

python多进程1:进程池使用时的死锁问题
一、为什么?
你正在使用多进程来在多个进程中运行一些代码,但它却“卡”住了。
你查看 CPU 使用情况,却发现没有任何进展,无法完成任何工作。
到底发生了什么?
在许多情况下,你只需要加上一行代码就可以解决这个问题(可以跳到最后一句尝试一下),但是首先,让我们深入探讨 Python 的故障以及 POSIX 系统编程的痛苦,并使用令人兴奋但不太令人信服的鲨鱼比喻!
我们来设定一下比喻场景:你正在一个到处都是鲨鱼的池子里游泳。(鲨鱼是进程的比喻)
接着,你拿了一把叉子。(叉子代表 fork())
你用这把叉子刺了自己,刺刺刺。鲜血流淌出来,鲨鱼开始盘旋,很快你发现自己——在水里被死锁了!
在这个时空之旅中,你将会遇到:
Python 的 multiprocessing.Pool 陷入死锁的神秘失败。 问题的根源:fork()。 一个难题:fork() 复制的所有内容都是问题,但不复制所有东西也是问题。 一些止血口罩无法解决的问题。 可以保持你的代码不被鲨鱼吞噬的解决方案。 让我们开始吧!
二、介绍multiprocessing.Pool
Python提供了一个方便的模块,允许你在进程池中运行任务,这是提高程序并行性的一种很好的方法。(请注意,这些示例都没有在Windows上测试;我在这里着重关注*nix平台。)
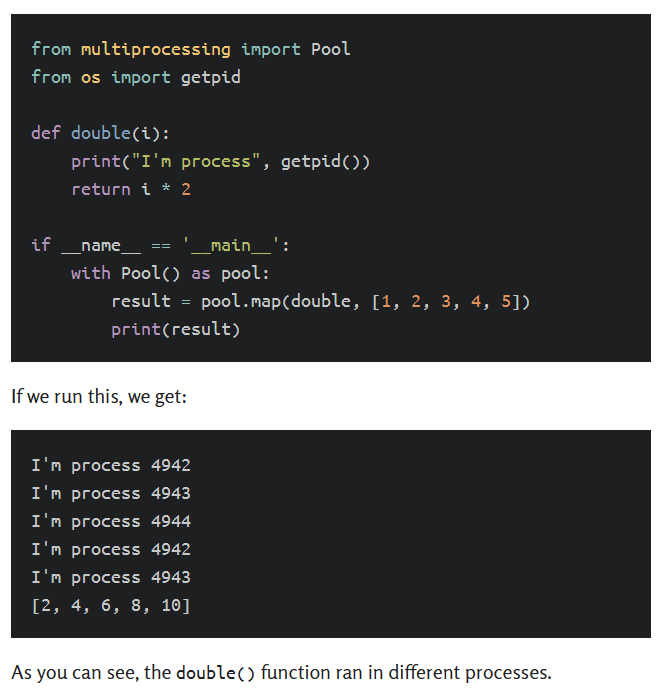
三、一些代码应该执行,却没有
不幸的是,虽然Pool类很有用,但它也充满了狡猾的陷阱,它们就在等待着你犯错。例如,以下代码看似完全合理:
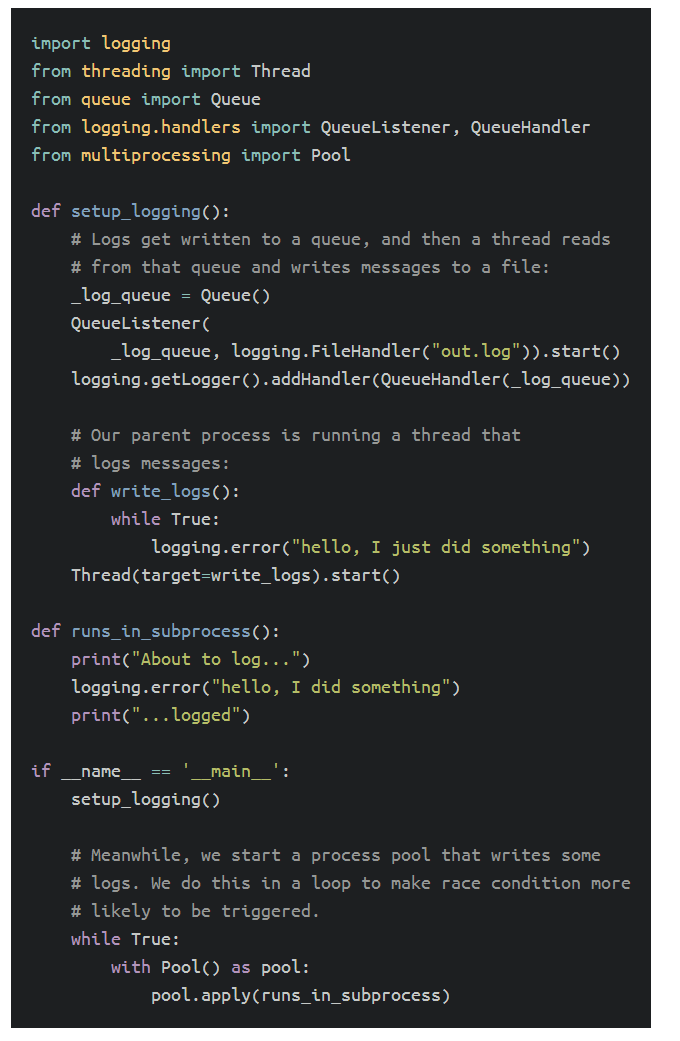
程序的功能如下:
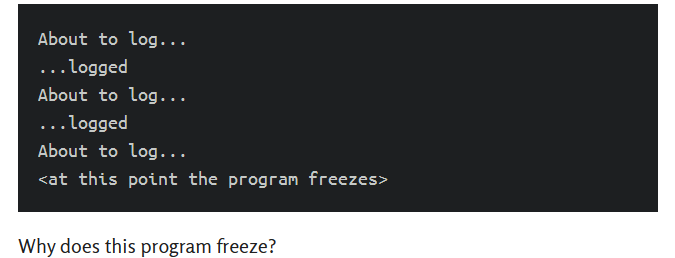
在父进程中,将日志消息路由到队列中,一个线程从队列中读取并将这些消息写入日志文件中。 另一线程连续写入日志消息。 最后,我们启动一个进程池,并在其中一个子进程中记录一条消息。 如果我们在Linux上运行这个程序,我们会得到以下输出:
四、只使用fork()的问题
所以好吧,Python仅通过fork()来启动进程池。这似乎很方便:子进程可以访问父进程内存中的所有内容的一个副本(尽管子进程无法再更改父进程中的任何内容)。但它究竟如何引起我们看到的死锁呢?
原因是在fork()后不带execve()继续运行代码的两个问题:
fork()会在内存中复制所有内容。 但它并没有复制所有内容。
fork()会在内存中复制所有内容 当你执行fork()时,它会在内存中复制所有内容,包括你在导入的Python模块中设置的任何全局变量。
例如,你的日志配置:
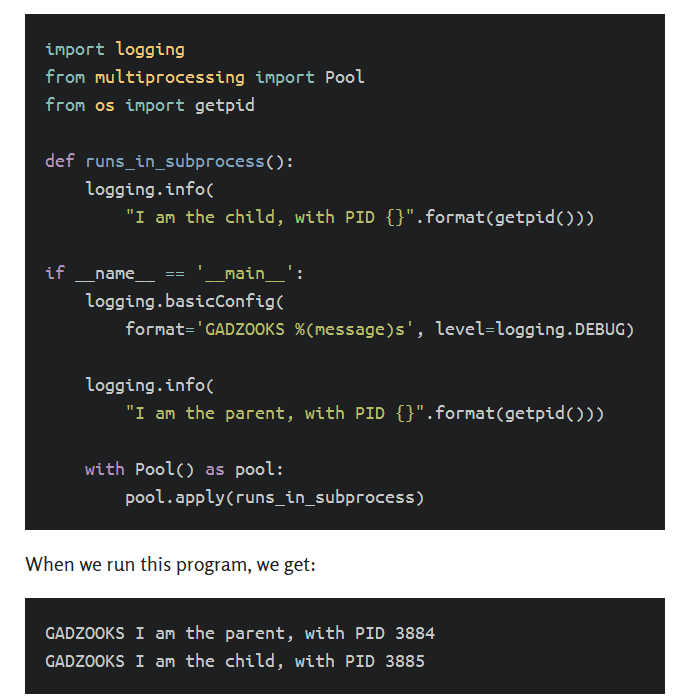
请注意,进程池中的子进程会继承父进程的日志配置,即使这不是你的意图!更广泛地说,你在父级中在模块级别上配置的所有内容都会被进程池中的进程继承,这可能会导致一些意外的行为。
但是fork()并没有复制所有内容 第二个问题是fork()实际上并没有复制所有内容。特别是,fork()没有复制线程。在父进程中运行的任何线程在子进程中都不存在。
启动线程:

当我们运行此程序时,我们可以看到我们启动的线程没有在fork()后继续存在:
父进程有2个线程 子进程有1个线程
谜团得到解决
以下是为什么那个原始程序死锁的原因:fork()这种方法把问题变得更复杂:
1、每当父进程的线程写入日志消息时,它会将其添加到一个队列中。这涉及到获取锁。
2、如果fork()发生在错误的时间,那么锁定会在获取的状态下被复制。
3、子进程会复制父进程的日志配置,包括队列。
4、每当子进程写入日志消息时,它尝试将其写入队列。
5、这意味着获取锁,但锁已经被获取。
6、子进程现在等待锁被释放。 锁永远不会被释放,因为会释放它的线程没有被fork()复制。 简化形式:

临时解决办法 有一些解决方法可以稍微改善这个问题。
对于模块状态,logging库可以在multiprocessing.Pool启动子进程时重置其配置。但是,这无法解决所有其他Python模块和库的问题,它们都会设置某种模块级全局状态。每个具有此问题的库都需要解决,以便与multiprocessing一起使用。
对于线程,可以在调用fork()时将锁设置回释放状态(Python已经为此提供了一个工单)。不幸的是,这不能解决由C库创建的锁的问题,它只能处理Python直接创建的锁。并且这也不能解决这些锁在子进程中是否仍然有意义的事实,无论它们是否已被释放。
幸运的是,有更好、更简单的解决方案。
真正的解决方案:停止使用普通的fork() 在Python 3中,multiprocessing库新增了启动子进程的新方法。其中一种方法是在fork()后跟随一种完全新的Python进程的execve()。这解决了我们的问题,因为模块状态不会被子进程继承:它从头开始。
启用这种替代配置只需要在程序中的任何其他import或使用multiprocessing之前更改程序中的两行代码;基本上,你的应用程序应该是:
from multiprocessing import set_start_method set_start_method("spawn") 这会全局更改你程序中的所有代码,因此如果你维护一个库,礼貌的做法是仅为自己的进程池使用“spawn”方法,如下所示:
from multiprocessing import get_context
def your_func(): with get_context("spawn").Pool() as pool: # ... everything else is unchanged 就是这样:这样做,我们所面对的所有问题就不会影响你了。(详情请参阅上下文文档。)
但这仍然需要你付出努力。它需要每个Python用户信任地按照文档中的示例,并迷惑不解地发现他们的程序有时会崩溃。
最终,这将得到修复:
从Python 3.12开始,你将收到一个DeprecationWarning,指出“fork”将在3.14中停止成为默认选项。 在Python 3.14中,默认选项将更改为“spawn”或“forkserver”(一个比“fork”更安全的替代方法)。 在那之前,你得自己解决它。
注意:如果你依赖“fork”来便宜地从父进程传递数据到子进程,请考虑使用这些替代方法来加速数据在进程之间的复制。

转载:Why your multiprocessing Pool is stuck (it’s full of sharks!) (pythonspeed.com)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
2021-04-22 tensorflow(三十):keras自定义网络实战
2021-04-22 tensorflow(二十九):模型的保存
2021-04-22 tensorflow(二十八):Keras自定义层,继承layer,model
2021-04-22 tensorflow(二十七):Keras一句话训练fit
2021-04-22 tensorflow(二十六):Keras计算准确率和损失
2021-04-22 tensorflow(二十五):Tensorboard可视化
2021-04-22 python(三):collection模块