

文本分类(六):不平衡文本分类,Focal Loss理论及PyTorch实现
转载于:https://zhuanlan.zhihu.com/p/361152151
转载于:https://www.jianshu.com/p/30043bcc90b6
摘要:本篇主要从理论到实践解决文本分类中的样本不均衡问题。首先讲了下什么是样本不均衡现象以及可能带来的问题;然后重点从数据层面和模型层面讲解样本不均衡问题的解决策略。数据层面主要通过欠采样和过采样的方式来人为调节正负样本比例,模型层面主要是通过加权Loss,包括基于类别Loss、Focal Loss和GHM Loss三种加权Loss函数;最后讲了下其他解决样本不均衡的策略,可以通过调节阈值修改正负样本比例和利用半监督或自监督学习解决样本不均衡问题。需要说明下上面解决样本不均衡问题的策略不仅仅适用于文本分类任务,还可以扩展到其他的机器学习任务中。对于希望解决样本不均衡问题的小伙伴可能有所帮助。
一、机器学习中的样本不均衡问题
1.1 什么是样本不均衡现象
机器学习领域中样本不均衡现象随处可见。咱们举一些例子说明,图片分类任务中假如我们要做猫狗图片的识别任务,因为猫狗在日常生活中随处可见,所以对应的样本猫和狗的图片很好找,样本比较均衡,咱们能很容易的得到1W张猫的图片和1W张狗的图片。但是如果我们现在做狗和狼图片识别任务,那情况就有些变化了。我们还是能方便的得到1W张狗的图片,但是狼因为在生活中不怎么常见,所以在同样的数据采集成本下我们可能只得到100张甚至更少的狼的图片。
还有比如CTR任务中我们需要预测用户是否会对广告进行点击,通常情况下曝光一个广告用户点击的比率非常低,这里我们假如给101个用户曝光广告可能只有一个人点击,那么得到的正负样本比例就为1:100。如果是更高层级的广告转化目标比如下载、付费等正负样本的比例就更低了。
同样的例子会出现在文本分类任务中,假如我们要做一个识别是否对传奇游戏标签感兴趣的文本二分类器,用户搜索中这部分的比例非常少,也许1W条用户搜索query中只有50条甚至更少的样本属于正例。这种现象就是样本不均衡,因为样本会呈现一个长尾分布,头部的标签包含了大量的样本,而尾部的标签拥有很少的样本,就像下面这张图片中表现的那样出现一个长长的尾巴,所以这种现场也称为长尾现象。
 图1 长尾现象
图1 长尾现象
1.2 样本不均衡可能带来的问题
上面讲了样本不均衡的现象在机器学习场景中经常出现,那么样本不均衡会带来什么问题呢?众所周知模型训练的本质是最小化损失函数,当某个类别的样本数量非常庞大,损失函数的值大部分被样本数量较大的类别所影响,导致的结果就是模型分类会倾向于样本量较大的类别。咱们拿上面文本分类的例子来说明,现在有1W条用户搜索的样本,其中50条和传奇游戏标签有关,9950条和传奇游戏标签无关,那么模型全部将样本预测为负例,也能得到99.5%的准确率,会让人有一种模型效果还不错的假象,但是实际的情况是这个模型根本没什么卵用,因为我们的目标是识别出这些数量较少的类别。这也是我们在实际业务场景中遇到的问题。
总体来看,解决样本不均衡的问题主要从数据层面和模型层面来解决,下面会分别从理论到实践的角度分享样本不均衡问题的解决策略。
二、从数据层面解决样本不均衡问题
现在我们遇到样本不均衡的问题,假如我们的正样本只有100条,而负样本可能有1W条。如果不采取任何策略,那么我们就是使用这1.01W条样本去训练模型。从数据层面解决样本不均衡的问题核心是通过人为控制正负样本的比例,分成欠采样和过采样两种。
2.1 欠采样
欠采样的基本做法是这样的,现在我们的正负样本比例为1:100。如果我们想让正负样本比例不超过1:10,那么模型训练的时候数量比较少的正样本也就是100条全部使用,而负样本随机挑选1000条,这样通过人为的方式我们把样本的正负比例强行控制在了1:10。这种方式存在一个问题,为了强行控制样本比例我们生生的舍去了那9000条负样本,这对于模型来说是莫大的损失。
相比于简单的对负样本随机采样的欠采样方法,实际工作中我们会使用迭代预分类的方式来采样负样本。具体流程如下图所示:
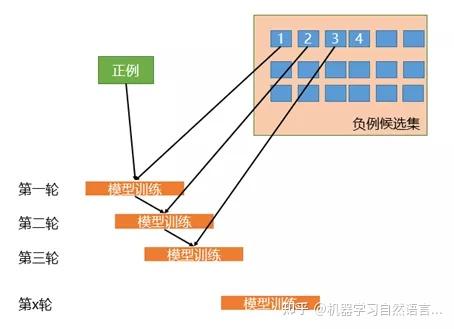 图2 迭代预分类方式的欠采样
图2 迭代预分类方式的欠采样
首先我们会使用全部的正样本和从负例候选集中随机采样一部分负样本(这里假如是100条)去训练第一轮分类器;然后用第一轮分类器去预测负例候选集剩余的9900条数据,把9900条负例中预测为正例的样本(也就是预测错误的样本)再随机采样100条和第一轮训练的数据放到一起去训练第二轮分类器;同样的方法用第二轮分类器去预测负例候选集剩余的9800条数据,直到训练的第N轮分类器可以全部识别负例候选集,这就是使用迭代预分类的方式进行欠采样。
相比于随机欠采样来说迭代预分类的欠采样方式能最大限度的利用负样本中差异性较大的负样本,从而在控制正负样本比例的基础上采样出了最有代表意义的负样本。
欠采样的方式整体来说或多或少的会损失一些样本,对于那些需要控制样本量级的场景下比较合适。如果没有严格控制样本量级的要求那么下面的过采样可能会更加适合你。
2.2 过采样
过采样和上面的欠采样比较类似,都是人工干预控制样本的比例,不同的是过采样不会损失样本。还拿上面的例子,现在有正样本100条,负样本1W条,最简单的过采样方式是我们会使用全部的负样本1W条,但是为了维持正负样本比例,我们会从正样本中有放回的重复采样,直到获取了1000条正样本,也就是说有些正样本可能会被重复采样到,这样就能保持1:10的正负样本比例了。这是最简单的过采样方式。
之前组里的小伙伴分享了基于SMOTE算法的过采样方式,感兴趣的小伙伴们可以关注下。在文本分类场景中我们主要通过样本增强技术来实现过采样。之前分享过一篇关于样本增强技术的文章《广告行业中那些趣事系列13:NLP中超实用的样本增强技术》,里面包含了回译技术、替换技术、随机噪声引入技术等方法可以实现样本增强,通过这种方式可以增加正样本,并且使得增加的正样本不仅仅是简单的重复样本,而是有细微差异的正样本,这里不再赘述。因为之前还没接触过文本生成,所以介绍的方法里通过文本生成来增强样本的部分比较少。最近参加了公司的比赛,了解了一些文本生成的技术,增加点这段时间学到的通过文本生成的角度来实现文本增强的知识和大家分享下。
从文本生成的角度来增加正样本从而间接的使用过采样的方式来控制正负样本比例主要尝试过基于BERT的有条件生成任务和基于SIMBERT来生成相似文本任务:
(1) 基于BERT的有条件生成文本
基于BERT的有条件生成任务主要是利用微软提供的UNILM来将BERT改造成可以处理Seq2Seq的任务,从而完成文本生成任务。下面是我用广告文案语料微调BERT从而生成的部分标签的文案的结果数据:
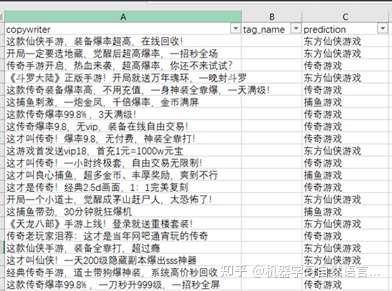 图3 基于BERT的有条件生成任务部分结果
图3 基于BERT的有条件生成任务部分结果
从上图中可以发现生成的文本其实和我们使用的文案语料很相似,但是又不完全相同。模型通过微调训练语料学习到了各个标签的知识,然后运用这些知识生成了相似的文案,这些文案虽然只有部分修改,但是语义是比较合理的,所以生成的结果也比较合理。这块使用的是苏剑林的bert4keras中的例子,有兴趣的小伙伴可以自己跑来玩一下:
(2) 基于SIMBERT生成相似文本
基于SIMBERT生成相似文本的方法是另外一种文本生成的方式,主要原理是生成和当前query比较相似的文本从而达到样本增强的目的。下面是我们使用SIMBERT来生成相似文本的结果:
 图4 使用SIMBERT生成相似文本
图4 使用SIMBERT生成相似文本
上图中我们输入的初始文本是“想开一家奶茶店,需要多少的预算?”,然后下面就是自动生成的相似的文本。可以发现生成的结果还不赖,整体语义一致,而文本的形式会有些许不同,从而达到了样本增强的目的。这块使用的也是苏剑林的bert4keras中的例子,感兴趣的小伙伴可以去试试:
三、从模型层面解决样本不均衡问题
上面主要从数据的层面来解决样本不均衡的问题,本节主要从模型层面解决样本不均衡的问题。相比于控制正负样本的比例,我们还可以通过控制Loss损失函数来解决样本不均衡的问题。拿二分类任务来举例,通常使用交叉熵来计算损失,下面是交叉熵的公式:
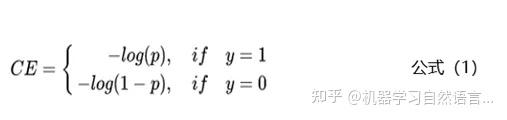
上面的公式中y是样本的标签,p是样本预测为正例的概率。
3.1 类别加权Loss
为了解决样本不均衡的问题,最简单的是基于类别的加权Loss,具体公式如下:
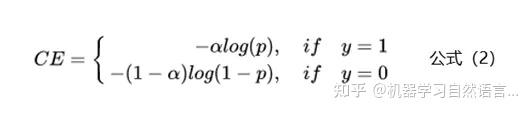
基于类别加权的Loss其实就是添加了一个参数a,这个a主要用来控制正负样本对Loss带来不同的缩放效果,一般和样本数量成反比。还拿上面的例子举例,有100条正样本和1W条负样本,那么我们设置a的值为10000/10100,那么正样本对Loss的贡献值会乘以一个系数10000/10100,而负样本对Loss的贡献值则会乘以一个比较小的系数100/10100,这样相当于控制模型更加关注正样本对损失函数的影响。通过这种基于类别的加权的方式可以从不同类别的样本数量角度来控制Loss值,从而一定程度上解决了样本不均衡的问题。
3.2 Focal Loss
上面基于类别加权Loss虽然在一定程度上解决了样本不均衡的问题,但是实际的情况是不仅样本不均衡会影响Loss,而且样本的难易区分程度也会影响Loss。基于这个问题2017年何恺明大神在论文《Focal Loss for Dense Object Detection》中提出了非常火的Focal Loss,下面是Focal Loss的计算公式:
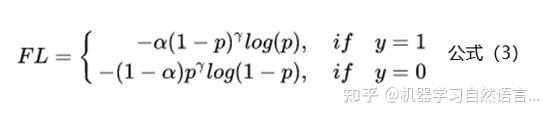
相比于公式2来说,Focal Loss添加了参数γ从置信的角度来加权Loss值。假如γ设置为0,那么公式3蜕变成了基于类别的加权也就是公式2;下面重点看看如何通过设置参数r来使得简单和困难样本对Loss的影响。当γ设置为2时,对于模型预测为正例的样本也就是p>0.5的样本来说,如果样本越容易区分那么(1-p)的部分就会越小,相当于乘了一个系数很小的值使得Loss被缩小,也就是说对于那些比较容易区分的样本Loss会被抑制,同理对于那些比较难区分的样本Loss会被放大,这就是Focal Loss的核心:通过一个合适的函数来度量简单样本和困难样本对总的损失函数的贡献。
关于参数γ的设置问题,Focal Loss的作者建议设置为2。下面是不同的参数值γ样本难易程度对Loss的影响对比图:
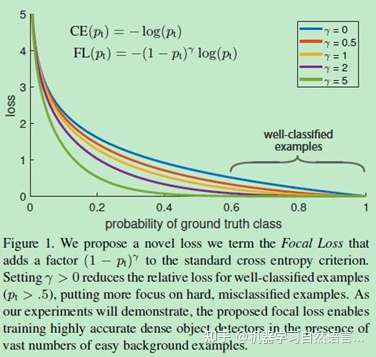 图5 不同的参数值γ样本难易程度对Loss的影响对比图
图5 不同的参数值γ样本难易程度对Loss的影响对比图
下面是一个Focal Loss的实现,感兴趣的小伙伴可以试试,看能不能对下游任务有积极效果:
 图6 Focal Loss的代码实现
图6 Focal Loss的代码实现
3.3 GHM Loss
Focal Loss主要结合样本的难易区分程度来解决样本不均衡的问题,使得整个Loss的曲线平滑稳定的下降,但是对于一些特别难区分的样本比如离群点会存在问题。可能一个模型已经收敛训练的很好了,但是因为一些比如标注错误的离群点使得模型去关注这些样本,反而降低了模型的效果。比如下面的离群点图:
 图7 离群点图
图7 离群点图
针对Focal Loss存在的问题,2019年论文《Gradient Harmonized Single-stage Detector》中提出了GHM(gradient harmonizing mechanism) Loss。相比于Focal Loss从置信度的角度去调整Loss,GHM Loss则是从一定范围置信度p的样本数量(论文中称为梯度密度)去调整Loss。
理解GHM Loss的第一步是先理解梯度模长的概念,梯度模长g的计算公式如下:
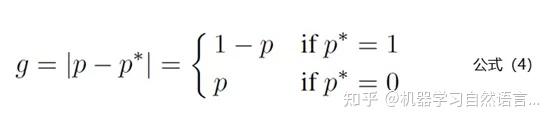
公式4中p代表模型预测为1的概率值,p*是标签值。也就是说如果样本越难区分,那么g的值就越大。下面看看梯度模长g和样本数量的关系图:
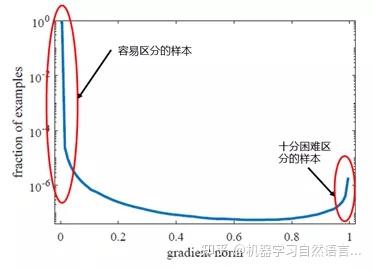 图8 梯度模长g和样本数量的关系
图8 梯度模长g和样本数量的关系
从上图中可以看出样本中有很大一部分是容易区分的样本,也就是梯度模长g趋于0的部分。但是还存在一些十分困难区分的样本,也就是上图中右边红圈中的样本。GHM Loss认为不仅仅要多关注容易区分的样本,这点和Focal Loss一致,同时还认为需要关注那些十分困难区分的样本,因为这部分样本可能是标注错误的离群点,过多的关注这部分样本不仅不会提升模型的效果,反而还会有一定的逆向效果。那么问题来了,怎么同时抑制容易区分的样本和十分困难区分的样本呢?
针对这个问题,从上图中可以发现容易区分的样本和十分困难区分的样本都存在一个共同点:数量多。那么只要我们抑制一定梯度范围内数量多的样本就可以达到这个效果,GHM Loss通过梯度密度GD(g)来表示一定梯度范围内的样本数量。这个其实有点像物理学中的密度,一定体积的物体的质量。梯度密度GD(G)的公式如下:
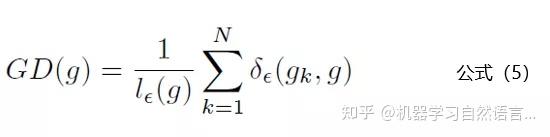
公式5中 代表样本中梯度模长g分布在
范围里面的样本的个数,
代表了
区间的长度。公式里面的细节小伙伴们可以去论文里面详细了解。
说完了梯度密度GD(g)的计算公式,下面就是GHM Loss的计算公式:
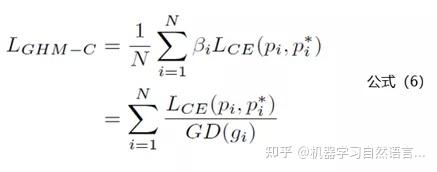
公式6中的Lce其实就是交叉熵损失函数,也就是公式1。
下面看看交叉熵损失函数、Focal Loss和GHM Loss三种损失函数对不同梯度模长样本的抑制效果图:
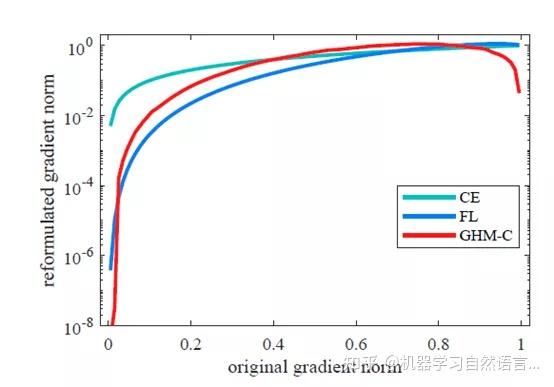 图9 三种损失函数对样本的抑制效果图
图9 三种损失函数对样本的抑制效果图
从上图中可以看出交叉熵损失函数基本没有抑制效果,Focal Loss可以有效的抑制容易区分的样本,而GHM Loss不仅可以很好的抑制简单样本,还能抑制十分困难的样本。
下面是复现了GHM Loss的一个github上工程,有兴趣的小伙伴可以试试:
https://github.com/libuyu/GHM_Detection
四、其他解决样本不均衡问题的策略
上面主要是从数据层面和模型损失函数来解决样本不均衡的问题,下面是一些其他的样本不均衡策略:
4.1 调节阈值修改正负样本比例
通常情况下Sigmoid函数会将大于0.5的阈值预测为正样本。这时候我们可以通过调节阈值来调整正负样本比例,比如设置0.3分作为阈值,将大于0.3的样本都判定为正样本,这样相当于增加了正样本的比例。
4.2 利用半监督或自监督学习解决样本不均衡
之前领导分享过一篇知乎高赞的文章,主要是通过半监督或自监督学习来解决样本不均衡的问题,因为篇幅有限,这里就不详细介绍。后面可能会专门出一篇文章来详细讲解这种策略。这里先把链接放在这里,有兴趣的小伙伴也可以学习下:
NeurIPS 2020 | 数据类别不平衡/长尾分布?不妨利用半监督或自监督学习
总结
本篇主要从理论到实践解决文本分类中的样本不均衡问题。首先讲了下什么是样本不均衡现象以及可能带来的问题;然后重点从数据层面和模型层面讲解样本不均衡问题的解决策略。数据层面主要通过欠采样和过采样的方式来人为调节正负样本比例,模型层面主要是通过加权Loss,包括基于类别Loss、Focal Loss和GHM Loss三种加权Loss函数;最后讲了下其他解决样本不均衡的策略,可以通过调节阈值修改正负样本比例和利用半监督或自监督学习解决样本不均衡问题。需要说明下上面解决样本不均衡问题的策略不仅仅适用于文本分类任务,还可以扩展到其他的机器学习任务中。对于希望解决样本不均衡问题的小伙伴可能有所帮助。
参考资料
[1] 《Focal Loss forDense Object Detection》
[2]《GradientHarmonized Single-stage Detector》
五、实战
一、基本理论
- 采用soft - gamma: 在训练的过程中阶段性的增大gamma 可能会有更好的性能提升。
- alpha 与每个类别在训练数据中的频率有关。
- F.nll_loss(torch.log(F.softmax(inputs, dim=1),target)的函数功能与F.cross_entropy相同。
F.nll_loss中实现了对于target的one-hot encoding,将其编码成与input shape相同的tensor,然后与前面那一项(即F.nll_loss输入的第一项)进行 element-wise production。

-
focal loss解决了什么问题?
(1)不同类别不均衡
(2)难易样本不均衡 -
在retinanet中,除了使用呢focal loss外,还对初始化做了特殊处理,具体是怎么做的?
在retinanet中,对 classification subnet 的最后一层conv设置它的偏置b为:
b=−log((1−π)/π)
π代表先验概率,就是类别不平衡中个数少的那个类别占总数的百分比,在检测中就是代表object的anchor占所有anchor的比重,论文中设置的为0.01。
二、公式
标准的Cross Entropy 为:[图片上传失败...(image-286df1-1571884440851)]
Focal Loss 为:[图片上传失败...(image-460db1-1571884440851)]
其中,[图片上传失败...(image-d6c655-1571884440851)]
关于Focal Loss的前向与后向推导见:知乎:Focal Loss 的前向与后向公式推导
三、代码实现
一、来自Kaggle的实现(基于二分类交叉熵实现)
class FocalLoss(nn.Module):
def __init__(self, alpha=1, gamma=2, logits=False, reduce=True):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.logits = logits
self.reduce = reduce
def forward(self, inputs, targets):
if self.logits:
BCE_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduce=False)
else:
BCE_loss = F.binary_cross_entropy(inputs, targets, reduce=False)
pt = torch.exp(-BCE_loss)
F_loss = self.alpha * (1-pt)**self.gamma * BCE_loss
if self.reduce:
return torch.mean(F_loss)
else:
return F_loss
二、来自知乎大佬的实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
class FocalLoss(nn.Module):
r"""
This criterion is a implemenation of Focal Loss, which is proposed in
Focal Loss for Dense Object Detection.
Loss(x, class) = - \alpha (1-softmax(x)[class])^gamma \log(softmax(x)[class])
The losses are averaged across observations for each minibatch.
Args:
alpha(1D Tensor, Variable) : the scalar factor for this criterion
gamma(float, double) : gamma > 0; reduces the relative loss for well-classified examples (p > .5),
putting more focus on hard, misclassified examples
size_average(bool): By default, the losses are averaged over observations for each minibatch.
However, if the field size_average is set to False, the losses are
instead summed for each minibatch.
"""
def __init__(self, class_num, alpha=None, gamma=2, size_average=True):
super(FocalLoss, self).__init__()
if alpha is None:
self.alpha = Variable(torch.ones(class_num, 1))
else:
if isinstance(alpha, Variable):
self.alpha = alpha
else:
self.alpha = Variable(alpha)
self.gamma = gamma
self.class_num = class_num
self.size_average = size_average
def forward(self, inputs, targets):
N = inputs.size(0)
C = inputs.size(1)
P = F.softmax(inputs)
class_mask = inputs.data.new(N, C).fill_(0)
class_mask = Variable(class_mask)
ids = targets.view(-1, 1)
class_mask.scatter_(1, ids.data, 1.)
#print(class_mask)
if inputs.is_cuda and not self.alpha.is_cuda:
self.alpha = self.alpha.cuda()
alpha = self.alpha[ids.data.view(-1)]
probs = (P*class_mask).sum(1).view(-1,1)
log_p = probs.log()
#print('probs size= {}'.format(probs.size()))
#print(probs)
batch_loss = -alpha*(torch.pow((1-probs), self.gamma))*log_p
#print('-----bacth_loss------')
#print(batch_loss)
if self.size_average:
loss = batch_loss.mean()
else:
loss = batch_loss.sum()
return loss
参考
- 知乎:Focal Loss 的Pytorch 实现以及实验
- Kaggle:A Pytorch implementation of Focal Loss
- GitHub:CoinCheung/pytorch-loss
- GitHub:Hsuxu/Loss_ToolBox-PyTorch
- 知乎:focal loss理解与初始化偏置b设置解释
- 个人博客:对focal loss中bias init的解释很好


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)