

(二)主动学习—以阿里巴巴淘系为例
前言
在大数据和算力的助力下,深度学习掀起了一波浪潮,在许多领域取得了显著的成绩。以监督学习为主的深度学习方法,往往期望能够拥有大量的标注样本进行训练,模型能够学到更多有价值的知识(如下左图展示了3组常见的图像分类数据集,拥有上万的标注样本)。
然而,实际应用场景的标注样本严重稀缺。并且,标注大量样本将产生昂贵的标注成本(如下右图所示,标注一张X射线图需要5分钟和30元左右的成本,一张CT图需要20分钟和70元的成本)。

在庞大而复杂的淘系电商场景中,类似的需求比比皆是:例如,咸鱼&躺平和洋淘等社区内容的治理,拍立淘的以图搜图,服饰分类(例如,iFashion)等场景都存在标注样本严重稀缺的问题。
综上,在实际应用场景中,如何“在模型达到目标性能的前提下,尽可能地减少标注成本”是一项亟需解决的挑战。
主动学习作为机器学习的一个子领域,旨在以尽可能少的标注样本达到模型的目标性能,广泛应用于实际需求中。本文的定位是主动学习方法的入门篇,主要介绍的内容包括:1)详细地介绍主动学习的基础知识;2)简要地介绍主动学习在学术界的研究现状;3)主动学习实践部分将简单介绍几个图像分类的案例;4)文末将给出本文的参考文献和相关资料。
主动学习的基本知识:
▐ 主动学习的概念和基本流程:
✎ 主动学习是什么
Burr Settles[1] 的文章《Active Learning Literature Survey》详细地介绍了主动学习:“主动学习是机器学习的一个子领域,在统计学领域也叫查询学习或最优实验设计”。
主动学习方法尝试解决样本的标注瓶颈,通过主动优先选择最有价值的未标注样本进行标注,以尽可能少的标注样本达到模型的预期性能。
✎ 主动学习的基本流程
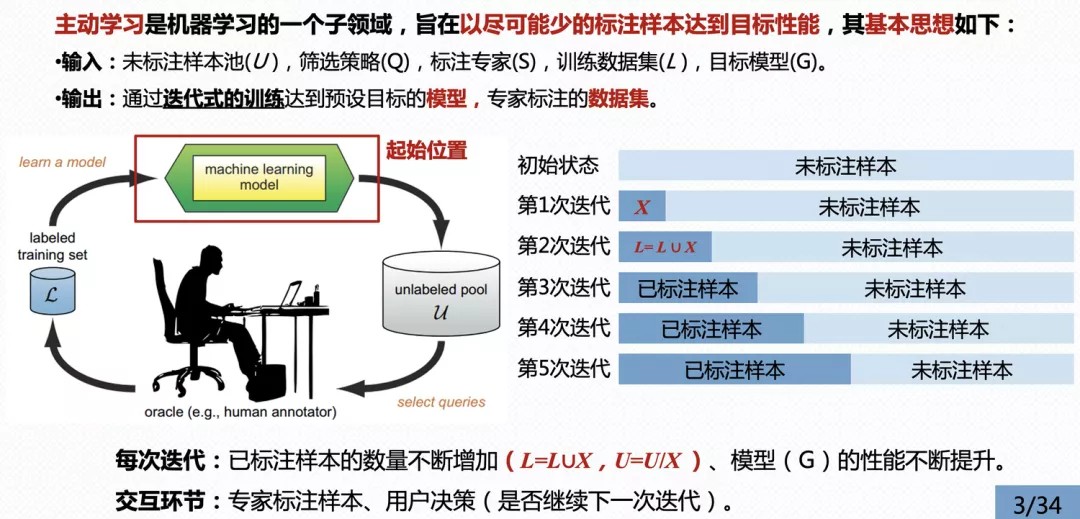
如下图所示,主动学习方法是一个迭代式的交互训练过程,主要由五个核心部分组成,包括:未标注样本池(unlabeled pool,记为U)、筛选策略(select queries,记为Q)、标注者(human annotator,记为S),标注数据集(labeled training set,记为L),目标模型(machine learning model,记为G)。
主动学习将上述五个部分组合到同一个流程中,并通过如下图所示的顺序,以不断迭代的训练方式更新模型性能、未标注样本池和标注数据集,直到目标模型达到预设的性能或者不再提供标注数据为止。
其中,在每次迭代过程中,已标注样本的数量不断增加,模型的性能也随之提升(理想情况)。在实际应用中,应尽可能保证标注者的准确率,缓解模型在训练初期学偏(此处特指错误标注的样本导致)的情况。
▐ 主动学习和被动学习、半监督学习的关系
✎ 主动学习和被动学习
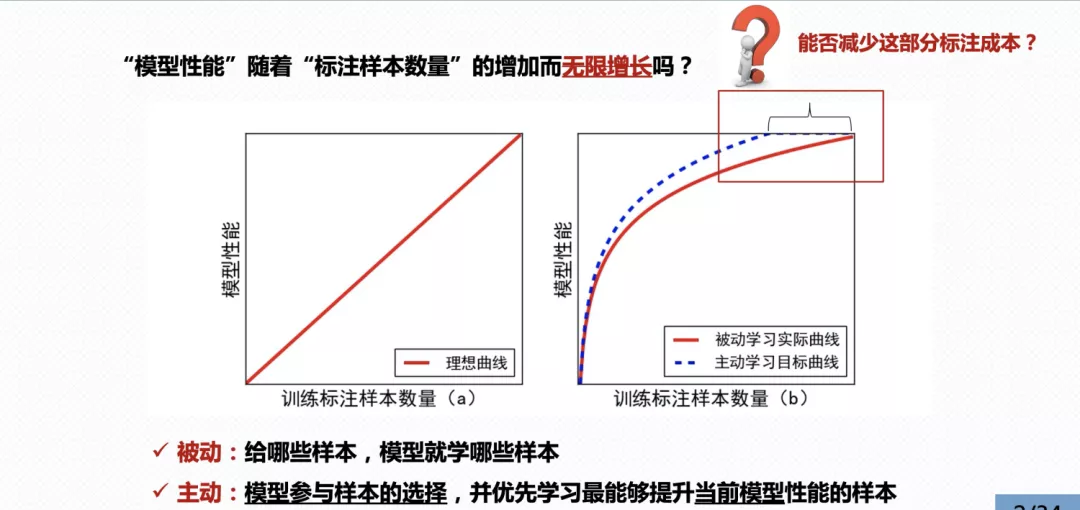
如下图(a)所示,红色实线表示理想情况下模型性能随着训练标注样本数量的增多而无限地提升。实际情况下往往是如下图(b)的红色实线所示,模型的性能不是随着标注数据量的增多而无限地提升。
此外,每个模型都会有与之对应的瓶颈性能(peak performance),研究者通过增加训练数据以及调参使之不断逼近瓶颈性能。主动学习核心解决的问题正是如何使用尽可能少的标注数据达到模型的瓶颈性能,从而减少不必要的标注成本。如下图(b)的蓝色虚线所示,主动学习根据合适的策略筛选出最具有价值的样本优先标注并给模型训练,从而以更少的标注样本达到模型的瓶颈性能。
✎ 主动学习和半监督学习
在机器学习领域中,根据是否需要样本的标签信息可分为“监督学习”和“无监督学习”。此外,同时利用未标注样本和标注样本进行机器学习的算法可进一步归纳为三类:半监督学习、直推式学习和主动学习 。
文献[21]简要介绍了主动学习与半监督学习的异同点:“半监督学习和主动学习都是从未标记样例中挑选部分价值量高的样例标注后补充到已标记样例集中来提高分类器精度,降低领域专家的工作量。“
但二者的学习方式不同:半监督学习一般不需要人工参与,是通过具有一定分类精度的基准分类器实现对未标注样例的自动标注;而主动学习有别于半监督学习的特点之一就是需要将挑选出的高价值样例进行人工准确标注。
半监督学习通过用计算机进行自动或半自动标注代替人工标注,虽然有效降低了标注代价,但其标注结果依赖于用部分已标注样例训练出的基准分类器的分类精度,因此并不能保证标注结果完全正确。
相比而言,主动学习挑选的样本是人工标注,尽可能引入最少的错误类标。值得一提的是,目前已有许多研究者尝试将主动学习和半监督学习进行结合,并取得了不错的效果。
主动学习的基本策略
样本的筛选策略直接关系到模型能够节约标注成本的程度。例如,使用不确定性策略比随机采样策略能够节约更多的标注样本[4,5] 。因为随机采样策略既没有利用到模型的预测信息,也没有利用到大量未标注样本池的结构信息,仅凭随机采样决定优先标注的样本。而不确定性策略通过与模型的预测信息进行交互,优先筛选出相对当前模型最有价值的样本。本节将围绕部分经典的筛选策略展开讨论。
1、随机采样策略(Random Sampling,RS): RS 不需要跟模型的预测结果做任何交互,直接通过随机数从未标注样本池筛选出一批样本给专家标注,常作为主动学习算法中最基础的对比实验。
2、不确定性策略(Uncertainty Strategy,US):US 假设最靠近分类超平面的样本相对分类器具有较丰富的信息量,根据当前模型对样本的预测值筛选出最不确定的样本。
US 包含了一些基础的衡量指标:
- 最不确定指标(Least Confidence,LC)将预测概率的最大值的相反数作为样本的不确定性分数。
- 边缘采样(Margin Sampling,MS)认为距离分类超平面越近的样本具有越高的不确定性,常与 SVM 结合并用于解决二分类任务,但在多分类任务上的表现不佳。
- 多类别不确定采样(Multi-Class Level Uncertainty,MCLU)是 MS 在多分类问题上的扩展,MCLU 选择离分类界面最远的两个样本,并将它们的距离差值作为评判标准。MCLU 能够在混合类别区域中筛选出最不确信度的样本,如式(2.3)所示。其中,xj 表示被选中的样本,C 表示样本 xi 所属的类别集合,c+ 表示最大预测概率对应的类别,f (xi, c) 表示样本 xi 到分类超平面的距离。
- 熵值最大化(Maximize Entropy,ME)优先筛选具有更大熵值的样本,熵值可以通过计算
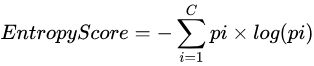
得到,其中 pi 表示第 i 个类别的预测值。
- 样本最优次优类别(Best vs Second Best, BvSB)[79]主要是针对多分类问题的一种衡量指标,并且能够缓解 ME 在多分类问题上效果不佳的情况。BvSB 只考虑样本预测值最大的两个类别,忽略了其他预测类别的影响,从而在多分类问题上的效果更佳。

3、委员会投票(Query by Committee,QBC):QBC[31]是一种基于版本空间缩减的采样策略,核心思想是优先选择能够最大程度缩减版本空间的未标记样本。
QBC 包括两个基本步骤:
- 使用多个模型构成委员会;
- 委员会中所有的模型依次对未标注样本进行预测并优先筛选出投票最不一致的样本进行标注。
由于 QBC 在实际应用的过程中需要训练若干个模型,导致具有较高的计算复杂度。基于此,熵值装袋算法(Entropy Query-By-Bagging,EQB)[80]和自适应不一致最大化(Adaptive Maximize Disagree,AMD)被提出并缓解了计算复杂度问题。其中,EQB 同时引入了 bagging 继承方法以及 bootstrap 采样;AMD 主要针对高维数据,将特征空间划分为一定数量的子集并构造委员会。
4、其他经典的策略:梯度长度期望(Expected Gradient Length,EGL) 策略根据未标注样本对当前模型的影响程度优先筛选出对模型影响最大的样本;EGL [4] 是代表性方法之一,能够应用在任意基于梯度下降方法的模型中。方差最小(Variance Reduction,VR)策略通过减少输出方差能够降低模型的泛化误差[81,82];Ji 等[82]提出了一种基于图的 VR 衡量指标的主动学习方法,通过将所有未标注样本构建在同一个图中,每个样本分布在图中每个结点上。紧接着,通过调和高斯随机场分类器直接预测未标注样本所属的标签;在优化的过程中,通过挑选一组未标注样本进行预测并获得对应的预测类别,使得未标注样本的预测类别方差最小。
▐ 主动学习的扩展方法
近年来,主动学习策略在很多实际应用场景中取得显著的效果。但同时也存在一些亟需解决的挑战。例如,不确定性策略只关注样本的不确定性,在BMAL(批量式主动学习方法,每次迭代筛选出N>1的样本数量)场景下会产生大量具有冗余信息的样本。因此,仅使用单一的策略尚未能最大程度地节约标注成本。
本节将围绕本文的核心工作简要地介绍几种主动学习的扩展方法。
1、组合多种基本策略的主动学习方法:组合策略将多个基本策略以互补的方式进行融合,广泛应用于图像分类任务中[36,37,38,83]。其中,Li 等[36]基于概率分类模型提出一种自适应的组合策略框架。Li 等[36]通过信息密度指标(Information Density Measure)将未标注样本的信息考虑在内,弥补了不确定性策略的不足。如算法 2-2所示,该算法能够自然地扩展到更多的组合策略。

2、结合半监督学习(Semi-Supervised Learning)的主动学习方法:自训练(Self-training)算法作为半监督学习的一种基础方法,其核心步骤如算法2-3所示。由于自训练算法在训练过程中会根据模型的预测信息,挑选合适的样本及其对应的预测标签加入训练集,而且初始化少量的标注样本能够保证模型的初始性能,因此初始化训练环节对其后续的学习过程至关重要。
半监督学习算法需要解决的挑战之一是:在训练的过程中容易引入大量的噪声样本,导致模型学习不到正确的信息。部分研究员们通过构建多个分类器的协同训练算法缓解噪声样本,如Co-Training[84] 和 Tri-Training[85]。

3、结合生成对抗网络的主动学习方法:生成对抗网络(Generative Adversarial Networks,GAN)模型以无监督的训练方式对大量未标注样本进行训练,并通过生成器产生新的样本。
经典的 GAN[15] 主要包括生成器和判别器等两个核心部分,两者以互相博弈的方式进行对抗训练,直到两者达到一个动态均衡的状态。GAN 的目标函数如式(2.4)所示,其中,V(G,D)=Ex∼Pdata[logD(x)]+Ex∼PG [log(1−D(x))] 表示数据真实分布 x ∼ Pdata 与生成模型得到的分布 x ∼ PG 之间的差异。文献[19,50]将生成器和主动学习策略进行融合并构建目标函数,通过解决优化问题控制生成器产生的样本。
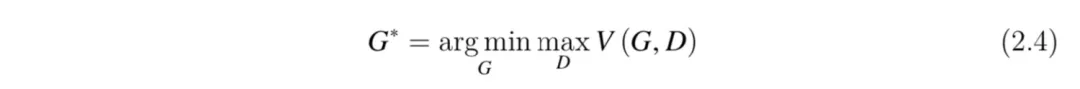
▐ 主动学习方法的基本评价指标
本文侧重介绍主动学习方法在保证不损失模型准确率的情况下,节约标注成本的性能,评价指标如下式所示。其中,SavedRate 表示主动学习方法相对于全样本训练减少的标注成本;ExpertAnnotated 表示当模型达到预定的目标性能时专家标注的样本数量;Full Samples 表示当前数据集提供的未标注样本数量,即全样本训练时所使用的标注样本数量。本文涉及的实验会先进行全样本训练,并分别记录最佳验证集准确率作为主动学习相关算法的目标准确率。
例如,在某组数据集中使用 AlexNet 模型对Full Samples张标注图像进行训练,记录训练过程中最佳的验证准确率(Best accuracy)并将其作为主动学习的目标准确率(Target accuracy);随后,模型通过迭代过程不断提升性能,当达到目标准确率时,记录专家所标注的样本数量 ExpertAnnotated;此时,就可以算出SavedRate 的值,即该方法能够节约多少标注成本。此外,我们也会将主动学习方法与一些常见的方法进行比较,比如 RS 策略常用于基准对比实验(baseline)。
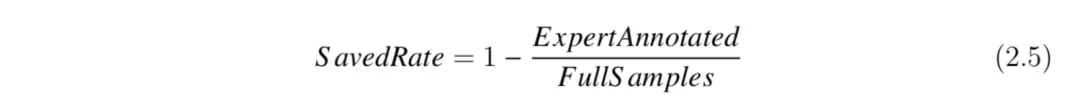
▐ 早期的主动学习面临的挑战及其解决方案
✎ 多类分类问题
在处理多类分类问题时,基于 Margin Sampling 的样例选择标准忽略了样例可能属于其他类别的信息,因此所选样例质量较差。基于熵的方法“基于不确定性的主动学习算法研究(2011)”虽考虑了样例从属于每个类别的概率,但在多类分类问题中,样例的熵也会受到那些不重要类别的干扰。
文献“Multi-class active learning for image classification(2009)”提出了基于最优标号和次优标号的准则(BvSB),考虑样例所属概率最高的前2个类别,忽略剩余类别对样例选择标准产生的干扰。
文献“基于主动学习和半监督学习的多类图像分类(2011)”将BvSB和带约束的自学习(Constrained self-training,CST)引入到基于SVM的图像分类中,显著提高了分类精度。
✎ 样本中的孤立点
若选择样例时能综合考虑样其代表性和不确定性,通常可避免采集到孤立点。
文献“Active Learning by querying informative and representative examples(2010)”中提出了一种综合利用聚类信息和分类间隔的样例选择方法;
文献“Active Learning using a Variational Dirichlet Processing model for pre-clustering and classification of underwater stereo imagery(2011)”提出了一种利用预聚类协助选择代表性样例的主动学习方法;
文献“Dual strategy active learning(2007)”利用样例的不确定性及其先验分布密度进行样例选择以获取优质样例;
文献“基于样本不确定性和代表性相结合的可控主动学习算法研究 (2009)”将样例的分布密度作为度量样例代表性的指标,结合以熵作为不确定性指标,提出了一种基于密度熵的样例选择策略,有效解决了孤立点问题给样例选择质量造成的影响。
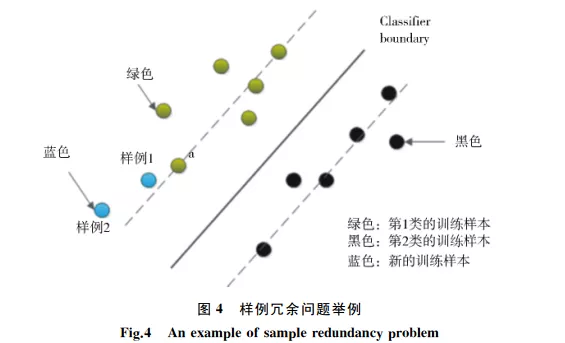
✎ 训练集样本冗余
如下图所示,蓝色圆圈所表示的新训练样本中,样例1与分类超平面的距离比样例2近,根据 BvSB 准则应当挑选样例1进行标注并补充到训练集中;但紧挨着样例1的绿色样例 a 已经在训练集中,此时若再加入样例1则对分类界面影响甚微。
相比而言,将样例2补充到训练集中,对当前分类模型的训练贡献度更大。通过上述分析可知,主动学习中的样例选择度量主要分为2种:
- 不确定性度量;
- 差异性度量或代表性度量;
样例的不确定性一般可通过计算其信息熵获得,样例的代表性通常可根据其是否在聚类中心判断,而样例的差异性则可通过计算余弦相似度(基于采样策略的主动学习算法研究进展,2012)或用高斯核函数(基于多特征融合的中文评论情感分类算法,2015)获得。
✎ 不平衡数据集
文献“一种新的SVM主动学习算法及其在障碍物检测中的应用(2009)”提出 KSVMactive 主动学习算法;文献“基于主动学习的加权支持向量机的分类(2009)”提出了改进的加权支持向量机模型;文献“基于专家委员会的主动学习算法研究(2010)”提出了基于SVM超平面位置校正的主动学习算法。
主动学习的研究现状
本节将围绕如下要点对主动学习方法的研究现状展开讨论,包括:
- 基于未标注样本池的主动学习策略;
- 批量式主动学习方法,侧重于组合式策略以及引入聚类算法的主动学习方法;
- 半监督主动学习方法;
- 结合生成对抗网络的主动学习方法。
此外,主动学习方法在近几年的进展不仅局限于上述归类的方法,本节将其总结在“其他主流的主动学习方法”(本文涉及的参考文献,都可以通过文末的参考文献提供的链接中获取)。
✎ 主动学习方法概述
主动学习作为机器学习的一个子领域,核心思想是通过一些启发式策略找到相对最具有“价值”的训练样本,使得模型能够以尽可能少的标注样本达到甚至超过预期的效果。
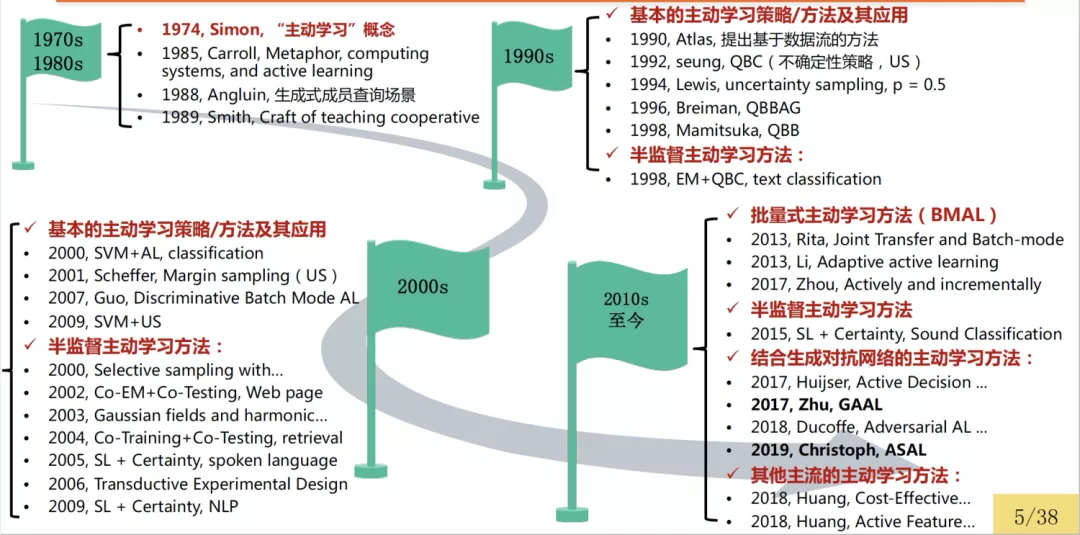
主动学习的概念是Simon[23]在1974年提出。随后,主动学习方法在许多领域中层出不穷,并进一步被归纳为生成式成员查询(Membership Query Synthesis)、流式主动学习方法(Stream-Based Selective Sampling)和基于未标注样本池的主动学习方法(Pool-Based Sampling)等经典的场景[4]。
Angluin等[24]于1988年提出了生成式成员查询场景,模型通过预设的条件控制生成新的样本并向标注专家询问标签;由于当时生成模型的能力有限,并且无法较好的控制生成所需的样本,因此这类方法的应用范围未被推广。
Atlas等[25]在1990提出了基于数据流的方法,模型按照顺序依次判断是否需要对样本进行标记。由于基于数据流的方法不需要将所有样本统一放在池中,因此适用于存储空间较小以及处理能力有限的情况(如,应用到移动设备),但存在最大的缺陷是无法获取样本的结构分布。
相较之下,基于未标注样本池的主动学习方法[26]将大量未标注样本构成未标注样本池,通过设计样本筛选策略从未标注样本池中筛选出最有“价值”的样本优先进行标注。此外,伴随着互联网的热潮以及数据采集技术的不断提升,很多领域能够以廉价的成本获取大量的未标注数据。因此,基于未标注样本池的主动学习方法最流行并且广泛应用于不同的领域中,在机器学习和数据挖掘的应用中处于非常重要的地位。
✎ 基于未标注样本池的主动学习方法
样本筛选策略的质量直接影响到基于未标注样本池的主动学习方法的效果。目前,一些手工设计策略不断被提出并应用到主动学习方法中,如不确定性策略和代表性策略。
文献[27,28]通过计算信息熵(entropy)表示最不确定的样本。文献[12,29,30]使用SVM作为目标分类器,通过选择距离支持向量最近的样本作为最不确定的样本。Seung等[31]首次提出了基于委员会的筛选算法(Query-by-Committee,QBC),首先训练了一组分类器组成委员会。紧接着,以委员投票的方式决定筛选哪个样本作为最不确定的样本。
随后,一些基于QBC的改进方法不断被提出:例如,Breiman等[32]基于Bagging提出的Query-by-Bagging(QBBAG)以及Mamitsuka等[33]基于Boosting提出的Query-by-Boosting(QBB)。
对于样本的代表性策略,文献[34,35]通过使用未标注样本的先验密度(PriorDensity)作为不确定性指标的权重,从而达到利用未标注样本的目的。Settles等[28]提出一种相似的框架,使用cosine距离衡量信息密度(InformationDensity)。
✎ 批量式主动学习(BatchModeActiveLearning,BMAL)方法
目前,大多数主动学习方法存在一个共同的问题:串行地筛选样本,即每次迭代选择一个样本进行标注,这种方式非常低效且无法满足大多数实际需求。在实际应用中,往往需要以分布式的形式并行处理,多名标注专家同时在不同的环境下标注样本。
BMAL旨在每次迭代中能够产生一批未标注样本,同时提供给多名标注者,从而极大地提升了应用效率。BMAL的发展历程中,起初,有研究尝试将很多不同的预测模型应用到不同的策略中。但他们在筛选样本时,只使用了单一的不确定性指标或者多样性指标的主动选择策略,导致所挑选的样本中存在大量的冗余信息,从而造成了额外的标注成本。
基于此,Li等[36]提出一种新颖的自适应组合式的样本筛选策略,将不确定性策略和信息密度指标进行结合。在每次迭代中,通过自适应地调整两种策略的权重,从而选择最具有“价值”的样本给专家标注,并在三组图像分类数据集上验证了所提出方法的有效性。
Gu等[37]提出了一种面向多分类的BMAL,通过组合不确定性策略和多样性策略,并在两组图像分类的数据集上进行验证,实验结果表明该方法能够挑选出同时满足最不确定性和最具多样性的样本。Zhou等[38]通过组合不确定性指标和多样性指标,同时引入了迁移学习和数据增强等技术,提出了AIFT方法并将其应用到医疗图像领域,验证了该方法至少能够减少一半的标注成本。Cardoso等[39]在传统BMAL的基础上提出了一种排序批量式主动学习方法(RBMAL),通过生成一个优化过的排序表决定样本被标注的优先级。RBMAL避免了标注专家频繁等待被选中的未标注样本,实验结果表明RBMAL能够在保证甚至提升模型性能的条件下显著地减少标注成本。此外,为了更加充分利用大量未标注样本的信息,有研究员[40,41,42]尝试将聚类算法引入主动学习中。
然而,目前大多数聚类方法都是先通过手工提取特征再聚类,在很大一定程度上局限于特征的质量。我们尝试将卷积自编码聚类算法[43]应用到BMAL中,通过将特征提取和聚类算法以端到端的形式整合到同一个模型里(本文暂不展开介绍)。从而既能够提升聚类性能,又能够利用卷积神经网络的优势处理更复杂的图像。
✎ 半监督主动学习方法
半监督学习能够在少量标注成本的情况下训练模型,通过挑选出预测结果较明确的样本并由模型直接给标签,但是容易产生噪声标签。
而主动学习则是挑选预测结果最不确定的样本给专家标注,能够保证标签质量。因此,半监督学习方法和主动学习方法的结合能够在一定程度上互补优缺。
1998年,McCallumzy等[44]首次组合了QBC和期望最大化(EM)算法,使用朴素贝叶斯方法作为分类器并在文本分类任务上进行实验。
随后,Muslea等[45]提出了一种QBC的改进方法,联合测试方法(Co-Testing),通过分别在不同视角训练的两个分类器共同筛选样本给专家标注,并将其与联合期望最大化(Co-EM)算法结合。Zhou等[46]尝试将Co-Testing和Co-Training方法进行结合并在图像检索任务中验证了算法的优势。
此外,文献[47,48,49]组合了不确定性策略和自学习方法(Self-Training)。上述方法将半监督学习和主动学习巧妙地结合,充分利用各自的优势并弥补不足,取得了显著的成绩。然而,目前的半监督主动学习方法尚未对噪声样本进行有效地处理,因此仍会对模型造成不小的影响。
✎ 结合生成对抗网络的主动学习方法
GANs对提升主动学习方法的样本筛选效率具有重要的意义。
文献[19,50]将主动学习策略结合生成器构建目标函数,通过解决优化问题使得生成器直接生成目标样本,提升了筛选样本的效率。Huijser等[20]首先使用GAN沿着与当前分类器决策边界垂直的方向生成一批样本。
紧接着,通过可视化从生成的样本中找出类别发生改变的位置,并将其加入待标注样本集。
最后,通过大量的图像分类实验验证了该方法的有效性。此外,除了图像分类任务以外,主动学习方法与GAN的结合也广泛应用到其他领域中,例如离群点检测[21]。
✎ 其他主流的主动学习方法
Huang等[51]提出一种针对深度神经网络的主动学习方法,能够用更少的标记样本将预训练好的深度模型迁移到不同的任务上,从而降低深度神经网络的学习代价。
Huang等[52]提出一种结合主动学习和矩阵补全技术的方法,能够在特征缺失严重的情况下有效利用标记信息,节省特征提取代价。
Chu等[53]认为应用在不同数据集上的主动学习策略存在有效的经验,并且这些经验可以被迁移到其他数据集中进而提升模型或者策略的性能。作者尝试将模型迁移到不同的数据集中,实验部分证明了当前大多数策略不仅存在有效的经验,而且经验能够被迁移到不同的数据集中,并提升特征学习任务的性能。
✎ NAS + Active Learning
最后,值得一提的是,考虑到上述归纳的主动学习方法中,任务模型是根据先验知识从现成的模型中筛选,即模型的网络结构是固定的。存在如下缺陷:
- 很多领域没有现成的模型可用,例如医疗图像领域;
- 在前期的迭代过程中,标注样本量较少,固定网络结构(通常会比较复杂一点)的模型可能会陷入过拟合。
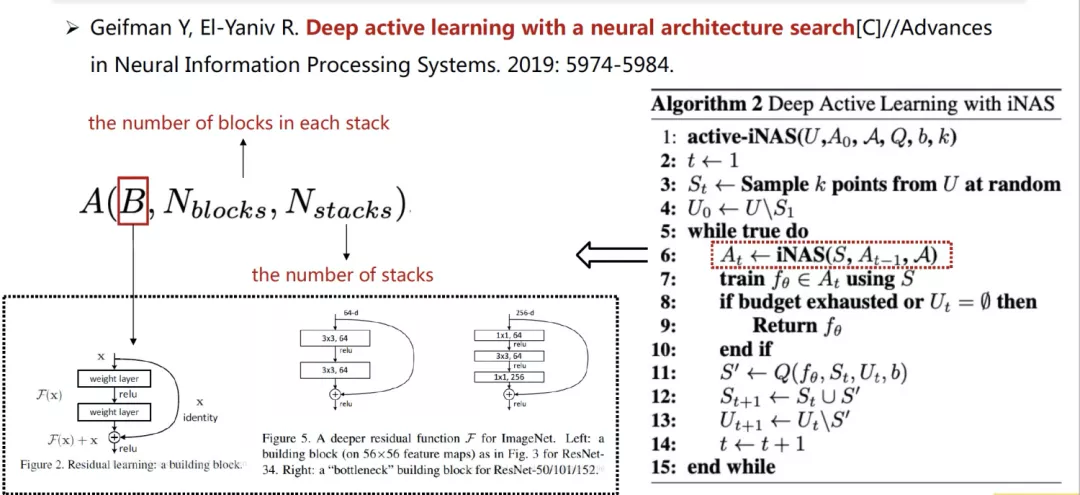
如下图所示,Geifman 等人首次尝试将NAS应用到主动学习方法中,使得模型的网络结构能够自适应新增的标注数据。实验结果表明,加入NAS后的主动学习方法的效率显著地优于固定网络结构的主动学习方法。
主动学习实践:牛刀小试
▐ 主动学习如何减少标注样本的简单案例
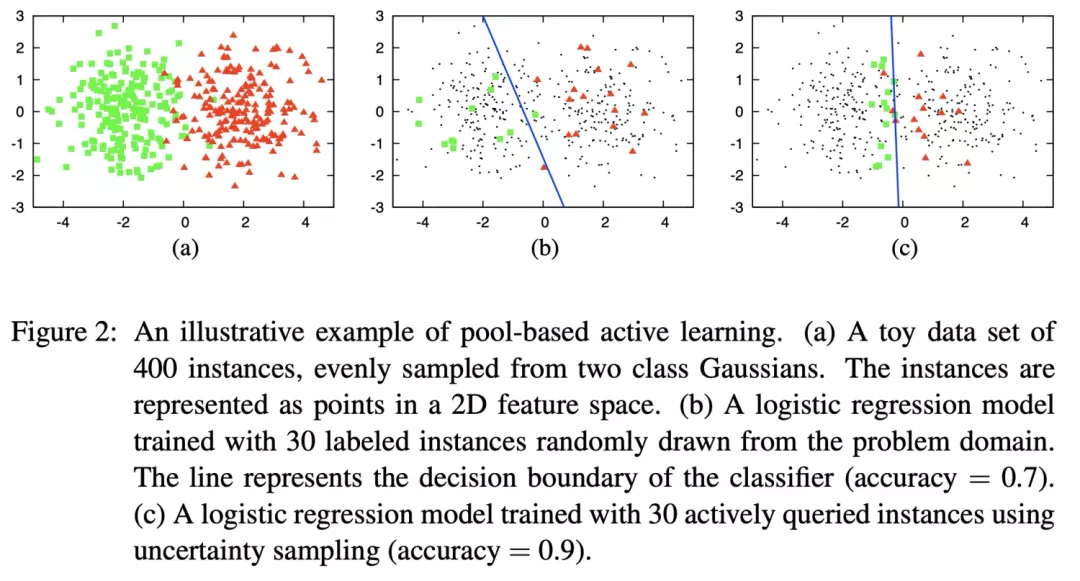
如下图所示,文献《Active Learning Literature Survey》提供了一个基于 pool-based的主动学习案例。
其中,数据集(toy data)是从高斯分布产生的400个样本,任务是2分类问题(每个类有200个样本),如(a)图所示将这些数据映射在2D特征空间上;图(b)使用了逻辑回归模型,通过训练随机选择的30个标注样本,得到70%的验证精度,蓝色线表示决策边界(decision boundary);图(c)同样使用逻辑回归模型,但训练的30个标注样本是通过主动学习策略(uncertain strategy)选择而来,达到90%的验证精度。
这个简单的案例体现了引入主动学习策略所带来的效果,使用30个标注样本能够提升20%的精度。值得注意的是,上述2分类的样本分别200个,样本数据非常平衡。但是在实际应用中,分类样本数据比例往往不能达到1:1,相关领域的研究者正在尝试解决这类问题。
▐ 图像分类数据集的实践
如算法2-1所示给出了“基于为标注样本池的主动学习方法”,本文也在第一部分详细地介绍了主动学习的基本流程,此处不再赘述。

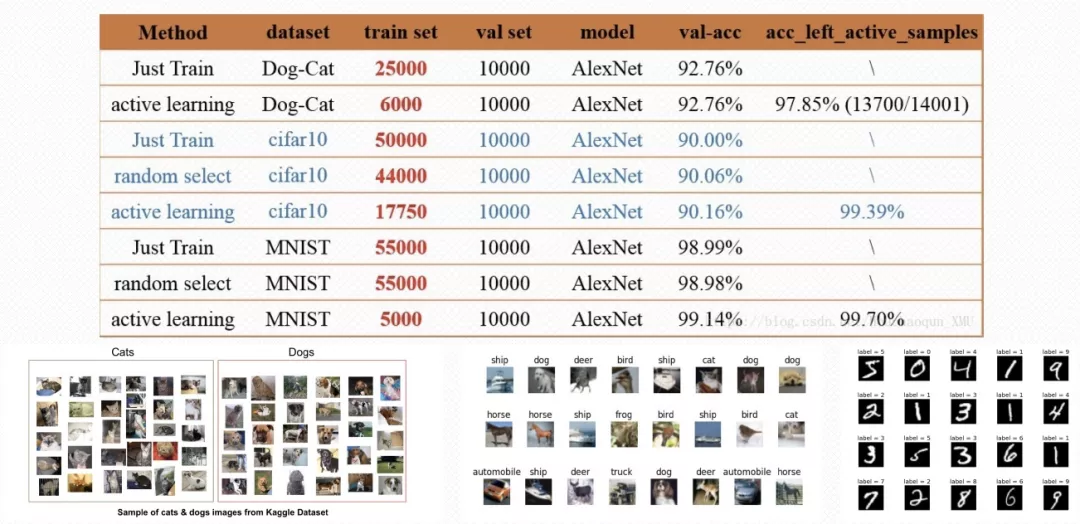
本文分享的实践部分,按照算法2-1分别对MNIST、Cifar-10和Dog-Cat三个数据集进行实验(分类模型使用了AlexNet,深度学习框架使用了PyTorch)。
如下表所示,在MNIST数据集的实验中(train_num=55000, val_num = 10000):
- 使用全部5.5万的训练数据直接训练模型,在1万个验证集得到的准确率为98.99%;
- 使用主动学习的不确定性策略(Uncertainty Strategy),只需要5000张标注样本,在相同的1万个验证集得到的准确率就达到99.14%。
此外,将训练好的模型对剩余的50000(55000-5000)张样本进行预测,得到99.70% 的效果。由此可见,仅仅使用不确定性策略在MNIST数据集上,就能够显著地减少大量的标注成本。值得注意的是,表中所示的三组图像分类数据集acc_left_active_samples 的准确率都很高。这部分样本表示未被主动学习策略筛选中的样本,即当前模型已经具备识别这部分样本的能力。
因此,模型在训练数据集的准确率达到 99.4% 时,使用当前模型对 acc_left_active_samples 这部分样本进行预测的精度也同样在 99.378% 左右,甚至更高。
问题1:主动学习为什么有时还能提升分类模型的准确率?
杨文柱等人发表的“主动学习算法研究进展”给出的解释是:标注样本可能存在低质量的样本,会降低模型的鲁棒性(模型过渡拟合噪声点)。如何高效地筛选出具有高分类贡献度的无类标样例进行标注,并补充到已有训练集中逐步提高分类器精度与鲁棒性是主动学习亟待解决的关键问题。
问题2:不确定性策略具体怎么实现?
重点关注每个样本预测结果的最大概率值:p_pred_max。我们初步认为 p_pred_max>0.5 的情况表示当前模型对该样本有个确定的分类结果(此处分类结果的正确与否不重要);反之,当前模型对该样本的判断结果模棱两可,标记为hard sample;比如:模型进行第一次预测,得到10个概率值,取其最大的概率 p_pred_max;对P(real lable) < p_threshold(此处的10分类任务取p_threshold=0.5)的样本进行排序,取前N个样本加入集合train_samples中;
应用:淘系商品的二分类问题
背景:商品的单包装和多包装属性影响着客户对商品价格的认知。比如:有些多包装属性的标价较高,但实际单价可能已经很划算了,而客户误将多包装的价格认为是单价,导致购买意向降低。因此区分出商品的包装属性对提高客户购买意向和优化商品价格分布具有较大的实际意义。对于此问题,有多种不同的解决方案。
其中,基于图像的分类方法能够直接的区分出商品的单/多包装属性。然而,监督学习需要大量的标注样本,众多品类将产生大量的标注需求,如何能够显著地减少标注代价也同样具有重大的意义。
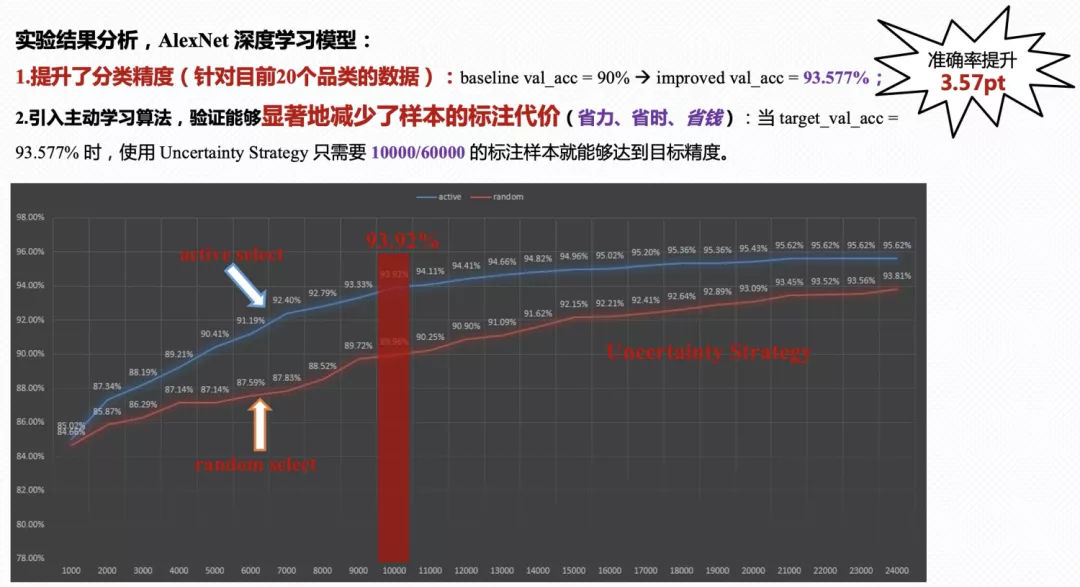
因此,我们尝试将主动学习方法应用图像分类中,解决单包装和多包装的二分类问题。如下图所示,我们分别对比了随机筛选策略和不确定策略。实验结果表明,引入不确定性策略主动筛选样本显著地减少了标注成本。
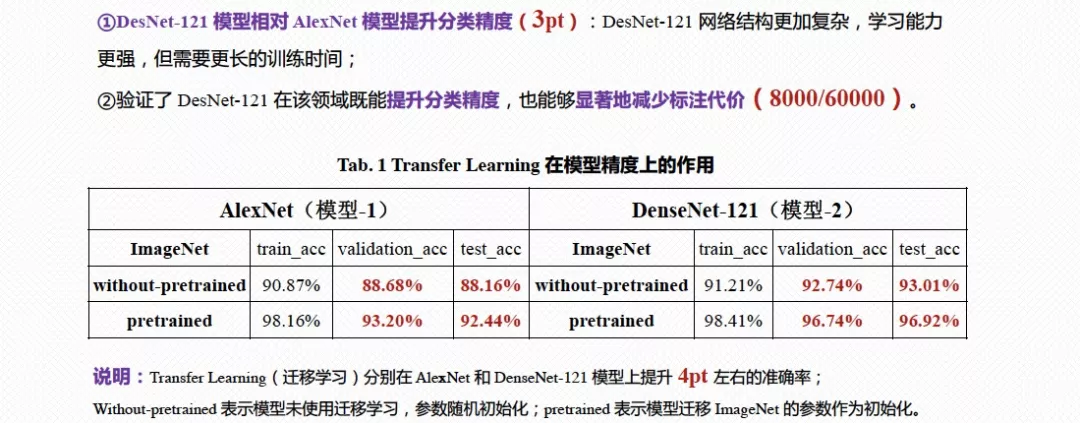
此外,我们尝试了更加复杂的模型(DesNet121),提高模型学习能力的同时,也带来了更多训练时长的弊端。但总体的分类精度提升了3pt。同时,我们也分别在AlexNet和DenseNet121等模型上验证了模型预训练带来的效率。
参考文献:
本文涉及的参考文献较多,由于篇幅问题,参考文献详见:




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧