

分布式基础设施上的可扩展深度学习:挑战、技术和工具
分布式基础设施上的可扩展深度学习:挑战、技术和工具
摘要
深度学习 (DL) 在最近取得了巨大成功,在图像识别和自然语言处理等各个领域取得了最先进的成果。这一成功的原因之一是 DL 模型的规模不断扩大以及可用的大量训练数据的激增。为了不断提高深度学习的性能,增加深度学习系统的可扩展性是必要的。在本次调查中,我们对分布式基础设施上可扩展深度学习的挑战、技术和工具进行了广泛而彻底的调查。这包含了 DL 的基础设施、并行 DL 训练的方法、多租户资源调度以及训练和模型数据的管理。此外,我们分析和比较了 11 个当前的开源 DL 框架和工具,并研究了哪些技术在实践中通常被实施。最后,我们强调了值得进一步研究的 DL 系统的未来研究趋势。
1、介绍
深度学习 (DL) 最近因其在语音识别 [65, 69]、光学字符识别 [20] 和目标检测 [95] 等任务中的卓越性能而受到了广泛关注。 DL 的应用在医学图像分析(例如,乳腺癌转移检测)[107]、机器翻译 [84]、图像恢复(例如,灰度图像自动着色)[75]、图像字幕[75]等众多领域中具有巨大的潜力。 68](即,创建图像的描述),并作为强化学习系统中的代理,将状态-动作对映射到预期奖励 [10]。在 DL 中,使用分类或未分类的数据集训练数学运算符网络,直到模型的权重准备好对以前看不见的数据做出正确的预测。主要公司和开源计划已经开发出强大的深度学习框架,例如 TensorFlow [4] 和 MXNet [125],它们可以自动管理由领域专家开发的大型深度学习模型的执行。
DL 成功的驱动因素之一是三个维度的训练规模。规模的第一个维度是模型本身的大小和复杂性。从简单的浅层神经网络开始,随着深度的增加和更复杂的模型架构,实现了模型准确性的新突破 [30, 38]。规模的第二个维度是训练数据量。通过将更多的训练数据输入模型 [56, 63],可以在很大程度上提高模型的准确性。在实践中,据报道在 DL 模型的训练中使用了 10 到 100 TB 的训练数据 [27, 62]。第三个维度是基础设施的规模。可编程高度并行硬件的可用性,尤其是图形处理单元 (GPU),是在短时间内用大量训练数据训练大型模型的关键因素 [30, 206]。
我们的调查主要集中在管理大型分布式DL基础设施时出现的挑战。托管大量的DL模型,用大量的训练数据进行训练是具有挑战性的。这包括并行化、资源调度和弹性、数据管理和可移植性等问题。这个领域现在正处于快速发展中,有来自不同研究团体的贡献,如分布式和网络化系统、数据管理和机器学习。同时,我们看到一些开源的DL框架和协调系统的出现[4, 24, 141, 195]。在这份调查报告中,我们汇集、分类和比较了来自该领域不同社区的关于DL分布式基础设施的大量工作。此外,我们还对现有的开源DL框架和工具进行了概述和比较,将分布式DL付诸实践。最后,我们强调并讨论了该领域的公开研究挑战。
1.1 补充性调查
有一些关于DL的调查是对我们的补充。Deng[41]提供了一个关于DL架构、算法和应用的一般调查。LeCunn等人提供了DL的一般概述[95]。Schmidhuber[156]对DL的历史和技术进行了全面调查。Pouyanfar等人[143]回顾了DL的当前应用。Luo[109]对ML训练中的超参数选择策略进行了回顾,包括神经网络的训练。这些调查涵盖了DL的一般技术,但没有关注DL的可扩展性和分布式系统。
Ben-Nun和Hoefler[14]提供了对并行和分布式DL训练中并发性的分析。Chen和Lin[25]对大数据(即高数据量、多样性和高速度)方面的DL挑战和观点进行了调查。Erickson等人[45]提供了DL框架的简短概述。我们的调查对分布式DL系统采取了更广泛的观点。特别是,我们包括诸如资源调度、多租户和数据管理等主题。当在共享集群或云环境中处理大型模型和海量训练数据时,可扩展DL系统的这些方面变得尤为重要。此外,我们深入分析了当前的开源DL框架和工具,并将它们与并行和分布式DL训练的研究联系起来。这在现有的调查中还没有做到。Pouyanfar等人[143]分析和比较了DL框架,但没有涉及并行化和分布式的问题。
1.2 调查的结构
我们的调查结构如下。在第2节中,我们介绍了DL,并为DL系统的进一步讨论提供了基础。在第3节中,我们详细讨论了可扩展DL的挑战和技术。我们涵盖了四个重要方面。分布式基础设施、DL训练的并行化、资源调度和数据管理。在第4节中,我们分析和比较了11个开源的DL框架和工具,将可扩展DL付诸实践。最后,在第5节。最后,我们对本次调查进行了总结,并对该领域当前的趋势和值得进一步研究的开放问题进行了展望
2、基础
2.1 . 深度学习的背景
人工智能(AI)是一个长期持有的愿景,即建立和编程计算机,使其能够独立(即没有人类参与)解决复杂问题[131, 157]。在最近的过去,人工智能在许多不同的领域取得了巨大的实际成就,如知识表示和自动推理[165]、规划[87]、自然语言处理[198]、计算机视觉[169]和机器人[99]。在人工智能研究中开发的方法包括控制论、符号和次符号以及统计机器学习(ML)。深度学习(DL)是ML的一种特殊方法,它涉及到深度神经网络的训练。图1直观地显示了人工智能、ML和DL之间的关系。
2.2 深度神经网络
神经网络(NN)是一个由相互连接的人工神经元组成的网络,它是将一组输入信号转换为输出信号的数学函数。通过将神经元分层并从输入层连接到输出层,整个网络代表一个函数f : x → y,将进入输入层(第1层)的输入信号映射到离开输出层(第n层)的输出信号。f的目标是接近目标函数f∗,例如,一个分类器y = f∗(x),它将输入x映射到一个类别y。在训练过程中,所有人工神经元的参数集Θ,即权重、偏置和阈值,都以这样一种方式调整,即f的输出以最佳精度接近f∗的输出。这通常是通过对损失函数的梯度进行反向传播[152]而实现的。相应层的权重。在DL中应用了不同的梯度下降算法;Ruder[151]对梯度下降算法做了详细的回顾。在训练过程中,每一次迭代都会使用小批量的训练数据,而不是单一的训练样本。这样做的好处是增加了训练过程中的并行性。网络的输出可以对整批训练样本进行并行计算。然而,选择过大的迷你批次尺寸可能会降低模型的准确性,并增加训练过程的内存占用[112]。训练过程本身的参数,即损失函数、梯度下降算法、激活函数、步长(权重向梯度变化的系数)和迷你批次的大小被称为超参数。
2.3 神经网络结构
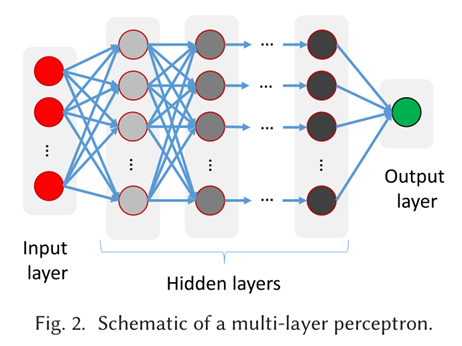
组织DNN的最简单方法是使用多个完全连接的神经元层,即一个层中的每个神经元都与后续层的每个神经元相连。这种结构也被称为多层感知器(MLP)(参见图2)。然而,MLPs有局限性[53, 96]。首先,MLPs有大量的权重,这需要大量的训练样本并占用大量的内存。其次,MLP对输入的几何平移和局部失真并不稳健。例如,在检测图像中的手写数字时,同一个数字在不同的图像中的书写会略有不同[96]。第三,MLP对输入的拓扑结构是不可知的,也就是说,输入信号的顺序不被考虑。然而,在许多情况下,输入数据中存在着局部结构。例如,在图像中,邻近的像素很可能是相关的[96],在语音识别中,输入数据的先前和未来的背景对检测一个口语单词特别相关[53]。为了克服MLPs的缺点,人们提出了更复杂的神经网络结构。在此,我们简要回顾一下最突出的那些。
卷积神经网络(CNNs)[96]引入了卷积层和子采样层。与MLPs中的全连接层不同,卷积层只与各自前一层的子区域相连,追求局部接受区的概念,其灵感来自生物学[72]。卷积层由多个平面组成,在每个平面中,所有神经元共享相同的权重(权重共享)。最后,卷积层与子采样层交替进行,以降低特征图的空间分辨率。除了前馈网络(神经元的输出不会回环到它们自己的输入),回环在许多使用情况下是有用的。例如,在自然语言处理中,一个句子中的一个词的含义可能取决于同一句子(甚至是以前的句子)中先前看到的一个词的含义。为了在DL网络中模拟这种现象,人们提出了循环神经网络(RNNs)。长短期记忆(LSTM)单元是RNN的特殊单元,以克服训练RNN时的梯度爆炸或消失的问题[67]。自动编码器[66]是用于学习高效编码(即压缩表征)的NN,从训练数据中提取重要特征。它们的结构包括一个编码器、一个编码和一个解码器,每个都由神经元层组成,其中网络的输出层具有与输入层相同数量的神经元,但恰好位于编码层和解码层之间的编码,其神经元数量要少得多。在生成式对抗网络(GANs)[51]中,两个NN相互对接,即一个生成式NN和一个鉴别式NN。另一个最近的NN架构是图神经网络[192],其中学习图结构的表示,而不是欧几里得空间的表示(如CNN)。
3分布式深度学习
用大量的训练数据训练大型DL模型是一项非同寻常的任务。通常,它是在一个由多个计算节点组成的分布式基础设施中进行的,每个节点可能配备了多个GPU。这带来了一系列的挑战。首先,处理资源必须得到有效利用,即必须避免因通信瓶颈而导致昂贵的GPU资源停滞。其次,计算、存储和网络资源通常在不同的用户或训练过程中共享,以降低成本并提供弹性(即云计算范式[9])。为了应对DL的这些挑战,计算系统和DL的交叉研究正受到越来越多的关注[4, 27, 36, 79, 141, 195]。这一点随着特别关注DL/ML系统研究的新研讨会和会议的出现而变得很明显,比如系统和机器学习会议(SysML)。然而,已有的社区,如数据管理社区,也在将他们的注意力转向DL/ML系统[93, 185]。在本节中,我们将深入讨论DL系统研究的主要方向。我们介绍了主要的研究挑战,讨论了最先进的方法,并分析了值得进一步关注的开放式研究问题。
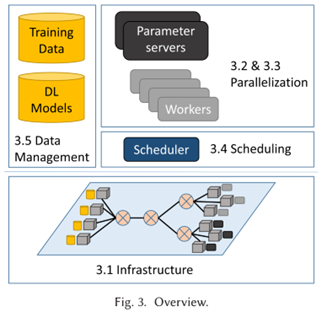
本节概述。图3提供了本节中所涉及的主题的概述。在最底层,我们在第3.1节中讨论了大型DL系统中使用的基础设施。我们将讨论所使用的硬件的最新趋势、网络架构以及DL系统的低级软件架构。在更高的层次上,我们在第3.2节中讨论了平行DL训练的方法。在第3.3节,我们更具体地讨论数据并行训练的挑战和方法。为了将并行DL系统的组件映射到基础设施上,我们采用了调度的方法。在第3.4节中,我们讨论了单租户和多租户情况下的调度问题。大规模DL的一个大挑战是需要维护的训练数据和DL模型的规模。在第3.5节中,我们讨论了DL中的数据管理的挑战和方法.
3.1 结构
为了理解DL的并行化、调度和数据管理方面的挑战,我们首先深入研究了进行DL训练的基础设施。我们把现有的工作分为两类。硬件创新和应用于实际DL工作负载的数据中心规模的基础设施。前者有可能用于单个计算节点或小型集群,而后者则描述了如何将单个硬件组件组成一个可扩展的分布式基础设施用于DL。
3.1.1 DL的硬件组件。虽然早期的DL部署是基于多核CPU的集群,但可扩展性的限制促使人们努力利用高度并行的硬件,甚至开发专门用于DL训练和服务的专用硬件。与CPU相比,GPU的性能优势取决于许多因素,如工作是受处理限制还是受内存限制,实现的效率,以及硬件本身[97]。CPU和GPU的硬件都在快速创新,这使得比较变得困难和短暂。尽管如此,DL的最先进的基础设施通常包括GPU,以加速训练和推理过程。硬件供应商为DL提供专门的服务器甚至工作站,如NVIDIA DGX站[2]。
除了以GPU为中心的DL,还提出了其他形式的硬件加速,如现场可编程门阵列(FPGAs)[135]。FPGA的一个优势被反复提及,就是它们能够使DL训练和推理更加节能。Farabet等人的NeuFlow[46]是最早解决将FPGA用于DL问题的作品之一,特别是用于视觉系统。Zhang等人设计的Caffeine[201]是一个硬件和软件共同设计的库,用于支持FPGA上的CNNs。在硬件方面,它提供了一个用于CNNs的FPGA加速器的高级合成实现。在他们的设计中,他们建立在以前开发的方法上,如解卷和流水线(参考Zhang等人[202])。在软件方面,Caffeine提供了一个允许轻松集成FPGA的驱动程序。Caffeine已经被集成到Caffe DL框架中,并显示与CPU相比,能耗降低了43.5倍,与GPU执行相比,能耗降低了1.5倍。Wang等人[181]提出了一个定制的FPGA设计,称为DLAU,以支持深度神经网络的训练。他们必须克服的一个主要挑战是FPGA的有限内存容量。他们提出了划分训练数据的瓦片技术,以及FIFO缓冲器和流水线处理单元,以尽量减少内存传输。在他们的评估中,他们表明DLAU可以训练神经网络,其能耗比GPU低10倍。张量处理单元(TPU)是由谷歌开发的特定应用集成电路(ASIC),它可以大大加快DL训练和推理的速度[86]。TPU是专有的,不能在商业上使用,但可以通过谷歌云服务租用。
除了这种遵循冯-诺依曼架构的更传统形式的计算架构,通过分离内存和处理单元,还有一些研究工作是为了开发新的内存内计算架构(也叫神经形态硬件[21])。这些努力受到了大脑生理学的启发,这与传统的冯-诺依曼计算架构的工作方式非常不同。Azarkhish等人的Neurostream[11]是一个为训练CNN而定制的处理器-内存解决方案。然而,神经形态的硬件架构仍然处于实验阶段,并没有广泛使用。
一些论文强调了高效实现DL内核的必要性,例如,通过利用SIMD(单指令,多数据)指令[97,176]和对非均匀内存访问(NUMA)的认识[150]。这就提出了对DNN训练中最相关的操作的可重复使用的、优化的内核实现的需求。主要的GPU专用库之一是cuDNN,这是一个为GPU提供DL原语的库[26]。英伟达集体通信库(NCCL)[1]提供了多GPU和多节点通信基元,并针对PCIe和NVLink高速互连进行了优化。DL框架通常包含这样的底层库,以充分挖掘硬件基础设施的能力。
3.1.2 用于DL的大规模基础设施。一个大规模的DL基础设施是由许多相互连接的硬件组件组成的,它们共同构建了一个仓库规模的计算机[13]。在本小节中,我们回顾了执行非常大的DL工作的组织,如Facebook、谷歌和微软,以及学术研究所描述的当前基础设施。
Facebook在最近的一篇论文[62]中描述了其ML基础设施。他们同时使用CPU和GPU进行训练,并依靠CPU进行推理。为此,他们建立了专门的基于CPU和GPU的计算服务器,以满足他们对训练和推理的特定需求。对于训练来说,GPU是首选,因为它们的性能更好;然而,在他们的数据中心,他们有大量现成的CPU,特别是在非高峰时段,他们也利用这些CPU。对于推理,他们依靠CPU,因为GPU架构是针对吞吐量而不是延迟进行优化的,但延迟是推理中的一个关键因素。有趣的是,对于分布式数据并行训练中训练服务器的相互连接,他们依靠50G以太网,而放弃使用专门的互连,如RDMA或NCCL[1]。
与Facebook类似,腾讯也采用了带有CPU和GPU的异构基础设施。他们的深度学习系统Mariana[211]由三个不同的框架组成,针对不同的基础设施和使用情况进行了优化。
Adam是微软的一个用于DL的大规模分布式系统[27]。它依靠大量的商品硬件CPU-服务器来进行DL训练。除了许多系统级的优化,Adam的一个以硬件为中心的特点是,他们以这样的方式划分DL模型,使模型层适合在L3高速缓存中,以提高训练性能。
关于TensorFlow的论文[4],一个由谷歌开发的可扩展的ML框架,提供了一些对谷歌的基础设施的见解。总的来说,当涉及到DL基础设施时,谷歌采用了与Facebook和微软不同的方法。首先,他们采用了TPU,这是定制的ASIC,而不是只使用商业现货(COTS)硬件。其次,他们利用专门的互连并使用多种通信协议,如TCP上的gRPC和聚合以太网上的RDMA(RoCE)。分布式TensorFlow支持通过消息传递接口(MPI)进行通信[180]。
在学术研究中,利用高性能计算(HPC)基础设施进行DL训练是一个越来越重要的话题。Coates等人[32]报告了使用一个由16台服务器组成的集群,每台服务器配备两个四核CPU和4个GPU,通过Infiniband互联。与以太网不同,Infiniband有很高的吞吐量,更重要的是,端到端延迟极低(在微秒级)。Ben-Nun和Hoefler[14]也观察到在DL研究中走向HPC基础设施的趋势。
总而言之,现实世界部署的大规模基础设施是高度异质的。
它们不仅包括GPU服务器,而且通常还包括CPU。总体而言,我们看到COTS硬件占据了一定的优势,正如其他大数据分析工作负载的情况一样,例如批处理[39]和图处理[111]。但是,定制硬件和HPC基础设施也在使用,特别是在谷歌和学术研究中。在HPC基础设施中,我们观察到DL系统是专门针对目标基础设施的,以提高性能,例如,关于RDMA、NCCL和MPI等通信协议。
分布式基础设施的性能可以用吞吐量、延迟和能源消耗来衡量。除了硬件的原始最大性能,另一个重要因素是通信协议,例如是否使用RDMA。进一步的重要问题是硬件组件如何组成以避免瓶颈。Li等人[100]对最近的GPU互连进行了全面的性能评估。在能源消耗方面,Wang等人[181]提供了比较FPGA和GPU的评估结果。
3.2 并行化方法
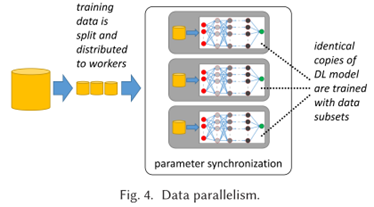
DL具有许多并行化的可能性。在此,我们介绍DL中三种主要的并行化方法,即数据、模型和管道并行化,以及混合形式的并行化。
3.2.1 数据并行化。在数据并行中,一些工作者(机器或设备,如GPU)加载一个相同的DL模型副本(见图4)。训练数据被分割成不重叠的小块,并被送入工人的模型副本中进行训练。每个工作者在其训练数据块上执行训练,这导致了模型参数的更新。因此,工作者之间的模型参数需要同步。在参数同步的问题上有许多挑战。我们将在第3.3节讨论这些挑战和解决这些问题的最新方法。
数据并行的主要优点是,它适用于任何DL模型架构,而不需要进一步了解模型的领域知识。对于计算密集型但只有少数参数的操作,如CNN,它具有良好的扩展性。然而,对于有许多参数的操作,数据并行是有限的,因为参数同步成为瓶颈[82, 91]。这个问题可以通过使用更大的批处理量来缓解;然而,这增加了工作者的数据滞后性,导致模型收敛性差。数据并行的另一个限制是,当模型尺寸过大,无法在单个设备上安装时,它就没有帮助。值得注意的是,在许多数据并行训练方案中,假定或要求训练数据是独立和相同分布的(i.i.d.),因此,由并行工作器计算的参数更新可以简单地加起来计算新的全局模型参数[196]。
3.2.2 模型并行化。在模型并行中,DL模型被分割开来,每个工作者加载DL模型的不同部分进行训练(见图5)。持有DL模型输入层的工作者被输入训练数据。在前向传递中,他们计算自己的输出信号,并将其传播给持有DL模型下一层的工作者。在反向传播过程中,梯度的计算从持有DL模型输出层的工作器开始,传播到持有DL模型输入层的工作器。
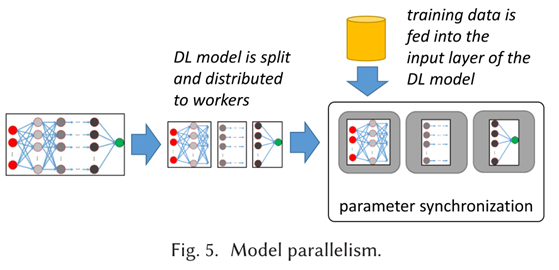
模型并行化的一个主要挑战是如何将模型分割成分配给并行工作者的分区[113]。找到一个好的模型分割的常用方法是使用强化学习[117, 118]。从某个初始分区开始,对该分区进行排列组合,并对性能进行测量(例如,对一个训练迭代)。在有改进的情况下,保持该分区,并进一步进行分区,直到测量的性能收敛。流式展开[47]是一个专门的解决方案,只适用于RNNs。
模型并行化的主要优点是减少了内存占用。由于模型被分割,每个工作者所需的内存就会减少。当完整的模型太大,无法在单个设备上安装时,这很有用。当设备由GPU或TPU等专用硬件组成时,就会出现这种情况。模型并行化的缺点是在工作者之间需要大量的通信。由于DL模型很难被有效地拆分,由于通信开销和同步延迟,可能会出现工作者的停滞。因此,增加模型的并行程度并不一定会导致训练速度的提高[118]。
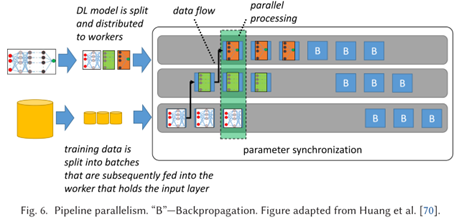
3.2.3 管线并行制。管线并行结合了模型并行和数据并行。在管道并行中,模型被拆分,每个工作者加载DL模型的不同部分进行训练(见图6)。此外,训练数据被分割成微批。现在,每个工作者计算一组微批的输出信号,并立即将它们传播给后续的工作者。以同样的方式,在反向传播通道中,工作者为他们的模型分区计算多个微批的梯度,并立即将它们传播给前面的工作者。通过将多个微批平行地流经正向和反向传播通道,与纯粹的模型并行相比,工作者的利用率可以显著提高,因为在这种情况下,一次只处理一个批处理。同时,模型并行的优势得以保持,因为单个工作者不需要持有完整的模型。目前支持流水线并行的方法有GPipe[70]和PipeDream[57, 58]。
3.2.4 混合并行。通常,DL模型是复杂的,由许多不同的层组成,遵循完全不同的架构,这反过来需要不同的并行化方法。因此,混合数据、模型和管道并行的混合方法很常见。
Mesh-TensorFlow[161]是TensorFlow的一个语言扩展,允许结合数据并行和模型并行。在Mesh-TensorFlow中,张量可以在处理器(如CPU、GPU或TPU)的 "网状 "上分割。为了实现数据并行,数据被分割成碎片;为了实现模型并行,张量被沿其任何属性分割。
有几篇论文提出了由领域专家手动设计的并行化的优化方案。Krizhevsky[91]提出对卷积层和池化层应用数据并行,因为这些层计算量大,只有很少的参数;对全连接层应用模型并行,因为它们计算量小,但有很多参数。在为谷歌翻译提供动力的谷歌神经机器翻译系统(GNMT)[191]中,他们应用了数据并行,但将其与每个模型副本的手工制作的模型并行相结合。
除了人工设计的混合模型,最近还开发了自动优化方法。Jia等人[81]提出了 "分层 "并行化。对于DNN的每一层,沿着该层的张量维度选择一个最佳的并行化方法。为了做到这一点,他们采用了一个成本模型和一个在缩小的图上的图搜索算法,该图为解决空间的模型。Jia等人[82]的FlexFlow是一个采用执行模拟器的自动并行化优化器。它优化了四个维度的并行性,被称为SOAP空间:样本、操作、属性和参数维度。样本维度指的是训练数据的批次,对应于数据的并行性。操作维度指的是人工神经元,属性维度指的是张量的属性,而参数维度指的是权重和其他模型参数。操作、属性和参数维度共同对应于模型的并行性[81]。
3.3 数据并行化的优化
数据并行DL系统中的参数同步带来了三个主要挑战。第一个挑战是如何同步参数。工作者应该通过集中式架构还是以分散的方式进行同步?第二个挑战是何时进行参数同步。工作者应该在每个批次之后被强制同步,还是允许他们有更多的自由来处理潜在的陈旧参数?第三个挑战是如何尽量减少同步的通信开销。
3.3.1 系统架构。系统结构描述了不同工作者的参数是如何同步的。主要的挑战之一是提供一个可扩展的系统结构,能够处理大量的并行工作器,这些工作器定期更新DL模型,并接收模型的更新视图用于进一步训练。第二个挑战是保持系统易于配置,也就是说,它应该能够产生良好的性能而不需要广泛的参数调整。第三个挑战是以最佳方式利用较低级别的基元,例如NCCL所提供的通信基元.
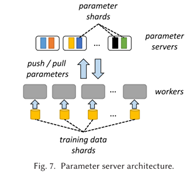
(1) 集中式。在(逻辑上)集中式架构中,工作者定期向一组参数服务器(PS)报告他们计算的参数或参数更新(见图7)。PS架构的根源可以追溯到黑板架构[164]和MapReduce[39],正如Alex Smola的报告[163]。PS架构是数据并行DL系统中最突出的架构。一个常见的方法是使用模型参数的分片,将分片分布在多个PS上,然后可以并行更新[38]。使用参数服务器架构的系统有GeePS[36]、DistBelief[38]、TensorFlow[4]、Project Adam[27]、Poseidon[206]、SINGA[134]、SparkNet[120],以及Yan等人的系统[197]。
(2) 分散式的。分散式结构的工作没有PS。相反,工作者通过Allreduce操作直接交换参数更新(见图8)。在这样做的时候,工作者的拓扑结构起着重要作用。一个完全连接的网络,每个工作者与其他工作者进行通信,在有n个工作者的情况下,通信成本为O(n2),因此,通信成为瓶颈。一个常见的替代方案是采用环形拓扑结构(被称为环形全还原)。Uber公司的Horovod[160]使用NCCL来实现环形全还原。百度是最早提出使用环形全还原进行数据并行DL训练的公司之一[50]。腾讯的Mariana DL系统[211]中的多GPU框架采用了类似的线性拓扑结构,用于工人之间的参数交换。其他已经提出的拓扑结构有 "蝴蝶"[207]、树[6]和基于Halton序列建立的图[101]。Wang等人[183]提出了一个参数共享协议,该协议允许任意的无循环工作器拓扑结构,也可以在系统运行时动态改变。与完全连接的拓扑结构不同,替代拓扑结构的主要缺点是向所有工作者传播参数更新需要更多时间,因为一对工作者之间可能有多个跳数。
工作者的拓扑结构不是减少网络负荷的唯一钮扣。Watcharapichat等人[186]的Ako采用了一个完全连接的工作者网络,但对工作者之间交换的梯度进行了分区(部分梯度交换)。在每一轮同步中,每个工作者只向其他每个工作者发送一个梯度分区;特别是,它可以向不同的工作者发送不同的分区。显然,通信开销既取决于分区的大小(其本身取决于分区的数量),也取决于工作者的数量。分区的数量是自动调整的,以使网络带宽保持恒定,不受工作者数量的影响。
与集中式架构的比较。Li等人[101]认为,与集中式结构相比,分散式结构的优点如下。通过使用分散式架构,人们避免了处理实现和调整参数服务器的不便之处。这不仅是系统代码的复杂性问题,而且也简化了部署。人们不需要计划为参数服务器和工人分配哪些资源。另一个优点是可以更容易实现容错,因为没有像参数服务器那样的单点故障。当分散式结构中的一个节点发生故障时,其他节点可以很容易地接管它的工作负荷,训练就会不间断地进行下去。参数服务器状态的重量级检查点是没有必要的。
分散式架构也有缺点。首先,最重要的是,如果不采取任何对策,分散式架构中的通信会随着工人数量的增加而呈四次方增长。如上所述,这些对策,如改变拓扑结构或分割梯度,会引起新的复杂性和权衡。总的来说,对于平行参数更新的同步化问题,并没有银弹。
L i a n e t a l.[105]的研究表明,在某些条件下,如果通信网络很慢,分散的架构可以比集中的架构表现得更好。
然而,他们的研究仅限于同步参数更新,他们所比较的集中式架构只采用了一个参数服务器。在这种情况下,连接单一中央参数服务器的网络很快就会成为瓶颈。Iandola等人[74]也报告了类似的结果,他们也倾向于采用树状结构的Allreduce架构,而不是单一的参数服务器。
集中式学习和分散式学习都在开源的DL框架中广泛实现。一些框架,如TensorFlow和MXNet,甚至同时支持这两种方式。在TensorFlow中,分散式架构被应用于具有多个GPU的单一计算节点上的训练,因为可以使用高效的allreduce实现,如NCCL allreduce。然而,集中式架构被应用于多节点训练[171]。
(3) 联合。集中式和分散式架构都假设一个受控环境(例如数据中心)、一个平衡且独立同分布的环境。将训练数据分发给工作人员,以及具有同质、高带宽的网络。与此相反,联邦学习 [90] 围绕训练数据本地保存在用户移动设备上的场景演变,并根据用户在本地设备上计算的更新训练全局模型。这样,可能包含隐私敏感信息的训练数据可以完全保存在本地,这也可以降低移动设备和中央数据中心之间的带宽需求。
移动设备互联网连接的低带宽和异步带宽(即上行链路通常比下行链路慢得多)使得它不可能将大型模型的更新参数重复上传到集中的参数服务器或分散的对等节点。Konec˘ný等人[90]研究了不同形式的参数采样和压缩,以缓解这一问题。
McMahan等人[114]对减少参数更新的联合平均算法进行了研究。他们的算法是基于回合的。在每一轮中,都会选择一部分的客户。每个被选中的客户计算它所拥有的所有训练数据的损失函数梯度。为了达到收敛,客户机上的模型实例从相同的随机初始化开始是很重要的。最后,一个中央服务器将来自选定客户的梯度汇总。在Nilsson等人[130]的性能比较研究中,作者表明联合平均法是联合学习的最佳算法,并且在使用i.i.d.训练数据时,实际上等同于集中式架构。然而,在非i.i.d.的情况下,集中式方法的表现比联合平均法更好。
联合学习仍然处于早期阶段,在开源的DL框架中还没有得到广泛的支持。最近,第一批用于联合学习的工具已经问世。TensorFlow Federated[173]是一个用于试验联合ML的模拟器。PySyft[144, 153]是一个Python库,可以在PyTorch中实现保护隐私的联合学习。特别是,PySyft将差分隐私方法[5]应用于联合学习,以防止关于训练数据的敏感信息被从模型中提取。
3.3.2 同步化。何时在并行工作者之间同步参数的问题已经得到了很多关注。参数同步的主要挑战是如何处理当工作者在陈旧的DL模型上进行训练时,训练质量或收敛速度的潜在损失与更新工作者的DL模型的同步成本之间的权衡。总的来说,有三种不同的主要方法。同步、有界异步和异步训练。表1对最相关的出版物进行了概述和分类。
(1) 同步的。在同步训练中,在每个迭代(处理一个批次)之后,工作者会同步他们的参数更新。这样一个严格的模型可以通过众所周知的抽象来实现,如批量同步并行(BSP)模型[175],在很多情况下,这些抽象在数据分析平台中已经可用,如Hadoop/MapReduce[39]、Spark[115,200]或Pregel[111]。严格同步的好处是,对模型收敛的推理更容易。然而,严格的同步化使训练过程容易出现散兵游勇问题,即最慢的工作者会拖累所有其他工作者[28]。
Cui等人的GeePS[36]是一个针对GPU的参数服务器实现。这包括一些优化,如预建索引、缓存、数据暂存和内存管理。虽然GeePS支持同步、有界异步和异步参数同步,但它的设计是为了最大限度地减少GPU上的散兵游勇问题,因此,在使用同步方法时能达到最佳收敛速度。Wang等人[184]提出了一种基于BSP的积极的同步方案,名为A-BSP。与BSP不同的是,A-BSP允许最快的任务获取由其他只处理了部分输入数据的任务(散兵游勇)产生的当前更新。作者在Spark[115, 200]以及Petuum系统[196]上都实现了A-BSP。Koliousis等人的CROSSBOW[89]介绍了同步模型平均化(SMA)。在SMA中,数据并行的工作者访问一个全局平均模型以相互协调。特别是,工作者在他们各自的训练数据碎片上独立地训练他们的模型副本,但根据他们的本地模型与全球平均模型的差异来修正他们的模型参数。Bonawitz等人[19]讨论了一个为联合学习的同步训练而定制的系统设计。他们解决的主要挑战是如何处理波动的设备可用性和流失、中断的连接和有限的设备能力。为了解决这些挑战,他们建议采用一个带有参数服务器的集中式架构。训练过程被分为后续几轮;每轮结束后,从参与的设备中收集本地计算的梯度更新,并使用联合平均法在参数服务器上进行汇总。通过选择一组新的设备参与每一轮训练,参数服务器可以平衡设备之间的负载,并可以灵活地对设备的流动等动态作出反应。
同步训练在广泛的开源DL框架中实现,如TensorFlow [4, 171] 和MXNet [24, 122]。它特别适合于在单个多GPU计算节点上进行并行训练,在这种情况下,通信延迟较小,计算负载均衡,因此散兵游勇问题不大[123, 171]。
(2) 有界限的异步性。异步训练利用了DL训练的近似性。回顾一下,DL模型是数学函数,它尽可能地接近目标函数f∗(参见第2.2节)。因此,训练过程中的小偏差和非确定性并不一定会损害模型的准确性。这与数据分析中的 "严格 "问题不同,比如数据库查询,它需要返回一个确定的结果。在有界异步训练中,工作者可以在陈旧的参数上进行训练,但陈旧性是有界的[28]。有约束的呆滞性允许对模型收敛特性进行数学分析和证明。该约束允许工作者有更多的自由,可以独立地进行训练,这在一定程度上缓解了散兵游勇的问题,并增加了吞吐量。
Cipar等人引入了陈旧的同步并行(SSP)模型[28]。与BSP模型不同的是,SSP允许工作者有一定的滞后性,也就是说,在一个工作者更新参数和其他工作者看到该更新的效果之间可能存在延迟。这种延迟是以迭代次数来表示的。Cui等人[35]的一篇后续论文对ML作业的SSP进行了实施。Dai等人[37]对SSP进行了理论分析,将其与理论上最优(但实际上无法实现)的方法进行比较。在分析过程中,他们提出了Eager SSP(ESSP),它是SSP模型的一种新的实现。在ESSP中,工作者急切地从参数服务器中提取更新,而SSP只有在工作者状态变得过于陈旧时才会提取更新。ESSP是在Petuum系统中实现的[196]。Li等人[102]的参数服务器有一个灵活的一致性模型,也支持有界延迟。Jiang等人[83]提出在SSP之上使用动态学习率来考虑异质工人。根据工作者的速度,其学习率被调整为陈旧的更新比新鲜的更新对全局参数的影响要小。
正如Zhang等人[203]所注意到的,有界异步模型在DL框架中没有广泛实施。Li[123]在Github讨论中指出,SSP没有在MXNet中实现,因为观察到的延迟只是由于GPU密集型操作的统一性能而导致的小延迟,这样SSP的好处就不够明显。有一些例外的情况。并行ML系统(PMLS)使用了Bösen[187],一个有边界的异步参数服务器。然而,PMLS和Bösen已经不再积极开发。CNTK[158]实现了顺时针模型更新和过滤(BMUF)[23],是有界异步训练的一个变种。Petuum,这是一个商业产品,实现了有界异步模型[196]。
(3) 异步的。在异步训练中,工作者完全独立于对方更新他们的模型。对陈旧性约束没有任何保证,也就是说,一个工作者可以在一个任意陈旧的模型上进行训练。这使得模型收敛的数学推理变得困难。然而,它为工人的训练过程提供了最大的灵活性,完全避免了所有的散兵游勇问题。
Recht等人的Hogwild[149]是并行SGD的一个异步实现。Hogwild的参数更新方案允许工作者在没有任何锁的情况下访问共享内存,也就是说,工作者可以互相覆盖对方的模型参数更新。由于更新丢失的问题,这似乎很危险:一个工作者写的新模型参数可能直接被另一个工作者覆盖,因此不会有任何影响。然而,作者表明,只要单个工作者的更新只修改模型的小部分,Hogwild就能达到近乎最佳的收敛效果。通过放弃锁定,Hogwild的执行速度比在每次更新前锁定模型参数的更新方案快一个数量级。Hogwild方案已成功应用于神经网络的训练[42]。Dogwild [133] b y Noel和Osindero是Hogwild的一个分布式实现。作者报告说,使用UDP会使网络堆栈拥堵,而使用TCP则不能充分利用通信带宽,还会造成延迟高峰,因此他们使用原始套接字代替。Zhang等人的Hogwild++[204]是对Hogwild的改编,用于基于NUMA的内存架构。Dean等人的Downpour SGD[38]是一个为大型商品机集群量身定做的异步SGD程序。Downpour SGD的主要概念包括分片参数服务器和自适应学习率的应用[44]。与无锁的Hogwild不同,Downpour SGD使用有锁保护的参数增量。Li等人的MALT[101]是一个异步的ML框架,遵循去中心化的架构。它为工作者提供了一个共享的内存抽象,提供了一个散射/收集接口以及一个更高级别的矢量对象库。
与同步训练一样,异步训练也是成熟的;在当前的开源DL框架中有许多实现,如TensorFlow[171]、MXNet[122]、CNTK[31]和PyTorch[145]。
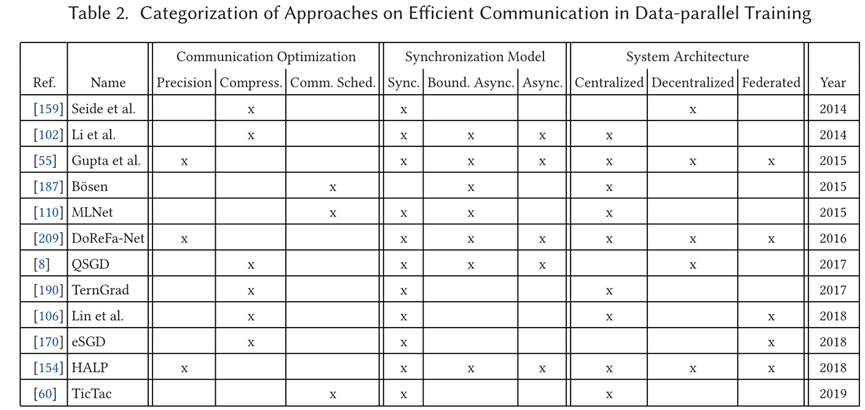
3.3.3 通信。在数据并行训练中同步模型副本需要工作者之间以及工作者和参数服务器之间(在集中式结构中)的通信。优化通信的主要挑战是防止通信成为整个训练过程的瓶颈,这将使计算资源得不到充分的利用。我们确定了三种提高通信效率的主要方法:(1)降低模型精度,(2)压缩模型更新,以及(3)改善通信调度。表2对目前的通信方法进行了分类。
(1) 降低模型精度。当参数更新需要通过网络传输时,降低模型参数的精度可以节省通信带宽。此外,它还可以减少模型的大小,当模型部署在资源受限的硬件(如GPU)上时,这可能是有用的。精度降低可以通过降低参数数据类型的精度来实现,例如,从双精度到单浮点精度,甚至更低。
Gupta等人[55]将DL模型的数值精度限制在16位定点运算。他们发现,当应用随机四舍五入而不是常见的四舍五入方法时,有限精度的方案达到的模型精度与应用DL中通常使用的传统32位浮点运算时几乎相同。这使得模型的大小可以减少一半。当应用于数据并行的DL系统时,这也将减少工作者和参数服务器之间沟通参数更新所需的网络带宽;该方法本身并不依赖于特定的同步方法或并行架构。Zhou等人的DoReFa-Net[209]专注于CNN。他们的主要想法是将权重、激活和梯度的数值精度降低到不同的位宽。他们报告说,在AlexNet CNN[92]上使用1位权重、2位激活和6位梯度,仍然可以达到与32位表示法相当的精度。De Sa等人[154]提出的高准确度低精度(HALP)是一种算法,它结合了两种优化技术,在参数精度有限的情况下达到高的模型准确度。首先,他们使用随机方差减少的梯度(SVRG)[85]来减少梯度方差带来的噪声。其次,为了减少参数量化带来的噪声,他们引入了一种新的技术,称为位中心化,即随着模型的收敛,对参数的定点表示进行再中心化和再缩放。与Gupta等人[55]一样,他们依靠随机舍入进行量化。
模型量化通常用于减少已经训练好的模型的大小,以提高推理的效率,例如,在移动设备上。例如,在TensorFlow Lite[172]、MXNet[126]和PyTorch[147]中实现了这种训练后量化。训练时的模型量化不太常见;它没有在DL框架中广泛实现。
(2) 压缩模型更新。工作者之间以及工作者和参数服务器之间交流的模型更新可以被压缩。无损压缩在可实现的压缩率方面是有限的,因为参数更新的冗余度通常是有限的。相反,要采用有损压缩。文献中的主要方法是梯度量化(减少每个梯度的比特数)和梯度稀疏化(只传达具有重要值的重要梯度)。
Seide等人[159]报告了将语音DNN中的梯度量化为一个单一比特。为了达到高精确度,他们提出了一种叫做误差反馈的技术。在误差反馈中,当量化梯度时,他们保存诱导的量化误差,并在量化前将其添加到相应的下一批梯度中。因此,梯度的信息不会因为量化而丢失,但所有的梯度最终都被加入到模型中。Wen等人的TernGrad[190]引入了三元梯度,即梯度的值可以是-1、0或1。为了提高模型的精度,他们提出了分层三元化(即对每一层使用不同的量化)和梯度剪切(即在量化之前限制每个梯度的大小)。Alistarh等人的QSGD[8]采用了类似的方法。他们应用了随机四舍五入(参考Gupta等人[55]和De Sal等人[154])和统计编码;后者的关键思想是,并非所有的值都是同样可能的,这在编码方案中得到了利用。
除了量化,另一种常见的技术是梯度稀疏化。它是基于这样的观察:在训练过程中,许多梯度非常小(即数值接近于0),对训练的贡献不大。通过排除不重要的梯度值,可以减少通信量。Li等人[102]的参数服务器允许通过用户定义的过滤器进行梯度稀疏化。eSGD[170]是一种用于联合架构的梯度稀疏化方法。Lin等人[106]提出了一种基于阈值的梯度稀疏化方法。只有大于阈值的梯度被传输。其余的梯度被累积,直到达到阈值。这与Seide等人[159]为量化提出的错误反馈类似。Lin等人将他们的稀疏化方法与动量校正结合起来,以减轻传输累积的小梯度所带来的问题。此外,他们还应用了梯度剪裁。
训练时的梯度量化和稀疏化在一些开源的DL框架中实现。CNTK实现了Seide等人的1位随机梯度下降[159]。MXNet支持带有误差反馈的2位量化;1位量化和稀疏化技术正在开发中[124]。
(3) 通信调度。数据并行DL中的通信模式通常是突发性的,特别是在严格的同步系统中。所有的工作者都可能在同一时间与他们的同伴工作者或参数服务器分享他们更新的参数。为了防止超过网络带宽和通信延迟,可以安排不同工作者的通信,使其不重叠。此外,当带宽受到限制,但有太多的参数更新需要发送时,通信调度可以将特定的消息优先于其他消息,例如,根据新鲜度或对模型收敛的重要性。
Wei等人的Bösen[187]通过优先考虑对模型收敛最重要的更新,使网络通信效率最大化。Hashemi等人的TicTac[60]是一个在同步集中式架构中进行通信调度的系统。他们观察到,在许多ML和DL系统中,如TensorFlow和PyTorch,参数在训练和推理过程中是随机传输的。这导致了迭代时间的高差异性,从而减慢了进程。为了克服这个问题,TicTac执行了一个网络传输的时间表,以优化迭代时间。Mai等人的MLNet[110]是一个用于集中式数据并行ML的通信层。他们将一个树形的通信覆盖层与流量控制和优先级相结合,以缓解网络瓶颈。
复杂的通信调度算法还没有在开源DL框架中找到它们的方式。这可能是由于这些方法的新颖性。
3.4 调度和弹性
DL中的调度问题是指如何将(可能是平行的)DL训练过程映射到分布式基础设施的处理节点上。我们确定了DL中调度的三个不同方面。
首先,是单租户调度(第3.4.1节)。如何将单个租户(即训练工作)的进程(如工作者和参数服务器)映射到可用的基础设施上?如果这种映射是动态的,我们可以改变训练进程的数量(例如,工人和参数服务器的数量)以及基础设施(例如,计算节点的数量),我们也会谈论调度问题的弹性。
其次,还有多租户调度(第3.4.2节)。给定多个相互竞争的训练作业(每个都有一些进程),如何将它们映射到可用的基础设施上?多租户的情况引入了额外的挑战,比如更大的复杂性和额外的要求或约束,比如租户之间的公平性。
第三,有一个具体的调度问题,涉及到DL中训练作业的创建,即模型架构和超参数搜索(3.4.3节)。这个问题与单租户和多租户的调度是紧密相连的。
3.4.1 单租户。在单租户调度中,我们假设有一组专用的、但可能是动态的资源(计算节点、CPU、GPU),可用于承载一组源自单个DL训练作业的进程。对于训练工作,我们指的是参与执行单个DL模型训练的所有进程。根据并行化的方法,这可能包括训练完整(数据并行)或部分(模型并行)模型副本的工作者,以及参数服务器。现在,调度需要回答以下问题:(1)哪个进程被放在哪个资源上(如计算节点、CPU或GPU)?(2) 何时或以何种顺序执行被放在同一资源上的进程?(3) 进程和/或资源的数量何时以及如何调整?在模型并行化中,需要解决的主要问题之一是将模型分割成多个部分。我们在第3.2节讨论了这个问题和解决这个问题的最先进的方法。一旦模型被分割,接下来的重要问题是将模型的各个部分放在哪里,以及何时训练模型的哪个部分。由于一个模型分区的训练迭代只有在该分区的所有输入数据可用时才能执行,因此在安排不同的模型分区时存在依赖性。Mayer等人[113]将模型并行DL中的调度问题正式化。虽然他们提出了几个启发式算法,但没有一个是在DL系统的背景下实现的。特别是,在模型分区和调度问题之间存在着相互依赖的关系,这一点还有待充分探讨。随着动态控制流的出现[79, 199],更多的挑战出现了,这使得静态调度变得不可行。Park等人[138]对层的放置进行了研究,但仅限于CNN。Kim等人的STRADS[88]是一个具有高级调度器的模型并行ML框架。特别是,STRADS可以考虑到模型分区的依赖结构,并且能够对计算进行优先排序。为此,用户必须通过调度、更新和聚合三个函数来实现他的训练任务。虽然本文包含了经典ML算法的实现实例,如LASSO和主题建模,但通过STRADS接口实现一个模型并行的DL训练工作并不简单。
Qiao等人的Litz[146]是一个弹性的ML框架,暴露了一个事件驱动的编程模型。在Litz中,计算被分解成微任务,在集群上动态调度。调度器考虑到了ML模型的依赖性和一致性要求。为了实现无中断的弹性,输入数据被 "过度分割 "到逻辑执行器上,这些执行器被动态地映射到物理资源上。这甚至允许透明地扩展有状态的工作者,即保持本地状态的工作者,不通过参数服务器或直接与同行工作者共享。当不同的模型状态受到不同范围的输入数据的训练影响时,这种特性是很有用的,这样为了更快地访问,模型状态的那一部分直接保存在工作器上。
Harlap等人的Proteus[59]利用了瞬时资源,如Amazon EC2现货实例和Google Compute Engine可抢占实例。它的主要概念是一个参数服务器框架,该框架针对瞬时资源的批量添加和撤销进行了优化,还有一个资源分配组件,该组件根据高度动态的现货市场动态分配瞬时资源,使每项工作的总体货币成本最小。
Koliousis等人的CROSSBOW[89]是一个分散的数据并行DL系统,可以在运行时自动调整工作者的数量。为此,在训练期间增加工人的数量,直到观察到训练吞吐量不再增加。这样一来,可用的基础设施就可以得到最佳利用。此外,CROSSBOW有一个动态任务调度器,可以根据资源的可用性在GPU上执行工人。Huang等人的FlexPS[71]解决了在执行ML训练过程中不同工作负载的问题。作为不同工作负载的来源,Huang等人提到了自适应超参数(特别是批次大小)和高级SGD方法,如SVRG[85]。作为这个问题的结果,并行度,即工作者的数量,需要进行调整,以重新平衡数据并行训练中通信和计算之间的权衡。
3.4.2 多租户。在一个多租户环境中,多个培训工作(租户)共享一组共同的资源。因此,一个资源调度器负责在资源上调度不同租户的进程。有大量的通用资源调度器,如Mesos[64]、YARN[178]和Borg[179]。然而,这些都不是针对DL训练任务的具体属性而定制的。例如,在DL中,训练任务的收敛率随时间变化。通常情况下,在训练的开始阶段,进展非常快;然而,随着训练在许多epochs中的发展,对模型准确性的改善会减少。此外,不同的DL训练工作可能有非常不同的训练曲线[205]。考虑到这些DL的特定属性,可以制定新的、针对DL的优化目标,例如,在所有预定的训练任务中,最大化整体训练进度。因此,新的DL资源调度器正在被提出。
Lee等人提出的Dolphin[98]是一个弹性集中的数据并行ML框架。在Dolphin中,参数服务器和工作者的配置是根据成本模型和持续监测动态调整的。这里,配置指的是服务器和工作者的数量,训练数据在工作者之间的分布以及模型参数在参数服务器之间的分布。该系统是在Apache REEF[188]的基础上实现的,这是一个分布式应用的框架。Peng等人的Optimus[141]是一个在运行时动态调整工作者和参数服务器的数量和位置以达到最佳资源效率和训练速度的系统。为此,它建立了基于抽样的性能模型,估计出收敛前所需的训练历时数以及不同配置(工作者和参数服务器的数量)对训练速度的影响。然后,一个贪婪的算法计算出工人和参数服务器的最佳资源分配。考虑到要安排的多个并发的训练作业,Optimus的目标是使平均作业完成时间最小。Optimus解决的另一个挑战是将模型参数划分到参数服务器上,使其负载均衡。与通用调度策略Dominant Resource Fairness[49]和Tetris[52]相比,Optimus在平均作业完成时间和makespan方面有明显的改进。Jeon等人[78]分析了一个大规模DL集群系统的日志痕迹。特别是,他们分析了占用大量(GPU)资源的大型训练作业的位置性约束和排队延迟之间的权衡。此外,他们观察到将不同的作业放在同一台服务器上可能会大大影响其性能。最后,他们还分析了DL训练中的故障以及发生这些故障的根本原因。
他们区分了由基础设施、DL框架和用户引起的故障。基于他们的分析,他们提出了一些多租户DL调度的最佳实践。首先,他们强调地方性是调度器的一个主要设计目标,肯定应该被考虑在内。第二,他们强调工作的隔离对于避免性能干扰是很重要的。第三,他们建议新的作业在进入集群之前应该首先在一小部分专用服务器上进行测试。Ease.ml[104]是一个ML服务平台,采用了多租户资源调度器。用户用声明性语言定义他们的训练作业,并通过网络界面提交给Ease.ml。然后,ease.ml不仅在可用资源上调度该作业,而且还自动进行模型架构和超参数搜索。ease.ml的总体目标是使所有租户(即系统的用户)的平均模型精度达到最大化。Zhang等人的SLAQ[205]有一个类似的目标,但支持更广泛的优化目标。它不仅使平均精度最大化,而且还解决了一个最小-最大问题,以提供租户之间的公平性。加州大学伯克利分校的Ray[121, 132]是一个分布式系统,专门用于支持强化学习的要求。Ray的设计使其有必要每秒动态调度数百万个任务,其中每个任务代表一个远程函数调用,可能只需要几毫秒就能完成。Ray中的调度器是分层的,有两个层次:一个单一的全局调度器和每个节点的本地调度器。只要一个节点没有过载,本地调度器就会自主地调度其任务。然而,如果本地调度器检测到过载,它就会将任务转发给全局调度器,后者将其分配给其他节点。
除了描述具体的多租户调度器的出版物,还有描述DL服务的出版物。IBM Fabric for Deep Learning[18](FfDL)是AI研究人员在IBM使用的基于云的深度学习堆栈。基于FfDL,IBM提供DL即服务(DLaaS)[17],这是一个完全自动化的DL云解决方案。Hauswald等人[61]描述了Djinn,一个用于大规模分布式基础设施中的DL即服务的开放基础设施,以及Tonic,一个用于图像、语音和语言处理的DL应用套件。他们分析了其系统的工作负载,并提出了适合DL工作负载的大规模基础设施的设计。他们的发现之一是,与只应用CPU相比,采用GPU进行DL训练和推理可以极大地降低总成本。在他们的分析中,他们考虑到了前期的资本支出、运营成本和融资成本。虽然GPU的购买价格较高,但由于在处理DL工作负载时运营成本较低,这种投资得到了回报。
3.4.3 模型结构和超参数搜索。模型结构和超参数搜索是DL训练中的一个关键问题。给定一个特定的任务(例如,图像分类),什么是最好的模型结构(例如,CNN有多少层和多少层维度),可以达到最好的准确性?以及什么是快速达到模型收敛的最佳超参数设置?找到这些问题的答案是困难的。典型的方法是反复尝试不同的架构和超参数设置,以找到最好的一个,即基于实验评价的搜索[166]。这种搜索可以是随机的[16],也可以是通过更复杂的模型进行的,如随机森林和贝叶斯优化[73],或e v e n r e inforcement learning[12, 210]。所有这些方法的共同点是,它们反复产生具有新配置(架构和超参数设置)的新训练作业,需要在一组共享的分布式资源上进行调度。在这里,我们讨论了明确考虑到由这种搜索策略产生的工作负载的调度方法。
Sparks等人的TuPAQ[166]是一个自动生成和执行模型搜索配置的系统。根据领域专家提供的性能概况,TuPAQ自动优化了数据并行训练的资源量。将访问相同训练数据的训练任务分批进行,可以减少网络负荷,并在执行中进一步优化。Rasley等人的HyperDrive[148]是一个调度器,它比TuPAQ更积极地优化了超参数搜索。特别是,HyperDrive支持提前停止配置不佳的作业的训练。此外,通过纳入训练模型的学习曲线轨迹,HyperDrive预测了预期的精度提高。在此基础上,与其他配置相比,更多的资源被分配给具有高预期精度改进的训练作业。Narayanan等人设计的HiveMind[127]是一个旨在优化在单个GPU上执行多个DL训练任务的系统。该系统联合执行一批模型,并进行跨模型的优化,如运算器融合(如不同模型架构上的共享层)和共享I/O(如对不同配置使用相同的训练数据)。Xiao等人的Gandiva[195]是一个在GPU驱动的计算节点集群上同时安排超参数搜索的作业集的系统。通过利用早期反馈,作业的子集可以被杀死,资源可以被释放。基于对作业执行时间的分析,Gandiva采用了细粒度的应用意识,对GPU资源进行时间切分,以最佳方式利用它们。为了把作业放在GPU上,Gandiva还考虑到了它们的内存占用以及通信强度,以尽量减少作业执行之间的干扰。
3.5 数据管理
大规模DL的巨大挑战之一是处理所涉及的数据。一方面,这指的是训练数据的管理,其数量很容易超过一个服务器上的单个磁盘或多个磁盘的能力。另一方面,它指的是DL模型的管理,包括完全训练好的模型以及目前处于训练阶段的模型的快照。
训练和模型数据需要以合适的方式处理,同时考虑到可用的分布式基础设施、运行中的训练过程和数据中心的资源调度。
3.5.1 训练数据。获得大型标记的训练数据集是一个困难的问题。实现这一目标的方法之一是采用人工标注的方式。例如,为了建立ImageNet数据集,作者通过Amazon Mechanical Turk进行众包,这导致了标签的高准确性[40]。然而,人工标注是昂贵和耗时的。因此,有几种方法允许用高噪声的训练数据进行训练,这些数据可以很容易地获得,例如从网络图像搜索中获得。Xiao等人[194]将一个标签噪声模型嵌入到一个DL框架中。他们训练两个CNN:其中一个CNN预测标签,而另一个CNN则预测训练数据集的噪声类型。为了训练,他们首先用干净的训练数据对两个CNN进行预训练。然后,他们用噪声数据训练模型,但混入有干净标签的数据以防止模型漂移。
总的来说,从噪声数据中学习是一个巨大的研究领域(参考文献[119, 168]),我们不会在本调查中全部涵盖。
除了获得数据(有噪音的或干净的),训练数据的预处理是数据管理的一个重要步骤。这包括规范化,如图像数据的裁剪、大小调整和其他调整[29],或数据增强,如从语音数据中创建谱图[53]。
除了规范化和增强,用扭曲的训练数据训练DL模型可以提高模型对噪声输入数据的鲁棒性[208]。因此,训练数据的预处理在整个DL架构中起着重要作用。例如,Project Adam和Facebook都描述了预处理是在不同的数据服务器上进行的[27, 62]。
一旦获得了训练数据并进行了预处理,就必须将其提供给训练服务器,以便在训练迭代中将其输入DL模型。Ozeri等人[136]使用简单而便宜的对象存储来存储和提供训练数据。对象存储的缺点是,数据提供的带宽被限制在单个请求的每秒35MB,而根据作者自己的测量,在一台有4个GPU的机器上,训练数据的吞吐量可以达到每秒570MB。他们在DL栈中添加了一个基于FUSE的文件系统,将POSIX API请求转化为REST API请求。为了克服读取吞吐量的限制,他们的存储层将单个读取请求转换为对对象存储的多个并发请求,以产生更高的总带宽。Kubernetes Volume Controller[94](KVC)是Kubernetes集群上训练数据管理的一个高级接口。它提供了一个可以被训练进程使用的训练数据的抽象,并在内部向用户透明地管理数据的放置和复制。Pinto等人的Hoard[142]是一个分布式缓存系统,它将训练数据剥离到工人机的本地磁盘上,以便快速访问。训练数据只从后端加载一次,然后可以从缓存中为随后的历时和使用相同训练数据的训练任务提供数据(例如,在探索性结构和超参数搜索)。
3.5.2 模型数据。管理训练过的模型与训练过程本身一样重要。
根据Vartak等人[177],模型管理包括对训练过的模型进行跟踪、存储和索引。模型管理的目标是促进DL模型的共享、查询和分析。为了使之成为可能,目前有许多倡议和方法。
为了促进不同DL框架之间的互操作性,正在开发开放神经网络交换格式(ONNX)[3]。ONNX是DL框架之间交换模型数据的事实标准。原生支持ONNX的DL框架有Caffe2、Chainer[7, 174]、CNTK[158]、MXNet[24]、PyTorch[139]、PaddlePaddle[137]、Matlab和SAS[155]。此外,TensorFlow[4]、Keras、Apple CoreML[33]、SciKit-learn[140]、XGBoost[193]、LIBSVM[22]和Tencent ncnn[128]都有模型转换器。V a r tak等人的ModelDB[177]是一个用于模型管理的系统,它提供了对ML模型的自动跟踪、索引以及通过SQL或可视化界面进行查询。除了模型本身,ModelDB还管理元数据(例如,训练过程的超参数)、质量指标以及每个模型的训练和测试数据集。Miao等人的ModelHub[116]是一个与ModelDB有类似目的的系统。除了提供一个版本化的模型存储和查询引擎以及用于模型架构和超参数搜索的特定领域语言外,ModelHub还提供了一个基于资源库的模型共享系统,以方便不同组织之间交换DL模型。
4 深度学习框架的比较
自从DL兴起以来,已经开发了大量不同的DL框架和工具,其中许多是开源的。它们实现了不同的并行化和分布的概念,我们在第3节已经讨论过了。拥有大量开源DL框架的选择是创新DL研究的动力之一。在本节中,我们回顾并比较了当前的开源DL框架和工具。
4.1 评价标准
我们根据以下标准来讨论和比较这些框架。
(1) APIs。DL框架应该支持大量的编程语言,这样来自不同领域的专家可以很容易地使用它们。此外,它们应该提供高层次的抽象,这样就可以在没有很多障碍的情况下快速创建一个运行中的DL用例。
(2) 支持分布和并行化。在云环境中,资源丰富且按需提供。DL框架应该允许轻松和直观地支持分布和并行化,而不需要定制代码。我们在第3节中讨论的并行化方法和优化方面特别研究了这一点。此外,我们还讨论了用户根据自己的需要微调其部署的可能性。这涉及到DL框架对DL模型和损失函数的自定义定义的支持,以及为参数服务器或去中心化系统中的自定义拓扑结构开发自定义代码。
(3) 社区。由于DL领域是动态发展的,新的DL模型架构和并行化方法正在被提出,因此DL框架拥有一个活跃的社区,讨论和实现最有前途的方法是至关重要的。我们通过过去六个月(即2018年10月至2019年3月)官方Github仓库的提交数量以及StackOverflow4上带有相应标签的主题总数来衡量社区活动(https://stackoverflow.com/)。
我们强调,我们没有讨论和比较DL框架的性能;对DL框架的全面性能评估不在本调查文章的范围之内。
还有一些比较性能的研究,例如Liu等人[108]或Jäger等人[77]的研究。
4.2 详细分析
在下文中,我们将更详细地讨论这些框架。表3提供了一个概述。
Caffe是一个由伯克利人工智能研究和社区贡献者开发的DL框架。它有命令行、Python和Matlab APIs。Caffe的一个特点是模型动物园,它是一个预训练模型的集合体,便于启动。它在CUDA平台上运行(使用cuDNN库),便于在GPU上进行并行化。Caffe不支持开箱即用的分布式训练。然而,有一些Caffe的分叉和扩展,如Intel Caffe5和CaffeOnSpark6,支持分布式训练。在Caffe的文档中,只有很少的信息是关于如何定制框架的,例如,开发新的损失函数。由于Caffe不支持多节点部署,因此也无法实现定制的并行化技术。Github上的提交活动几乎完全停止了。在StackOverflow上,有2750个问题被标记为 "Caffe",与其他框架相比,这个数值很高。
Caffe2是由Facebook和社区贡献者开发的Caffe框架的继承者。它的API是以C++和Python语言提供的。Caffe的模型可以很容易地转换为Caffe2的工作。除此之外,Caffe2也提供了它自己的模型动物园。Caffe2在以下几点上扩展了Caffe。首先,Caffe2自然支持分布式训练。本机支持使用同步模型进行分散的数据并行训练;不支持(有界)异步训练,也没有参数服务器架构。也有对量化模型的原生支持,即数据类型精度降低的模型。最近,Caffe2的代码被并入PyTorch。这使得我们很难评估Caffe2代码的更新频率。在StackOverflow上,有116个问题被标记为 "Caffe2",与其他框架相比,这个数值相当低。
Chainer是一个DL框架,由日本公司Preferred Networks与几个工业伙伴和社区贡献者共同开发。它是用Python编写的,只有一个Python接口。关于如何编写自定义函数、优化器和训练器,有很好的文档。
ChainerMN是一个扩展包,可以在多个节点上实现分布式和并行DL。它通过一个分散的全还原架构,使用同步训练方法(不支持参数服务器或异步训练)支持数据并行。在过去的六个月里,官方Github仓库有3939个提交,这是一个相当高的数值。
在StackOverflow上,有132个问题被标记为 "Chainer",与其他框架相比,这个数值相当低。
CNTK(Microsoft Cognitive Toolkit)是微软和社区贡献者共同开发的深度学习框架。该 API 在 C++、C# 和 Python 中可用。此外,CNTK 提供了一种称为 BrainScript 的自定义模型描述语言。模型评估函数也可以在 Java 程序中使用。开箱即用地支持数据并行和分布式训练。 Seide 等人 [159] 的 1 位随机梯度下降被集成到框架中。 CNTK 支持带有参数服务器的集中式架构,使用异步训练或分块模型更新和过滤 (BMUF) [23],这是有界异步训练的一种变体。目前,CNTK 不支持模型并行。扩展 CNTK 很容易。新的操作符、损失函数等可以通过 API 实现。在过去的六个月里,官方 Github 存储库有 138 次提交,这是一个相对较低的值。在 StackOverflow 上,有 488 个问题标记为“CNTK”,这是与其他框架相比的平均值。
Deeplearning4j 是由 Skymind 公司和 Eclipse 基金会组织的社区贡献者开发的 DL 框架。该框架是用 Java 和 C++ 编写的(用于核心组件),API 在 Java 中可用,这使得它可用于 Java、Scala 和 Clojure 项目(但不能从 Python 中访问)。它支持使用 Spark 进行分布式和并行训练。
实施了两种数据并行训练的变体。首先,Strom [167] 提出了一种分散的异步方法,该方法还结合了梯度的量化。其次,使用单个参数服务器进行集中式同步训练。不支持模型并行性。创建自定义层实现很容易,但不支持更复杂的自定义(损失函数、并行化配置等)。在过去的六个月里,官方 Github 存储库有 390 次提交,这是一个平均值。
在 StackOverflow 上,有 243 个问题标记为“Deeplearning4j”,与其他框架相比,这个值相当低。
Keras 不是一个深度学习框架,而是一个深度学习库,可以集成到许多其他深度学习框架中,例如 CNTK、Deeplearning4j、TensorFlow 和 Theano。它是作为一个社区项目开发的,由 F. Chollet 发起。 Keras 是用 Python 编写的,可以轻松集成到其他基于 Python 的框架中。自然支持 GPU 上的并行训练;更高级别的并行化概念必须由使用 Keras 的 DL 框架来实现。 Keras 直接支持模型量化(到 8 位模型权重)。该库很容易使用新模块进行扩展。在过去的六个月里,官方 Github 存储库有 310 次提交,这是一个平均值。在 StackOverflow 上,有 14,630 个问题标记为“Keras”,与其他框架相比,这是一个非常高的价值。
MXNet是一个DL框架和一个Apache项目(正在孵化)。其API可用于C++、Python、Julia、Matlab、JavaScript、Go、R、Scala、Perl和Wolfram Language。MXNet支持广泛的并行化方法。模型并行支持单个节点上的多个GPU;但不支持多节点模型并行。数据并行是通过集中式架构实现的,支持通过分片式键值存储使用多个参数服务器。同步和异步训练都是开箱即支持的。MXNet还支持根据英特尔(R)深度神经网络数学内核库(Intel(R) MKL-DNN)[126]定制的训练后8位模型量化。在训练过程中,支持带有误差反馈的2位梯度量化[124]。它很容易实现自定义运算符或层以及损失函数。在过去6个月中,官方Github仓库有837个提交,这是一个平均值。在StackOverflow上,有455个问题被标记为 "MXNet",与其他框架相比是一个平均值。
PyTorch是一个由Facebook和社区贡献者开发的DL框架。其API可用于C++和Python。PyTorch原生支持分布式、数据并行训练以及模型并行训练。对于数据并行训练,PyTorch实现了分散式架构,支持同步和异步训练。PyTorch支持通过QNNPACK库进行模型量化[147]。梯度量化是不支持开箱即用的。编写新的运算符或层可以通过扩展接口轻松完成;也可以编写自定义的损失函数。在过去6个月中,官方Github仓库有3484个提交,这是一个比较高的数值。在StackOverflow上,有2413个问题被标记为 "PyTorch",与其他框架相比,这个数值相当高。
SINGA是一个DL框架和Apache项目(正在孵化),由社区贡献者开发。项目的发起人来自新加坡国立大学。它有C++和Python的API。Singa原生支持分布式、数据并行和模型并行训练,以及混合并行(结合数据和模型并行)。数据并行是通过集中式方法实现的,支持多个参数服务器。然而,分散式结构可以通过每个工作者使用一个本地参数服务器来模拟。同步和异步训练都得到支持。没有对模型或梯度量化的支持。定制比其他框架更困难。文档中没有任何关于如何实现自定义层或损失函数的提示。在过去6个月中,官方Github仓库有44个提交,这是一个相当低的数值。在StackOverflow上,没有标记为 "Singa "或 "Apache Singa "的问题,在搜索关键词 "Singa "时,只返回一个单一的问题。
TensorFlow 是由 Google 和社区贡献者开发的 ML 框架。该 API 适用于 C++、Go、Java、JavaScript、Python 和 Swift。此外,社区还为 C#、Haskell、Ruby、Rust 和 Scala 提供绑定。 TensorFlow 原生支持分布式和并行训练。特别是,它同时支持模型并行和数据并行。在数据并行性中,支持通过参数服务器的集中式方法,使用异步或同步训练。训练后的模型可以使用 TensorFlow Lite [172] 进行量化。目前,没有对梯度量化或通信调度的原生支持。通过实现可用的接口可以直接自定义层和损失函数。在过去的六个月里,官方 Github 存储库有 10,930 次提交,这是一个极高的价值。在 StackOverflow 上,有 39,334 个问题标记为“TensorFlow”,这是所有分析的 DL 框架中数量最多的。
Theano 是由蒙特利尔大学蒙特利尔学习算法研究所开发的深度学习框架。该 API 仅适用于 Python。不支持在多个节点上进行分布式训练。但是,支持在单个节点上使用多个 GPU。 Theano 支持模型并行,但不支持数据并行。新层可以通过接口实现。也可以定义自定义损失函数。在撰写本调查报告时,提交到官方 Github 存储库的频率很低。根据 Theano 邮件列表 7 上的一篇帖子,Theano 的主要开发随着 1.0 版的发布而停止。但是,从那时起,新的维护版本一直是个问题。在过去的六个月中,官方 Github 存储库仍有 55 次提交。在 StackOverflow 上,有 2,389 个问题标记为“Theano”,与其他框架相比,这是一个相当高的价值。
其他。由于各种原因,我们没有在比较中详细介绍其他几个框架。 Minerva [182] 是一个开源的深度学习系统,但在过去的 4 年里没有得到维护。 SparkNet [120] 允许在 Spark 上进行分布式 DL,但在过去 3 年中一直没有维护。 Neon [129] 是另一个已停止开发超过 1 年的深度学习框架。 Scikit-learn [140] 是一个 ML 框架,它并不特定于 DL。虽然实现了神经网络训练,但不支持使用 GPU 或分布式训练。 Weka 工作台 [48] 是 ML 和数据挖掘算法的集合。 WekaDeeplearning4j [189] 是 Weka 工作台的 DL 包。作为后端,它使用我们上面讨论过的 Deeplearning4j。
5 结论与展望
深度学习在工业界和学术界变得越来越重要,毫无疑问是过去几年计算机科学中最具影响力的革命之一。然而,该领域的快速发展使得很难保持概览。特别是,目前正在从许多不同的角度和不同的社区对深度学习进行研究。在本次调查中,我们从可扩展分布式系统的角度深入研究了深度学习。我们调查了使深度学习系统规模化的主要挑战,并回顾了研究人员为应对这些挑战而提出的常用技术。这包括对 DL 训练中使用的分布式基础设施以及并行化、调度和数据管理技术的分析。最后,我们对当前开源的深度学习系统和工具进行了概述和比较,并分析了哪些研究中开发的技术已经实际实施。我们看到,可扩展深度学习的各种技术都在开源深度学习框架中实现。这表明研究与实际应用之间存在着卓有成效的互动,这也是深度学习获得如此大势头的原因之一。
我们可以从我们的调查中得出一些关于如何设计未来 DL 基础设施和工具的见解。在我们看来,随着更多训练数据和更多 DL 模型的激增,训练和模型数据的管理成为一个更大的挑战。这需要更好的工具支持,以便可以缓解 DL 可扩展性的新瓶颈和限制。此外,分散式培训(例如联邦学习)的当前发展和进步可能会改变 DL 基础设施和工具的要求和设计。如果基础设施变得更加异构,那么这必须反映在 DL 工具中,这些工具不仅可以处理这种异构性,甚至可以利用它来优化训练过程。
展望未来,我们看到了一些在未来几年很重要的趋势。
虽然对可扩展 DL 的研究主要集中在 DL 训练的并行化和分布方面,但仍需要研究 DL 环境的其他部分,例如数据管理和多租户调度。这是分布式系统和数据库社区研究的一个大领域。此外,DL 服务,即使用训练有素的 DL 模型进行推理,受到越来越多的关注 [34、54、76]。尽管 DL 服务与 DL 训练密切相关,但需求和解决方案却完全不同。 DL 的另一个重要方面是隐私 [5, 103, 162],由于在《通用数据保护条例》(GDPR)等立法改革的推动下,社会对大数据时代隐私问题的认识日益提高,隐私受到越来越多的关注) 在欧盟。在不断增长的对更多训练数据的需求以改进 DL 模型与数据规避和数据经济原则以保护隐私之间存在一个有趣的权衡。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧