
NLP(五十一):利用对比学习设计自己的损失函数
转https://zhuanlan.zhihu.com/p/590547670
Contrastive Loss简介
对比损失在非监督学习中应用很广泛。最早源于2006年Yann LeCun的”Dimensionality Reduction by Learning an Invariant Mapping“,该损失函数主要是用于降维中,即本来相似的样本,在经过降维(特征提取)后,在特征空间中,两个样本仍旧相似;而原本不相似的样本,在经过降维后,在特征空间中,两个样本仍旧不相似。同样,该损失函数也可以很好的表达成对样本的匹配程度。
在非监督学习时,对于一个数据集内的所有样本,因为我们没有样本真实标签,所以在对比学习框架下,通常以每张图片作为单独的语义类别,并假设:同一个图片做不同变换后不改变其语义类别,比如一张猫的图片,旋转或局部图片都不能改变其猫的特性。
因此,假设对于原始图片X,分别对其做不同变换得到A和B,此时对比损失希望A、B之间的特征距离要小于A和任意图片Y的特征距离。
Contrastive Loss定义
定义对比损失函数L为:
�(�,(�,�1,�2))=1�∑�=1����2+(1−�)���(�−��,0)2
其中, ��(�1,�2)=||�1−�2||2=(∑�=1�(�1�−�2�)2)12
�� 代表两个样本特征的欧式距离, � 代表特征的维度, � 为两个样本是否匹配的标签( �=1 代表两个样本相似或匹配, �=0 代表两个样本不相似或不匹配), � 为设定的阈值(超过 � 的把其loss看作0,即如果两个不相似特征离得很远,那么对比loss应该是很低的), � 为样本数量。
通过 �(�,(�,�1,�2))=1�∑�=1����2+(1−�)���(�−��,0)2 可以发现,对比损失可以很好的描述成对样本的匹配程度,可以很好的用于训练提取特征的模型:
当 �=1时,即两个样本相似或匹配时,损失函数��=1�∑�=1����2,即如果原本相似或匹配的样本如果其被模型提取的特征欧氏距离很大,说明模型效果不好导致loss很大。
当�=0时,即两个样本不相似或不匹配时,损失函数��=(1−�)���(�−��,0)2,如果这时两个样本被模型提取的特征欧式距离很小,那么loss会变大以增大模型的惩罚从而使loss减小,如果两个样本被模型提取的特征欧式距离很大,说明两个样本特征离得很远,此时如果超过阈值 � 则把其loss看作0,此时的loss很小。
应用了对比损失的工作小结
Improved Deep Metric Learning with Multi-class N-pair Loss Objective-2016
N-pair loss,需要从N个不同的类中构造N对样本,自监督学习
本文是基于Distance metric learning,目标是学习数据表征,但要求在embedding space中保持相似的数据之间的距离近,不相似的数据之间的距离远。其实在诸如人脸识别和图片检索的应用中,就已经使用了contrastive loss和triplet loss,但仍然存在一些问题,比如收敛慢,陷入局部最小值,相当部分原因就是因为损失函数仅仅只使用了一个negative样本,在每次更新时,与其他的negative的类没有交互。之前LeCun提出的对比损失只考虑输入成对的样本去训练一个神经网络去预测它们是否属于同一类,上文已经解释了对比损失。
Triplet loss(三元损失函数)是Google在2015年发表的FaceNet论文中提出的,与前文的对比损失目的是一致的,具体做法是考虑到query样本和postive样本的比较以及query样本和negative样本之间的比较,Triplet Loss的目标是使得相同标签的特征在空间位置上尽量靠近,同时不同标签的特征在空间位置上尽量远离,同时为了不让样本的特征聚合到一个非常小的空间中要求对于同一类的两个正例和一个负例,负例应该比正例的距离至少远m
(margin):
�tri�(�,�+,�−;�)=max(0,‖�−�+‖22−‖�−�−‖22+�)
该loss将促使query样本和positive样本之间的距离比query样本和negative样本之间的距离大于m
(margin)。
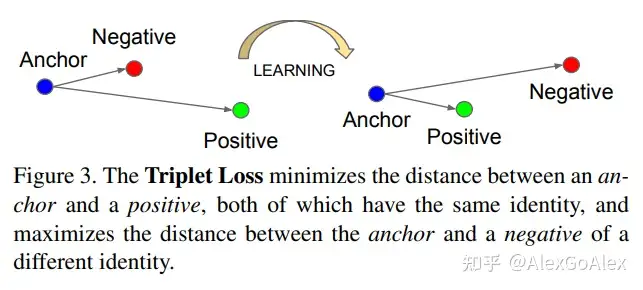
但是三元损失函数考虑的negative样本太少了,收敛慢,因此,本文提出了一个考虑多个negative样本的方法: (N+1)-tuplet loss,即训练样本为样本x以及(N-1)个negative样本和一个positive样本,当N=2时,即是triplet loss。训练样本为{�,�+,�1,⋯,��−1}:�+是一个positive样本,{��}�=1�−1是(N-1)个negative 样本。
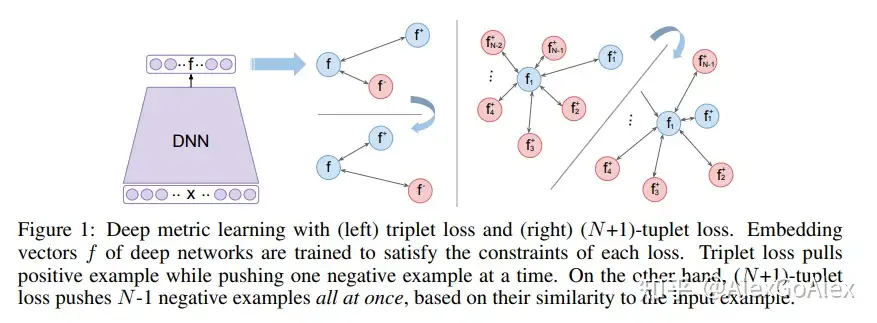
由图所示(蓝色代表positive样本,红色代表negative样本),Triplet loss在将positive样本拉近的同时一次只能推离一个negative样本;而(N+1)-tuplet loss基于样本之间的相似性,一次可以将(N-1)个negative样本推离(提高了收敛速度),而且N的值越大,负样本数越多,近似越准确。
但是如果直接采用(N+1)-tuplet loss,batch size 为N,那么一次更新需要传递Nx(N+1)个样本,网络层数深的时候会有问题,为了避免过大的计算量,本文提出了N-pair loss,如下图:
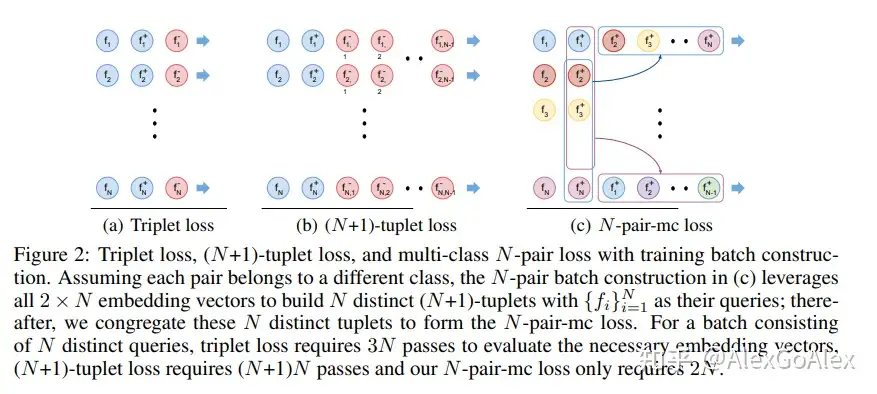
N-pair loss其实就是重复利用了embedding vectors的计算来作为negative样本(把其他样本的正样本作为当前样本的负样本,这样就不用重复计算不同样本的负样本,只需要计算N次即可得出),避免了每一行都要计算新的negative样本的embedding vectors, 从而将�×(�+1)的计算量降低为2N(batch size=N,需要计算N次,之前计算负样本需要计算N次,所以计算量=N+N=2N)。
上述文章的亮点在于,首先提出了需要在三元损失函数中加入更多的负样本提高收敛速度,然后又想到了一种方式通过将其他样本的正样本当作当前样本的负样本的方法降低了计算复杂度。
Unsupervised Feature Learning via Non-Parametric Instance Discrimination-2018
Instance discrimination区分不同实例,将当前实例于不同实例进行空间划分
memory bank由数据集中所有样本的表示组成。
本文将instance discrimination机智地引入了memory bank机制,并且真正地把loss用到了unsupervised learning。该论文主要论述如何通过非参数的instance discrimination进行无监督的特征学习。主要的思想是将每个单一实例都看作不同的“类”。
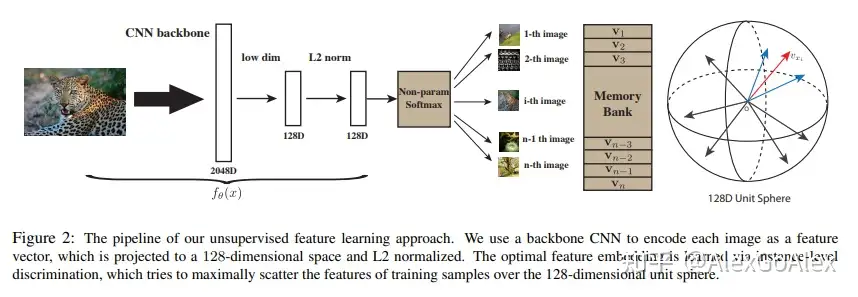
通过CNN backbone,原始图片输入网络后输出一个经过L2标准化的128维向量,通过Non-Parametric Softmax Classifier计算每个单一样本被识别正确的概率,同时使用Memory Bank存储特征向量,通过NCE(noise-contrastive estimation,噪音对比估计)来近似估计softmax的数值减少计算复杂度,最后使用Proximal Regularization稳定训练过程的波动性。实例间的相似度直接从特征中以非参数方式计算,即:每个实例的特征存储在离散的bank中,而不是网络的权重。
噪声对比估计是一种采样损失,通常用于训练具有较大输出词汇量的分类器。在大量可能的类上计算softmax开销非常大。使用NCE,我们可以通过训练分类器从“真实”分布和人工生成的噪声分布中区分样本,从而将问题简化为二分类问题。
因此,主要有以下三个问题需要考虑:
- 能否仅通过特征表示来区分不同的实例。
- 能否通过纯粹的判别学习(discriminative learning)反应样本间的相似性。
- 将不同个例都看作不同的“类”,那这个数量将是巨大的,该如何进行处理。
Non-Parametric Softmax Classifier
采用softmax的instance-level的分类目标,假如有n个images �1,…,�� ,即有n个类, ��=��(��) ,它们的特征为�1,…,�� 。传统的parametric的softmax可以表示为:
�(�|�)=exp(����)∑�=1�exp(����)
其中 �� 是类别j的权重向量, ���� 用来评价v与第j个实例的匹配程度。这种loss的问题是权重向量只是作为一种类的prototype,而无法对实例之间进行明确的比较。所以本文通过替换����为����,并且限制‖�‖=1,可以得到一种non-parametric的softmax函数,这样就不用训练权重参数:
�(�|�)=exp(����/�)∑�=1�exp(����/�),�是temperature参数,控制softmax的平滑程度。
非参数的softmax主要思路是每个样本特征除了可以作为特征之外,也可以起到分类器的作用。因为L2-norm之后的特征乘积本身就等于cos相似性,cos(��,�)=����。学习的目标就是最大化joint probability:
∏�=1���(�|��(��)) ,即每一个 ��(�|��(��)) 越大越好,也等同于最小化negative log-likelihood:
�(�)=−∑�=1�log�(�|��(��))=−∑�=1�logexp(����/�)∑�=1�exp(����/�) , ��=��(��)
使用Mermory Bank V 来存储上述的 {��},在每个iteration对应修改其值��→��,在初始化时通过单位随机向量对V进行初始化。
NCE Loss
如果直接用上述的loss function去训练,当类的数量n很大时,要求的计算量非常大,于是使用NCE来估算。其基本思想是将多分类问题转化为一组二分类问题,其中二分类任务是区分数据样本和噪声样本。关于对NCE loss的理解如下:
当我们设计一个模型来拟合数据时,经常会遇上指数族分布:
�(�)=exp�^(�)�
其中分母部分是归一化常数,一个目的是用来让这个分布真的成为一个“分布”要求(分布积分=1)。很多时候,比如计算一个巨大(几十上百万词)的词表在每一个词上的概率得分的时候,计算这个分母会变得非常非常非常消耗资源。
比如一个language model最后softmax层中,在inference阶段其实只要找到argmax的那一项就够了,并不需要归一化,但在training stage,由于分母Z中是包含了模型参数的,所以也要一起参与优化,所以这个计算省不了。
而NCE做了一件很intuitive的事情:用负样本采样的方式,不计算完整的归一化项。让模型通过负样本,估算出真实样本的概率,从而在真实样本上能做得了极大似然。相当于把任务转换成了一个分类任务,然后再用类似交叉熵的方式来对模型进行优化(其实本质上是优化了两个部分:模型本身,和一个负例采样的分布和参数)。
另一方面,NCE其实证明了这种采样在负例足够多的情况下,对模型梯度优化方向和“完整计算归一化项进行优化”是一致的,这一点证明了NCE在用负采样方式解决归一化项的正确性。
Memory bank中特征表示 � 对应于第 � 个样例的概率为:
�(�|�)=���(����/�)��
��=∑�=1����(����/�)
我们设定噪声分布为一个均匀分布: ��=1/� ,假设噪声样本的频率是数据样本的 � 倍,那么样本 � 及特征�来自数据分布 ()(�=1) 的后验概率为:
ℎ(�,�):=�(�=1|�,�)=�(�|�)�(�|�)+���(�)
训练目标为最小化 ����(�)=−���[logℎ(�,�)]−�⋅���[log(1−ℎ(�,�′)]
其中, �� 指代真实数据分布,对��而言�是 �� 的特征; �′ 是来自另一幅图片,从噪声分布 �� 中随机采样得到。注:�和�′都是从Memory Bank中采样得到的。
�� 的计算量过大,我们把它当作常量,由Monte Carlo算法估计得到:
�≈��≈���[���(�����/�)]=��∑�=1����(������/�)
{��}是indices的随机子集,NCE将每个样例的计算复杂度从 �(�) 减少到 �(1) 。
最后一点是,这篇文章加入了近似正则化项‖��(�)−��(�−1)‖22,来使训练过程更加平滑和稳定。
本文引入 memory bank把前一个step 学习到的实例特征存储起来,然后在下一个step把这些存储的memory去学习。效率有所提升。但是实际在优化的时候当前的实例特征是跟outdated memory去对比的,所以学习效果还不是最优的。
Momentum Contrast for Unsupervised Visual Representation Learning-2020
MoCo
解决了一个非常重要的工程问题:如何节省内存节省时间搞到大量的negative samples?
至于文章的motivation,之前contrastive learning存在两种问题。在用online的dictionary时,也就是文章中比较的end-to-end情形,constrastive learning的性能会受制于batch size,或者说显存大小。在用offline的dictionary时,也就是文章中说的memory bank(InstDisc)情形,dictionary是由过时的模型生成的,某种程度上可以理解为supervision不干净,影响训练效果。那么很自然的,我们想要一个trade-off,兼顾dictionary的大小和质量。文章给出的解法是对模型的参数空间做moving average,相当于做一个非常平滑的update。
MoCo完全专注在 Contrastive Loss 上,将这个问题想象成有一个很大的字典,神经网络的目的就是一个 Encoder 要将图片 Encode 成唯一的一把 Key ,此时要如何做到让Key Space Large and Consistent 是最重要的。

首先借鉴了instance discrimination的文章的Memory Bank ,建一个 Bank 来保存所有的 Key (或称为 Feature)。此方法相对把所有图塞进 Batch少用很多内存,但对于很大的 Dataset 依旧难以按比例扩大。
因此,MoCo改进了 Bank,用一个 Dynamic Queue 来取代,但是单纯这样做的话是行不通的,因为每次个 Key 会受到 Network 改变太多,Contrastive Loss 无法收敛。 因此 MoCo将种子 feature extractor 拆成两个独立的 Network: Encoder 和 Momentum Encoder。
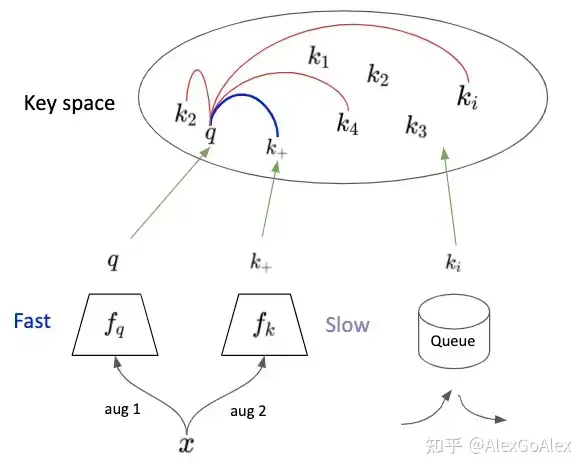
�� ::Encoder, �� :Momentum Encoder, 初始化时,它们的参数值一致。Queue里maintain着最新的K个key。
为了结合图5对文章中的Algorithm进行分析,我们假设Batch size N=1,同样的x经过不同的augmentation,encode为q和 �+ ,它们俩为positive pair。将q与Queue中的K个key (Negative Sample )进行比较,计算 Similarity 。由此,即可按照上述的N-pair contrastive loss计算loss,并对 �� Encoder 更新parameters。等Encoder Update 完后,在用 Momentum Update �� Momentum Encoder。 并将这次的 Batch 放入到 Queue 中。
�k←��k+(1−�)�q
可以看到key对应的�� Momentum Encoder是由query对应的�� Encoder 来更新的,同时受到key对应的Encoder上一次的状态(更新后的Encoder)影响。因此其更新速率,与query对应的encoder相比要慢, 能提供很稳定的 Key ,也就是 Momentum Encoder 把这个Key Space 先摆好。具体要有多慢呢?慢到Queue中最旧key依然能够反映出最新的Momentum encoder信息。所以文章给出m=0.999,要远好于m=0.9。直观的的感受就是,key对应的Momentum encoder基本不动,非常缓慢的更新,Queue中所有的key可以近似的看成由目前的Momentum encoder编码得到。
如果 �+ 与Queue中原本的 Key比较远,如图5所示,再回想一下,MoCo本质上还是在做instance discrimination。 所以,这时的Loss较小,且主要去 Update �� Encoder,使得q更接近�+ ,而Momentum Encoder更新又很缓慢,它更新后, �+ 依然会与Queue中原本的 Key相距较远。如果 �+ 与Queue中原本的 Key容易混淆,这时候的 Loss 较大, �� Encoder的更新使得q远离Queue中原本的Key,同时尽可能地距离�+较近,随后Momentum Encoder缓慢更新,倾向于使得�+ 远离Queue中原本的 Key,相当于找一个比较空的区域放 �+ , 而不影响原本的Queue中原本的 Key。但此处只是直观上的分析,缺乏严谨的理论证明。
近期,何凯明团队推出了MoCo_V2,效果相对于V1有了较大提升,但没有改变MoCo_V1的框架。
reference:
MrChenFeng:详解对比损失(contrastive loss)与交叉熵损失(cross-entropy)的关系
元想:从 Contrastive Loss 学习 Loss function的设计
“噪声对比估计”杂谈:曲径通幽之妙 - 科学空间|Scientific Spaces
