
智能体的策略 (Policy) 通常用字母\(\pi\)表示。策略\(\pi(a|s)=P(A_t=a|S_t=s)\)是一个函数,表示在输入状态\(s\)情况下采取动作\(a\)的概率。当一个策略是确定性策略 (deterministic policy) 时,它在每个状态时只输出一个确定性的动作,即只有该动作的概率为 1, 其他动作的概率为 0; 当一个策略是随机性策略 (stochastic policy) 时,它在每个状态时输出的是关于动作的概率分布,然后根据该分布进行采样就可以得到一个动作。在 MDP 中,由于马尔可夫性质的存在,策略只需要与当前状态有关, 不需要考虑历史状态。回顾一下在 MRP 中的价值函数,在 MDP 中也同样可以定义类似的价值函数。但此时的价值函数与策略有关,这意为着对于两个不同的策略来说,它们在同一个状态下的价值也很可能是不同的。这很好理解,因为不同的策略会采取不同的动作,从而之后会遇到不同的状态,以及获得不同的奖励,所以它们的累积奖励的期望也就不同,即状态价值不同。
3.4.2 状态价值函数
我们用\(V^{\pi}(s)\)表示在 MDP 中基于策略\(\pi\)的状态价值函数 (state-value function), 定义为从状态\(s\)出发遵循策略\(\pi\)能获得的期望回报,数学表达为:
3.4.3 动作价值函数
不同于 MRP,在 MDP 中,由于动作的存在,我们额外定义一个动作价值函数 (action-value function) 。我们用\(Q^{\pi}(s,a)\)表示在 MDP 遵循策略\(\pi\)时,对当前状态\(s\)执行动作\(a\)得到的期望回报:
状态价值函数和动作价值函数之间的关系:在使用策略\(\pi\)中,状态\(s\)的价值等于在该状态下基于策略\(\pi\)采取所有动作的概率与相应的价值相乘再求和的结果:
使用策略\(\pi\)时,状态\(s\)下采取动作\(a\)的价值等于即时奖励加上经过衰减后的所有可能的下一个状态的状态转移概率与相应的价值的乘积:
3.4.4 贝尔曼期望方程
在贝尔曼方程中加上“期望”二字是为了与接下来的贝尔曼最优方程进行区分。我们通过简单推导就可以分别得到两个价值函数的贝尔曼期望方程(Bellman Expectation Equation):
价值函数和贝尔曼方程是强化学习非常重要的组成部分,之后的一些强化学习算法都是据此推导出来的,读者需要明确掌握。
图 3-4 是一个马尔可夫决策过程的简单例子,其中每个深色圆圈代表一个状态,一共有从\(s_1\sim s_5\)这 5 个状态。黑色实线箭头代表可以采取的动作,浅色小圆圈代表动作,需要注意,并非在每个状态都能采取所有动作,例如在状态\(s_{1}\), 智能体只能采取"保持\(s_1\)"和"前往\(s_{2}\)"这两个动作,无法采取其他动作。
每个浅色小圆圈旁的数字代表在某个状态下采取某个动作能获得的奖励。虚线箭头代表采取动作后可能转移到的状态,箭头边上的数字代表转移概率,如果没有数字则表示转移概率为1。例如,在\(s_2\)下,如果采取动作“前往\(s_{3}\)”,就能得到奖励-2,并且转移到\(s_3\);在\(s_4\)下,如果采取"概率前往",就能得到奖励 1, 并且会分别以概率 0.2,0.4,0.4 转移到\(s_2s_3\)或\(s_4\)。
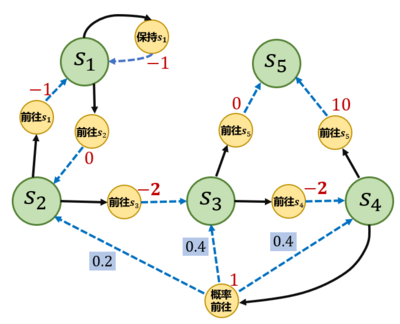
图3-4 马尔可夫决策过程的一个简单例子
接下来我们编写代码来表示图 3-4 中的马尔可夫决策过程,并定义两个策略。第一个策略是一个完全随机策略,即在每个状态下,智能体会以同样的概率选取它可能采取的动作。例如,在\(s_1\)下,智能体会以 0.5 和 0.5 的概率选取动作"保持\(s_{1}^{\prime\prime}\)和“前往\(s_{2}\) ”。第二个策略是一个提前设定的一个策略。
S = ["s1", "s2", "s3", "s4", "s5"] # 状态集合
A = ["保持s1", "前往s1", "前往s2", "前往s3", "前往s4", "前往s5", "概率前往"] # 动作集合
# 状态转移函数
P = {
"s1-保持s1-s1": 1.0,
"s1-前往s2-s2": 1.0,
"s2-前往s1-s1": 1.0,
"s2-前往s3-s3": 1.0,
"s3-前往s4-s4": 1.0,
"s3-前往s5-s5": 1.0,
"s4-前往s5-s5": 1.0,
"s4-概率前往-s2": 0.2,
"s4-概率前往-s3": 0.4,
"s4-概率前往-s4": 0.4,
}
# 奖励函数
R = {
"s1-保持s1": -1,
"s1-前往s2": 0,
"s2-前往s1": -1,
"s2-前往s3": -2,
"s3-前往s4": -2,
"s3-前往s5": 0,
"s4-前往s5": 10,
"s4-概率前往": 1,
}
gamma = 0.5 # 折扣因子
MDP = (S, A, P, R, gamma)
# 策略1,随机策略
Pi_1 = {
"s1-保持s1": 0.5,
"s1-前往s2": 0.5,
"s2-前往s1": 0.5,
"s2-前往s3": 0.5,
"s3-前往s4": 0.5,
"s3-前往s5": 0.5,
"s4-前往s5": 0.5,
"s4-概率前往": 0.5,
}
# 策略2
Pi_2 = {
"s1-保持s1": 0.6,
"s1-前往s2": 0.4,
"s2-前往s1": 0.3,
"s2-前往s3": 0.7,
"s3-前往s4": 0.5,
"s3-前往s5": 0.5,
"s4-前往s5": 0.1,
"s4-概率前往": 0.9,
}
# 把输入的两个字符串通过“-”连接,便于使用上述定义的P、R变量
def join(str1, str2):
return str1 + '-' + str2
接下来我们想要计算该 MDP 下,一个策略\(\pi\)的状态价值函数。我们现在有的工具是 MRP 的解析解方法。于是,一个很自然的想法是:给定一个 MDP 和一个策略\(\pi\),我们是否可以将其转化为一个 MRP? 答案是肯定的。我们可以将策略的动作选择进行边缘化 (marginalization),就可以得到没有动作的 MRP 了。具体来说,对于某一个状态,我们根据策略所有动作的概率进行加权,得到的奖励和就可以认为是一个 MRP 在该状态下的奖励,即:
同理,我们计算采取动作的概率与使\(s\)转移到\(s^{\prime}\)的概率的乘积,再将这些乘积相加,其和就是一个 MRP 的状态从\(s\)转移至\(s^{\prime}\)的概率:
于是,我们构建得到了一个 MRP:\(\langle S,P^{\prime},r^{\prime},\gamma\rangle\)。根据价值函数的定义可以发现,转化前的 MDP 的状态价值函数和转化后的MRP 的价值函数是一样的。于是我们可以用 MRP 中计算价值函数的解析解来计算这个 MDP 中该策略的状态价值函数。
我们接下来就编写代码来实现该方法,计算用随机策略 (也就是代码中的 Pi_1) 时的状态价值函数。为了简单起见,我们直接给出转化后的 MRP 的状态转移矩阵和奖励函数,感兴趣的读者可以自行验证。
gamma = 0.5
# 转化后的MRP的状态转移矩阵
P_from_mdp_to_mrp = [
[0.5, 0.5, 0.0, 0.0, 0.0],
[0.5, 0.0, 0.5, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.5, 0.5],
[0.0, 0.1, 0.2, 0.2, 0.5],
[0.0, 0.0, 0.0, 0.0, 1.0],
]
P_from_mdp_to_mrp = np.array(P_from_mdp_to_mrp)
R_from_mdp_to_mrp = [-0.5, -1.5, -1.0, 5.5, 0]
V = compute(P_from_mdp_to_mrp, R_from_mdp_to_mrp, gamma, 5)
print("MDP中每个状态价值分别为\n", V)
MDP中每个状态价值分别为
[[-1.22555411]
[-1.67666232]
[ 0.51890482]
[ 6.0756193 ]
[ 0. ]]
知道了状态价值函数\(V^\pi(s)\)后,我们可以计算动作价值函数\(Q^\pi(s,a)\)。例如 (\(s_4\), 概率前往) 的动作价值为 2.152, 根据以下公式可以计算得到:
这个 MRP 解析解的方法在状态动作集合比较大的时候不是很适用,那有没有其他的方法呢?第 4 章将介绍用动态规划算法来计算得到价值函数。3.5 节将介绍用蒙特卡洛方法来近似估计这个价值函数,用蒙特卡洛方法的好处在于我们不需要知道 MDP 的状态转移函数和奖励函数,它可以得到一个近似值,并且采样数越多越淮确。
3.5 蒙特卡洛方法
蒙特卡洛方法(Monte-Carlo methods)也被称为统计模拟方法,是一种基于概率统计的数值计算方法。运用蒙特卡洛方法时,我们通常使用重复随机抽样,然后运用概率统计方法来从抽样结果中归纳出我们想求的目标的数值估计。一个简单的例子是用蒙特卡洛方法来计算圆的面积。例如,在图 3-5 所示的正方形内部随机产生若干个点,细数落在圆中点的个数,圆的面积与正方形面积之比就等于圆中点的个数与正方形中点的个数之比。如果我们随机产生的点的个数越多,计算得到圆的面积就越接近于真实的圆的面积。
圆的面积/正方形的面积=圆中点的个数/正方形中点的个数
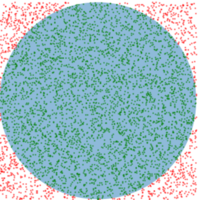
图3-5 用蒙特卡洛方法估计圆的面积
我们现在介绍如何用蒙特卡洛方法来估计一个策略在一个马尔可夫决策过程中的状态价值函数。回忆一下,一个状态的价值是它的期望回报,那么一个很直观的想法就是用策略在 MDP 上采样很多条序列,计算从这个状态出发的回报再求其期望就可以了,公式如下:
在一条序列中,可能没有出现过这个状态,可能只出现过一次这个状态,也可能出现过很多次这个状态。我们介绍的蒙特卡洛价值估计方法会在该状态每一次出现时计算它的回报。还有一种选择是一条序列只计算一次回报,也就是这条序列第一次出现该状态时计算后面的累积奖励,而后面再次出现该状态时,该状态就被忽略了。假设我们现在用策略\(\pi\)从状态\(s\)开始采样序
列,据此来计算状态价值。我们为每一个状态维护一个计数器和总回报,计算状态价值的具体过程如下所示。
(1) 使用策略\(\pi\)采样若干条序列:
(2) 对每一条序列中的每一时间步\(t\)的状态\(s\)进行以下操作:
· 更新状态\(s\)的计数器 \(N(s)\gets N(s)+1;\)
· 更新状态\(s\)的总回报 \(M(s)\gets M(s)+G_t;\)
(3)每一个状态的价值被估计为回报的平均值 \(V(s)=M(s)/N(s)\)。
根据大数定律,当\(N(s)\to\infty\),有\(V(s)\to V^{\pi}(s)\)。计算回报的期望时,除了可以把所有的回报加起来除以次数,还有一种增量更新的方法。对于每个状态\(s\)和对应回报\(G\), 进行如下计算:
· \(N(s)\gets N(s)+1\)
这种增量式更新期望的方法已经在第 2 章中展示过。
接下来我们用代码定义一个采样函数。采样函数需要遵守状态转移矩阵和相应的策略,每次将(s,a,r,s_next)元组放入序列中,直到到达终止序列。然后我们通过该函数,用随机策略在图 3-4 的 MDP 中随机采样几条序列。
def sample(MDP, Pi, timestep_max, number):
''' 采样函数,策略Pi,限制最长时间步timestep_max,总共采样序列数number '''
S, A, P, R, gamma = MDP
episodes = []
for _ in range(number):
episode = []
timestep = 0
s = S[np.random.randint(4)] # 随机选择一个除s5以外的状态s作为起点
# 当前状态为终止状态或者时间步太长时,一次采样结束
while s != "s5" and timestep <= timestep_max:
timestep += 1
rand, temp = np.random.rand(), 0
# 在状态s下根据策略选择动作
for a_opt in A:
temp += Pi.get(join(s, a_opt), 0)
if temp > rand:
a = a_opt
r = R.get(join(s, a), 0)
break
rand, temp = np.random.rand(), 0
# 根据状态转移概率得到下一个状态s_next
for s_opt in S:
temp += P.get(join(join(s, a), s_opt), 0)
if temp > rand:
s_next = s_opt
break
episode.append((s, a, r, s_next)) # 把(s,a,r,s_next)元组放入序列中
s = s_next # s_next变成当前状态,开始接下来的循环
episodes.append(episode)
return episodes
# 采样5次,每个序列最长不超过20步
episodes = sample(MDP, Pi_1, 20, 5)
print('第一条序列\n', episodes[0])
print('第二条序列\n', episodes[1])
print('第五条序列\n', episodes[4])
第一条序列
[('s1', '前往s2', 0, 's2'), ('s2', '前往s3', -2, 's3'), ('s3', '前往s5', 0, 's5')]
第二条序列
[('s4', '概率前往', 1, 's4'), ('s4', '前往s5', 10, 's5')]
第五条序列
[('s2', '前往s3', -2, 's3'), ('s3', '前往s4', -2, 's4'), ('s4', '前往s5', 10, 's5')]
# 对所有采样序列计算所有状态的价值
def MC(episodes, V, N, gamma):
for episode in episodes:
G = 0
for i in range(len(episode) - 1, -1, -1): #一个序列从后往前计算
(s, a, r, s_next) = episode[i]
G = r + gamma * G
N[s] = N[s] + 1
V[s] = V[s] + (G - V[s]) / N[s]
timestep_max = 20
# 采样1000次,可以自行修改
episodes = sample(MDP, Pi_1, timestep_max, 1000)
gamma = 0.5
V = {"s1": 0, "s2": 0, "s3": 0, "s4": 0, "s5": 0}
N = {"s1": 0, "s2": 0, "s3": 0, "s4": 0, "s5": 0}
MC(episodes, V, N, gamma)
print("使用蒙特卡洛方法计算MDP的状态价值为\n", V)
使用蒙特卡洛方法计算MDP的状态价值为
{'s1': -1.228923788722258, 's2': -1.6955696284402704, 's3': 0.4823809701532294, 's4': 5.967514743019431, 's5': 0}
可以看到用蒙特卡洛方法估计得到的状态价值和我们用 MRP 解析解得到的状态价值是很接近的。这得益于我们采样了比较多的序列,感兴趣的读者可以尝试修改采样次数,然后观察蒙特卡洛方法的结果。
3.6 占用度量
3.4 节提到,不同策略的价值函数是不一样的。这是因为对于同一个 MDP,不同策略会访问到的状态的概率分布是不同的。想象一下,图3-4 的 MDP 中现在有一个策略,它的动作执行会使得智能体尽快到达终止状态\(s_{5}\),于是当智能体处于状态\(s_{3}\)时, 不会采取“前往\(s_{4}\)”的动作,而只会以 1 的概率采取"前往\(s_{5}\)“的动作,所以智能体也不会获得在\(s_{4}\)状态下采取“前往\(s_{5}\)”可以得到的很大的奖励 10。可想而知,根据贝尔曼方程,这个策略在状态\(s_{3}\)的概率会比较小,究其原因是因为它没法到达状态\(s_{4}\)。因此我们需要理解不同策略会使智能体访问到不同概率分布的状态这个事实,这会影响到策略的价值函数。
首先我们定义 MDP 的初始状态分布为\(\nu_0(s)\),在有些资料中,初始状态分布会被定义进 MDP 的组成元素中。我们用\(P_t^\pi(s)\)表示采取策略\(\pi\)使得智能体在\(t\)时刻状态为\(s\)的概率,所以我们有\(P_0^\pi(s)=\nu_0(s)\),然后就可以定义一个策略的状态访问分布 (state visitation distribution) :
\(\nu^\pi(s)=(1-\gamma)\sum_{t=0}^\infty\gamma^tP_t^\pi(s)\)
其中,\(1-\gamma\)是用来使得概率加和为 1 的归一化因子。状态访问概率表示一个策略和 MDP 交互会访问到的状态的分布。需要注意的是,理论上在计算该分布时需要交互到无穷步之后,但实际上智能体和 MDP 的交互在一个序列中是有限的。不过我们仍然可以用以上公式来表达状态访问概率的思想,状态访问概率有如下性质:
此外,我们还可以定义策略的占用度量 (occupancy measure) :
它表示动作状态对\((s,a)\)被访问到的概率。二者之间存在如下关系:
进一步得出如下两个定理。
定理 1: 智能体分别以策略\(\pi_1\)和\(\pi_2\)和同一个 MDP 交互得到的占用度量\(\rho^{\pi_1}\)和\(\rho^\mathrm{\pi_2}\)满足
定理 2: 给定一合法占用度量\(\rho\), 可生成该占用度量的唯一策略是
注意:以上提到的"合法"占用度量是指存在一个策略使智能体与 MDP 交互产生的状态动作对被访问到的概率。
接下来我们编写代码来近似估计占用度量。这里我们采用近似估计,即设置一个较大的采样轨迹长度的最大值,然后采样很多次,用状态动作对出现的频率估计实际概率。
def occupancy(episodes, s, a, timestep_max, gamma):
''' 计算状态动作对(s,a)出现的频率,以此来估算策略的占用度量 '''
rho = 0
total_times = np.zeros(timestep_max) # 记录每个时间步t各被经历过几次
occur_times = np.zeros(timestep_max) # 记录(s_t,a_t)=(s,a)的次数
for episode in episodes:
for i in range(len(episode)):
(s_opt, a_opt, r, s_next) = episode[i]
total_times[i] += 1
if s == s_opt and a == a_opt:
occur_times[i] += 1
for i in reversed(range(timestep_max)):
if total_times[i]:
rho += gamma**i * occur_times[i] / total_times[i]
return (1 - gamma) * rho
gamma = 0.5
timestep_max = 1000
episodes_1 = sample(MDP, Pi_1, timestep_max, 1000)
episodes_2 = sample(MDP, Pi_2, timestep_max, 1000)
rho_1 = occupancy(episodes_1, "s4", "概率前往", timestep_max, gamma)
rho_2 = occupancy(episodes_2, "s4", "概率前往", timestep_max, gamma)
print(rho_1, rho_2)
0.112567796310472 0.23199480615618912
通过以上结果可以发现,不同策略对于同一个状态动作对的占用度量是不一样的。
3.7 最优策略
强化学习的目标通常是找到一个策略,使得智能体从初始状态出发能获得最多的期望回报。我们首先定义策略之间的偏序关系:当且仅当对于任意的状态\(s\)都有\(V^{\pi}(s)\geq V^{\pi^{\prime}}(s)\),记\(\pi>\pi^{\prime}\)。于是在有限状态和动作集合的 MDP 中,至少存在一个策略比其他所有策略都好或者至少存在一个策略不差于其他所有策略,这个策略就是最优策略(optimal policy)。最优策略可能有很多个,我们都将其表示为\(\pi^*(s)\)。
最优策略都有相同的状态价值函数,我们称之为最优状态价值函数,表示为:
同理,我们定义最优动作价值函数:
为了使\(Q^{\pi}(s,a)\)最大,我们需要在当前的状态动作对\((s,a)\)之后都执行最优策略。于是我们得到了最优状态价值函数和最优动作价值函数之间的关系:
这与在普通策略下的状态价值函数和动作价值函数之间的关系是一样的。另一方面,最优状态价值是选择此时使最优动作价值最大的那一个动作时的状态价值:
3.7.1 贝尔曼最优方程
根据\(V^*(s)\)和\(Q^*(s,a)\)的关系,我们可以得到贝尔曼最优方程 (Bellman optimality equation) :
第 4 章将介绍如何用动态规划算法得到最优策略。
3.8 总结
本章从零开始介绍了马尔可夫决策过程的基础概念知识,并讲解了如何通过求解贝尔曼方程得到状态价值的解析解以及如何用蒙特卡洛方法估计各个状态的价值。马尔可夫决策过程是强化学习中的基础概念,强化学习中的环境就是一个马尔可夫决策过程。我们接下来将要介绍的强化学习算法通常都是在求解马尔可夫决策过程中的最优策略。
