

NLP(四十五):keyword_bert
引子
问&答 是人和人之间非常重要的沟通方式,其关键在于:我们要理解对方的问题,并给出他想要的答案。设想这样一个场景,当你的女朋友or老婆大人在七夕前一晚,含情脉脉地跟你说
亲爱的,七夕快到了,可以给我换个新手机吗?
而此时沉迷王者峡谷的你,也许会不假思索地回答
好啊亲爱的~ 昨天刚看到拼多多九块九包邮买一送一可便宜呢~ 多买几个哦一个壳容易坏呀
你话音未落,一记绝杀扑面而来
(王大锤,卒,享年28)
所以,对于生活中这种随处可见的送命题,只要我们惜命&稍微上点心,是不会轻易丢分的。但对于机器来说,这却是个莫大的挑战,因为机器对相似文本的误解非常常见,所以我们的AI也常常被用户戏谑为人工智障(一个听上去很缺AI的称呼)。作为AI背后的男人,我们一直致力于提升AI的能力,让机器早日摆脱智商困境。具体地,针对这种问答场景,我们提出了一套新的方法论和杀手级模型,从而让AI更懂你,远离送命题~
背景
在日常生活中,我们会经常询问我们的语音助手 (小微/Siri/Alexa/小爱/小度 等等)各种各样的问题,其中有一类问题的问法相对严谨,返回的答案需要精准,比如
『姚明的老婆的身高是多少』、『周杰伦的稻香是哪一年发行的?收录在哪张专辑?』
这类问题我们称其为 精准问答,可以借助知识图谱技术,解析问题里的各个成分(实体/实体关系 等等),进行严谨的推理,并返回答案。(我们在图谱问答方面也有积累,有机会再分享,本文先不表)也有一类问题,要么问法多样,要么答案开放,比如
『蛋包饭怎么做』、『评价下cxk的篮球水平』、『酒精到底多少度才能烧起来啊』
对于这类问题的问答,我们将其称为 开放域问答。这类问题要么难以严谨地分析句子成分进行推理、要么无法给出精准的答案,所以一般通过寻找相似问题,来曲线救国。大致的流程如下
首先我们需要维护一个海量且高质量的问答库。然后对于用户的问题(Query),我们从问答库里先粗略地检索出比较相似的问题 (Questions),对于这些候选问题,再进一步进行『语义匹配』,找出最匹配的那个问题,然后将它所对应的答案,返回给用户,从而完成『开放域问答』我们可以看到,粗略检索出来的 Question,里面噪音很多,跟我们的 Query 相比,很多都是 形似而神不似。所以最最最核心的模块,便是Query-Question 的语义匹配,用来从一堆形似的候选问题中,找出跟 Query神似的 Question。而一旦匹配错误,便可能陷入 手机 和 手机壳 的险境,轻则用户流失,重则机毁AI亡。
挑战&当前解
解决开放域的语义匹配并非易事,其挑战主要来自以下两方面:
对于第二点,问题对关键信息敏感,我们可以来看一些 case。下面 False Positive 的 case形似但神不似、被模型错分了,而 Fasle Negative 的 case 是神似但形不似,也被模型错分了。
蓝色加粗的词代表模型自以为匹配上的关键信息,红色代表实际要匹配的关键信息、但模型失配了为了解决开放域语义匹配的问题,工业界学术界可谓是八仙过海,各显神通。总的来说,可以看成从数据和模型两个维度去解决问题。
数据维度
训练数据的正样本(也就是 相似问题对儿)一般通过人工标注而来,而负样本(也就是 不相似问题对儿) 的生成策略则各有巧妙不同。最简单粗暴的就是随机负采样,即 给一个问题,从海量的其他问题里随便找个问题,跟它组合在一起,构成一个负样本。但这种负样本对模型来说显然 so easy,并不能很好地训练模型。所以要去找到真正难以区分的负样本(我们称为 混淆样本),从而提升模型的能力。
可以看出,当前并没有一种最优策略来得到这样高质量的数据,或多或少都要加入人工。从本质上来说,语义匹配模型都严重依赖数据的标注,这其实是一种 数据痛点。
模型维度
更为大家所熟知的改进,是从模型上入手。学术界工业界每年都有层出不穷、花样翻新的语义匹配模型,也确实解决了它们所宣称的某些问题,这里我们列举了一部分:
这些模型虽然种类繁多,但从模型结构上看,无非两大类:基于表示和基于交互。基于表示的模型是先对 query-question 分别进行底层表示,然后 high-level 层面进行交互,代表作DSSM、ArcI,基于交互的模型则是让query-question在底层就相互交互,代表作 Bert、ArcII、MIX。不同模型的差异性无非就是内部模块的不同(RNN, CNN, Transformer...),大框架上无外乎此。
本文无意探讨两大类模型的优劣,此方面讨论早有珠玉在前。我们重点讨论的,是:
这些模型,能否真正解决开放域问答的两大挑战:覆盖面广和关键信息敏感?
从我们对这些模型的评测结果上看,答案是:不能。
至于深层次的解释,我认为还是受制于数据的制约,所谓 数据决定上限,模型只是逼近这个上限的程度。如果我们不能提供足够的训练样本,去教会模型分辨出关键信息,光凭模型自身的花式 CNN/RNN/Attention,纵使使出浑身解数,在一些很难分辨的 case 上也未必work。而在预测阶段,鉴于开放域的问题覆盖面很广,很容易出现在训练样本中没出现过的问题对儿(即 Out-Of-Vocabulary, OOV问题),主要问题里的关键信息(相似/不相似 的词对儿)没出现过,此时模型只能抓瞎。
痛点总结
综上,尽管工业界学术界的诸位大神在这个领域持续发光发热笔耕不辍,但我们在开放域的语义匹配场景下,依然面临着两大痛点:
-
数据痛点: 模型依赖高质量数据标注
-
模型痛点:
-
模型对难分样本的关键信息捕获无力
-
模型对 OOV 的相似/不相似词对儿无能为力
-
道: 方法论
为了从根本上解决这两大痛点,我们不再只拘泥于术的层面,去做一些数据采样、模型方面的小改进,而是先深入思考问题的根源,从道的层面提出一套方法论,如下所示:
我们对传统语义匹配模型的框架做了两处改进,一处是加入了 关键词系统,从海量的开放域中提取关键词/词组,然后给训练样本/预测样本中出现的关键词,额外添加一个标注。另一处,是对模型做相应改进,去增强模型对这种关键信息的捕获。这两处改动的核心,是为数据和模型 显式地引入关键信息,这样我们便能从根本上解决我们所面临的数据和模型的痛点,不再只是隔靴搔痒。
为何如此一来,便能解决问题?且听分解。
释道
为了方便大家理解,我们将结合具体 case,来逐条阐释我们的道。
1. 改进的模型:强化模型对关键信息的捕获
这一点很好理解,我们在模型中,额外增加了对关键词词对儿的处理,相当于增加了额外的 feature,给模型提供更多信息,加强模型对问题对儿的区分能力。至于具体的改进细节,我们将会在下节提到,这里先不表。
2. 带关键词的样本:减少对标注数据依赖
我们举个例子,也是我们在引子部分提到的一个负样本:怎么扫码加微信和怎么扫码进微信群。这两个问题不相似的根源,在于微信和微信群的含义不同。但模型一开始学出来的可能是加和进这两个动词的差异(因为微信和微信群的embedding可能非常接近),只有我们提供了额外的样本,比如告诉模型怎么加豆瓣小组和怎么进豆瓣小组这两个问题是相似的,模型才可能学出进和加不是关键,继而学到真正的关键信息。所以如果我们一开始就标注出关键词,相当于告诉模型,这些是候选的、可能的关键信息,模型(经过我们改进后的)就会有意识地针对这部分进行学习,而不需要自行通过更多的样本去判别,从而从根本上解决对标组数据的依赖。我们的结果也佐证了这一点,先提前贴出来,下图是传统的bert模型和经过我们改造的keyword-bert模型,在达到相似准确率上所需要的数据量,具体的我们会在下节阐述。
3. 带关键词的样本:开放领域的先验信息,减少训练集OOV
我们依然举一个例子,一个待预测的样本如何扫码加QQ群和如何扫码进微信群,在训练样本里,QQ群可能从来没跟微信群一起出现在一个问题对儿里(也就是所谓的 OOV),但如果在预测的时候,我们额外标注出QQ群和微信群都是关键词,相当于给出一个 先验信息,模型(经过我们改进的)便能通过自身的关键词模块,专门学习这两个词的异/同,得到一个更好的分类结果,减少OOV带来的负面影响。
术: 实现
道的层面阐释清楚之后,一切就豁然开朗,剩下的实现都是很自然而然的,无非就是围绕我们对传统框架做的两处改进:
-
如何构造一个 关键词系统?
-
如何 改进模型?
在具体实现方法上 并没有标准答案,比如关键词系统,只要能抽取出开放域海量高质量的关键词,就是好系统;再比如模型改进,也不只局限在我们所改进的 Fastpair 和 BERT 上,相似的思想其实可以迁移到目前学术界/工业界大部分已知模型上不过我们还是会毫无保留地给大家展示我们的具体实现,以供参考,抛砖引玉。
关键词系统
如上面所说,一个好的关键词系统,要能抽取出多又好的关键词——即:数量多、质量高。
为了达成这个目标,我们引入了领域的概念,正好契合我们开放域问答的特点——涉及领域多、覆盖面广所以我们先获取了海量的、带有领域标签的新闻/文章,通过各种手段从里面提取出候选的关键词。然后 设计了一个 diff-idf 分值,去衡量这个关键词的领域特性,直观来说,就是这个关键词在自己领域出现的文档频次,远高于其他领域。通过这个分值排序截断后,再进行后处理,去除噪音、实体归一化等等,最后与一些公开词条一起,构成一个庞大的关键词词典。具体的流程如下(比较细碎 但缺一不可)。
这个流程每天都在运行和更新,我们目前的关键词数量达到数百万级,人工评测的质量也不错。下面是一些 case 展示:
模型演化
同样的,模型也要进行相应的升级。我们的模型演化路线如下所示
首先是我们针对之前线上 run 的 Fastpair,做了关键词方面的改进,接着我们鸟枪换炮,升级到 BERT,以应对更复杂的业务场景,并同样对 BERT 做了改进,我们称之为 Keyword-BERT, 从指标上看,这是一个杀手级模型,一下子实现了匹配的质量的质的飞跃,接下来我们将详细阐述。
改进Fastpair
Fastpair 的模型结构如下:
它其实是改造了 Fasttext 以适配文本对儿分类的场景。因为 Fasttext 是针对单文本分类,而要对文本对儿分类,仅用两个文本各自的 n-gram 特征显然是不够的,所以很自然而然地加入两个文本里 各自的词组合在一起形成的 pair-wise 交互特征,这种思想其实跟我们在文章开头提到的,那些『基于交互』的模型的思路很像,先对两个文本的信息进行充分交互融合,再做分类那么我们的问题就是,如何改造 Fastpair 模型,使得它能额外去『关注』关键信息呢?我们的改动非常直观,就是给包含了关键词的 pair-wise 特征,额外加上一个可学的权重,如下所示:
这里我们借鉴了 FM 中参数分解的思想,将孤立的 Wkq 分解成两个词的 embedding 内积,这样既能减少参数量,又能刻画含有相似关键词的 pair-wise 特征之间的共性我们构建了 60w 左右的百度知道问题对儿(正负样本比例 1:1)用来训练,然后人工标注了2k个难分的正负样本用来预测,从预测指标上看,提升非常显著。
然而由于 Fasttext 模型层数浅的固有问题,Fastpair 精度并不高,而且对于 OOV 的 pair-wise 特征也无能为力,当业务场景面临更大挑战时,我们便需要考虑升级我们的武器库了。
Keyword-BERT
BERT 相比其他已知的深度模型,是核弹级别的改进,所以我们理所当然地选择了它 (事实上我们也做了线下实验,结果都在意料之中)鉴于 BERT 的结构已家喻户晓,我们就不细述了,我们重点思考的,是如何给 BERT 增加额外的关键信息捕捉模块?我们的思路跟 Fastpair 的改进一脉相承,只不过将这种 pair-wise 的交互,变成了 attention 机制,具体细节如下:
一方面,我们在最上层引入一个额外的 keyword layer,通过 attention 和 mask ,专门对两个文本之间的关键词信息进行互相之间的 attention, 增强他们之间的互信息,另一方面,对于输出的两个文本的表示,我们借鉴了机器阅读理解里 fusion 的思想进行融合,然后将融合后的结果和 CLS 一起,输出到分类层通过这样的改造,Keyword-BERT 在不同 layer 数目下的指标都优于原始 BERT。
我们发现, layer 数越少,Keyword-BERT 相比原始 BERT 提升越明显。这也很好理解,因为 layer 数越少, BERT 所能学到的句子级别的信息越少,而关键词相当于对这种句子级别信息进行了补充我们最后上线的是 6 layer 的 Keyword-BERT,因为它的性能跟原始 12 layer BERT 非常相似,而推断速度要快很多(在我们内部自研的 BERT 加速框架下)。
延伸
模型结构尝试
正文中给出的 Keyword-BERT 的结构是我们在多次试错上的最优实践,我们还尝试过:
-
直接用 keyword attention layer 取代原始 BERT 第12层layer:效果不好,原因在于,关键词只能作为额外的补充信息,而不是取代原来的语义信息。
-
将 Keyword attention layer 加在模型的底层:效果不好,原因在于,底层信息向上层『传播』过程中,关键词信息被逐渐弱化。
未来工作
关键词仅仅提供了一个维度的信息,我们还可以加入更丰富的信息 (如 词的词性、词的图谱属性 等等) 来增强模型的区分能力,模型框架依然可以用我们现有的结构。
论文原文和源码可见:https://github.com/DataTerminatorX/Keyword-BERT
简介:
深度语义匹配是各种自然语言处理应用中关键的一环,比如说问答 (QA),需要将输入的 query 和 QA 语料库中每一个候选的问题进行相关性比较。在开放域的场景下,question-query pair 中的 word tokens 往往比较丰富,同一个词在不同的领域下可能有不同的语义,不同的词也可能包含相同的语义,所以在这种情况下衡量 question-query pair 的相似度比较困难。本文提出了一种”关键词注意“(keyword-attentive) 的方法提高深层语义匹配 (deep semantic matching) 的表现。首先利用来自大语料库的领域标签生成领域增强的 keyword 字典。然后基于 BERT,在其之上添加了一层 keyword-attentive transformer 层来突出 question-query pair 中关键词的重要性。模型训练过程中,使用了一种新颖的基于 question-query pair 关键词覆盖率的负采样方法。并且使用了各种评价标准对本文提出的方法在 Chinese QA corpus 上的表现进行评估,包括候选 question 的精确率和语义匹配的准确性。
论文地址:https://arxiv.org/ftp/arxiv/papers/2003/2003.11516.pdf
主要内容:
Problem definition
假定现在有一个 query 和相关的候选 question 集合,对于每一个 query pair (q, Qi),计算一个相似度得分 sim(q, Qi) 用于候选排名,为了计算 sim(q, Qi),现在要解决两个问题:
1、如何轻松简单、灵活地获得原始 query 的良好表示形式?
2、如何将 query 表示形式使用到匹配模型中?
本文提出了一个基于领域的关键词抽取方法抽取 query pair 中高质量的关键词解决了第一个问题;使用 keyword-attentive BERT 整合关键词到端到端模型训练解决了第二个问题。
Domain keyword extraction
传统的检索方法例如 TSUBAKI、Elasticsearch 使用 OKAPI BM25 或者 Lucene similarity 衡量 query-question 之间的距离。但是这些方法可能会提取低质量的 "keyword",从而导致检索结果质量较低。如下表,"中国" 和 "GDP" 是关键词,但是搜索引擎倾向于检索形式上看上去更相近的 "similar Q1" 和 "similar Q2",但是显然忽略了重要关键词的匹配。

实际上,开放域 question 的 keywords 是和 question 的领域高度相关的,比如说:经济、政治、体育等等。基于这些,引入了如图所示的基于领域的关键词抽取方法生成领域相关的关键词。并且收集了大型的中文语料库,其中包含数千万条属于特定领域的文章,并且每天对其进行更新以涵盖新的关键字/关键词 (keyword/keyphrase)。
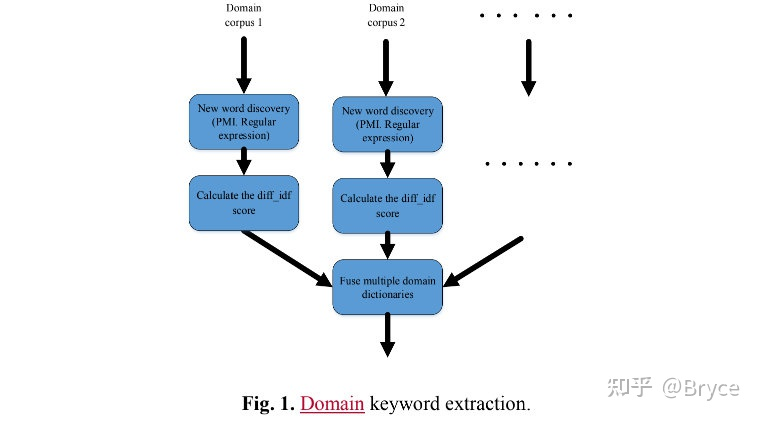
在中文 NLP 场景下,一个中文词语包含几个中文字符,并且没有空格边界,所以分词是中文 NLP 场景下的基础问题。PMI (point-wise mutual information) 是一种衡量两个词紧密程度的常用手段,可以用来发现新词:
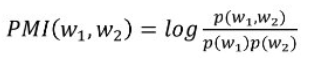
第二步,利用领域信息衡量一个词的重要性。首先,计算每个词的 IDF,然后引入 diff-idf 按照如下方式衡量一个领域词的重要性:

标记 ^domain 表示领域外,使用 df 而非 tf 是因为领域中一个词的 df 比 tf 更加重要,也更加合理,这里是要根据领域抽取关键词并不是要统计某个词对某一个文档的重要性。一个词在不是其领域的文档中的 idf 肯定要比领域内文档的 idf 大,当词越具有领域性,这个差距会越大,得分也就越高。
在每个领域语料库中重复以上步骤,创建领域字典,最后合并领域字典形成最终的关键字词典,并应用于搜索引擎。
和其他无监督/监督方法比起来,此方法具有以下优点:
- 可充分利用语料库的领域信息抽取领域关键词
- 无需手动标注关键词,不严重依赖于模型结构
Semantic matching
- Keyword attention mechanism
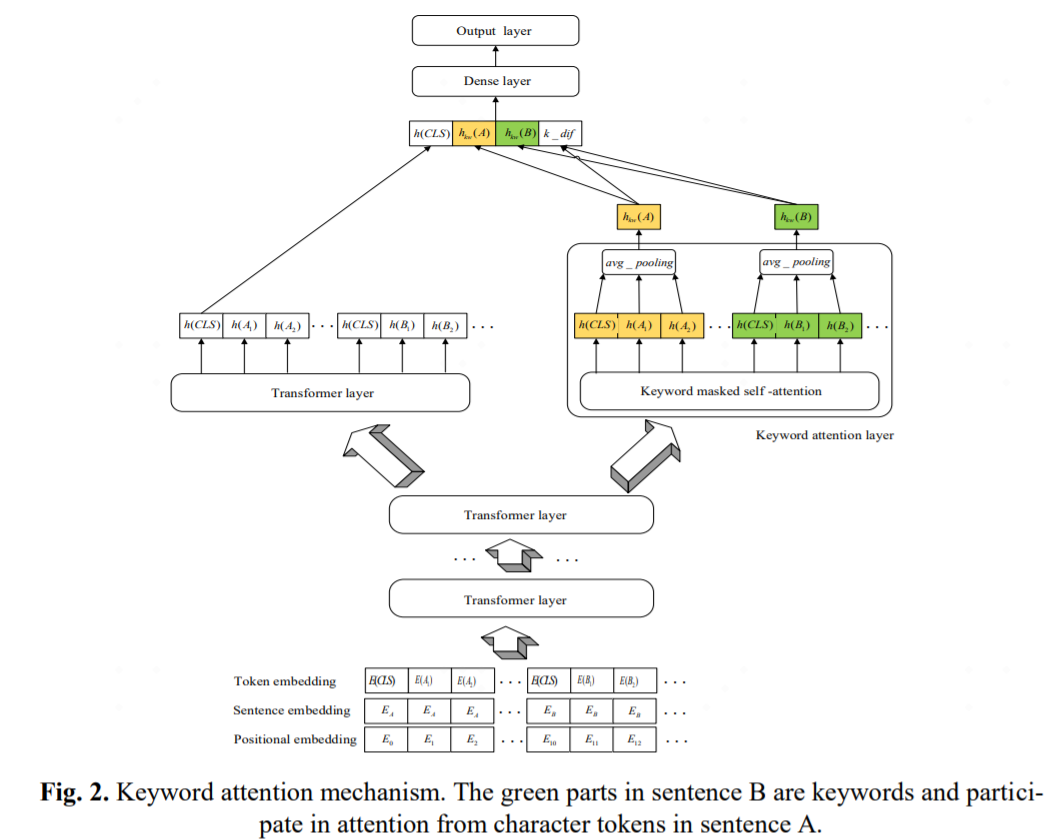
由于监督信号的不充足,深层模型无法精确地捕捉 query pair 中的关键信息用于有效的相似度辨别。A 句中的每个 token 只能关注到 B 句中的关键词 token,反之同理。下图中 A 和 B 是一个负样本,由于都包含 "扫码" A 和 B 看上去很相似,但是整句含义却不同,A 说的是进微信群,B 说的是加好友微信。而本文提出的 keyword-attentive 机制会强制模型关注 A 和 B 关键词的不同而学习它们之间的差异。这个机制可以简单地通过 self-attention mask 的方式实现。然后对 A 和 B (包括 CLS,SEP token) 进行平均池化生成 A 和 B 的表示,为了模拟两个句子间的差异引入了 keyword difference 向量:
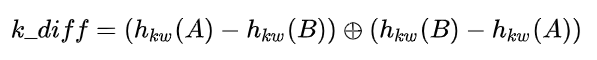
其中中间的符号表示拼接,这个拼接有点迷,前后两者互为相反数,感觉并不能提供更多的特征信息。
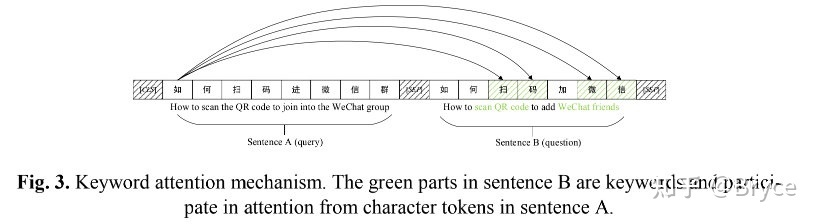
通过 keyword-atttentive 层,关键词信息被注入到距离输出更近的位置。最终拼接来自各个模块的表示用于最终的预测:
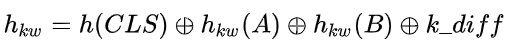
- Negative sampling approach
随机采样生成负样本比较盲目且容易忽略包含丰富信息的负样本。而我们的目标是通过更好的采样方式训练一个鲁棒的模型。
具体做法是,首先通过把关键词接在原始 query 后面的方式增强在搜索引擎中的检索,例如:原始 query ,keyword
,增强后的搜索 query 则为:
。
然后希望没有人工干预的情况下从搜索引擎中取出负样本。一个直接可以参考的指标是根据搜索引擎获得的相似度得分判断检索的候选 question 是不是够自信。如果相似度得分低于某个阈值,则检索出的候选 question 可能是负样本。另外,本文引入了query 和候选 question 中的 keyword 重叠率,一个好的负样本应该在非重叠和重叠部分有着较好的平衡。最终结合两个指标作为负样本选择的规则:
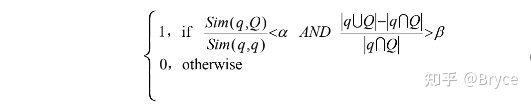
对于上式,有一点疑问,假设 Q 是一个与 query 完全没有重合的样本,此时,关键词重叠率会趋于无穷大,而相似度得分方面也极有可能小于 α (两个字面完全不重合的句子语义相同的概率比较小),这样的一个负样本应该算是一个非常简单的样本了,但是上面的规则貌似无法过滤掉。我想应该是在第一步使用搜索引擎搜索的时候,这样的样本基本不会被检索出来吧,所以这两个指标都是在尽力去保证检索出来的样本是负样本。
还有一种通过随机替换实体的方式来生成负样本,比如: "What factors will affect China’s GDP?" 被替换为 "What factors will affect America’s GDP?",这个过生成的样本看上去极为相似但实则为负样本。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧