

NAS-bench-101
0. 摘要
神经网络搜索近年来取得进步巨大,但是由于其需要巨大的计算资源,导致很难去复现实验。本文目标是通过引入NAS-Bench-101的方法来缓解以上问题。在NAS-Bench-101中,设计了一个紧凑且丰富的搜索空间。通过图同构的方式来区别423k个网络架构。
在CIFAR10数据集上多次训练以上所有网络,并得到验证集上的结果。这使得研究人员可以通过查询预先计算的数据集,以毫秒为单位评估各种模型的质量。通过分析数据集作为一个整体,并通过对一系列架构优化算法进行基准测试来证明它的实用性。
1. 介绍
简单来说,NAS-Bench-101就是谷歌设计了一个搜索空间,在搜索空间中穷尽枚举了大约5百万个子网络。在CIFAR10数据集上进行训练,在验证集上测试。将子网的结构以及对应的验证集精度记录下来,形成一个表,研究人员使用的时候只需要通过查表就可以得到对应的验证集精度,这样就不需要重新训练和测试,降低了对计算资源的依赖。
为了摸清这篇工作内容,我们需要搞清楚几个关键点:
- 搜索空间,如何设计搜索空间的?
- 训练策略,采用了什么训练策略?
- 使用方法,研究人员如何使用NAS-bench-101?
- 潜在方向,使用nas-bench-101有哪些潜在的研究方向?
2. 搜索空间
NasBench101中设计的搜索空间是基于cell的搜索空间,如图所示,网络的初始层(conv stem)是由3x3卷积和128的输出通道组成的主干,每个单元堆叠三次,然后进行下采样,使用最大池化将通道数和空间分辨率减半,最后使用一个global average pooling和一个softmax层得到分类的概率。

每个cell内部有V个节点,每个节点包括L个标签,分别代表相应的操作。其中in和out代表输入的tensor和输出的tensor。该有向无环图的搜索空间与V和L呈指数关系增长,为了控制搜索空间的大小,提出了以下几个约束:
- L=3,包括3x3卷积、1x1卷积、3x3 maxpool
- 边的最大个数设置为9
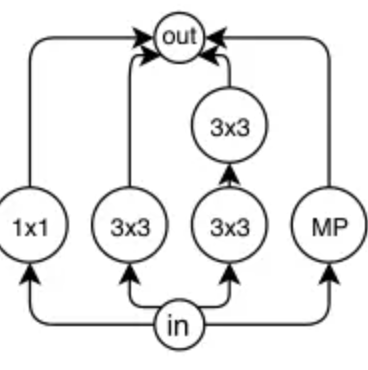
单元编码方法:Nas-Bench-101中使用了一个通用的编码方式,有7个顶点的有向无环图,使用7x7的上三角二进制矩阵和一个包含5个标签的列表(分别代表5个中间节点的op)
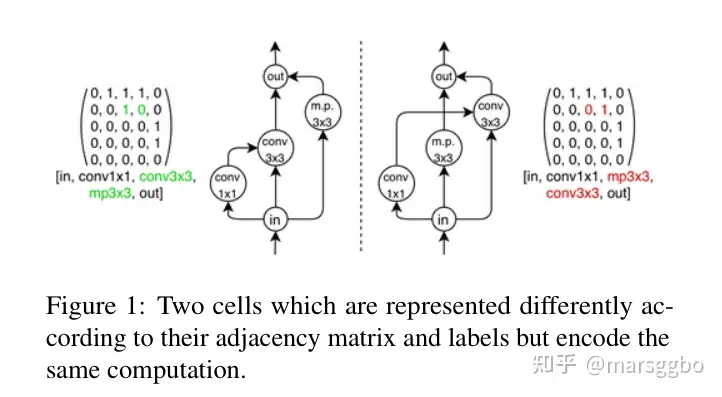
区分同构的cell 在以上搜索空间中,存在不同的邻接矩阵或者不同标签,但计算等价的模型,这就称为同构的cell

从上图得知,两个cell虽然编码不相同,但实际的计算过程是相同的。所以采用迭代图哈希算法来快速确定两个cell是否是同构的。
经过去掉不符合要求和同构的网络以后,剩下了大概423k个子网络。
此外,还有一个小问题:通道个数的匹配和特征融合方法的选择。Nas-Bench-101进行了认为固定设置,如下图所示:
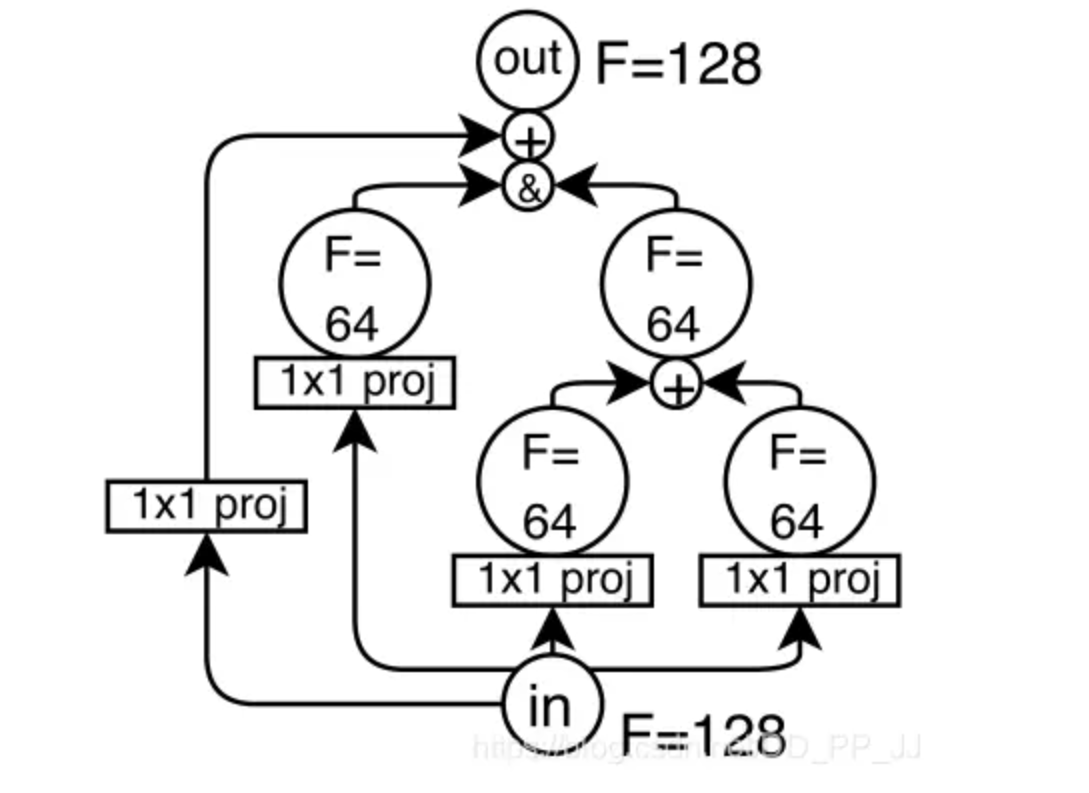
上图中&代表concate操作,+代表addition操作,proj代表1x1卷积。所以具体策略是:将所有指向输出节点的张量concate到一起,将指向其他顶点(非输出节点)的张量add到一起。来自输入顶点的输出张量使用1x1卷积映射,以匹配通道个数的一致性。
3. 训练策略
由于训练策略的不同对最终的实验结果造成的影响非常大,所以要对训练策略、实现细节、超参数选取进行确认。
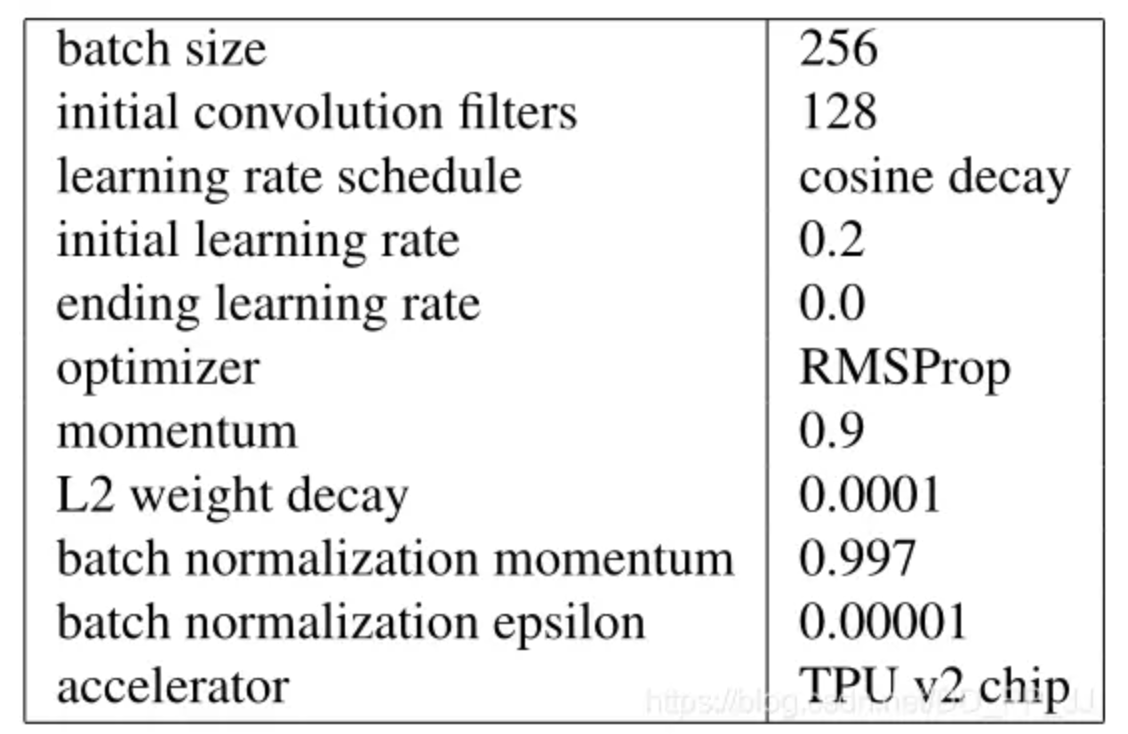
参数选择:对所有的Nas-bench-101模型选取一组固定的参数,而并不是对每个模型自己设置各自的超参数。而固定的超参数的选择是通过网格搜索50个随机抽样得到的子网络平均精度得到的。
实现细节: 使用和resnet一致的数据增强技术,learning rate使用cosine decay, 使用RMSporp作为优化器。
4. 使用方法
4.1 评价指标
nas-bench-101中使用到了以下几种指标:
- 训练精度
- 验证精度
- 测试精度
- 训练时间
- 训练模型参数
4.2 安装环境
从github上clone该项目
git clone https://github.com/google-research/nasbench
进入该项目文件夹
cd nasbench
安装(若当前环境中无tensorflow cpu版本,该步会安装Tensorflow)
pip install -e .
下载数据集:
- 4个epochs训练的结果 (1.95 GB)https://storage.googleapis.com/nasbench/nasbench_full.tfrecord
- 108个epochs训练结果子集(499MB)https://storage.googleapis.com/nasbench/nasbench_only108.tfrecord
4.3 使用教程
官方提供的demo如下所示:
from absl import app
from nasbench import api
# Load the data from file (this will take some time)
nasbench = api.NASBench('/home/pdluser/download/nasbench_only108.tfrecord')
INPUT = 'input'
OUTPUT = 'output'
CONV1X1 = 'conv1x1-bn-relu'
CONV3X3 = 'conv3x3-bn-relu'
MAXPOOL3X3 = 'maxpool3x3'
# Create an Inception-like module (5x5 convolution replaced with two 3x3
# convolutions).
model_spec = api.ModelSpec(
# Adjacency matrix of the module
matrix=[[0, 1, 1, 1, 0, 1, 0], # input layer
[0, 0, 0, 0, 0, 0, 1], # 1x1 conv
[0, 0, 0, 0, 0, 0, 1], # 3x3 conv
[0, 0, 0, 0, 1, 0, 0], # 5x5 conv (replaced by two 3x3's)
[0, 0, 0, 0, 0, 0, 1], # 5x5 conv (replaced by two 3x3's)
[0, 0, 0, 0, 0, 0, 1], # 3x3 max-pool
[0, 0, 0, 0, 0, 0, 0]], # output layer
# Operations at the vertices of the module, matches order of matrix
ops=[INPUT, CONV1X1, CONV3X3, CONV3X3, CONV3X3, MAXPOOL3X3, OUTPUT])
# Query this model from dataset, returns a dictionary containing the metrics
# associated with this model.
data = nasbench.query(model_spec) # 根据配置查询结果
result = nasbench.get_budget_counters() # 返回训练时间,epochs
print("data:", data)
print("result:", result)
fixed_metrics, computed_metrics = nasbench.get_metrics_from_spec(model_spec)
# 每个epoch结果
for epochs in nasbench.valid_epochs:
for repeat_index in range(len(computed_metrics[epochs])):
data_point = computed_metrics[epochs][repeat_index] # 重复次数 每个epoch重复的结果
输出结果:

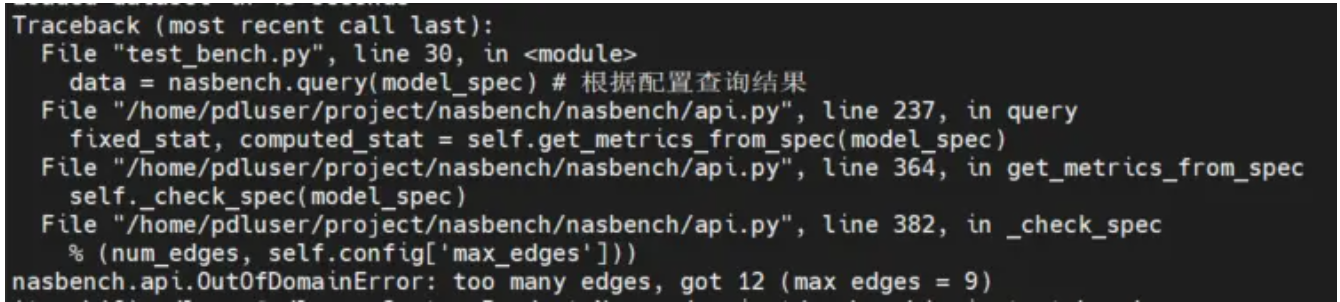
如果设置边数太多会报错:
5. 实验内容
这篇论文中对nas-bench-101数据集的几个指标进行了统计,并深入探索了NAS的特性。
5.1 统计量
- 经验累积分布empirical cumulative distribution ECDF
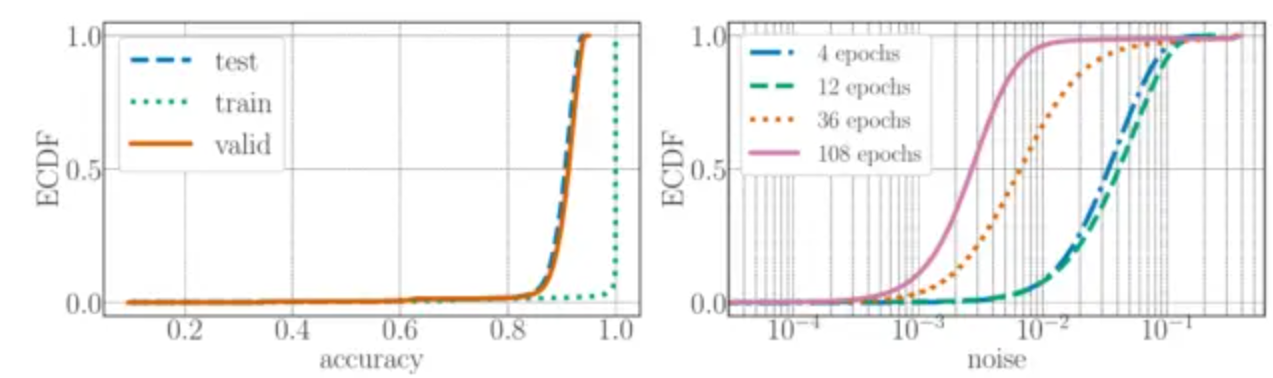
可以从准确率累积经验分布看出,accuracy在0.8-1.0之间分布居多,并且训练集结果逼近1;还可以从该图中观察到一个现象,即验证集和测试集的相关性比较高r=0.999, 这表明模型的训练并没有过拟合。
noise代表的是经过多次训练之间的准确率差异 ,可以发现108个epoch训练的noise最小。
- 训练时间、可训练参数与训练精度之间的关系

左图展示了横轴训练参数、纵轴训练时间和训练精度之间的关系,可以发现以下几个规律:
- 模型容量比较小,参数量小,训练时间过长反而在验证集准确率不好。
- 模型容量比较大,参数量大,训练时间大体上是越长效果越好。
- 在训练时间相同的情况下,模型参数量越大,验证机准确率越高。
右图展示了训练时间和训练精度的帕累托曲线,实验发现resnet、inception这类人工设计的模型非常靠近帕累托前沿。这表明网络拓扑和具体操作的选择非常重要。
5.2 架构设计
为了探寻选取不同操作的影响,进行了替换实验,将原先的op替换为新op以后查看其对准确率的影响。
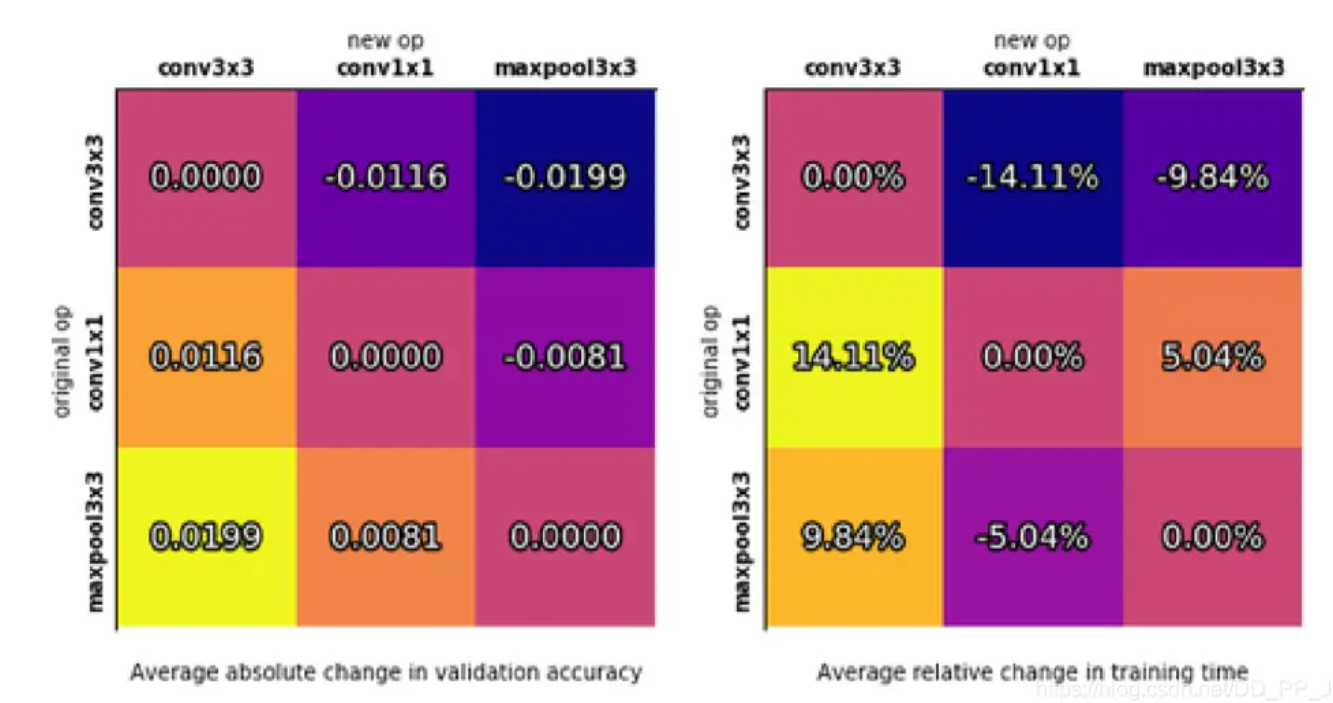
从上图中可以得到以下发现:
-
将卷积替换为池化带来的负面影响比较大。
-
将池化替换为卷积带来的正面影响比较大。
-
将3x3卷积替换为1x1卷积或池化可以有效降低训练时间。
5.3 局部性
NAS中的局部性是:相似的网络架构的准确率也是相似的。很多NAS算法都在利用NAS的局部性原理来进行搜索。局部性衡量的指标是RWA(random-walk autocorrelation) 即随机游走自相关。RWA定义为当我们在空间中进行长距离随机变化时所访问的点的精度的自相关
RWA在比较近的距离上有较高的相关性,反映了局部性。从下图中发现,当距离超过6以后,就无法判断是否是相关性还是噪声,所以搜索的过程最好约束在6以内。

6. 总结
nas-bench-101是一个表格型的数据集,在设计的搜索空间中找到网络的架构,并通过实际运行得到每个epoch的验证集结果。使用过程比较方便,根据规定配置从nas-bench-101中找到对应的网络架构以及相应的准确率、参数量等信息。
7. 参考文献
1. 模型整体结构
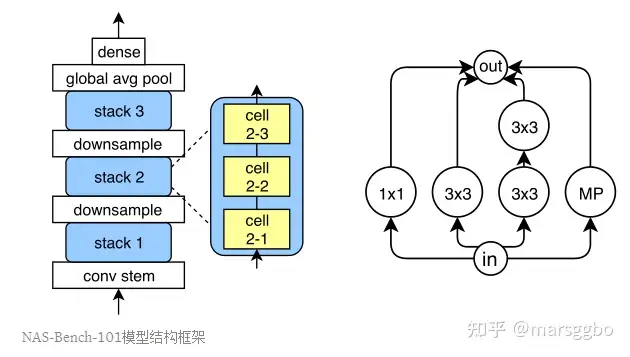
NAS-Bench-101模型结构框架
上图(左)展示了模型的整体结构,由stem,stack,downsample,global avg pool和最后的全连接层dense组成,每个stack由3个cell组成,右图给出了某个cell的示意图,下面详细介绍cell的结构。
2. Cell结构
2.1 限制条件
Cell结构遵循以下设计要求
- cell由7个节点组成,其中第一个和最后一个是固定的,分别是
in和out。 - cell的最大边数不能超过9
- 每个节点对应一个操作,候选操作只有三个(卷积操作后面都会加上
BN+ReLU):
- 3x3 conv
- 1x1 conv
- 3x3 max-pool
2.2 Cell编码方式
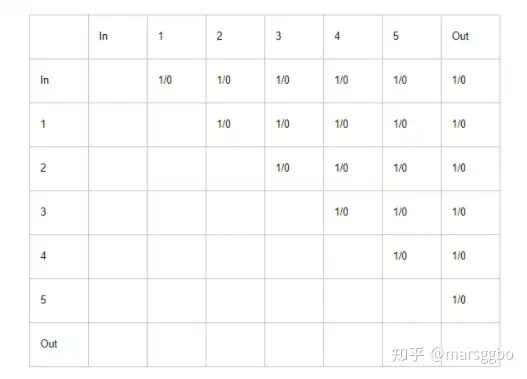
Cell的编码方式用如下表示的上三角矩阵表示,复杂度如下:
- edges:
1/0表示对应节点之间是否相连,所以有 221种连接方式 - ops: 除去
in & out两个节点,每个节点都有3个候选操作,所以总共有 35中组合
所以总共搜索空间有 221×35≈510� 中可能的cell结构。不过因为规定了edge总数不能大于9,另外减去重复的,最后总共有将近 423K 个不同的结构图。
下图给出了两个例子用来帮助理解这个编码方式,以左边的cell为例,可以看到矩阵定义了节点之间的联系方式,矩阵下的list [in,con1x1,conv3x3,mp3x3,out]定义了5个节点各自的操作。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧