

STAN: A sequential transformation attention-based network for scene text recognition
摘要
Scene text with an irregular layout is difficult to recognize. To this end, a S equential T ransformation A ttention-based N etwork (STAN), which comprises a sequential transformation network and an attention- based recognition network, is proposed for general scene text recognition. The sequential transformation network rectifies irregular text by decomposing the task into a series of patch-wise basic transforma- tions, followed by a grid projection submodule to smooth the junction between neighboring patches. The entire rectification process is able to be trained in an end-to-end weakly supervised manner, requiring only images and their corresponding groundtruth text. Based on the rectified images, an attention-based recognition network is employed to predict a character sequence. Experiments on several benchmarks demonstrate the state-of-the-art performance of STAN on both regular and irregular text.
布局不规则的场景文本难以识别。 为此,提出了用于一般场景文本识别的顺序转换基于注意力的网络(STAN),该网络包括顺序转换网络和基于注意力的识别网络。 顺序变换网络通过将任务分解为一系列逐块基本变换来纠正不规则文本,然后是网格投影子模块以平滑相邻块之间的连接。 整个整改过程能够以端到端弱监督的方式进行训练,只需要图像及其相应的真实文本。 基于校正后的图像,采用基于注意力的识别网络来预测字符序列。 在几个基准上的实验证明了 STAN 在规则和不规则文本上的最先进性能。
一、简介
Scene text recognition has been attracting increasing interest in the research community in recent years given its potential applica- tions, such as autonomous driving, intelligent inspection and image searching. With the rapid development of scene text detection [1–4] , research on scene text recognition has become more important, and many investigators have reported successful results for reading regular scene text [5–7] . By integrating convolutional neural net- works, recurrent neural networks and attention mechanisms, many new models [8–10] have yielded better performance.
Nonetheless, in real-world scenarios, scene text often suffers from various types of distortions, such as perspective distortion and curved text (as exemplified in Fig. 1 ), which increase the dif- ficulty of recognition. Rectifying the text image is one promising solution to address this issue. The Spatial Transformation Network (STN) [11] was first proposed for general object rectification, in- cluding translation, scale and rotation. Liu et al. [12] adopted this affine transformation to rectify irregular text images, thereby de- creasing the difficulty of the recognition task. However, the distor- tions of scene text images are more complicated. Recent methods studied more flexible and effective rectification. For example, Shi et al. [13] used a series of the control points and apply the ThinPlate Spline transformation [14] . Luo et al. [15] rectified distorted images by predicting the offset of each part of the image with- out any geometric constraints. Zhan et al. [16] employed a novel line-fitting transformation to estimate the pose of text lines. These methods suggest that there exists much room for improvement of the rectification mechanism.
鉴于其潜在的应用,例如自动驾驶、智能检测和图像搜索,场景文本识别近年来引起了研究界越来越多的兴趣。随着场景文本检测[1-4]的快速发展,对场景文本识别的研究变得越来越重要,许多研究者已经报道了阅读常规场景文本的成功结果[5-7]。通过整合卷积神经网络、循环神经网络和注意力机制,许多新模型 [8-10] 产生了更好的性能。
尽管如此,在现实场景中,场景文本经常受到各种类型的扭曲,例如透视扭曲和弯曲文本(如图 1 所示),这增加了识别的难度。纠正文本图像是解决此问题的一种很有前途的解决方案。空间变换网络(STN)[11]首先被提出用于一般对象校正,包括平移、缩放和旋转。刘等人。 [12]采用这种仿射变换来纠正不规则的文本图像,从而降低识别任务的难度。然而,场景文本图像的失真更为复杂。最近的方法研究更灵活有效的整改。例如,Shi 等人。 [13] 使用了一系列控制点并应用 ThinPlate 样条线变换 [14]。罗等人。 [15] 通过在没有任何几何约束的情况下预测图像每个部分的偏移量来校正失真图像。詹等人。 [16] 采用一种新颖的线条拟合变换来估计文本行的姿态。这些方法表明,整改机制还有很大的改进空间。
To this end, we take the advantage of the basic design of STN and improve the rectification flexibility by applying STN on di- vided image patches, rather than on the whole image. The idea is borrowed from the algorithm of Riemann Integral [17] , where the area of a curved trapezoid is calculated by a series of rect- angles. We divide the text image into several patches and apply STN on each patch to fit the curve shape of the text. As the text is sequence-like objects [7] , we apply the transformation sequen- tially. Therefore, the rectification is named as “Sequential Trans- formation (ST)”. Moreover, in the ST, we propose a grid projec- tion that appropriately organizes several predicted transformation to enable a smooth transformation.
为此,我们利用 STN 的基本设计,通过将 STN 应用于分割的图像块而不是整个图像来提高校正灵活性。 这个想法是从黎曼积分算法[17]中借用的,其中弯曲梯形的面积由一系列矩形计算。 我们将文本图像分成几个补丁,并在每个补丁上应用 STN 以适应文本的曲线形状。 由于文本是类似序列的对象 [7],我们按顺序应用转换。 因此,整流被命名为“顺序变换(ST)”。 此外,在 ST 中,我们提出了一个网格投影,它适当地组织了几个预测的转换以实现平滑的转换。
In this paper, we introduce a Sequential Transformation Attention-based Network (STAN), which consists of a Sequential Transformation and an Attention-based Recognizer (AR). Given an text image, the ST rectifies the text into a more regular shape. Then the AR takes the rectified image as input and predicts the text string using attention mechanism [18] .
在本文中,我们介绍了一个基于序列转换注意力的网络(STAN),它由一个序列转换和一个基于注意力的识别器(AR)组成。 给定文本图像,ST 将文本纠正为更规则的形状。 然后 AR 将校正后的图像作为输入,并使用注意力机制 [18] 预测文本字符串。 我们工作的贡献总结如下
The contributions of our work are summarized as follows
We propose a Sequential Transformation Attention-based Net- work (STAN) for general text recognition. The STAN comprises a sequential transformation (ST) and an attention-based recog- nizer (AR). Taking decomposition as the key idea, we achieve complex transformation by applying several simple transfor- mations. Therefore, the ST is flexible to rectify irregular scene text images into regular ones, which are more readable for the AR.
•We propose a grid projection method to smooth the sequen- tial transformation. Thus, several predicted rectifications can be organized appropriately to achieve a smooth transformation.
•The ST is optimized in an end-to-end weakly supervised man- ner, requiring only images and corresponding ground truth text. Experiments on several benchmarks demonstrate state- of-the-art performance of STAN on both regular and irregular text.
我们提出了一种用于一般文本识别的顺序转换基于注意力的网络(STAN)。 STAN 包括一个顺序变换(ST)和一个基于注意力的识别器(AR)。 以分解为关键思想,我们通过应用几个简单的转换来实现复杂的转换。 因此,ST 可以灵活地将不规则的场景文本图像纠正为规则的图像,这对 AR 来说更具可读性。
•我们提出了一种网格投影方法来平滑顺序变换。 因此,可以适当地组织几个预测的校正以实现平滑的转换。
• ST 以端到端弱监督的方式进行优化,只需要图像和相应的地面实况文本。 在几个基准上的实验证明了 STAN 在规则和不规则文本上的最先进性能。

二、相关工作
2.1. Scene text recognition
2.1. 场景文字识别
In the past decade, a large number of scene text recognition systems have been proposed. In the early years, most traditional methods recognized text in a bottom-up manner. They first ex- tracted hand-crafted features to localize individual characters and group them into words. Wang et al. [19,20] trained a character recognizer with the HOG descriptors [21] , then recognized char- acters of the cropped word images by a sliding window. Shi et al. [22] built an end-to-end scene text recognition system using tree- structured models. Seok et al. [23] built a recognizer using Hough forest semi-Markov conditional random fields.
在过去的十年中,已经提出了大量的场景文本识别系统。 早些年,大多数传统方法以自下而上的方式识别文本。 他们首先提取手工制作的特征来定位单个字符并将它们组合成单词。 王等人。 [19,20] 使用 HOG 描述符 [21] 训练字符识别器,然后通过滑动窗口识别裁剪后的单词图像的字符。 石等人。 [22] 使用树结构模型构建了一个端到端的场景文本识别系统。 Seok 等人。 [23] 使用霍夫森林半马尔可夫条件随机场构建了一个识别器。
These traditional text recognition systems always exhibited poor performance due to the limitation of representation capacity of the hand-crafted features. With the rapid development of neural networks [24] , many researchers have begun to adopt deep neural networks for scene text recognition. Jaderberg et al. [5] used con- volutional neural networks to extract the features from the entire word image for a 90k-word classification. However, this approach was limited to the pre-defined vocabulary. Recently, many re- searchers have treated scene text recognition as a sequence trans- lation task to overcome this limitation. For example, Shi et al. [7] proposed an end-to-end trainable network that integrates fea- ture extraction, sequence modeling and transcription into a unified framework. Inspired by the Neural Machine Translation [18] , Shi et al. [10] and Lee et al. [6] both introduced the attention mech- anism in their decoder to automatically select the informative re- gions for recognizing individual characters. With the help of the at- tention mechanism, the scene text recognition task achieved state- of-the-art performance. For example, Cheng et al. [8] proposed a focus mechanism to tackle the problem of attention drift, achiev- ing accurate alignments between feature areas and targets. How- ever, it must be trained with additional character-level bounding box annotation
由于手工特征的表示能力的限制,这些传统的文本识别系统总是表现出较差的性能。随着神经网络[24]的快速发展,许多研究人员开始采用深度神经网络进行场景文本识别。贾德伯格等人。 [5] 使用卷积神经网络从整个单词图像中提取特征,以进行 90k 单词分类。然而,这种方法仅限于预定义的词汇。最近,许多研究人员将场景文本识别视为序列翻译任务来克服这一限制。例如,Shi 等人。 [7] 提出了一个端到端的可训练网络,将特征提取、序列建模和转录集成到一个统一的框架中。受神经机器翻译 [18] 的启发,Shi 等人。 [10] 和李等人。 [6] 都在其解码器中引入了注意力机制,以自动选择用于识别单个字符的信息区域。在注意力机制的帮助下,场景文本识别任务达到了最先进的性能。例如,Cheng 等人。 [8] 提出了一种聚焦机制来解决注意力漂移问题,实现特征区域和目标之间的精确对齐。然而,它必须用额外的字符级边界框注释进行训练。
2.2. Irregular scene text recognition
不规则场景文字识别
In real-world scenarios, scene text often suffers from various types of distortions, which increase the challenge of scene text recognition. The aforementioned methods mainly work on regu- lar scene text recognition, and can not be generalized to irregu- lar scene text well. Recently, the research of irregular scene text recognition becomes popular. Cheng et al. [9] introduced an ar- bitrary orientation network to recognize arbitrarily oriented texts. Yang et al. [25] introduced an auxiliary dense character detec- tor to enhance visual representation learning and an alignment loss to guide the training of an attention model. The model is able to accurately extract character features and ignore re- dundant background information. However, it requires additional character-level annotation for training, which is resource consum- ing. Liu et al. [26] introduced a novel hierarchical attention mech- anism to detect and rectify individual characters, and fed them into a character-level classifier. Their method can recognize text with distortion; however, it fails when handling blurry text im- ages. Liu et al. [27] guided the feature maps of the original im- age toward that of the clean image to reduce recognition diffi- culty. Their method can handle text with severe geometric dis- tortion; however, it fails in the text with low resolution. Both Li et al. [28] and Liao et al. [29] recognized scene text from a two-dimensional perspective to achieve better results. Compared with one-dimensional text recognition methods, two-dimensional methods are more time-consuming in the process of feature extraction.
在现实场景中,场景文本经常受到各种类型的扭曲,这增加了场景文本识别的挑战。上述方法主要适用于规则场景文本识别,不能很好地推广到不规则场景文本。最近,不规则场景文本识别的研究开始流行起来。程等人。 [9] 引入了一个任意方向网络来识别任意方向的文本。杨等人。 [25] 引入了一个辅助密集字符检测器来增强视觉表示学习和一个对齐损失来指导注意力模型的训练。该模型能够准确提取字符特征并忽略冗余背景信息。然而,它需要额外的字符级注释进行训练,这是资源消耗。刘等人。 [26] 引入了一种新颖的分层注意机制来检测和纠正单个字符,并将它们输入到字符级分类器中。他们的方法可以识别失真的文本;然而,它在处理模糊文本图像时失败。刘等人。 [27]将原始图像的特征图导向干净图像的特征图,以降低识别难度。他们的方法可以处理严重几何失真的文本;但是,它在分辨率低的文本中失败。 Li等人。 [28] 和廖等人。 [29] 从二维角度识别场景文本以达到更好的效果。与一维文本识别方法相比,二维方法在特征提取过程中更加耗时。
The rectification-based method is one of the main approaches to solve the problem of irregular scene text recognition, which has been widely studied. For example, Liu et al. [12] employed an affine transformation network to modify rotated, slant and differ- ently scaled text into more regular text. In the real-world scenar- ios, scene text may suffer from large distortions. However, sub- ject to the inflexibility of single affine transformation, the net- work in Liu et al. [12] is unable to rectify text with large dis- tortions or text with curve distribution. Shi et al. [10,13] adopted the Thin-Plate Spline transformation [14] to model more compli- cated transformations in the scene text. Gained from Thin-Plate Spline transformation, [10,13] are more flexible to model complex distortions. However, they are both unstable to rectify text ow- ing to the limitation of regression precision of the fiducial points. Luo et al. [15] designed a rectification network that could rectify the distorted images without any geometric constraint. It recti- fied irregular text by directly regressing the offset of each part of the image without any geometric constraint, and the train- ing process is unstable, therefore a three-step training strategy was designed to achieve better results. Zhan et al. [16] employed a novel line-fitting transformation to estimate the pose of text lines in scenes. However, the estimation of line-fitting transforma- tion is difficult; therefore, an iterative rectification pipeline is re- quired to achieve a good rectification and recognition result. All the rectification-based methods mentioned above differ consider- ably in the design of text rectification network, leading to different performance of text recognition results. Our rectification network is entirely different compared to these methods. Unlike the afore- mentioned methods, we use decomposition as the key concept, and achieve complex transformation by applying several simple transformations. Compared with [12] , our method is more flexible when handling various types of distortions. Compared with [10,13] , STAN is based on affine transformation, and it does not require regressing the fiducial points. Compared with [15] , STAN is sta- ble and can be trained in an end-to-end manner. Compared with [16] , STAN dose not require iterative rectification, and can achieve a good result in one rectification. Therefore, STAN is simple yet effective.
基于校正的方法是解决不规则场景文本识别问题的主要方法之一,得到了广泛的研究。例如,刘等人。 [12] 采用仿射变换网络将旋转、倾斜和不同缩放的文本修改为更规则的文本。在现实世界的场景中,场景文本可能会受到很大的扭曲。然而,由于单一仿射变换的不灵活性,Liu 等人的网络。 [12] 无法纠正大失真的文本或曲线分布的文本。石等人。 [10,13]采用薄板样条变换[14]来模拟场景文本中更复杂的变换。从薄板样条变换中获得,[10,13] 更灵活地模拟复杂的扭曲。然而,由于基准点回归精度的限制,它们都不稳定地纠正文本。罗等人。 [15] 设计了一个矫正网络,可以在没有任何几何约束的情况下矫正失真的图像。它通过直接回归图像各部分的偏移量来纠正不规则文本,没有任何几何约束,训练过程不稳定,因此设计了三步训练策略以获得更好的效果。詹等人。 [16] 采用了一种新颖的线条拟合变换来估计场景中文本行的姿态。然而,线拟合变换的估计是困难的;因此,需要一个迭代的纠错流水线来实现良好的纠错和识别结果。上述所有基于校正的方法在文本校正网络的设计上都有很大不同,导致文本识别结果的性能不同。与这些方法相比,我们的整流网络完全不同。与上述方法不同,我们以分解为关键概念,通过应用几个简单的变换来实现复杂的变换。与[12]相比,我们的方法在处理各种类型的失真时更加灵活。与[10,13]相比,STAN基于仿射变换,不需要回归基准点。与 [15] 相比,STAN 是稳定的,可以以端到端的方式进行训练。与[16]相比,STAN不需要迭代整改,一次整改即可取得较好的效果。因此,STAN 简单而有效。
三、方法
STAN consists of two parts, the sequential transformation and the attention-based recognizer. We describe these two parts in de- tail in the following section.
STAN 由两部分组成,顺序变换和基于注意力的识别器。 我们将在下一节中详细描述这两个部分。
3.1. Sequential transformation
3.1. 顺序变换
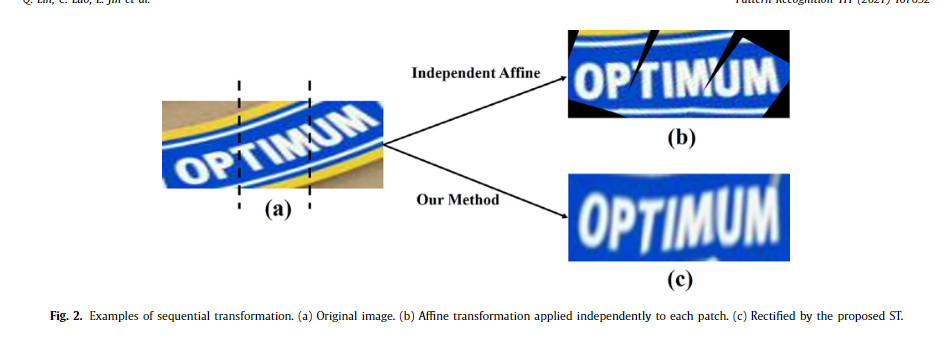
Scene text images often suffer from various types of distor- tion. It is difficult for common methods, such as affine transfor- mation, to manage such a complicated transformation, because affine transformation is limited to rotation, scaling and transla- tion. However, by separating the irregular text into several small patches, each patch is easier to be rectified. An intuitive ap- proach to implementing this idea is to divide the image into several non-overlapping patches, and then independently apply the affine transformation to these patches (possibly followed by interpolation). After using this naive method, the characters in- side each patch become horizontal. However, we found that this naive method results in severe discontinuities at the junction of neighboring patches, as shown in Fig. 2 (b). In order to achieve a smoother transformation, we design the ST, which is equipped with grid projection to smoothly transform an image as shown in Fig. 2 (c). The overall structure of ST is shown in Fig. 3 .
场景文本图像经常遭受各种类型的失真。仿射变换等常用方法很难管理如此复杂的变换,因为仿射变换仅限于旋转、缩放和平移。但是,通过将不规则文本分成几个小块,每个小块更容易被纠正。实现这个想法的一个直观方法是将图像划分为几个不重叠的补丁,然后独立地对这些补丁应用仿射变换(可能随后进行插值)。使用这种朴素的方法后,每个补丁里面的字符都变成了水平的。然而,我们发现这种朴素的方法会导致相邻补丁的连接处出现严重的不连续性,如图 2(b)所示。为了实现更平滑的变换,我们设计了ST,它配备了网格投影来平滑变换图像,如图2(c)所示。 ST的整体结构如图3所示。

Since the ST focuses on the orientation of text but not its de- tail, the input image is downsampled to (16,48) before convolu- tional layers to reduce the amount of calculation. Then a stack of convolutional layers are applied to the downsampled image to ex- tract the feature maps. Thereafter, we divide the feature maps into N patches in the horizontal direction. We decompose the transfor- mation on the feature map level instead of the image level . Com- pared with decomposition on the image level, we achieve two ben- efits. One is that every part of the transformation gains a broader receptive field that lead to more accurate transformation parame- ters and, in turn, better rectification. The other benefit is that the receptive field of neighboring patches overlaps. After decomposi- tion, each patch is followed by a localization network, which con- sists of several fully-connected layers, to predict the affine trans- formation parameters,
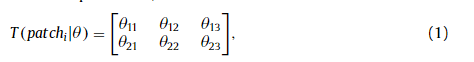
由于 ST 侧重于文本的方向而不是其细节,因此在卷积层之前将输入图像下采样到 (16,48) 以减少计算量。 然后将一堆卷积层应用于下采样图像以提取特征图。 此后,我们将特征图在水平方向上划分为 N 个补丁。 我们在特征图级别而不是图像级别上分解变换。 与图像级别的分解相比,我们实现了两个好处。 一是转换的每个部分都获得了更广泛的接受域,从而导致更准确的转换参数,进而导致更好的校正。 另一个好处是相邻补丁的感受野重叠。 分解后,每个patch后面跟着一个由几个全连接层组成的定位网络,用于预测仿射变换参数,
where θdenotes the parameters of the localization network, and patch i denotes the feature maps of i -th patch, where i traverses from 1 to N .
其中 θ 表示定位网络的参数,patch i 表示第 i 个 patch 的特征图,其中 i 从 1 到 N 遍历。
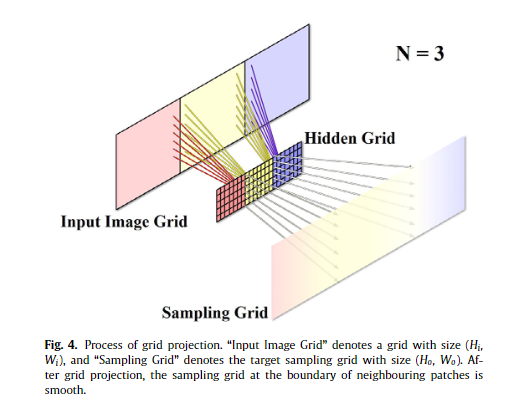
Compared with the STN method [11] which directly generates a sampling grid, we generate the sampling grid through the pro- posed grid projection mechanism. The grid projection first creates a ( m, N ×n ) hidden grid. Suppose the size of input image I is ( H i , W i ), and the size of output image I ′ is ( H o , W o ). For each coordi- nate ( x o , y o ) in the output image, we determine the corresponding pixel value of ( x i , y i ) in the input image through the hidden grid. The process of grid projection is shown in Fig. 4 , which consists of the following steps:
与直接生成采样网格的 STN 方法 [11] 相比,我们通过提出的网格投影机制生成采样网格。 网格投影首先创建一个 ( m, N ×n ) 隐藏网格。 假设输入图像I的大小为(H i , W i ),输出图像I'的大小为( H o , W o )。 对于输出图像中的每个坐标(x o ,y o ),我们通过隐藏网格确定输入图像中( x i ,y i )的对应像素值。 网格投影的过程如图4所示,包括以下步骤:
First, ( x o , y o ) is localized to the corresponding patch according to
首先,( x o , y o ) 本地化到相应的补丁根据
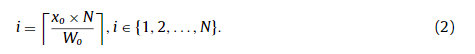
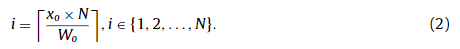
Additionally we project ( x o , y o ) to a space whose dimension is ( m, N ×n ) to obtain a hidden grid. The projection process is repre- sented as:
此外,我们将 ( x o , y o ) 投影到维度为 ( m, N ×n ) 的空间以获得隐藏网格。 投影过程表示为:
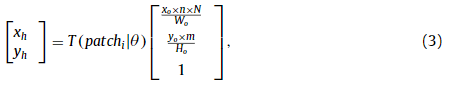
where ( x h , y h ) denotes the coordinate of hidden grid.
其中 ( x h , y h ) 表示隐藏网格的坐标。
Second, ( x h , y h ) is smoothly projected onto the input image grid whose size is ( H i , W i ) using bilinear interpolation:
其次,使用双线性插值将 ( x h , y h ) 平滑投影到大小为 ( Hi i , Wi i ) 的输入图像网格上:
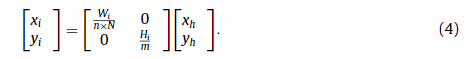
Thus, grid projection can be represented as:
因此,网格投影可以表示为:

where P denotes the grid projection function, which is computed by:
其中 P 表示网格投影函数,其计算公式为:

The sampling grid is upsampled from hidden grid using bilin- ear interpolation. After upsampling using bilinear interpolation, the values of the sampling grid at the junction of neighboring patches are weighted sums of the values of these two neighboring patches, which results in the smoothness of the sampling grid and, in turn, the continuity of transformation between neighboring patches.
采样网格是使用双线性插值从隐藏网格上采样的。 使用双线性插值进行上采样后,相邻块交点处的采样网格的值是这两个相邻块的值的加权和,从而导致采样网格的平滑性,进而导致相邻块之间变换的连续性。 补丁。
After grid projection, we generate output image I ′ by sampling from input image I . Since both x i and y i are decimals, the pixel value is sampled using bilinear interpolation,
在网格投影之后,我们通过从输入图像 I 中采样来生成输出图像 I '。 由于 x i 和 y i 都是小数,像素值使用双线性插值采样,
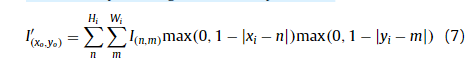
where I ′ (x o ,y o ) is the pixel value at location ( x o , y o ) of output image I ′ , and I ( n,m ) is the pixel value at location ( n, m ) of input image I .
其中 I ′ (x o ,y o ) 是输出图像 I ′ 位置 ( x o , y o ) 处的像素值, I ( n,m ) 是输入图像 I 位置 ( n, m ) 处的像素值。
Note that all the equations of (3) - (7) are differentiable. This allows ST to back-propagate the gradients. ST can be trained in a weakly supervised manner, with images and associated text labels only.
请注意,(3) - (7) 的所有等式都是可微的。 这允许 ST 反向传播梯度。 ST 可以以弱监督的方式进行训练,仅使用图像和相关的文本标签。
3.2. Attention-based recognizer
3.2. 基于注意力的识别器
We employ attention mechanism for the scene text recognizer which is designed as an encoder-decoder framework. In the en- coding stage, the encoder first extracts hierarchical features with a stack of convolutional layers. In order to improve the perfor- mance of the encoder, we employ DenseNet [30] as our feature extractor because it can strengthen feature extraction and substan- tially reduce the number of parameters simultaneously. In order to learn broader contextual information, we employ a multi-layer bidirectional L STM (BL STM) network [31] over the output features. Then we obtain a feature sequence, denoted by H = [ h 1 , h 2 , . . . , h L ] , where L is the length of the feature sequence. In the decoding stage, we use an attention-based recurrent neural network de- coder [18] to precisely align the attention regions and correspond- ing ground-truth-labels ( y 1 , y 2 , . . . , y N ). At time step t , the output y t is calculated by,
我们为场景文本识别器采用了注意力机制,它被设计为编码器-解码器框架。 在编码阶段,编码器首先用一堆卷积层提取层次特征。 为了提高编码器的性能,我们采用 DenseNet [30] 作为我们的特征提取器,因为它可以加强特征提取并同时大幅减少参数数量。 为了学习更广泛的上下文信息,我们在输出特征上采用了多层双向 L STM (BL STM) 网络 [31]。 然后我们得到一个特征序列,记为 H = [ h 1 , h 2 , ... . . , h L ] ,其中 L 是特征序列的长度。 在解码阶段,我们使用基于注意力的循环神经网络解码器 [18] 来精确对齐注意力区域和相应的真实标签 (y 1 , y 2 , . . . , y N )。 在时间步 t ,输出 y t 由下式计算,

where s t is the hidden state at time step t , computed by
其中 s t 是时间步 t 处的隐藏状态,计算公式为

where RNN represents a recurrent network (e.g. LSTM [32] ), and g t represents the weighted sum of sequential feature vectors,
其中 RNN 表示循环网络(例如 LSTM [32]),g t 表示序列特征向量的加权和,

where αt,i denotes a vector of attention weights,
其中 αt,i 表示注意力权重向量,
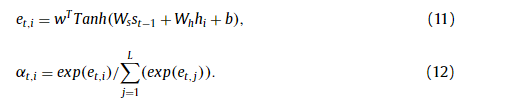
Above, W, w, W s , W h and b are all trainable parameters. The attention model is optimized with a frame-wise loss,
上面,W、w、W s 、W h 和 b 都是可训练的参数。 注意模型通过逐帧损失进行优化,

here I and y t denote the input and ground truth of the t th char- acter, respectively.
这里 I 和 y 分别表示第 t 个字符的输入和真实情况。
idirectional decoder The bidirectional attention decoder was first introduced in Shi et al. [13] to leverage dependencies in both directions. The bidirectional decoder consists of two decoders in opposite directions. One decoder reads the characters from left to right and the other from right to left. By merging the output of the two directions, the decoder achieves robust performance, which leads to better classifier performance. The total loss is the average of the losses of the left-to-right decoder and right-to-left decoder,
双向注意力解码器双向注意力解码器是在 Shi 等人中首次引入的。 [13] 在两个方向上利用依赖关系。 双向解码器由两个方向相反的解码器组成。 一个解码器从左到右读取字符,另一个从右到左读取字符。 通过合并两个方向的输出,解码器实现了稳健的性能,从而获得更好的分类器性能。 总损失是从左到右解码器和从右到左解码器的损失的平均值,
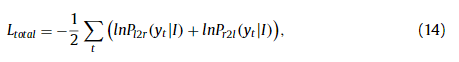
During inference, we select the outputs of the bidirectional de- coder with the highest prediction score as our final result. The pre- diction score is the mean value of the log-softmax scores of all predicted symbols
在推理过程中,我们选择具有最高预测分数的双向解码器的输出作为我们的最终结果。 预测分数是所有预测符号的 log-softmax 分数的平均值
四、实验
4.1 数据集
We trained our model on 8-million synthetic data released by Jaderberg et al. [5] and 6-million synthetic data released by Gupta et al. [33] . Thereafter we evaluated STAN on the following public benchmarks using word accuracy.
我们在 Jaderberg 等人发布的 800 万个合成数据上训练了我们的模型。 [5] 和 Gupta 等人发布的 600 万合成数据。 [33]。 此后,我们使用词准确率在以下公共基准上评估了 STAN。
•IIIT5K-Words (IIIT5K) [34] contains 30 0 0 cropped word images for testing. These images are all collected from the Internet.
•Street View Text (SVT) [19] was collected from the Google Street View, consisting of 647 word images in its test set. Many images are severely corrupted by noise and blur, or have very low resolutions.
•ICDAR 2003 (IC03) [35] contains 251 scene images that are labeled with text bounding boxes. For a fair comparison, we discarded images that contain non-alphanumeric characters or those with less than three characters, following Wang et al. [19] . The filtered dataset contains 867 cropped images.
•ICDAR 2013 (IC13) [36] inherits most of its samples from IC03. It contains 1015 cropped text images.
•SVT-Perspective (SVTP) [37] contains 639 cropped images for testing. Images are selected from side-view angle snapshots in Google Street View. Therefore most of them are perspective dis- torted.
•CUTE [38] contains 80 high-resolution images taken in natural scenes. It was specifically collected for evaluating the perfor- mance of curve text recognition. It contains 288 cropped natu- ral images for testing.
•ICDAR 2015(IC15) [39] contains 2077 cropped images including more than 200 irregular text.
•IIIT5K-Words (IIIT5K) [34] 包含 30 0 0 个用于测试的裁剪单词图像。这些图片都是从网上收集的。
•街景文本(SVT)[19] 是从谷歌街景中收集的,由其测试集中的647 个单词图像组成。许多图像被噪声和模糊严重破坏,或者分辨率非常低。
•ICDAR 2003 (IC03) [35] 包含 251 个用文本边界框标记的场景图像。为了公平比较,我们按照 Wang 等人的方法丢弃了包含非字母数字字符或少于三个字符的图像。 [19]。过滤后的数据集包含 867 个裁剪图像。
•ICDAR 2013 (IC13) [36] 继承了IC03 的大部分样本。它包含 1015 个裁剪的文本图像。
•SVT-Perspective (SVTP) [37] 包含 639 个裁剪图像用于测试。图像是从 Google 街景中的侧视图角度快照中选择的。因此,它们中的大多数是透视扭曲的。
•CUTE [38] 包含 80 张在自然场景中拍摄的高分辨率图像。它是专门为评估曲线文本识别的性能而收集的。它包含 288 张裁剪的自然图像用于测试。
•ICDAR 2015(IC15) [39] 包含 2077 个裁剪图像,其中包括 200 多个不规则文本。
4.2、实现细节
Network We set the input image size of ST to (64, 192) to main- tain a high resolution before rectification, and then downsample the input image to a low resolution (16, 48) before applying the convolutional layers of ST to reduce the amount of calculation. The ST consists of 6 convolutional layers with kernel size 3 ×3, and the third and fifth convolutional layers are followed by a 2 ×2 max-pooling layer. The numbers of output filters in the convolu- tional layers are 32, 64, 128, 256, 256 and 256, respectively. The localization network consists of two fully-connected layers to pre- dict the transformation parameters. The number of hidden units of the first fully-connected layer are 256. We found that three affine transformations could handle most types of distortion, so the patch number N is set to 3. We further discuss the effect of parame- ter N in the following. We set the size of the hidden grid to (8, 3 ×8). ST outputs images of size (32, 100) which is the input size of AR. Namely, H in = 64 , W in = 192 , H out = 32 , W out = 100 , m = 8 , n = 8 and N = 3 .
网络 我们将 ST 的输入图像大小设置为 (64, 192) 以在整流前保持高分辨率,然后在应用 ST 的卷积层以减少输入图像之前将输入图像下采样到低分辨率 (16, 48)计算量。 ST 由 6 个卷积层组成,内核大小为 3 ×3,第三和第五个卷积层后跟一个 2 ×2 的最大池化层。卷积层中输出滤波器的数量分别为 32、64、128、256、256 和 256。定位网络由两个全连接层组成,用于预测变换参数。第一个全连接层的隐藏单元数为 256。我们发现三个仿射变换可以处理大多数类型的失真,因此补丁数 N 设置为 3。我们进一步讨论参数 N 在下列的。我们将隐藏网格的大小设置为 (8, 3 ×8)。 ST 输出大小为 (32, 100) 的图像,这是 AR 的输入大小。即,H in = 64,W in = 192,H out = 32,W out = 100,m = 8,n = 8 和 N = 3。
Since the DenseNet [30] can strengthen the performance of fea- ture extraction, and reduce the number of parameters, we em- ploy DenseNet as our feature extractor. Before entering the first dense block, a 5 ×5 convolutional layer with 64 output chan- nels is performed on the rectified images, and followed by a 2 ×2 max pooling layer. Then the feature maps are entered to four dense blocks. Each dense blocks consists of several dense units. Each dense unit consists of a 1 ×1 convolution followed by 3 ×3 convolution to reduce network parameters. The numbers of dense units in each block are 6, 8, 8 and 10, respectively, and the growth rate is set to 32. We use 1 ×1 convolution followed by 2 ×2 average pooling as transition layers between two contiguous dense blocks, and the stride of average pooling layer are 2 ×2, 2 ×1 and 2 ×1, respectively. The transition layer reduces the number of feature maps of each block by half. Details of DenseNet can refer to [30] . Finally, a 2 ×2 convolutional layer with stride 1 ×1 and no padding is employed to generate a feature map whose height is 1. Each convolutional layer is followed by a batch normalization layer and ReLU layer. Although the feature extractor consists of many convolutional layers, each layer only comprises a small number of parameters. The number of parameters of the feature extractor is almost half of the ResNet-based feature extrac- tor which is used in Shi et al. [13] , while the performance is bet- ter. The convolutional feature extractor is followed by two BLSTMs, each with 256 hidden units. The decoder are attentional LSTMs. The numbers of attention units and hidden units are both 256. Batch normalization [40] is used after every convolutional layer. The AR can classify 37 classes, including 26 letters, 10 digits and 1 EOS symbol
由于 DenseNet [30] 可以增强特征提取的性能,并减少参数数量,我们采用 DenseNet 作为我们的特征提取器。在进入第一个密集块之前,对校正后的图像执行具有 64 个输出通道的 5 × 5 卷积层,然后是 2 × 2 最大池化层。然后将特征图输入到四个密集块中。每个密集块由几个密集单元组成。每个密集单元由 1 × 1 卷积和 3 × 3 卷积组成,以减少网络参数。每个块中密集单元的数量分别为 6、8、8 和 10,增长率设置为 32。我们使用 1×1 卷积和 2×2 平均池化作为两个连续密集块之间的过渡层,平均池化层的步长分别为2×2、2×1和2×1。过渡层将每个块的特征图数量减少了一半。 DenseNet的细节可以参考[30]。最后,采用步长为 1 ×1 且无填充的 2 ×2 卷积层生成高度为 1 的特征图。每个卷积层之后是批归一化层和 ReLU 层。尽管特征提取器由许多卷积层组成,但每一层仅包含少量参数。特征提取器的参数数量几乎是 Shi 等人使用的基于 ResNet 的特征提取器的一半。 [13] ,而性能更好。卷积特征提取器后面是两个 BLSTM,每个都有 256 个隐藏单元。解码器是注意力 LSTM。注意单元和隐藏单元的数量都是 256。在每个卷积层之后使用批量归一化 [40]。 AR 可以分类 37 个类别,包括 26 个字母、10 个数字和 1 个 EOS 符号
Training detail The model is trained in an end-to-end manner from scratch. We train our model using the ADADELTA [41] opti- mization method. No extra data are used. As suggested in Shi et al. [13] , the learning rate is set to 1.0 initially and decayed to 0.1 and 0.01 at step 0.6 M and 0.8 M respectively. Although the learning rate in ADADELTA [41] is adaptive, we find that decreased learn- ing rate contributes to better convergence. To stabilize training, the learning rate of ST is set to 0.1 times that of the base learning rate.
Weight initialization We initialize the parameters of all layers randomly, except for the last fully-connected layer of ST. We set the weights of this layer to zeros and the bias to [1,0,0,0,1,0] so that the rectified image I ′ is identical to the input image at the beginning of training. We find that this initialization scheme can facilitate network training.
Computational costs Our model is trained on a single NVIDIA GTX-1080Ti GPU. It takes approximately 2.2 ms for training with a batch-size of 64 and 15 ms for testing with a batch-size of 1.
训练细节 从头开始以端到端的方式训练模型。我们使用 ADADELTA [41] 优化方法训练我们的模型。不使用额外的数据。正如 Shi 等人所建议的那样。 [13],学习率最初设置为 1.0,并在步长 0.6 M 和 0.8 M 时分别衰减到 0.1 和 0.01。尽管 ADADELTA [41] 中的学习率是自适应的,但我们发现降低的学习率有助于更好的收敛。为了稳定训练,ST 的学习率设置为基础学习率的 0.1 倍。
权重初始化我们随机初始化所有层的参数,除了 ST 的最后一个全连接层。我们将此层的权重设置为零,将偏差设置为 [1,0,0,0,1,0],以便校正后的图像 I' 与训练开始时的输入图像相同。我们发现这种初始化方案可以促进网络训练。
计算成本 我们的模型是在单个 NVIDIA GTX-1080Ti GPU 上训练的。批量大小为 64 的训练大约需要 2.2 毫秒,批量大小为 1 的测试需要 15 毫秒。
4.3. Ablation studies 4.3. 消融研究
4.3.1. Effect of ST
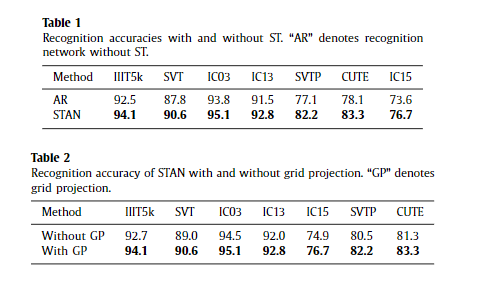
Before comparing our method with other recognition methods, we conduct an ablation study, shown in Table 1 , to evaluate the ef- fectiveness of ST. The first experiment in Table 1 is conducted only with the AR, with no rectification performed. The second experi- ment is our method, where ST is added to the bottom of the AR to rectify the input images. As shown in Table 1 , the model with ST performs significantly better on all datasets, particularly SVTP (5.1%) , CUTE (5.2%) , and IC15 (3.1%) . Since these three datasets contain numerous examples of irregular text, the results indicate that the ST performs remarkably in rectifying irregular text. Note that the ST can slightly improves the performance on regular text datasets, because there exists a few irregular text images in these datasets. With respect to the regular text images, the ST may just perform approximately identical transformation
在将我们的方法与其他识别方法进行比较之前,我们进行了表 1 所示的消融研究,以评估 ST 的有效性。 表 1 中的第一个实验仅使用 AR 进行,未进行任何整流。 第二个实验是我们的方法,其中将 ST 添加到 AR 的底部以校正输入图像。 如表 1 所示,带有 ST 的模型在所有数据集上的表现都明显更好,尤其是 SVTP (5.1%)、CUTE (5.2%) 和 IC15 (3.1%)。 由于这三个数据集包含大量不规则文本的示例,结果表明 ST 在纠正不规则文本方面表现出色。 请注意,ST 可以稍微提高常规文本数据集的性能,因为这些数据集中存在一些不规则的文本图像。 对于常规文本图像,ST 可以只进行近似相同的变换
4.3.2. Effect of grid projection
网格投影的效果
We further discuss the effect of the proposed grid projection in this section. For STAN without grid projection, we directly gen- erate a sampling grid with its corresponding affine transformation parameters, and then sample from input image with the sampling grid. The effect of grid projection is visualized in Fig. 5 . As shown in Fig. 5 (b), STAN without grid projection may produce images that appear jaggy at the junction of neighboring patches, whereas STAN with grid projection is able to alleviate the problem. As shown in Fig. 5 (c), the images rectified by STAN with grid projection are much smoother. We further compare the recognition accuracy of STAN with and without grid projection, as shown in Table 2 . STAN with grid projection outperforms that without grid projection on all datasets.
我们将在本节中进一步讨论所提出的网格投影的效果。 对于没有网格投影的STAN,我们直接生成一个采样网格及其对应的仿射变换参数,然后用采样网格从输入图像中进行采样。 网格投影的效果如图5所示。 如图 5(b)所示,没有网格投影的 STAN 可能会产生在相邻块的交界处出现锯齿状的图像,而带有网格投影的 STAN 能够缓解这个问题。 如图 5(c)所示,STAN 用网格投影校正的图像更加平滑。 我们进一步比较了有和没有网格投影的STAN的识别精度,如表2所示。 带有网格投影的 STAN 在所有数据集上都优于没有网格投影的 STAN。

Q. Lin、C. Luo、L. Jin 等。 模式识别 111 (2021) 107692 图 5. 网格投影的效果。 (a) 原始图像。 (b) 在没有网格投影的情况下进行整流。 (c) 用网格投影校正。 不光滑的区域用红色椭圆标记。 (为了解释这个图例中对颜色的引用,读者可以参考本文的网络版本。)
4 .3.3. Effect of patch number
补丁号的影响
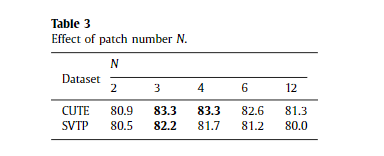
We discuss patch number N in this section. After a stack of con- volutional layers, we obtain a feature map of size (4,12). N is set to 2, 3, 4, 6, or 12 to demonstrate its effect on the recognition re- sults. The results are listed in Table 3 . We find that STAN with N = 3 performs best, while STAN with other settings has slight de- crease. Since there are numerous curve text images in CUTE, STAN with N = 2 is unstable to handle such curve text, which leads to a worse recognition result.
我们在本节讨论补丁号 N。 在一堆卷积层之后,我们获得了一个大小为 (4,12) 的特征图。 N 设置为 2、3、4、6 或 12 以证明其对识别结果的影响。 结果列于表3中。 我们发现 N = 3 的 STAN 表现最好,而其他设置的 STAN 略有下降。 由于CUTE中有大量曲线文字图像,N=2的STAN处理这样的曲线文字是不稳定的,导致识别结果更差。
4.4. Comparisons with other rectification methods
4.4. 与其他整流方法的比较
Affine transformation Liu et al. [12] conducted STAR-Net using affine transformation. For a fair comparison, we only replace the affine transformation network of STAR-Net with ST, and keep the recognition network unperturbed. A direct comparison of results is provided in Table 4 . The ST outperforms the affine transforma- tion network on all datasets listed in Table 4 , which demonstrates the superiority of ST. As shown in the second row of Fig. 6 , affine transformation can only deal with slight distortion, and it is too difficult to rectify text with large distortion, particularly the curve text. However, STAN is adequately robust to rectify text with a small curve angle. Furthermore, redundant noise is eliminated by ST. This shows that our ST is more capable and flexible than the affine transformation network in handling complicated distortion.
仿射变换 Liu 等人。 [12] 使用仿射变换进行 STAR-Net。 为了公平比较,我们仅将 STAR-Net 的仿射变换网络替换为 ST,并保持识别网络不受干扰。 结果的直接比较在表 4 中提供。 ST 在表 4 中列出的所有数据集上都优于仿射变换网络,这证明了 ST 的优越性。 如图6第二行所示,仿射变换只能处理轻微的畸变,对于畸变较大的文本,尤其是曲线文本,矫正难度太大。 然而,STAN 足够健壮以纠正具有小曲线角度的文本。 此外,ST 消除了冗余噪声。 这表明我们的 ST 在处理复杂失真方面比仿射变换网络更有能力和灵活性。
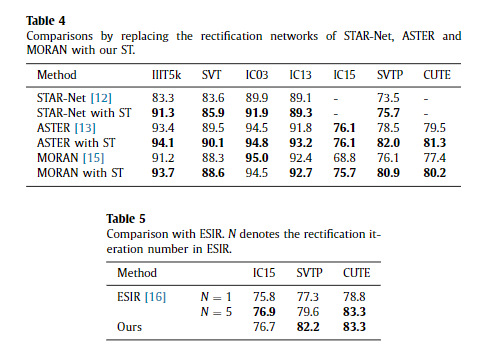
ASTER [13] adopts the Thin-Plate-Spline [14] transformation in the rectification network to handle complicated transforma- tions. We directly compare the rectification network using exactly the same recognition network proposed in ASTER. The results are shown in Table 4 . STAN outperforms ASTER on all datasets listed in Table 4 , which demonstrates the superiority of STAN.
ASTER [13] 在整流网络中采用 Thin-Plate-Spline [14] 变换来处理复杂的变换。 我们使用与 ASTER 中提出的完全相同的识别网络直接比较了整流网络。 结果如表4所示。 STAN 在表 4 中列出的所有数据集上均优于 ASTER,这证明了 STAN 的优越性。
ASTER and our method have different benefits and drawbacks. ASTER rectifies images based on fiducial points, therefore, it can tightly bound the text in the image if the fiducial points can be precisely located. However, if the fiducial points are regressed in- correctly, ASTER may incompletely crop a text region from the text image. This leads to information loss of text, and hence, poor per- formance in recognition.
ASTER 和我们的方法有不同的优点和缺点。 ASTER基于基准点对图像进行校正,因此,如果能够精确定位基准点,则可以将图像中的文本紧密绑定。 但是,如果基准点回归不正确,ASTER 可能会不完全地从文本图像中裁剪文本区域。 这会导致文本信息丢失,从而导致识别性能不佳。
As shown in Fig. 6 , both ASTER and STAN are able to handle var- ious types of distortion. Most images rectified by ASTER are more tightly-bounded than those rectified by STAN, however, it some- times may incompletely crop a text region from the text image and lead to a wrong prediction of the text sequence (as exemplified in the third row and seventh column of Fig. 6 ). Additionally, STAN generally leads to more horizontal characters than ASTER. However, both ASTER and STAN are unable to handle severely curved text.
如图 6 所示,ASTER 和 STAN 都能够处理各种类型的失真。 大多数由 ASTER 修正的图像比由 STAN 修正的图像更紧密,然而,它有时可能不完全地从文本图像中裁剪文本区域并导致对文本序列的错误预测(如第三行和 图 6 的第七列)。 此外,STAN 通常比 ASTER 产生更多的水平字符。 但是,ASTER 和 STAN 都无法处理严重弯曲的文本。
ORAN [15] rectifies irregular text by directly regressing the offset of each part of the image without any geometric constraint, which is sufficiently flexible to rectify large distortion. However, training without any geometric constraint makes it difficult for the rectification network to converge. Therefore, MORAN designs a three-step training strategy to stabilize the training process.
We directly compare the rectification network using exactly the same recognition network proposed in MORAN, and the results are listed in Table 4 . Our method outperforms MORAN on all datasets, except IC03. Furthermore, our method achieves considerable re- sults on irregular datasets. For instance, our method outperforms MORAN with an accuracy increase of 2.8% on CUTE, 4.8% on SVTP and 6.9% on IC15. Note that our method is end-to-end trainable. As shown in Fig. 6 , both MORAN and STAN are able to handle var- ious types of distortion, and the images rectified by our method appears more horizontal than those of MORAN.
ORAN [15] 通过直接回归图像每个部分的偏移量来纠正不规则文本,没有任何几何约束,这对于纠正大的失真来说足够灵活。然而,没有任何几何约束的训练使得整流网络难以收敛。因此,MORAN 设计了三步训练策略来稳定训练过程。
我们使用与 MORAN 中提出的完全相同的识别网络直接比较了整流网络,结果如表 4 所示。除了 IC03,我们的方法在所有数据集上都优于 MORAN。此外,我们的方法在不规则数据集上取得了可观的结果。例如,我们的方法优于 MORAN,在 CUTE 上准确度提高了 2.8%,在 SVTP 上提高了 4.8%,在 IC15 上提高了 6.9%。请注意,我们的方法是端到端可训练的。如图 6 所示,MORAN 和 STAN 都能够处理各种类型的失真,并且通过我们的方法校正的图像看起来比 MORAN 的图像更水平。
ESIR [16] designed a novel line-fitting transformation to model the pose of scene texts and correct perspective and curvature dis- tortions for better scene text recognition. We compare the results of STAN and ESIR in Table 5 . As shown in the table, we achieve comparable results on the three irregular datasets. It is worth men- tioning that ESIR needed to rectify the irregular text images several times to achieve a good result, whereas our method can achieve a good result in one rectification. When both methods only rectify the irregular text images once, our method achieves convincing results on the three irregular datasets. The significant improvement on the SVTP dataset (2.6%) which contains many low resolution images reveals the generality of our method.
To further verify the superiority of our rectification network, we fix the recognition module across different methods, and evaluate the rectification module of STAR-Net [12] , ASTER [13] and MORAN [15] in Table 6 . We use the recognition network proposed in Shi et al. [13] , which is an attention-based recognition network. As shown in Table 6 , our rectification method achieves the best re- sults among these rectification-based methods on the three irreg- ular datasets, which shows the superiority of our method.
ESIR [16] 设计了一种新颖的线拟合变换来模拟场景文本的姿态,并纠正透视和曲率失真,以更好地识别场景文本。我们在表 5 中比较了 STAN 和 ESIR 的结果。如表所示,我们在三个不规则数据集上取得了可比较的结果。值得一提的是,ESIR 需要对不规则的文本图像进行多次校正才能达到较好的效果,而我们的方法一次校正即可达到较好的效果。当两种方法只对不规则文本图像进行一次校正时,我们的方法在三个不规则数据集上都取得了令人信服的结果。包含许多低分辨率图像的 SVTP 数据集 (2.6%) 的显着改进揭示了我们方法的通用性。
为了进一步验证我们的整流网络的优越性,我们修复了不同方法的识别模块,并在表 6 中评估了 STAR-Net [12]、ASTER [13] 和 MORAN [15] 的整流模块。我们使用 Shi 等人提出的识别网络。 [13],这是一个基于注意力的识别网络。如表 6 所示,我们的整流方法在三个不规则数据集上取得了这些基于整流的方法中最好的结果,这显示了我们方法的优越性。

来自 STAR-Net、ASTER、MORAN 和 STAN 的校正图像和识别结果。 真实情况和预测结果列在其各自的图像下方。 基本事实以绿色标记,识别错误以红色标记。 ASTER 1 和 MORAN 2 的代码和模型由 Shi 等人发布。 [13] 和罗等人。 [15] , 分别


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧