

(十)pytorch多线程训练,DataLoader的num_works参数设置
一、概述
数据集较小时(小于2W)建议num_works不用管默认就行,因为用了反而比没用慢。
当数据集较大时建议采用,num_works一般设置为(CPU线程数+-1)为最佳,可以用以下代码找出最佳num_works(注意windows用户如果要使用多核多线程必须把训练放在if __name__ == '__main__':下才不会报错)
二、代码

import time import torch.utils.data as d import torchvision import torchvision.transforms as transforms if __name__ == '__main__': BATCH_SIZE = 100 transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]) train_set = torchvision.datasets.MNIST('\mnist', download=False, train=True, transform=transform) # data loaders train_loader = d.DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True) for num_workers in range(20): train_loader = d.DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True, num_workers=num_workers) # training ... start = time.time() for epoch in range(1): for step, (batch_x, batch_y) in enumerate(train_loader): pass end = time.time() print('num_workers is {} and it took {} seconds'.format(num_workers, end - start))
三、查看线程数
1、cpu个数
grep 'physical id' /proc/cpuinfo | sort -u
2、核心数
grep 'core id' /proc/cpuinfo | sort -u | wc -l
3、线程数
grep 'processor' /proc/cpuinfo | sort -u | wc -l
4、例子
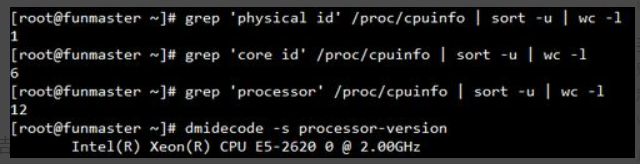
命令执行结果如图所示,根据结果得知,此服务器有1个cpu,6个核心,每个核心2线程,共12线程。
分类:
机器学习


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧