

文本分类(三):使用Pytorch进行文本分类——Transformer
一、前言
文本分类不是生成式的任务,因此只使用Transformer的编码部分(Encoder)进行特征提取。如果不熟悉Transformer模型的原理请移步。
二、架构图
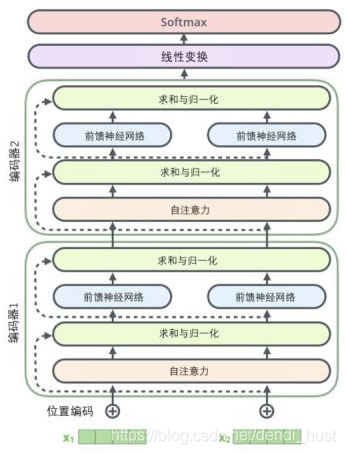
三、代码
1、自注意力模型

class TextSlfAttnNet(nn.Module): ''' 自注意力模型 ''' def __init__(self, config: TextSlfAttnConfig, char_size=5000, pinyin_size=5000): super(TextSlfAttnNet, self).__init__() # 字向量 self.char_embedding = nn.Embedding(char_size, config.embedding_size) # 拼音向量 self.pinyin_embedding = nn.Embedding(pinyin_size, config.embedding_size) # 位置向量 self.pos_embedding = nn.Embedding.from_pretrained( get_sinusoid_encoding_table(config.max_sen_len, config.embedding_size, padding_idx=0), freeze=True) self.layer_stack = nn.ModuleList([ EncoderLayer(config.embedding_size, config.hidden_dims, config.n_heads, config.k_dims, config.v_dims, dropout=config.keep_dropout) for _ in range(config.hidden_layers) ]) self.fc_out = nn.Sequential( nn.Dropout(config.keep_dropout), nn.Linear(config.embedding_size, config.hidden_dims), nn.ReLU(inplace=True), nn.Dropout(config.keep_dropout), nn.Linear(config.hidden_dims, config.num_classes), ) def forward(self, char_id, pinyin_id, pos_id): char_inputs = self.char_embedding(char_id) pinyin_iputs = self.pinyin_embedding(pinyin_id) sen_inputs = torch.cat((char_inputs, pinyin_iputs), dim=1) # sentence_length = sen_inputs.size()[1] # pos_id = torch.LongTensor(np.array([i for i in range(sentence_length)])) pos_inputs = self.pos_embedding(pos_id) # batch_size * sen_len * embedding_size inputs = sen_inputs + pos_inputs for layer in self.layer_stack: inputs, _ = layer(inputs) enc_outs = inputs.permute(0, 2, 1) enc_outs = torch.sum(enc_outs, dim=-1) return self.fc_out(enc_outs)
2、编码层
class EncoderLayer(nn.Module): '''编码层''' def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1): ''' :param d_model: 模型输入维度 :param d_inner: 前馈神经网络隐层维度 :param n_head: 多头注意力 :param d_k: 键向量 :param d_v: 值向量 :param dropout: ''' super(EncoderLayer, self).__init__() self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout) self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout) def forward(self, enc_input, non_pad_mask=None, slf_attn_mask=None): ''' :param enc_input: :param non_pad_mask: :param slf_attn_mask: :return: ''' enc_output, enc_slf_attn = self.slf_attn(enc_input, enc_input, enc_input, mask=slf_attn_mask) if non_pad_mask is not None: enc_output *= non_pad_mask enc_output = self.pos_ffn(enc_output) if non_pad_mask is not None: enc_output *= non_pad_mask return enc_output, enc_slf_attn
3、多头注意力
class MultiHeadAttention(nn.Module): ''' “多头”注意力模型 ''' def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1): ''' :param n_head: “头”数 :param d_model: 输入维度 :param d_k: 键向量维度 :param d_v: 值向量维度 :param dropout: ''' super(MultiHeadAttention, self).__init__() self.n_head = n_head self.d_k = d_k self.d_v = d_v # 产生 查询向量q,键向量k, 值向量v self.w_qs = nn.Linear(d_model, n_head * d_k) self.w_ks = nn.Linear(d_model, n_head * d_k) self.w_vs = nn.Linear(d_model, n_head * d_v) nn.init.normal_(self.w_qs.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_k))) nn.init.normal_(self.w_ks.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_k))) nn.init.normal_(self.w_vs.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_v))) self.attention = ScaledDotProductAttention(temperature=np.power(d_k, 0.5)) self.layer_normal = nn.LayerNorm(d_model) self.fc = nn.Linear(n_head * d_v, d_model) nn.init.xavier_normal_(self.fc.weight) self.dropout = nn.Dropout(dropout) def forward(self, q, k, v, mask=None): ''' 计算多头注意力 :param q: 用于产生 查询向量 :param k: 用于产生 键向量 :param v: 用于产生 值向量 :param mask: :return: ''' d_k, d_v, n_head = self.d_k, self.d_v, self.n_head sz_b, len_q, _ = q.size() sz_b, len_k, _ = k.size() sz_b, len_v, _ = v.size() residual = q q = self.w_qs(q).view(sz_b, len_q, n_head, d_k) k = self.w_ks(k).view(sz_b, len_k, n_head, d_k) v = self.w_vs(v).view(sz_b, len_v, n_head, d_v) # (n*b) x lq x dk q = q.permute(2, 0, 1, 3).contiguous().view(-1, len_q, d_k) # (n*b) x lk x dk k = k.permute(2, 0, 1, 3).contiguous().view(-1, len_k, d_k) # (n*b) x lv x dv v = v.permute(2, 0, 1, 3).contiguous().view(-1, len_v, d_v) # mask = mask.repeat(n_head, 1, 1) # (n*b) x .. x .. # output, attn = self.attention(q, k, v, mask=None) # (n_heads * batch_size) * lq * dv output = output.view(n_head, sz_b, len_q, d_v) # batch_size * len_q * (n_heads * dv) output = output.permute(1, 2, 0, 3).contiguous().view(sz_b, len_q, -1) output = self.dropout(self.fc(output)) output = self.layer_normal(output + residual) return output, attn
4、前馈神经网络
class PositionwiseFeedForward(nn.Module): ''' 前馈神经网络 ''' def __init__(self, d_in, d_hid, dropout=0.1): ''' :param d_in: 输入维度 :param d_hid: 隐藏层维度 :param dropout: ''' super(PositionwiseFeedForward, self).__init__() self.w_1 = nn.Conv1d(d_in, d_hid, 1) self.w_2 = nn.Conv1d(d_hid, d_in, 1) self.layer_normal = nn.LayerNorm(d_in) self.dropout = nn.Dropout(dropout) def forward(self, x): residual = x output = x.transpose(1, 2) output = self.w_2(F.relu(self.w_1(output))) output = output.transpose(1, 2) output = self.dropout(output) output = self.layer_normal(output + residual) return output
5、位置函数
def get_sinusoid_encoding_table(n_position, d_hid, padding_idx=None): ''' 计算位置向量 :param n_position: 位置的最大值 :param d_hid: 位置向量的维度,和字向量维度相同(要相加求和) :param padding_idx: :return: ''' def cal_angle(position, hid_idx): return position / np.power(10000, 2 * (hid_idx // 2) / d_hid) def get_posi_angle_vec(position): return [cal_angle(position, hid_j) for hid_j in range(d_hid)] sinusoid_table = np.array([get_posi_angle_vec(pos_i) for pos_i in range(n_position)]) sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1 if padding_idx is not None: # zero vector for padding dimension sinusoid_table[padding_idx] = 0. return torch.FloatTensor(sinusoid_table)
四、经验值
在分类任务中,与BILSTM+ATTENTION(链接)相比:
模型比LSTM大很多,同样的任务LSTM模型6M左右,Transformer模型55M;
收敛速度比较慢;
超参比较多,不易调参,但同时也意味着弹性比较大;
效果和BILSTM模型差不多;
分类:
文本分类


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧