

(一)主动学习概念与技术
主动学习背景介绍
机器学习的研究领域包括有监督学习(Supervised Learning),无监督学习(Unsupervised Learning),半监督学习(Semi-supervised Learning)和强化学习(Reinforcement Learning)等诸多内容。针对有监督学习和半监督学习,都需要一定数量的标注数据,也就是说在训练模型的时候,全部或者部分数据需要带上相应的标签才能进行模型的训练。但是在实际的业务场景或者生产环境中,工作人员获得样本的成本其实是不低的,甚至在某些时候是相对较高的,那么如何通过较少成本来获得较大价值的标注数据,进一步地提升算法的效果就是值得思考的问题了。
 机器学习
机器学习在工业界的图像标注领域,虽然有 ImageNet 这个学术界和工业界都在使用的图像数据库,但是在很多特殊的业务场景上,从业人员依旧需要想尽办法去获取业务标注数据。在安全风控领域,黑产用户相对于正常用户是偏少的,因此,如何通过极少的黑产用户来建立模型则是值得思考的问题之一。在业务运维领域,服务器,app 的故障时间相对于正常运行的时间也是偏少的,必然会出现样本不均衡的情况。因此,在这些业务领域,要想获得样本和构建模型,就必须要通过人力的参与。那么如何通过一些机器学习算法来降低人工标注的成本就是从业者需要关注的问题了。毕竟需要标注 100 个样本和需要标注成千上万的样本所需要的人力物力是截然不同的。
在学术界,同样有学者在关注这方面的问题,学者们通过一些技术手段或者数学方法来降低人们标注的成本,学者们把这个方向称之为主动学习(Active Learning)。在整个机器学习建模的过程中有人工参与的部分和环节,并且通过机器学习方法筛选出合适的候选集给人工标注的过程。主动学习(Active Learning)的大致思路就是:通过机器学习的方法获取到那些比较“难”分类的样本数据,让人工再次确认和审核,然后将人工标注得到的数据再次使用有监督学习模型或者半监督学习模型进行训练,逐步提升模型的效果,将人工经验融入机器学习的模型中。
在没有使用主动学习(Active Learning)的时候,通常来说系统会从样本中随机选择或者使用一些人工规则的方法来提供待标记的样本供人工进行标记。这样虽然也能够带来一定的效果提升,但是其标注成本总是相对大的。
用一个例子来比喻,一个高中生通过做高考的模拟试题以希望提升自己的考试成绩,那么在做题的过程中就有几种选择。一种是随机地从历年高考和模拟试卷中随机选择一批题目来做,以此来提升考试成绩。但是这样做的话所需要的时间也比较长,针对性也不够强;另一种方法是每个学生建立自己的错题本,用来记录自己容易做错的习题,反复地巩固自己做错的题目,通过多次复习自己做错的题目来巩固自己的易错知识点,逐步提升自己的考试成绩。其主动学习的思路就是选择一批容易被错分的样本数据,让人工进行标注,再让机器学习模型训练的过程。
那么主动学习(Active Learning)的整体思路究竟是怎样的呢?在机器学习的建模过程中,通常包括样本选择,模型训练,模型预测,模型更新这几个步骤。在主动学习这个领域则需要把标注候选集提取和人工标注这两个步骤加入整体流程,也就是:
- 机器学习模型:包括机器学习模型的训练和预测两部分;
- 待标注的数据候选集提取:依赖主动学习中的查询函数(Query Function);
- 人工标注:专家经验或者业务经验的提炼;
- 获得候选集的标注数据:获得更有价值的样本数据;
- 机器学习模型的更新:通过增量学习或者重新学习的方式更新模型,从而将人工标注的数据融入机器学习模型中,提升模型效果。
 主动学习的流程
主动学习的流程通过这种循环往复的方法,就可以达到人工调优模型的结果。其应用的领域包括:
- 个性化的垃圾邮件,短信,内容分类:包括营销短信,订阅邮件,垃圾短信和邮件等等;
- 异常检测:包括但不限于安全数据异常检测,黑产账户识别,时间序列异常检测等等。
主动学习的模型分类包括两种,第一种是流式的主动学习(Sequential Active Learning),第二种是离线批量的主动学习(Pool-based Active Learning)。在不同的场景下,业务人员可以选择不同的方案来执行。
 主动学习的三种场景
主动学习的三种场景而查询策略(Query Strategy Frameworks)就是主动学习的核心之处,通常可以选择以下几种查询策略:
- 不确定性采样的查询(Uncertainty Sampling);
- 基于委员会的查询(Query-By-Committee);
- 基于模型变化期望的查询(Expected Model Change);
- 基于误差减少的查询(Expected Error Reduction);
- 基于方差减少的查询(Variance Reduction);
- 基于密度权重的查询(Density-Weighted Methods)。
不确定性采样(Uncertainty Sampling)
顾名思义,不确定性采样的查询方法就是将模型中难以区分的样本数据提取出来,提供给业务专家或者标注人员进行标注,从而达到以较快速度提升算法效果的能力。而不确定性采样方法的关键就是如何描述样本或者数据的不确定性,通常有以下几种思路:
- 置信度最低(Least Confident);
- 边缘采样(Margin Sampling);
- 熵方法(Entropy);
Least Confident
对于二分类或者多分类的模型,通常它们都能够对每一个数据进行打分,判断它究竟更像哪一类。例如,在二分类的场景下,有两个数据分别被某一个分类器预测,其对两个类别的预测概率分别是:(0.9,0.1) 和 (0.51, 0.49)。在此情况下,第一个数据被判定为第一类的概率是 0.9,第二个数据被判定为第一类的概率是 0.51,于是第二个数据明显更“难”被区分,因此更有被继续标注的价值。所谓 Least Confident 方法就是选择那些最大概率最小的样本进行标注,用数学公式描述就是:

其中 
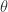


Margin Sampling
边缘采样(margin sampling)指的是选择那些极容易被判定成两类的样本数据,或者说这些数据被判定成两类的概率相差不大。边缘采样就是选择模型预测最大和第二大的概率差值最小的样本,用数学公式来描述就是:

其中 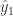
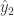
特别地,如果针对二分类问题,least confident 和 margin sampling 其实是等价的。
Entropy
在数学中,可以使用熵(Entropy)来衡量一个系统的不确定性,熵越大表示系统的不确定性越大,熵越小表示系统的不确定性越小。因此,在二分类或者多分类的场景下,可以选择那些熵比较大的样本数据作为待定标注数据。用数学公式表示就是:
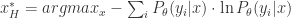
相较于 least confident 和 margin sample 而言,entropy 的方法考虑了该模型对某个
 不确定性采样的差异性
不确定性采样的差异性基于委员会的查询(Query-By-Committee)
除了考虑单个模型的不确定性采样方法之外,还可以考虑多个模型的场景,这就是类似集成学习的方法。通过多个模型投票的模式,来选择出那些较“难”区分的样本数据。在 QBC(Query-By-Committee)的技术方案中,可以假设有 


如果不需要考虑每个模型的检测效果,其实可以考虑类似不确定性采样中的 least confident 和 margin sampling 方法。可以选择某一个分类器难以区分的样本数据,也可以选择其中两三个分类器难以区分的数据。但是如果要考虑所有模型的分类效果的时候,则还是需要熵(Entropy)或者 KL 散度等指标。因此,QBC 通常也包括两种方法:
- 投票熵(Vote Entropy):选择这些模型都无法区分的样本数据;
- 平均 KL 散度(Average Kullback-Leibler Divergence):选择 KL 散度较大的样本数据。
投票熵(Vote Entropy)
对于这种多模型

其中 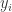

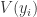
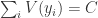
平均 KL 散度(Average KL Divergence)
KL 散度可以衡量两个概率之间的“距离”,因此可以用 KL 散度计算出那些偏差较大的数据样本。用数学公式来描述就是:

其中 

期望模型变化(Expected Model Change)
模型变化最大其实可以选择那些使得梯度变化最大的样本数据。
期望误差减少(Expected Error Reduction)
可以选择那些通过增加一个样本就使得 loss 函数减少最多的样本数据。
方差减少(Variance Reduction)
选择那些方差减少最多的样本数据。
基于密度权重的选择方法(Density-Weighted Methods)
有的时候,某个数据点可能是异常点或者与大多数数据偏差较大,不太适合做样本选择或者区分,某些时候考虑那些稠密的,难以区分的数据反而价值更大。于是,可以在使用不确定性采样或者 QBC 方法的时候,将样本数据的稠密性考虑进去。用数学公式表示就是:
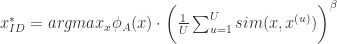
在这里,
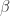


 B 附近的点信息量会大于 A 附近的点
B 附近的点信息量会大于 A 附近的点总结
在主动学习(Active Learning)领域,其关键在于如何选择出合适的标注候选集给人工进行标注,而选择的方法就是所谓的查询策略(Query Stategy)。查询策略基本上可以基于单个机器学习模型,也可以基于多个机器学习模型,在实际使用的时候可以根据情况来决定。整体来看,主动学习都是为了降低标注成本,迅速提升模型效果而存在的。主动学习的应用场景广泛,包括图像识别,自然语言处理,安全风控,时间序列异常检测等诸多领域。后续笔者将会持续关注这一领域的发展并撰写相关文档。
参考资料
- Settles, Burr. Active learning literature survey. University of Wisconsin-Madison Department of Computer Sciences, 2009.
- Aggarwal, Charu C., et al. “Active learning: A survey.” Data Classification: Algorithms and Applications. CRC Press, 2014. 571-605.
- https://zr9558.com/2020/09/13/activelearning-2/
- https://zhuanlan.zhihu.com/p/239756522


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧